demo chinese text binary classification with bert
1.0.0

去年, Google 的BERT 模型一發佈出來,我就很興奮。
因為我當時正在用fast.ai 的ULMfit 做自然語言分類任務(還專門寫了《如何用Python 和深度遷移學習做文本分類?》一文分享給你)。 ULMfit 和BERT 都屬於預訓練語言模型(Pre-trained Language Modeling),具有很多的相似性。
所謂語言模型,就是利用深度神經網絡結構,在海量語言文本上訓練,以抓住一種語言的通用特徵。
上述工作,往往只有大機構才能完成。因為花費實在太大了。
這花費包括但不限於:
預訓練就是指他們訓練好之後,把這種結果開放出來。我們普通人或者小型機構,也可以借用其結果,在自己的專門領域文本數據上進行微調,以便讓模型對於這個專門領域的文本有非常清晰的認識。
所謂認識,主要是指你遮擋上某些詞彙,模型可以較準確地猜出來你藏住了什麼。
甚至,你把兩句話放在一起,模型可以判斷它倆是不是緊密相連的上下文關係。

這種“認識”有用嗎?
當然有。
BERT 在多項自然語言任務上測試,不少結果已經超越了人類選手。

BERT 可以輔助解決的任務,當然也包括文本分類(classification),例如情感分類等。這也是我目前研究的問題。
然而,為了能用上BERT ,我等了很久。
Google 官方代碼早已開放。就連Pytorch 上的實現,也已經迭代了多少個輪次了。
但是我只要一打開他們提供的樣例,就頭暈。
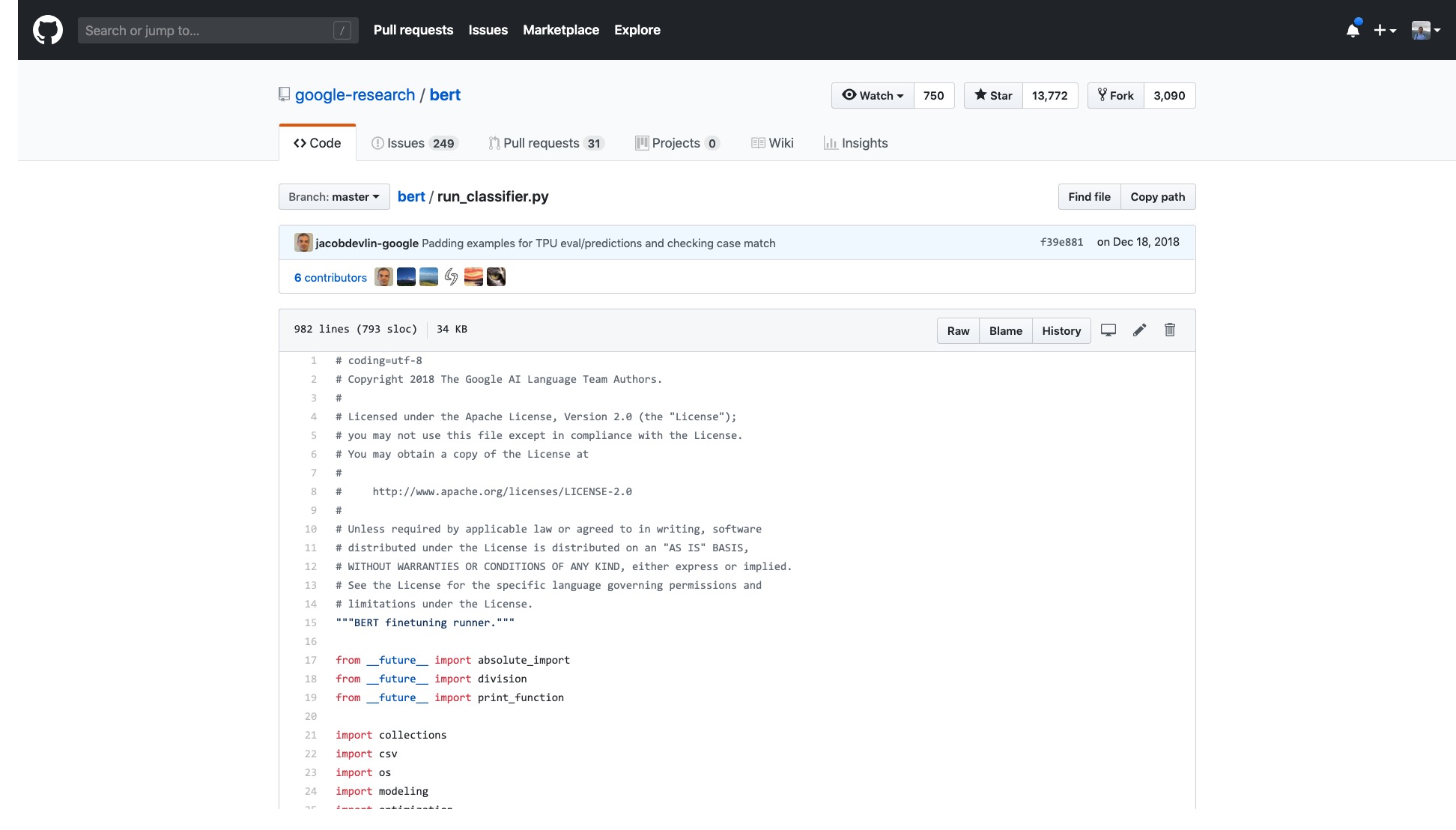
單單是那代碼的行數,就非常嚇人。
而且,一堆的數據處理流程(Data Processor) ,都用數據集名稱命名。我的數據不屬於上述任何一個,那麼我該用哪個?

還有莫名其妙的無數旗標(flags) ,看了也讓人頭疼不已。

