sparseml
v1.8.0
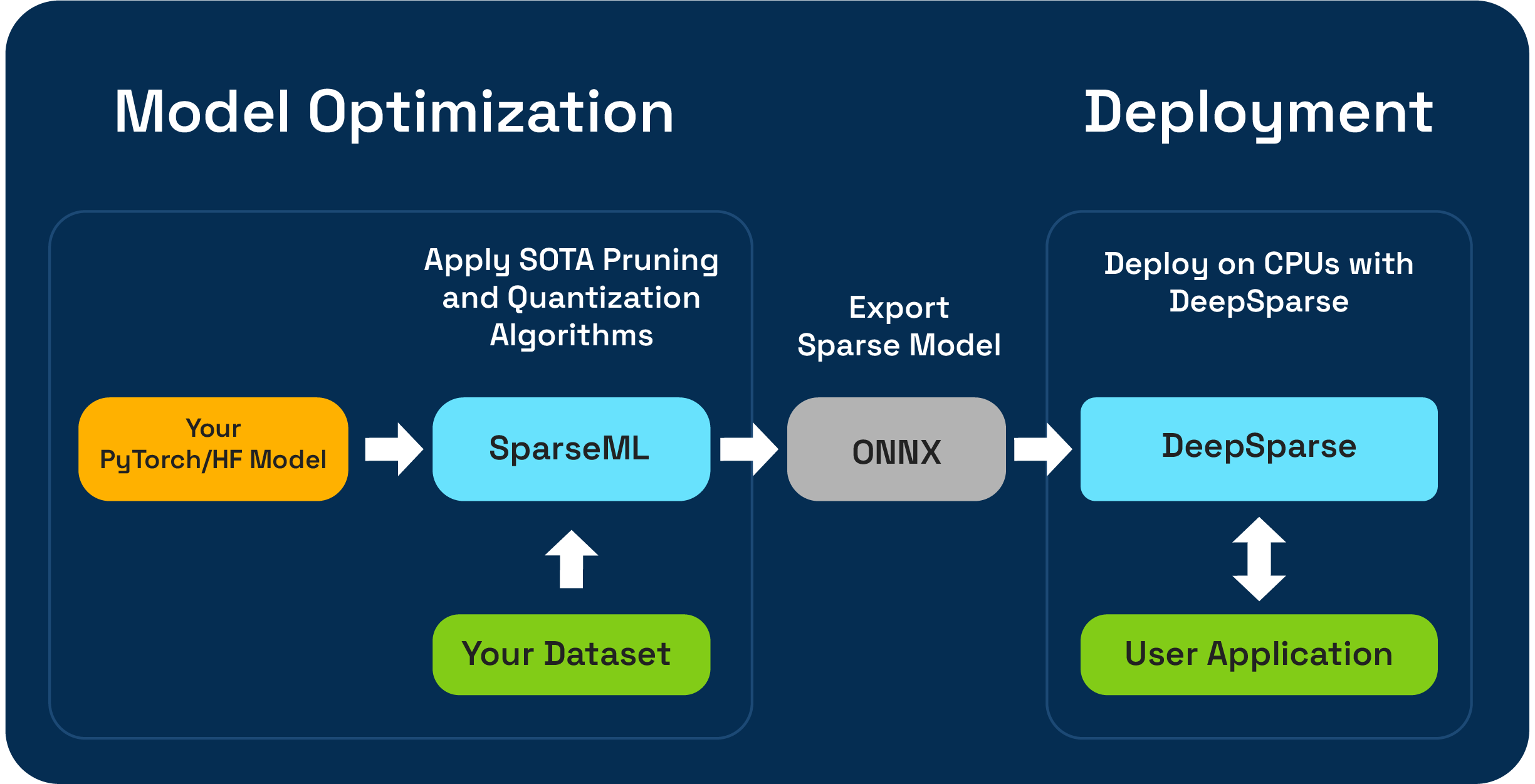
SPARSEML adalah alat optimasi model open-source yang memungkinkan Anda membuat model jarang yang dioptimalkan inferensi menggunakan algoritma pemangkasan, kuantisasi, dan distilasi. Model yang dioptimalkan dengan sparseml kemudian dapat diekspor ke ONNX dan digunakan dengan DeepSparse untuk kinerja kelas GPU pada perangkat keras CPU.
Neural Magic sangat bersemangat untuk mempratinjau alur kerja kompresi satu-shot llm menggunakan SparseGPTModfier baru!
