PERT
1.0.0
Chinesisch | Englisch

Im Bereich der natürlichen Sprachverarbeitung sind vorgeborene Sprachmodelle (PLMs) zu einer sehr wichtigen Grundtechnologie geworden. In den letzten zwei Jahren hat das Joint Laboratory Iflytek eine Vielzahl von chinesischen Modellressourcen und damit verbundenen Unterstützungswerkzeugen veröffentlicht. Als Fortsetzung der verwandten Arbeiten schlagen wir in diesem Projekt ein vorgebildetes Modell (Pert) vor, das auf außerordentlichem Sprachmodell basiert, das selbst überprüftes Lernen von semantischen Informationen von Texten ohne Einführung von Maskenmarke [Mask]. Pert hat Leistungsverbesserungen bei einigen chinesischen und englischen NLU -Aufgaben erzielt, hat aber auch schlechte Ergebnisse bei einigen Aufgaben. Bitte verwenden Sie es gegebenenfalls. Derzeit werden PERT -Modelle in Chinesisch und Englisch bereitgestellt, einschließlich zwei Modellgrößen (Basis, groß).
Chinesische LERT | Chinese Englisch Pert | Chinesischer Macbert | Chinesische Elektrik | Chinesische xlnet | Chinesische Bert | Knowledge Destillation Tool Textbrewer | Modellschneidwerkzeug Textpruner
Siehe weitere Ressourcen,
2023/3/28 Open Source Chinese Lama & Alpaca Big Model, das schnell auf dem PC eingesetzt und erfahren werden kann, https://github.com/ymcui/chinese-lama-alpaca
2022/10/29 Wir schlagen eine vorgebildete Modelllert vor, die sprachliche Informationen integriert. Ansicht: https://github.com/ymcui/lert
2022/5/7 Aktualisierte ein spezielles Leseverständnis, das sich fein abgestimmt auf mehreren Datensätzen für das Leseverständnis und eine Interaktive -Demo für das Huggingface -Online -Demo zur Verfügung stellte: Modell Download: Model Download
2022/3/15 Der technische Bericht wurde veröffentlicht. Weitere Informationen finden Sie unter: https://arxiv.org/abs/2203.06906
2022/2/24 Pert-Base und Pert-Large in Chinesisch und Englisch wurden veröffentlicht. Sie können die Bert-Struktur direkt laden und nachgeschaltete Aufgaben feinabstimmen. Der technische Bericht wird nach Fertigstellung ausgestellt und die Zeit wird voraussichtlich Mitte März sein. Vielen Dank für Ihre Geduld.
2022/2/17 Vielen Dank für Ihre Aufmerksamkeit für dieses Projekt. Das Modell wird voraussichtlich nächste Woche ausgestellt, und der technische Bericht wird nach einer Verbesserung ausgestellt.
| Kapitel | beschreiben |
|---|---|
| Einführung | Das Grundprinzip des Pert-Pert-aus-Modells |
| Modell Download | Laden Sie die Adresse des PERT-PER-Modells herunter |
| Schnelles Laden | So verwenden Sie Transformatoren schnell laden Modelle |
| Basissystemeffekte | Auswirkungen des Grundliniensystems auf einige chinesische und englische NLU -Aufgaben |
| FAQ | FAQs und Antworten |
| Zitat | Technischer Bericht dieses Projekts |
Das Lernen von vorbereiteten Modellen für das Verständnis der natürlichen Sprache (NLU) ist grob in zwei Kategorien unterteilt: Verwendung und Nicht -Eingabetxt mit Maskenmarkierung [Maske].
Inspiriertes Algorithmus: Ein gewisses Maß an ausreißender Text hat keinen Einfluss auf das Verständnis. Können wir also semantisches Wissen aus außerordentlichen Texten lernen?
