PERT
1.0.0
Chinese | English

In the field of natural language processing, pre-trained language models (PLMs) have become a very important basic technology. In the past two years, IFLYTEK Joint Laboratory has released a variety of Chinese pre-training model resources and related supporting tools. As a continuation of related work, in this project, we propose a pre-trained model (PERT) based on out-of-order language model that self-supervised learning of text semantic information without introducing mask mark [MASK]. PERT has achieved performance improvements on some Chinese and English NLU tasks, but it also has poor results on some tasks. Please use it as appropriate. Currently, PERT models are provided in Chinese and English, including two model sizes (base, large).
Chinese LERT | Chinese English PERT | Chinese MacBERT | Chinese ELECTRA | Chinese XLNet | Chinese BERT | Knowledge distillation tool TextBrewer | Model cutting tool TextPruner
See more resources released by iFL of Harbin Institute of Technology (HFL): https://github.com/ymcui/HFL-Anthology
2023/3/28 Open source Chinese LLaMA&Alpaca big model, which can be quickly deployed and experienced on PC, view: https://github.com/ymcui/Chinese-LLaMA-Alpaca
2022/10/29 We propose a pre-trained model LERT that integrates linguistic information. View: https://github.com/ymcui/LERT
2022/5/7 Updated a special reading comprehension PERT finely tuned on multiple reading comprehension datasets, and provided a huggingface online interactive demo, check: model download
2022/3/15 The technical report has been released, please refer to: https://arxiv.org/abs/2203.06906
2022/2/24 PERT-base and PERT-large in Chinese and English have been released. You can directly load using the BERT structure and perform downstream tasks fine-tuning. The technical report will be issued after completion, and the time is expected to be in mid-March. Thank you for your patience.
2022/2/17 Thanks for your attention to this project. The model is expected to be issued next week, and the technical report will be issued after improvement.
| chapter | describe |
|---|---|
| Introduction | The basic principle of PERT pre-trained model |
| Model download | Download address of PERT pre-trained model |
| Quick loading | How to use Transformers quickly load models |
| Baseline system effects | Baseline system effects on some Chinese and English NLU tasks |
| FAQ | FAQs and Answers |
| Quote | Technical Report of this project |
The learning of pretrained models for natural language understanding (NLU) is roughly divided into two categories: using and not using input text with mask marking [MASK].
Algorithm inspired: A certain degree of out-of-order text does not affect understanding. So can we learn semantic knowledge from out-of-order texts?
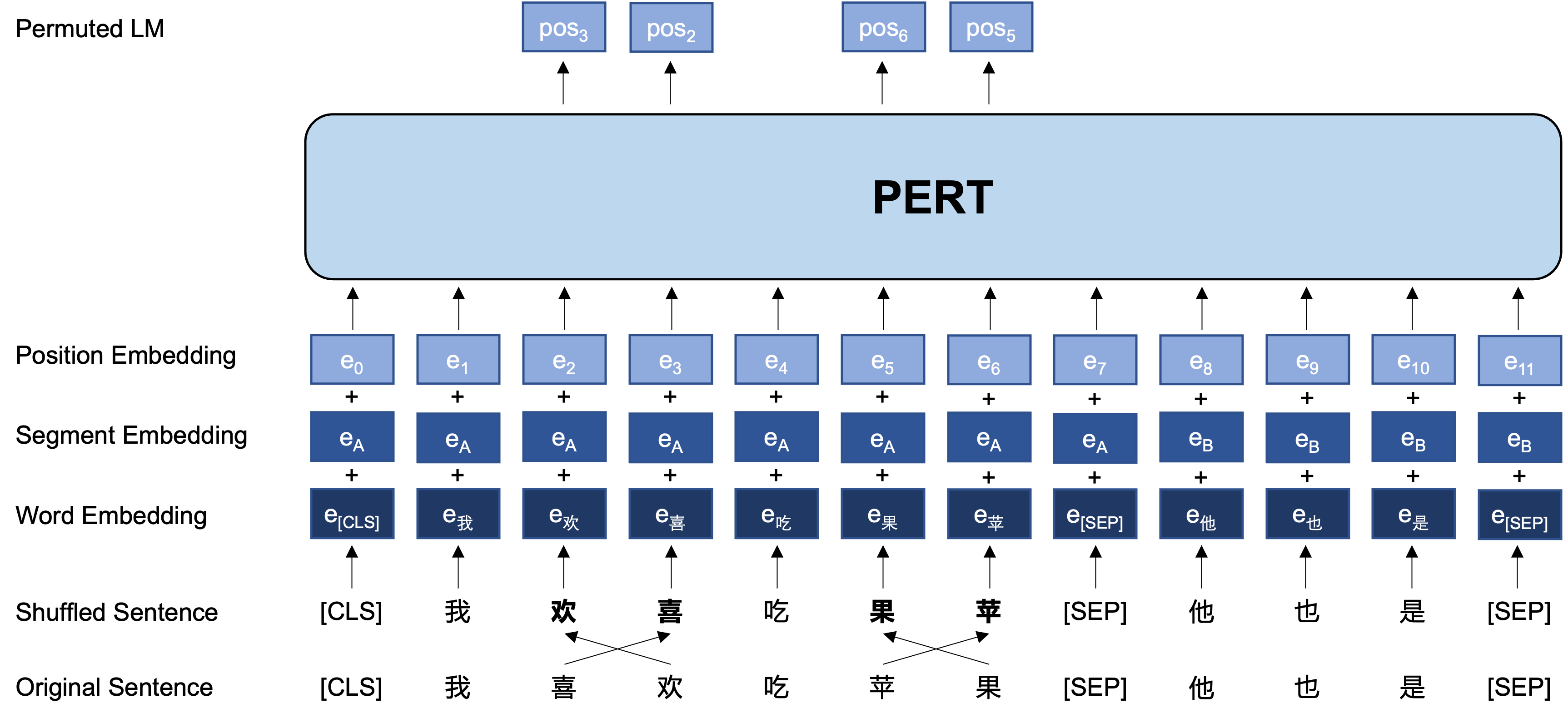
