PERT
1.0.0
Chinois | Anglais

Dans le domaine du traitement du langage naturel, les modèles de langage pré-formés (PLMS) sont devenus une technologie de base très importante. Au cours des deux dernières années, Iflytek Joint Laboratory a publié une variété de ressources de modèle de pré-formation chinoises et d'outils de support connexes. En tant que continuation de travaux connexes, dans ce projet, nous proposons un modèle pré-formé (PERT) basé sur un modèle de langage hors service que l'apprentissage auto-supervisé des informations sémantiques de texte sans introduire la marque de masque [masque]. PERT a atteint des améliorations de performances sur certaines tâches de NLU chinois et anglaises, mais elle a également de mauvais résultats sur certaines tâches. Veuillez l'utiliser le cas échéant. Actuellement, des modèles PERT sont fournis en chinois et en anglais, y compris deux tailles de modèle (base, grande).
Lert chinois | Pert anglais chinois | Macbert chinois | Electra chinois | Xlnet chinois | Chinois Bert | Outil de distillation de connaissances TextBrewer | Modèle de coupe TextPruner
Voir plus de ressources publiées par l'IFL de Harbin Institute of Technology (HFL): https://github.com/ymcui/hfl-anthology
2023/3/28 Open Source Chinese Llama & Alpaca Big Model, qui peut être rapidement déployé et expérimenté sur PC, Voir: https://github.com/ymcui/chinese-llama-alpaca
2022/10/29 Nous proposons un modèle Lert pré-formé qui intègre des informations linguistiques. Voir: https://github.com/ymcui/lert
2022/5/7 MISE À JOUR Une compréhension spéciale de la lecture Pert finement réglée sur plusieurs ensembles de données de compréhension de la lecture et a fourni une démo interactive en ligne étreinte, Vérifiez: Téléchargement du modèle
2022/3/15 Le rapport technique a été publié, veuillez vous référer à: https://arxiv.org/abs/2203.06906
2022/2/24 PERT-base et pert-lancier en chinois et en anglais ont été publiés. Vous pouvez charger directement à l'aide de la structure Bert et effectuer des tâches en aval. Le rapport technique sera publié après l'achèvement et le délai devrait être à la mi-mars. Merci pour votre patience.
2022/2/17 Merci pour votre attention à ce projet. Le modèle devrait être publié la semaine prochaine et le rapport technique sera publié après amélioration.
| chapitre | décrire |
|---|---|
| Introduction | Le principe de base du modèle pré-formé PERT |
| Téléchargement du modèle | Télécharger l'adresse du modèle pré-formé PERT |
| Chargement rapide | Comment utiliser les transformateurs à charger rapidement les modèles |
| Effets du système de base | Effets du système de base sur certaines tâches NLU chinois et anglaises |
| FAQ | FAQ et réponses |
| Citation | Rapport technique de ce projet |
L'apprentissage des modèles pré-entraînés pour la compréhension du langage naturel (NLU) est à peu près divisé en deux catégories: l'utilisation et ne pas utiliser de texte d'entrée avec le marquage du masque [masque].
Algorithme Inspiré: Un certain degré de texte hors de commande n'affecte pas la compréhension. Alors, pouvons-nous apprendre les connaissances sémantiques à partir de textes hors service?