Allgemeine Idee: Pert führt einen bestimmten Wortreihenaug auf dem ursprünglichen Eingabetxt aus und bildet so einen ausdrücklichen Text (so werden keine zusätzlichen [Masken] -Tags eingeführt). Das Lernziel von Pert ist es, den Ort des ursprünglichen Tokens vorherzusagen, siehe das folgende Beispiel.
| veranschaulichen | Text eingeben | Ausgangsziel |
|---|---|---|
| Originaltext | Untersuchungen zeigen, dass die Reihenfolge dieses Satzes keinen Einfluss auf das Lesen hat. | - - |
| Wortstück Wort Partizip | Untersuchungen zeigen, dass die Reihenfolge dieses Satzes keinen Einfluss auf das Lesen hat. | - - |
| Bert | Untersuchungen zeigen, dass dieser Satz [Maske] nicht nach Lesen klingt. | Position 7 → Telefonposition 10 → Sequenzposition 13 → Schatten |
| Regelmäßig | Die Reihenfolge dieses Satzes hat keinen Einfluss auf das Lesen . | Position 2 (schmal) → Position 3 (Tabelle) Position 3 (Tabelle) → Position 2 (schmal) Position 13 (Resonanz) → Position 14 (Schatten) Position 14 (Film) → Position 13 (Resonant) |
Im Folgenden finden Sie die Grundstruktur und das Eingangs- und Ausgangsformat des Pert-Modells in der Vorausbildungsphase (Hinweis: Die Bilder im technischen Bericht von ARXIV sind derzeit falsch. Bitte beziehen Sie sich auf die folgenden Bilder. Wenn das Papier das nächste Mal aktualisiert wird, wird es durch das richtige Bild ersetzt.)
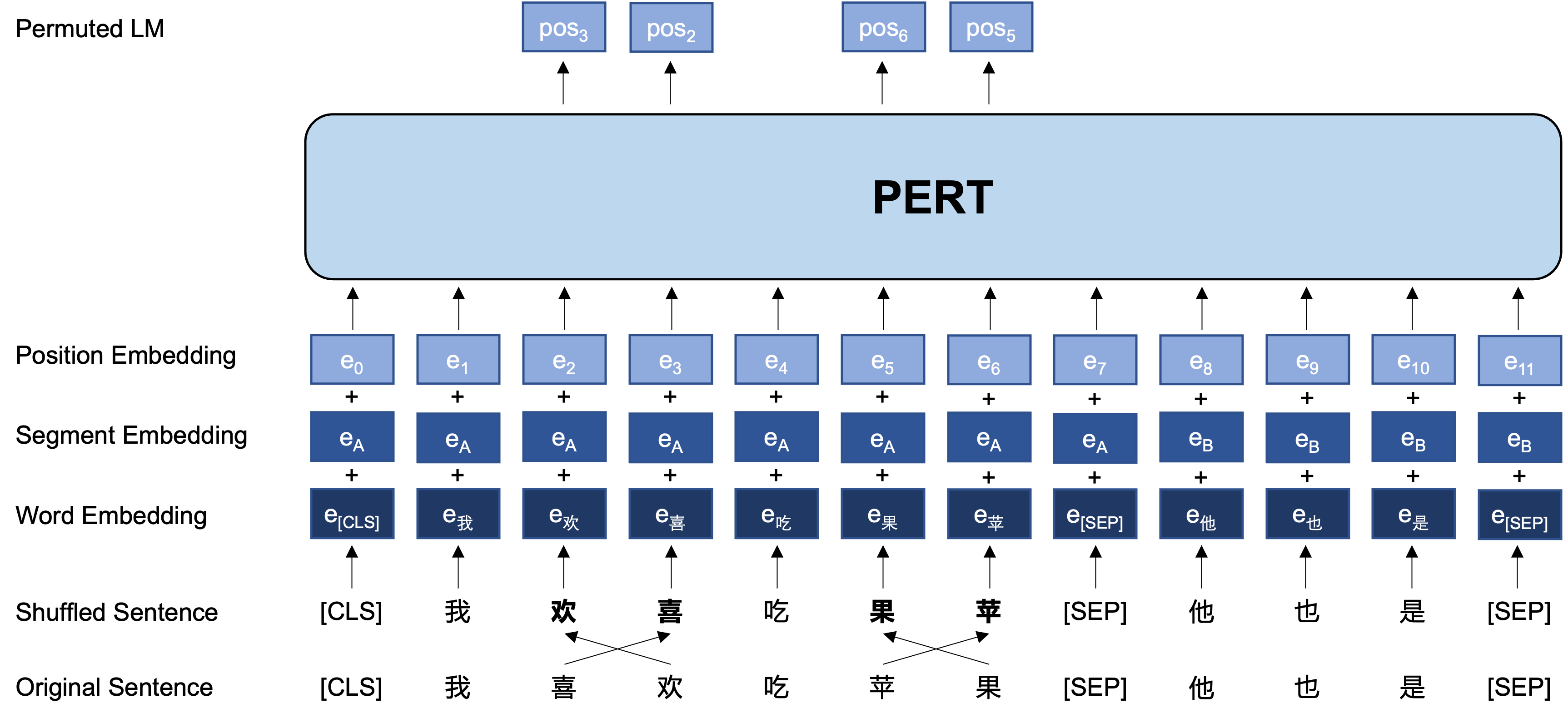
Hier stellen wir hauptsächlich die Modellgewichte von TensorFlow Version 1.15 an. Wenn Sie eine Pytorch- oder TensorFlow2 -Version des Modells benötigen, lesen Sie bitte den nächsten Abschnitt.
