PERT
1.0.0
中文| English

在自然語言處理領域中,預訓練語言模型(Pre-trained Language Models,PLMs)已成為非常重要的基礎技術。在近兩年,哈工大訊飛聯合實驗室發布了多種中文預訓練模型資源以及相關配套工具。作為相關工作的延續,在本項目中,我們提出了一種基於亂序語言模型的預訓練模型(PERT),在不引入掩碼標記[MASK]的情況下自監督地學習文本語義信息。 PERT在部分中英文NLU任務上獲得性能提升,但也在部分任務上效果較差,請酌情使用。目前提供了中文和英文的PERT模型,包含兩種模型大小(base、large)。
中文LERT | 中英文PERT | 中文MacBERT | 中文ELECTRA | 中文XLNet | 中文BERT | 知識蒸餾工具TextBrewer | 模型裁剪工具TextPruner
查看更多哈工大訊飛聯合實驗室(HFL)發布的資源:https://github.com/ymcui/HFL-Anthology
2023/3/28 開源了中文LLaMA&Alpaca大模型,可快速在PC上部署體驗,查看:https://github.com/ymcui/Chinese-LLaMA-Alpaca
2022/10/29 我們提出了一種融合語言學信息的預訓練模型LERT。查看:https://github.com/ymcui/LERT
2022/5/7 更新了在多個閱讀理解數據集上精調的閱讀理解專用PERT,並提供了huggingface在線交互Demo,check:模型下載
2022/3/15 技術報告已發布,請參考:https://arxiv.org/abs/2203.06906
2022/2/24 中文、英文的PERT-base和PERT-large已發布。可直接使用BERT結構加載並進行下游任務精調。技術報告待完善後發出,時間預計在3月中旬,感謝耐心等待。
2022/2/17 感謝對本項目的關注,預計下週發出模型,技術報告待完善後發出。
| 章節 | 描述 |
|---|---|
| 簡介 | PERT預訓練模型的基本原理 |
| 模型下載 | PERT預訓練模型的下載地址 |
