PERT
1.0.0
الصينية | إنجليزي

في مجال معالجة اللغة الطبيعية ، أصبحت نماذج اللغة التي تم تدريبها مسبقًا (PLMs) تقنية أساسية مهمة للغاية. في العامين الماضيين ، أصدر مختبر Iflytek المشترك مجموعة متنوعة من موارد نموذج ما قبل التدريب الصينية وأدوات الدعم ذات الصلة. كاستمرار للعمل ذي الصلة ، في هذا المشروع ، نقترح نموذجًا مدربًا مسبقًا (PERT) استنادًا إلى نموذج اللغة خارج الترتيب والذي تم التعلم ذاتيًا للمعلومات الدلالية النصية دون تقديم علامة قناع [القناع]. حقق PERT تحسينات في الأداء على بعض مهام NLU الصينية والإنجليزية ، ولكن لديها أيضًا نتائج سيئة في بعض المهام. الرجاء استخدامه حسب الاقتضاء. حاليًا ، يتم توفير نماذج PERT باللغة الصينية والإنجليزية ، بما في ذلك أحجام النماذج (قاعدة ، كبيرة).
ليرت الصينية | اللغة الإنجليزية الصينية بيرت | صينية ماكبرت | إلكترا الصينية | صينية XLNET | بيرت الصينية | أداة التقطير المعرفة TextBrewer | أداة قطع النموذج TextPruner
شاهد المزيد من الموارد التي أصدرها IFL من معهد Harbin للتكنولوجيا (HFL): https://github.com/ymcui/hfl-anthology
2023/3/28 Open Source Chinese Llama & Alpaca Big Model ، والذي يمكن نشره بسرعة وتجربته على الكمبيوتر الشخصي ، عرض: https://github.com/ymcui/Chinese-llama-alpaca
2022/10/29 نقترح LERT النموذج الذي تم تدريبه مسبقًا يدمج المعلومات اللغوية. عرض: https://github.com/ymcui/lert
2022/5/7 تم تحديثه لفهم القراءة الخاص بتواضع تم ضبطه بدقة على مجموعات بيانات فهم القراءة المتعددة ، وقدم عرضًا تفاعليًا على الإنترنت ، تحقق: تنزيل النموذج
2022/3/15 تم إصدار التقرير الفني ، يرجى الرجوع إلى: https://arxiv.org/abs/2203.06906
2022/2/24 تم إصدار Pert-Base و Pert-Large باللغة الصينية والإنجليزية. يمكنك التحميل مباشرة باستخدام بنية BERT وأداء المهام المصب. سيتم إصدار التقرير الفني بعد الانتهاء ، ومن المتوقع أن يكون الوقت في منتصف مارس. شكرا لك على صبرك.
2022/2/17 ، شكرًا على اهتمامك بهذا المشروع. من المتوقع إصدار النموذج الأسبوع المقبل ، وسيتم إصدار التقرير الفني بعد التحسن.
| الفصل | يصف |
|---|---|
| مقدمة | المبدأ الأساسي لنموذج PERT مسبقًا |
| تنزيل النموذج | تنزيل عنوان النموذج الذي تم تدريبه مسبقًا |
| تحميل سريع | كيفية استخدام المحولات بسرعة تحميل النماذج |
| تأثيرات نظام الأساس | تأثيرات نظام خط الأساس على بعض مهام NLU الصينية والإنجليزية |
| التعليمات | الأسئلة الشائعة والإجابات |
| يقتبس | التقرير الفني لهذا المشروع |
ينقسم تعلم النماذج المسبقة لفهم اللغة الطبيعية (NLU) تقريبًا إلى فئتين: استخدام نص الإدخال وعدم استخدامه مع وضع علامة القناع [قناع].
مستوحاة من الخوارزمية: لا تؤثر درجة معينة من النص خارج الترتيب على الفهم. فهل يمكننا تعلم المعرفة الدلالية من النصوص خارج الترتيب؟
الفكرة العامة: تؤدي PERT إلى تبديل ترتيب كلمة معين على نص الإدخال الأصلي ، وبالتالي تكوين نص خارج الترتيب (لذلك لا يتم تقديم علامات إضافية [قناع]). الهدف التعليمي لـ PERT هو التنبؤ بموقع الرمز المميز الأصلي ، انظر المثال التالي.