讓我們來對比一下,同樣是做分類任務,Scikit-learn 裡面的語法結構是什麼樣的。
from sklearn . datasets import load_iris
from sklearn import tree
iris = load_iris ()
clf = tree . DecisionTreeClassifier ()
clf = clf . fit ( iris . data , iris . target )即便是圖像分類這種數據吞吐量大,需要許多步驟的任務,你用fast.ai ,也能幾行代碼,就輕輕鬆松搞定。
!g it clone https : // github . com / wshuyi / demo - image - classification - fastai . git
from fastai . vision import *
path = Path ( "demo-image-classification-fastai/imgs/" )
data = ImageDataBunch . from_folder ( path , test = 'test' , size = 224 )
learn = cnn_learner ( data , models . resnet18 , metrics = accuracy )
learn . fit_one_cycle ( 1 )
interp = ClassificationInterpretation . from_learner ( learn )
interp . plot_top_losses ( 9 , figsize = ( 8 , 8 ))別小瞧這幾行代碼,不僅幫你訓練好一個圖像分類器,還能告訴你,那些分類誤差最高的圖像中,模型到底在關注哪裡。

對比一下,你覺得BERT 樣例和fast.ai 的樣例區別在哪兒?
我覺得,後者是給人用的。
我總以為,會有人把代碼重構一下,寫一個簡明的教程。
畢竟,文本分類任務是個常見的機器學習應用。應用場景多,也適合新手學習。
但是,這樣的教程,我就是沒等來。
當然,這期間,我也看過很多人寫的應用和教程。
有的就做到把一段自然語言文本,轉換到BERT 編碼。戛然而止。
有的倒是認真介紹怎麼在官方提供的數據集上,對BERT 進行“稍微修改”使用。所有的修改,都在原始的Python 腳本上完成。那些根本沒用到的函數和參數,全部被保留。至於別人如何復用到自己的數據集上?人家根本沒提這事兒。
我不是沒想過從頭啃一遍代碼。想當年讀研的時候,我也通讀過仿真平台上TCP 和IP 層的全部C 代碼。我確定眼前的任務,難度更低一些。
但是我真的懶得做。我覺得自己被Python 機器學習框架,特別是fast.ai 和Scikit-learn 寵壞了。
後來, Google 的開發人員把BERT 弄到了Tensorflow Hub 上。還專門寫了個Google Colab Notebook 樣例。
看到這個消息,我高興壞了。
我嘗試過Tensorflow Hub 上的不少其他模型。使用起來很方便。而Google Colab 我已在《如何用Google Colab 練Python? 》一文中介紹給你,是非常好的Python 深度學習練習和演示環境。滿以為雙劍合璧,這次可以幾行代碼搞定自己的任務了。
且慢。
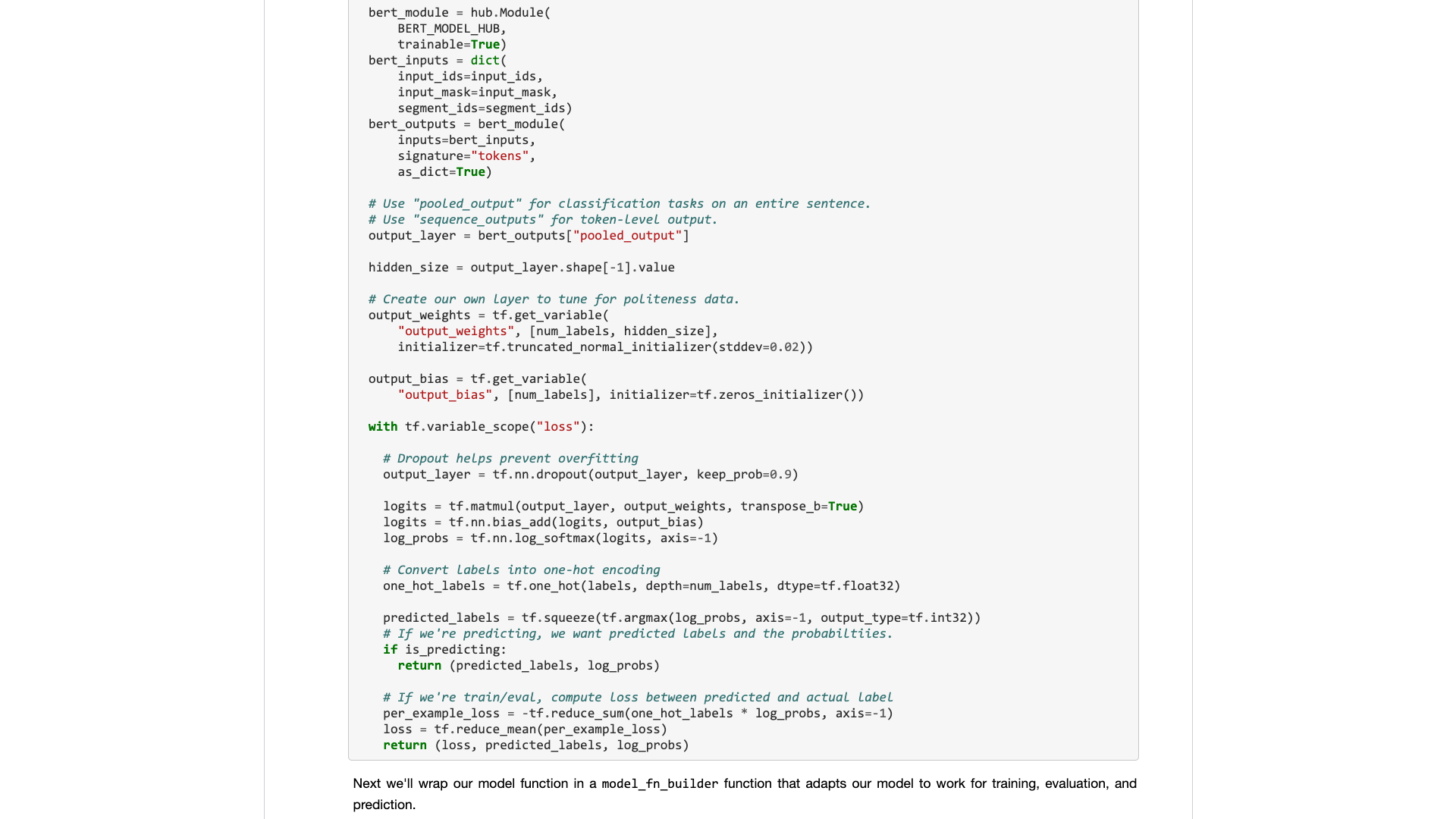
真正打開一看,還是以樣例數據為中心。
普通用戶需要什麼?需要一個接口。
你告訴我輸入的標準規範,然後告訴我結果都能有什麼。即插即用,完事兒走人。
一個文本分類任務,原本不就是給你個訓練集和測試集,告訴你訓練幾輪練多快,然後你告訴我準確率等結果嗎?
你至於讓我為了這麼簡單的一個任務,去讀幾百行代碼,自己找該在哪裡改嗎?
