PERT
1.0.0
Китайский | Английский

В области обработки естественного языка предварительно обученные языковые модели (PLMS) стали очень важной основной технологией. За последние два года совместная лаборатория Iflytek выпустила множество китайских модельных ресурсов перед тренировкой и связанных с ними инструментов поддержки. В качестве продолжения связанной работы в этом проекте мы предлагаем предварительно обученную модель (PERT), основанную на модели языка вне заказа, которая самоподдерживаемое изучение текстовой семантической информации без введения знака маски [Маска]. PERT достиг улучшения производительности в некоторых китайских и английских задачах NLU, но также имеет плохие результаты по некоторым задачам. Пожалуйста, используйте его по мере необходимости. В настоящее время модели PERT представлены на китайском и английском языке, включая два размера модели (база, большой).
Китайский Лерт | Китайский английский pert | Китайский Макберт | Китайская электро | Китайский Xlnet | Китайский берт | Инструмент для дистилляции знаний TextBrewer | Модельный режущий инструмент текст
См. Больше ресурсов, выпущенных IFL из Технологического института Харбина (HFL): https://github.com/ymcui/hfl-anthology
2023/3/28 Китайская большая модель Llama & Alpaca, которая может быть быстро развернута и опыта на ПК, просмотр: https://github.com/ymcui/chinese-llama-alpaca
2022/10/29 Мы предлагаем предварительно обученную модель LERT, которая интегрирует лингвистическую информацию. Просмотр: https://github.com/ymcui/lert
2022/5/7 Обновлено специальное понимание прочитанного, точно настроенное на несколько наборов данных по пониманию чтения и предоставила интерактивную демонстрацию онлайн -huggingface, проверка: загрузка модели
2022/3/15 Технический отчет был опубликован, пожалуйста, см.
2022/2/24 Pert-Base и Pert-Large на китайском и английском языке были выпущены. Вы можете напрямую загружаться, используя структуру BERT и выполнять непрерывные задачи. Технический отчет будет выпущен после завершения, и ожидается, что время будет в середине марта. Спасибо за терпение.
2022/2/17 Спасибо за внимание к этому проекту. Ожидается, что модель будет выпущена на следующей неделе, а технический отчет будет выпущен после улучшения.
| глава | описывать |
|---|---|
| Введение | Основной принцип предварительно обученной модели PER |
| Модель скачать | Скачать адрес предварительной модели PERT |
| Быстрая загрузка | Как использовать трансформаторы быстро загружать модели |
| Базовые системы системы | Базовые системы системы на некоторые китайские и английские задачи NLU |
| Часто задаваемые вопросы | Часто задаваемые вопросы и ответы |
| Цитировать | Технический отчет этого проекта |
Изучение предварительно проведенных моделей для понимания естественного языка (NLU) примерно разделено на две категории: использование и использование входного текста с маркировкой маски [маска].
Алгоритм вдохновлен: определенная степень текста вне порядка не влияет на понимание. Так можем ли мы выучить семантические знания из текстов вне заказа?
