PERT
1.0.0
Cina | Bahasa inggris

Di bidang pemrosesan bahasa alami, model bahasa pra-terlatih (PLM) telah menjadi teknologi dasar yang sangat penting. Dalam dua tahun terakhir, Laboratorium Gabungan Iflytek telah merilis berbagai sumber daya model pra-pelatihan Cina dan alat pendukung terkait. Sebagai kelanjutan dari pekerjaan terkait, dalam proyek ini, kami mengusulkan model pra-terlatih (PERT) berdasarkan model bahasa yang tidak sesuai pesanan yang pembelajaran informasi semantik teks sendiri tanpa memperkenalkan Mark Mark [Mask]. PERT telah mencapai peningkatan kinerja pada beberapa tugas NLU Cina dan Inggris, tetapi juga memiliki hasil yang buruk pada beberapa tugas. Harap gunakan yang sesuai. Saat ini, model PERT disediakan dalam bahasa Cina dan Inggris, termasuk dua ukuran model (base, besar).
Lert Cina | Bahasa Inggris Tiongkok PERT | Macbert Cina | China Electra | Xlnet Cina | Bert Cina | Alat Distilasi Pengetahuan TextBrewer | Model Cutting Tool TextPruner
Lihat lebih banyak sumber daya yang dirilis oleh IFL of Harbin Institute of Technology (HFL): https://github.com/ymcui/hfl-anthology
2023/3/28 Open Source Chinese Llama & Alpaca Big Model, yang dapat dengan cepat digunakan dan dialami di PC, Lihat: https://github.com/ymcui/chinese-llama-alpaca
2022/10/29 Kami mengusulkan model pra-terlatih yang mengintegrasikan informasi linguistik. Lihat: https://github.com/ymcui/lert
2022/5/7 Diperbarui Pemahaman Bacaan Khusus PERT TETAP TERJUAL DI Ganda Dataset Pemahaman Bacaan, dan memberikan demo interaktif Online HuggingFace, Periksa: Model Download
2022/3/15 Laporan teknis telah dirilis, silakan merujuk ke: https://arxiv.org/abs/2203.06906
2022/2/24 PERT-BASE DAN PER-Large dalam bahasa Cina dan Inggris telah dirilis. Anda dapat secara langsung memuat menggunakan struktur Bert dan melakukan fine-tuning tugas hilir. Laporan teknis akan dikeluarkan setelah selesai, dan waktunya diharapkan pada pertengahan Maret. Terima kasih atas kesabaran Anda.
2022/2/17 Terima kasih atas perhatian Anda pada proyek ini. Model ini diharapkan akan dikeluarkan minggu depan, dan laporan teknis akan dikeluarkan setelah perbaikan.
| bab | menggambarkan |
|---|---|
| Perkenalan | Prinsip dasar model pra-terlatih pert |
| Download model | Unduh alamat model pra-terlatih pert |
| Pemuatan cepat | Cara menggunakan transformer dengan cepat memuat model |
| Efek sistem dasar | Efek sistem dasar pada beberapa tugas NLU Cina dan Inggris |
| FAQ | FAQ dan Jawaban |
| Mengutip | Laporan Teknis Proyek ini |
Pembelajaran model pretrained untuk pemahaman bahasa alami (NLU) secara kasar dibagi menjadi dua kategori: menggunakan dan tidak menggunakan teks input dengan penandaan mask [topeng].
Algoritma yang terinspirasi: Tingkat teks yang tidak sesuai pesanan tidak mempengaruhi pemahaman. Jadi bisakah kita belajar pengetahuan semantik dari teks yang tidak sesuai pesanan?
