PERT
1.0.0
Chino | Inglés

En el campo del procesamiento del lenguaje natural, los modelos de lenguaje previamente capacitados (PLM) se han convertido en una tecnología básica muy importante. En los últimos dos años, el Laboratorio Conjunto de Iflytek ha publicado una variedad de recursos del modelo de pre-entrenamiento chino y herramientas de apoyo relacionadas. Como continuación del trabajo relacionado, en este proyecto, proponemos un modelo previamente capacitado (PERT) basado en el modelo de lenguaje fuera de servicio que el aprendizaje auto-supervisado de la información semántica de texto sin introducir la marca de máscara [máscara]. Pert ha logrado mejoras de rendimiento en algunas tareas de NLU chinas e inglesas, pero también tiene malos resultados en algunas tareas. Úselo según corresponda. Actualmente, los modelos PERT se proporcionan en chino e inglés, incluidos dos tamaños de modelo (base, grande).
Lert chino | Inglés chino Pert | Macbert chino | Electra chino | Chino xlnet | Bert chino | Herramienta de destilación de conocimiento TextBrewer | Herramienta de corte de modelos Pruner de texto
Ver más recursos publicados por IFL del Harbin Institute of Technology (HFL): https://github.com/ymcui/hfl-anthology
2023/3/28 Open Source chino Llama y Alpaca Big Model, que se puede implementar y experimentar rápidamente en PC, Ver: https://github.com/ymcui/chinese-llama-alpaca
2022/10/29 Proponemos un modelo de modelo previamente capacitado que integra información lingüística. Ver: https://github.com/ymcui/lert
2022/5/7 Actualizado una comprensión de lectura especial pertinamente sintonizada en múltiples conjuntos de datos de comprensión de lectura, y proporcionó una demostración interactiva en línea de Huggingface, verificar: Descargar modelo
2022/3/15 Se ha publicado el informe técnico, consulte: https://arxiv.org/abs/2203.06906
Se han lanzado 2022/2/24 pert-base y pert-large en chino e inglés. Puede cargar directamente usando la estructura Bert y realizar tareas aguas abajo ajustando. El informe técnico se emitirá después de la finalización, y se espera que el tiempo sea a mediados de marzo. Gracias por tu paciencia.
2022/2/17 Gracias por su atención a este proyecto. Se espera que el modelo se publique la próxima semana, y el informe técnico se emitirá después de la mejora.
| capítulo | describir |
|---|---|
| Introducción | El principio básico del modelo perseguido pert. |
| Descargar modelo | Descargar la dirección del modelo PERT previamente capacitado |
| Carga rápida | Cómo usar transformadores de carga rápidamente modelos |
| Efectos del sistema de referencia | Efectos del sistema de referencia en algunas tareas de la NLU chino e inglés |
| Preguntas frecuentes | Preguntas frecuentes y respuestas |
| Cita | Informe técnico de este proyecto |
El aprendizaje de los modelos previos al estado de la comprensión del lenguaje natural (NLU) se divide aproximadamente en dos categorías: usar y no usar texto de entrada con marca de máscara [máscara].
Algoritmo inspirado: un cierto grado de texto fuera de servicio no afecta la comprensión. Entonces, ¿podemos aprender conocimiento semántico de textos fuera de servicio?
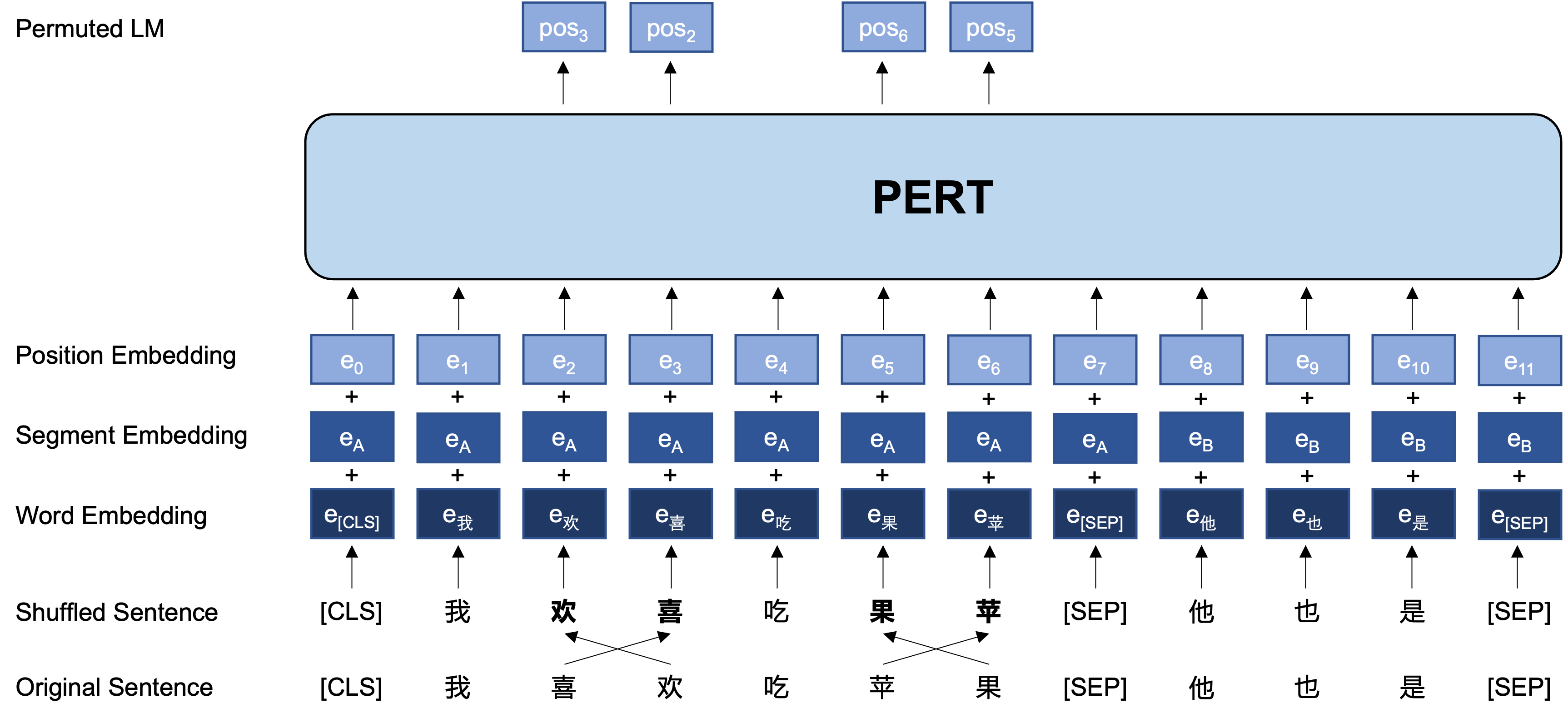
Idea general: Pert realiza un cierto intercambio de orden de palabras en el texto de entrada original, formando así un texto fuera de orden (por lo que no se introducen etiquetas adicionales [máscara]). El objetivo de aprendizaje de PERT es predecir la ubicación del token original, vea el siguiente ejemplo.
| ilustrar | Ingresar texto | Objetivo de salida |
|---|---|---|
| Texto original | La investigación muestra que el orden de esta oración no afecta la lectura. | - |
| Piel de palabras participio de palabras | La investigación muestra que el orden de esta oración no afecta la lectura. | - |
| Bert | La investigación muestra que esta oración [máscara] no suena como leer. | Posición 7 → Posición del teléfono 10 → Secuencia Posición 13 → Sombra |
| IMPERTINENTE | El orden de esta oración no afecta la lectura . | Posición 2 (estrecho) → Posición 3 (Tabla) Posición 3 (Tabla) → Posición 2 (estrecha) Posición 13 (resonante) → Posición 14 (sombra) Posición 14 (película) → Posición 13 (resonante) |
La siguiente es la estructura básica y el formato de entrada y salida del modelo PERT en la etapa previa a la capacitación (nota: Las imágenes en el informe técnico ARXIV son actualmente incorrectos, consulte las siguientes imágenes. La próxima vez que se actualice el papel, se reemplazará con la imagen correcta).
Aquí proporcionamos principalmente los pesos del modelo de TensorFlow versión 1.15. Si necesita una versión Pytorch o TensorFlow2 del modelo, consulte la siguiente sección.
La versión de código abierto solo contiene los pesos de la parte del transformador, que se puede utilizar directamente para el ajuste fino de la tarea aguas abajo, o los pesos iniciales del pre-entrenamiento secundario de otros modelos previamente capacitados. Para obtener más información, consulte las preguntas frecuentes.
PERT-large : 24 capas, 1024 escondidas, 16 cabezas, 330 m parámetrosPERT-base 12 capas, 768 escondidas, 12 cabezas, 110 m parámetros| Abreviatura del modelo | Idioma | Materiales | Descarga de Google | Descarga de disco de Baidu |
|---|---|---|---|---|
| Paternidad china | Chino | Datos ext [1] | Flujo tensor | TensorFlow (contraseña: E9HS) |
| Base china | Chino | Datos ext [1] | Flujo tensor | TensorFlow (contraseña: RCSW) |
| Prudente en inglés (no basado) | Inglés | Wikibooks [2] | Flujo tensor | TensorFlow (contraseña: WXWI) |
| Base de inglés (no basado) | Inglés | Wikibooks [2] | Flujo tensor | TensorFlow (contraseña: 8JGQ) |
[1] Los datos EXT incluyen: Wikipedia china, otras enciclopedias, noticias, preguntas y respuestas y otros datos, con un número total de palabras que alcanzan 5.4b, que ocupan aproximadamente 20 g de espacio en disco, lo mismo que Macbert.
[2] Wikipedia + BookCorpus
Tomar la versión TensorFlow de Chinese-PERT-base como ejemplo, después de descargar, descomprima el archivo zip para obtener:
chinese_pert_base_L-12_H-768_A-12.zip
|- pert_model.ckpt # 模型权重
|- pert_model.meta # 模型meta信息
|- pert_model.index # 模型index信息
|- pert_config.json # 模型参数
|- vocab.txt # 词表(与谷歌原版一致)
Entre ellos, bert_config.json y vocab.txt son exactamente los mismos que BERT-base, Chinese original de Google (la versión en inglés es consistente con la versión de Bert-Onculado).
Los modelos de versión TensorFlow (V2) y Pytorch se pueden descargar a través de la biblioteca de modelos Transformers.
Método de descarga: haga clic en cualquier modelo que desee descargar → Seleccione la pestaña "Archivos y versiones" → Descargue el archivo de modelo correspondiente.
| Abreviatura del modelo | Tamaño del archivo de modelo | dirección de la biblioteca de modelos de transformadores |
|---|---|---|
| Paternidad china | 1.2g | https://huggingface.co/hfl/chinese-pert-large |
| Base china | 0.4g | https://huggingface.co/hfl/chinese-pert-base |
| Chino-patge-mrc | 1.2g | https://huggingface.co/hfl/chinese-pert-large-mrc |
| MRC-BASE-BASE | 0.4g | https://huggingface.co/hfl/chinese-pert-base-mrc |
| Paternidad inglesa | 1.2g | https://huggingface.co/hfl/english-pert-large |
| Base de inglés | 0.4g | https://huggingface.co/hfl/english-pert-base |
Dado que la parte del cuerpo PERT sigue siendo una estructura Bert, los usuarios pueden llamar fácilmente al modelo PERT utilizando la biblioteca Transformers.
Nota: Todos los modelos en este directorio se cargan utilizando BertTokenizer y Bertmodel (los modelos MRC usan BertforQuestionAnwering).
from transformers import BertTokenizer , BertModel
tokenizer = BertTokenizer . from_pretrained ( "MODEL_NAME" )
model = BertModel . from_pretrained ( "MODEL_NAME" ) La lista correspondiente de MODEL_NAME es la siguiente:
| Nombre del modelo | Model_name |
|---|---|
| Paternidad china | HFL/chino-patergia |
| Base china | HFL/Pérdico chino |
| Chino-patge-mrc | HFL/China-Perth-Large-MRC |
| MRC-BASE-BASE | HFL/China-Base-Base-MRC |
| Paternidad inglesa | HFL/English-Pert-Large |
| Base de inglés | HFL/Pérdico en inglés |
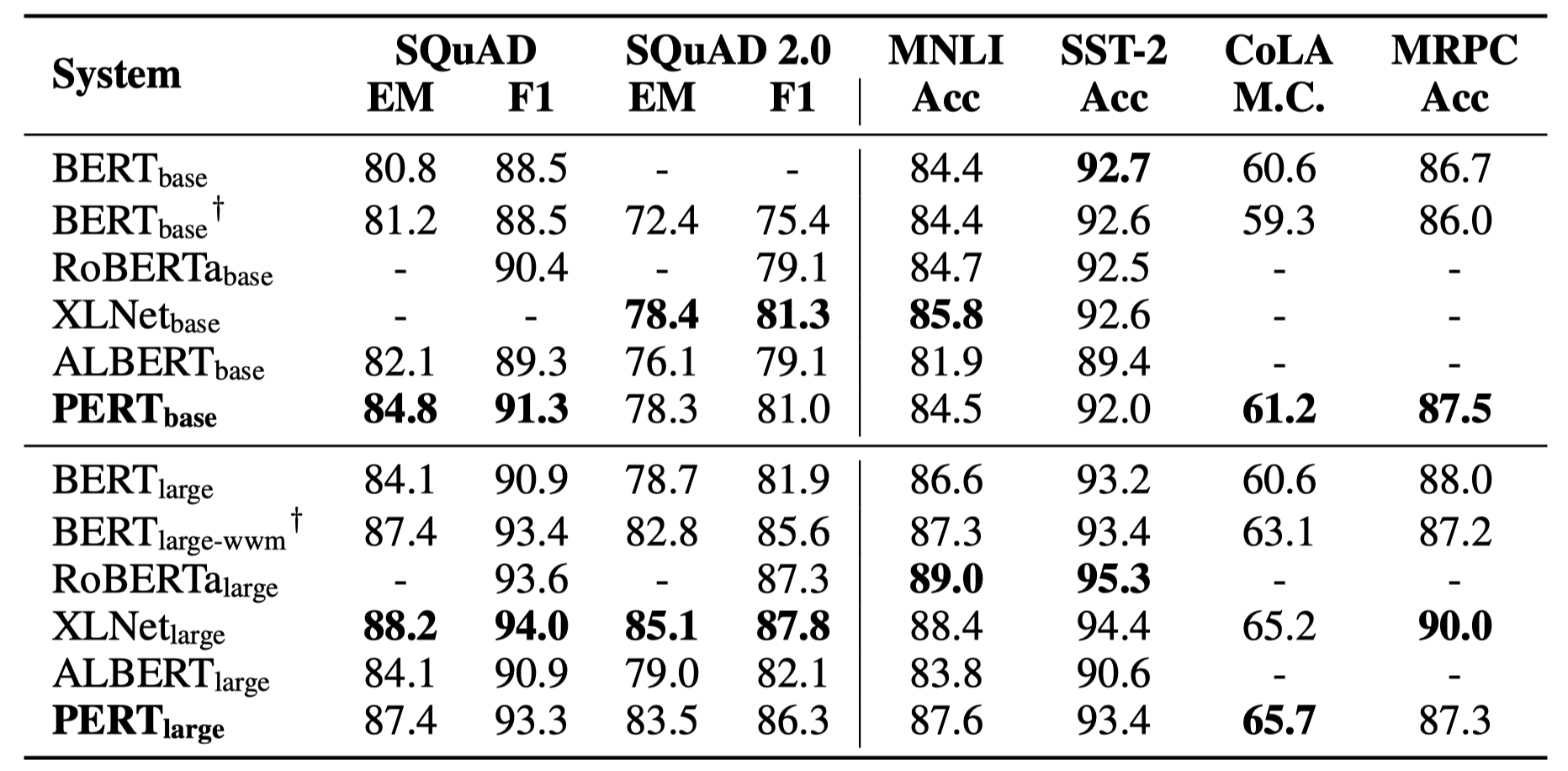
Solo algunos resultados experimentales se enumeran a continuación. Consulte el documento para obtener resultados y análisis detallados. En la tabla de resultados experimentales, el valor máximo fuera de los soportes es el valor promedio dentro de los soportes.
Las pruebas de efectividad se realizaron en las siguientes 10 tareas.