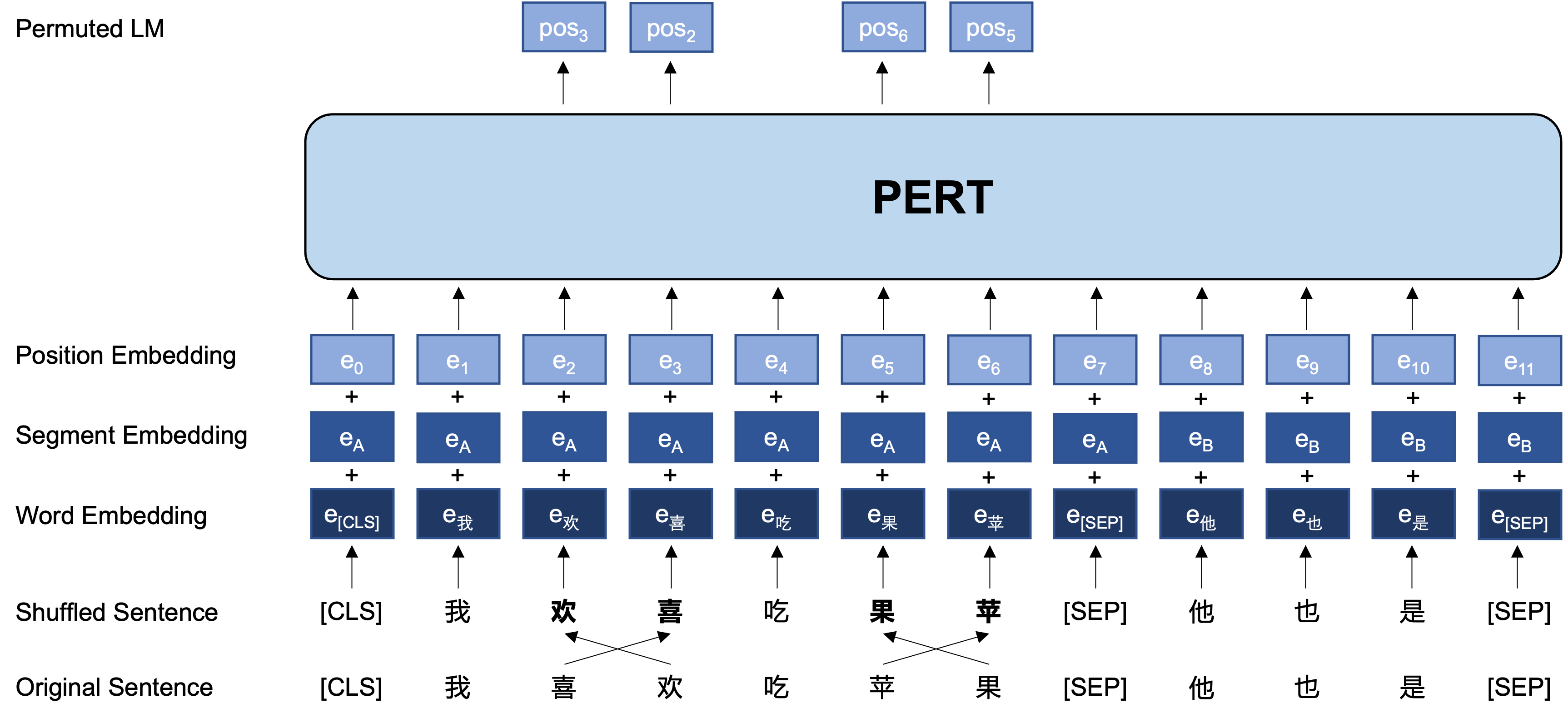
Общая идея: PERT выполняет определенное обмен заказом слова на исходном входном тексту, формируя тем самым текст вне порядка (поэтому не введено дополнительные теги [Маски]). Цель обучения PERT состоит в том, чтобы предсказать местоположение оригинального токена, см. Следующий пример.
| иллюстрировать | Введите текст | Выходная цель |
|---|---|---|
| Оригинальный текст | Исследования показывают, что порядок этого предложения не влияет на чтение. | - |
| Причастие слов Wordiece | Исследования показывают, что порядок этого предложения не влияет на чтение. | - |
| БЕРТ | Исследования показывают, что это предложение [маска] не звучит как чтение. | Положение 7 → Положение телефона 10 → Позиция последовательности 13 → тень |
| Проницательный | Порядок этого предложения не влияет на чтение . | Положение 2 (узкое) → позиция 3 (таблица) Положение 3 (таблица) → Положение 2 (узкое) Положение 13 (резонанс) → позиция 14 (тень) Позиция 14 (фильм) → позиция 13 (резонанс) |
Ниже приведено основной структуру и входной и выходной формат модели PERT на стадии предварительного обучения (примечание: изображения в техническом отчете ARXIV в настоящее время неверны, пожалуйста, см. Следующие изображения. В следующий раз, когда бумага будет обновлена, она будет заменена на правильную картину.).
Здесь мы в основном предоставляем веса модели Tensorflow версии 1.15. Если вам нужна версия модели Pytorch или TensorFlow2, см. В следующем разделе.
