demo chinese text binary classification with bert
1.0.0

В прошлом году я был очень взволнован, как только модель Google Bert была выпущена.
Поскольку я использовал Fast.ai Ulmfit для выполнения задач классификации естественного языка в то время (я также написал специальную статью «Как использовать Python и Deep Transfer Learning для классификации текстов?», Чтобы поделиться с вами). Ulmfit и Bert являются предварительно обученными языковыми моделями и имеют много сходств.
Так называемая языковая модель использует глубокую структуру нейронной сети для обучения массовым языковым текстам, чтобы понять общие черты языка.
Вышеуказанная работа часто возможна только для завершения крупных учреждений. Потому что стоимость слишком велика.
Эта стоимость включает, но не ограничивается:
Предварительное обучение означает, что они открывают этот результат после обучения. Мы, обычные люди или небольшие учреждения, также можем заимствовать результаты и точно настроить наши собственные текстовые данные на наших специализированных областях, чтобы модель могла иметь очень четкое понимание текста в этой специализированной области.
Так называемое понимание в основном относится к тому факту, что вы блокируете определенные слова, и модель может более точно угадать, что вы скрываете.
Даже если вы соедините два предложения, модель может определить, являются ли они тесно связаны контекстные отношения.

Это «знание» полезно?
Конечно есть.
Берт проверил на нескольких задачах естественного языка, и многие результаты превзошли человеческих игроков.

Берт может помочь в решении задач, конечно, также включать классификацию текста, такую как классификация эмоций. Это также проблема, которую я в настоящее время изучаю.
Однако, чтобы использовать Берт, я долго ждал.
Официальный код Google был открыт. Даже реализация на Pytorch была иедирована на многие раунды.
Но мне просто нужно открыть образец, который они предоставляют, и я чувствую головокружение.
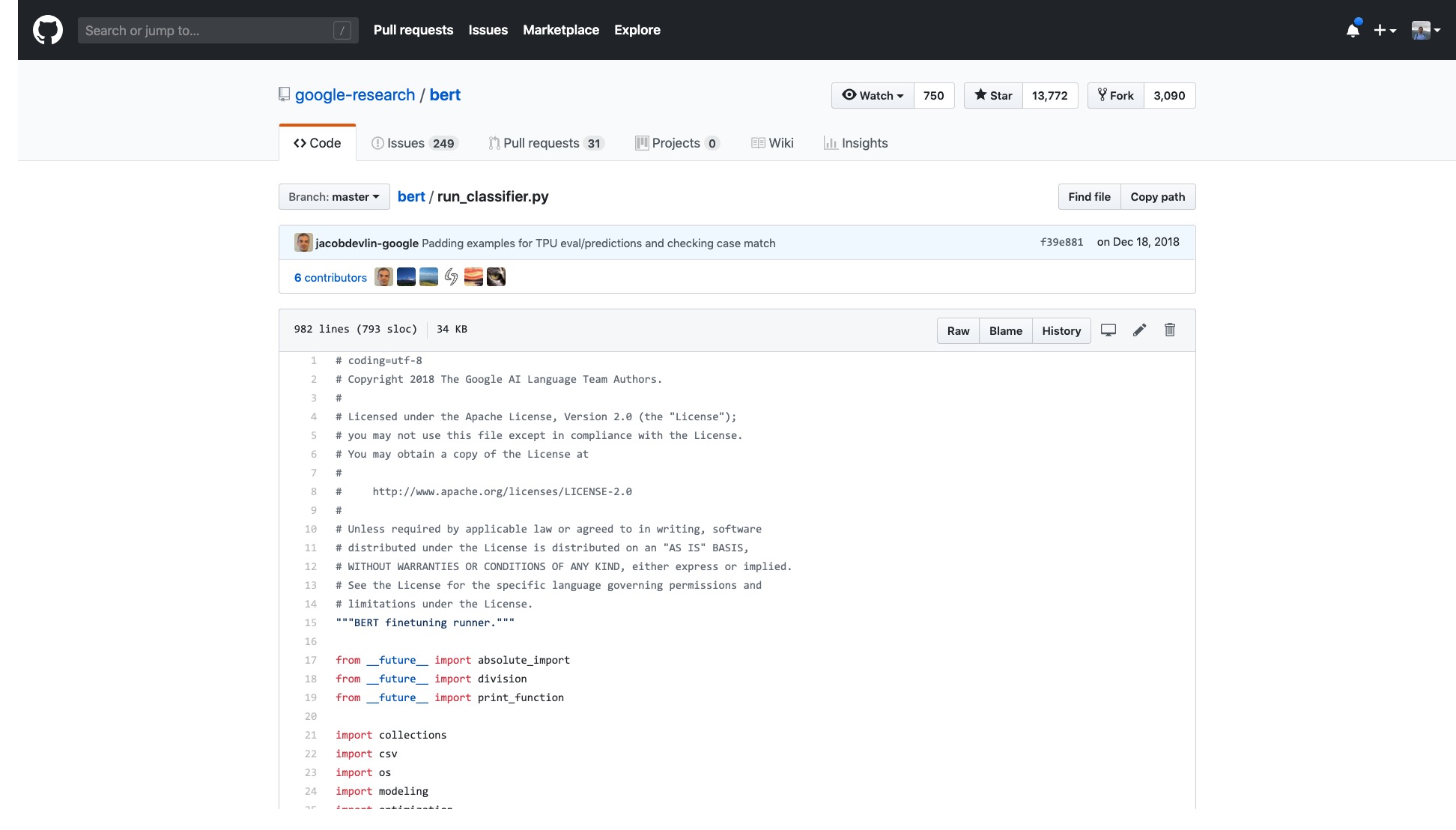
Количество строк только в этом коде очень страшно.
Кроме того, группа процессов обработки данных (процессоры данных) названа в честь имени набора данных. Мои данные не принадлежат ни одному из вышеперечисленного, так что какой из них мне следует использовать?