Untuk memangkas dan mengukur model obrolan Tinyllama, hanya beberapa langkah untuk menginstal dependensi, mengunduh resep, dan menerapkannya pada model:
git clone https://github.com/neuralmagic/sparseml
pip install -e "sparseml[transformers]"
wget https://huggingface.co/neuralmagic/TinyLlama-1.1B-Chat-v0.4-pruned50-quant-ds/raw/main/recipe.yaml
sparseml.transformers.text_generation.oneshot --model_name TinyLlama/TinyLlama-1.1B-Chat-v1.0 --dataset_name open_platypus --recipe recipe.yaml --output_dir ./obcq_deployment --precision float16
Readme di src/sparseml/transformers/sparsification/obcq memiliki panduan terperinci.
Sparseml memungkinkan Anda untuk membuat model jarang yang dilatih pada dataset Anda dengan dua cara:
Pembelajaran transfer yang jarang memungkinkan Anda untuk menyempurnakan model yang telah dipilih sebelumnya dari Sparsezoo (repositori open-source dari model jarang seperti Bert, Yolov5, dan ResNet-50) ke dalam dataset Anda, sambil mempertahankan sparsity. Jalur ini berfungsi seperti penyempurnaan khas yang biasa Anda lakukan dalam pelatihan model CV dan NLP, dan sangat disukai karena jika arsitektur model Anda tersedia di Sparsezoo.
Sparsifikasi dari awal memungkinkan Anda untuk menerapkan pemangkasan canggih (seperti pemangkasan besar atau pemangkasan obs) dan kuantisasi (seperti pelatihan kuantisasi sadar) algoritma untuk pytorch sewenang-wenang dan memeluk model wajah. Jalur ini membutuhkan lebih banyak eksperimen, tetapi memungkinkan Anda untuk membuat versi yang jarang dari model apa pun.

Repositori ini diuji pada sistem Python 3.8-3.11, dan Linux/Debian.
Disarankan untuk menginstal di lingkungan virtual untuk menjaga sistem Anda tetap teratur. Kerangka kerja ML yang didukung saat ini adalah sebagai berikut: torch>=1.1.0,<=2.0 , tensorflow>=1.8.0,<2.0.0 , tensorflow.keras >= 2.2.0 .
Instal dengan PIP menggunakan:
pip install sparsemlInformasi lebih lanjut tentang instalasi seperti dependensi opsional dan persyaratan dapat ditemukan di sini.
Untuk memungkinkan fleksibilitas, kemudahan penggunaan, dan pengulangan, sparseml menggunakan antarmuka deklaratif yang disebut recipes untuk menentukan algoritma dan hiperparameter terkait sparsity yang harus diterapkan oleh sparseml.
Recipes adalah YAML-Files diformat sebagai daftar modifiers , yang menyandikan instruksi untuk sparseml. Contoh modifiers dapat berupa apa saja, mulai dari menetapkan tingkat pembelajaran hingga mengkode hiperparameter dari algoritma pemangkasan besarnya. Sistem SPARSEML mem -parsing recipes ke dalam format asli untuk setiap kerangka kerja dan menerapkan modifikasi pada model dan pipa pelatihan.
Karena pendekatan deklaratif berbasis resep, Anda dapat menambahkan sparseml ke pipa pelatihan Pytorch Anda yang ada. Kelas ScheduleModifierManager bertanggung jawab untuk mem -parsing recipes YAML dan menimpa model Pytorch standar dan objek pengoptimal, mengkode logika algoritma sparsity dari resep. Setelah Anda menelepon manager.modify .
Alur kerja terlihat seperti ini:
model = Model () # model definition
optimizer = Optimizer () # optimizer definition
train_data = TrainData () # train data definition
batch_size = BATCH_SIZE # training batch size
steps_per_epoch = len ( train_data ) // batch_size
from sparseml . pytorch . optim import ScheduledModifierManager
manager = ScheduledModifierManager . from_yaml ( PATH_TO_RECIPE )
optimizer = manager . modify ( model , optimizer , steps_per_epoch )
# typical PyTorch training loop, using your model/optimizer as usual
manager . finalize ( model )Trainer wajah pemeluk.Selain API tingkat kode, SPARSEML menawarkan pipa pelatihan yang sudah dibuat sebelumnya untuk tugas NLP dan CV umum melalui antarmuka CLI. CLI memungkinkan Anda untuk memulai pelatihan dengan berbagai utilitas seperti pemuatan dataset dan pra-pemrosesan, penghematan pos pemeriksaan, pelaporan metrik, dan penebangan yang ditangani untuk Anda. Ini membuatnya mudah untuk bangun dan berjalan di jalur pelatihan umum.
Misalnya, kita dapat menggunakan yang berikut ini untuk memulai pembelajaran transfer YOLOV5 yang jarang berjalan ke dataset VOC (menggunakan stubs SPARSEZOO untuk menarik pos pemeriksaan model yang jarang dan mentransfer resep pembelajaran):
sparseml.yolov5.train
--weights zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned75_quant-none ? recipe_type=transfer_learn
--recipe zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned75_quant-none ? recipe_type=transfer_learn
--data VOC.yaml
--hyp hyps/hyp.finetune.yaml --cfg yolov5s.yaml --patience 0Informasi lebih lanjut tentang basis kode dan proses yang terkandung dapat ditemukan di dokumen SPARSEML:
Bangunan resmi di -host di PYPI
Selain itu, informasi lebih lanjut dapat ditemukan melalui rilis GitHub.
Proyek ini dilisensikan di bawah Lisensi Apache versi 2.0.
Kami menghargai kontribusi pada kode, contoh, integrasi, dan dokumentasi serta laporan bug dan permintaan fitur! Pelajari bagaimana di sini.
Untuk bantuan pengguna atau pertanyaan tentang SPARSEML, daftar atau masuk ke Slack komunitas sulap saraf kami. Kami menumbuhkan anggota komunitas oleh anggota dan senang melihat Anda di sana. Bug, permintaan fitur, atau pertanyaan tambahan juga dapat diposting ke antrian masalah GitHub kami.
Anda bisa mendapatkan berita terbaru, webinar dan undangan acara, makalah penelitian, dan informasi ML lainnya dengan berlangganan komunitas sihir saraf.
Untuk pertanyaan yang lebih umum tentang sihir saraf, silakan isi formulir ini.
Temukan proyek ini berguna dalam penelitian Anda atau komunikasi lain? Harap pertimbangkan mengutip:
@InProceedings {
pmlr-v119-kurtz20a,
title = { Inducing and Exploiting Activation Sparsity for Fast Inference on Deep Neural Networks } ,
author = { Kurtz, Mark and Kopinsky, Justin and Gelashvili, Rati and Matveev, Alexander and Carr, John and Goin, Michael and Leiserson, William and Moore, Sage and Nell, Bill and Shavit, Nir and Alistarh, Dan } ,
booktitle = { Proceedings of the 37th International Conference on Machine Learning } ,
pages = { 5533--5543 } ,
year = { 2020 } ,
editor = { Hal Daumé III and Aarti Singh } ,
volume = { 119 } ,
series = { Proceedings of Machine Learning Research } ,
address = { Virtual } ,
month = { 13--18 Jul } ,
publisher = { PMLR } ,
pdf = { http://proceedings.mlr.press/v119/kurtz20a/kurtz20a.pdf } ,
url = { http://proceedings.mlr.press/v119/kurtz20a.html } ,
abstract = {Optimizing convolutional neural networks for fast inference has recently become an extremely active area of research. One of the go-to solutions in this context is weight pruning, which aims to reduce computational and memory footprint by removing large subsets of the connections in a neural network. Surprisingly, much less attention has been given to exploiting sparsity in the activation maps, which tend to be naturally sparse in many settings thanks to the structure of rectified linear (ReLU) activation functions. In this paper, we present an in-depth analysis of methods for maximizing the sparsity of the activations in a trained neural network, and show that, when coupled with an efficient sparse-input convolution algorithm, we can leverage this sparsity for significant performance gains. To induce highly sparse activation maps without accuracy loss, we introduce a new regularization technique, coupled with a new threshold-based sparsification method based on a parameterized activation function called Forced-Activation-Threshold Rectified Linear Unit (FATReLU). We examine the impact of our methods on popular image classification models, showing that most architectures can adapt to significantly sparser activation maps without any accuracy loss. Our second contribution is showing that these these compression gains can be translated into inference speedups: we provide a new algorithm to enable fast convolution operations over networks with sparse activations, and show that it can enable significant speedups for end-to-end inference on a range of popular models on the large-scale ImageNet image classification task on modern Intel CPUs, with little or no retraining cost.}
} @misc {
singh2020woodfisher,
title = { WoodFisher: Efficient Second-Order Approximation for Neural Network Compression } ,
author = { Sidak Pal Singh and Dan Alistarh } ,
year = { 2020 } ,
eprint = { 2004.14340 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
}

