PERT
1.0.0
Chinês | Inglês

No campo do processamento de linguagem natural, os modelos de idiomas pré-treinados (PLMs) se tornaram uma tecnologia básica muito importante. Nos últimos dois anos, o Laboratório Conjunto de Iflytek divulgou uma variedade de recursos de modelo de pré-treinamento chinês e ferramentas de suporte relacionadas. Como continuação do trabalho relacionado, neste projeto, propomos um modelo pré-treinado (PERT) com base no modelo de idioma fora de ordem que aprendemos auto-supervisionado de informações semânticas de texto sem introduzir a marca de máscara [máscara]. A PERT alcançou melhorias de desempenho em algumas tarefas da NLU chinesa e inglesa, mas também possui maus resultados em algumas tarefas. Por favor, use -o conforme apropriado. Atualmente, os modelos PERT são fornecidos em chinês e inglês, incluindo dois tamanhos de modelo (base, grande).
Lert chinês | Pert inglesa chinesa | MacBert chinês | Electra chinês | Xlnet chinês | Bert chinês | Ferramenta de destilação do conhecimento Textbrewer | Ferramenta de corte de modelos Princinente de texto
Veja mais recursos divulgados pela IFL do Harbin Institute of Technology (HFL): https://github.com/ymcui/hfl-anthology
2023/3/28 Llama chinesa de código aberto e modelo Alpaca, que pode ser rapidamente implantado e experimentado no PC, View: https://github.com/ymcui/chinese-llama-alpaca
2022/10/29 Propomos um modelo pré-treinado Lert que integra informações linguísticas. View: https://github.com/ymcui/lert
2022/5/7 Atualizou uma compreensão especial de leitura, com sintonia finamente sintonizada em vários conjuntos de dados de compreensão de leitura e forneceu uma demonstração interativa de Huggingface Online, check: download do modelo
2022/3/15 O relatório técnico foi divulgado, consulte: https://arxiv.org/abs/2203.06906
2022/2/24 PERC-BASE e Pert-Garge em chinês e inglês foram divulgados. Você pode carregar diretamente usando a estrutura BERT e executar tarefas a jusante de ajuste fino. O relatório técnico será emitido após a conclusão, e espera-se que o tempo seja em meados de março. Obrigado por sua paciência.
2022/2/17 Obrigado pela sua atenção a este projeto. Espera -se que o modelo seja emitido na próxima semana e o relatório técnico será emitido após a melhoria.
| capítulo | descrever |
|---|---|
| Introdução | O princípio básico do modelo pré-treinado de TET |
| Download do modelo | Download Endereço do modelo pré-treinado Pert |
| Carregamento rápido | Como usar transformadores carregar modelos rapidamente |
| Efeitos da linha de base do sistema | Efeitos do sistema de linha de base em algumas tarefas da NLU chinesa e inglesa |
| Perguntas frequentes | Perguntas frequentes e respostas |
| Citar | Relatório técnico deste projeto |
O aprendizado de modelos pré -rastreados para o entendimento da linguagem natural (NLU) é dividido aproximadamente em duas categorias: usando e não usando texto de entrada com marcação de máscara [máscara].
Algoritmo inspirado: um certo grau de texto fora de ordem não afeta a compreensão. Então, podemos aprender conhecimento semântico de textos fora da ordem?