Есть также бесчисленные флаги (флаги), которые необъяснимых хлопот.

Давайте сравним, как выглядит синтаксическая структура в Scikit-Learn при выполнении задач классификации.
from sklearn . datasets import load_iris
from sklearn import tree
iris = load_iris ()
clf = tree . DecisionTreeClassifier ()
clf = clf . fit ( iris . data , iris . target )Даже если пропускная способность данных классификации изображений большая и требует много шагов, вы можете легко сделать это с несколькими строками кода, используя Fast.ai.
!g it clone https : // github . com / wshuyi / demo - image - classification - fastai . git
from fastai . vision import *
path = Path ( "demo-image-classification-fastai/imgs/" )
data = ImageDataBunch . from_folder ( path , test = 'test' , size = 224 )
learn = cnn_learner ( data , models . resnet18 , metrics = accuracy )
learn . fit_one_cycle ( 1 )
interp = ClassificationInterpretation . from_learner ( learn )
interp . plot_top_losses ( 9 , figsize = ( 8 , 8 ))Не недооценивайте эти строки кода. Это не только помогает вам обучить классификатор изображения, но и сообщает, где модель обращает внимание на этих изображениях с самой высокой ошибкой классификации.

Сравнение, как вы думаете, что является разницей между примером Bert и примером Fast.ai?
Я думаю, что последнее - для людей, чтобы использовать .
Я всегда думал, что кто -то рефактирует код и напишет краткий учебник.
В конце концов, задачи классификации текста являются общим приложением машинного обучения. Существует много сценариев приложений, а также подходит для начинающих.
Тем не менее, я просто не ждал такого урока.
Конечно, в течение этого периода я также читал приложения и учебные пособия, написанные многими людьми.
Некоторые люди могут преобразовать текст естественного языка в кодирование Bert. Это закончилось внезапно.
Некоторые люди тщательно представляют, как использовать BERT в официальных наборах данных. Все модификации сделаны на исходном сценарии Python. Все функции и параметры, которые вообще не используются, сохраняются. Что касается того, как другие повторно используют свои собственные наборы данных? Люди не упоминали об этом вообще.