好在,有了這個樣例做基礎,總比沒有好。
我耐下心來,把它整理了一番。
聲明一下,我並沒有對原始代碼進行大幅修改。
所以不講清楚的話,就有剽竊嫌疑,也會被鄙視的。
這種整理,對於會Python 的人來說,沒有任何技術難度。
可正因為如此,我才生氣。這事兒難做嗎? Google 的BERT 樣例編寫者怎麼就不肯做?
從Tensorflow 1.0 到2.0,為什麼變動會這麼大?不就是因為2.0 才是給人用的嗎?
你不肯把界面做得清爽簡單,你的競爭者(TuriCreate 和fast.ai)會做,而且做得非常好。實在坐不住了,才肯降尊紆貴,給普通人開發一個好用的界面。
教訓啊!為什麼就不肯吸取呢?
我給你提供一個Google Colab 筆記本樣例,你可以輕易地替換上自己的數據集來運行。你需要去理解(包括修改)的代碼,不超過10行。
我先是測試了一個英文文本分類任務,效果很好。於是寫了一篇Medium 博客,旋即被Towards Data Science 專欄收錄了。
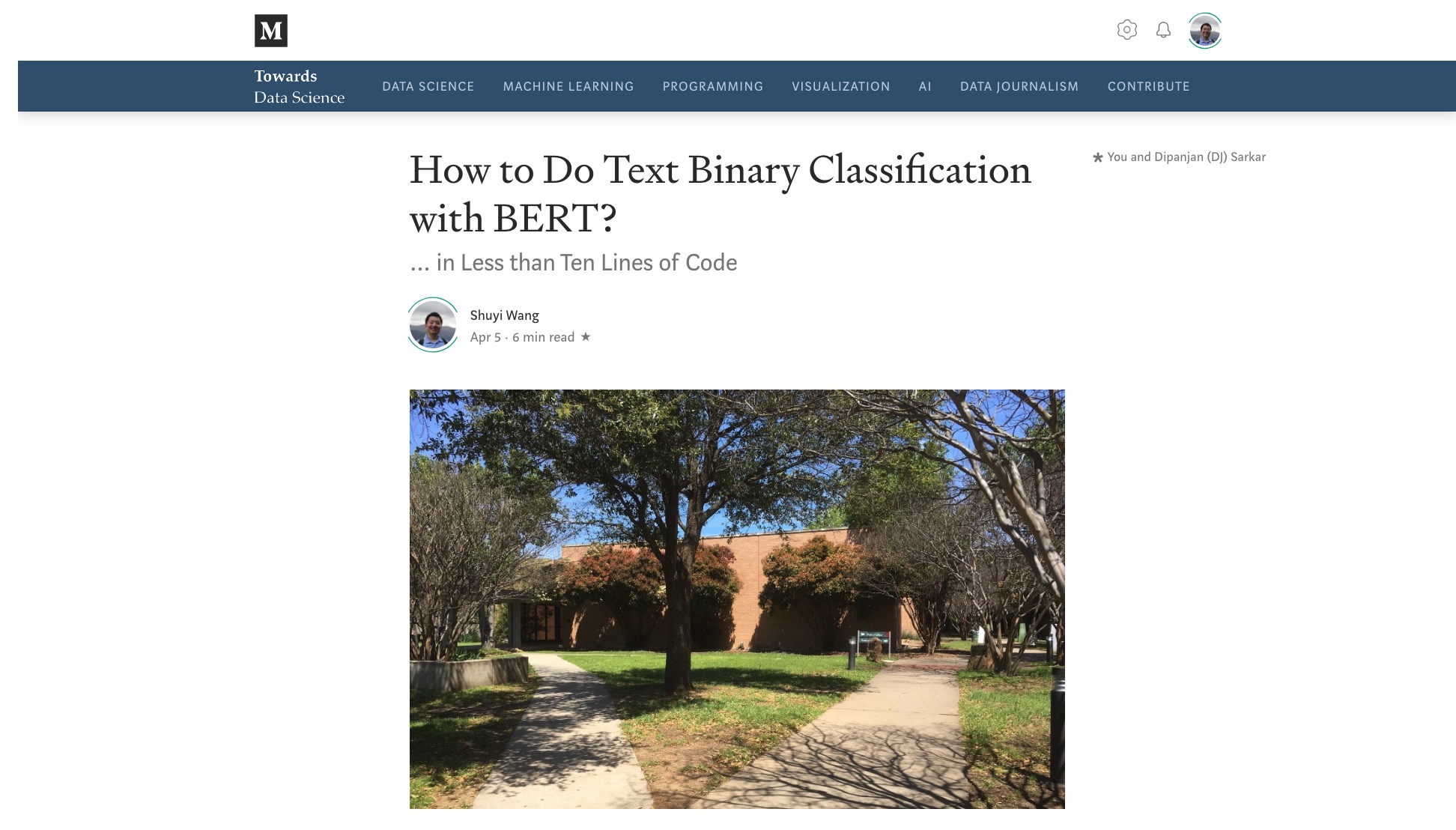
Towards Data Science 專欄編輯給我私信,說:
Very interesting, I like this considering the default implementation is not very developer friendly for sure.