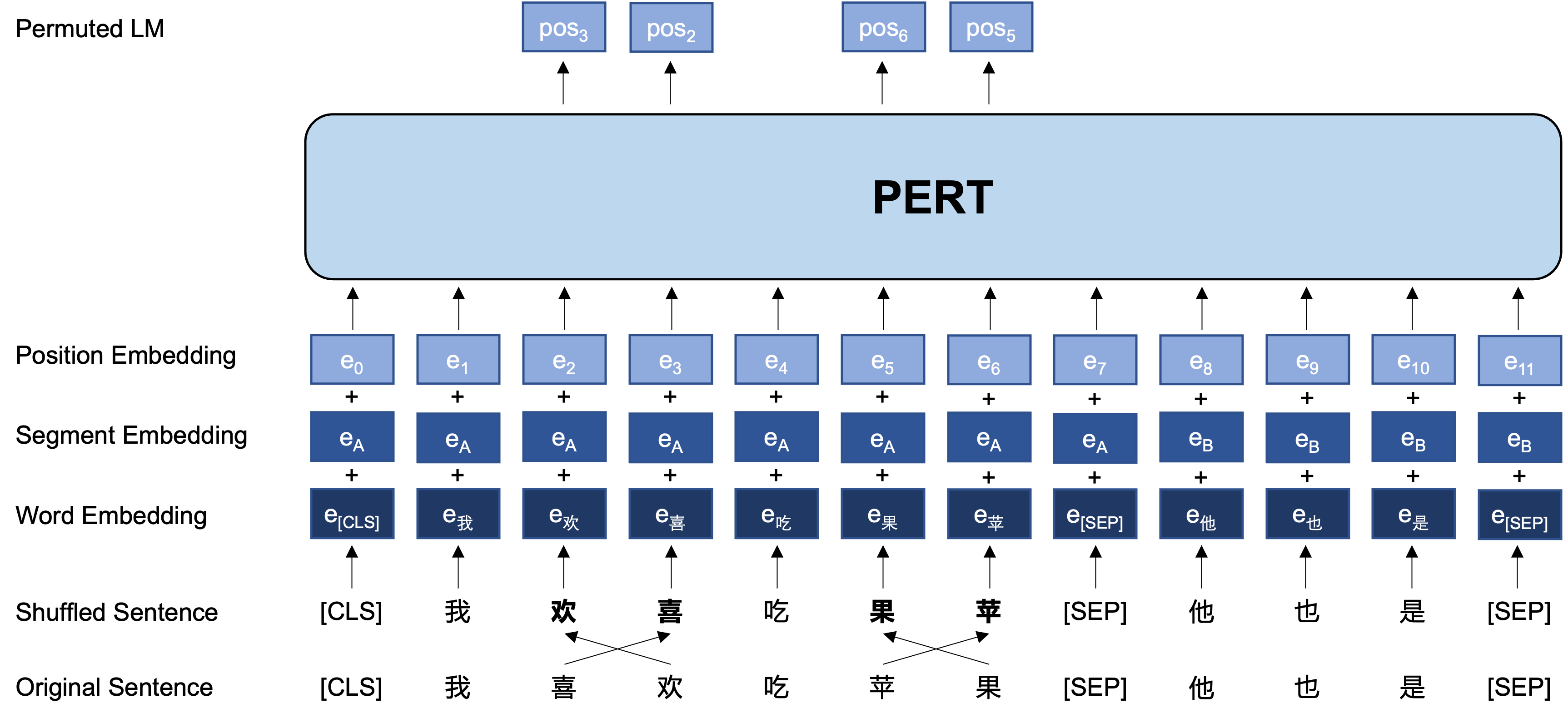
Idéia geral: o PERT executa uma certa troca de ordem de palavras no texto de entrada original, formando assim o texto fora de ordem (para que não sejam introduzidas tags adicionais [máscara]). O objetivo de aprendizado do PERT é prever a localização do token original, consulte o exemplo a seguir.
| ilustrar | Digite o texto | Alvo de saída |
|---|---|---|
| Texto original | Pesquisas mostram que a ordem desta frase não afeta a leitura. | - |
| Palavra da palavra particípio | Pesquisas mostram que a ordem desta frase não afeta a leitura. | - |
| Bert | Pesquisas mostram que essa frase [máscara] não soa como leitura. | Posição 7 → Posição do telefone 10 → Posição da sequência 13 → Shadow |
| Pert | A ordem desta frase não afeta a leitura . | Posição 2 (estreita) → Posição 3 (Tabela) Posição 3 (Tabela) → Posição 2 (estreita) Posição 13 (ressonante) → Posição 14 (sombra) Posição 14 (filme) → Posição 13 (ressonante) |
A seguir, a estrutura básica e o formato de entrada e saída do modelo PERT no estágio de pré-treinamento (Nota: As imagens no relatório técnico do ARXIV estão atualmente incorretas, consulte as figuras a seguir. Na próxima vez que o documento for atualizado, ele será substituído pela imagem correta.).
Aqui, fornecemos principalmente os pesos do modelo do Tensorflow versão 1.15. Se você precisar de uma versão pytorch ou tensorflow2 do modelo, consulte a próxima seção.