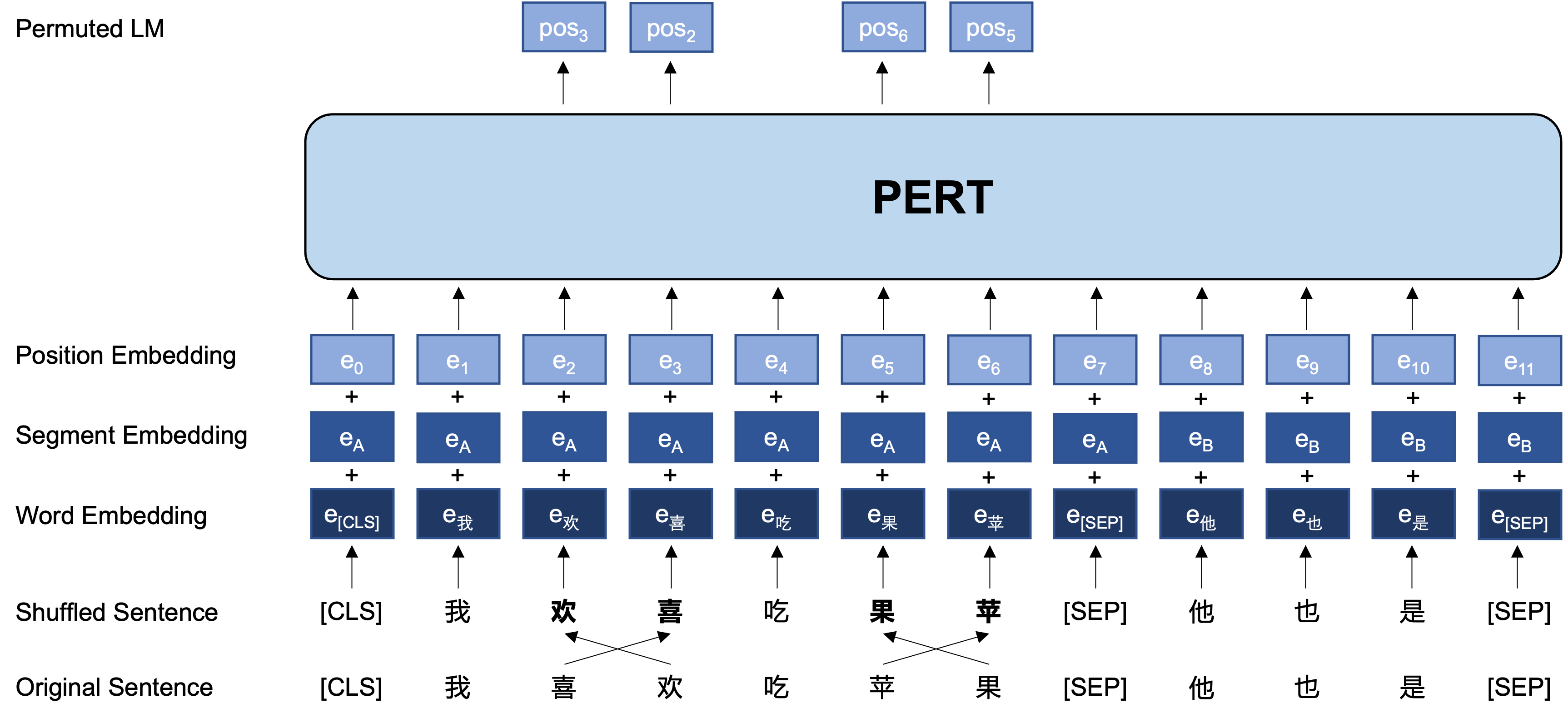
Idée générale: PERT effectue un certain échange d'ordre des mots sur le texte d'entrée d'origine, formant ainsi du texte hors commande (donc aucune balise [masque] supplémentaire n'est introduite). L'objectif d'apprentissage de PERT est de prédire l'emplacement du jeton d'origine, voir l'exemple suivant.
| illustrer | Entrer le texte | Cible de sortie |
|---|---|---|
| Texte original | La recherche montre que l'ordre de cette phrase n'affecte pas la lecture. | - |
| Joueur de bouche participe | La recherche montre que l'ordre de cette phrase n'affecte pas la lecture. | - |
| Bert | La recherche montre que ce [masque] de la phrase ne ressemble pas à la lecture. | Position 7 → Position du téléphone 10 → Position de séquence 13 → Shadow |
| Pertinence | L'ordre de cette phrase n'affecte pas la lecture . | Position 2 (étroite) → Position 3 (tableau) Position 3 (tableau) → Position 2 (étroite) Position 13 (Resonant) → Position 14 (Omballe) Position 14 (film) → Position 13 (Résonant) |
Ce qui suit est la structure de base et le format d'entrée et de sortie du modèle PERT à l'étape de pré-formation (Remarque: Les images du rapport technique ArXIV sont actuellement incorrectes, veuillez vous référer aux images suivantes. La prochaine fois que le papier sera mis à jour, il sera remplacé par l'image correcte.).
Ici, nous fournissons principalement les poids du modèle de TensorFlow Version 1.15. Si vous avez besoin d'une version Pytorch ou Tensorflow2 du modèle, veuillez consulter la section suivante.
