sparseml
v1.8.0
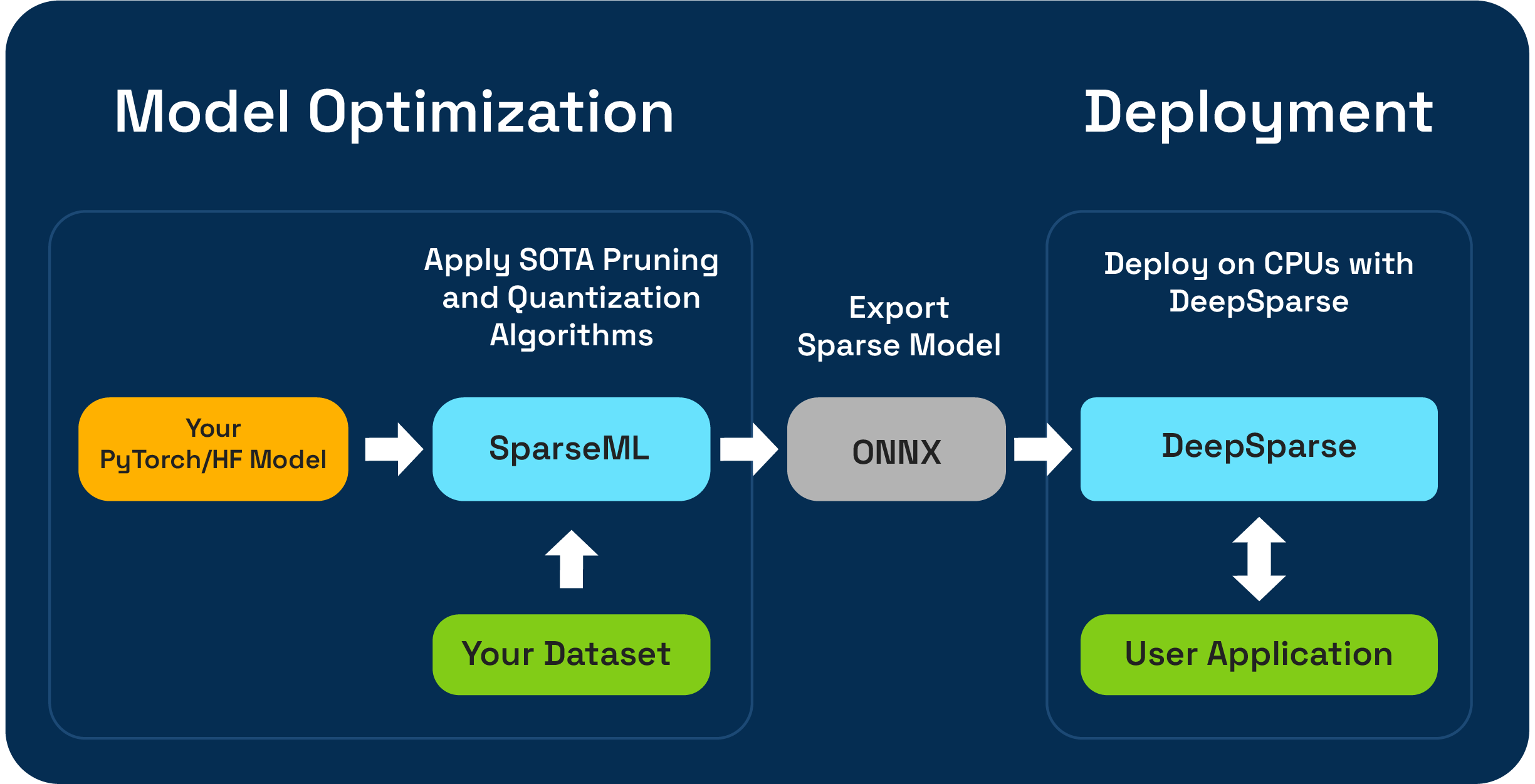
SparsEml هي مجموعة أدوات تحسين نموذج مفتوحة المصدر تمكنك من إنشاء نماذج متناثرة محسّنة للاستدلال باستخدام خوارزميات التقليم والتكميلية والتقطير. يمكن بعد ذلك تصدير النماذج المحسّنة باستخدام sparseml إلى ONNX ونشرها مع DeepSparse لأداء من فئة GPU على أجهزة وحدة المعالجة المركزية.
السحر العصبي متحمس لمعاينة سير عمل ضغط LLM واحد باستخدام SparseGPTModfier الجديد!
