sparseml
v1.8.0
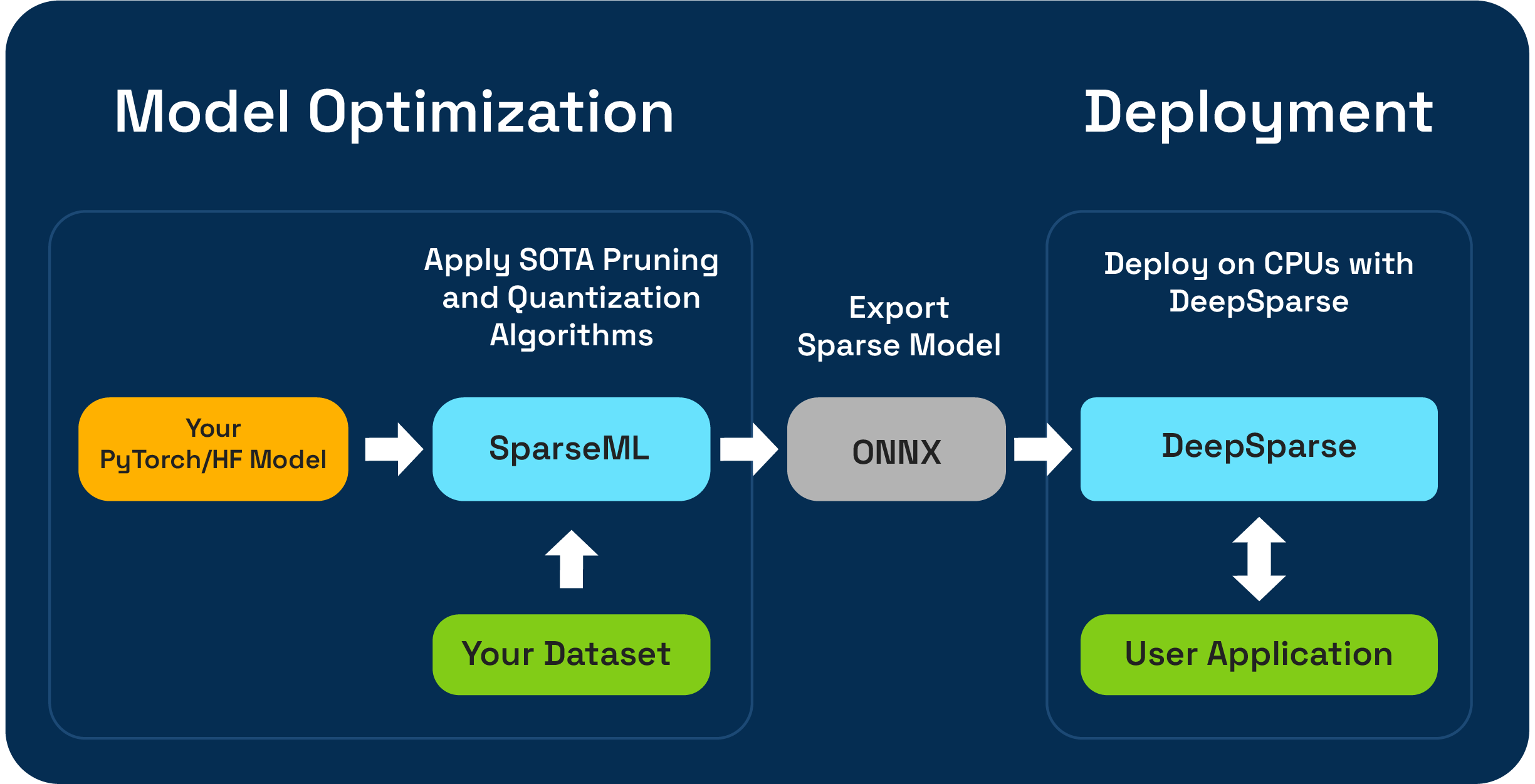
Sparseml ist ein Open-Source-Modelloptimierungs-Toolkit, mit dem Sie inferenzoptimierte spärliche Modelle mithilfe von Schnitt-, Quantisierungs- und Destillationsalgorithmen erstellen können. Modelle, die mit Sparseml optimiert sind, können dann in den ONNX exportiert und mit DeepSparse für die Leistung der GPU-Klasse auf CPU-Hardware bereitgestellt werden.
Neural Magic freut sich, eine One-Shot-LLM-Komprimierungs-Workflows mit dem neuen SparseGPTModfier voranzutreiben!