有一個讀者,居然連續給這篇文章點了50個贊(Claps),我都看呆了。

看來,這種忍受已久的痛點,不止屬於我一個人。
估計你的研究中,中文分類任務可能遇到得更多。所以我乾脆又做了一個中文文本分類樣例,並且寫下這篇教程,一併分享給你。
咱們開始吧。
請點擊這個鏈接,查看我在Github 上為你做好的IPython Notebook 文件。
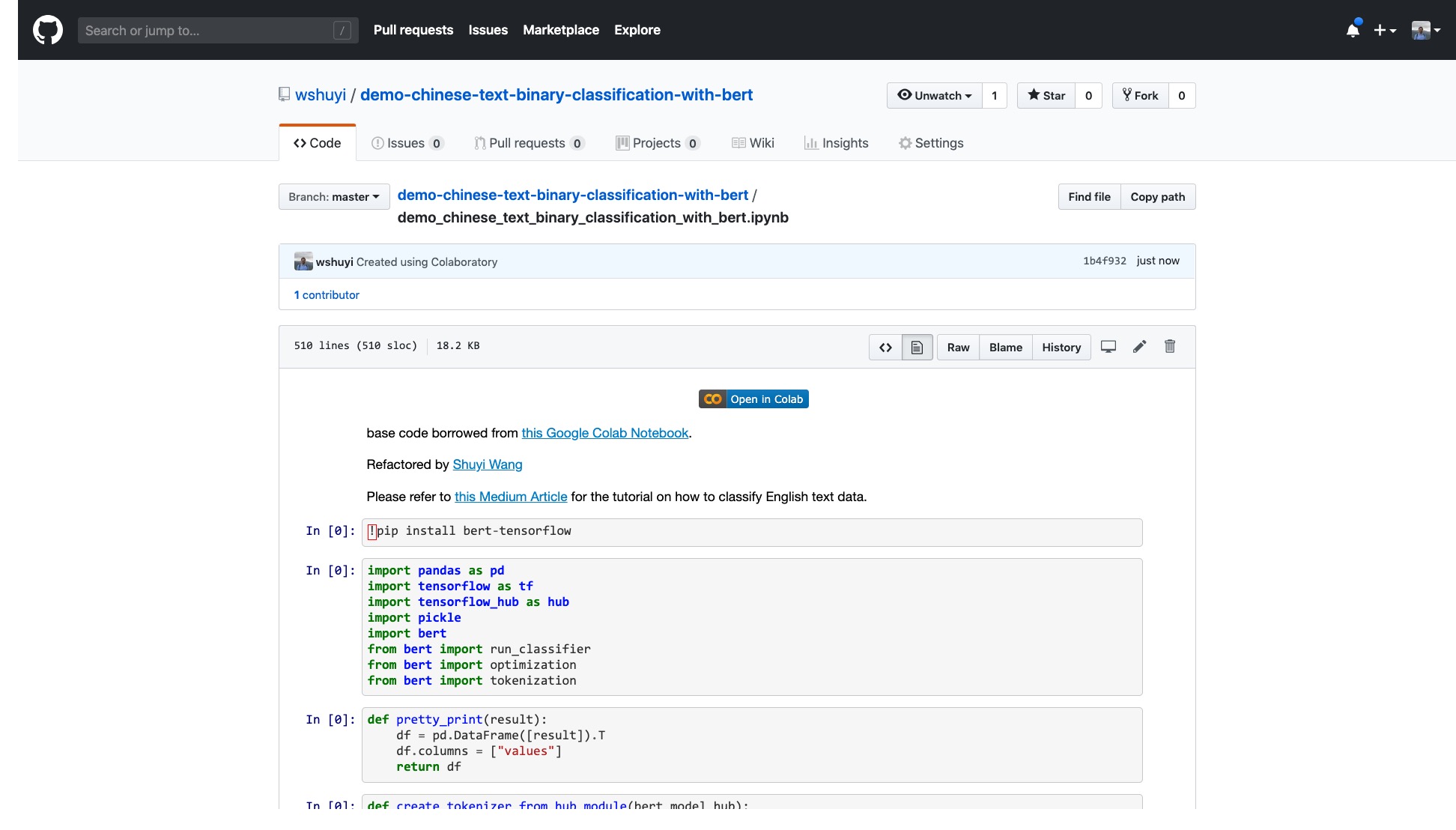