| يوضح | أدخل النص | هدف الإخراج |
|---|---|---|
| النص الأصلي | تظهر الأبحاث أن ترتيب هذه الجملة لا يؤثر على القراءة. | - |
| WordPiece Word النعت | تظهر الأبحاث أن ترتيب هذه الجملة لا يؤثر على القراءة. | - |
| بيرت | تظهر الأبحاث أن هذه الجملة [القناع] لا تبدو مثل القراءة. | الموضع 7 ← موضع الهاتف 10 ← موضع التسلسل 13 ← الظل |
| بيرت | ترتيب هذه الجملة لا يؤثر على القراءة . | الموضع 2 (ضيق) → الموضع 3 (الجدول) الموضع 3 (الجدول) → الموضع 2 (ضيق) الموضع 13 (الرنين) → الموضع 14 (الظل) الموضع 14 (فيلم) → الموضع 13 (الرنين) |
فيما يلي هيكله الأساسي وتنسيق الإدخال والإخراج لنموذج PERT في مرحلة ما قبل التدريب (ملاحظة: الصور في التقرير الفني ARXIV غير صحيحة حاليًا ، يرجى الرجوع إلى الصور التالية. في المرة التالية التي يتم فيها تحديث الورقة ، سيتم استبدالها بالصورة الصحيحة.).
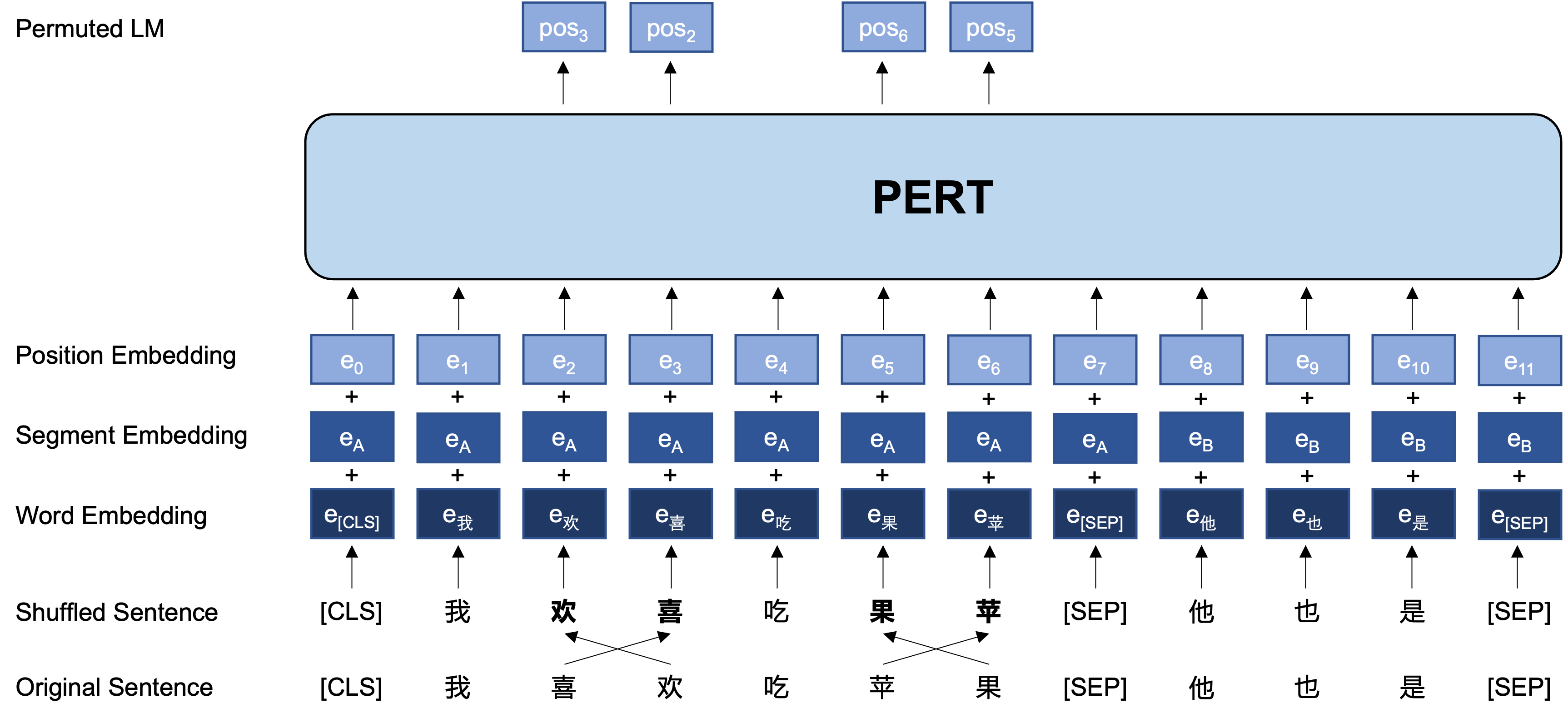
نحن هنا نقدم بشكل أساسي أوزان نموذج TensorFlow الإصدار 1.15. إذا كنت بحاجة إلى إصدار Pytorch أو TensorFlow2 من النموذج ، فيرجى الاطلاع على القسم التالي.