La version open source ne contient que les poids de la partie du transformateur, qui peuvent être directement utilisés pour le réglage fin des tâches en aval, ou les poids initiaux de la pré-formation secondaire des autres modèles pré-formés. Pour plus d'informations, voir FAQ.
PERT-large : 24 couches, 1024, 16 têtes, 330m paramètresPERT-base 12 couches, 768, coiffures, 12 têtes, 110 m de paramètres| Abréviation du modèle | Langue | Matériels | Google Download | Téléchargement du disque Baidu |
|---|---|---|---|---|
| Chinois-pert-grand | Chinois | Données EXT [1] | Tensorflow | TensorFlow (mot de passe: E9HS) |
| Bassin chinois | Chinois | Données EXT [1] | Tensorflow | TensorFlow (mot de passe: RCSW) |
| Anglais-PERT-LAGE (Unleased) | Anglais | WikiBooks [2] | Tensorflow | TensorFlow (mot de passe: WXWI) |
| Anglais-PERT-base (Unleased) | Anglais | WikiBooks [2] | Tensorflow | TensorFlow (mot de passe: 8jgq) |
[1] Les données EXT comprennent: Wikipedia chinois, d'autres encyclopédies, des nouvelles, des questions et réponses et d'autres données, avec un nombre total de mots atteignant 5,4B, occupant environ 20 g d'espace disque, le même que Macbert.
[2] Wikipedia + BookCorpus
Prendre la version TensorFlow de Chinese-PERT-base comme exemple, après téléchargement, décompressez le fichier zip à obtenir:
chinese_pert_base_L-12_H-768_A-12.zip
|- pert_model.ckpt # 模型权重
|- pert_model.meta # 模型meta信息
|- pert_model.index # 模型index信息
|- pert_config.json # 模型参数
|- vocab.txt # 词表(与谷歌原版一致)
Parmi eux, bert_config.json et vocab.txt sont exactement les mêmes que BERT-base, Chinese d'origine de Google (la version anglaise est cohérente avec la version Bert-Oclé).
Les modèles TensorFlow (V2) et Pytorch peuvent être téléchargés via la bibliothèque de modèles Transformers.
Méthode de téléchargement: cliquez sur n'importe quel modèle que vous souhaitez télécharger → Sélectionnez l'onglet "Fichiers et versions" → Téléchargez le fichier de modèle correspondant.
| Abréviation du modèle | Taille du fichier du modèle | Adresse de la bibliothèque du modèle Transformers |
|---|---|---|
| Chinois-pert-grand | 1,2 g | https://huggingface.co/hfl/chinese-pert-large |
| Bassin chinois | 0,4 g | https://huggingface.co/hfl/chinese-pert-base |
| Chinois-PERT-LANGE-MRC | 1,2 g | https://huggingface.co/hfl/chinese-pert-large-mrc |
| Chinois-PERT-base-MRC | 0,4 g | https://huggingface.co/hfl/chinese-pert-base-mrc |
| Anglais-pert-grand | 1,2 g | https://huggingface.co/hfl/english-pert-large |
| Bassin anglais | 0,4 g | https://huggingface.co/hfl/english-pert-base |
Étant donné que la partie du corps PERT est toujours une structure Bert, les utilisateurs peuvent facilement appeler le modèle PERT à l'aide de la bibliothèque Transformers.
Remarque: Tous les modèles de ce répertoire sont chargés à l'aide de Bertokezizer et Bertmodel (les modèles MRC utilisent BertForQuestionanswering).