Я думал о том, чтобы жевать код с самого начала. Я помню, когда я учился в аспирантуре, я также прочитал все коды С -слоев TCP и IP на платформе моделирования. Я определил задачу передо мной, что было менее трудным.
Но я действительно не хочу этого делать. Я чувствую, что меня избаловано рамками Python Machine Learning, особенно Fast.ai и Scikit-learn.
Позже разработчики Google принесли Bert в Tensorflow Hub. Я также написал образец ноутбука Google Colab специально.
Я был так счастлив видеть эту новость.
Я пробовал много других моделей на Tensorflow Hub. Это очень удобно использовать. И Google Colab Я практиковал Python с Google Colab? 》 Представлено вам в статье », которая является очень хорошим упражнением по глубокому обучению Python и демонстрационной среде. Я думал, что эти два меча могут быть объединены, и на этот раз я мог выполнять свои собственные задачи с несколькими линиями кода.
Подожди.
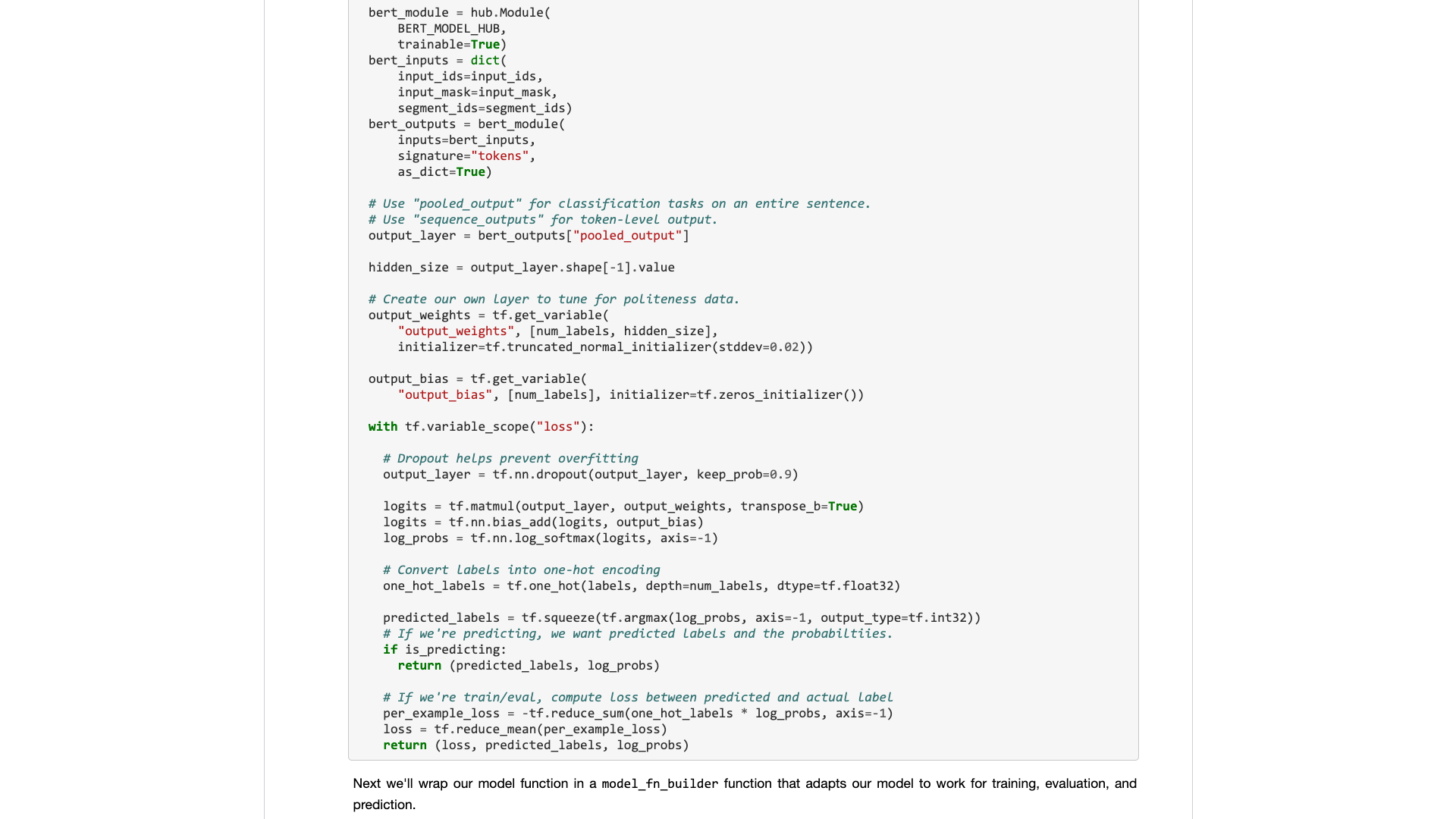
Когда вы действительно откроете его, вы все равно сосредоточитесь на образце данных.