يحتوي الإصدار المفتوح المصدر فقط على أوزان جزء المحول ، والذي يمكن استخدامه مباشرة لضرب المهام المصب ، أو الأوزان الأولية للتدريب الثانوي لنماذج أخرى تم تدريبها مسبقًا. لمزيد من المعلومات ، انظر الأسئلة الشائعة.
PERT-large : 24 طبقة ، 1024-Hidden ، 16 رأس ، 330 متر معلماتPERT-base 12 Layer ، 768-Hidden ، 12 Heads ، 110 M Parameters| نموذج الاختصار | لغة | مواد | تنزيل Google | تنزيل قرص بايدو |
|---|---|---|---|---|
| الصينية بيرت | الصينية | بيانات EXT [1] | Tensorflow | TensorFlow (كلمة المرور: E9HS) |
| صينية بيرت | الصينية | بيانات EXT [1] | Tensorflow | TensorFlow (كلمة المرور: RCSW) |
| اللغة الإنجليزية بيرج (غير قائمة) | إنجليزي | wikibooks [2] | Tensorflow | TensorFlow (كلمة المرور: WXWI) |
| الإنجليزية pert-base (uncars) | إنجليزي | wikibooks [2] | Tensorflow | TensorFlow (كلمة المرور: 8JGQ) |
[1] تشمل بيانات EXT: ويكيبيديا الصينية ، الموسوعات الأخرى ، الأخبار ، سؤال وجواب وغيرها من البيانات ، مع إجمالي عدد الكلمات التي يصل إلى 5.4B ، تشغل حوالي 20 جرام من القرص ، مثل Macbert.
[2] Wikipedia + BookCorpus
أخذ إصدار TensorFlow من Chinese-PERT-base كمثال ، بعد تنزيل ، إلغاء ضغط ملف zip للحصول على:
chinese_pert_base_L-12_H-768_A-12.zip
|- pert_model.ckpt # 模型权重
|- pert_model.meta # 模型meta信息
|- pert_model.index # 模型index信息
|- pert_config.json # 模型参数
|- vocab.txt # 词表(与谷歌原版一致)
من بينها ، bert_config.json و vocab.txt تمامًا مثل BERT-base, Chinese الأصلي من Google (الإصدار الإنجليزي يتوافق مع الإصدار المعتمد على Bert).
يمكن تنزيل نماذج TensorFlow (V2) و Pytorch من خلال مكتبة Transformers Model.
طريقة التنزيل: انقر فوق أي طراز تريد تنزيله → حدد علامة التبويب "الملفات والإصدارات" → قم بتنزيل ملف النموذج المقابل.
| نموذج الاختصار | حجم ملف النموذج | عنوان مكتبة نموذج المحولات |
|---|---|---|
| الصينية بيرت | 1.2 جم | https://huggingface.co/hfl/chinese-pert-large |
| صينية بيرت | 0.4 جم | https://huggingface.co/hfl/chinese-pert-base |
| الصينية pert-large-mrc | 1.2 جم | https://huggingface.co/hfl/chinese-pert-large-mrc |
| الصينية pert-base-mrc | 0.4 جم | https://huggingface.co/hfl/chinese-pert-base-mrc |
| الإنجليزية بيرت | 1.2 جم | https://huggingface.co/hfl/english-pert-large |
| الإنجليزية pert-base | 0.4 جم | https://huggingface.co/hfl/english-pert-base |
نظرًا لأن جزء Pert Body لا يزال بنية Bert ، يمكن للمستخدمين الاتصال بسهولة بنموذج PERT باستخدام مكتبة Transformers.