| 快速加載 | 如何使用?Transformers快速加載模型 |
| 基線系統效果 | 在部分中英文NLU任務上的基線系統效果 |
| FAQ | 常見問題答疑 |
| 引用 | 本項目的技術報告 |
面向自然語言理解(NLU)的預訓練模型的學習大致分為兩類:使用和不使用帶掩碼標記[MASK]的輸入文本。
算法啟發:一定程度的亂序文本不影響理解。那麼能否從亂序文本中學習語義知識?
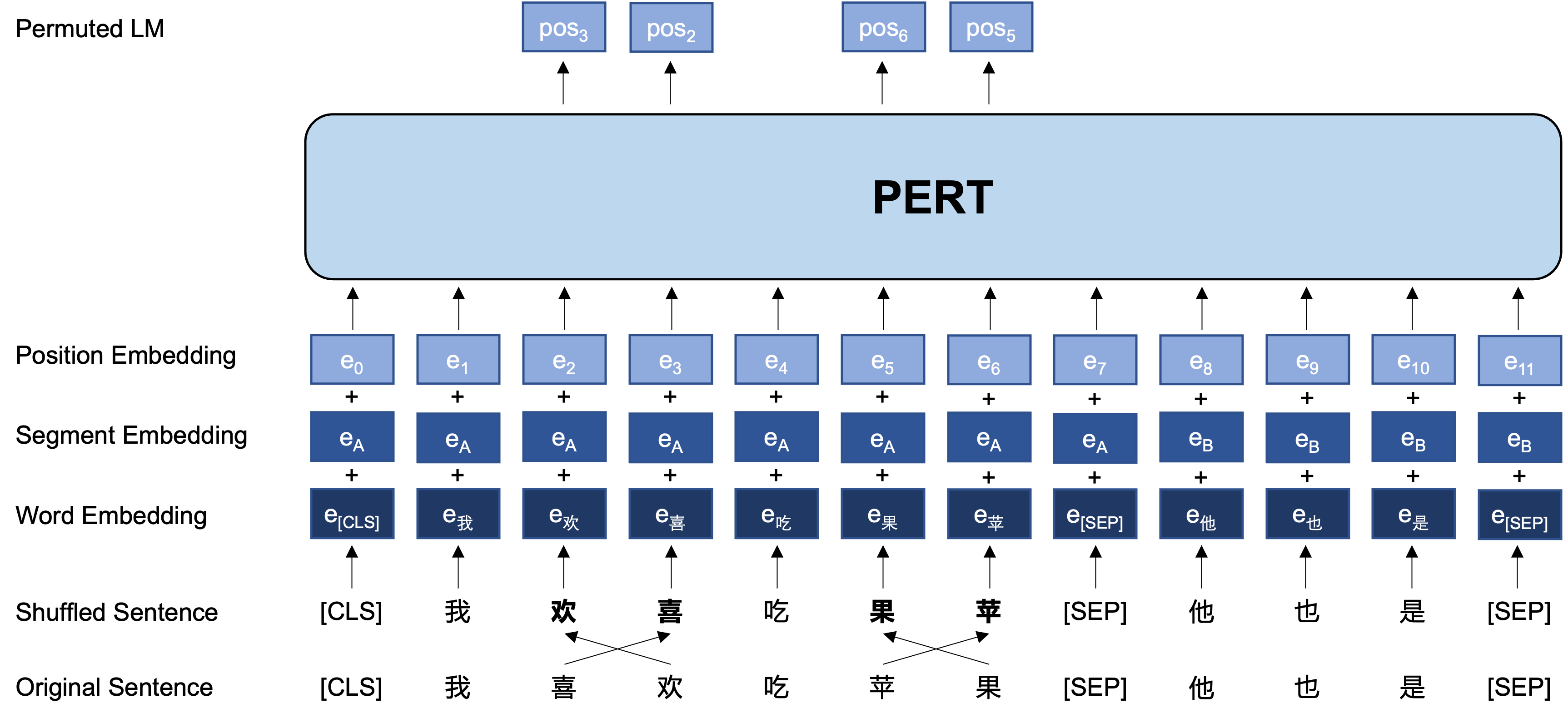
大體思想:PERT對原始輸入文本進行一定的詞序調換,從而形成亂序文本(因此不會引入額外的[MASK]標記)。 PERT的學習目標是預測原token所在的位置,具體見下例。
| 說明 | 輸入文本 | 輸出目標 |
|---|---|---|
| 原始文本 | 研究表明這一句話的順序並不影響閱讀。 | - |
| WordPiece分詞後 | 研究表明這一句話的順序並不影響閱讀。 | - |
| BERT | 研究表明這一句[MASK]的順[MASK]並不[MASK]響閱讀。 | 位置7 → 話位置10 → 序位置13 → 影 |
| PERT | 研究明表這一句話的順序並不響影閱 讀。 | 位置2(明)→位置3(表) 位置3(表)→位置2(明) 位置13(響)→位置14(影) 位置14(影)→位置13(響) |
以下是PERT模型在預訓練階段的基本結構和輸入輸出格式(注意:目前arXiv技術報告中的圖片有誤,請以下圖為準。下次更新論文時會替換為正確圖片。)。
這裡主要提供TensorFlow 1.15版本的模型權重。如需PyTorch或者TensorFlow2版本的模型,請看下一小節。
開源版本僅包含Transformer部分的權重,可直接用於下游任務精調,或者其他預訓練模型二次預訓練的初始權重,更多說明見FAQ。
PERT-large :24-layer, 1024-hidden, 16-heads, 330M parametersPERT-base 12-layer, 768-hidden, 12-heads, 110M parameters| 模型簡稱 | 語種 | 語料 | Google下載 | 百度盤下載 |
|---|---|---|---|---|