Версия с открытым исходным кодом содержит только веса трансформаторной части, которая может быть непосредственно использовать для тонкой настройки вниз по течению или начальных весов вторичного предварительного обучения других предварительно обученных моделей. Для получения дополнительной информации см. FAQ.
PERT-large : 24-слойный, 1024 скрытый, 16 голов, параметры 330 мPERT-base , 768 скрытых, 12 голов, 110 м. Параметры| Модель аббревиатура | Язык | Материалы | Google скачать | Baidu Disk Download |
|---|---|---|---|---|
| Китайский-пройд | китайский | Данные EXT [1] | Tensorflow | Tensorflow (пароль: E9HS) |
| Китайская база | китайский | Данные EXT [1] | Tensorflow | Tensorflow (пароль: RCSW) |
| Английский-продливый (неработающий) | Английский | Wikibooks [2] | Tensorflow | TensorFlow (пароль: wxwi) |
| Английская-первая база (UNCASE) | Английский | Wikibooks [2] | Tensorflow | Tensorflow (пароль: 8jgq) |
[1] Данные EXT включают в себя: китайскую Википедию, другие энциклопедии, новости, вопросы и ответы и другие данные, с общим количеством слов, достигающих 5,4 б, занимая около 20 г дискового пространства, так же, как Макберт.
[2] Википедия + BookCorpus
Взяв в качестве примера версию TensorFlow Chinese-PERT-base , после загрузки, распаковывает файл ZIP, чтобы получить:
chinese_pert_base_L-12_H-768_A-12.zip
|- pert_model.ckpt # 模型权重
|- pert_model.meta # 模型meta信息
|- pert_model.index # 模型index信息
|- pert_config.json # 模型参数
|- vocab.txt # 词表(与谷歌原版一致)
Среди них bert_config.json и vocab.txt точно такие же, как и оригинальная BERT-base, Chinese Google (английская версия соответствует версии Bert-предоставления).
Модели версий TensorFlow (V2) и Pytorch могут быть загружены через библиотеку модели Transformers.
Метод загрузки: нажмите на любую модель, которую вы хотите загрузить → Выберите вкладку «Файлы и версии» → Загрузите соответствующий файл модели.
| Модель аббревиатура | Размер файла модели | Адрес библиотеки Transformers Model |
|---|---|---|
| Китайский-пройд | 1,2 г | https://huggingface.co/hfl/chinese-pert-large |
| Китайская база | 0,4 г | https://huggingface.co/hfl/chinese-pert-base |
| Китайский-заполняющий-MRC | 1,2 г | https://huggingface.co/hfl/chinese-pert-large-mrc |
| Китайский-пертец-баз-MRC | 0,4 г | https://huggingface.co/hfl/chinese-pert-base-mrc |
| Английский-заполненный | 1,2 г | https://huggingface.co/hfl/english-pert-large |
| Английская первая база | 0,4 г | https://huggingface.co/hfl/english-pert-base |
Поскольку часть тела PERT по -прежнему является структурой BERT, пользователи могут легко вызвать модель PERT, используя библиотеку трансформаторов.
Примечание. Все модели в этом каталоге загружаются с использованием Berttokenizer и Bertmodel (MRC -модели используют Bertforquestionanswering).