ملاحظة: يتم تحميل جميع النماذج في هذا الدليل باستخدام BertTokenizer و BertModel (تستخدم نماذج MRC BertForQuestionAment).
from transformers import BertTokenizer , BertModel
tokenizer = BertTokenizer . from_pretrained ( "MODEL_NAME" )
model = BertModel . from_pretrained ( "MODEL_NAME" ) القائمة المقابلة لـ MODEL_NAME هي كما يلي:
| اسم النموذج | model_name |
|---|---|
| الصينية بيرت | HFL/صينية بيرت |
| صينية بيرت | HFL/الصينية pert-base |
| الصينية pert-large-mrc | HFL/الصينية pert-large-mrc |
| الصينية pert-base-mrc | HFL/الصينية pert-base-mrc |
| الإنجليزية بيرت | HFL/English-Pert-Large |
| الإنجليزية pert-base | HFL/English-pert-base |
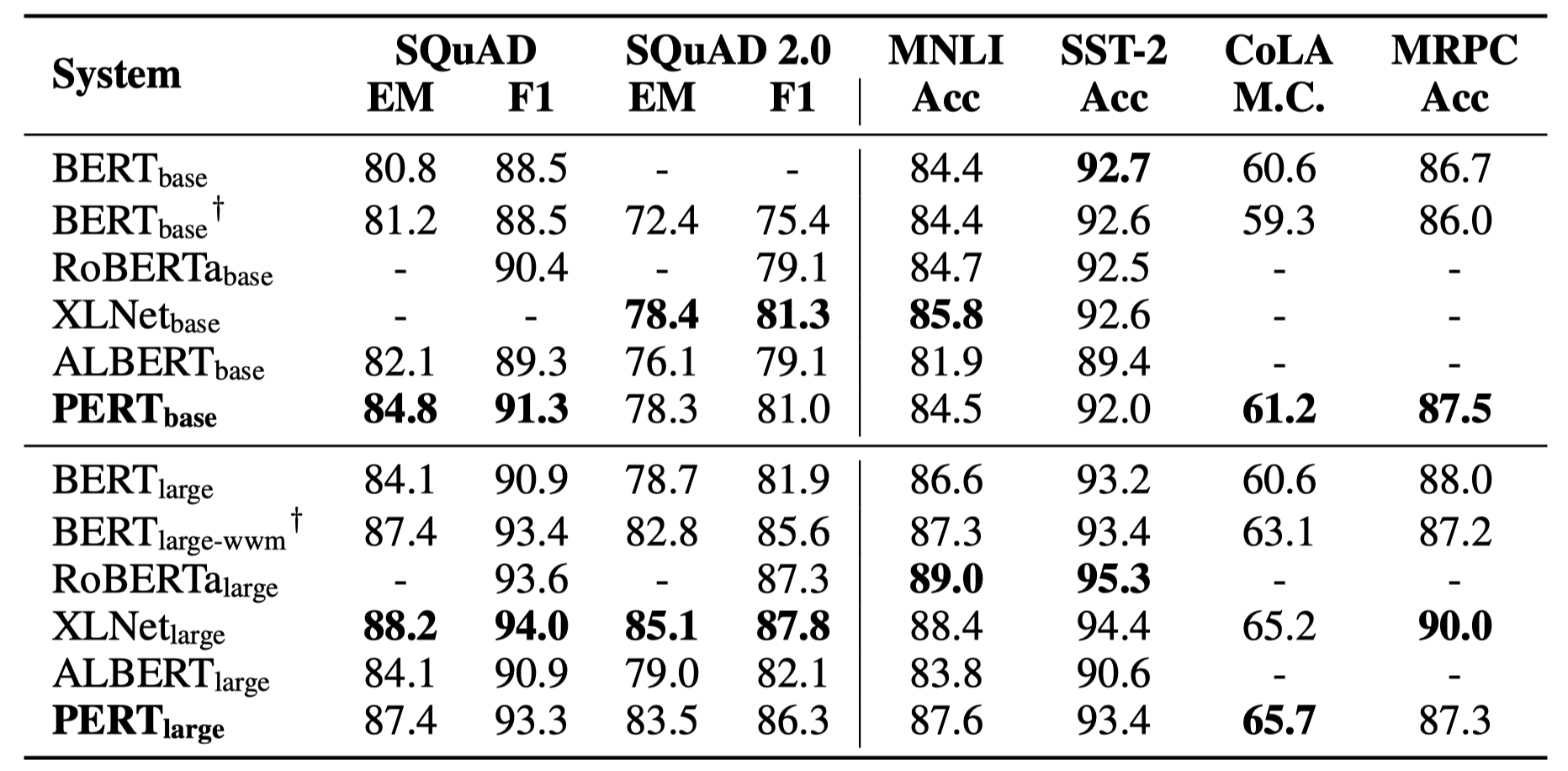
يتم سرد بعض النتائج التجريبية فقط أدناه. انظر الورقة للحصول على نتائج مفصلة والتحليل. في جدول النتائج التجريبية ، فإن الحد الأقصى للقيمة خارج الأقواس هو متوسط القيمة داخل الأقواس.