A versão de código aberto contém apenas os pesos da parte do transformador, que podem ser usados diretamente para o ajuste fino da tarefa a jusante ou os pesos iniciais do pré-treinamento secundário de outros modelos pré-treinados. Para mais informações, consulte as perguntas frequentes.
PERT-large : parâmetros de 24 camadas, 1024 ocultos, 16 cabeças, 330mPERT-base 12 camadas, 768 parâmetros de 12 cabeças, 110m| Abreviação de modelo | Linguagem | Materiais | Download do Google | Download do disco Baidu |
|---|---|---|---|---|
| Chinês-Pert-Large | chinês | Dados ext [1] | Tensorflow | Tensorflow (senha: E9HS) |
| Base Chinesa-Pert | chinês | Dados ext [1] | Tensorflow | Tensorflow (senha: RCSW) |
| Inglês-pert-grande (não baseado) | Inglês | Wikibooks [2] | Tensorflow | Tensorflow (senha: WXWI) |
| Inglês-Pert-Base (não baseado) | Inglês | Wikibooks [2] | Tensorflow | Tensorflow (senha: 8JGQ) |
[1] Os dados EXT incluem: Wikipedia chinesa, outras enciclopédias, notícias, perguntas e respostas e outros dados, com um número total de palavras atingindo 5,4b, ocupando cerca de 20g de espaço em disco, o mesmo que Macbert.
[2] Wikipedia + Bookcorpus
Tomando a versão Tensorflow do Chinese-PERT-base como exemplo, após o download, descompacte o arquivo zip para obter:
chinese_pert_base_L-12_H-768_A-12.zip
|- pert_model.ckpt # 模型权重
|- pert_model.meta # 模型meta信息
|- pert_model.index # 模型index信息
|- pert_config.json # 模型参数
|- vocab.txt # 词表(与谷歌原版一致)
Entre eles, bert_config.json e vocab.txt são exatamente os mesmos da BERT-base, Chinese (a versão em inglês é consistente com a versão Bert-Based Based).
Os modelos de versão Tensorflow (V2) e Pytorch podem ser baixados através da Biblioteca do Modelo Transformers.
Método de download: clique em qualquer modelo que você deseja baixar → selecione os "arquivos e versões" TAB → Faça o download do arquivo de modelo correspondente.
| Abreviação de modelo | Modelo Tamanho do arquivo | Endereço da biblioteca de modelos Transformers |
|---|---|---|
| Chinês-Pert-Large | 1.2g | https://huggingface.co/hfl/chinese-pert-large |
| Base Chinesa-Pert | 0,4g | https://huggingface.co/hfl/chinese-pert-base |
| Mrc chinês-pert-large | 1.2g | https://huggingface.co/hfl/chinese-pert-large-mrc |
| Chinês-Pert-Base-Mrc | 0,4g | https://huggingface.co/hfl/chinese-pert-base-mrc |
| Inglês-Pert-Large | 1.2g | https://huggingface.co/hfl/english-pert-large |
| Inglês-Pert-Base | 0,4g | https://huggingface.co/hfl/english-pert-base |
Como a parte do corpo Pert ainda é uma estrutura Bert, os usuários podem chamar o modelo PERT usando a biblioteca Transformers.
NOTA: Todos os modelos neste diretório são carregados usando o BertTokenizer e o Bertmodel (os modelos MRC usam o BertFestionAnswering).
