sparseml
v1.8.0
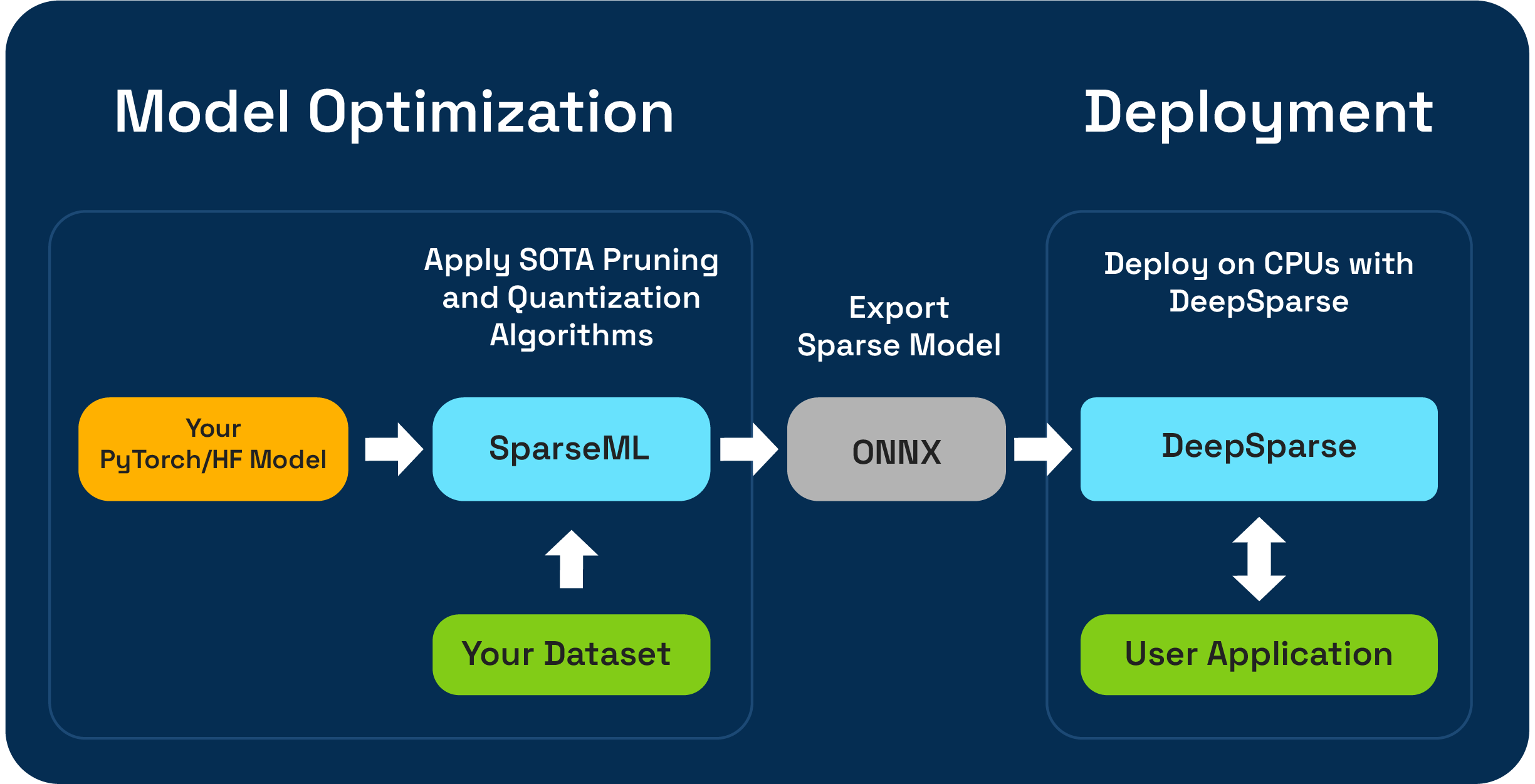
Sparseml은 오픈 소스 모델 최적화 툴킷으로 가지 치기, 양자화 및 증류 알고리즘을 사용하여 추론-최적화 된 스파 스 모델을 만들 수 있습니다. 그런 다음 Sparseml로 최적화 된 모델을 ONNX로 내보내고 CPU 하드웨어에서 GPU 클래스 성능을 위해 DeepSparse와 함께 배포 할 수 있습니다.
신경 마술은 새로운 SparseGPTModfier 사용하여 원샷 LLM 압축 워크 플로를 미리 보게되어 기쁩니다!