from transformers import BertTokenizer , BertModel
tokenizer = BertTokenizer . from_pretrained ( "MODEL_NAME" )
model = BertModel . from_pretrained ( "MODEL_NAME" ) La liste correspondante de MODEL_NAME est la suivante:
| Nom du modèle | Model_name |
|---|---|
| Chinois-pert-grand | HFL / chinois-pert-gard |
| Bassin chinois | HFL / Chine-Pert-base |
| Chinois-PERT-LANGE-MRC | HFL / Chinese-Pert-Large-MRC |
| Chinois-PERT-base-MRC | HFL / Chinese-Pert-Base-MRC |
| Anglais-pert-grand | HFL / ANGLAIS-PERT-GARD |
| Bassin anglais | HFL / ANGLAIS-PERT-base |
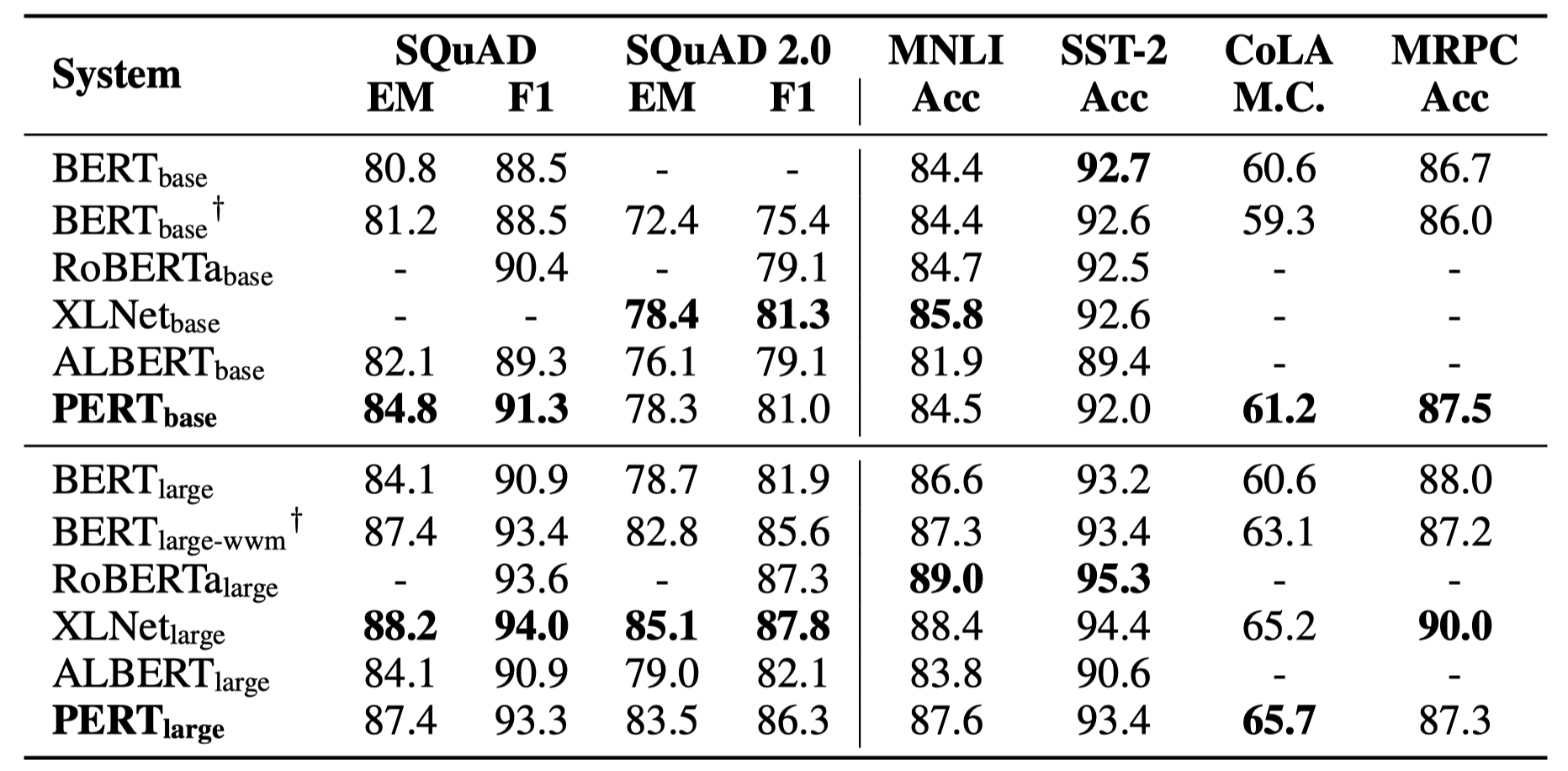
Seuls certains résultats expérimentaux sont répertoriés ci-dessous. Voir l'article pour les résultats et l'analyse détaillés. Dans le tableau des résultats expérimentaux, la valeur maximale en dehors des supports est la valeur moyenne à l'intérieur des supports.