from transformers import BertTokenizer , BertModel
tokenizer = BertTokenizer . from_pretrained ( "MODEL_NAME" )
model = BertModel . from_pretrained ( "MODEL_NAME" ) A lista correspondente de MODEL_NAME é a seguinte:
| Nome do modelo | Model_name |
|---|---|
| Chinês-Pert-Large | HFL/Chinês-Pert-Large |
| Base Chinesa-Pert | HFL/Chinês-Pert-Base |
| Mrc chinês-pert-large | HFL/Chinês-Pert-Large-Mrc |
| Chinês-Pert-Base-Mrc | HFL/Chinês-Pert-Base-Mrc |
| Inglês-Pert-Large | HFL/inglês-pert-grande |
| Inglês-Pert-Base | HFL/Inglês-Pert-Base |
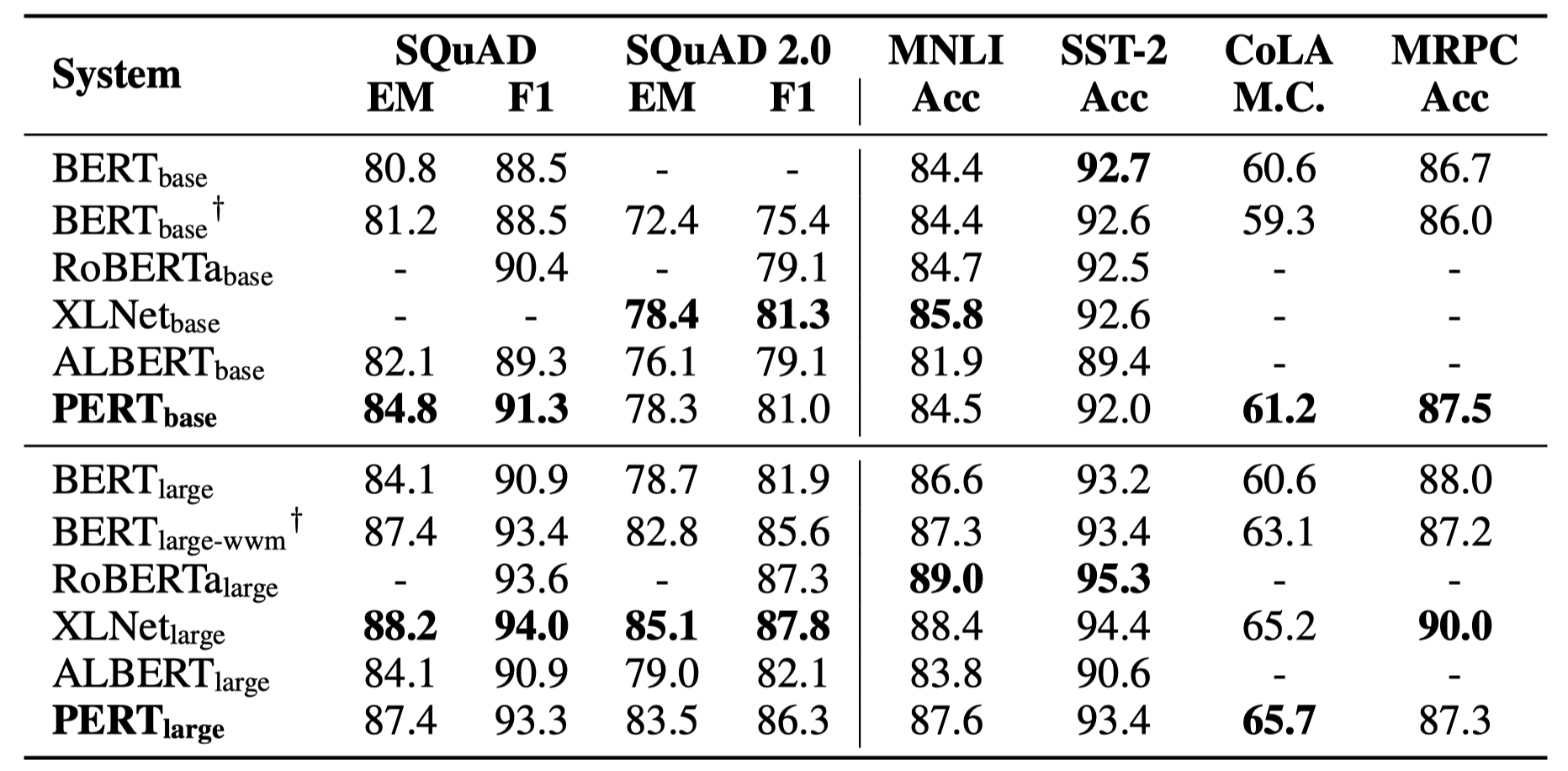
Apenas alguns resultados experimentais estão listados abaixo. Consulte o artigo para obter resultados e análises detalhados. Na tabela de resultados experimentais, o valor máximo fora dos colchetes é o valor médio dentro dos colchetes.
Os testes de eficácia foram realizados nas 10 tarefas a seguir.