Die Open-Source-Version enthält nur die Gewichte des Transformator-Teils, die direkt für die Feinabstimmung der nachgeschalteten Aufgaben oder die anfänglichen Gewichte der sekundären Vorausbildung anderer vorgebildeter Modelle verwendet werden können. Weitere Informationen finden Sie unter FAQ.
PERT-large : 24-LAYER, 1024 HIDDEN, 16-KEINE, 330M ParameterPERT-base 12-Layer, 768 versteckte, 12-Head-, 110-m-Parameter| Modellabkürzung | Sprache | Materialien | Google Download | BAIDU DISK DOWNLOAD |
|---|---|---|---|---|
| Chinese-Pert-Large | chinesisch | Ext -Daten [1] | Tensorflow | TensorFlow (Passwort: E9HS) |
| Chinesisch-PERT-Base | chinesisch | Ext -Daten [1] | Tensorflow | TensorFlow (Passwort: RCSW) |
| Englisch-pert-large (ungezogen) | Englisch | Wikibooks [2] | Tensorflow | TensorFlow (Passwort: WXWI) |
| Englisch-PERT-Base (ungezogen) | Englisch | Wikibooks [2] | Tensorflow | TensorFlow (Passwort: 8JGQ) |
[1] Ext -Daten umfassen: chinesische Wikipedia, andere Enzyklopädien, Nachrichten, Fragen und Antworten und andere Daten, wobei eine Gesamtzahl von Wörtern 5,4B erreicht und etwa 20 g Speicherplatz belegt, genau wie Macbert.
[2] Wikipedia + bookcorpus
Nehmen Sie die TensorFlow-Version von Chinese-PERT-base als Beispiel nach dem Herunterladen der ZIP-Datei, um zu erhalten, um zu erhalten:
chinese_pert_base_L-12_H-768_A-12.zip
|- pert_model.ckpt # 模型权重
|- pert_model.meta # 模型meta信息
|- pert_model.index # 模型index信息
|- pert_config.json # 模型参数
|- vocab.txt # 词表(与谷歌原版一致)
Unter ihnen sind bert_config.json und vocab.txt genau die gleichen wie die ursprüngliche BERT-base, Chinese von Google (die englische Version steht im Einklang mit der Bert-Unbekannten Version).