Des tests d'efficacité ont été effectués sur les 10 tâches suivantes.
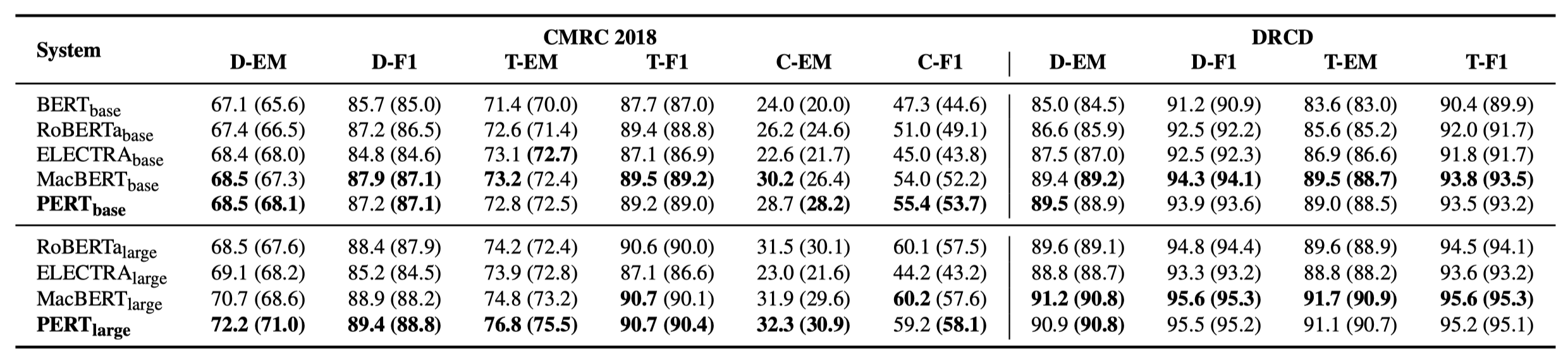
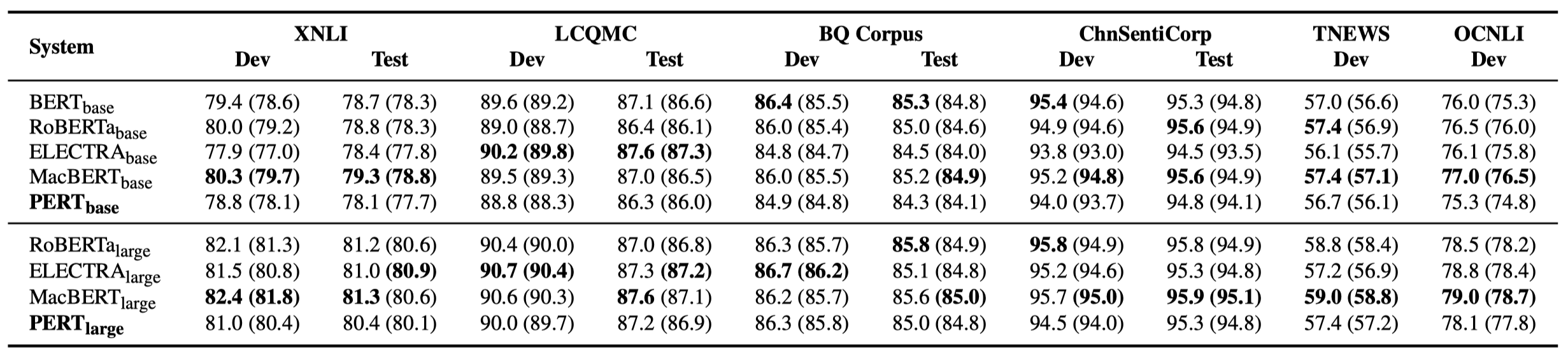
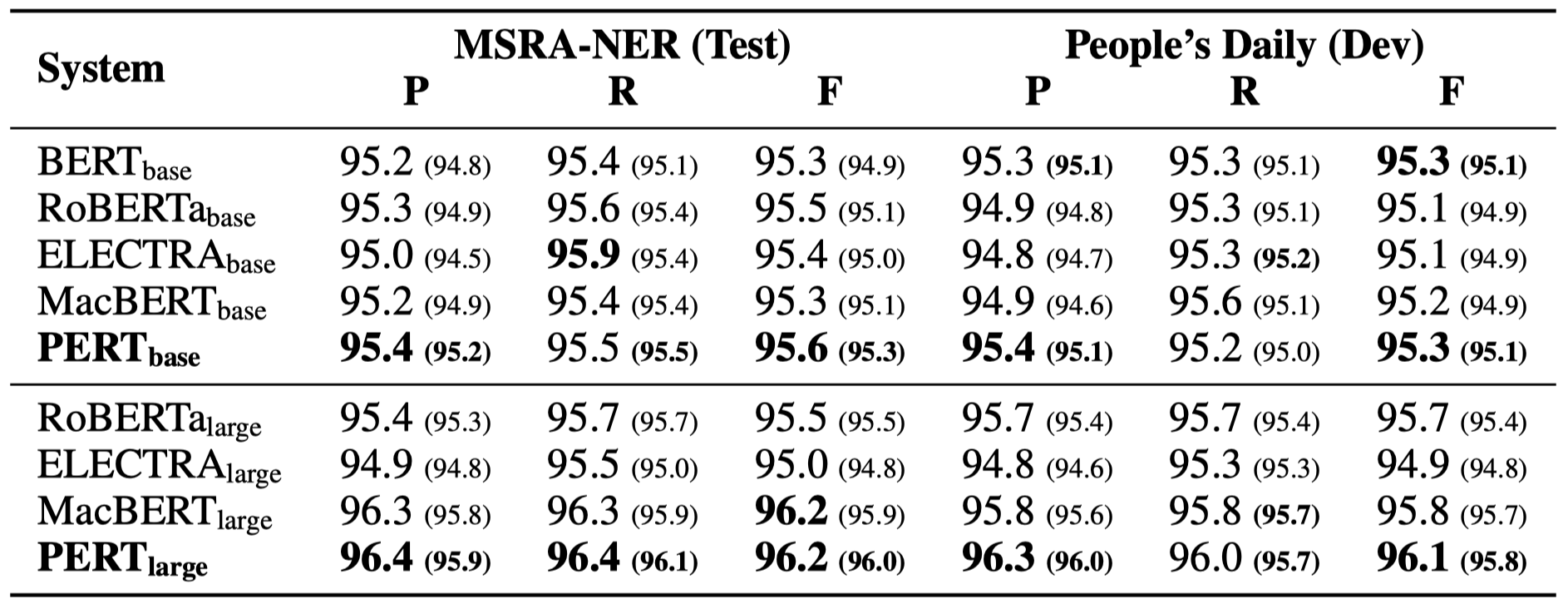
En plus des tâches ci-dessus, nous avons également testé les tâches hors service dans la correction d'erreur de texte, et l'effet est le suivant.

Des tests d'efficacité ont été effectués sur les 6 tâches suivantes.
Q1: À propos de la version open source Poids de PERT
A1: La version open source ne contient que les poids de la partie du transformateur, qui peuvent être directement utilisés pour le réglage des tâches en aval, ou les poids initiaux de la pré-formation secondaire des autres modèles pré-formés. Les poids de version TF d'origine peuvent contenir des poids MLM initialisés au hasard . C'est pour:
Q2: À propos de l'effet de Pert sur les tâches en aval
A2: La conclusion préliminaire est qu'elle a de meilleurs résultats dans des tâches telles que la compréhension de la lecture et l'étiquetage des séquences, mais de mauvais résultats dans les tâches de classification du texte. Veuillez essayer les résultats spécifiques sur vos propres tâches. Pour plus de détails, veuillez consulter notre article: https://arxiv.org/abs/2203.06906
Si les modèles ou les conclusions connexes dans ce projet sont utiles pour vos recherches, veuillez citer l'article suivant: https://arxiv.org/abs/2203.06906
@article{cui2022pert,
title={PERT: Pre-training BERT with Permuted Language Model},
author={Cui, Yiming and Yang, Ziqing and Liu, Ting},
year={2022},
eprint={2203.06906},
archivePrefix={arXiv},
primaryClass={cs.CL}
}Bienvenue à suivre le compte officiel officiel de WECHAT de Iflytek Joint Laboratory pour en savoir plus sur les dernières tendances techniques.

Si vous avez des questions, veuillez la soumettre dans le problème de GitHub.