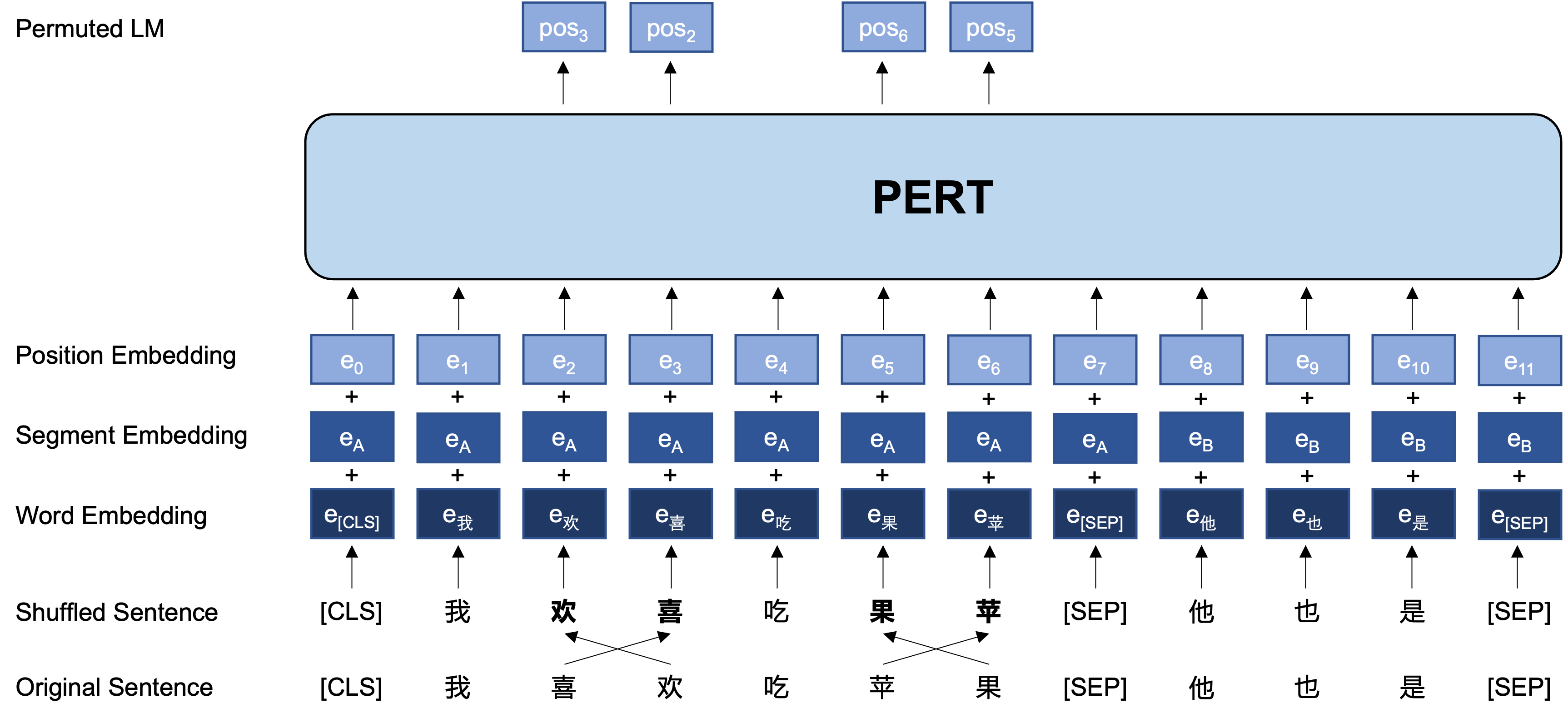
Gagasan Umum: PERT melakukan pertukaran urutan kata tertentu pada teks input asli, sehingga membentuk teks out-of-order (jadi tidak ada tag [mask] tambahan yang diperkenalkan). Tujuan pembelajaran PERT adalah untuk memprediksi lokasi token asli, lihat contoh berikut.
| menjelaskan | Masukkan teks | Target output |
|---|---|---|
| Teks asli | Penelitian menunjukkan bahwa urutan kalimat ini tidak mempengaruhi membaca. | - |
| Kata kata participle | Penelitian menunjukkan bahwa urutan kalimat ini tidak mempengaruhi membaca. | - |
| Bert | Penelitian menunjukkan bahwa kalimat [topeng] ini tidak terdengar seperti membaca. | Posisi 7 → Posisi Telepon 10 → Posisi Urutan 13 → Bayangan |
| NAKAL | Urutan kalimat ini tidak memengaruhi pembacaan . | Posisi 2 (sempit) → Posisi 3 (tabel) Posisi 3 (Tabel) → Posisi 2 (Sempit) Posisi 13 (resonansi) → Posisi 14 (bayangan) Posisi 14 (film) → Posisi 13 (resonansi) |
Berikut ini adalah struktur dasar dan format input dan output dari model PERT pada tahap pra-pelatihan (Catatan: Gambar dalam laporan teknis ARXIV saat ini salah, silakan merujuk ke gambar-gambar berikut. Lain kali kertas diperbarui, itu akan diganti dengan gambar yang benar.).
