PERT
1.0.0
중국어 | 영어

자연 언어 처리 분야에서 미리 훈련 된 언어 모델 (PLM)은 매우 중요한 기본 기술이되었습니다. 지난 2 년 동안 Iflytek Joint Laboratory는 다양한 중국 사전 훈련 모델 리소스 및 관련 지원 도구를 발표했습니다. 관련 작업의 연속으로서,이 프로젝트에서, 우리는 마스크 마크 [마스크]를 소개하지 않고 텍스트 의미 론적 정보에 대한 자체 감독하는 언서 외 언어 모델을 기반으로 미리 훈련 된 모델 (PERT)을 제안합니다. Pert는 일부 중국 및 영어 NLU 작업에서 성능 향상을 달성했지만 일부 작업에 대한 결과가 좋지 않습니다. 적절하게 사용하십시오. 현재 PERT 모델은 두 가지 모델 크기 (기본, 대형)를 포함하여 중국어와 영어로 제공됩니다.
중국어 | 중국 영어 pert | 중국 맥버트 | 중국 전자 | 중국어 xlnet | 중국 버트 | 지식 증류 도구 텍스트 브루어 | 모델 절단 도구 TextPruner
HARBIN Institute of Technology (HFL)의 IFL이 발표 한 자료를 더 많이보기 : https://github.com/ymcui/hfl-anthology
2023/3/28 오픈 소스 중국 라마 & 알파카 빅 모델.
2022/10/29 우리는 언어 정보를 통합하는 미리 훈련 된 모델 lert를 제안합니다. 보기 : https://github.com/ymcui/lert
2022/5/7은 여러 읽기 이해 데이터 세트에서 미세하게 조정 된 특별 읽기 이해력을 업데이트하고 온라인 대화 형 데모를 제공했습니다. 확인 : 모델 다운로드
2022/3/15 기술 보고서가 발표되었습니다. https://arxiv.org/abs/2203.06906 참조하십시오.
2022/2/24 중국어 및 영어의 Pert-Base 및 Pert-Large가 출시되었습니다. 버트 구조를 사용하여 직접로드하고 다운 스트림 작업을 미세 조정할 수 있습니다. 기술 보고서는 완료 후 발행되며 시간은 3 월 중순에있을 것으로 예상됩니다. 인내심에 감사드립니다.
2022/2/17이 프로젝트에 주목해 주셔서 감사합니다. 이 모델은 다음 주에 발행 될 것으로 예상되며 기술 보고서는 개선 후 발행 될 예정입니다.
| 장 | 설명하다 |
|---|---|
| 소개 | PERT 미리 훈련 된 모델의 기본 원리 |
| 모델 다운로드 | PERT 미리 훈련 된 모델의 주소를 다운로드하십시오 |
| 빠른 로딩 | 변압기를 사용하는 방법은 모델을 빠르게로드합니다 |
| 기준 시스템 효과 | 일부 중국 및 영어 NLU 작업에 대한 기준 시스템 효과 |
| FAQ | FAQ와 답변 |
| 인용하다 | 이 프로젝트의 기술 보고서 |
자연 언어 이해 (NLU)를위한 사전 미리 모델에 대한 학습은 마스크 마크 [마스크]와 함께 입력 텍스트를 사용하지 않는 두 가지 범주로 대략적으로 나뉩니다.
알고리즘 영감 : 어느 정도의 주문 외부 텍스트는 이해에 영향을 미치지 않습니다. 그렇다면 우리는 순서 외 텍스트에서 의미 론적 지식을 배울 수 있습니까?