Что нужно обычным пользователям? Требуется интерфейс.
Вы говорите мне стандартные спецификации, которые вы ввели, а затем говорите мне, какими могут быть результаты. Подключите и играйте, и уходите в конце концов.
Первоначально задача классификации текста дала вам обучающий набор и набор тестирования, сообщив вам, насколько быстро находятся учебные раунды, а затем сообщили мне скорость точности и результаты?
Что касается того, чтобы я просил меня прочитать сотни строк кода для такой простой задачи, и выяснить, где его изменить?
К счастью, с этим примером в качестве основы, он лучше, чем ничего.
Я взял свое терпение и разобрал его.
Чтобы заявить, я не внес никаких серьезных изменений в исходном коде.
Поэтому, если вы не объясните это ясно, вы будете подозреваны в плагиате и будете презираются.
Такая организация технически не сложна для людей, которые знают, как использовать Python.
Но из -за этого я злюсь. Это трудно сделать? Почему писатель Google Bert Bert отказался от этого делать?
Почему существует такое большое изменение от Tensorflow 1,0 до 2.0? Разве не потому, что 2.0 для людей использует?
Вы не сделаете интерфейс освежающим и простым, ваши конкуренты (Turicreate и Fast.ai) сделают это, и они делают это очень хорошо. Только когда я не могу сидеть все еще, могу ли я быть готовым преуменьшать благородного и разработать полезный интерфейс для обычных людей.
Урок! Почему ты не поглощаешь это?
Я предоставлю вам образец ноутбука Google Colab, который вы можете легко заменить в своем собственном наборе данных. Вы должны понимать (включая изменение) кода, не более 10 строк .
Впервые я проверил задачу классификации текстовой текста английского языка, и это работало очень хорошо. Поэтому я написал средний блог, который был немедленно включен в колонку «Название данных».
Редактор столбцов с данными науки прислал мне личное сообщение с надписью:
Очень интересно, мне это нравится, учитывая, что реализация по умолчанию не очень дружелюбна для разработчиков.
Был читатель, который на самом деле дал эту статью 50 лайков (хлопки) подряд, и я был ошеломлен.

Кажется, что эта длинносодержащая болезнь-не только я.
Предполагается, что китайские задачи классификации могут столкнуться с большим количеством в вашем исследовании. Поэтому я просто сделал еще один пример китайской текстовой классификации и написал этот учебник и поделился им с вами.
Давайте начнем.
Пожалуйста, нажмите на эту ссылку, чтобы просмотреть файл ноутбука ipython, который я сделал для вас на GitHub.
