PERT
1.0.0
中国語|英語

自然言語処理の分野では、事前に訓練された言語モデル(PLM)が非常に重要な基本技術になっています。過去2年間で、Iflytek共同研究所は、中国のさまざまなトレーニング前モデルリソースと関連するサポートツールをリリースしました。関連する作業の継続として、このプロジェクトでは、マスクマーク[マスク]を導入せずにテキストセマンティック情報を自己監視して学習する順序外言語モデルに基づいた事前訓練モデル(PERT)を提案します。 PERTは、一部の中国語および英語のNLUタスクでパフォーマンスの改善を達成していますが、一部のタスクでも結果が不十分です。必要に応じて使用してください。現在、PERTモデルは、2つのモデルサイズ(ベース、大)を含む中国語と英語で提供されています。
中国語のレート|中国の英語のパート|中国のマッバート|中国のエレクトラ|中国のxlnet |中国のバート|知識蒸留ツールTextBrewer |モデル切削工具TextPruner
Harbin Institute of Technology(HFL)のIFLがリリースするリソースをご覧ください:https://github.com/ymcui/hfl-anthology
2023/3/28オープンソースチャイニーズラマ&アルパカビッグモデルは、PCで迅速に展開および経験することができます。
2022/10/29言語情報を統合する事前に訓練されたモデルLERTを提案します。表示:https://github.com/ymcui/lert
2022/5/7は、複数の読解データセットで細かく調整された特別な読解力を更新し、オンラインインタラクティブデモを提供しました、チェック:モデルダウンロード
2022/3/15テクニカルレポートがリリースされました。https://arxiv.org/abs/2203.06906を参照してください。
2022/2/24中国語と英語のパートベースとパートと大部分がリリースされました。 Bert構造を使用して直接読み込み、下流タスクを微調整することができます。技術レポートは完了後に発行され、3月中旬に時間が予想されます。忍耐をありがとう。
2022/2/17このプロジェクトにご注意いただきありがとうございます。モデルは来週発行される予定であり、技術レポートは改善後に発行されます。
| 章 | 説明する |
|---|---|
| 導入 | PERT事前訓練モデルの基本原則 |
| モデルダウンロード | PERTの事前訓練モデルのアドレスをダウンロードします |
| クイックロード | 変圧器の使用方法は、モデルをすばやくロードします |
| ベースラインシステム効果 | いくつかの中国語および英語のNLUタスクにベースラインシステムの影響 |
| よくある質問 | FAQと回答 |
| 引用 | このプロジェクトの技術レポート |
自然言語理解(NLU)のための前提型モデルの学習は、マスクマーキング[マスク]を使用して入力テキストを使用して使用しないという2つのカテゴリにほぼ分けられます。
インスピレーションを受けたアルゴリズム:ある程度のオーダーアウトオブオーダーテキストは、理解に影響しません。それでは、オーダーアウトオブオーダーテキストからセマンティック知識を学ぶことができますか?