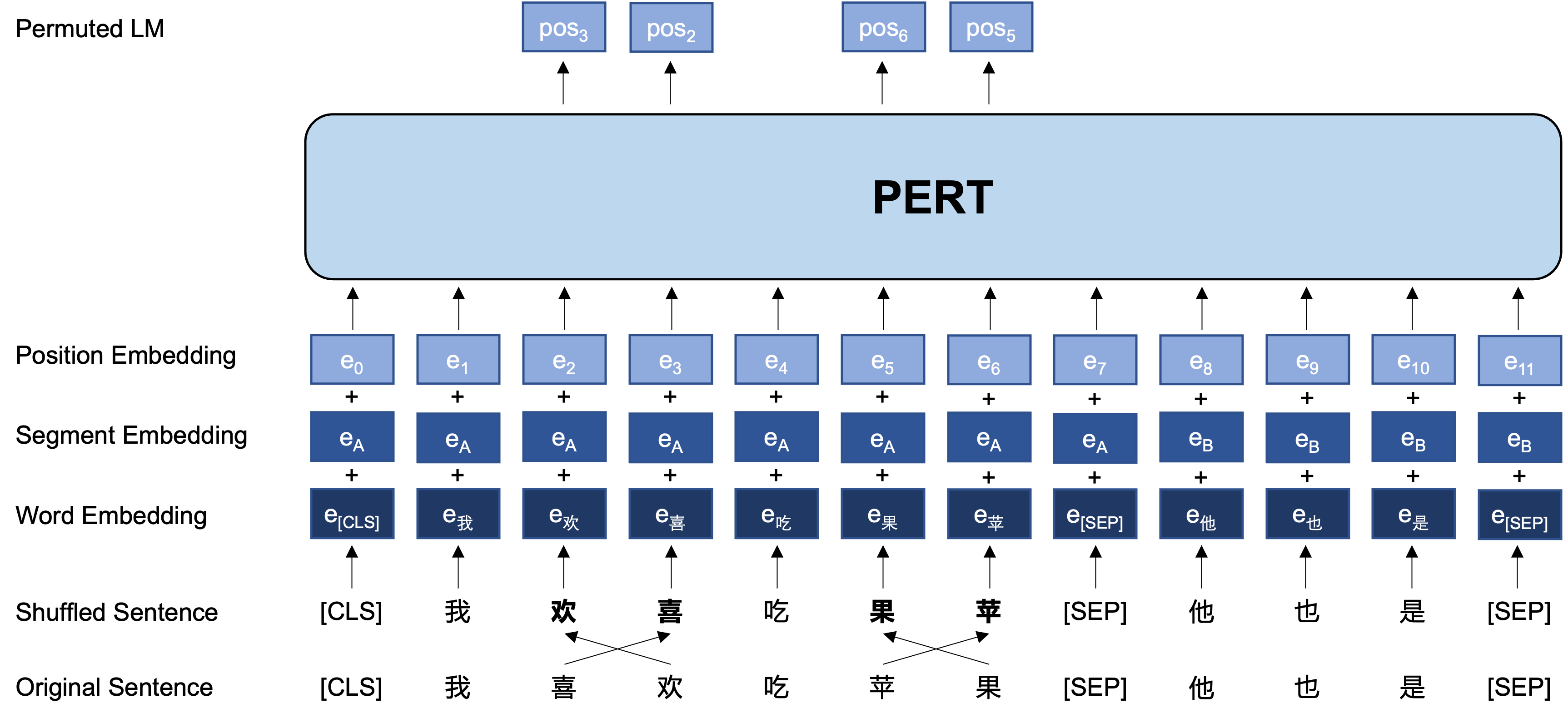
일반적인 아이디어 : PERT는 원래 입력 텍스트에서 특정 단어 순서 스왑을 수행하여 주문 외 텍스트를 형성합니다 (따라서 추가 [마스크] 태그가 소개되지 않음). Pert의 학습 목표는 원래 토큰의 위치를 예측하는 것입니다. 다음 예제를 참조하십시오.
| 설명 | 텍스트를 입력하십시오 | 출력 대상 |
|---|---|---|
| 원본 텍스트 | 연구에 따르면이 문장의 순서는 독서에 영향을 미치지 않습니다. | - |
| 단어 단어 분사 | 연구에 따르면이 문장의 순서는 독서에 영향을 미치지 않습니다. | - |
| 버트 | 연구에 따르면이 문장 [마스크]는 독서 처럼 들리지 않습니다 . | 위치 7 → 전화 위치 10 → 시퀀스 위치 13 → 그림자 |
| 건방진 | 이 문장 의 순서는 독서에 영향을 미치지 않습니다 . | 위치 2 (좁은) → 위치 3 (테이블) 위치 3 (표) → 위치 2 (좁은) 위치 13 (공명) → 위치 14 (그림자) 위치 14 (영화) → 위치 13 (공명) |
다음은 사전 훈련 단계에서 PERT 모델의 기본 구조 및 입력 및 출력 형식입니다 (참고 : ARXIV 기술 보고서의 그림은 현재 부정확합니다. 다음 그림을 참조하십시오. 다음에 논문이 업데이트되면 올바른 그림으로 대체됩니다.).