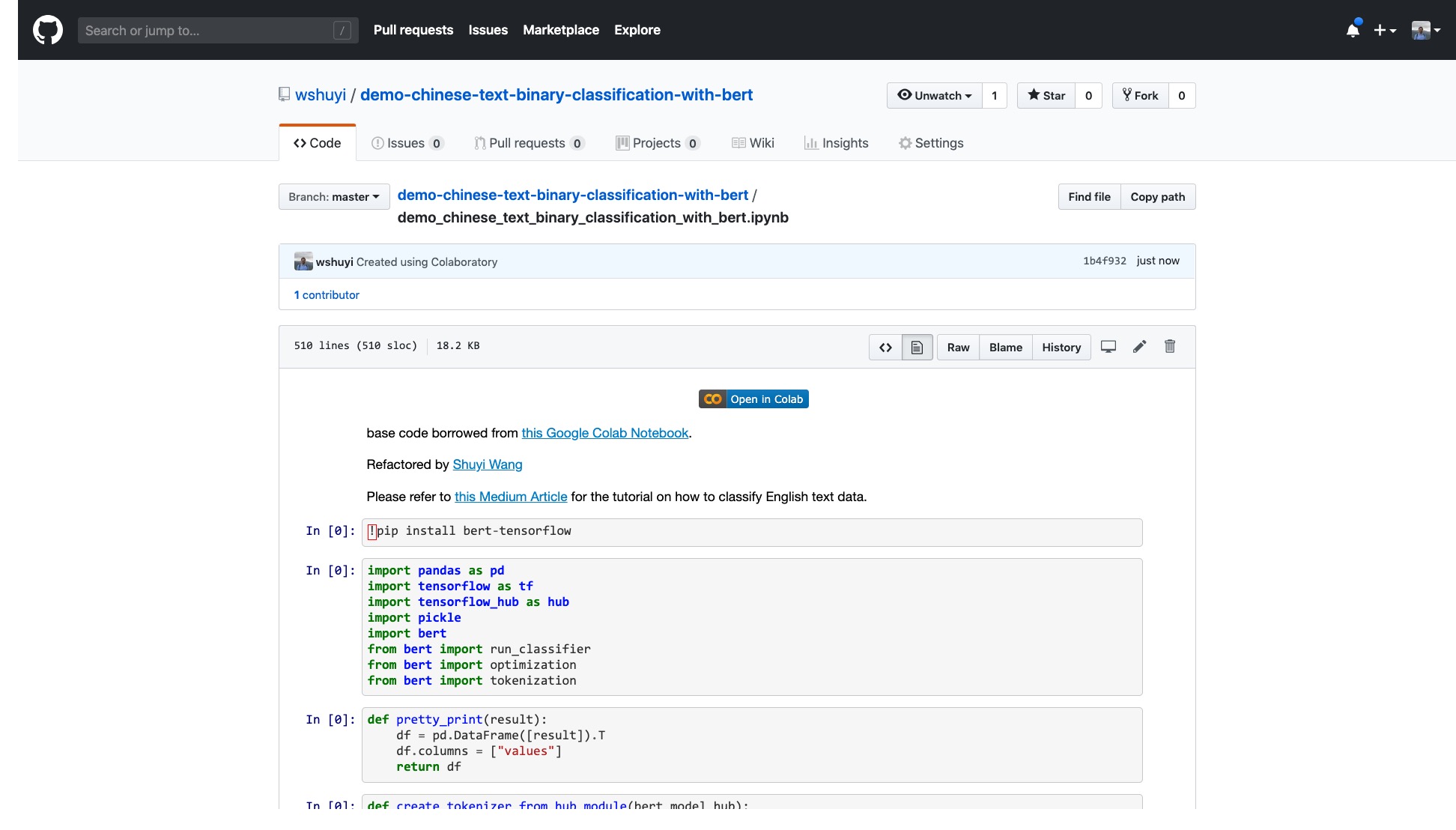
В верхней части ноутбука есть очень очевидная кнопка «Открыть в колабах». Нажмите на него, и Google Colab автоматически включит и загрузите эту ноутбук.
