sparseml
v1.8.0
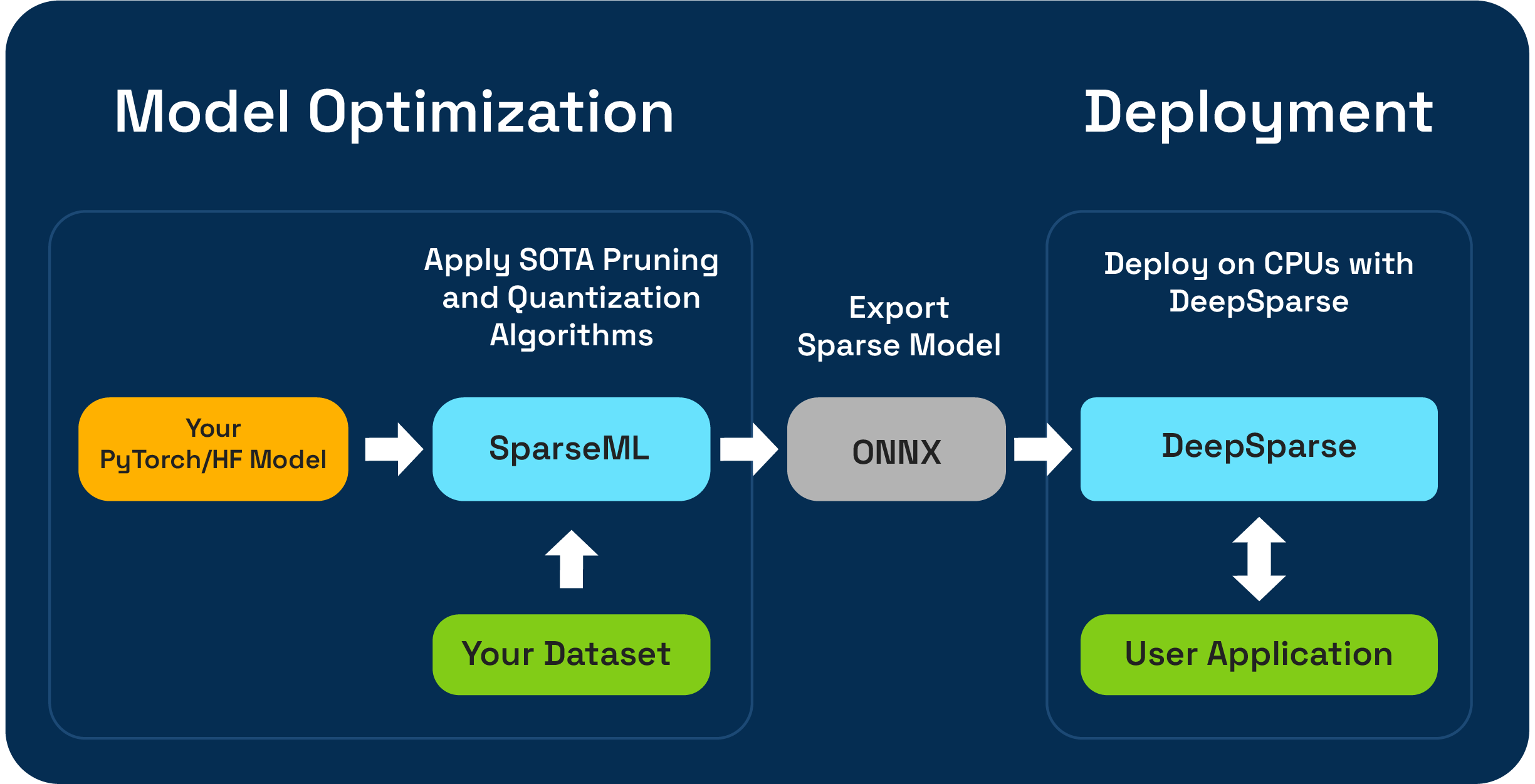
Sparseml es un conjunto de herramientas de optimización de modelos de código abierto que le permite crear modelos dispersos optimizados por inferencia utilizando algoritmos de poda, cuantización y destilación. Los modelos optimizados con Sparseml se pueden exportar al ONNX e implementarse con DeepSparse para el rendimiento de la clase GPU en el hardware de la CPU.