Notebook 頂端,有個非常明顯的"Open in Colab" 按鈕。點擊它,Google Colab 就會自動開啟,並且載入這個Notebook 。
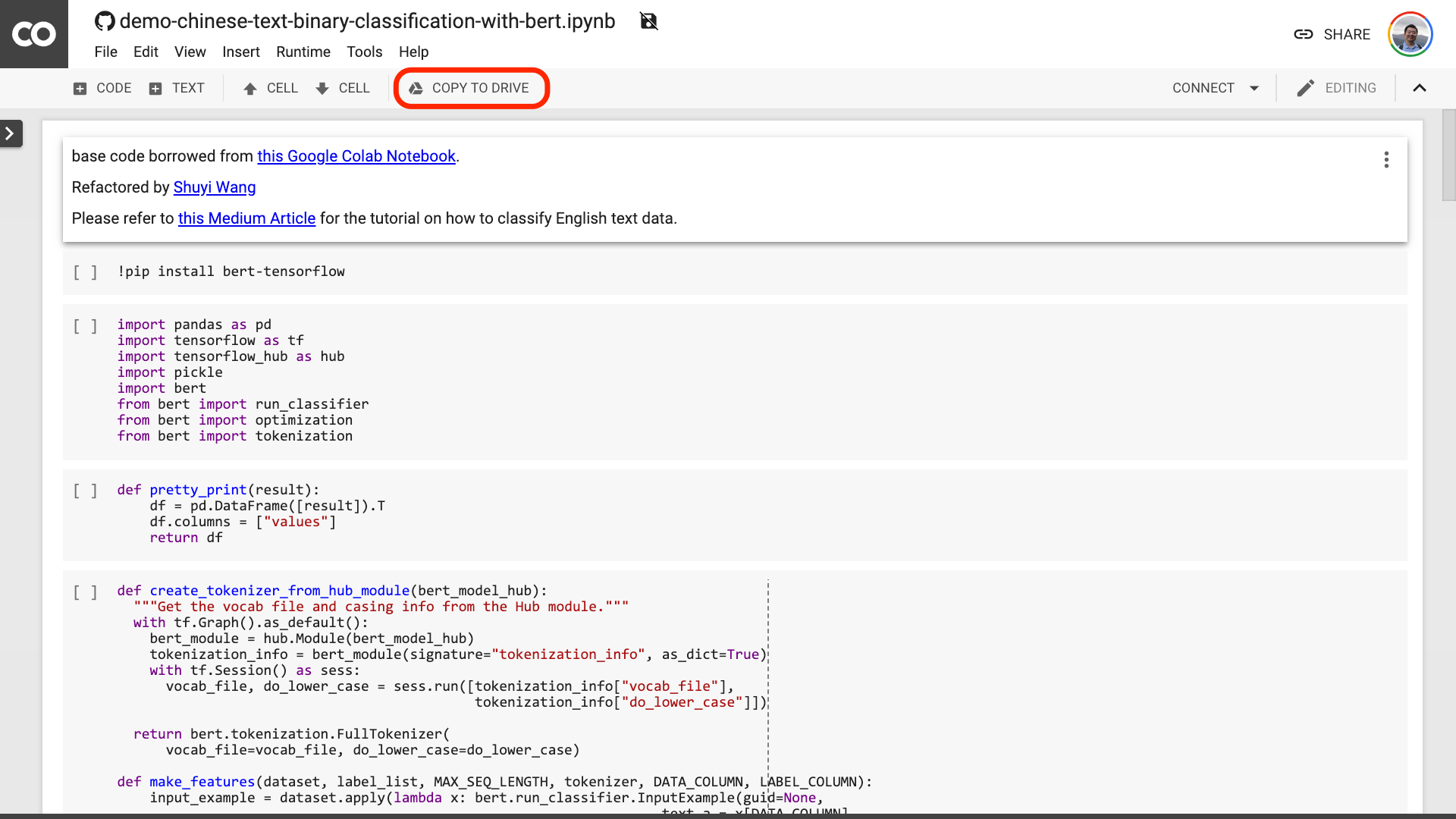
我建議你點一下上圖中紅色圈出的“COPY TO DRIVE” 按鈕。這樣就可以先把它在你自己的Google Drive 中存好,以便使用和回顧。
這件事做好以後,你實際上只需要執行下面三個步驟:
當你把Notebook 存好之後。定睛一看,或許會覺得上當了。
老師你騙人!說好了不超過10行代碼的!