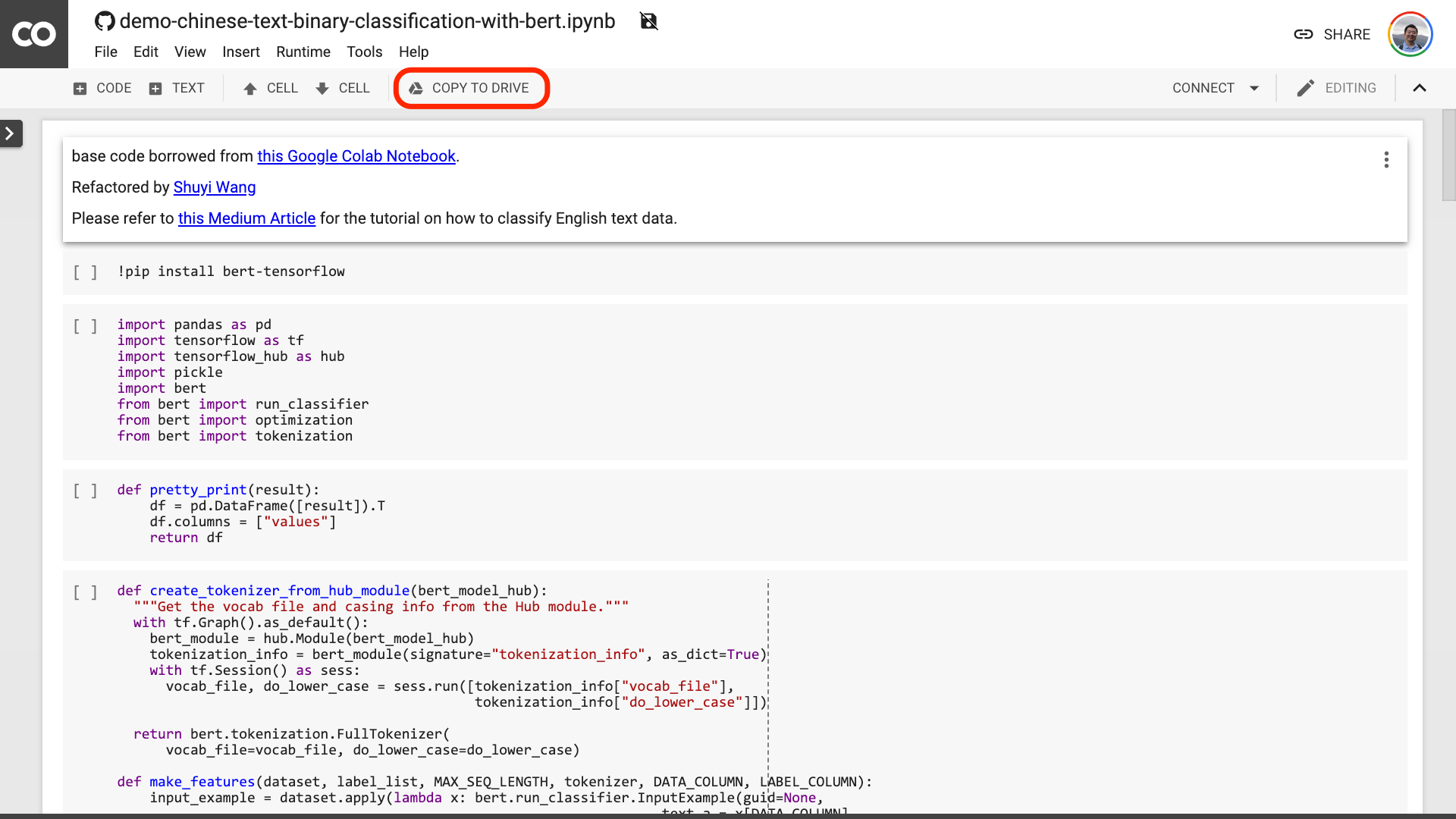
Я предлагаю вам нажать кнопку «Копировать на драйв», обведенная в красном изображении выше. Сначала это сохранит его в вашем собственном Google Drive для использования и просмотра.
После того, как это сделано, вам на самом деле нужно выполнить только следующие три шага:
После того, как вы сохраните ноутбук. Если вы присмотритесь, вы можете почувствовать себя обманутым.
