PERT
1.0.0
จีน | ภาษาอังกฤษ

ในด้านการประมวลผลภาษาธรรมชาติแบบจำลองภาษาที่ผ่านการฝึกอบรมมาก่อน (PLMS) ได้กลายเป็นเทคโนโลยีพื้นฐานที่สำคัญมาก ในช่วงสองปีที่ผ่านมา Iflytek Joint Laboratory ได้เปิดตัวทรัพยากรรูปแบบการฝึกอบรมก่อนการฝึกอบรมของจีนและเครื่องมือสนับสนุนที่เกี่ยวข้อง ในฐานะที่เป็นความต่อเนื่องของงานที่เกี่ยวข้องในโครงการนี้เราเสนอรูปแบบที่ผ่านการฝึกอบรมมาก่อน (PERT) ตามรูปแบบภาษาที่ไม่ได้สั่งซื้อที่เรียนรู้ด้วยตนเองเกี่ยวกับข้อมูลความหมายของข้อความโดยไม่ต้องแนะนำ MASK Mark [MASK] PERT ได้รับการปรับปรุงประสิทธิภาพการทำงานในงานภาษาจีนและภาษาอังกฤษ NLU บางอย่าง แต่ก็มีผลลัพธ์ที่ไม่ดีในบางงาน โปรดใช้ตามความเหมาะสม ปัจจุบันโมเดล PERT มีให้เป็นภาษาจีนและภาษาอังกฤษรวมถึงสองรุ่น (ฐานขนาดใหญ่)
Lert จีน ภาษาอังกฤษภาษาอังกฤษ Pert | Macbert จีน Electra จีน XLNET จีน | เบิร์ตจีน เครื่องมือกลั่นความรู้ TextBrewer | เครื่องมือตัดแบบจำลอง TextPruner
ดูแหล่งข้อมูลเพิ่มเติมที่เผยแพร่โดย IFL of Harbin Institute of Technology (HFL): https://github.com/ymcui/hfl-anthology
2023/3/28 โอเพ่นซอร์ส Llama & Alpaca Big Model ซึ่งสามารถนำไปใช้อย่างรวดเร็วและมีประสบการณ์บนพีซีดู: https://github.com/ymcui/chinese-llama-alpaca
2022/10/29 เราเสนอรูปแบบที่ได้รับการฝึกอบรมล่วงหน้าซึ่งรวมข้อมูลภาษาศาสตร์ ดู: https://github.com/ymcui/lert
2022/5/7 อัปเดตความเข้าใจในการอ่านพิเศษ PERT ปรับแต่งอย่างประณีตในชุดข้อมูลความเข้าใจในการอ่านหลายชุดและให้การสาธิตแบบอินเทอร์แอคทีฟออนไลน์ของ HuggingFace ตรวจสอบ: ดาวน์โหลดรุ่น
2022/3/15 รายงานทางเทคนิคได้รับการเผยแพร่โปรดดูที่: https://arxiv.org/abs/2203.06906
2022/2/24 Pert-Base และ Pert-large ในภาษาจีนและภาษาอังกฤษได้รับการปล่อยตัว คุณสามารถโหลดได้โดยตรงโดยใช้โครงสร้าง Bert และดำเนินการปรับแต่งอย่างละเอียด รายงานทางเทคนิคจะออกหลังจากเสร็จสิ้นและเวลาคาดว่าจะอยู่ในช่วงกลางเดือนมีนาคม ขอบคุณสำหรับความอดทน
2022/2/17 ขอบคุณที่ให้ความสนใจกับโครงการนี้ รูปแบบคาดว่าจะออกในสัปดาห์หน้าและรายงานทางเทคนิคจะออกหลังจากการปรับปรุง
| บท | อธิบาย |
|---|---|
| การแนะนำ | หลักการพื้นฐานของแบบจำลองที่ได้รับการฝึกฝนมาก่อน |
| ดาวน์โหลดรุ่น | ดาวน์โหลดที่อยู่ของ PERT Pre-Traned Model |
| การโหลดอย่างรวดเร็ว | วิธีใช้หม้อแปลงโหลดแบบจำลองอย่างรวดเร็ว |
| เอฟเฟกต์ระบบพื้นฐาน | ผลกระทบของระบบพื้นฐานต่องาน NLU ภาษาจีนและภาษาอังกฤษบางส่วน |
| คำถามที่พบบ่อย | คำถามที่พบบ่อยและคำตอบ |
| อ้าง | รายงานทางเทคนิคของโครงการนี้ |
การเรียนรู้แบบจำลองที่ผ่านการฝึกอบรมสำหรับการทำความเข้าใจภาษาธรรมชาติ (NLU) แบ่งออกเป็นสองประเภท: การใช้และไม่ใช้ข้อความอินพุตกับการทำเครื่องหมายหน้ากาก [MASK]
อัลกอริทึมที่ได้รับแรงบันดาลใจ: ข้อความที่ไม่ได้สั่งซื้อในระดับหนึ่งไม่ส่งผลกระทบต่อความเข้าใจ ดังนั้นเราสามารถเรียนรู้ความรู้เชิงความหมายจากข้อความที่ไม่ได้สั่งซื้อได้หรือไม่?