General idea: PERT performs a certain word order swap on the original input text, thus forming out-of-order text (so no additional [MASK] tags are introduced). The learning goal of PERT is to predict the location of the original token, see the following example.
| illustrate | Enter text | Output target |
|---|---|---|
| Original text | Research shows that the order of this sentence does not affect reading. | - |
| WordPiece word participle | Research shows that the order of this sentence does not affect reading. | - |
| BERT | Research shows that this sentence [MASK] does not sound like reading. | Position 7 → Phone Position 10 → Sequence Position 13 → Shadow |
| PERT | The order of this sentence does not affect reading . | Position 2 (narrow) → Position 3 (table) Position 3 (table) → Position 2 (narrow) Position 13 (resonant) → Position 14 (shadow) Position 14 (movie) → Position 13 (resonant) |
The following is the basic structure and input and output format of the PERT model in the pre-training stage (Note: The pictures in the arXiv technical report are currently incorrect, please refer to the following pictures. The next time the paper is updated, it will be replaced with the correct picture.).
Here we mainly provide the model weights of TensorFlow version 1.15. If you need a PyTorch or TensorFlow2 version of the model, please see the next section.
The open source version only contains the weights of the Transformer part, which can be directly used for downstream task fine-tuning, or the initial weights of secondary pre-training of other pre-trained models. For more information, see FAQ.
PERT-large : 24-layer, 1024-hidden, 16-heads, 330M parametersPERT-base 12-layer, 768-hidden, 12-heads, 110M parameters| Model abbreviation | Language | Materials | Google Download | Baidu disk download |
|---|---|---|---|---|
| Chinese-PERT-large | Chinese | EXT data [1] | TensorFlow | TensorFlow (password: e9hs) |
| Chinese-PERT-base | Chinese | EXT data [1] | TensorFlow | TensorFlow (password: rcsw) |
| English-PERT-large (uncased) | English | WikiBooks [2] | TensorFlow | TensorFlow (password: wxwi) |
| English-PERT-base (uncased) | English | WikiBooks [2] | TensorFlow | TensorFlow (password: 8jgq) |
[1] EXT data includes: Chinese Wikipedia, other encyclopedias, news, Q&A and other data, with a total number of words reaching 5.4B, occupying about 20G disk space, the same as MacBERT.
[2] Wikipedia + BookCorpus
Taking the TensorFlow version of Chinese-PERT-base as an example, after downloading, decompress the zip file to obtain:
chinese_pert_base_L-12_H-768_A-12.zip
|- pert_model.ckpt # 模型权重
|- pert_model.meta # 模型meta信息
|- pert_model.index # 模型index信息
|- pert_config.json # 模型参数
|- vocab.txt # 词表(与谷歌原版一致)
Among them, bert_config.json and vocab.txt are exactly the same as Google's original BERT-base, Chinese (the English version is consistent with the BERT-uncased version).
The TensorFlow (v2) and PyTorch version models can be downloaded through the transformers model library.