Um ein Tinyllama -Chat -Modell zu beschneiden und zu quantisieren, sind es nur einige Schritte, um Abhängigkeiten zu installieren, ein Rezept herunterzuladen und auf das Modell anzuwenden:
git clone https://github.com/neuralmagic/sparseml
pip install -e "sparseml[transformers]"
wget https://huggingface.co/neuralmagic/TinyLlama-1.1B-Chat-v0.4-pruned50-quant-ds/raw/main/recipe.yaml
sparseml.transformers.text_generation.oneshot --model_name TinyLlama/TinyLlama-1.1B-Chat-v1.0 --dataset_name open_platypus --recipe recipe.yaml --output_dir ./obcq_deployment --precision float16
Die Readme von src/sparseml/transformers/sparsification/obcq hat eine detaillierte Anleitung.
Mit Sparseml können Sie ein spärliches Modell erstellen, das auf zwei Arten auf Ihrem Datensatz trainiert wird:
Mit einem spärlichen Übertragungslernen können Sie ein vorgespiegeltes Modell von Sparsezoo (ein Open-Source-Repository von spärlichen Modellen wie Bert, Yolov5 und Resnet-50) auf Ihrem Datensatz fein abteilen und gleichzeitig die Sparsamkeit beibehalten. Dieser Weg funktioniert genauso wie typische Feinabstimmungen, an die Sie im Training von CV- und NLP-Modellen gewöhnt sind, und wird dringend bevorzugt, wenn Ihre Modellarchitektur in Sparsezoo verfügbar ist.
Mit der Sparsifikation von Grund auf können Sie hochmoderne Beschneidungs-Beschneidung (wie das Beschneiden von Größen oder das Beschneiden von Obs) und die Quantisierung (wie das Quantisierungsbewusstsein) auf willkürliche Pytorch- und umarmende Gesichtsmodelle anwenden. Dieser Weg erfordert mehr Experimente, ermöglicht es Ihnen jedoch, eine spärliche Version eines beliebigen Modells zu erstellen.

Dieses Repository wird auf Python 3.8-3.11 und Linux/Debian-Systemen getestet.
Es wird empfohlen, in einer virtuellen Umgebung zu installieren, um Ihr System in Ordnung zu halten. Derzeit unterstützte ML -Frameworks sind Folgendes: torch>=1.1.0,<=2.0 , tensorflow>=1.8.0,<2.0.0 , tensorflow.keras >= 2.2.0 .
Installieren Sie mit PIP mit:
pip install sparsemlWeitere Informationen zur Installation wie optionale Abhängigkeiten und Anforderungen finden Sie hier.
Um Flexibilität, Benutzerfreundlichkeit und Wiederholbarkeit zu ermöglichen, verwendet Sparseml eine deklarative Schnittstelle, die als recipes bezeichnet wird, um die Sparsity-bezogenen Algorithmen und Hyperparameter anzugeben, die von Sparseml angewendet werden sollten.
Recipes werden Yaml-Files als eine Liste von modifiers formatiert, die die Anweisungen für Sparseml codieren. modifiers können von der Festlegung der Lernrate bis hin zur Codierung der Hyperparameter des Algorithmus zur Graditionsgröße sein. Das Sparseml -System analysiert die recipes für jeden Framework in ein nationales Format und wendet die Modifikationen an die Modell- und Trainingspipeline an.
Aufgrund des deklarativen, rezeptbasierten Ansatzes können Sie Ihren vorhandenen Pytorch-Trainingspipelines Sparseml hinzufügen. Die ScheduleModifierManager -Klasse ist für die Parsen der YAML recipes und für die überschreibende Standard -Pytorch- und Optimierer -Objekte verantwortlich, wodurch die Logik der Sparsity -Algorithmen aus dem Rezept codiert wird. Sobald Sie manager.modify anrufen.
Der Workflow sieht so aus:
model = Model () # model definition
optimizer = Optimizer () # optimizer definition
train_data = TrainData () # train data definition
batch_size = BATCH_SIZE # training batch size
steps_per_epoch = len ( train_data ) // batch_size
from sparseml . pytorch . optim import ScheduledModifierManager
manager = ScheduledModifierManager . from_yaml ( PATH_TO_RECIPE )
optimizer = manager . modify ( model , optimizer , steps_per_epoch )
# typical PyTorch training loop, using your model/optimizer as usual
manager . finalize ( model )Trainer zu verwenden.Zusätzlich zur API auf Code-Ebene bietet Sparseml über die CLI-Schnittstelle vorgefertigte Trainingspipelines für gemeinsame NLP- und CV-Aufgaben. Die CLI ermöglicht es Ihnen, das Training mit verschiedenen Dienstprogrammen wie dem Lade- und Vorverarbeitungspflicht, dem Sparen von Checkpoint, der für Sie verwalteten Metrikberichterstattung und Protokollierung zu starten. Dies erleichtert es einfach, in gemeinsamen Trainingswege in Betrieb zu gehen.
Zum Beispiel können wir Folgendes verwenden, um einen yolov5 -spärlichen Übertragungslernen auf dem VOC -Datensatz zu starten (mit Sparsezoo -Stubs, um ein Sparse -Modell -Checkpoint und die Übertragung von Lernrezept) zu fällen):
sparseml.yolov5.train
--weights zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned75_quant-none ? recipe_type=transfer_learn
--recipe zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned75_quant-none ? recipe_type=transfer_learn
--data VOC.yaml
--hyp hyps/hyp.finetune.yaml --cfg yolov5s.yaml --patience 0Weitere Informationen zur Codebasis und den enthaltenen Prozessen finden Sie in den Sparseml -Dokumenten:
Offizielle Builds werden auf PYPI veranstaltet
Zusätzlich finden Sie weitere Informationen über Github -Releases.
Das Projekt ist unter der Apache -Lizenzversion 2.0 lizenziert.
Wir schätzen Beiträge zu Code, Beispielen, Integrationen und Dokumentation sowie Fehlerberichten und Feature -Anfragen! Erfahren Sie, wie hier.
Für Benutzer Hilfe oder Fragen zu Sparseml melden Sie sich an, oder melden Sie sich bei unserer neuronalen Magie -Community -Slack an. Wir wachsen das Community -Mitglied von Mitglied und freuen uns, Sie dort zu sehen. Fehler, Feature -Anfragen oder zusätzliche Fragen können auch in unserer GitHub -Ausgabewarteschlange veröffentlicht werden.
Sie können die neuesten Nachrichten, Webinar- und Event -Einladungen, Forschungsarbeiten und andere ML -Performance -Tidbits erhalten, indem Sie sich die neuronale Magie -Community abonnieren.
Allgemeinere Fragen zu neuronaler Magie füllen Sie dieses Formular aus.
Finden Sie dieses Projekt in Ihrer Forschung oder anderen Kommunikation nützlich? Bitte erwägen Sie: zitieren:
@InProceedings {
pmlr-v119-kurtz20a,
title = { Inducing and Exploiting Activation Sparsity for Fast Inference on Deep Neural Networks } ,
author = { Kurtz, Mark and Kopinsky, Justin and Gelashvili, Rati and Matveev, Alexander and Carr, John and Goin, Michael and Leiserson, William and Moore, Sage and Nell, Bill and Shavit, Nir and Alistarh, Dan } ,
booktitle = { Proceedings of the 37th International Conference on Machine Learning } ,
pages = { 5533--5543 } ,
year = { 2020 } ,
editor = { Hal Daumé III and Aarti Singh } ,
volume = { 119 } ,
series = { Proceedings of Machine Learning Research } ,
address = { Virtual } ,
month = { 13--18 Jul } ,
publisher = { PMLR } ,
pdf = { http://proceedings.mlr.press/v119/kurtz20a/kurtz20a.pdf } ,
url = { http://proceedings.mlr.press/v119/kurtz20a.html } ,
abstract = {Optimizing convolutional neural networks for fast inference has recently become an extremely active area of research. One of the go-to solutions in this context is weight pruning, which aims to reduce computational and memory footprint by removing large subsets of the connections in a neural network. Surprisingly, much less attention has been given to exploiting sparsity in the activation maps, which tend to be naturally sparse in many settings thanks to the structure of rectified linear (ReLU) activation functions. In this paper, we present an in-depth analysis of methods for maximizing the sparsity of the activations in a trained neural network, and show that, when coupled with an efficient sparse-input convolution algorithm, we can leverage this sparsity for significant performance gains. To induce highly sparse activation maps without accuracy loss, we introduce a new regularization technique, coupled with a new threshold-based sparsification method based on a parameterized activation function called Forced-Activation-Threshold Rectified Linear Unit (FATReLU). We examine the impact of our methods on popular image classification models, showing that most architectures can adapt to significantly sparser activation maps without any accuracy loss. Our second contribution is showing that these these compression gains can be translated into inference speedups: we provide a new algorithm to enable fast convolution operations over networks with sparse activations, and show that it can enable significant speedups for end-to-end inference on a range of popular models on the large-scale ImageNet image classification task on modern Intel CPUs, with little or no retraining cost.}
} @misc {
singh2020woodfisher,
title = { WoodFisher: Efficient Second-Order Approximation for Neural Network Compression } ,
author = { Sidak Pal Singh and Dan Alistarh } ,
year = { 2020 } ,
eprint = { 2004.14340 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
}

