sparseml
v1.8.0
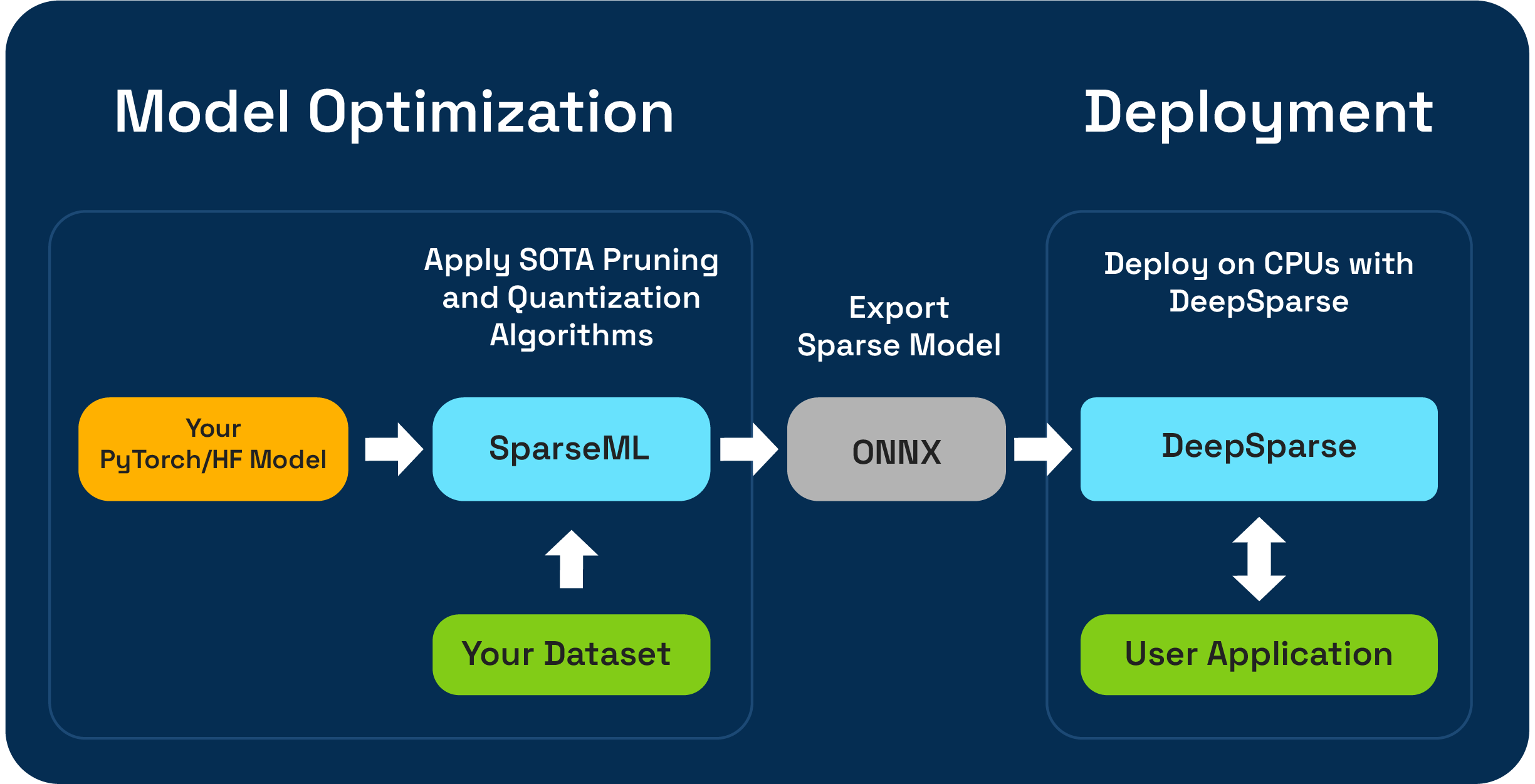
O Sparseml é um kit de ferramentas de otimização de modelo de código aberto que permite criar modelos esparsos otimizados para inferência usando algoritmos de poda, quantização e destilação. Modelos otimizados com Sparseml podem ser exportados para o ONNX e implantados com DeepSparse para desempenho da classe GPU no hardware da CPU.