لتوخّم نموذج دردشة Tinyllama وتكميته ، فإنه مجرد خطوات قليلة لتثبيت التبعيات وتنزيل وصفة وتطبيقها على النموذج:
git clone https://github.com/neuralmagic/sparseml
pip install -e "sparseml[transformers]"
wget https://huggingface.co/neuralmagic/TinyLlama-1.1B-Chat-v0.4-pruned50-quant-ds/raw/main/recipe.yaml
sparseml.transformers.text_generation.oneshot --model_name TinyLlama/TinyLlama-1.1B-Chat-v1.0 --dataset_name open_platypus --recipe recipe.yaml --output_dir ./obcq_deployment --precision float16
README في src/sparseml/transformers/sparsification/obcq لديه تجول مفصل.
يمكّنك Sparseml من إنشاء نموذج متناثر مدرب على مجموعة البيانات بطريقتين:
يمكّنك تعلم النقل المتفوق من ضبط نموذج مسبقًا مسبقًا من sparsezoo (مستودع مفتوح المصدر من النماذج المتفرقة مثل Bert و Yolov5 و Resnet-50) على مجموعة البيانات الخاصة بك ، مع الحفاظ على التباين. يعمل هذا المسار تمامًا مثل التثبيت النموذجي الذي تستخدمه في تدريب نماذج السيرة الذاتية و NLP ، ويفضل بشدة إذا كانت بنية النموذج الخاصة بك متوفرة في sparsezoo.
يمكّنك التباين من نقطة الصفر من تطبيق أحدث التقليم (مثل التقليم التدريجي أو التقليم أو OBS) والتكميلية (مثل التدريب الكمي) على نماذج الوجه التعسفي والوجه التعسفي. يتطلب هذا المسار المزيد من التجارب ، ولكنه يسمح لك بإنشاء نسخة متناثرة من أي نموذج.

يتم اختبار هذا المستودع على Python 3.8-3.11 ، وأنظمة Linux/Debian.
يوصى بالتثبيت في بيئة افتراضية للحفاظ على نظامك بالترتيب. أطر ML المدعومة حاليًا هي ما يلي: torch>=1.1.0,<=2.0 ، tensorflow>=1.8.0,<2.0.0 ، tensorflow.keras >= 2.2.0 .
تثبيت مع PIP باستخدام:
pip install sparsemlيمكن العثور على مزيد من المعلومات حول التثبيت مثل التبعيات والمتطلبات الاختيارية هنا.
لتمكين المرونة ، وسهولة الاستخدام ، والتكرار ، يستخدم Sparseml واجهة تعريفية تسمى recipes لتحديد الخوارزميات المرتبطة بالتفاؤل ومقاطعات فرطمية يجب تطبيقها بواسطة sparseml.
Recipes عبارة عن ملفات yaml منسقة كقائمة من modifiers ، والتي تشفر إرشادات sparseml. يمكن أن تكون modifiers على سبيل المثال أي شيء من تحديد معدل التعلم إلى ترميز المقاييس المفرطة في خوارزمية تقليم الحجم التدريجي. يقوم نظام sparseml بتخفيض recipes في تنسيق أصلي لكل إطار ويطبق التعديلات على طراز أنابيب النموذج والدراب.
نظرًا للنهج التصريحي القائم على الوصفة ، يمكنك إضافة Sparseml إلى خطوط أنابيب تدريب Pytorch الحالية. فئة ScheduleModifierManager هي المسؤولة عن تحليل recipes YAML والتجاوز نموذج Pytorch القياسي وكائنات المُحسّنة ، مما يشفر منطق خوارزميات sparsity من الوصفة. بمجرد الاتصال بـ manager.modify ، يمكنك بعد ذلك استخدام النموذج والمحسّن كالمعتاد ، حيث يقوم Sparseml بإخفاء تعقيد خوارزميات Sparsification.
يبدو سير العمل هكذا:
model = Model () # model definition
optimizer = Optimizer () # optimizer definition
train_data = TrainData () # train data definition
batch_size = BATCH_SIZE # training batch size
steps_per_epoch = len ( train_data ) // batch_size
from sparseml . pytorch . optim import ScheduledModifierManager
manager = ScheduledModifierManager . from_yaml ( PATH_TO_RECIPE )
optimizer = manager . modify ( model , optimizer , steps_per_epoch )
# typical PyTorch training loop, using your model/optimizer as usual
manager . finalize ( model )Trainer الوجه المعانقة.بالإضافة إلى واجهة برمجة التطبيقات على مستوى الكود ، يوفر Sparseml خطوط أنابيب تدريب مسبقة الصنع لمهام NLP و CV الشائعة عبر واجهة CLI. يمكّنك CLI من تشغيل التدريب مع مختلف المرافق مثل تحميل مجموعات البيانات والمعالجة المسبقة ، وحفظ نقاط التفتيش ، وتقارير قياس ، وتسجيلها معالجة لك. هذا يجعل من السهل النهوض والتشغيل في مسارات التدريب الشائعة.