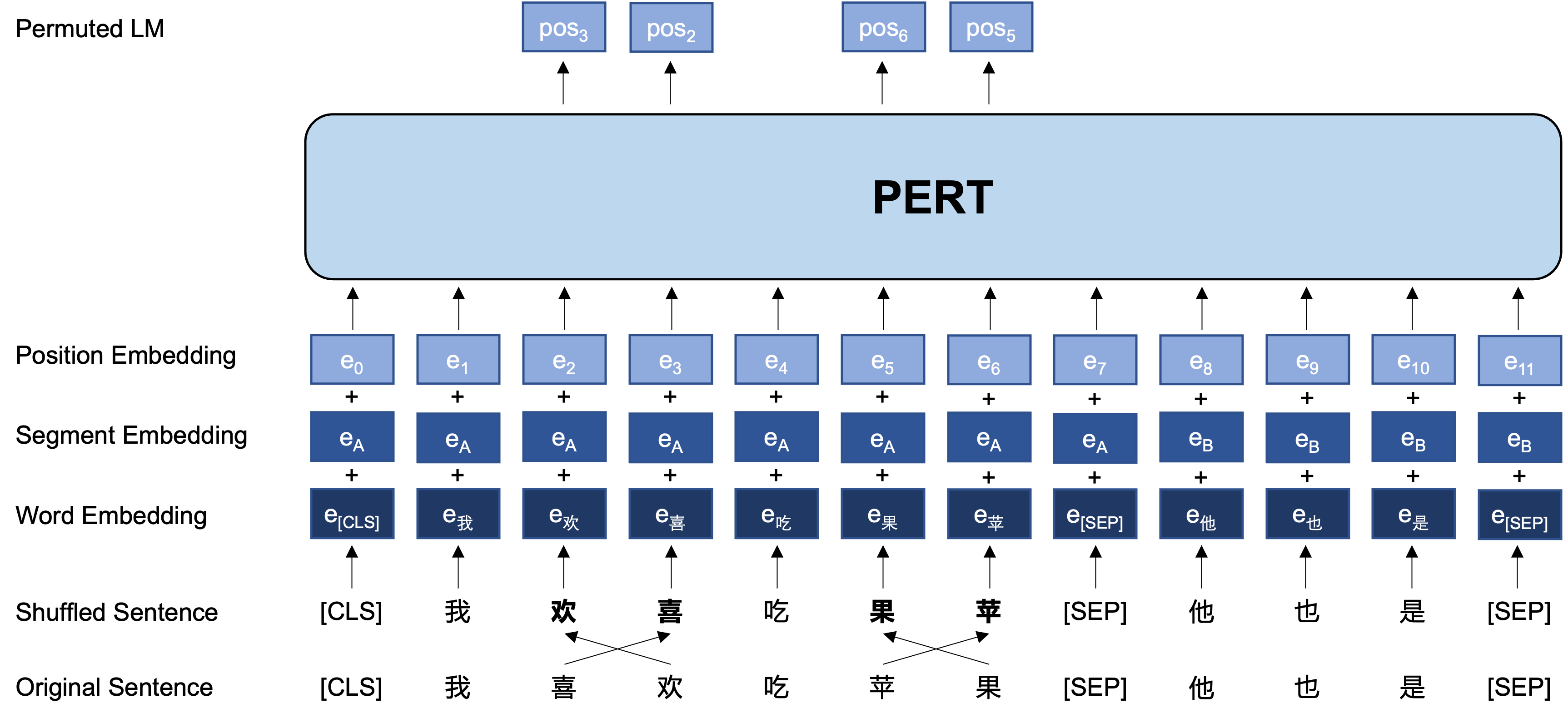
แนวคิดทั่วไป: PERT ดำเนินการแลกเปลี่ยนคำสั่งคำที่แน่นอนบนข้อความอินพุตต้นฉบับดังนั้นจึงสร้างข้อความที่ไม่ได้สั่งซื้อ (ดังนั้นจึงไม่มีการแนะนำแท็ก [MASK] เพิ่มเติม) เป้าหมายการเรียนรู้ของ PERT คือการทำนายที่ตั้งของโทเค็นดั้งเดิมดูตัวอย่างต่อไปนี้
| อธิบาย | ป้อนข้อความ | เป้าหมายเอาต์พุต |
|---|---|---|
| ข้อความต้นฉบับ | การวิจัยแสดงให้เห็นว่าคำสั่งของประโยคนี้ไม่ส่งผลกระทบต่อการอ่าน | - |
| คำศัพท์คำนาม | การวิจัยแสดงให้เห็นว่าคำสั่งของประโยคนี้ไม่ส่งผลกระทบต่อการอ่าน | - |
| เบิร์ต | การวิจัยแสดงให้เห็นว่าประโยคนี้ [หน้ากาก] ไม่ เหมือน การอ่าน | ตำแหน่ง 7 →ตำแหน่งโทรศัพท์ 10 →ตำแหน่งลำดับ 13 →เงา |
| ฮึกเหิม | คำสั่งของ ประโยค นี้ ไม่ส่งผลกระทบต่อ การ อ่าน | ตำแหน่ง 2 (แคบ) →ตำแหน่ง 3 (ตาราง) ตำแหน่ง 3 (ตาราง) →ตำแหน่ง 2 (แคบ) ตำแหน่งที่ 13 (เรโซแนนท์) →ตำแหน่ง 14 (เงา) ตำแหน่ง 14 (ภาพยนตร์) →ตำแหน่ง 13 (เรโซแนนท์) |