Di sini kami terutama memberikan bobot model TensorFlow versi 1.15. Jika Anda memerlukan versi model Pytorch atau TensorFlow2, silakan lihat bagian berikutnya.
Versi open source hanya berisi bobot bagian transformator, yang dapat langsung digunakan untuk fine-tuning tugas hilir, atau bobot awal pra-pelatihan sekunder model pra-terlatih lainnya. Untuk informasi lebih lanjut, lihat FAQ.
PERT-large : 24-lapis, 1024-tersembunyi, 16-heads, parameter 330mPERT-base 12-LAYER, 768-HIDDEN, 12-HEADS, PARAMETER 110M| Singkatan model | Bahasa | Bahan | Download Google | Baidu Disk Download |
|---|---|---|---|---|
| Tiongkok-besar-besar | Cina | Data ekst [1] | Tensorflow | TensorFlow (Kata Sandi: E9HS) |
| Basis Cina-Basis | Cina | Data ekst [1] | Tensorflow | TensorFlow (Kata Sandi: RCSW) |
| Bahasa Inggris-Pert-Large (Uncased) | Bahasa inggris | Wikibooks [2] | Tensorflow | TensorFlow (Kata Sandi: WXWI) |
| Basis Inggris-Base (Uncased) | Bahasa inggris | Wikibooks [2] | Tensorflow | TensorFlow (Kata Sandi: 8JGQ) |
[1] Data EXT meliputi: Wikipedia Cina, ensiklopedi lain, berita, tanya jawab dan data lainnya, dengan jumlah total kata yang mencapai 5.4b, menempati sekitar 20g ruang disk, sama dengan Macbert.
[2] Wikipedia + BookCorpus
Mengambil versi TensorFlow dari Chinese-PERT-base sebagai contoh, setelah mengunduh, mendekompres file zip untuk mendapatkan:
chinese_pert_base_L-12_H-768_A-12.zip
|- pert_model.ckpt # 模型权重
|- pert_model.meta # 模型meta信息
|- pert_model.index # 模型index信息
|- pert_config.json # 模型参数
|- vocab.txt # 词表(与谷歌原版一致)
Di antara mereka, bert_config.json dan vocab.txt persis sama dengan BERT-base, Chinese (versi bahasa Inggris konsisten dengan versi Bert-tidak).
Model TensorFlow (V2) dan Pytorch Version dapat diunduh melalui Perpustakaan Model Transformers.
Metode Unduh: Klik model apa pun yang ingin Anda unduh → Pilih tab "File dan Versi" → Unduh file model yang sesuai.
| Singkatan model | Ukuran file model | Alamat Perpustakaan Model Transformers |
|---|---|---|
| Tiongkok-besar-besar | 1.2g | https://huggingface.co/hfl/chinese-pert-barge |
| Basis Cina-Basis | 0.4g | https://huggingface.co/hfl/chinese-pert-base |
| China-PERT-LARGE-MRC | 1.2g | https://huggingface.co/hfl/chinese-pert-large-mrc |
| China-PERT-BASE-MRC | 0.4g | https://huggingface.co/hfl/chinese-pert-base-mrc |
| Bahasa Inggris-Pert-Large | 1.2g | https://huggingface.co/hfl/English-pert-barge |
| Basis Bahasa Inggris-Base | 0.4g | https://huggingface.co/hfl/english-pert-base |
Karena bagian tubuh PERT masih merupakan struktur Bert, pengguna dapat dengan mudah memanggil model PERT menggunakan pustaka Transformers.
Catatan: Semua model dalam direktori ini dimuat menggunakan Berttokenizer dan Bertmodel (model MRC menggunakan BertForQuestionAnswering).