| Chinese-PERT-large | 中文 | EXT數據[1] | TensorFlow | TensorFlow(密碼:e9hs) |
| Chinese-PERT-base | 中文 | EXT數據[1] | TensorFlow | TensorFlow(密碼:rcsw) |
| English-PERT-large (uncased) | 英文 | WikiBooks [2] | TensorFlow | TensorFlow(密碼:wxwi) |
| English-PERT-base (uncased) | 英文 | WikiBooks [2] | TensorFlow | TensorFlow(密碼:8jgq) |
[1] EXT數據包括:中文維基百科,其他百科、新聞、問答等數據,總詞數達5.4B,約佔用20G磁盤空間,與MacBERT相同。
[2] Wikipedia + BookCorpus
以TensorFlow版Chinese-PERT-base為例,下載完畢後對zip文件進行解壓得到:
chinese_pert_base_L-12_H-768_A-12.zip
|- pert_model.ckpt # 模型权重
|- pert_model.meta # 模型meta信息
|- pert_model.index # 模型index信息
|- pert_config.json # 模型参数
|- vocab.txt # 词表(与谷歌原版一致)
其中bert_config.json和vocab.txt與穀歌原版BERT-base, Chinese完全一致(英文版與BERT-uncased版本一致)。
通過?transformers模型庫可以下載TensorFlow (v2)和PyTorch版本模型。
下載方法:點擊任意需要下載的模型→ 選擇"Files and versions"選項卡→ 下載對應的模型文件。
| 模型簡稱 | 模型文件大小 | transformers模型庫地址 |
|---|---|---|
| Chinese-PERT-large | 1.2G | https://huggingface.co/hfl/chinese-pert-large |