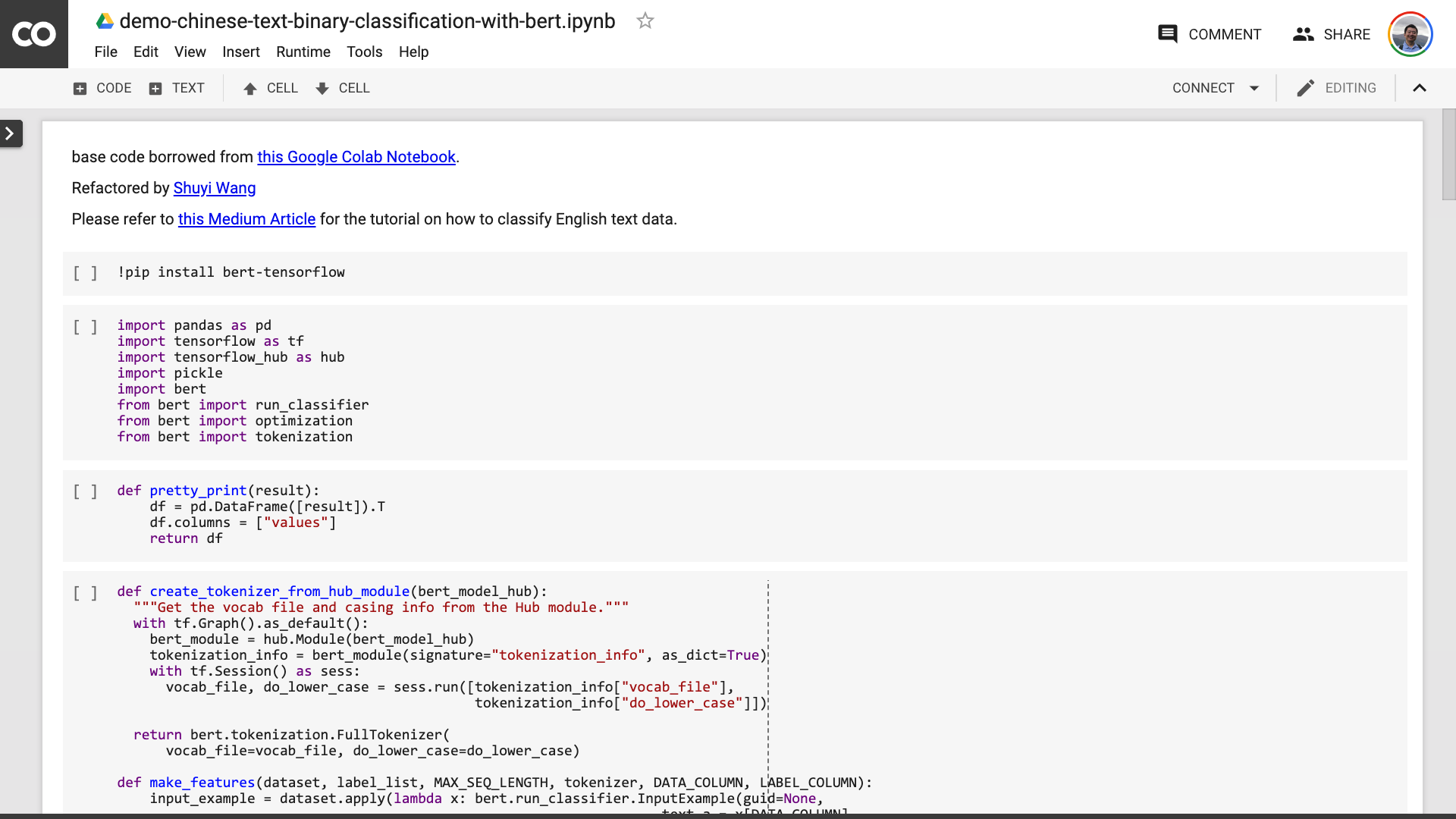
Учитель, ты солгал! Согласно, что не более 10 строк кода!
Не беспокойся .
Вам не нужно что -то изменять, прежде чем предложение обведено в красном на рисунке ниже.