تم إجراء اختبارات الفعالية في المهام العشرة التالية.
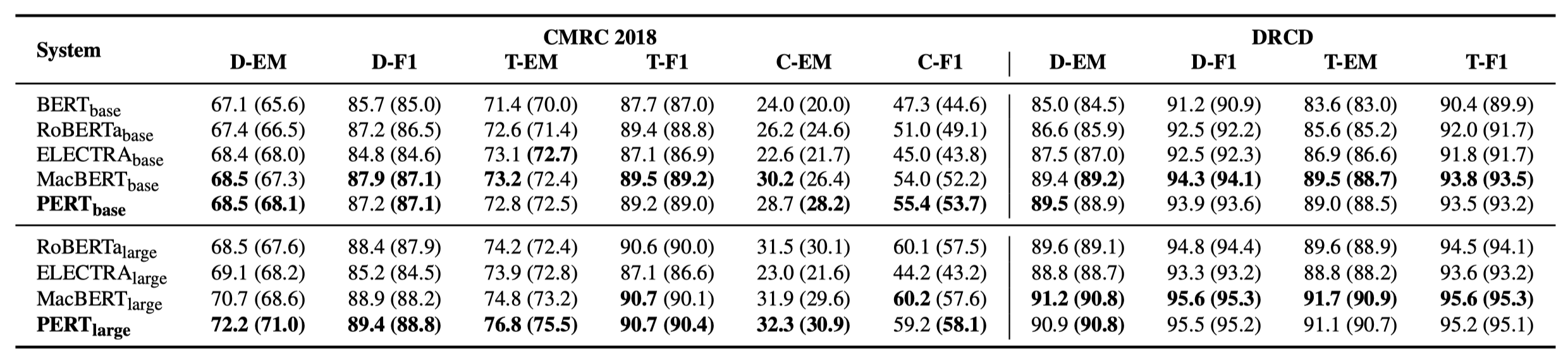
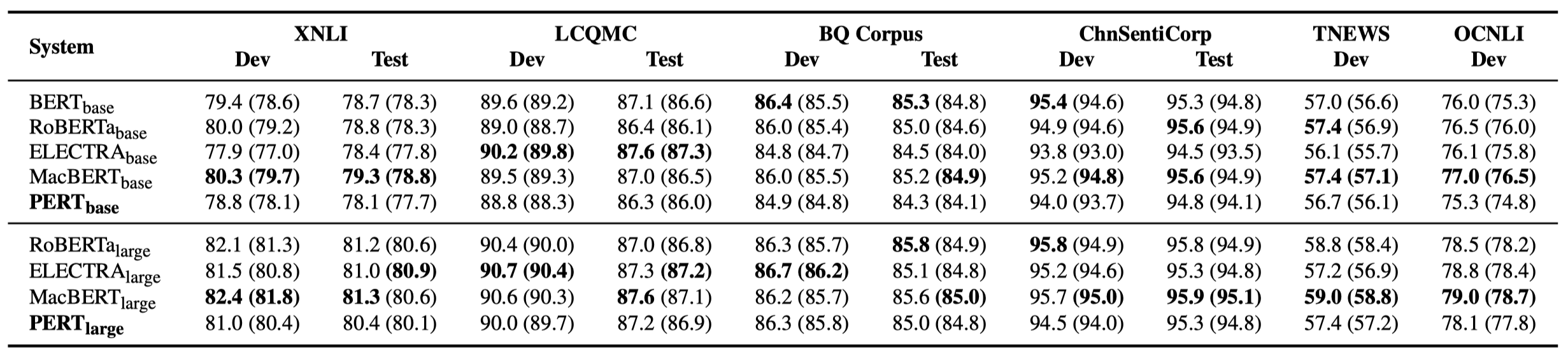
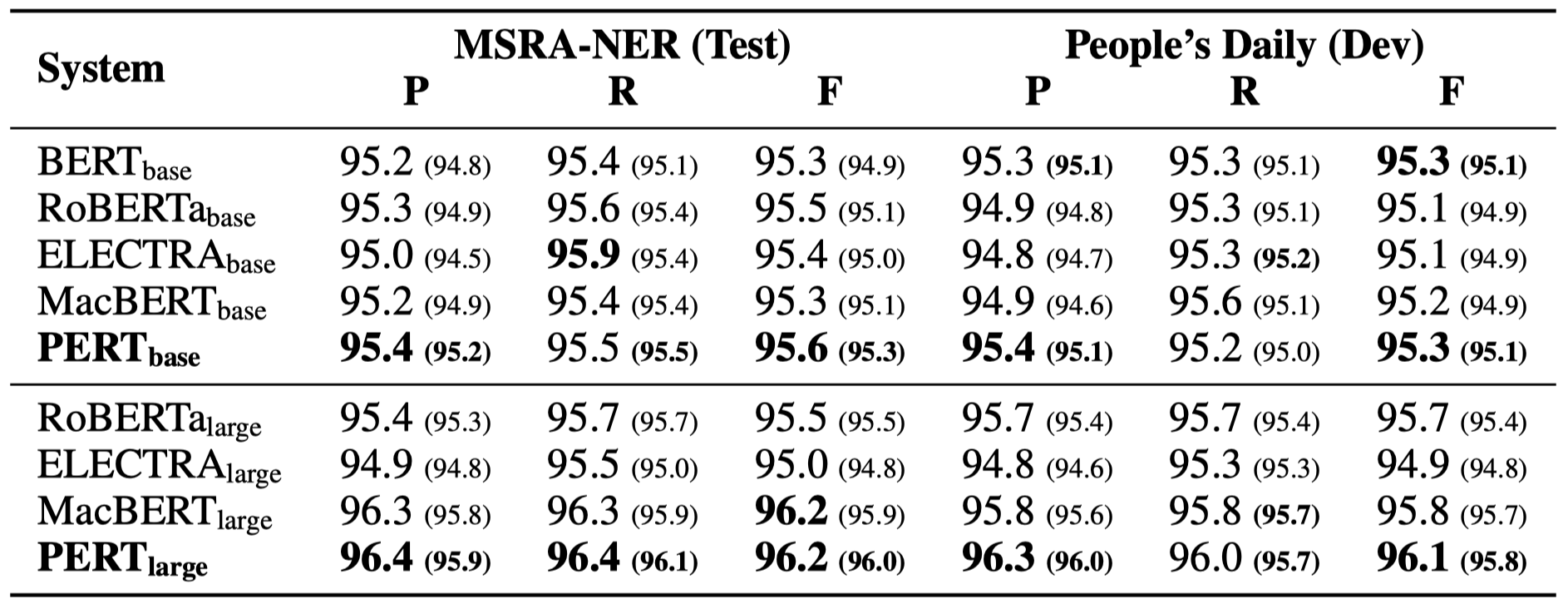
بالإضافة إلى المهام المذكورة أعلاه ، قمنا أيضًا باختبار المهام خارج الترتيب في تصحيح خطأ النص ، والتأثير كما يلي.

تم إجراء اختبارات الفعالية في المهام الست التالية.
س 1: حول وزن الإصدار مفتوح المصدر من بيرت
A1: يحتوي الإصدار المفتوح المصدر فقط على أوزان جزء المحول ، والذي يمكن استخدامه مباشرة في صقل المهام المصب ، أو الأوزان الأولية للتدريب الثانوي لنماذج أخرى تم تدريبها. قد تحتوي أوزان إصدار TF الأصلية على أوزان MLM تهيئة عشوائيًا . هذا من أجل:
س 2: حول تأثير بيرت على مهام المصب
A2: الاستنتاج الأولي هو أنه يحظى بنتائج أفضل في مهام مثل فهم القراءة ووضع تسلسل ، ولكن النتائج السيئة في مهام تصنيف النص. يرجى تجربة النتائج المحددة في مهامك. للحصول على تفاصيل ، يرجى الرجوع إلى ورقتنا: https://arxiv.org/abs/2203.06906
إذا كانت النماذج أو الاستنتاجات ذات الصلة في هذا المشروع مفيدة لبحثك ، فيرجى الاستشهاد بالمقالة التالية: https://arxiv.org/abs/2203.06906
@article{cui2022pert,
title={PERT: Pre-training BERT with Permuted Language Model},
author={Cui, Yiming and Yang, Ziqing and Liu, Ting},
year={2022},
eprint={2203.06906},
archivePrefix={arXiv},
primaryClass={cs.CL}
}مرحبًا بك لمتابعة الحساب الرسمي الرسمي لـ WeChat لمختبر Iflytek المشترك للتعرف على أحدث الاتجاهات الفنية.

إذا كان لديك أي أسئلة ، فيرجى إرسالها في قضية GitHub.