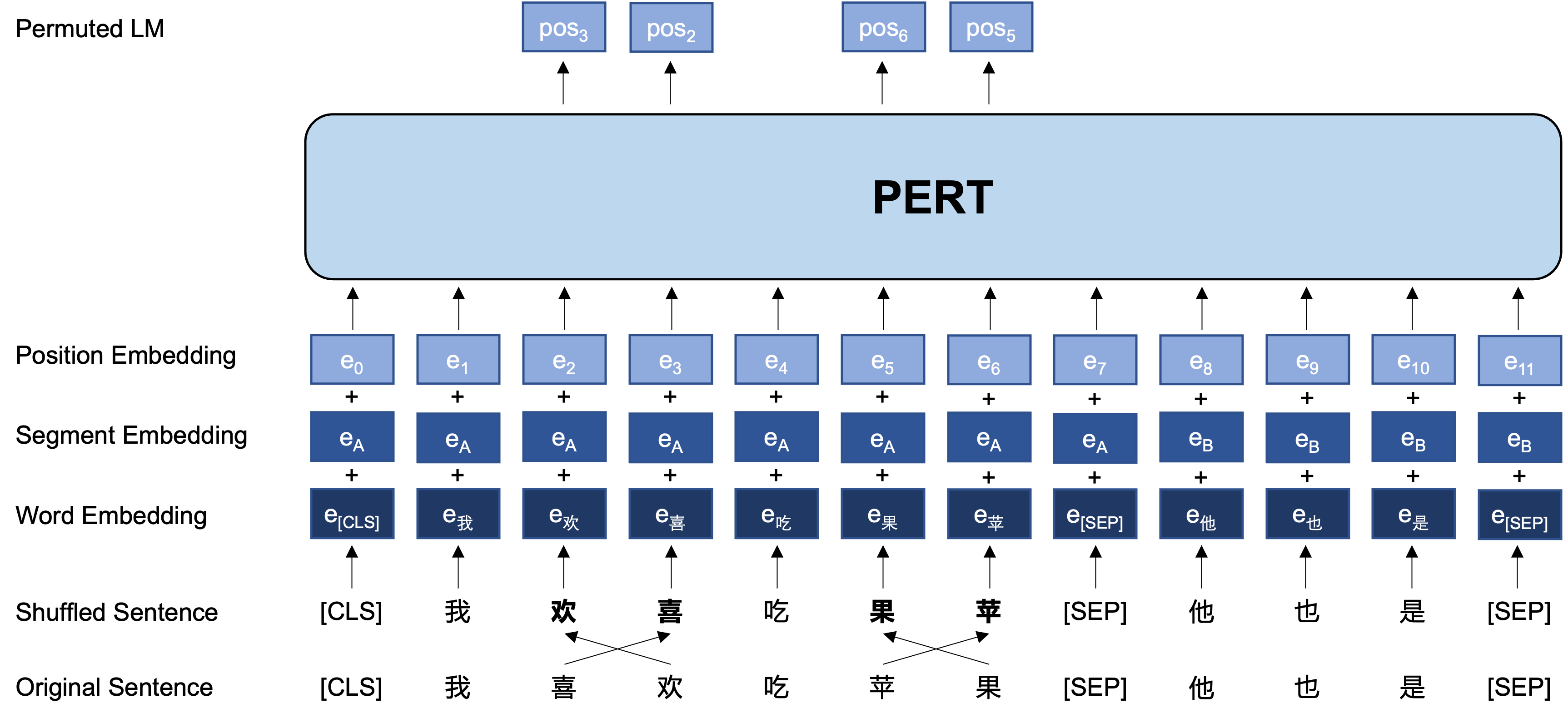
一般的なアイデア:PERTは、元の入力テキストで特定の語順スワップを実行するため、オーダーアウトオブオーダーテキストを形成します(したがって、追加の[マスク]タグは導入されません)。 PERTの学習目標は、元のトークンの位置を予測することです。次の例を参照してください。
| 説明します | テキストを入力します | 出力ターゲット |
|---|---|---|
| 元のテキスト | 調査によると、この文の順序は読みに影響しないことが示されています。 | - |
| ワードピースワード分詞 | 調査によると、この文の順序は読みに影響しないことが示されています。 | - |
| バート | 調査によると、この文は読書のように聞こえないことが示されています。 | 位置7→電話位置10→シーケンス位置13→影 |
| パート | この文の順序は読みに影響しません。 | 位置2(狭い)→位置3(表) 位置3(表)→位置2(狭い) 位置13(共鳴)→位置14(影) 位置14(映画)→位置13(共鳴) |
以下は、トレーニング前の段階にあるPERTモデルの基本構造と出力形式です(注:ARXIVテクニカルレポートの写真は現在間違っています。次の写真を参照してください。次に紙が更新されると、正しい写真に置き換えられます)。
ここでは、主にTensorflowバージョン1.15のモデル重量を提供します。モデルのpytorchまたはtensorflow2バージョンが必要な場合は、次のセクションをご覧ください。
オープンソースバージョンには、トランスパーツの重みのみが含まれています。これは、ダウンストリームタスクの微調整、または他の事前訓練モデルの二次プリトレーニングの初期重みに直接使用できます。詳細については、FAQを参照してください。
PERT-large :24層、1024人の隠された、16頭、330mパラメーターPERT-base 12層、768人の隠された、12頭、110mパラメーター| モデルの略語 | 言語 | 材料 | Googleダウンロード | Baiduディスクのダウンロード |
|---|---|---|---|---|
| 中国語 - と主張 | 中国語 | extデータ[1] | Tensorflow | Tensorflow(パスワード:E9HS) |
| 中国語のベース | 中国語 | extデータ[1] | Tensorflow | Tensorflow(パスワード:RCSW) |
| 英語のパート - と- | 英語 | wikibooks [2] | Tensorflow | Tensorflow(パスワード:WXWI) |
| 英語版ベース(覆われている) | 英語 | wikibooks [2] | Tensorflow | Tensorflow(パスワード:8JGQ) |
[1] extデータには、中国のウィキペディア、その他の百科事典、ニュース、Q&A、その他のデータが含まれます。合計単語の数は5.4bに達し、マッバートと同じ約20gディスクスペースを占めています。
[2] Wikipedia + BookCorpus
TensorflowバージョンのChinese-PERT-baseを例として、ダウンロードした後、ZIPファイルを減圧して取得します。
chinese_pert_base_L-12_H-768_A-12.zip
|- pert_model.ckpt # 模型权重
|- pert_model.meta # 模型meta信息
|- pert_model.index # 模型index信息
|- pert_config.json # 模型参数
|- vocab.txt # 词表(与谷歌原版一致)
その中でも、 bert_config.jsonとvocab.txt 、GoogleのオリジナルのBERT-base, Chineseとまったく同じです(英語版はBert廃止バージョンと一致しています)。
Tensorflow(V2)およびPytorchバージョンモデルは、Transformersモデルライブラリからダウンロードできます。
ダウンロード方法:ダウンロードするモデルをクリックします→[ファイルとバージョン]タブを選択→対応するモデルファイルをダウンロードします。
| モデルの略語 | モデルファイルサイズ | トランスモデルライブラリアドレス |
|---|---|---|
| 中国語 - と主張 | 1.2g | https://huggingface.co/hfl/chinese-pert-large |
| 中国語のベース | 0.4g | https://huggingface.co/hfl/chinese-pert-base |
| 中国語 - と - とMRC | 1.2g | https://huggingface.co/hfl/chinese-pert-large-mrc |
| 中国語base-mrc | 0.4g | https://huggingface.co/hfl/chinese-pert-base-mrc |
| 英語のパート・ラージ | 1.2g | https://huggingface.co/hfl/english-pert-large |
| 英語のパートベース | 0.4g | https://huggingface.co/hfl/english-pert-base |
PERTボディの部分はまだBERT構造であるため、ユーザーはトランスライブラリを使用してPERTモデルを簡単に呼び出すことができます。
注:このディレクトリのすべてのモデルは、BerttokenizerとBertmodelを使用してロードされます(MRCモデルはBertforquestionansweringを使用します)。
from transformers import BertTokenizer , BertModel
tokenizer = BertTokenizer . from_pretrained ( "MODEL_NAME" )
model = BertModel . from_pretrained ( "MODEL_NAME" ) MODEL_NAMEの対応するリストは次のとおりです。
| モデル名 | model_name |
|---|---|
| 中国語 - と主張 | HFL/中国語 - ゆっくり |
| 中国語のベース | HFL/中国語のベース |
| 中国語 - と - とMRC | HFL/中国語 - パート - ラージ-MRC |
| 中国語base-mrc | HFL/中国語 - ベース-MRC |
| 英語のパート・ラージ | HFL/English-Pert-Large |
| 英語のパートベース | HFL/English-Pert-Base |
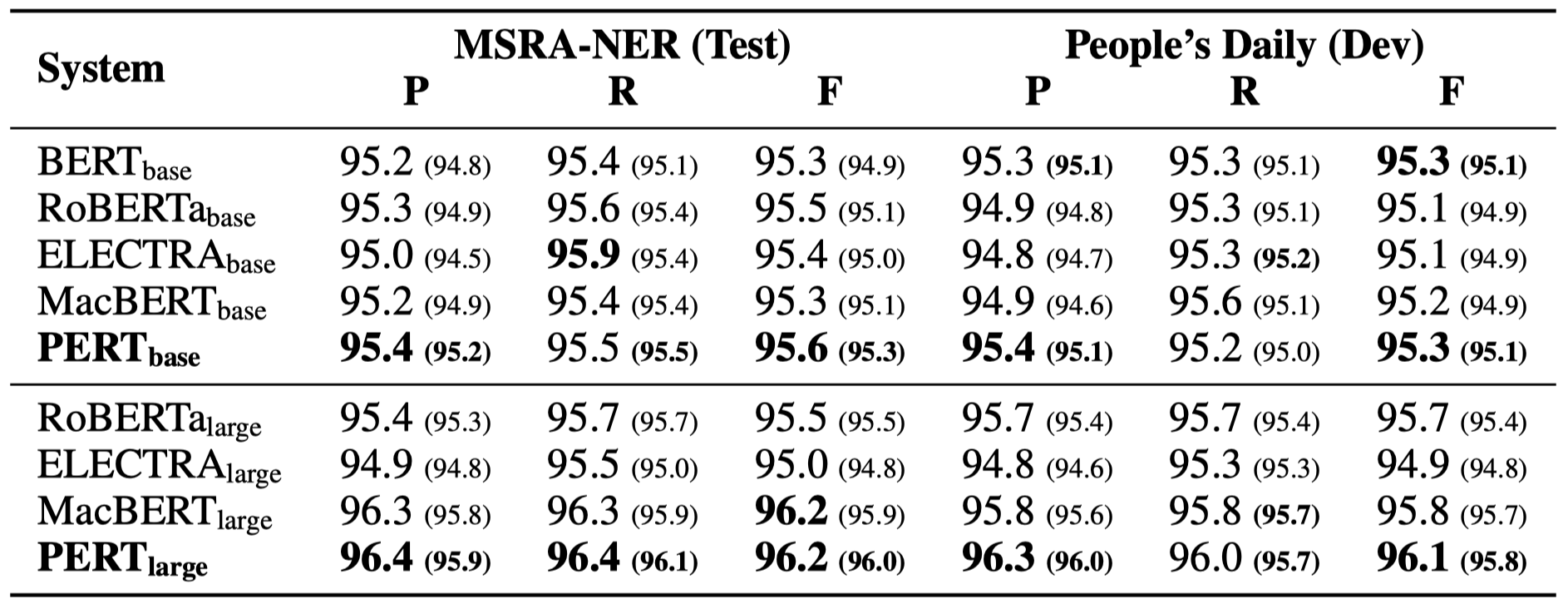
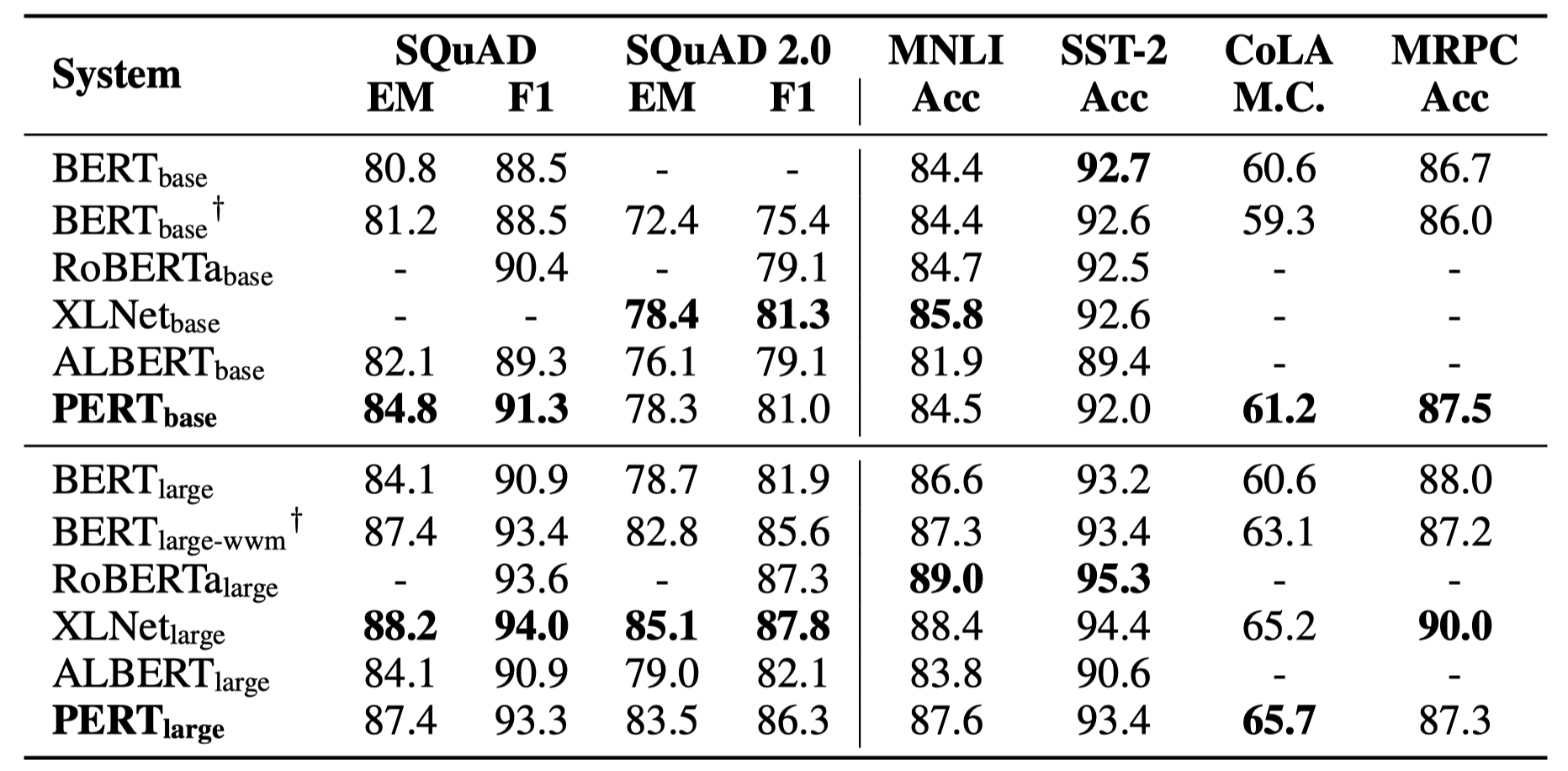
いくつかの実験結果のみを以下に示します。詳細な結果と分析については、論文を参照してください。実験結果テーブルでは、ブラケットの外側の最大値は、ブラケット内の平均値です。
次の10のタスクで有効性テストが実行されました。
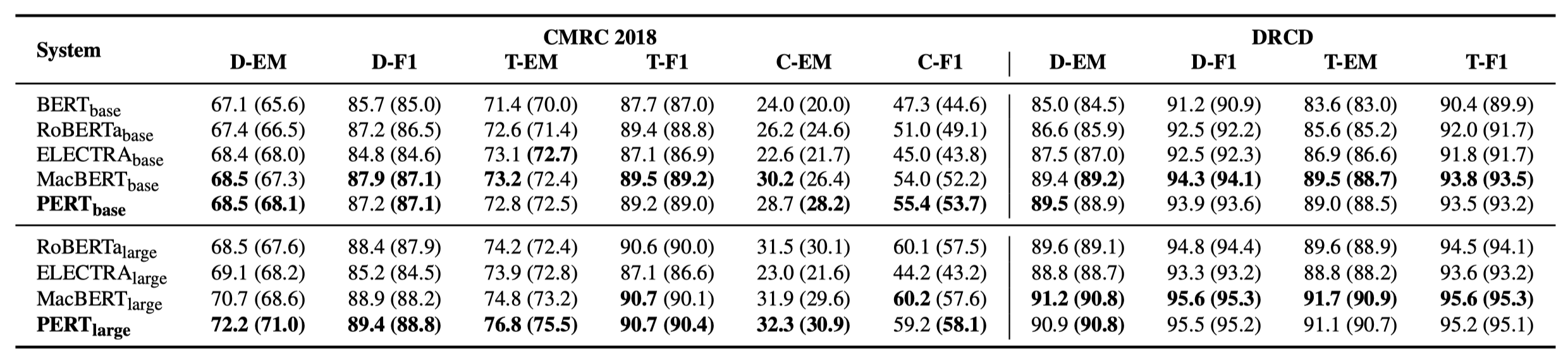
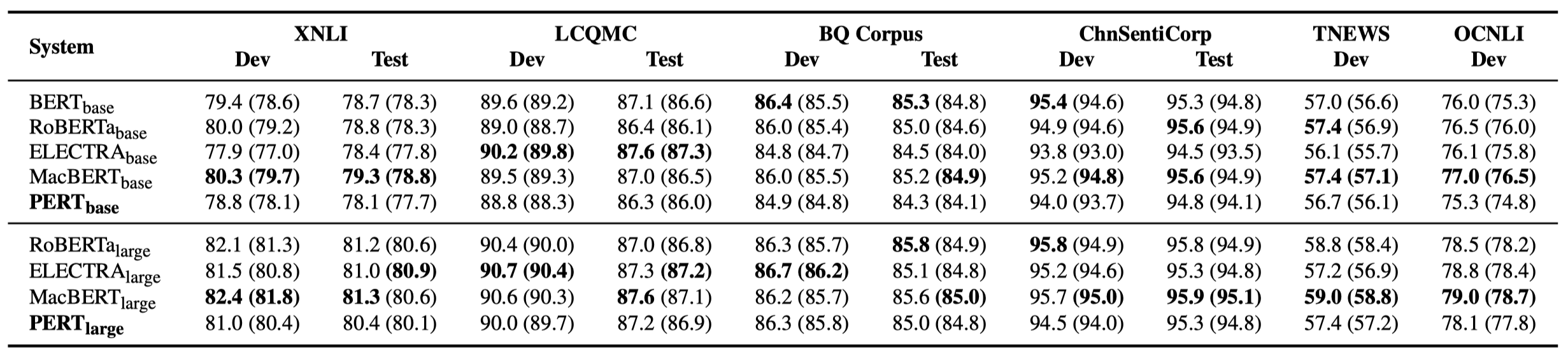