여기서 우리는 주로 Tensorflow 버전 1.15의 모델 가중치를 제공합니다. 모델의 Pytorch 또는 TensorFlow2 버전이 필요한 경우 다음 섹션을 참조하십시오.
오픈 소스 버전에는 변압기 부품의 가중치 만 포함되어 있으며 다운 스트림 작업 미세 조정에 직접 사용할 수 있으며, 다른 미리 훈련 된 모델의 2 차 사전 훈련의 초기 가중치. 자세한 내용은 FAQ를 참조하십시오.
PERT-large : 24 계층, 1024- 히든, 16 개의 헤드, 330m 매개 변수PERT-base 12 계층, 768-hidden, 12-Heads, 110m 매개 변수| 모델 약어 | 언어 | 재료 | Google 다운로드 | 바이두 디스크 다운로드 |
|---|---|---|---|---|
| 중국-거대한 | 중국인 | EXT 데이터 [1] | 텐서 플로 | 텐서 플로우 (비밀번호 : E9HS) |
| 중국-퍼트베이스 | 중국인 | EXT 데이터 [1] | 텐서 플로 | 텐서 플로우 (비밀번호 : RCSW) |
| 영어 -pert-large (uncased) | 영어 | Wikibooks [2] | 텐서 플로 | 텐서 플로우 (비밀번호 : WXWI) |
| 영어-기반 (기반) | 영어 | Wikibooks [2] | 텐서 플로 | 텐서 플로우 (비밀번호 : 8JGQ) |
[1] ext 데이터에는 다음이 포함됩니다 : 중국 Wikipedia, 기타 백과 사전, 뉴스, Q & A 및 기타 데이터는 5.4b에 도달하여 약 20g 디스크 공간을 점유하는 총 단어 수가 MacBert와 동일합니다.
[2] Wikipedia + Bookcorpus
Chinese-PERT-base 의 Tensorflow 버전을 예로 들어 다운로드 한 후 ZIP 파일을 압축 해제하여 다음을 얻습니다.
chinese_pert_base_L-12_H-768_A-12.zip
|- pert_model.ckpt # 模型权重
|- pert_model.meta # 模型meta信息
|- pert_model.index # 模型index信息
|- pert_config.json # 模型参数
|- vocab.txt # 词表(与谷歌原版一致)
그 중에서 bert_config.json 및 vocab.txt Google의 원래 BERT-base, Chinese 와 정확히 동일합니다 (영어 버전은 Bert-incased 버전과 일치합니다).
Tensorflow (v2) 및 Pytorch 버전 모델은 Transformers 모델 라이브러리를 통해 다운로드 할 수 있습니다.
다운로드 방법 : 다운로드 할 모델을 클릭하십시오 → "파일 및 버전"탭 → 해당 모델 파일 다운로드를 선택하십시오.
| 모델 약어 | 모델 파일 크기 | 변압기 모델 라이브러리 주소 |
|---|---|---|
| 중국-거대한 | 1.2g | https://huggingface.co/hfl/chinese-pert-large |
| 중국-퍼트베이스 | 0.4g | https://huggingface.co/hfl/chinese-pert-base |
| 중국어-대규모 MRC | 1.2g | https://huggingface.co/hfl/chinese-pert-large-mrc |
| 중국-퍼트베이스 -MRC | 0.4g | https://huggingface.co/hfl/chinese-pert-base-mrc |
| 영어-대단한 | 1.2g | https://huggingface.co/hfl/english-pert-large |
| 영어-기본 | 0.4g | https://huggingface.co/hfl/english-pert-base |
PERT 본체 부품은 여전히 BERT 구조이므로 사용자는 Transformers 라이브러리를 사용하여 PERT 모델을 쉽게 호출 할 수 있습니다.