Download method: Click any model you want to download → select the "Files and versions" tab → download the corresponding model file.
| Model abbreviation | Model file size | transformers model library address |
|---|---|---|
| Chinese-PERT-large | 1.2G | https://huggingface.co/hfl/chinese-pert-large |
| Chinese-PERT-base | 0.4G | https://huggingface.co/hfl/chinese-pert-base |
| Chinese-PERT-large-MRC | 1.2G | https://huggingface.co/hfl/chinese-pert-large-mrc |
| Chinese-PERT-base-MRC | 0.4G | https://huggingface.co/hfl/chinese-pert-base-mrc |
| English-PERT-large | 1.2G | https://huggingface.co/hfl/english-pert-large |
| English-PERT-base | 0.4G | https://huggingface.co/hfl/english-pert-base |
Since the PERT body part is still a BERT structure, users can easily call the PERT model using the transformers library.
Note: All models in this directory are loaded using BertTokenizer and BertModel (MRC models use BertForQuestionAnswering).
from transformers import BertTokenizer , BertModel
tokenizer = BertTokenizer . from_pretrained ( "MODEL_NAME" )
model = BertModel . from_pretrained ( "MODEL_NAME" ) The corresponding list of MODEL_NAME is as follows:
| Model name | MODEL_NAME |
|---|---|
| Chinese-PERT-large | hfl/chinese-pert-large |
| Chinese-PERT-base | hfl/chinese-pert-base |
| Chinese-PERT-large-MRC | hfl/chinese-pert-large-mrc |
| Chinese-PERT-base-MRC | hfl/chinese-pert-base-mrc |
| English-PERT-large | hfl/english-pert-large |
| English-PERT-base | hfl/english-pert-base |
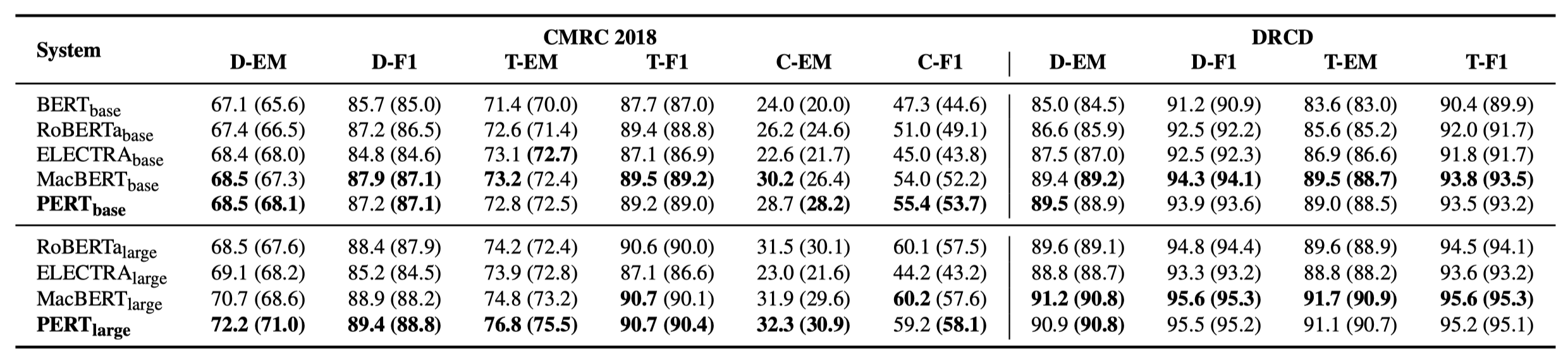
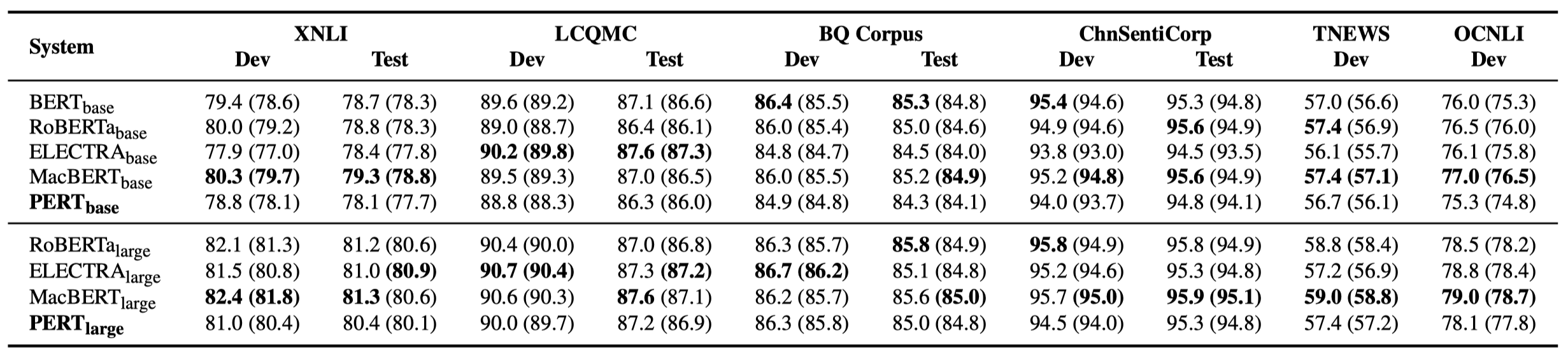
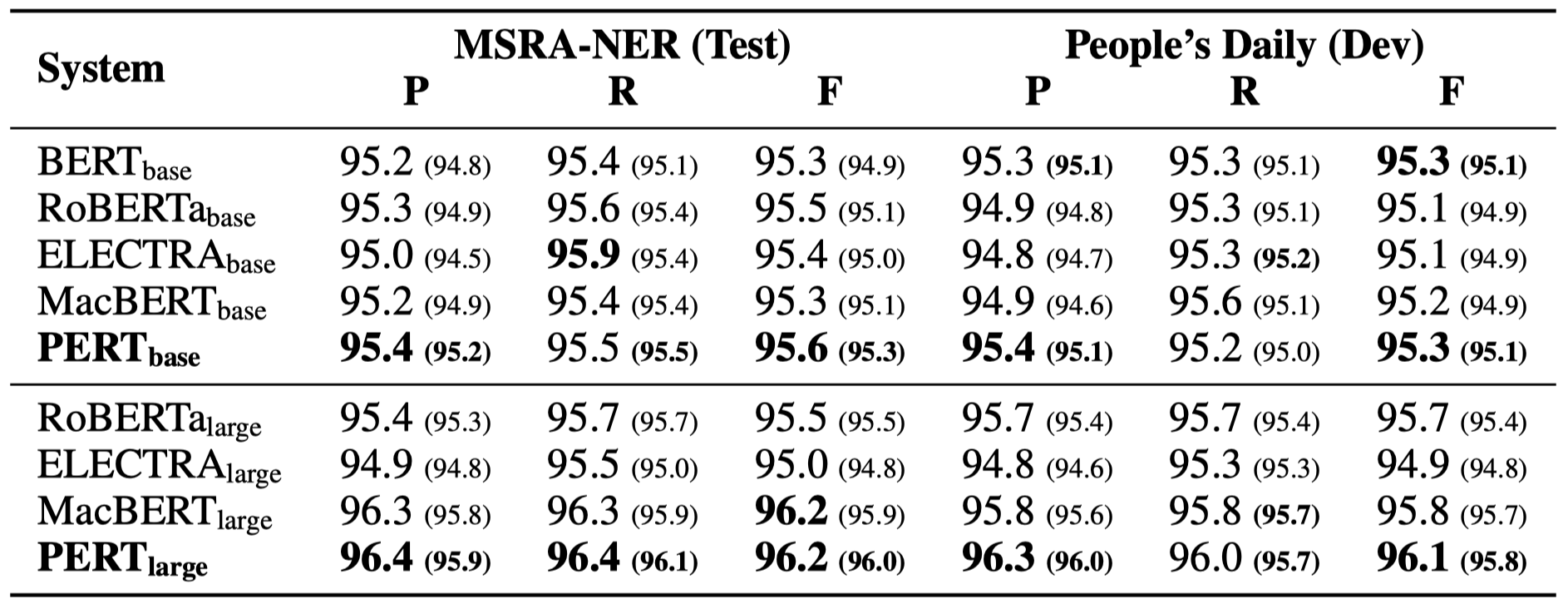
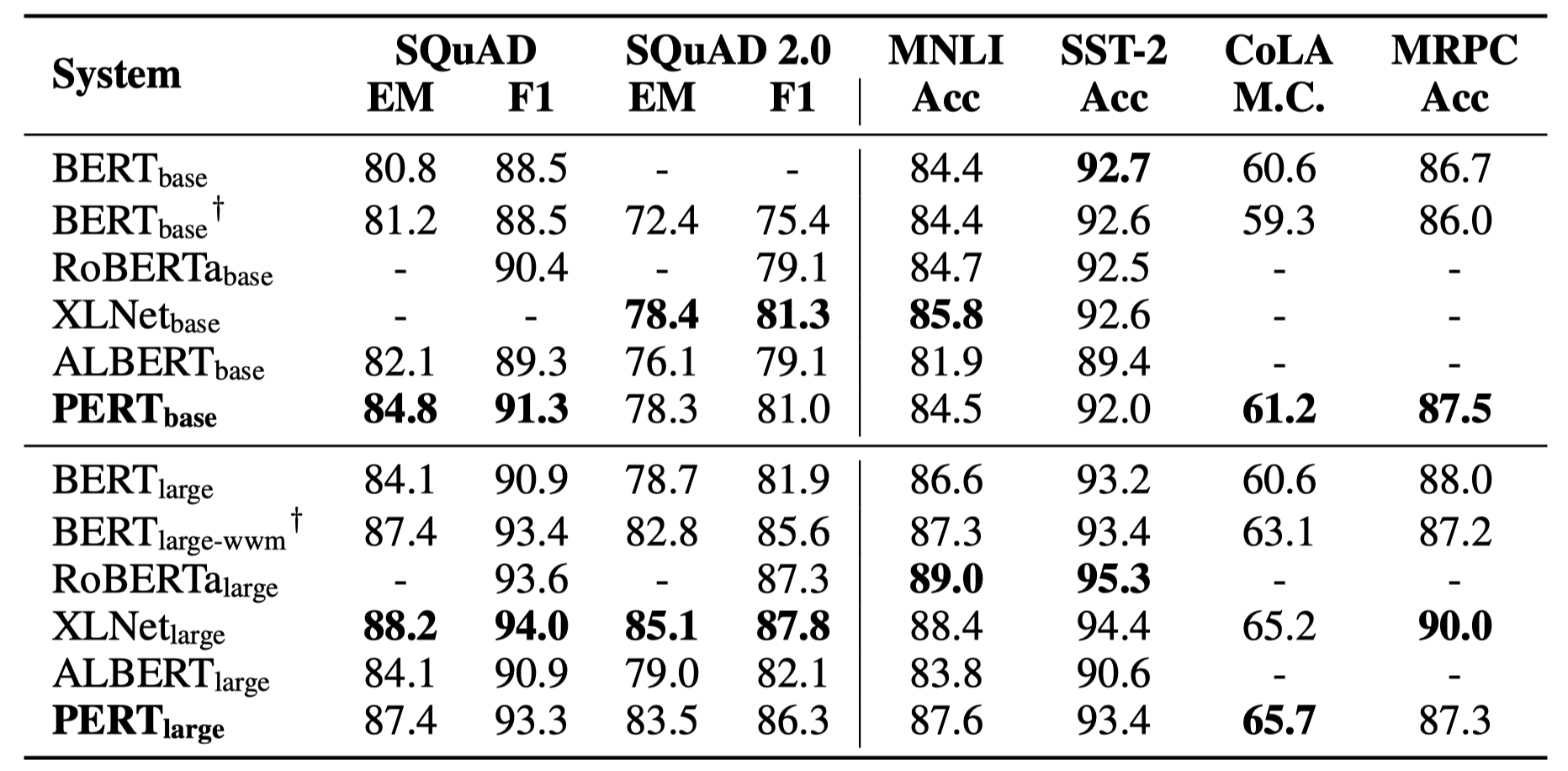
Only some experimental results are listed below. See the paper for detailed results and analysis. In the experimental results table, the maximum value outside the brackets is the average value inside the brackets.
Effectiveness tests were performed on the following 10 tasks.
In addition to the above tasks, we also tested the out-of-order tasks in text error correction, and the effect is as follows.

Effectiveness tests were performed on the following 6 tasks.
Q1: About the open source version weight of PERT
A1: The open source version only contains the weights of the Transformer part, which can be directly used for downstream task fine-tuning, or the initial weights of the secondary pre-training of other pre-trained models. The original TF version weights may contain randomly initialized MLM weights. This is for:
Q2: About the effect of PERT on downstream tasks
A2: The preliminary conclusion is that it has better results in tasks such as reading comprehension and sequence labeling, but poor results in text classification tasks. Please try the specific results on your own tasks. For details, please refer to our paper: https://arxiv.org/abs/2203.06906
If the models or related conclusions in this project are helpful for your research, please cite the following article: https://arxiv.org/abs/2203.06906
@article{cui2022pert,
title={PERT: Pre-training BERT with Permuted Language Model},
author={Cui, Yiming and Yang, Ziqing and Liu, Ting},
year={2022},
eprint={2203.06906},
archivePrefix={arXiv},
primaryClass={cs.CL}
}Welcome to follow the official WeChat official account of IFLYTEK Joint Laboratory to learn about the latest technical trends.

If you have any questions, please submit it in GitHub Issue.