Neural Magic se complace en obtener una vista previa de los flujos de trabajo de compresión LLM de un solo disparo utilizando el nuevo SparseGPTModfier !
Para podar y cuantizar un modelo de chat Tinyllama, son solo unos pocos pasos para instalar dependencias, descargar una receta y aplicarla al modelo:
git clone https://github.com/neuralmagic/sparseml
pip install -e "sparseml[transformers]"
wget https://huggingface.co/neuralmagic/TinyLlama-1.1B-Chat-v0.4-pruned50-quant-ds/raw/main/recipe.yaml
sparseml.transformers.text_generation.oneshot --model_name TinyLlama/TinyLlama-1.1B-Chat-v1.0 --dataset_name open_platypus --recipe recipe.yaml --output_dir ./obcq_deployment --precision float16
El ReadMe en src/sparseml/transformers/sparsification/obcq tiene un tutorial detallado.
Sparseml le permite crear un modelo escaso capacitado en su conjunto de datos de dos maneras:
El aprendizaje de transferencia dispersa le permite ajustar un modelo preparsificado de Sparsezoo (un repositorio de código abierto de modelos dispersos como Bert, Yolov5 y ResNet-50) en su conjunto de datos, mientras mantiene la escasez. Esta vía funciona al igual que el ajuste fino típico al que está acostumbrado en el entrenamiento de modelos CV y PNL, y se prefiere fuertemente si su arquitectura modelo está disponible en Sparsezoo.
La dispersión desde cero le permite aplicar la poda de última generación (como poda o poda de magnitud gradual o poda) y algoritmos de cuantificación (como entrenamiento consciente de cuantificación) a modelos arbitrarios de pytorch y abrazos de abrazos. Esta vía requiere más experimentación, pero le permite crear una versión escasa de cualquier modelo.

Este repositorio se prueba en Python 3.8-3.11 y Linux/Debian Systems.
Se recomienda instalar en un entorno virtual para mantener su sistema en orden. Los marcos ML compatibles actualmente son los siguientes: torch>=1.1.0,<=2.0 , tensorflow>=1.8.0,<2.0.0 , tensorflow.keras >= 2.2.0 .
Instale con PIP usando:
pip install sparsemlAquí puede encontrar más información sobre la instalación, como dependencias y requisitos opcionales.
Para permitir la flexibilidad, la facilidad de uso y la repetibilidad, Sparseml utiliza una interfaz declarativa llamada recipes para especificar los algoritmos e hiperparámetros relacionados con la escasez que debe aplicar por Sparseml.
Recipes son archivos YAML formateados como una lista de modifiers , que codifican las instrucciones para Sparseml. modifiers de ejemplo pueden ser cualquier cosa, desde establecer la velocidad de aprendizaje hasta codificar los hiperparámetros del algoritmo de poda de magnitud gradual. El sistema SPARSEML analiza las recipes en un formato nativo para cada marco y aplica las modificaciones al modelo y la tubería de capacitación.
Debido al enfoque declarativo basado en recetas, puede agregar Sparseml a sus tuberías de entrenamiento de Pytorch existentes. La clase ScheduleModifierManager es responsable de analizar las recipes YAML y anular el modelo Pytorch estándar y los objetos optimizador, codificando la lógica de los algoritmos de escasez de la receta. Una vez que llame manager.modify , puede usar el modelo y el optimizador como de costumbre, ya que Sparseml abstrae la complejidad de los algoritmos de dispersión.
El flujo de trabajo se ve así:
model = Model () # model definition
optimizer = Optimizer () # optimizer definition
train_data = TrainData () # train data definition
batch_size = BATCH_SIZE # training batch size
steps_per_epoch = len ( train_data ) // batch_size
from sparseml . pytorch . optim import ScheduledModifierManager
manager = ScheduledModifierManager . from_yaml ( PATH_TO_RECIPE )
optimizer = manager . modify ( model , optimizer , steps_per_epoch )
# typical PyTorch training loop, using your model/optimizer as usual
manager . finalize ( model )Trainer de la cara abrazada.Además de la API a nivel de código, Sparseml ofrece tuberías de entrenamiento prefabricadas para tareas comunes de NLP y CV a través de la interfaz CLI. La CLI le permite las ejecuciones de entrenamiento de inicio con varias utilidades como la carga del conjunto de datos y el preprocesamiento, el ahorro de puntos de control, los informes métricos y el registro manejado para usted. Esto hace que sea fácil ponerse en marcha en caminos de entrenamiento comunes.
Por ejemplo, podemos usar lo siguiente para iniciar un aprendizaje de transferencia dispersa Yolov5 se ejecuta en el conjunto de datos VOC (usando sparsezoo Stubs para retirar un punto de control de modelo escaso y una receta de aprendizaje de transferencia):
sparseml.yolov5.train
--weights zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned75_quant-none ? recipe_type=transfer_learn
--recipe zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned75_quant-none ? recipe_type=transfer_learn
--data VOC.yaml
--hyp hyps/hyp.finetune.yaml --cfg yolov5s.yaml --patience 0Puede encontrar más información sobre la base de código y los procesos contenidos en los documentos de Sparseml:
Las construcciones oficiales están alojadas en Pypi
Además, se puede encontrar más información a través de las versiones de GitHub.
El proyecto tiene licencia bajo la Licencia Apache Versión 2.0.
¡Apreciamos las contribuciones al código, ejemplos, integraciones y documentación, así como informes de errores y solicitudes de funciones! Aprende cómo aquí.
Para ayuda del usuario o preguntas sobre Sparseml, regístrese o inicie sesión en nuestra comunidad de la comunidad de magia neural . Estamos haciendo crecer el miembro de la comunidad por miembro y felices de verte allí. Los errores, las solicitudes de funciones o las preguntas adicionales también se pueden publicar en nuestra cola de problemas de GitHub.
Puede obtener las últimas noticias, seminarios web y de eventos, trabajos de investigación y otros cositas de rendimiento de ML suscribiéndose a la comunidad de magia neural.
Para preguntas más generales sobre la magia neuronal, complete este formulario.
¿Encuentra este proyecto útil en su investigación u otras comunicaciones? Considere citar:
@InProceedings {
pmlr-v119-kurtz20a,
title = { Inducing and Exploiting Activation Sparsity for Fast Inference on Deep Neural Networks } ,
author = { Kurtz, Mark and Kopinsky, Justin and Gelashvili, Rati and Matveev, Alexander and Carr, John and Goin, Michael and Leiserson, William and Moore, Sage and Nell, Bill and Shavit, Nir and Alistarh, Dan } ,
booktitle = { Proceedings of the 37th International Conference on Machine Learning } ,
pages = { 5533--5543 } ,
year = { 2020 } ,
editor = { Hal Daumé III and Aarti Singh } ,
volume = { 119 } ,
series = { Proceedings of Machine Learning Research } ,
address = { Virtual } ,
month = { 13--18 Jul } ,
publisher = { PMLR } ,
pdf = { http://proceedings.mlr.press/v119/kurtz20a/kurtz20a.pdf } ,
url = { http://proceedings.mlr.press/v119/kurtz20a.html } ,
abstract = {Optimizing convolutional neural networks for fast inference has recently become an extremely active area of research. One of the go-to solutions in this context is weight pruning, which aims to reduce computational and memory footprint by removing large subsets of the connections in a neural network. Surprisingly, much less attention has been given to exploiting sparsity in the activation maps, which tend to be naturally sparse in many settings thanks to the structure of rectified linear (ReLU) activation functions. In this paper, we present an in-depth analysis of methods for maximizing the sparsity of the activations in a trained neural network, and show that, when coupled with an efficient sparse-input convolution algorithm, we can leverage this sparsity for significant performance gains. To induce highly sparse activation maps without accuracy loss, we introduce a new regularization technique, coupled with a new threshold-based sparsification method based on a parameterized activation function called Forced-Activation-Threshold Rectified Linear Unit (FATReLU). We examine the impact of our methods on popular image classification models, showing that most architectures can adapt to significantly sparser activation maps without any accuracy loss. Our second contribution is showing that these these compression gains can be translated into inference speedups: we provide a new algorithm to enable fast convolution operations over networks with sparse activations, and show that it can enable significant speedups for end-to-end inference on a range of popular models on the large-scale ImageNet image classification task on modern Intel CPUs, with little or no retraining cost.}
} @misc {
singh2020woodfisher,
title = { WoodFisher: Efficient Second-Order Approximation for Neural Network Compression } ,
author = { Sidak Pal Singh and Dan Alistarh } ,
year = { 2020 } ,
eprint = { 2004.14340 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
}