참고 :이 디렉토리의 모든 모델은 Berttokenizer 및 BertModel을 사용하여로드됩니다 (MRC 모델은 Bertforquestionanswering을 사용합니다).
from transformers import BertTokenizer , BertModel
tokenizer = BertTokenizer . from_pretrained ( "MODEL_NAME" )
model = BertModel . from_pretrained ( "MODEL_NAME" ) MODEL_NAME 의 해당 목록은 다음과 같습니다.
| 모델 이름 | model_name |
|---|---|
| 중국-거대한 | HFL/중국-페트-라지 |
| 중국-퍼트베이스 | HFL/중국-퍼트베이스 |
| 중국어-대규모 MRC | HFL/중국-퍼트-래지 -MRC |
| 중국-퍼트베이스 -MRC | HFL/중국-퍼트베이스 -MRC |
| 영어-대단한 | HFL/영어 -pert-large |
| 영어-기본 | HFL/영어-기본 |
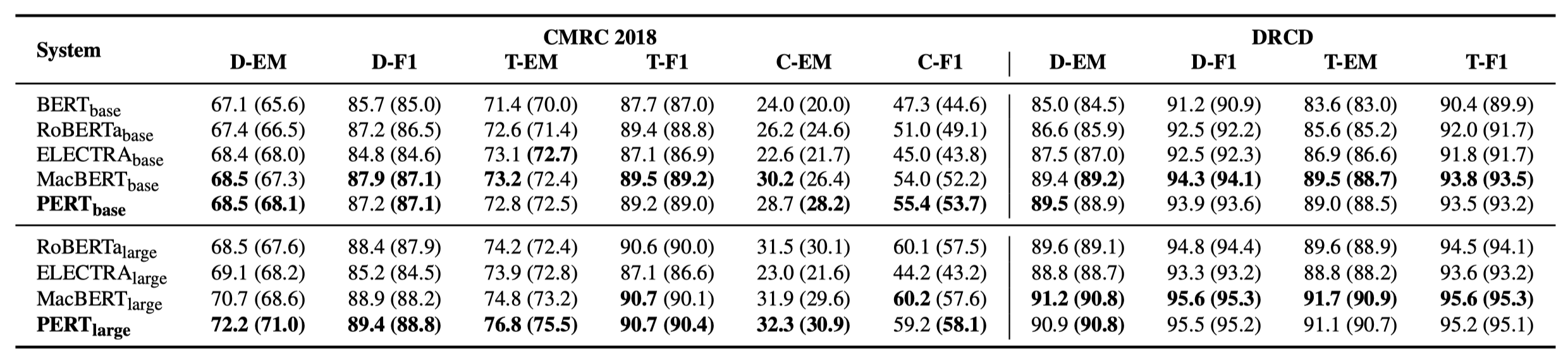