Die Modelle TensorFlow (V2) und Pytorch -Version können über die Transformers Model Library heruntergeladen werden.
Download -Methode: Klicken Sie auf ein beliebiges Modell, das Sie herunterladen möchten. → Wählen Sie die Registerkarte "Dateien und Versionen" aus → Laden Sie die entsprechende Modelldatei herunter.
| Modellabkürzung | Modelldateigröße | Transformatorenmodellbibliotheksadresse |
|---|---|---|
| Chinese-Pert-Large | 1,2g | https://huggingface.co/hfl/chinese-pert-large |
| Chinesisch-PERT-Base | 0,4 g | https://huggingface.co/hfl/chinese-pert-base |
| Chinese-Pert-Large-MRC | 1,2g | https://huggingface.co/hfl/chinese-pert-large-mrc |
| Chinese-Pert-Base-MRC | 0,4 g | https://huggingface.co/hfl/chinese-pert-base-mrc |
| Englisch-pert-large | 1,2g | https://huggingface.co/hfl/english-pert-large |
| Englisch-PERT-Base | 0,4 g | https://huggingface.co/hfl/english-pert-base |
Da es sich bei dem PERT -Körperteil noch um eine Bert -Struktur handelt, können Benutzer das Pert -Modell problemlos mit der Transformers Library aufrufen.