Tinyllama 채팅 모델을 잘라 내고 양자화하려면 종속성을 설치하고 레시피를 다운로드하여 모델에 적용하는 몇 가지 단계 일뿐입니다.
git clone https://github.com/neuralmagic/sparseml
pip install -e "sparseml[transformers]"
wget https://huggingface.co/neuralmagic/TinyLlama-1.1B-Chat-v0.4-pruned50-quant-ds/raw/main/recipe.yaml
sparseml.transformers.text_generation.oneshot --model_name TinyLlama/TinyLlama-1.1B-Chat-v1.0 --dataset_name open_platypus --recipe recipe.yaml --output_dir ./obcq_deployment --precision float16
src/sparseml/transformers/sparsification/obcq 의 readme에는 상세한 연습이 있습니다.
sparseml은 두 가지 방법으로 데이터 세트에서 훈련 된 스파 스 모델을 만들 수 있습니다.
Sparse Transfer Learning을 사용하면 Sparsezoo (Bert, Yolov5 및 Resnet-50과 같은 Sparse 모델의 오픈 소스 저장소)에서 데이터 세트에 데이터 세트에 미리 제공된 모델을 미세 조정할 수 있습니다. 이 경로는 CV 및 NLP 모델을 훈련시키는 데 익숙한 전형적인 미세 조정과 같이 작동하며 Sparsezoo에서 모델 아키텍처를 사용할 수있는 경우에 선호됩니다.
처음부터 스파이 션화하면 최첨단 가지 치기 (점진적 크기 가지 치기 또는 옵션 치기) 및 양자화 (양자 인식 교육) 알고리즘을 임의의 pytorch 및 포옹 얼굴 모델에 적용 할 수 있습니다. 이 경로에는 더 많은 실험이 필요하지만 모든 모델의 희소 버전을 만들 수 있습니다.

이 저장소는 Python 3.8-3.11 및 Linux/Debian Systems에서 테스트됩니다.
가상 환경에 설치하여 시스템을 순서대로 유지하는 것이 좋습니다. 현재 지원되는 ML 프레임 워크는 다음과 같습니다. torch>=1.1.0,<=2.0 , tensorflow>=1.8.0,<2.0.0 , tensorflow.keras >= 2.2.0 .
다음을 사용하여 PIP로 설치하십시오.
pip install sparseml선택적 종속성 및 요구 사항과 같은 설치에 대한 자세한 내용은 여기를 참조하십시오.
Sparseml은 유연성, 사용 편의성 및 반복성을 가능하게하기 위해 Sparseml에 의해 적용 해야하는 Sparsity 관련 알고리즘 및 하이퍼 파라미터를 지정하기 위해 recipes 라는 선언적 인터페이스를 사용합니다.
Recipes modifiers 목록으로 형식화되어 Sparseml에 대한 지침을 인코딩하는 Yaml-Files입니다. 예제 modifiers 학습 속도 설정부터 점진적인 크기 가지 치기 알고리즘의 하이퍼 파라미터를 인코딩하는 것까지 무엇이든 할 수 있습니다. Sparseml 시스템은 recipes 각 프레임 워크에 대한 기본 형식으로 구문 분석하고 모델 및 교육 파이프 라인에 수정을 적용합니다.
선언적, 레시피 기반 접근 방식으로 인해 기존 Pytorch 교육 파이프 라인에 Sparseml을 추가 할 수 있습니다. ScheduleModifierManager 클래스는 YAML recipes 구문 분석하고 표준 Pytorch 모델 및 최적화 객체를 우선적으로 수행하여 레시피의 희소성 알고리즘의 논리를 인코딩합니다. Sparseml은 Sparsification 알고리즘의 복잡성을 추상화하기 때문에 manager.modify 호출하면 모델과 Optimizer를 평소와 같이 사용할 수 있습니다.
워크 플로는 다음과 같습니다.
model = Model () # model definition
optimizer = Optimizer () # optimizer definition
train_data = TrainData () # train data definition
batch_size = BATCH_SIZE # training batch size
steps_per_epoch = len ( train_data ) // batch_size
from sparseml . pytorch . optim import ScheduledModifierManager
manager = ScheduledModifierManager . from_yaml ( PATH_TO_RECIPE )
optimizer = manager . modify ( model , optimizer , steps_per_epoch )
# typical PyTorch training loop, using your model/optimizer as usual
manager . finalize ( model )Trainer 와 Sparseml 사용에 대한 자세한 내용은 Hugging Face Integration Docs를 확인하십시오.Sparseml은 코드 레벨 API 외에도 CLI 인터페이스를 통해 일반적인 NLP 및 CV 작업을위한 사전 제작 된 교육 파이프 라인을 제공합니다. CLI를 사용하면 데이터 세트로드 및 사전 처리, 체크 포인트 저장, 메트릭보고 및 처리 된 로깅과 같은 다양한 유틸리티로 시작하는 교육을받을 수 있습니다. 이를 통해 일반적인 훈련 경로에서 쉽게 일어나고 달리기가 쉽습니다.
