sparseml
v1.8.0
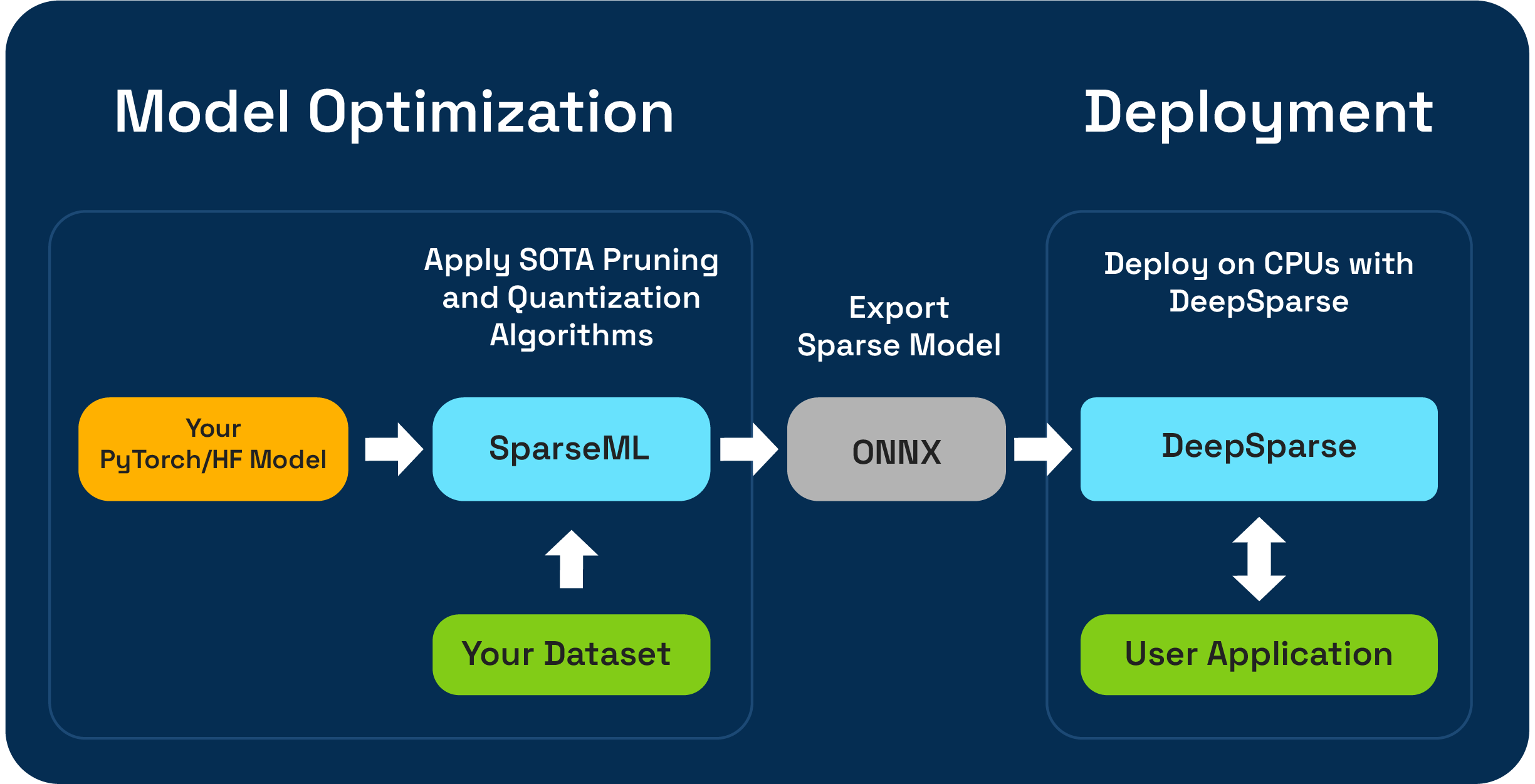
SparSEML เป็นชุดเครื่องมือเพิ่มประสิทธิภาพแบบจำลองโอเพนซอร์ซที่ช่วยให้คุณสร้างโมเดลกระจัดกระจายที่ปรับการอนุมานได้โดยใช้การตัดแต่งกิ่งปริมาณและอัลกอริทึมการกลั่น โมเดลที่ปรับให้เหมาะสมด้วย SparSEML สามารถส่งออกไปยัง ONNX และปรับใช้กับ DeepSparse สำหรับประสิทธิภาพระดับ GPU บนฮาร์ดแวร์ CPU
Neural Magic รู้สึกตื่นเต้นที่จะดูตัวอย่างเวิร์กโฟลว์การบีบอัด LLM One-Shot โดยใช้ SparseGPTModfier ใหม่!
ในการตัดแต่งและหาปริมาณโมเดลแชท Tinyllama มันเป็นเพียงไม่กี่ขั้นตอนในการติดตั้งการพึ่งพาดาวน์โหลดสูตรและนำไปใช้กับรุ่น:
git clone https://github.com/neuralmagic/sparseml
pip install -e "sparseml[transformers]"
wget https://huggingface.co/neuralmagic/TinyLlama-1.1B-Chat-v0.4-pruned50-quant-ds/raw/main/recipe.yaml
sparseml.transformers.text_generation.oneshot --model_name TinyLlama/TinyLlama-1.1B-Chat-v1.0 --dataset_name open_platypus --recipe recipe.yaml --output_dir ./obcq_deployment --precision float16
readMe ที่ src/sparseml/transformers/sparsification/obcq มีคำแนะนำโดยละเอียด
SparSEML ช่วยให้คุณสร้างโมเดลที่กระจัดกระจายได้รับการฝึกฝนบนชุดข้อมูลของคุณในสองวิธี:
การเรียนรู้การถ่ายโอนแบบกระจัดกระจาย ช่วยให้คุณสามารถปรับแต่งโมเดลที่กระจายล่วงหน้าจาก Sparsezoo (ที่เก็บโอเพนซอร์ซของโมเดลกระจัดกระจายเช่น Bert, YOLOV5 และ RESNET-50) ลงในชุดข้อมูลของคุณในขณะที่ยังคงความเป็นไปได้ เส้นทางนี้ใช้งานได้เช่นเดียวกับการปรับแต่งทั่วไปที่คุณคุ้นเคยในการฝึกอบรม CV และ NLP รุ่นและเป็นที่ต้องการอย่างยิ่งหากสถาปัตยกรรมแบบจำลองของคุณมีอยู่ใน Sparsezoo
การเปลี่ยนจากรอยขีดข่วน ช่วยให้คุณสามารถใช้การตัดแต่งกิ่งที่ทันสมัย (เช่นการตัดแต่งกิ่งขนาดค่อยเป็นค่อยไปหรือการตัดแต่งกิ่ง) และการวัดปริมาณ (เช่นการฝึกอบรมเชิงปริมาณ) อัลกอริทึมไปยัง pytorch โดยพลการและแบบจำลองใบหน้ากอด เส้นทางนี้ต้องการการทดลองมากขึ้น แต่ช่วยให้คุณสร้างรุ่นที่กระจัดกระจายของรุ่นใดก็ได้

ที่เก็บนี้ได้รับการทดสอบใน Python 3.8-3.11 และระบบ Linux/Debian
ขอแนะนำให้ติดตั้งในสภาพแวดล้อมเสมือนจริงเพื่อให้ระบบของคุณเป็นระเบียบ เฟรมเวิร์ก ML ที่รองรับในปัจจุบันมีดังต่อไปนี้: torch>=1.1.0,<=2.0 , tensorflow>=1.8.0,<2.0.0 , tensorflow.keras >= 2.2.0
ติดตั้งด้วย PIP โดยใช้:
pip install sparsemlข้อมูลเพิ่มเติมเกี่ยวกับการติดตั้งเช่นการพึ่งพาและข้อกำหนดเพิ่มเติมสามารถพบได้ที่นี่
เพื่อเปิดใช้งานความยืดหยุ่นความสะดวกในการใช้งานและการทำซ้ำ SparSEML ใช้อินเทอร์เฟซที่เรียกว่า recipes สำหรับการระบุอัลกอริทึมที่เกี่ยวข้องกับ sparsity และ hyperparameters ที่ควรใช้โดย SparSEML
Recipes คือ Yaml-Files ที่จัดรูปแบบเป็นรายการของ modifiers ซึ่งเข้ารหัสคำแนะนำสำหรับ SparsEML ตัวอย่าง modifiers สามารถเป็นอะไรก็ได้ตั้งแต่การตั้งค่าอัตราการเรียนรู้ไปจนถึงการเข้ารหัสไฮเปอร์พารามิเตอร์ของอัลกอริทึมการตัดแต่งกิ่งขนาดค่อยเป็นค่อยไป ระบบ SparSEML วิเคราะห์ recipes เป็นรูปแบบดั้งเดิมสำหรับแต่ละเฟรมเวิร์กและใช้การปรับเปลี่ยนโมเดลและการฝึกอบรมไปป์ไลน์
เนื่องจากวิธีการที่ประกาศใช้ตามสูตรคุณสามารถเพิ่ม sparsEML ลงในท่อฝึกอบรม pytorch ที่มีอยู่ของคุณ คลาส ScheduleModifierManager มีหน้าที่ในการแยกวิเคราะห์ recipes YAML และการเอาชนะโมเดล pytorch มาตรฐานและวัตถุเพิ่มประสิทธิภาพการเข้ารหัสตรรกะของอัลกอริทึม sparsity จากสูตร เมื่อคุณโทรหา manager.modify แล้วคุณสามารถใช้โมเดลและเครื่องมือเพิ่มประสิทธิภาพได้ตามปกติเช่น sparsEML abstracts ความซับซ้อนของอัลกอริทึม sparsification
เวิร์กโฟลว์มีลักษณะเช่นนี้:
model = Model () # model definition
optimizer = Optimizer () # optimizer definition
train_data = TrainData () # train data definition
batch_size = BATCH_SIZE # training batch size
steps_per_epoch = len ( train_data ) // batch_size
from sparseml . pytorch . optim import ScheduledModifierManager
manager = ScheduledModifierManager . from_yaml ( PATH_TO_RECIPE )
optimizer = manager . modify ( model , optimizer , steps_per_epoch )
# typical PyTorch training loop, using your model/optimizer as usual
manager . finalize ( model )Trainerนอกเหนือจาก API ระดับรหัสแล้ว SparsEML ยังมีท่อฝึกอบรมที่ทำไว้ล่วงหน้าสำหรับงาน NLP และ CV ทั่วไปผ่านอินเตอร์เฟส CLI CLI ช่วยให้คุณสามารถเริ่มการฝึกอบรมได้ด้วยยูทิลิตี้ต่างๆเช่นการโหลดชุดข้อมูลและการประมวลผลล่วงหน้าการบันทึกจุดตรวจการรายงานการวัดและการบันทึกสำหรับคุณ สิ่งนี้ทำให้ง่ายต่อการลุกขึ้นและวิ่งในเส้นทางการฝึกอบรมทั่วไป
ตัวอย่างเช่นเราสามารถใช้สิ่งต่อไปนี้เพื่อเริ่มต้นการเรียนรู้การถ่ายโอน YOLOV5 แบบเบาบางลงบนชุดข้อมูล VOC (โดยใช้ Stubs Sparsezoo เพื่อดึงจุดตรวจสอบแบบจำลองและการถ่ายโอนสูตรการเรียนรู้):
sparseml.yolov5.train
--weights zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned75_quant-none ? recipe_type=transfer_learn
--recipe zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned75_quant-none ? recipe_type=transfer_learn
--data VOC.yaml
--hyp hyps/hyp.finetune.yaml --cfg yolov5s.yaml --patience 0ข้อมูลเพิ่มเติมเกี่ยวกับ codebase และกระบวนการที่มีอยู่สามารถพบได้ในเอกสาร SparSEML:
งานสร้างอย่างเป็นทางการเป็นเจ้าภาพใน PYPI
นอกจากนี้ข้อมูลเพิ่มเติมสามารถพบได้ผ่านการเผยแพร่ GitHub
โครงการได้รับใบอนุญาตภายใต้ Apache License Version 2.0
เราขอขอบคุณที่มีส่วนร่วมในรหัสตัวอย่างการรวมและเอกสารรวมถึงรายงานข้อผิดพลาดและคำขอคุณสมบัติ! เรียนรู้วิธีการที่นี่
สำหรับความช่วยเหลือของผู้ใช้หรือคำถามเกี่ยวกับ SparsEML ลงทะเบียนหรือเข้าสู่ระบบของ ชุมชนเวทมนตร์ประสาท ของเรา เรากำลังเติบโตสมาชิกชุมชนโดยสมาชิกและมีความสุขที่ได้พบคุณที่นั่น ข้อบกพร่องคำขอคุณสมบัติหรือคำถามเพิ่มเติมสามารถโพสต์ไปยังคิวปัญหา GitHub ของเราได้
คุณสามารถรับข่าวสารล่าสุดการสัมมนาผ่านเว็บและการเชิญงานงานวิจัยและเกร็ดความรู้อื่น ๆ ของ ML โดยการสมัครรับชุมชนเวทมนตร์ประสาท
สำหรับคำถามทั่วไปเพิ่มเติมเกี่ยวกับเวทมนตร์ของระบบประสาทโปรดกรอกแบบฟอร์มนี้
ค้นหาโครงการนี้มีประโยชน์ในการวิจัยหรือการสื่อสารอื่น ๆ ของคุณ? โปรดพิจารณาอ้าง:
@InProceedings {
pmlr-v119-kurtz20a,
title = { Inducing and Exploiting Activation Sparsity for Fast Inference on Deep Neural Networks } ,
author = { Kurtz, Mark and Kopinsky, Justin and Gelashvili, Rati and Matveev, Alexander and Carr, John and Goin, Michael and Leiserson, William and Moore, Sage and Nell, Bill and Shavit, Nir and Alistarh, Dan } ,
booktitle = { Proceedings of the 37th International Conference on Machine Learning } ,
pages = { 5533--5543 } ,
year = { 2020 } ,
editor = { Hal Daumé III and Aarti Singh } ,
volume = { 119 } ,
series = { Proceedings of Machine Learning Research } ,
address = { Virtual } ,
month = { 13--18 Jul } ,
publisher = { PMLR } ,
pdf = { http://proceedings.mlr.press/v119/kurtz20a/kurtz20a.pdf } ,
url = { http://proceedings.mlr.press/v119/kurtz20a.html } ,
abstract = {Optimizing convolutional neural networks for fast inference has recently become an extremely active area of research. One of the go-to solutions in this context is weight pruning, which aims to reduce computational and memory footprint by removing large subsets of the connections in a neural network. Surprisingly, much less attention has been given to exploiting sparsity in the activation maps, which tend to be naturally sparse in many settings thanks to the structure of rectified linear (ReLU) activation functions. In this paper, we present an in-depth analysis of methods for maximizing the sparsity of the activations in a trained neural network, and show that, when coupled with an efficient sparse-input convolution algorithm, we can leverage this sparsity for significant performance gains. To induce highly sparse activation maps without accuracy loss, we introduce a new regularization technique, coupled with a new threshold-based sparsification method based on a parameterized activation function called Forced-Activation-Threshold Rectified Linear Unit (FATReLU). We examine the impact of our methods on popular image classification models, showing that most architectures can adapt to significantly sparser activation maps without any accuracy loss. Our second contribution is showing that these these compression gains can be translated into inference speedups: we provide a new algorithm to enable fast convolution operations over networks with sparse activations, and show that it can enable significant speedups for end-to-end inference on a range of popular models on the large-scale ImageNet image classification task on modern Intel CPUs, with little or no retraining cost.}
} @misc {
singh2020woodfisher,
title = { WoodFisher: Efficient Second-Order Approximation for Neural Network Compression } ,
author = { Sidak Pal Singh and Dan Alistarh } ,
year = { 2020 } ,
eprint = { 2004.14340 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
}