別急。
在下面這張圖紅色圈出的這句話之前,你不用修改任何內容。
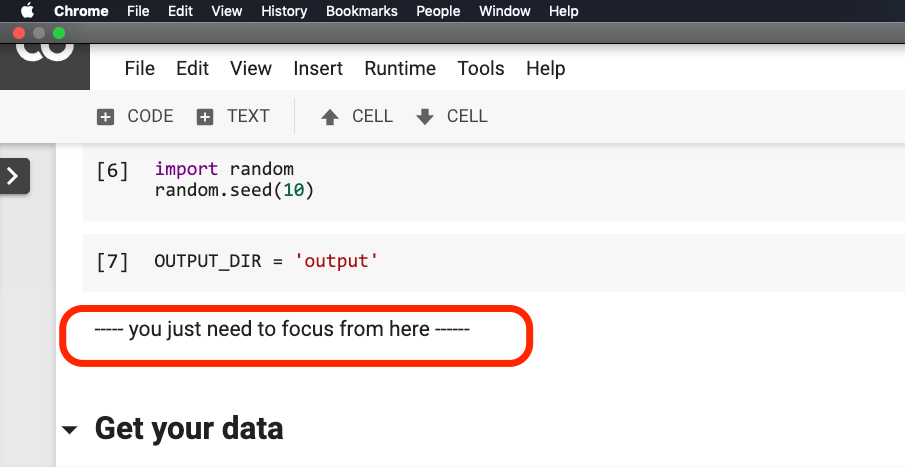
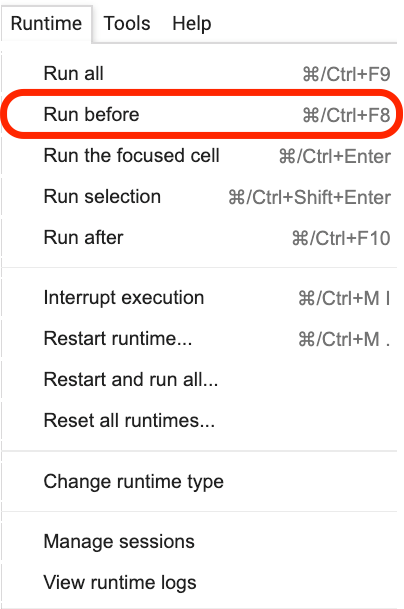
請你點擊這句話所在位置,然後從菜單中如下圖選擇Run before 。
下面才都是緊要的環節,集中註意力。
第一步,就是把數據準備好。
!w get https : // github . com / wshuyi / demo - chinese - text - binary - classification - with - bert / raw / master / dianping_train_test . pickle
with open ( "dianping_train_test.pickle" , 'rb' ) as f :
train , test = pickle . load ( f )這裡使用的數據,你應該並不陌生。它是餐飲點評情感標註數據,我在《如何用Python和機器學習訓練中文文本情感分類模型? 》和《如何用Python 和循環神經網絡做中文文本分類? 》中使用過它。只不過,為了演示的方便,這次我把它輸出為pickle 格式,一起放在了演示Github repo 裡,便於你下載和使用。
其中的訓練集,包含1600條數據;測試集包含400條數據。標註裡面1代表正向情感,0代表負向情感。
利用下面這條語句,我們把訓練集重新洗牌(shuffling),打亂順序。以避免過擬合(overfitting)。
train = train . sample ( len ( train ))這時再來看看我們訓練集的頭部內容。
train . head ()
如果你後面要替換上自己的數據集,請注意格式。訓練集和測試集的列名稱應該保持一致。
第二步,我們來設置參數。
myparam = {
"DATA_COLUMN" : "comment" ,
"LABEL_COLUMN" : "sentiment" ,
"LEARNING_RATE" : 2e-5 ,
"NUM_TRAIN_EPOCHS" : 3 ,
"bert_model_hub" : "https://tfhub.dev/google/bert_chinese_L-12_H-768_A-12/1"