from transformers import BertTokenizer , BertModel
tokenizer = BertTokenizer . from_pretrained ( "MODEL_NAME" )
model = BertModel . from_pretrained ( "MODEL_NAME" ) Daftar MODEL_NAME yang sesuai adalah sebagai berikut:
| Nama model | Model_name |
|---|---|
| Tiongkok-besar-besar | HFL/China-Pert-Large |
| Basis Cina-Basis | HFL/China-Pert-Base |
| China-PERT-LARGE-MRC | HFL/Cina-Pert-Large-Mrc |
| China-PERT-BASE-MRC | HFL/China-Pert-Base-MRC |
| Bahasa Inggris-Pert-Large | HFL/Bahasa Inggris-Pert-Large |
| Basis Bahasa Inggris-Base | HFL/BAHASA INGGRIS-PERT |
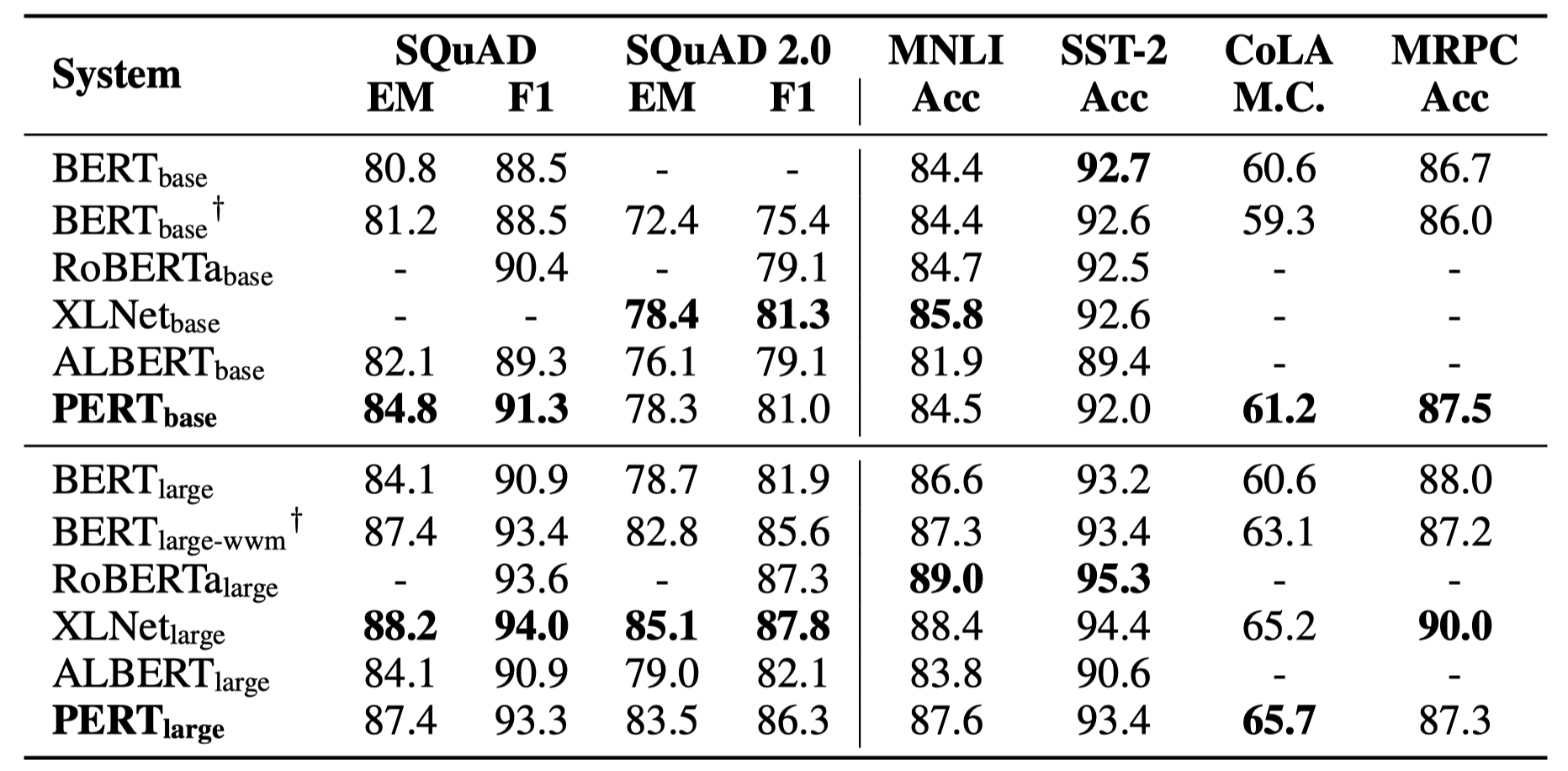
Hanya beberapa hasil eksperimen yang tercantum di bawah ini. Lihat makalah untuk hasil dan analisis yang terperinci. Dalam tabel hasil percobaan, nilai maksimum di luar kurung adalah nilai rata -rata di dalam kurung.
Tes efektivitas dilakukan pada 10 tugas berikut.
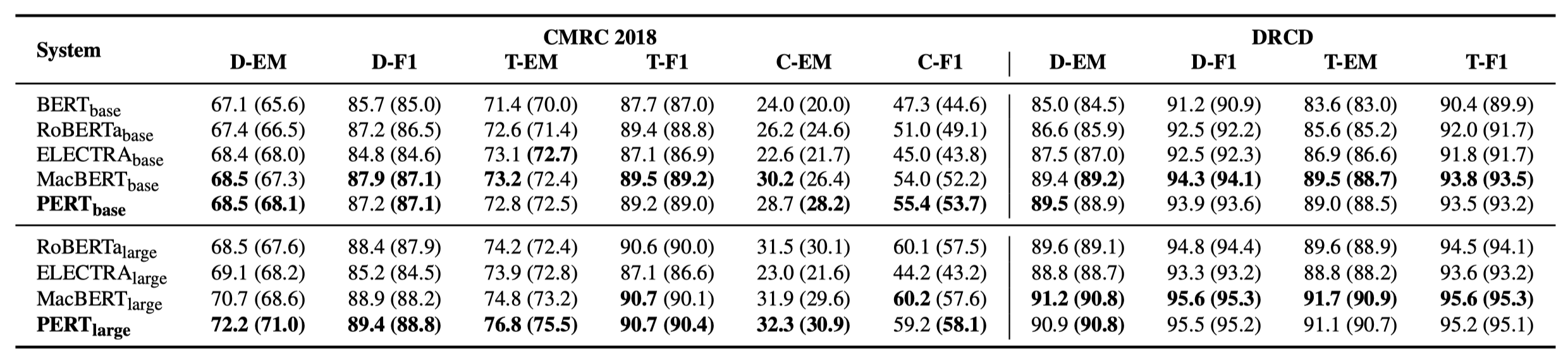
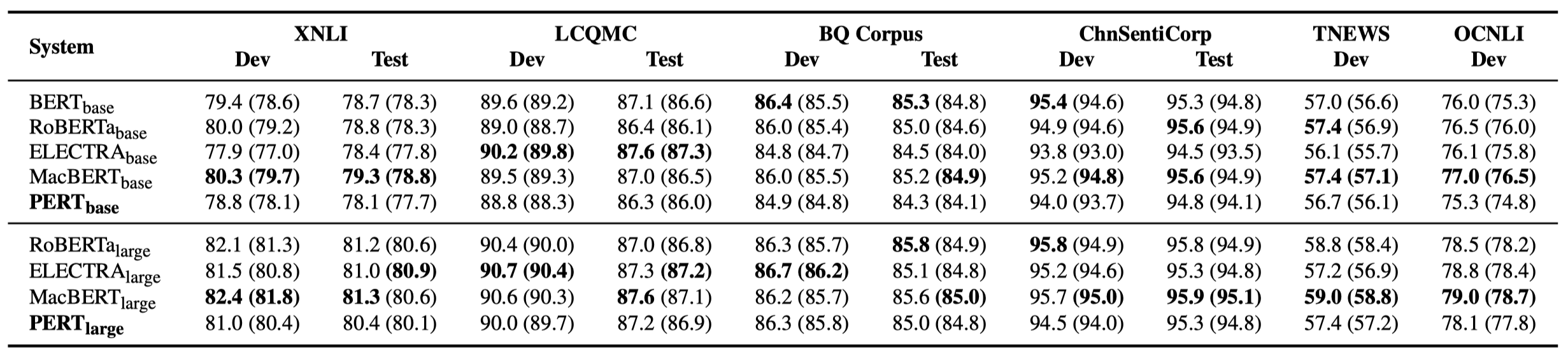
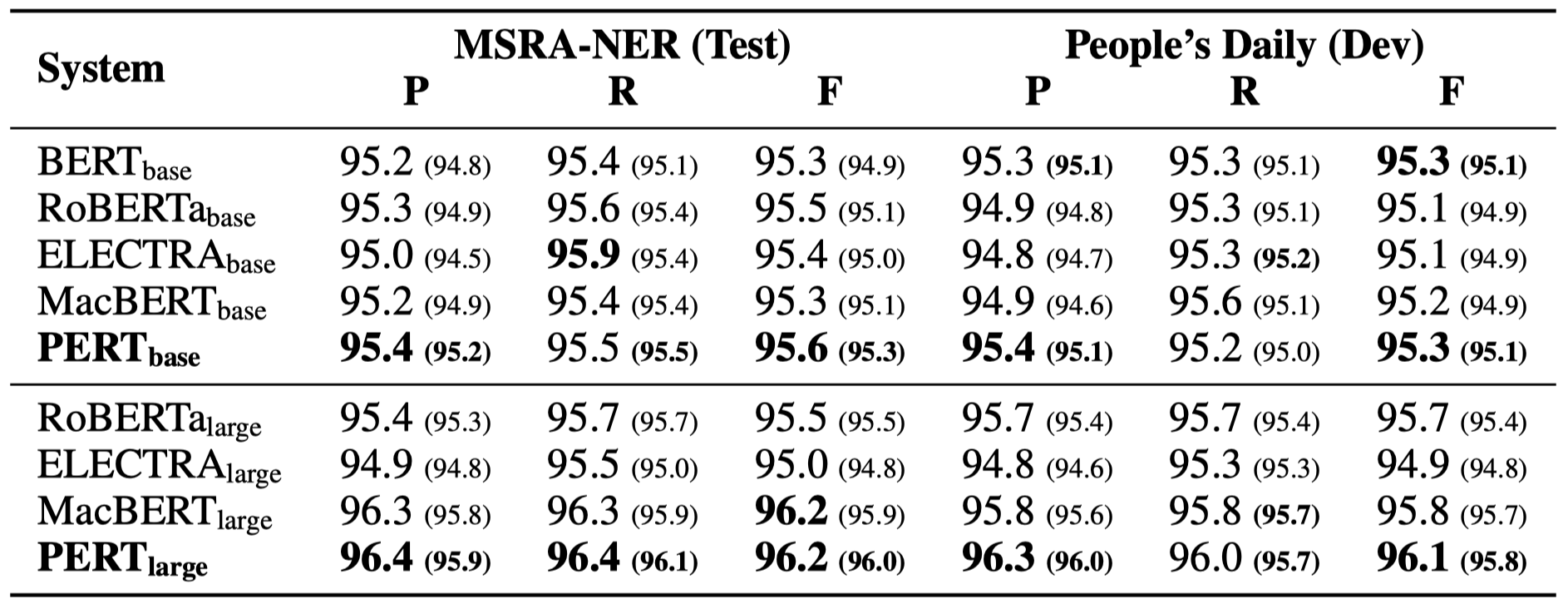
Selain tugas-tugas di atas, kami juga menguji tugas yang tidak sesuai pesanan dalam koreksi kesalahan teks, dan efeknya adalah sebagai berikut.

Tes efektivitas dilakukan pada 6 tugas berikut.
T1: Tentang Versi Open Source Bobot PERT
A1: Versi open source hanya berisi bobot bagian transformator, yang dapat langsung digunakan untuk fine-tuning tugas hilir, atau bobot awal dari pelatihan pra-pelatihan sekunder dari model pra-terlatih lainnya. Bobot versi TF asli dapat berisi bobot MLM yang diinisialisasi secara acak . Ini untuk:
T2: Tentang efek pert pada tugas hilir
A2: Kesimpulan awal adalah bahwa ia memiliki hasil yang lebih baik dalam tugas -tugas seperti pemahaman membaca dan pelabelan urutan, tetapi hasil yang buruk dalam tugas klasifikasi teks. Silakan coba hasil spesifik pada tugas Anda sendiri. Untuk detailnya, silakan merujuk ke makalah kami: https://arxiv.org/abs/2203.06906
Jika model atau kesimpulan terkait dalam proyek ini bermanfaat untuk penelitian Anda, silakan kutip artikel berikut: https://arxiv.org/abs/2203.06906
@article{cui2022pert,
title={PERT: Pre-training BERT with Permuted Language Model},
author={Cui, Yiming and Yang, Ziqing and Liu, Ting},
year={2022},
eprint={2203.06906},
archivePrefix={arXiv},
primaryClass={cs.CL}
}Selamat datang untuk mengikuti akun resmi WeChat resmi Laboratorium Gabungan IFLYTEK untuk mempelajari tentang tren teknis terbaru.

Jika Anda memiliki pertanyaan, silakan kirimkan dalam masalah GitHub.