HINWEIS: Alle Modelle in diesem Verzeichnis werden mit BertTokenizer und Bertmodel geladen (MRC -Modelle verwenden BertforquestionAnswerer).
from transformers import BertTokenizer , BertModel
tokenizer = BertTokenizer . from_pretrained ( "MODEL_NAME" )
model = BertModel . from_pretrained ( "MODEL_NAME" ) Die entsprechende Liste von MODEL_NAME lautet wie folgt:
| Modellname | Model_name |
|---|---|
| Chinese-Pert-Large | HFL/Chinese-Pert-Large |
| Chinesisch-PERT-Base | HFL/Chinese-Pert-Base |
| Chinese-Pert-Large-MRC | HFL/Chinese-Pert-Large-MRC |
| Chinese-Pert-Base-MRC | HFL/Chinese-Pert-Base-MRC |
| Englisch-pert-large | HFL/English-Pert-Large |
| Englisch-PERT-Base | HFL/English-Pert-Base |
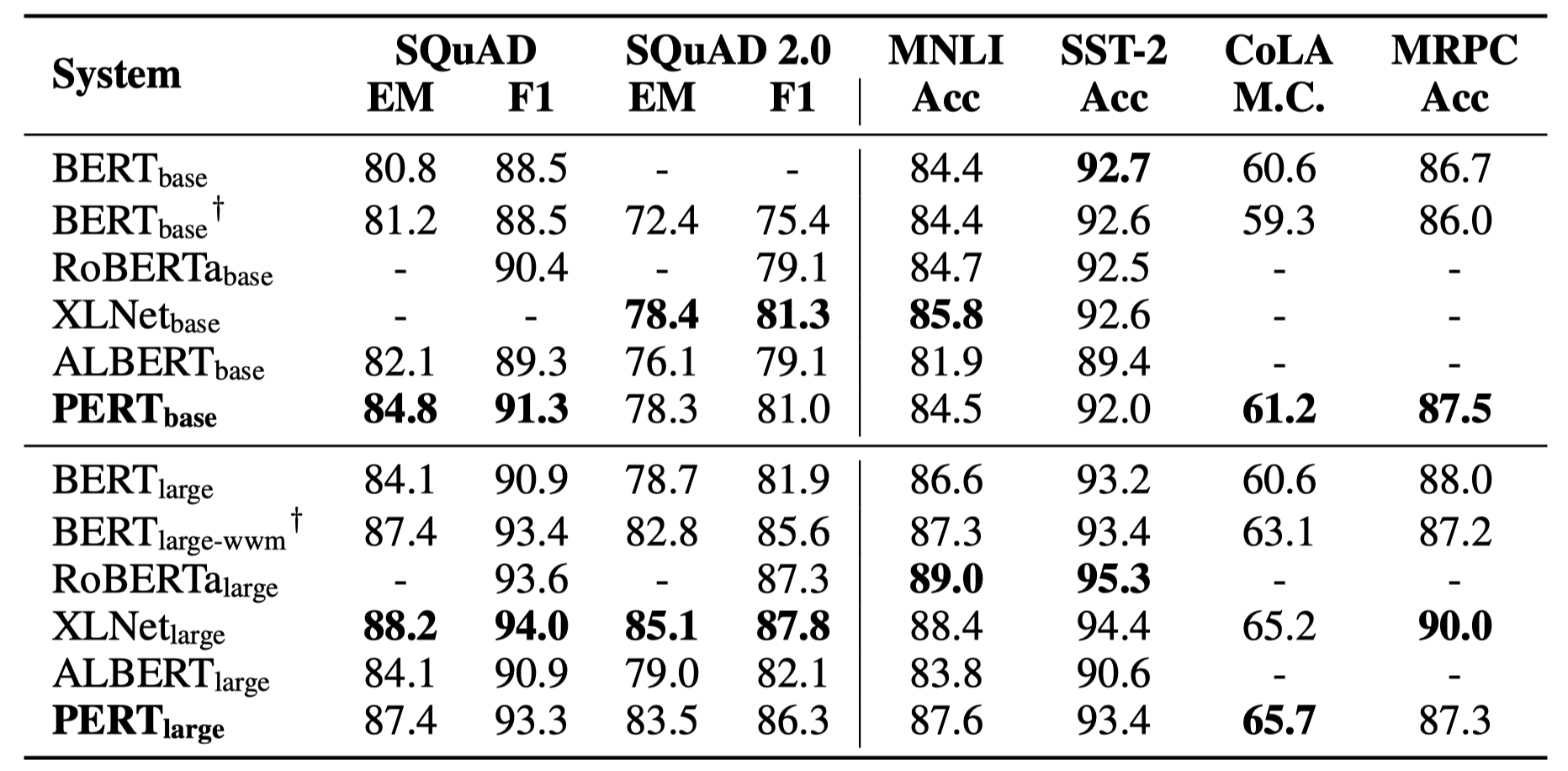
Im Folgenden sind nur einige experimentelle Ergebnisse aufgeführt. Weitere Ergebnisse und Analyse finden Sie in der Arbeit. In der experimentellen Ergebnistabelle ist der Maximalwert außerhalb der Klammern der Durchschnittswert innerhalb der Klammern.
Effektivitätstests wurden bei den folgenden 10 Aufgaben durchgeführt.
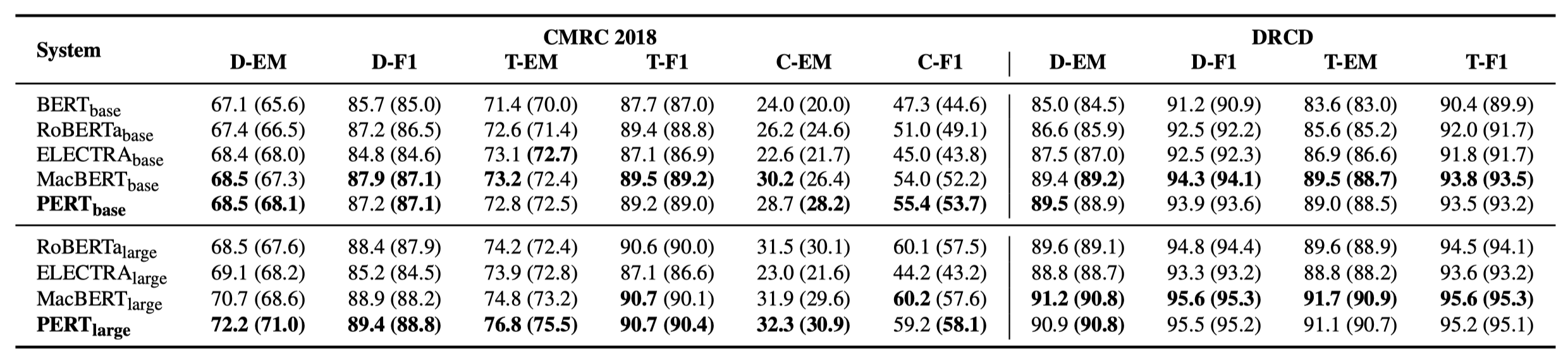
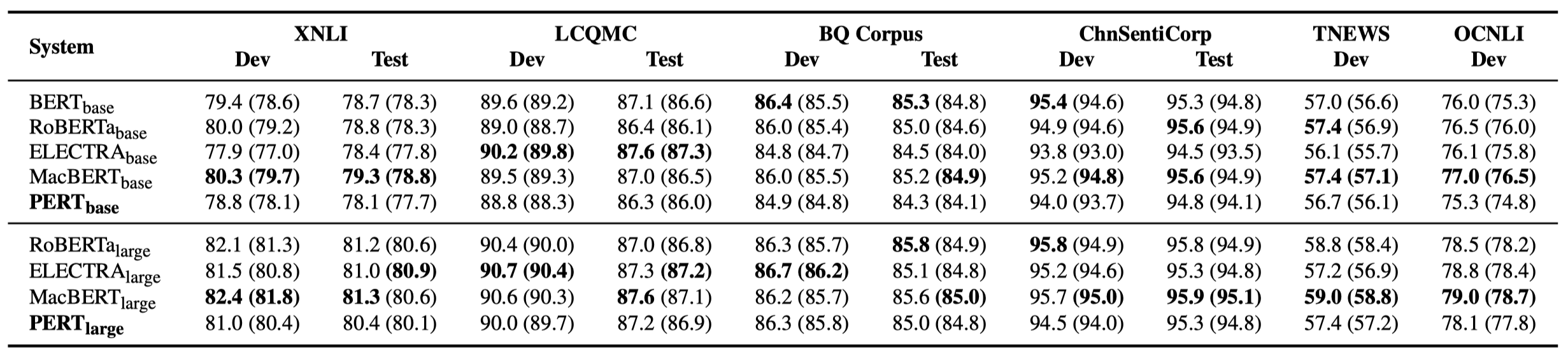
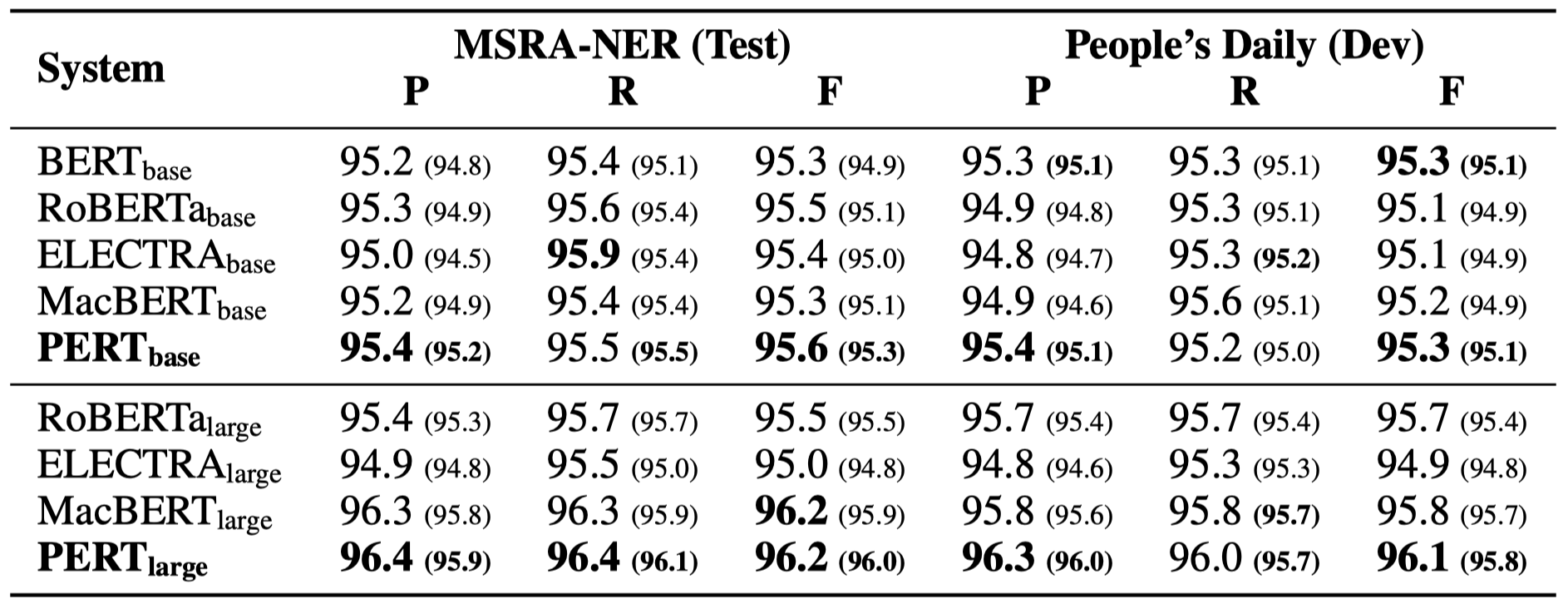
Zusätzlich zu den oben genannten Aufgaben haben wir auch die Aufgaben außerhalb der Ordnung in der Textfehlerkorrektur getestet, und der Effekt ist wie folgt.

Effektivitätstests wurden an den folgenden 6 Aufgaben durchgeführt.
Q1: Über das Open -Source -Versionsgewicht von Pert
A1: Die Open-Source-Version enthält nur die Gewichte des Transformator-Teils, die direkt für die Feinabstimmung der nachgeschalteten Aufgaben oder die anfänglichen Gewichte der sekundären Vorausbildung anderer vorgebildeter Modelle verwendet werden können. Die ursprünglichen TF -Versionsgewichte können zufällig initialisierte MLM -Gewichte enthalten. Dies ist für:
Q2: Über den Effekt von PERT auf nachgeschaltete Aufgaben
A2: Die vorläufige Schlussfolgerung ist, dass es bessere Ergebnisse bei Aufgaben wie Leseverständnis und Sequenzmarkierung hat, aber schlechte Ergebnisse bei Textklassifizierungsaufgaben. Bitte probieren Sie die spezifischen Ergebnisse für Ihre eigenen Aufgaben aus. Weitere Informationen finden Sie in unserem Artikel: https://arxiv.org/abs/2203.06906
Wenn die Modelle oder verwandte Schlussfolgerungen in diesem Projekt für Ihre Forschung hilfreich sind, geben Sie den folgenden Artikel an: https://arxiv.org/abs/2203.06906
@article{cui2022pert,
title={PERT: Pre-training BERT with Permuted Language Model},
author={Cui, Yiming and Yang, Ziqing and Liu, Ting},
year={2022},
eprint={2203.06906},
archivePrefix={arXiv},
primaryClass={cs.CL}
}Willkommen, um dem offiziellen WeChat Offiziellen Bericht des gemeinsamen Labors Iflytek zu folgen, um mehr über die neuesten technischen Trends zu erfahren.

Wenn Sie Fragen haben, senden Sie diese bitte in Github -Problem.