}前兩行,是把文本、標記對應的列名,指示清楚。
第三行,指定訓練速率。你可以閱讀原始論文,來進行超參數調整嘗試。或者,你乾脆保持默認值不變就可以。
第四行,指定訓練輪數。把所有數據跑完,算作一輪。這裡使用3輪。
最後一行,是說明你要用的BERT 預訓練模型。咱們要做中文文本分類,所以使用的是這個中文預訓練模型地址。如果你希望用英文的,可以參考我的Medium 博客文章以及對應的英文樣例代碼。
最後一步,我們依次執行代碼就好了。
result , estimator = run_on_dfs ( train , test , ** myparam )注意,執行這一句,可能需要花費一段時間。做好心理準備。這跟你的數據量和訓練輪數設置有關。
在這個過程中,你可以看到,程序首先幫助你把原先的中文文本,變成了BERT 可以理解的輸入數據格式。
當你看到下圖中紅色圈出文字時,就意味著訓練過程終於結束了。
然後你就可以把測試的結果打印出來了。
pretty_print ( result )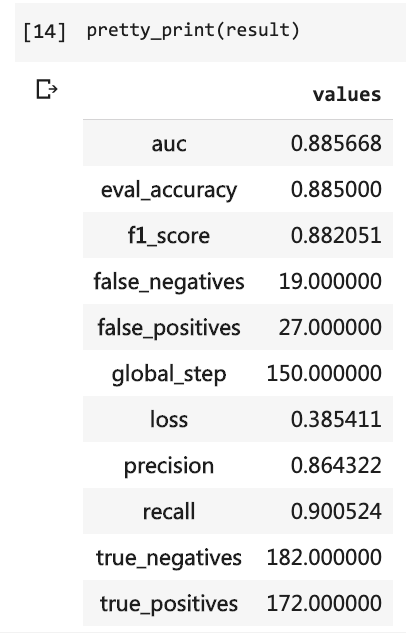
跟咱們之前的教程(使用同一數據集)對比一下。
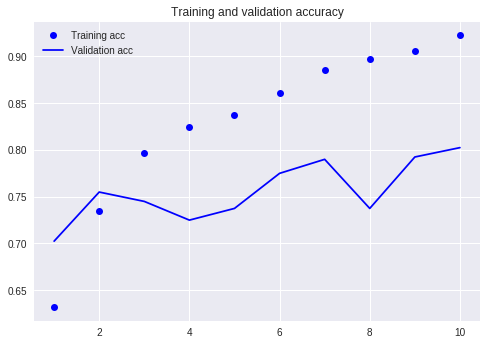
當時自己得寫那麼多行代碼,而且需要跑10個輪次,可結果依然沒有超過80% 。這次,雖然只訓練了3個輪次,但準確率已經超過了88% 。
在這樣小規模數據集上,達到這樣的準確度,不容易。
BERT性能之強悍,可見一斑。
講到這裡,你已經學會瞭如何用BERT 來做中文文本二元分類任務了。希望你會跟我一樣開心。
如果你是個資深Python 愛好者,請幫我個忙。
還記得這條線之前的代碼嗎?
能否幫我把它們打個包?這樣咱們的演示代碼就可以更加短小精悍和清晰易用了。
歡迎在咱們的Github 項目上提交你的代碼。如果你覺得這篇教程對你有幫助,歡迎給這個Github 項目加顆星。謝謝!
祝深度學習愉快!
你可能也會對以下話題感興趣。點擊鏈接就可以查看。
喜歡請點贊和打賞。還可以微信關注和置頂我的公眾號“玉樹芝蘭”(nkwangshuyi)。
如果你對Python 與數據科學感興趣,不妨閱讀我的系列教程索引貼《如何高效入門數據科學? 》,裡面還有更多的有趣問題及解法。
知識星球入口在這裡:


