sparseml
v1.8.0
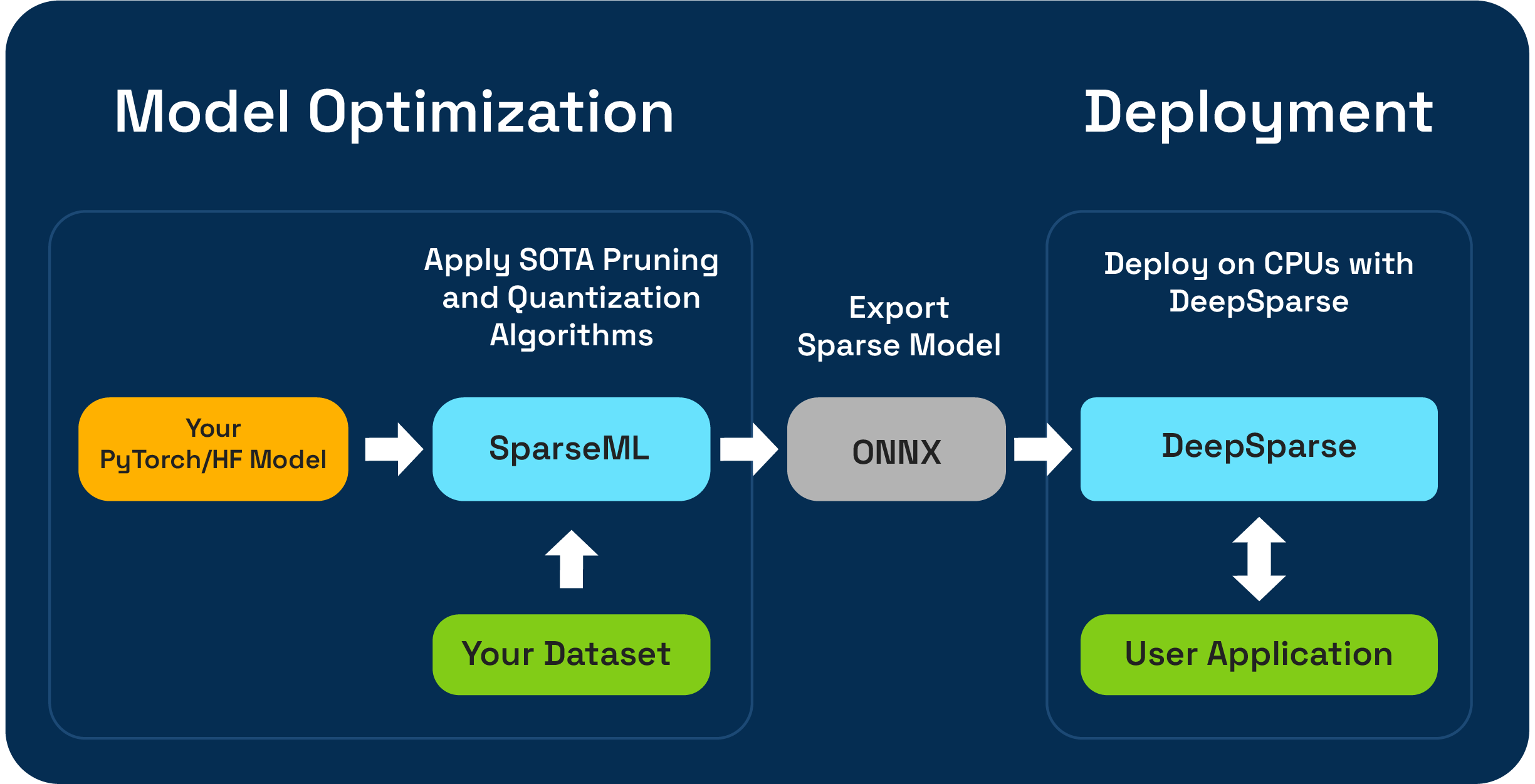
SPARSEMLは、剪定、量子化、および蒸留アルゴリズムを使用して、推論が最適化されたスパースモデルを作成できるオープンソースモデルの最適化ツールキットです。 Sparsemlで最適化されたモデルをONNXにエクスポートし、CPUハードウェアでGPUクラスのパフォーマンスのためにDeepsParseで展開できます。
Neural Magicは、新しいSparseGPTModfierを使用して、ワンショットLLM圧縮ワークフローをプレビューすることに興奮しています!
Tinyllamaチャットモデルを剪定して量子化するには、依存関係をインストールし、レシピをダウンロードしてモデルに適用するのはほんの数ステップです。
git clone https://github.com/neuralmagic/sparseml
pip install -e "sparseml[transformers]"
wget https://huggingface.co/neuralmagic/TinyLlama-1.1B-Chat-v0.4-pruned50-quant-ds/raw/main/recipe.yaml
sparseml.transformers.text_generation.oneshot --model_name TinyLlama/TinyLlama-1.1B-Chat-v1.0 --dataset_name open_platypus --recipe recipe.yaml --output_dir ./obcq_deployment --precision float16
src/sparseml/transformers/sparsification/obcqのREADMEには、詳細なウォークスルーがあります。
SPARSEMLを使用すると、2つの方法でデータセットでトレーニングされたスパースモデルを作成できます。
スパース転送学習を使用すると、Sparsezoo(Bert、Yolov5、Resnet-50などのスパースモデルのオープンソースリポジトリ)から、スパースを維持しながら、スパースモデルのオープンソースリポジトリ)を微調整できます。この経路は、CVモデルとNLPモデルのトレーニングに慣れている典型的な微調整と同じように機能し、モデルアーキテクチャがSparsezooで利用可能である場合に強く好まれます。
ゼロからのスパース化により、最先端の剪定(段階的なマグニチュードプルーニングやオブスプルーニングなど)および量子化(量子化認識トレーニングなど)のアルゴリズムを任意のPytorchおよびHugging Face Modelsに適用できます。この経路では、より多くの実験が必要ですが、あらゆるモデルのスパースバージョンを作成できます。

このリポジトリは、Python 3.8-3.11およびLinux/Debianシステムでテストされています。
システムを順番に保つために、仮想環境にインストールすることをお勧めします。現在サポートされているMLフレームワークは次のとおりです。Torch torch>=1.1.0,<=2.0 、 tensorflow>=1.8.0,<2.0.0 、 tensorflow.keras >= 2.2.0 。
PIPを使用してインストールしてください。
pip install sparsemlオプションの依存関係や要件などのインストールの詳細については、こちらをご覧ください。
SparSemlは、柔軟性、使いやすさ、再現性を可能にするために、SPARSEMLが適用する必要があるスパース関連アルゴリズムとハイパーパラメーターを指定するために、 recipesと呼ばれる宣言的インターフェイスを使用します。
Recipesは、sparsemlの指示をエンコードするmodifiersのリストとしてフォーマットされています。 modifiersの例は、学習レートの設定から、段階的なマグニチュードプルーニングアルゴリズムのハイパーパラメーターをエンコードするまで、あらゆるものにすることができます。 SPARSEMLシステムは、各フレームワークのrecipesネイティブ形式に分析し、モデルとトレーニングパイプラインに変更を適用します。
宣言的なレシピベースのアプローチにより、既存のPytorchトレーニングパイプラインにSparsemlを追加できます。 ScheduleModifierManagerクラスは、YAML recipesを解析し、標準のPytorchモデルとオプティマイザーオブジェクトをオーバーライドする責任があり、レシピのスパース性アルゴリズムのロジックをエンコードします。 manager.modifyに電話をかけると、SparsemlがSparsification Algorithmsの複雑さを抽象化するため、モデルとオプティマイザーを通常どおり使用できます。
ワークフローは次のようになります:
model = Model () # model definition
optimizer = Optimizer () # optimizer definition
train_data = TrainData () # train data definition
batch_size = BATCH_SIZE # training batch size
steps_per_epoch = len ( train_data ) // batch_size
from sparseml . pytorch . optim import ScheduledModifierManager
manager = ScheduledModifierManager . from_yaml ( PATH_TO_RECIPE )
optimizer = manager . modify ( model , optimizer , steps_per_epoch )
# typical PyTorch training loop, using your model/optimizer as usual
manager . finalize ( model )TrainerでSparsemlを使用する詳細については、Hugging Face Integration Docsをご覧ください。コードレベルのAPIに加えて、SPARSEMLは、CLIインターフェイスを介した一般的なNLPおよびCVタスクの事前に作成されたトレーニングパイプラインを提供しています。 CLIを使用すると、データセットの読み込みや前処理、チェックポイントの保存、メトリックレポート、ロギングなどのさまざまなユーティリティを使用してトレーニングをオフにできます。これにより、一般的なトレーニング経路で立ち上がって実行しやすくなります。
たとえば、以下を使用して、Yolov5スパーストランスファーラーニングをVOCデータセットにキックオフできます(Sparsezooスタブを使用してスパースモデルチェックポイントを引き下げ、学習レシピを転送する):
sparseml.yolov5.train
--weights zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned75_quant-none ? recipe_type=transfer_learn
--recipe zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned75_quant-none ? recipe_type=transfer_learn
--data VOC.yaml
--hyp hyps/hyp.finetune.yaml --cfg yolov5s.yaml --patience 0コードベースと含まれるプロセスの詳細については、SPARSEMLドキュメントをご覧ください。
公式ビルドはPypiでホストされています
さらに、GitHubリリースを介して詳細を確認できます。
このプロジェクトは、Apacheライセンスバージョン2.0に基づいてライセンスされています。
コード、例、統合、ドキュメントへの貢献、バグレポートと機能リクエストに感謝します!ここでどのように学びましょう。
Sparsemlに関するユーザーヘルプまたは質問については、サインアップまたはニューラルマジックコミュニティのSlackにログインしてください。私たちはメンバーによってコミュニティメンバーを成長させており、そこでお会いできてうれしいです。バグ、機能リクエスト、または追加の質問は、GitHub発行キューにも投稿できます。
Neural Magic Communityを購読することにより、最新のニュース、ウェビナー、イベントの招待状、研究論文、その他のMLパフォーマンスの情報を入手できます。
ニューラルマジックに関するより一般的な質問については、このフォームに記入してください。
このプロジェクトは、あなたの研究や他のコミュニケーションで役立つと思いますか?引用を検討してください:
@InProceedings {
pmlr-v119-kurtz20a,
title = { Inducing and Exploiting Activation Sparsity for Fast Inference on Deep Neural Networks } ,
author = { Kurtz, Mark and Kopinsky, Justin and Gelashvili, Rati and Matveev, Alexander and Carr, John and Goin, Michael and Leiserson, William and Moore, Sage and Nell, Bill and Shavit, Nir and Alistarh, Dan } ,
booktitle = { Proceedings of the 37th International Conference on Machine Learning } ,
pages = { 5533--5543 } ,
year = { 2020 } ,
editor = { Hal Daumé III and Aarti Singh } ,
volume = { 119 } ,
series = { Proceedings of Machine Learning Research } ,
address = { Virtual } ,
month = { 13--18 Jul } ,
publisher = { PMLR } ,
pdf = { http://proceedings.mlr.press/v119/kurtz20a/kurtz20a.pdf } ,
url = { http://proceedings.mlr.press/v119/kurtz20a.html } ,
abstract = {Optimizing convolutional neural networks for fast inference has recently become an extremely active area of research. One of the go-to solutions in this context is weight pruning, which aims to reduce computational and memory footprint by removing large subsets of the connections in a neural network. Surprisingly, much less attention has been given to exploiting sparsity in the activation maps, which tend to be naturally sparse in many settings thanks to the structure of rectified linear (ReLU) activation functions. In this paper, we present an in-depth analysis of methods for maximizing the sparsity of the activations in a trained neural network, and show that, when coupled with an efficient sparse-input convolution algorithm, we can leverage this sparsity for significant performance gains. To induce highly sparse activation maps without accuracy loss, we introduce a new regularization technique, coupled with a new threshold-based sparsification method based on a parameterized activation function called Forced-Activation-Threshold Rectified Linear Unit (FATReLU). We examine the impact of our methods on popular image classification models, showing that most architectures can adapt to significantly sparser activation maps without any accuracy loss. Our second contribution is showing that these these compression gains can be translated into inference speedups: we provide a new algorithm to enable fast convolution operations over networks with sparse activations, and show that it can enable significant speedups for end-to-end inference on a range of popular models on the large-scale ImageNet image classification task on modern Intel CPUs, with little or no retraining cost.}
} @misc {
singh2020woodfisher,
title = { WoodFisher: Efficient Second-Order Approximation for Neural Network Compression } ,
author = { Sidak Pal Singh and Dan Alistarh } ,
year = { 2020 } ,
eprint = { 2004.14340 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
}