上記のタスクに加えて、テキストエラー補正でオーダーアウトオブオーダータスクもテストしましたが、その効果は次のとおりです。

次の6つのタスクで有効性テストが実行されました。
Q1:PERTのオープンソースバージョンの重みについて
A1:オープンソースバージョンには、トランスパーツの重みのみが含まれています。これは、ダウンストリームタスクの微調整に直接使用できます。元のTFバージョンの重みには、ランダムに初期化されたMLM重みが含まれる場合があります。これは次のとおりです。
Q2:下流タスクに対するPERTの影響について
A2:予備的な結論は、読解力やシーケンスのラベル付けなどのタスクでより良い結果が得られるが、テキスト分類タスクでは不十分な結果であるということです。独自のタスクで特定の結果を試してください。詳細については、https://arxiv.org/abs/2203.06906を参照してください
このプロジェクトのモデルまたは関連する結論が研究に役立つ場合は、次の記事を引用してください:https://arxiv.org/abs/2203.06906
@article{cui2022pert,
title={PERT: Pre-training BERT with Permuted Language Model},
author={Cui, Yiming and Yang, Ziqing and Liu, Ting},
year={2022},
eprint={2203.06906},
archivePrefix={arXiv},
primaryClass={cs.CL}
}イフィーテク共同研究所の公式WeChat公式アカウントをフォローして、最新の技術動向について学びます。

ご質問がある場合は、GitHub Issueで送信してください。