A Magia Neural está animada para visualizar os fluxos de trabalho de compressão One-Shot LLM usando o novo SparseGPTModfier !
Para podar e quantizar um modelo de bate -papo de Tinyllama, são apenas algumas etapas para instalar dependências, baixar uma receita e aplicá -la ao modelo:
git clone https://github.com/neuralmagic/sparseml
pip install -e "sparseml[transformers]"
wget https://huggingface.co/neuralmagic/TinyLlama-1.1B-Chat-v0.4-pruned50-quant-ds/raw/main/recipe.yaml
sparseml.transformers.text_generation.oneshot --model_name TinyLlama/TinyLlama-1.1B-Chat-v1.0 --dataset_name open_platypus --recipe recipe.yaml --output_dir ./obcq_deployment --precision float16
O ReadMe no src/sparseml/transformers/sparsification/obcq possui um passo a passo detalhado.
O Sparseml permite criar um modelo esparso treinado no seu conjunto de dados de duas maneiras:
O aprendizado de transferência esparsa permite ajustar um modelo pré-comparado da Sparsezoo (um repositório de código aberto de modelos escassos como Bert, Yolov5 e Resnet-50) no seu conjunto de dados, mantendo a escarridade. Esse caminho funciona como o ajuste fino típico que você está acostumado no treinamento de modelos CV e PNL e é fortemente preferido se a sua arquitetura de modelo estiver disponível no Sparsezoo.
A escarificação do Scratch permite aplicar a poda de ponta (como a poda de magnitude ou a poda de magnitude gradual) e a quantização (como o treinamento com consciência de quantização) algoritmos para arbitrários de pytorch e abraçar modelos de rosto. Esse caminho requer mais experimentação, mas permite criar uma versão escassa de qualquer modelo.

Este repositório é testado nos sistemas Python 3.8-3.11 e Linux/Debian.
Recomenda -se instalar em um ambiente virtual para manter seu sistema em ordem. Atualmente, as estruturas ML suportadas são as seguintes: torch>=1.1.0,<=2.0 , tensorflow>=1.8.0,<2.0.0 , tensorflow.keras >= 2.2.0 .
Instale com PIP usando:
pip install sparsemlMais informações sobre instalação, como dependências e requisitos opcionais, podem ser encontrados aqui.
Para permitir flexibilidade, facilidade de uso e repetibilidade, o SparseML usa uma interface declarativa chamada recipes para especificar os algoritmos e hiperparâmetros relacionados à esparsidade que devem ser aplicados por SparseML.
Recipes são formatadas como uma lista de modifiers , que codificam as instruções para o Sparseml. modifiers de exemplo podem ser qualquer coisa desde definir a taxa de aprendizado até a codificação dos hiperparâmetros do algoritmo de poda de magnitude gradual. O sistema SPARSEML analisa as recipes em um formato nativo para cada estrutura e aplica as modificações no modelo e no pipeline de treinamento.
Devido à abordagem declarativa e baseada em receitas, você pode adicionar sparseml aos seus pipelines de treinamento de Pytorch existentes. A classe ScheduleModifierManager é responsável por analisar as recipes da YAML e o modelo de Pytorch padrão e os objetos de otimizador padrão, codificando a lógica dos algoritmos de esparsidade da receita. Depois de ligar para manager.modify , você pode usar o modelo e o otimizador como de costume, pois o Sparseml abstrairá a complexidade dos algoritmos de escarsificação.
O fluxo de trabalho se parece com o seguinte:
model = Model () # model definition
optimizer = Optimizer () # optimizer definition
train_data = TrainData () # train data definition
batch_size = BATCH_SIZE # training batch size
steps_per_epoch = len ( train_data ) // batch_size
from sparseml . pytorch . optim import ScheduledModifierManager
manager = ScheduledModifierManager . from_yaml ( PATH_TO_RECIPE )
optimizer = manager . modify ( model , optimizer , steps_per_epoch )
# typical PyTorch training loop, using your model/optimizer as usual
manager . finalize ( model )Trainer .Além da API em nível de código, o Sparseml oferece pipelines de treinamento pré-fabricados para tarefas comuns de NLP e CV via interface da CLI. A CLI permite que você inicie as execuções de treinamento com vários utilitários, como carregamento de dados e pré-processamento, economia de ponto de verificação, relatórios métricos e registro de registro para você. Isso facilita a corrida e a corrida em caminhos de treinamento comuns.
Por exemplo, podemos usar o seguinte para iniciar um aprendizado de transferência esparsa do Yolov5 no conjunto de dados VOC (usando stubs Sparsezoo para puxar um ponto de verificação de modelo esparso e transferir receita de aprendizado):
sparseml.yolov5.train
--weights zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned75_quant-none ? recipe_type=transfer_learn
--recipe zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned75_quant-none ? recipe_type=transfer_learn
--data VOC.yaml
--hyp hyps/hyp.finetune.yaml --cfg yolov5s.yaml --patience 0Mais informações sobre a base de código e processos contidos podem ser encontrados nos documentos Sparseml:
Construções oficiais estão hospedadas no Pypi
Além disso, mais informações podem ser encontradas através de lançamentos do GitHub.
O projeto está licenciado no Apache License versão 2.0.
Agradecemos contribuições para o código, exemplos, integrações e documentação, bem como relatórios de bugs e solicitações de recursos! Saiba como aqui.
Para obter ajuda ou perguntas sobre o Sparseml, inscreva -se ou faça login em nossa folga da comunidade mágica neural . Estamos cultivando o membro da comunidade por membro e felizes em vê -lo lá. Bugs, solicitações de recursos ou perguntas adicionais também podem ser publicadas em nossa fila de problemas do GitHub.
Você pode receber as últimas notícias, webinar e convites de eventos, trabalhos de pesquisa e outros boatos de desempenho de ML, assinando a comunidade mágica neural.
Para perguntas mais gerais sobre magia neural, preencha este formulário.
Encontre este projeto útil em sua pesquisa ou outras comunicações? Por favor, considere citar:
@InProceedings {
pmlr-v119-kurtz20a,
title = { Inducing and Exploiting Activation Sparsity for Fast Inference on Deep Neural Networks } ,
author = { Kurtz, Mark and Kopinsky, Justin and Gelashvili, Rati and Matveev, Alexander and Carr, John and Goin, Michael and Leiserson, William and Moore, Sage and Nell, Bill and Shavit, Nir and Alistarh, Dan } ,
booktitle = { Proceedings of the 37th International Conference on Machine Learning } ,
pages = { 5533--5543 } ,
year = { 2020 } ,
editor = { Hal Daumé III and Aarti Singh } ,
volume = { 119 } ,
series = { Proceedings of Machine Learning Research } ,
address = { Virtual } ,
month = { 13--18 Jul } ,
publisher = { PMLR } ,
pdf = { http://proceedings.mlr.press/v119/kurtz20a/kurtz20a.pdf } ,
url = { http://proceedings.mlr.press/v119/kurtz20a.html } ,
abstract = {Optimizing convolutional neural networks for fast inference has recently become an extremely active area of research. One of the go-to solutions in this context is weight pruning, which aims to reduce computational and memory footprint by removing large subsets of the connections in a neural network. Surprisingly, much less attention has been given to exploiting sparsity in the activation maps, which tend to be naturally sparse in many settings thanks to the structure of rectified linear (ReLU) activation functions. In this paper, we present an in-depth analysis of methods for maximizing the sparsity of the activations in a trained neural network, and show that, when coupled with an efficient sparse-input convolution algorithm, we can leverage this sparsity for significant performance gains. To induce highly sparse activation maps without accuracy loss, we introduce a new regularization technique, coupled with a new threshold-based sparsification method based on a parameterized activation function called Forced-Activation-Threshold Rectified Linear Unit (FATReLU). We examine the impact of our methods on popular image classification models, showing that most architectures can adapt to significantly sparser activation maps without any accuracy loss. Our second contribution is showing that these these compression gains can be translated into inference speedups: we provide a new algorithm to enable fast convolution operations over networks with sparse activations, and show that it can enable significant speedups for end-to-end inference on a range of popular models on the large-scale ImageNet image classification task on modern Intel CPUs, with little or no retraining cost.}
} @misc {
singh2020woodfisher,
title = { WoodFisher: Efficient Second-Order Approximation for Neural Network Compression } ,
author = { Sidak Pal Singh and Dan Alistarh } ,
year = { 2020 } ,
eprint = { 2004.14340 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
}