ต่อไปนี้เป็นโครงสร้างพื้นฐานและรูปแบบอินพุตและเอาต์พุตของโมเดล PERT ในขั้นตอนการฝึกอบรมก่อน (หมายเหตุ: รูปภาพในรายงานทางเทคนิคของ ArxIV ไม่ถูกต้องในขณะนี้โปรดดูรูปภาพต่อไปนี้ในครั้งต่อไปที่กระดาษได้รับการอัปเดตมันจะถูกแทนที่ด้วยภาพที่ถูกต้อง)
ที่นี่ส่วนใหญ่เราให้น้ำหนักรุ่นของ TensorFlow เวอร์ชัน 1.15 หากคุณต้องการรุ่น pytorch หรือ tensorflow2 ของรุ่นโปรดดูส่วนถัดไป
เวอร์ชันโอเพ่นซอร์สมีเพียงน้ำหนักของส่วนหม้อแปลงซึ่งสามารถใช้โดยตรงสำหรับการปรับแต่งงานดาวน์สตรีมหรือน้ำหนักเริ่มต้นของการฝึกอบรมก่อนการฝึกอบรมก่อนอื่น สำหรับข้อมูลเพิ่มเติมดูคำถามที่พบบ่อย
PERT-large : 24 ชั้น, 1024 ซ่อน, 16 หัว, พารามิเตอร์ 330mPERT-base 12-layer, 768 ซ่อน, 12 หัว, พารามิเตอร์ 110m| ตัวย่อแบบจำลอง | ภาษา | วัสดุ | ดาวน์โหลด Google | ดาวน์โหลดดิสก์ Baidu |
|---|---|---|---|---|
| จีนใหญ่ | ชาวจีน | ข้อมูล ext [1] | เทนเซอร์โฟลว์ | tensorflow (รหัสผ่าน: E9HS) |
| จีน-เบส | ชาวจีน | ข้อมูล ext [1] | เทนเซอร์โฟลว์ | tensorflow (รหัสผ่าน: RCSW) |
| English-Pert-Large (uncased) | ภาษาอังกฤษ | Wikibooks [2] | เทนเซอร์โฟลว์ | tensorflow (รหัสผ่าน: WXWI) |
| English-Pert-Base (uncased) | ภาษาอังกฤษ | Wikibooks [2] | เทนเซอร์โฟลว์ | tensorflow (รหัสผ่าน: 8jgq) |
[1] ข้อมูล EXT รวมถึง: Wikipedia จีนสารานุกรมอื่น ๆ ข่าวคำถามและคำตอบและข้อมูลอื่น ๆ ที่มีจำนวนคำทั้งหมดถึง 5.4B ครอบครองพื้นที่ดิสก์ประมาณ 20 กรัมเหมือนกับ Macbert
[2] Wikipedia + Bookcorpus
การใช้ตัวอย่างของ Tensorflow ของ Chinese-PERT-base เป็นตัวอย่างหลังจากดาวน์โหลดแล้วจะคลายไฟล์ ZIP เพื่อรับ:
chinese_pert_base_L-12_H-768_A-12.zip
|- pert_model.ckpt # 模型权重
|- pert_model.meta # 模型meta信息
|- pert_model.index # 模型index信息
|- pert_config.json # 模型参数
|- vocab.txt # 词表(与谷歌原版一致)
ในหมู่พวกเขา bert_config.json และ vocab.txt นั้นเหมือนกับ BERT-base, Chinese (เวอร์ชันภาษาอังกฤษสอดคล้องกับเวอร์ชัน Bert-uncased)
รุ่น TensorFlow (V2) และรุ่น Pytorch สามารถดาวน์โหลดได้ผ่านห้องสมุดโมเดล Transformers
วิธีการดาวน์โหลด: คลิกรุ่นใด ๆ ที่คุณต้องการดาวน์โหลด→เลือกแท็บ "ไฟล์และเวอร์ชัน" →ดาวน์โหลดไฟล์รุ่นที่เกี่ยวข้อง
| ตัวย่อแบบจำลอง | ขนาดไฟล์รุ่น | ที่อยู่ห้องสมุดโมเดล Transformers |
|---|---|---|
| จีนใหญ่ | 1.2 กรัม | https://huggingface.co/hfl/chinese-pert-large |
| จีน-เบส | 0.4g | https://huggingface.co/hfl/chinese-pert-base |
| จีนขนาดใหญ่ | 1.2 กรัม | https://huggingface.co/hfl/chinese-pert-large-mrc |
| Chinese-Pert-Base-MRC | 0.4g | https://huggingface.co/hfl/chinese-pert-base-mrc |
| ภาษาอังกฤษขนาดใหญ่ | 1.2 กรัม | https://huggingface.co/hfl/english-pert-large |
| ภาษาอังกฤษ-pert-base | 0.4g | https://huggingface.co/hfl/english-pert-base |
เนื่องจากส่วนของร่างกาย PERT ยังคงเป็นโครงสร้างเบิร์ตผู้ใช้จึงสามารถเรียกโมเดล PERT ได้อย่างง่ายดายโดยใช้ไลบรารี Transformers
หมายเหตุ: ทุกรุ่นในไดเรกทอรีนี้จะถูกโหลดโดยใช้ berttokenizer และ bertmodel (รุ่น MRC ใช้ BertforQuestionanswering)
from transformers import BertTokenizer , BertModel
tokenizer = BertTokenizer . from_pretrained ( "MODEL_NAME" )
model = BertModel . from_pretrained ( "MODEL_NAME" ) รายการที่สอดคล้องกันของ MODEL_NAME มีดังนี้:
| ชื่อนางแบบ | model_name |
|---|---|
| จีนใหญ่ | HFL/chinese-pert-large |
| จีน-เบส | HFL/Chinese-Pert-base |
| จีนขนาดใหญ่ | HFL/Chinese-Pert-Large-MRC |
| Chinese-Pert-Base-MRC | HFL/Chinese-Pert-Base-MRC |
| ภาษาอังกฤษขนาดใหญ่ | HFL/English-Pert-Large |
| ภาษาอังกฤษ-pert-base | HFL/English-Pert-base |
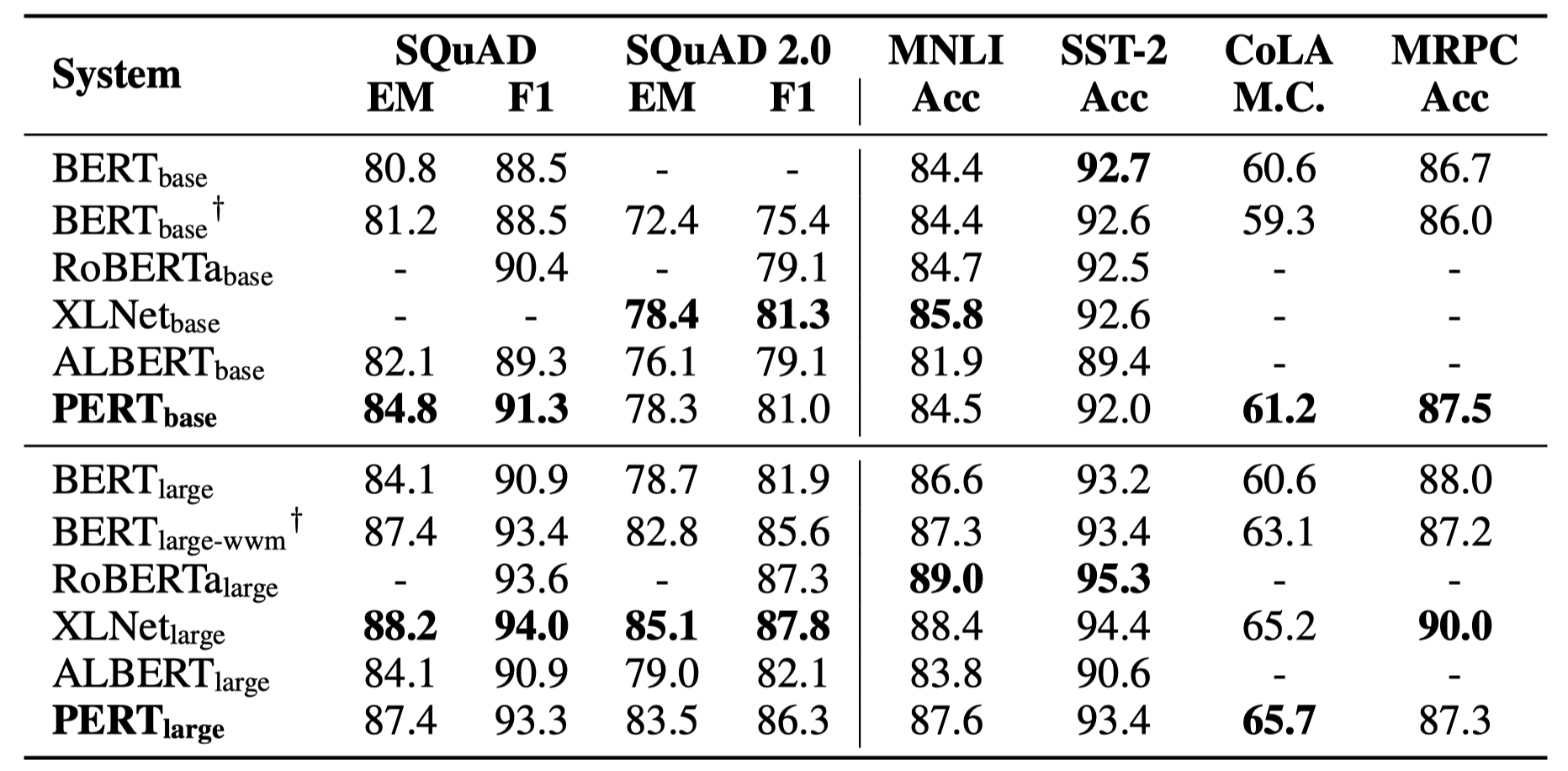
มีเพียงผลการทดลองบางอย่างเท่านั้นที่แสดงอยู่ด้านล่าง ดูกระดาษเพื่อดูรายละเอียดและการวิเคราะห์ ในตารางผลการทดลองค่าสูงสุดที่อยู่นอกวงเล็บคือค่าเฉลี่ยภายในวงเล็บ
การทดสอบประสิทธิภาพได้ดำเนินการใน 10 งานต่อไปนี้
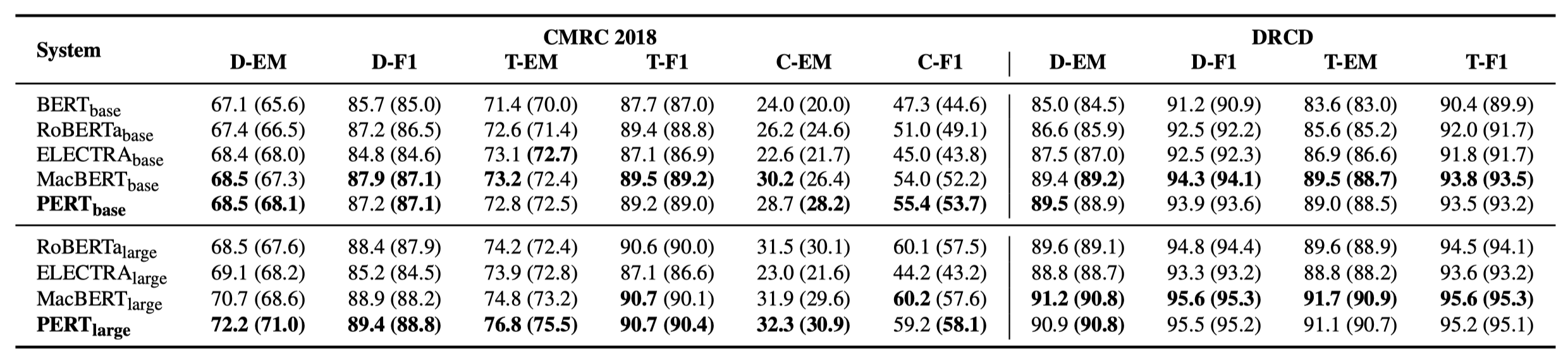
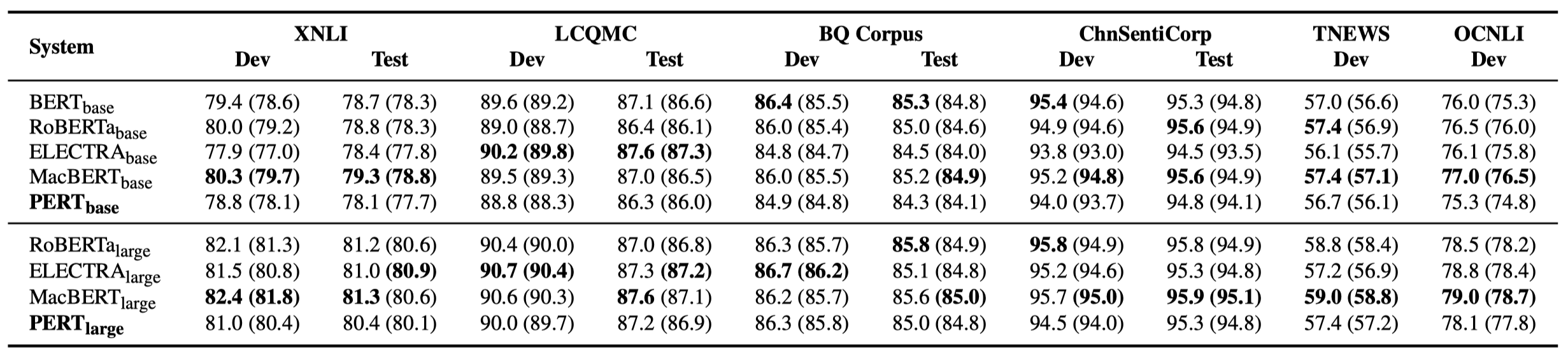
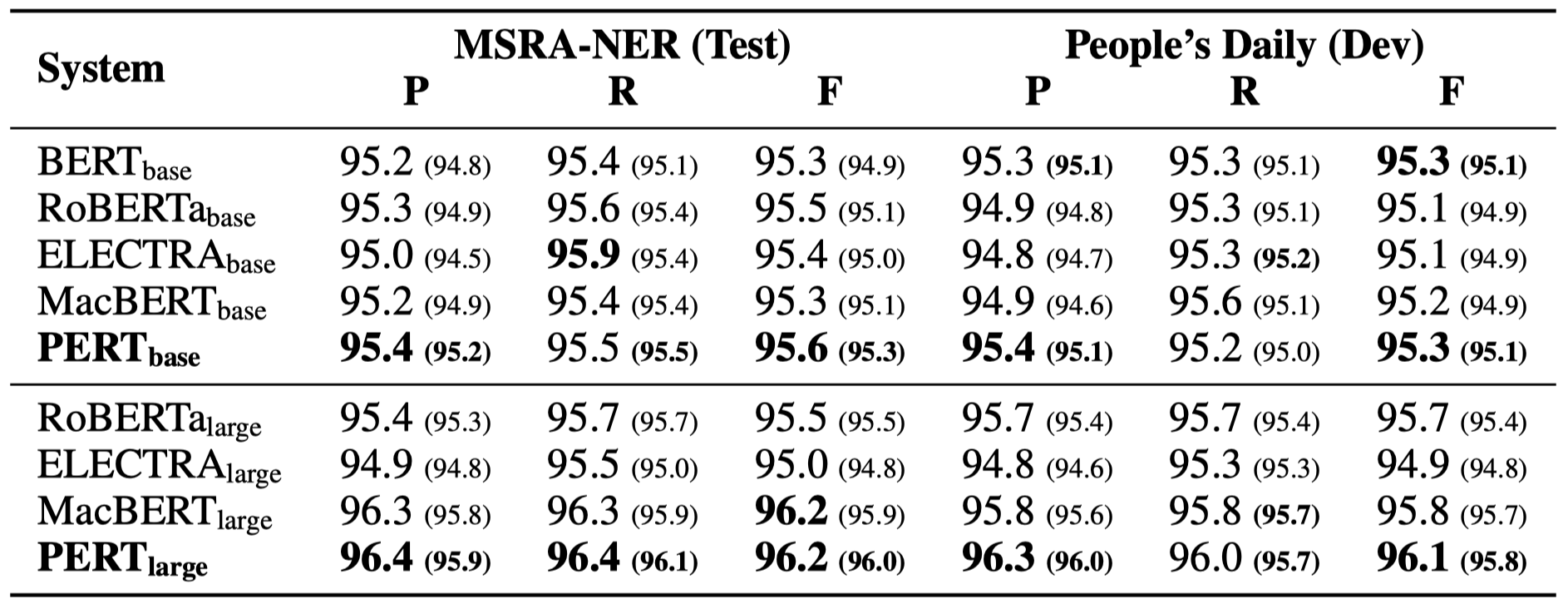
นอกเหนือจากงานข้างต้นแล้วเรายังได้ทดสอบงานที่ไม่ได้สั่งซื้อในการแก้ไขข้อผิดพลาดข้อความและผลกระทบมีดังนี้

การทดสอบประสิทธิภาพได้ดำเนินการใน 6 งานต่อไปนี้
Q1: เกี่ยวกับน้ำหนักโอเพ่นซอร์สของ PERT
A1: เวอร์ชันโอเพ่นซอร์สมีเพียงน้ำหนักของส่วนหม้อแปลงซึ่งสามารถใช้โดยตรงสำหรับการปรับแต่งงานดาวน์สตรีมหรือน้ำหนักเริ่มต้นของการฝึกอบรมก่อนการฝึกอบรมก่อนอื่น น้ำหนักรุ่น TF ดั้งเดิมอาจมีน้ำหนัก MLM ที่เริ่มต้นแบบสุ่ม นี่คือ:
Q2: เกี่ยวกับผลกระทบของ PERT ต่องานดาวน์สตรีม
A2: ข้อสรุปเบื้องต้นคือมันมีผลลัพธ์ที่ดีกว่าในงานเช่นการอ่านความเข้าใจและการติดฉลากลำดับ แต่ผลลัพธ์ที่ไม่ดีในงานการจำแนกประเภทข้อความ โปรดลองผลลัพธ์ที่เฉพาะเจาะจงในงานของคุณเอง สำหรับรายละเอียดโปรดดูเอกสารของเรา: https://arxiv.org/abs/2203.06906
หากแบบจำลองหรือข้อสรุปที่เกี่ยวข้องในโครงการนี้มีประโยชน์สำหรับการวิจัยของคุณโปรดอ้างอิงบทความต่อไปนี้: https://arxiv.org/abs/2203.06906
@article{cui2022pert,
title={PERT: Pre-training BERT with Permuted Language Model},
author={Cui, Yiming and Yang, Ziqing and Liu, Ting},
year={2022},
eprint={2203.06906},
archivePrefix={arXiv},
primaryClass={cs.CL}
}ยินดีต้อนรับสู่การติดตามบัญชีอย่างเป็นทางการของ WeChat อย่างเป็นทางการของห้องปฏิบัติการร่วม IFLYTEK เพื่อเรียนรู้เกี่ยวกับแนวโน้มทางเทคนิคล่าสุด

หากคุณมีคำถามใด ๆ โปรดส่งในปัญหา GitHub