from transformers import BertTokenizer , BertModel
tokenizer = BertTokenizer . from_pretrained ( "MODEL_NAME" )
model = BertModel . from_pretrained ( "MODEL_NAME" ) Соответствующий список MODEL_NAME заключается в следующем:
| Название модели | Model_name |
|---|---|
| Китайский-пройд | HFL/китайский промежуточный |
| Китайская база | HFL/китайская база |
| Китайский-заполняющий-MRC | HFL/китайский-первая-большая-MRC |
| Китайский-пертец-баз-MRC | HFL/китайская-первая база-MRC |
| Английский-заполненный | HFL/English-Pert-Large |
| Английская первая база | HFL/английская база |
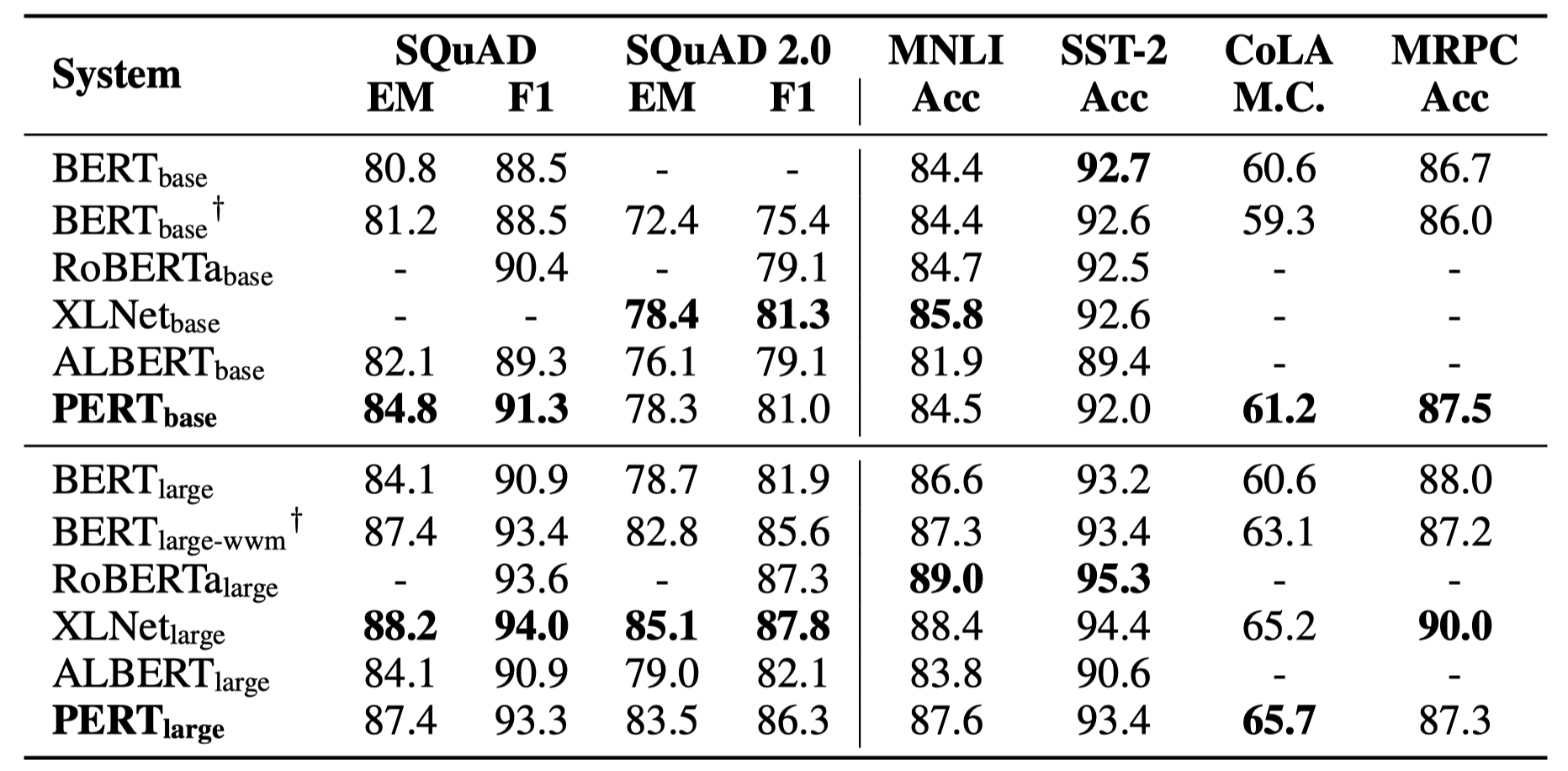
Только некоторые экспериментальные результаты перечислены ниже. См. Документ для подробных результатов и анализа. В таблице экспериментальных результатов максимальное значение вне кронштейнов - это среднее значение внутри скобков.
Тесты эффективности были выполнены в следующих 10 задачах.