| Chinese-PERT-base | 0.4G | https://huggingface.co/hfl/chinese-pert-base |
| Chinese-PERT-large-MRC | 1.2G | https://huggingface.co/hfl/chinese-pert-large-mrc |
| Chinese-PERT-base-MRC | 0.4G | https://huggingface.co/hfl/chinese-pert-base-mrc |
| English-PERT-large | 1.2G | https://huggingface.co/hfl/english-pert-large |
| English-PERT-base | 0.4G | https://huggingface.co/hfl/english-pert-base |
由於PERT主體部分仍然是BERT結構,用戶可以使用transformers庫輕鬆調用PERT模型。
注意:本目錄中的所有模型均使用BertTokenizer以及BertModel加載(MRC模型使用BertForQuestionAnswering)。
from transformers import BertTokenizer , BertModel
tokenizer = BertTokenizer . from_pretrained ( "MODEL_NAME" )
model = BertModel . from_pretrained ( "MODEL_NAME" )其中MODEL_NAME對應列表如下:
| 模型名 | MODEL_NAME |
|---|---|
| Chinese-PERT-large | hfl/chinese-pert-large |
| Chinese-PERT-base | hfl/chinese-pert-base |
| Chinese-PERT-large-MRC | hfl/chinese-pert-large-mrc |
| Chinese-PERT-base-MRC | hfl/chinese-pert-base-mrc |
