sparseml
v1.8.0
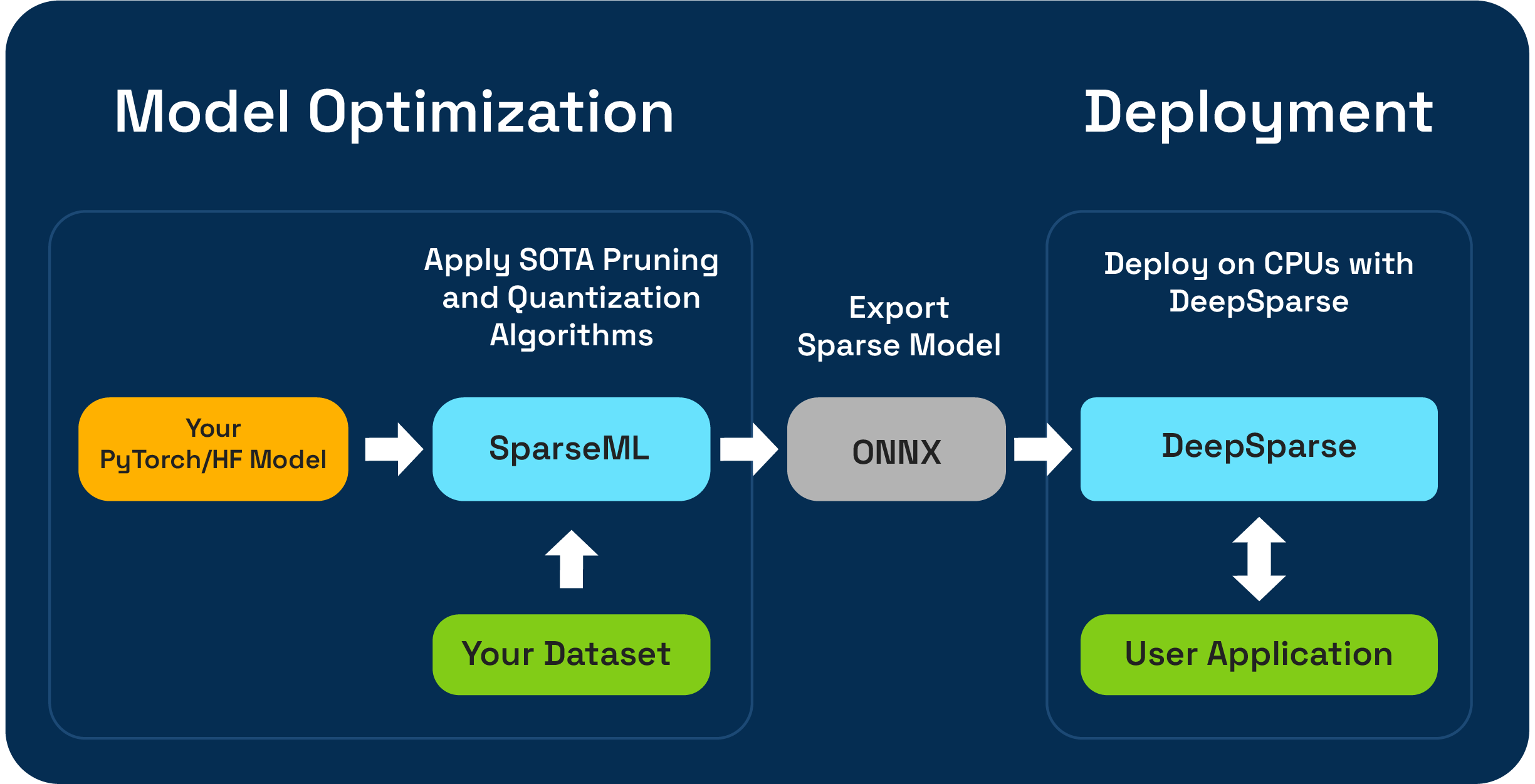
SPARSEML est une boîte à outils d'optimisation de modèle open source qui vous permet de créer des modèles clairsemés optimisés par l'inférence à l'aide d'algorithmes d'élagage, de quantification et de distillation. Les modèles optimisés avec SPARSEML peuvent ensuite être exportés vers l'ONNX et déployés avec DeepSparse pour les performances de classe GPU sur le matériel CPU.
Neural Magic est ravi de prévisualiser les workflows de compression LLM One-Shot en utilisant le nouveau SparseGPTModfier !
Pour tailler et quantifier un modèle de chat TinyLlama, ce ne sont que quelques étapes pour installer des dépendances, télécharger une recette et l'appliquer au modèle:
git clone https://github.com/neuralmagic/sparseml
pip install -e "sparseml[transformers]"
wget https://huggingface.co/neuralmagic/TinyLlama-1.1B-Chat-v0.4-pruned50-quant-ds/raw/main/recipe.yaml
sparseml.transformers.text_generation.oneshot --model_name TinyLlama/TinyLlama-1.1B-Chat-v1.0 --dataset_name open_platypus --recipe recipe.yaml --output_dir ./obcq_deployment --precision float16
Le Readme de src/sparseml/transformers/sparsification/obcq a une procédure détaillée.
SPARSEML vous permet de créer un modèle clairsemé formé sur votre ensemble de données de deux manières:
L'apprentissage par transfert clairsemé vous permet d'adapter un modèle pré-séparé de Sparseezoo (un référentiel open source de modèles clairsemés tels que Bert, Yolov5 et RESNET-50) sur votre ensemble de données, tout en maintenant la clairserie. Cette voie fonctionne comme un réglage fin typique auquel vous êtes habitué à former des modèles CV et NLP, et est fortement préféré si votre architecture de modèle est disponible en sterrsezoo.
La sparsification à partir de zéro vous permet d'appliquer l'élagage de pointe (comme l'élagage de magnitude progressive ou l'élagage obscur) et les algorithmes de quantification (comme la formation de connaissance de la quantification) aux modèles arbitraires de pytorche et d'étreindre les modèles de visage. Cette voie nécessite plus d'expérimentation, mais vous permet de créer une version clairsemée de n'importe quel modèle.

Ce référentiel est testé sur Python 3.8-3.11 et les systèmes Linux / Debian.
Il est recommandé d'installer dans un environnement virtuel pour maintenir votre système en ordre. Les cadres ML actuellement pris en charge sont les suivants: torch>=1.1.0,<=2.0 , tensorflow>=1.8.0,<2.0.0 , tensorflow.keras >= 2.2.0 .
Installer avec PIP en utilisant:
pip install sparsemlPlus d'informations sur l'installation telles que les dépendances et les exigences facultatives peuvent être trouvées ici.
Pour permettre la flexibilité, la facilité d'utilisation et la répétabilité, SPARSEML utilise une interface déclarative appelée recipes pour spécifier les algorithmes et les hyperparamètres liés à la rareté qui doivent être appliqués par SPARSEML.
Recipes sont des fichiers YAML formatés comme une liste de modifiers , qui encodent les instructions pour SPARSEML. modifiers d'exemples peuvent être quelque chose de la définition du taux d'apprentissage au codage des hyperparamètres de l'algorithme d'élagage progressif. Le système sparseml analyse les recipes dans un format natif pour chaque cadre et applique les modifications au modèle et au pipeline de formation.
En raison de l'approche déclarative basée sur les recettes, vous pouvez ajouter SPARSEML à vos pipelines de formation Pytorch existants. La classe ScheduleModifierManager est responsable de l'analyse des recipes YAML et du modèle Pytorch standard et des objets Optimizer standard, codant pour la logique des algorithmes de rareté de la recette. Une fois que vous appelez manager.modify , vous pouvez ensuite utiliser le modèle et l'optimiseur comme d'habitude, car SPARSEML résume la complexité des algorithmes de sparsification.
Le workflow ressemble à ceci:
model = Model () # model definition
optimizer = Optimizer () # optimizer definition
train_data = TrainData () # train data definition
batch_size = BATCH_SIZE # training batch size
steps_per_epoch = len ( train_data ) // batch_size
from sparseml . pytorch . optim import ScheduledModifierManager
manager = ScheduledModifierManager . from_yaml ( PATH_TO_RECIPE )
optimizer = manager . modify ( model , optimizer , steps_per_epoch )
# typical PyTorch training loop, using your model/optimizer as usual
manager . finalize ( model )Trainer de face étreint.En plus de l'API au niveau du code, SPARSEML propose des pipelines d'entraînement préfabriqués pour les tâches NLP et CV communes via l'interface CLI. La CLI vous permet de lancer des courses d'entraînement avec divers services publics comme le chargement de données et le prétraitement, l'enregistrement des points de contrôle, les rapports métriques et la journalisation gérés pour vous. Cela facilite la mise en service dans les voies d'entraînement communes.
Par exemple, nous pouvons utiliser ce qui suit pour lancer un apprentissage par transfert clairsemé Yolov5 sur l'ensemble de données VOC (en utilisant des talons sparsezoo pour réduire un point de contrôle de modèle clairsemé et une recette d'apprentissage de transfert):
sparseml.yolov5.train
--weights zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned75_quant-none ? recipe_type=transfer_learn
--recipe zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned75_quant-none ? recipe_type=transfer_learn
--data VOC.yaml
--hyp hyps/hyp.finetune.yaml --cfg yolov5s.yaml --patience 0Plus d'informations sur la base de code et les processus contenus peuvent être trouvés dans les documents SPARSEML:
Les constructions officielles sont hébergées sur PYPI
De plus, plus d'informations peuvent être trouvées via les versions GitHub.
Le projet est sous licence en vertu de la version 2.0 de la licence Apache.
Nous apprécions les contributions au code, aux exemples, aux intégrations et à la documentation ainsi qu'aux rapports de bogues et aux demandes de fonctionnalités! Apprenez comment ici.
Pour l'aide des utilisateurs ou des questions sur SPARSEML, inscrivez-vous ou connectez-vous à notre Slack de la communauté magique neurale . Nous cultivons le membre de la communauté par membre et heureux de vous y voir. Les bogues, les demandes de fonctionnalités ou les questions supplémentaires peuvent également être publiés dans notre file d'attente GitHub.
Vous pouvez obtenir les dernières nouvelles, webinaires et invitations d'événements, articles de recherche et autres friandises de performance ML en abonnement à la communauté magique neuronale.
Pour des questions plus générales sur la magie neurale, veuillez remplir ce formulaire.
Vous trouverez ce projet utile dans votre recherche ou d'autres communications? Veuillez envisager de citer:
@InProceedings {
pmlr-v119-kurtz20a,
title = { Inducing and Exploiting Activation Sparsity for Fast Inference on Deep Neural Networks } ,
author = { Kurtz, Mark and Kopinsky, Justin and Gelashvili, Rati and Matveev, Alexander and Carr, John and Goin, Michael and Leiserson, William and Moore, Sage and Nell, Bill and Shavit, Nir and Alistarh, Dan } ,
booktitle = { Proceedings of the 37th International Conference on Machine Learning } ,
pages = { 5533--5543 } ,
year = { 2020 } ,
editor = { Hal Daumé III and Aarti Singh } ,
volume = { 119 } ,
series = { Proceedings of Machine Learning Research } ,
address = { Virtual } ,
month = { 13--18 Jul } ,
publisher = { PMLR } ,
pdf = { http://proceedings.mlr.press/v119/kurtz20a/kurtz20a.pdf } ,
url = { http://proceedings.mlr.press/v119/kurtz20a.html } ,
abstract = {Optimizing convolutional neural networks for fast inference has recently become an extremely active area of research. One of the go-to solutions in this context is weight pruning, which aims to reduce computational and memory footprint by removing large subsets of the connections in a neural network. Surprisingly, much less attention has been given to exploiting sparsity in the activation maps, which tend to be naturally sparse in many settings thanks to the structure of rectified linear (ReLU) activation functions. In this paper, we present an in-depth analysis of methods for maximizing the sparsity of the activations in a trained neural network, and show that, when coupled with an efficient sparse-input convolution algorithm, we can leverage this sparsity for significant performance gains. To induce highly sparse activation maps without accuracy loss, we introduce a new regularization technique, coupled with a new threshold-based sparsification method based on a parameterized activation function called Forced-Activation-Threshold Rectified Linear Unit (FATReLU). We examine the impact of our methods on popular image classification models, showing that most architectures can adapt to significantly sparser activation maps without any accuracy loss. Our second contribution is showing that these these compression gains can be translated into inference speedups: we provide a new algorithm to enable fast convolution operations over networks with sparse activations, and show that it can enable significant speedups for end-to-end inference on a range of popular models on the large-scale ImageNet image classification task on modern Intel CPUs, with little or no retraining cost.}
} @misc {
singh2020woodfisher,
title = { WoodFisher: Efficient Second-Order Approximation for Neural Network Compression } ,
author = { Sidak Pal Singh and Dan Alistarh } ,
year = { 2020 } ,
eprint = { 2004.14340 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
}