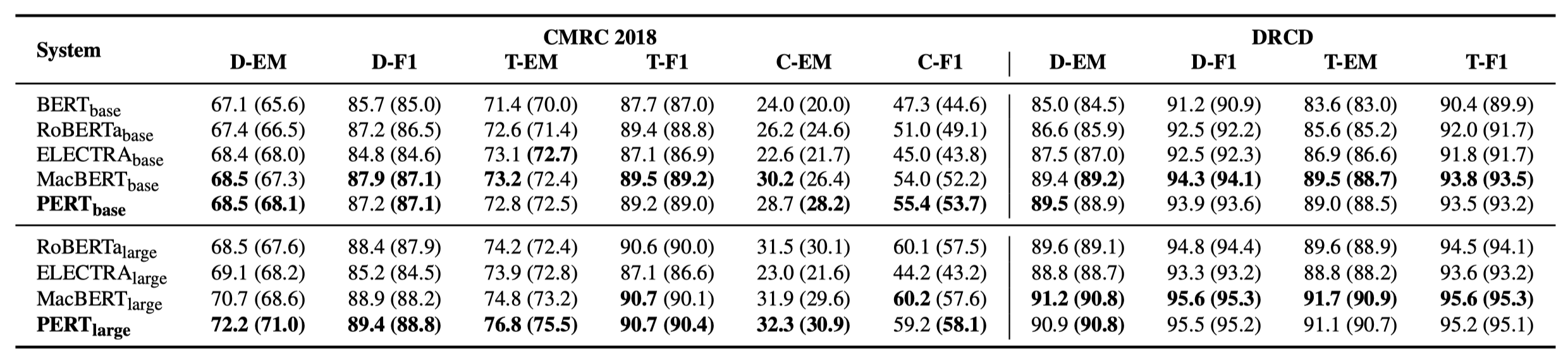
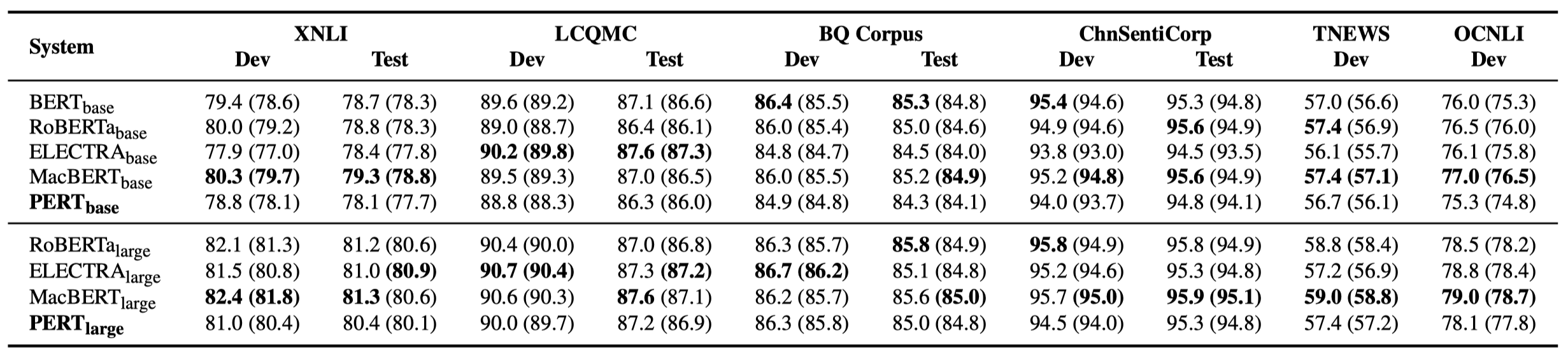
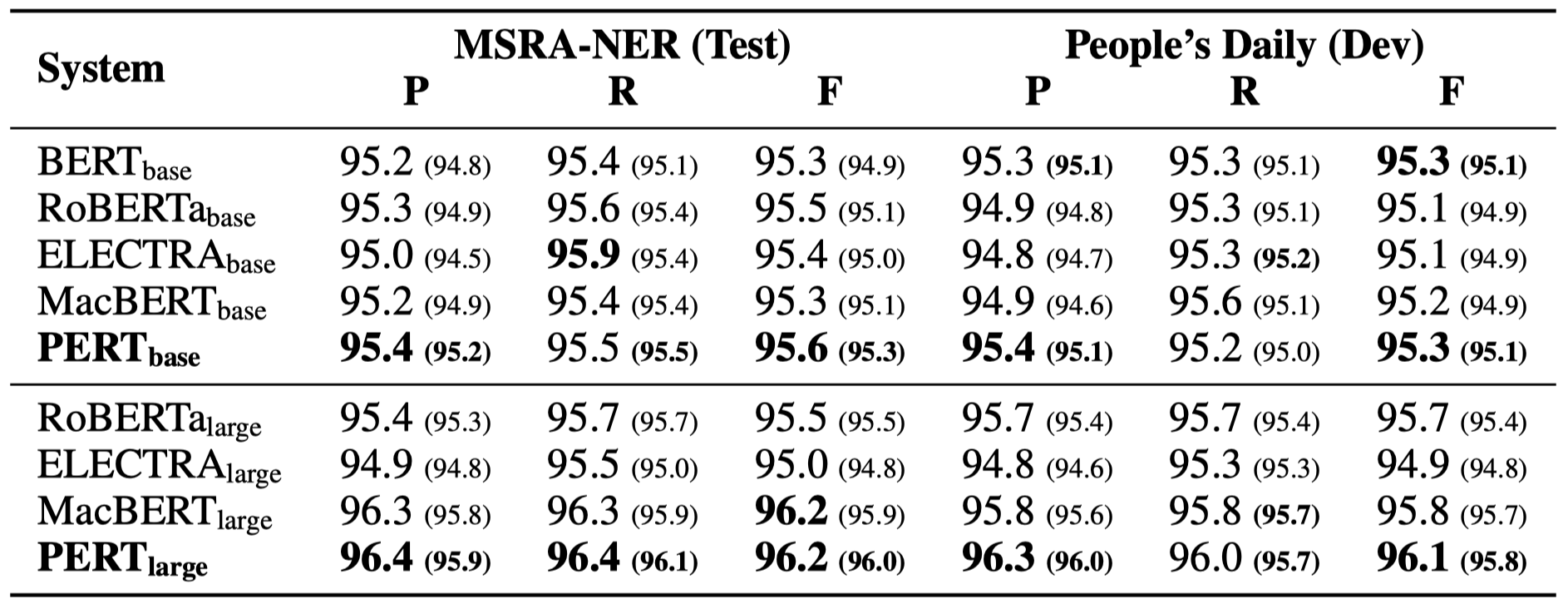
В дополнение к вышеуказанным задачам мы также проверили задачи вне порядка в коррекции текстовых ошибок, и эффект заключается в следующем.

Тесты эффективности были выполнены в следующих 6 задачах.
Q1: О весте версии с открытым исходным кодом
A1: Версия с открытым исходным кодом содержит только веса трансформаторной части, которая может быть непосредственно использовать для тонкой настройки в нижнем потоке или начальных весов вторичного предварительного обучения других предварительно обученных моделей. Оригинальные веса версии TF могут содержать случайно инициализированные веса MLM. Это для:
Q2: о влиянии PERT на нижестоящие задачи
A2: Предварительный вывод заключается в том, что он имеет лучшие результаты в таких задачах, как понимание прочитанного и маркировка последовательности, но плохие результаты в задачах классификации текста. Пожалуйста, попробуйте конкретные результаты по собственным задачам. Для получения подробной информации, пожалуйста, обратитесь к нашей статье: https://arxiv.org/abs/2203.06906
Если модели или связанные выводы в этом проекте полезны для вашего исследования, укажите следующую статью: https://arxiv.org/abs/2203.06906
@article{cui2022pert,
title={PERT: Pre-training BERT with Permuted Language Model},
author={Cui, Yiming and Yang, Ziqing and Liu, Ting},
year={2022},
eprint={2203.06906},
archivePrefix={arXiv},
primaryClass={cs.CL}
}Добро пожаловать, чтобы следить за официальным официальным отчетом WeChat об Объединенной лаборатории Iflytek, чтобы узнать о последних технических тенденциях.

Если у вас есть какие -либо вопросы, пожалуйста, отправьте их в выпуске GitHub.