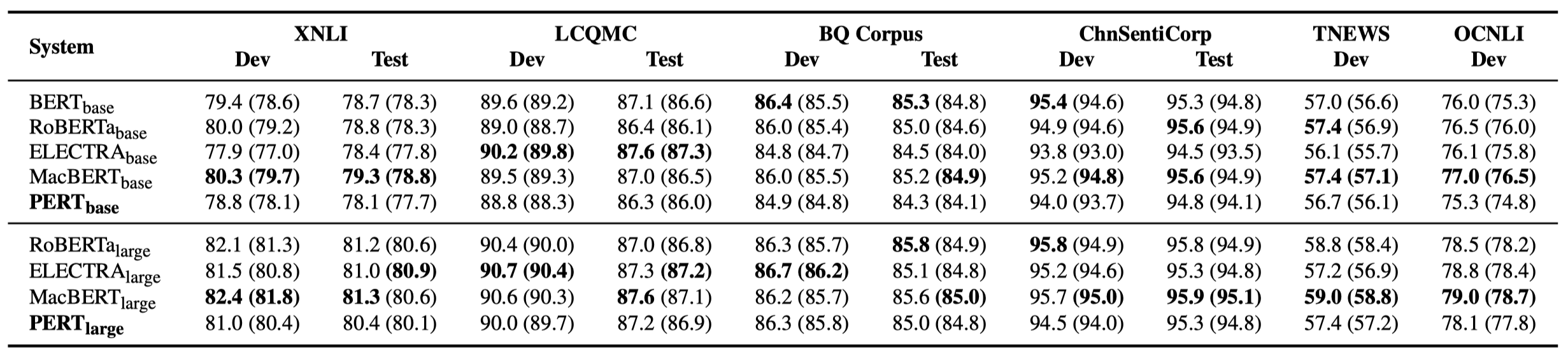
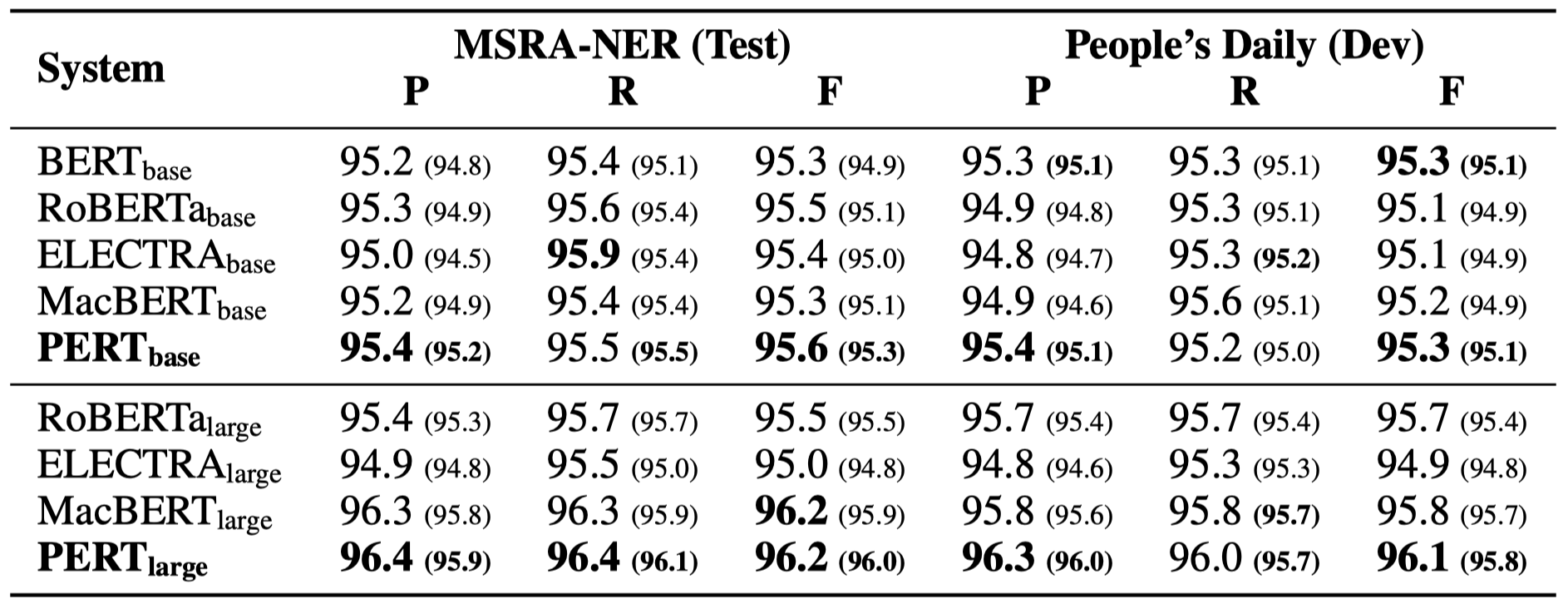
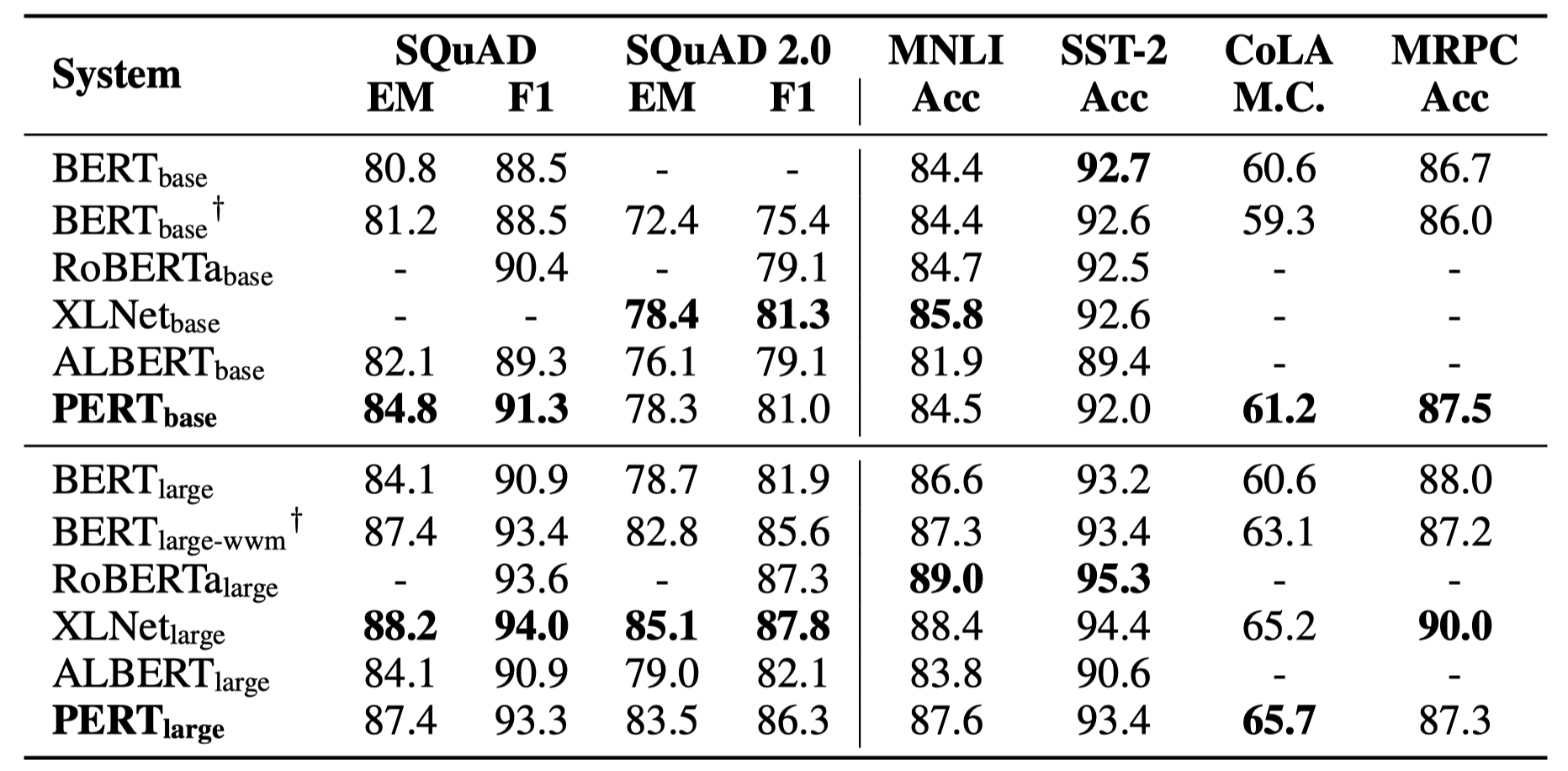
일부 실험 결과 만 아래에 나열되어 있습니다. 자세한 결과 및 분석은 논문을 참조하십시오. 실험 결과 테이블에서 괄호 외부의 최대 값은 괄호 안의 평균 값입니다.
효율성 테스트는 다음 10 가지 작업에서 수행되었습니다.
위의 작업 외에도 텍스트 오류 수정에서 외부 작업을 테스트했으며 그 효과는 다음과 같습니다.

효율성 테스트는 다음 6 가지 작업에서 수행되었습니다.
Q1 : Pert의 오픈 소스 버전 무게에 대해
A1 : 오픈 소스 버전에는 변압기 부품의 가중치 만 포함되어 있으며, 다운 스트림 작업 미세 조정에 직접 사용할 수 있으며, 다른 미리 훈련 된 모델의 보조 사전 훈련의 초기 가중치. 원래 TF 버전 가중치에는 무작위로 초기화 된 MLM 가중치가 포함될 수 있습니다. 이것은 :
Q2 : 다운 스트림 작업에 대한 PERT의 영향에 대해
A2 : 예비 결론은 독해력 및 시퀀스 라벨링과 같은 작업에서 더 나은 결과를 가져 오지만 텍스트 분류 작업이 좋지 않다는 것입니다. 자신의 작업에 대한 구체적인 결과를 시도하십시오. 자세한 내용은 당사 논문을 참조하십시오 : https://arxiv.org/abs/2203.06906
이 프로젝트의 모델 또는 관련 결론이 귀하의 연구에 도움이된다면 다음 기사를 인용하십시오. https://arxiv.org/abs/2203.06906
@article{cui2022pert,
title={PERT: Pre-training BERT with Permuted Language Model},
author={Cui, Yiming and Yang, Ziqing and Liu, Ting},
year={2022},
eprint={2203.06906},
archivePrefix={arXiv},
primaryClass={cs.CL}
}Iflytek Joint Laboratory의 공식 WeChat 공식 계정을 따라 최신 기술 트렌드에 대해 알아보십시오.

궁금한 점이 있으면 GitHub 문제로 제출하십시오.