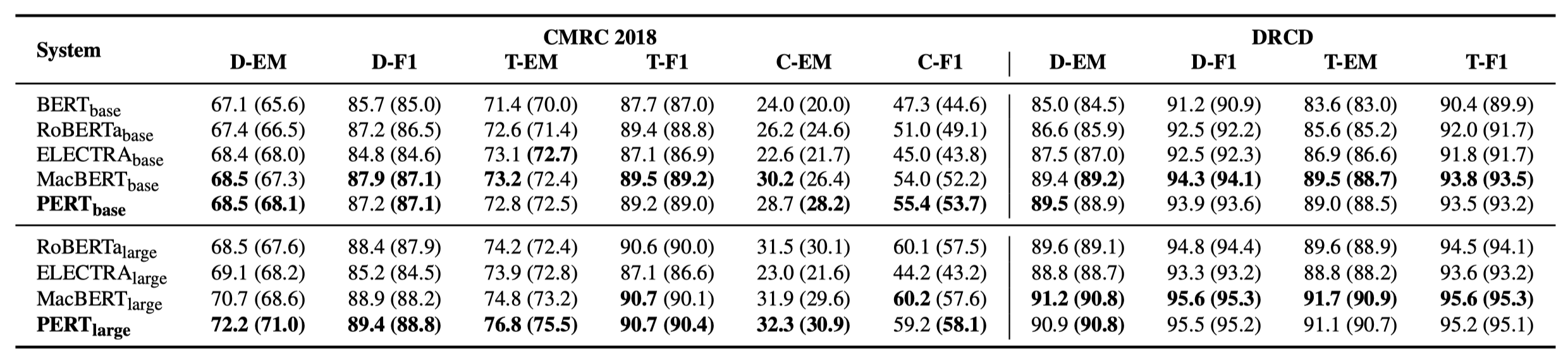
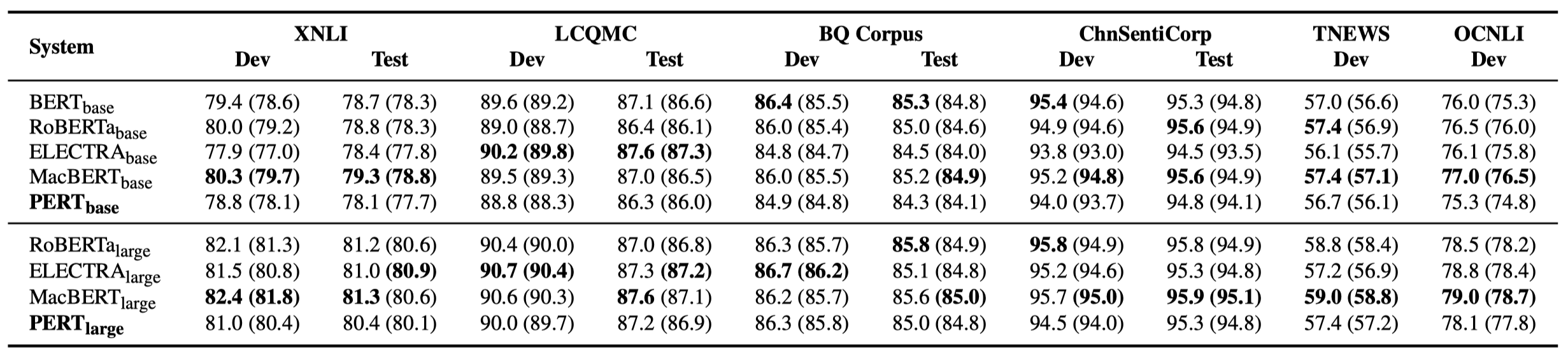
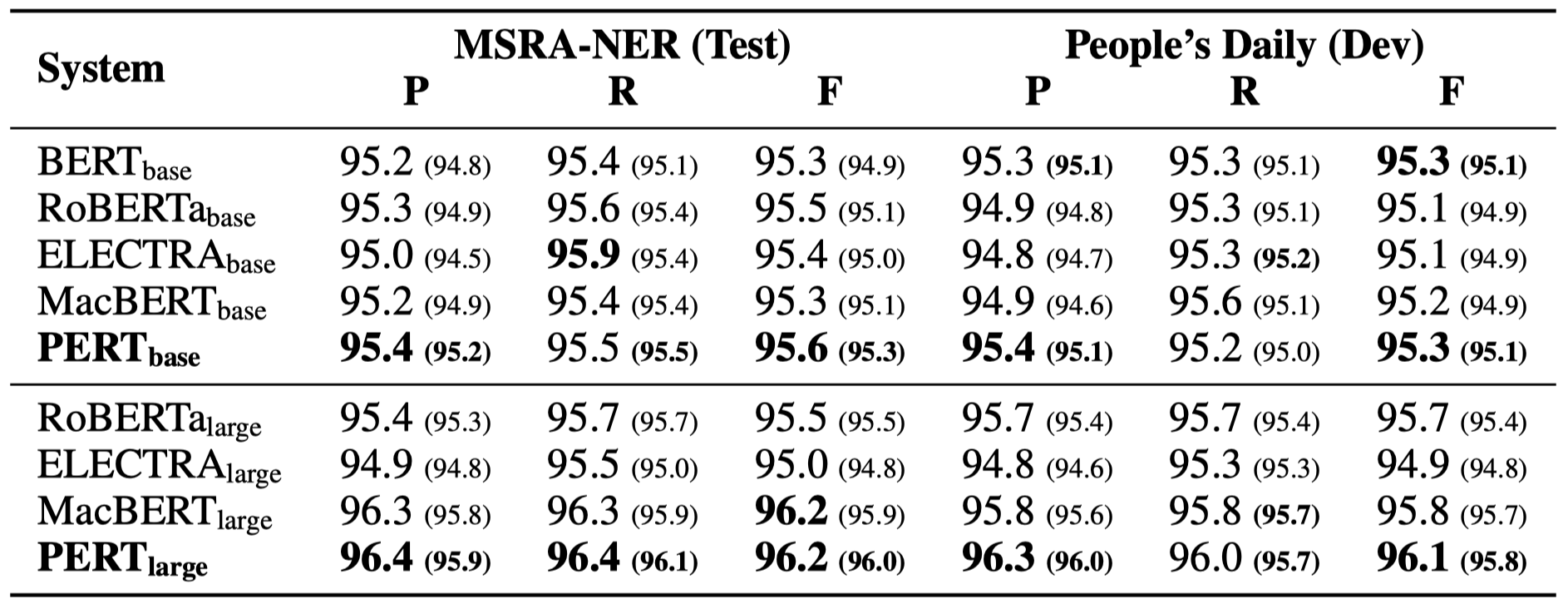
Além das tarefas acima, também testamos as tarefas fora de ordem na correção de erros de texto, e o efeito é o seguinte.

Os testes de eficácia foram realizados nas 6 tarefas a seguir.
Q1: Sobre o peso da versão de código aberto de Pert
A1: A versão de código aberto contém apenas os pesos da parte do transformador, que podem ser usados diretamente para o ajuste fino da tarefa a jusante ou os pesos iniciais do pré-treinamento secundário de outros modelos pré-treinados. Os pesos originais da versão TF podem conter pesos MLM inicializados aleatoriamente . Isto é para:
Q2: Sobre o efeito do PERT nas tarefas a jusante
A2: A conclusão preliminar é que ele tem melhores resultados em tarefas como compreensão de leitura e marcação de sequência, mas maus resultados em tarefas de classificação de texto. Tente os resultados específicos em suas próprias tarefas. Para detalhes, consulte o nosso artigo: https://arxiv.org/abs/2203.06906
Se os modelos ou conclusões relacionadas neste projeto forem úteis para sua pesquisa, cite o seguinte artigo: https://arxiv.org/abs/2203.06906
@article{cui2022pert,
title={PERT: Pre-training BERT with Permuted Language Model},
author={Cui, Yiming and Yang, Ziqing and Liu, Ting},
year={2022},
eprint={2203.06906},
archivePrefix={arXiv},
primaryClass={cs.CL}
}Bem -vindo a seguir o relato oficial oficial do WeChat do Laboratório Conjunto de Iflytek para aprender sobre as mais recentes tendências técnicas.

Se você tiver alguma dúvida, envie -o no problema do GitHub.