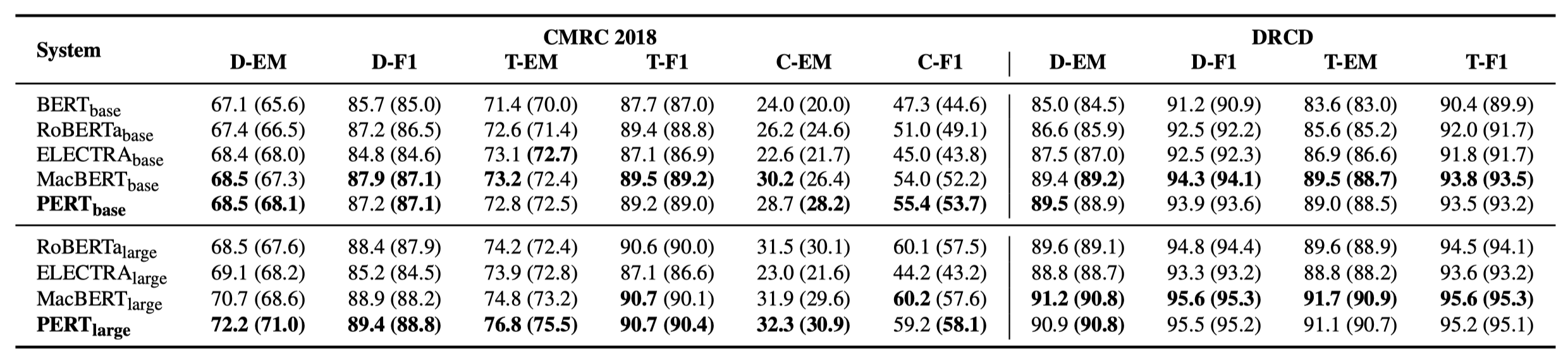
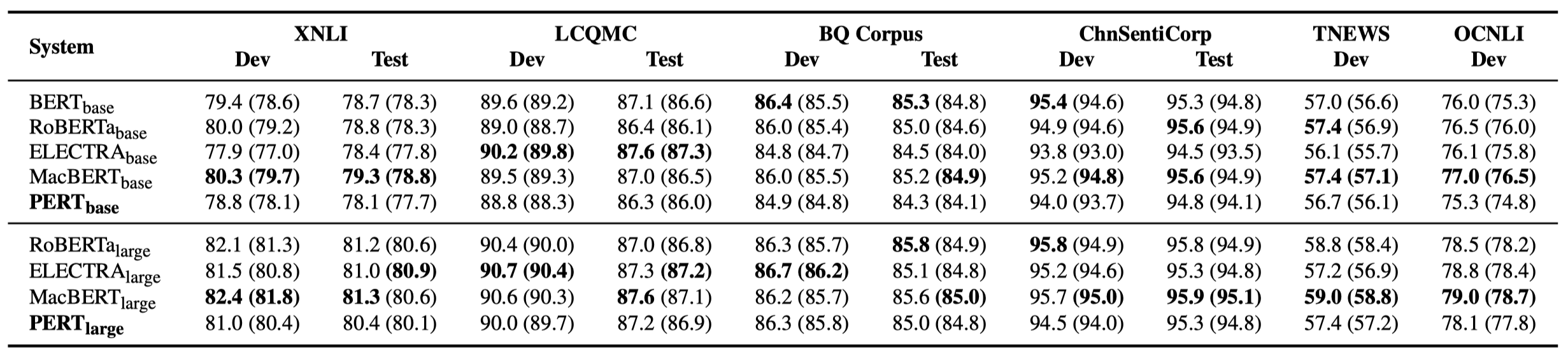
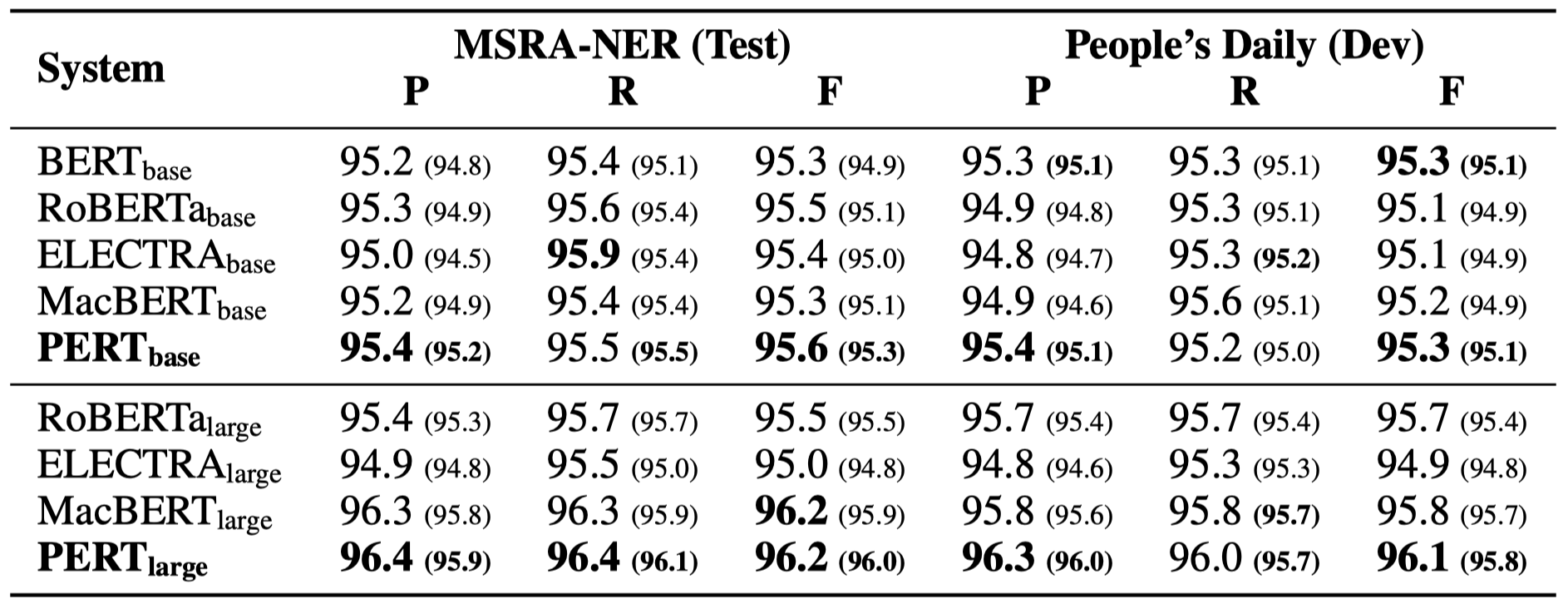
Además de las tareas anteriores, también probamos las tareas fuera de orden en la corrección de errores de texto, y el efecto es el siguiente.

Las pruebas de efectividad se realizaron en las siguientes 6 tareas.
P1: sobre la versión de código abierto, peso de PERT
A1: La versión de código abierto solo contiene los pesos de la parte del transformador, que se puede utilizar directamente para el ajuste fino de la tarea aguas abajo, o los pesos iniciales del pre-entrenamiento secundario de otros modelos previamente capacitados. Los pesos originales de la versión TF pueden contener pesos MLM inicializados al azar . Esto es para:
P2: sobre el efecto de PERT en las tareas aguas abajo
A2: La conclusión preliminar es que tiene mejores resultados en tareas como la comprensión de lectura y el etiquetado de la secuencia, pero los malos resultados en las tareas de clasificación de texto. Pruebe los resultados específicos en sus propias tareas. Para más detalles, consulte nuestro artículo: https://arxiv.org/abs/2203.06906
Si los modelos o conclusiones relacionadas en este proyecto son útiles para su investigación, cite el siguiente artículo: https://arxiv.org/abs/2203.06906
@article{cui2022pert,
title={PERT: Pre-training BERT with Permuted Language Model},
author={Cui, Yiming and Yang, Ziqing and Liu, Ting},
year={2022},
eprint={2203.06906},
archivePrefix={arXiv},
primaryClass={cs.CL}
}Bienvenido a seguir la cuenta oficial oficial de WeChat del Laboratorio Conjunto de Iflytek para conocer las últimas tendencias técnicas.

Si tiene alguna pregunta, envíelo en el problema de GitHub.