على سبيل المثال ، يمكننا استخدام ما يلي لبدء تشغيل التعلم النقل المتفرق على YOLOV5 على مجموعة بيانات VOC (باستخدام Stubs subso to sparsezoo لسحب نقطة تفتيش طراز متناثرة ونقل وصفة التعلم):
sparseml.yolov5.train
--weights zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned75_quant-none ? recipe_type=transfer_learn
--recipe zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned75_quant-none ? recipe_type=transfer_learn
--data VOC.yaml
--hyp hyps/hyp.finetune.yaml --cfg yolov5s.yaml --patience 0يمكن العثور على مزيد من المعلومات حول قاعدة كود وعمليات محتوية في مستندات Sparseml:
يتم استضافة التصميمات الرسمية على PYPI
بالإضافة إلى ذلك ، يمكن العثور على مزيد من المعلومات عبر إصدارات GitHub.
تم ترخيص المشروع بموجب إصدار ترخيص Apache 2.0.
نحن نقدر المساهمات في الكود والأمثلة والتكامل والوثائق وكذلك تقارير الأخطاء وطلبات الميزات! تعلم كيف هنا.
للحصول على مساعدة المستخدم أو أسئلة حول SparsEml ، قم بالتسجيل أو تسجيل الدخول إلى Slack Magic Community Slack . نحن ننمو عضو المجتمع من قبل عضو وسعيد رؤيتك هناك. يمكن أيضًا نشر الأخطاء أو طلبات الميزات أو الأسئلة الإضافية في قائمة انتظار قضية GitHub.
يمكنك الحصول على أحدث الأخبار ، ودعوات الحدث والمناسبات ، والأوراق البحثية ، وغيرها من الحكايات أداء ML من خلال الاشتراك في مجتمع السحر العصبي.
لمزيد من الأسئلة العامة حول السحر العصبي ، يرجى ملء هذا النموذج.
هل تجد هذا المشروع مفيدًا في بحثك أو اتصالات أخرى؟ يرجى النظر في الإشارة:
@InProceedings {
pmlr-v119-kurtz20a,
title = { Inducing and Exploiting Activation Sparsity for Fast Inference on Deep Neural Networks } ,
author = { Kurtz, Mark and Kopinsky, Justin and Gelashvili, Rati and Matveev, Alexander and Carr, John and Goin, Michael and Leiserson, William and Moore, Sage and Nell, Bill and Shavit, Nir and Alistarh, Dan } ,
booktitle = { Proceedings of the 37th International Conference on Machine Learning } ,
pages = { 5533--5543 } ,
year = { 2020 } ,
editor = { Hal Daumé III and Aarti Singh } ,
volume = { 119 } ,
series = { Proceedings of Machine Learning Research } ,
address = { Virtual } ,
month = { 13--18 Jul } ,
publisher = { PMLR } ,
pdf = { http://proceedings.mlr.press/v119/kurtz20a/kurtz20a.pdf } ,
url = { http://proceedings.mlr.press/v119/kurtz20a.html } ,
abstract = {Optimizing convolutional neural networks for fast inference has recently become an extremely active area of research. One of the go-to solutions in this context is weight pruning, which aims to reduce computational and memory footprint by removing large subsets of the connections in a neural network. Surprisingly, much less attention has been given to exploiting sparsity in the activation maps, which tend to be naturally sparse in many settings thanks to the structure of rectified linear (ReLU) activation functions. In this paper, we present an in-depth analysis of methods for maximizing the sparsity of the activations in a trained neural network, and show that, when coupled with an efficient sparse-input convolution algorithm, we can leverage this sparsity for significant performance gains. To induce highly sparse activation maps without accuracy loss, we introduce a new regularization technique, coupled with a new threshold-based sparsification method based on a parameterized activation function called Forced-Activation-Threshold Rectified Linear Unit (FATReLU). We examine the impact of our methods on popular image classification models, showing that most architectures can adapt to significantly sparser activation maps without any accuracy loss. Our second contribution is showing that these these compression gains can be translated into inference speedups: we provide a new algorithm to enable fast convolution operations over networks with sparse activations, and show that it can enable significant speedups for end-to-end inference on a range of popular models on the large-scale ImageNet image classification task on modern Intel CPUs, with little or no retraining cost.}
} @misc {
singh2020woodfisher,
title = { WoodFisher: Efficient Second-Order Approximation for Neural Network Compression } ,
author = { Sidak Pal Singh and Dan Alistarh } ,
year = { 2020 } ,
eprint = { 2004.14340 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
}