예를 들어, 우리는 다음을 사용하여 VOC 데이터 세트에서 Yolov5 스파 스 전송 학습 실행을 시작할 수 있습니다 (Sparsezoo Stubs를 사용하여 스파 스 모델 체크 포인트를 끌어 내고 전송어 학습 레시피를 전송합니다.
sparseml.yolov5.train
--weights zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned75_quant-none ? recipe_type=transfer_learn
--recipe zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned75_quant-none ? recipe_type=transfer_learn
--data VOC.yaml
--hyp hyps/hyp.finetune.yaml --cfg yolov5s.yaml --patience 0코드베이스 및 포함 된 프로세스에 대한 자세한 내용은 Sparseml 문서에서 찾을 수 있습니다.
공식 빌드는 PYPI에서 호스팅됩니다
또한 자세한 정보는 Github 릴리스를 통해 확인할 수 있습니다.
이 프로젝트는 Apache 라이센스 버전 2.0에 따라 라이센스가 부여됩니다.
버그 보고서 및 기능 요청뿐만 아니라 코드, 예제, 통합 및 문서에 대한 기여에 감사드립니다! 여기서 어떻게 배우십시오.
sparseml에 대한 사용자 도움이나 질문을 보려면 신경 마술 커뮤니티 슬랙 에 가입하거나 로그인하십시오. 우리는 회원이 커뮤니티 회원을 키우고 있으며 그곳에서 만나서 기쁩니다. 버그, 기능 요청 또는 추가 질문은 GitHub 문제 큐에도 게시 될 수 있습니다.
신경 마술 커뮤니티에 가입하여 최신 뉴스, 웹 세미나 및 이벤트 초대, 연구 논문 및 기타 ML 성능 소식을 얻을 수 있습니다.
신경 마술에 대한보다 일반적인 질문은이 형식을 작성하십시오.
이 프로젝트가 귀하의 연구 또는 기타 커뮤니케이션에 유용하다고 생각하십니까? 인용을 고려하십시오 :
@InProceedings {
pmlr-v119-kurtz20a,
title = { Inducing and Exploiting Activation Sparsity for Fast Inference on Deep Neural Networks } ,
author = { Kurtz, Mark and Kopinsky, Justin and Gelashvili, Rati and Matveev, Alexander and Carr, John and Goin, Michael and Leiserson, William and Moore, Sage and Nell, Bill and Shavit, Nir and Alistarh, Dan } ,
booktitle = { Proceedings of the 37th International Conference on Machine Learning } ,
pages = { 5533--5543 } ,
year = { 2020 } ,
editor = { Hal Daumé III and Aarti Singh } ,
volume = { 119 } ,
series = { Proceedings of Machine Learning Research } ,
address = { Virtual } ,
month = { 13--18 Jul } ,
publisher = { PMLR } ,
pdf = { http://proceedings.mlr.press/v119/kurtz20a/kurtz20a.pdf } ,
url = { http://proceedings.mlr.press/v119/kurtz20a.html } ,
abstract = {Optimizing convolutional neural networks for fast inference has recently become an extremely active area of research. One of the go-to solutions in this context is weight pruning, which aims to reduce computational and memory footprint by removing large subsets of the connections in a neural network. Surprisingly, much less attention has been given to exploiting sparsity in the activation maps, which tend to be naturally sparse in many settings thanks to the structure of rectified linear (ReLU) activation functions. In this paper, we present an in-depth analysis of methods for maximizing the sparsity of the activations in a trained neural network, and show that, when coupled with an efficient sparse-input convolution algorithm, we can leverage this sparsity for significant performance gains. To induce highly sparse activation maps without accuracy loss, we introduce a new regularization technique, coupled with a new threshold-based sparsification method based on a parameterized activation function called Forced-Activation-Threshold Rectified Linear Unit (FATReLU). We examine the impact of our methods on popular image classification models, showing that most architectures can adapt to significantly sparser activation maps without any accuracy loss. Our second contribution is showing that these these compression gains can be translated into inference speedups: we provide a new algorithm to enable fast convolution operations over networks with sparse activations, and show that it can enable significant speedups for end-to-end inference on a range of popular models on the large-scale ImageNet image classification task on modern Intel CPUs, with little or no retraining cost.}
} @misc {
singh2020woodfisher,
title = { WoodFisher: Efficient Second-Order Approximation for Neural Network Compression } ,
author = { Sidak Pal Singh and Dan Alistarh } ,
year = { 2020 } ,
eprint = { 2004.14340 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
}