| English-PERT-large | hfl/english-pert-large |
| English-PERT-base | hfl/english-pert-base |
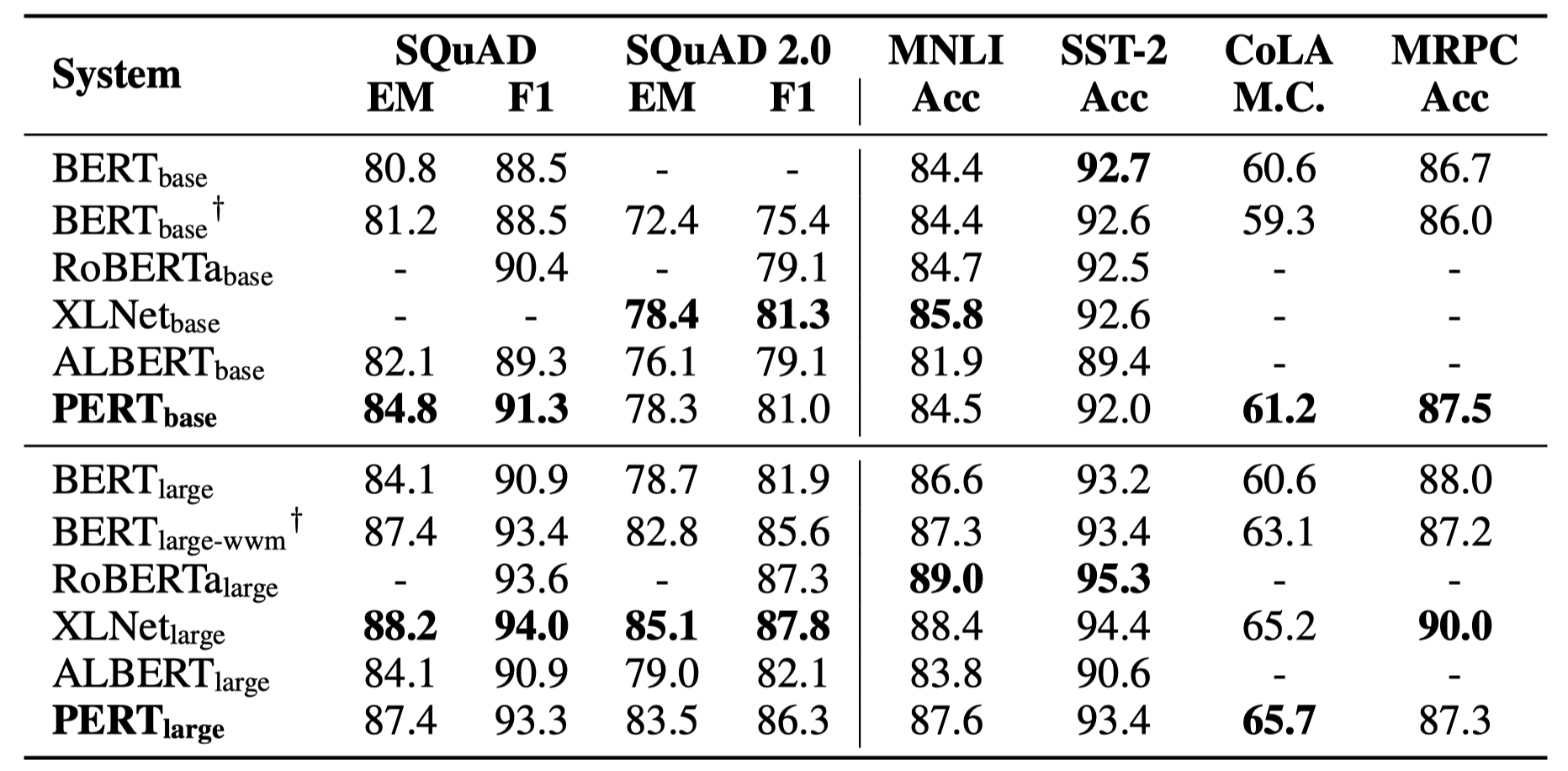
以下僅列舉部分實驗結果。詳細結果和分析見論文。實驗結果表格中,括號外為最大值,括號內為平均值。
在以下10個任務上進行了效果測試。
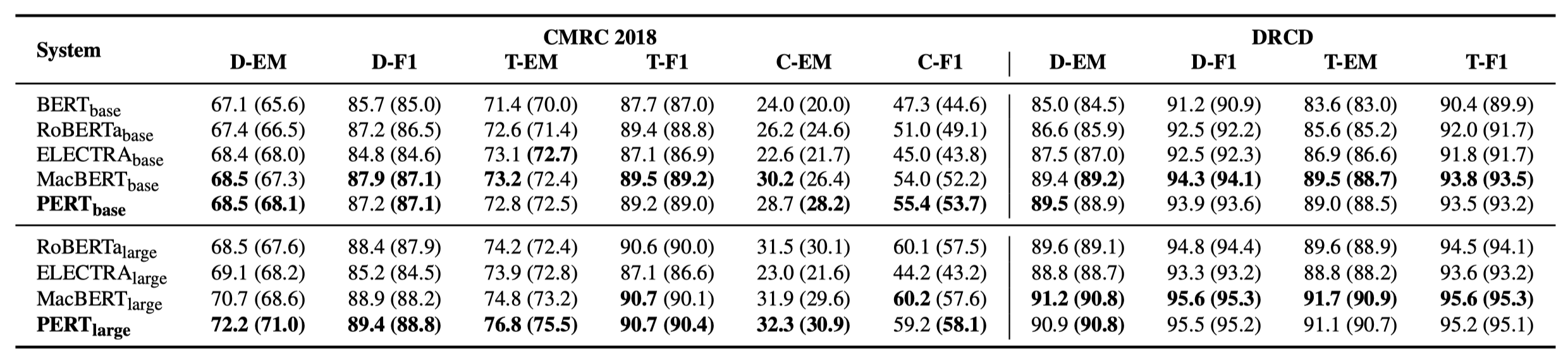
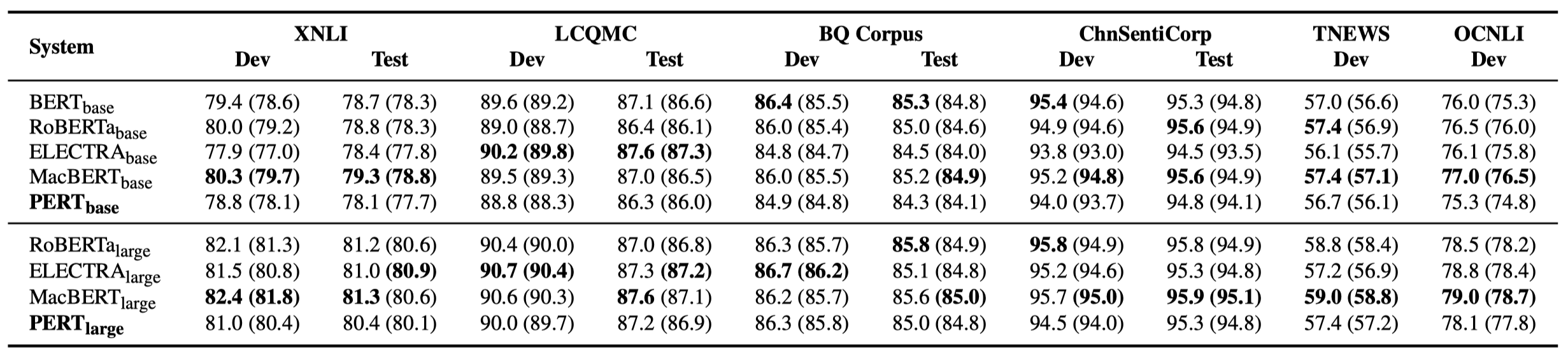
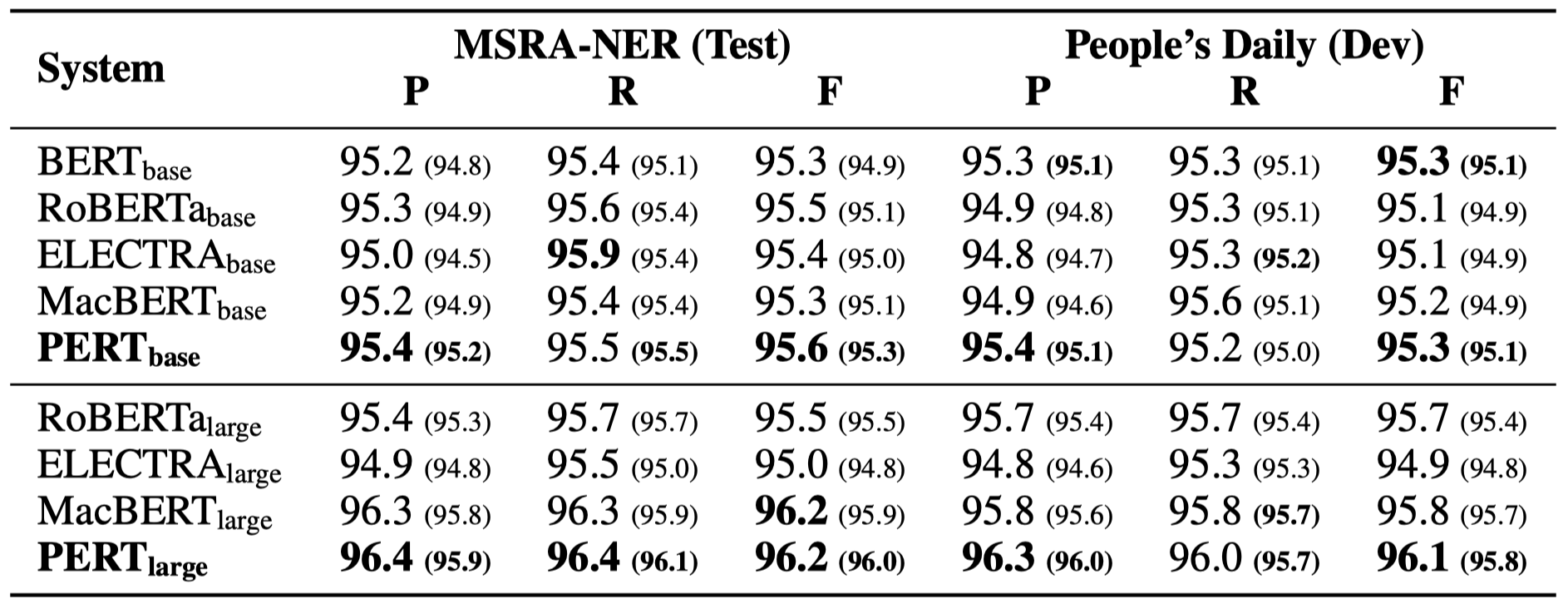
除了上述任務之外,我們還在文本糾錯中的亂序任務上進行了測試,效果如下。

在以下6個任務上進行了效果測試。
Q1: 關於PERT的開源版本權重
A1: 開源版本僅包含Transformer部分的權重,可直接用於下游任務精調,或者其他預訓練模型二次預訓練的初始權重。原始TF版本權重可能包含隨機初始化的MLM權重。這是為了:
Q2: 關於PERT在下游任務上的效果
A2: 初步結論是在閱讀理解、序列標註等任務上效果較好,但在文本分類任務上效果較差。具體效果請各位在各自任務上自行嘗試。具體細節請參考我們的論文:https://arxiv.org/abs/2203.06906
如果本項目中的模型或者相關結論有助於您的研究,請引用以下文章:https://arxiv.org/abs/2203.06906
@article{cui2022pert,
title={PERT: Pre-training BERT with Permuted Language Model},
author={Cui, Yiming and Yang, Ziqing and Liu, Ting},
year={2022},
eprint={2203.06906},
archivePrefix={arXiv},
primaryClass={cs.CL}
}歡迎關注哈工大訊飛聯合實驗室官方微信公眾號,了解最新的技術動態。

如有問題,請在GitHub Issue中提交。