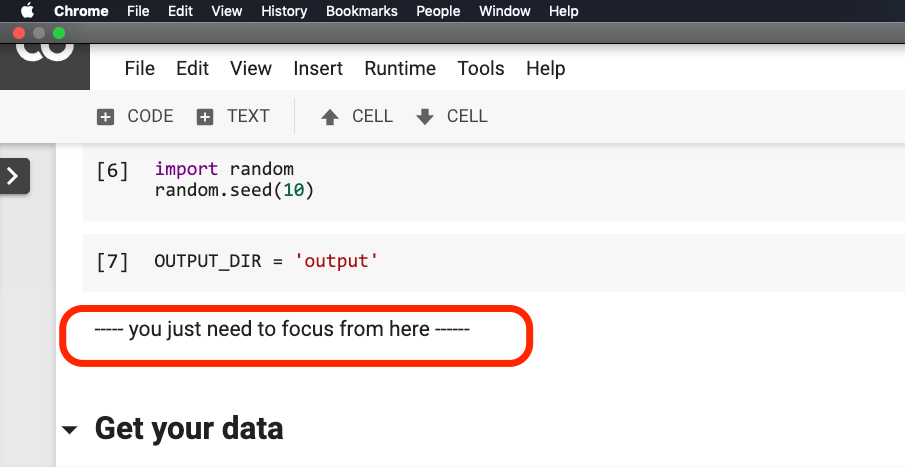
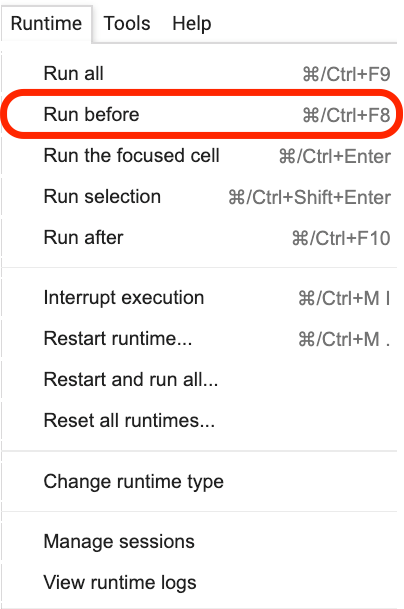
Пожалуйста, нажмите, где находится это предложение, а затем выберите Run before в меню, как показано на следующем рисунке.
Ниже приведены все важные ссылки, фокус.
Первым шагом является подготовка данных.
!w get https : // github . com / wshuyi / demo - chinese - text - binary - classification - with - bert / raw / master / dianping_train_test . pickle
with open ( "dianping_train_test.pickle" , 'rb' ) as f :
train , test = pickle . load ( f )Вы должны быть знакомы с данными, используемыми здесь. Это эмоциональные данные аннотации обзоров общественного питания. Я нахожусь в «Как обучить китайскую модель классификации текстовых эмоций с питоном и машинным обучением?》 И« Как использовать Python и повторяющиеся нейронные сети для классификации китайских текстов? 》 Использовал его. Тем не менее, для удобства демонстрации я вывожу его в качестве формата Pickle на этот раз и вкладываю в демонстрационный Github Repo вместе для вашей загрузки и использования.
Учебный набор содержит 1600 кусков данных; Тестовый набор содержит 400 элементов данных. На этикетке 1 представляет положительные эмоции, а 0 представляет отрицательные эмоции.
Используя следующее утверждение, мы перетасоваем учебный набор и нарушаем заказ. Чтобы избежать переживания.
train = train . sample ( len ( train ))Давайте посмотрим на содержание головы в нашем обучении.
train . head ()
Если вы хотите заменить свой собственный набор данных позже, пожалуйста, обратите внимание на формат. Названия столбцов обучающих и тестовых наборов должны быть последовательными.
На втором этапе мы установим параметры.
myparam = {
"DATA_COLUMN" : "comment" ,
"LABEL_COLUMN" : "sentiment" ,
"LEARNING_RATE" : 2e-5 ,
"NUM_TRAIN_EPOCHS" : 3 ,
"bert_model_hub" : "https://tfhub.dev/google/bert_chinese_L-12_H-768_A-12/1"
}Первые две строки должны четко указать соответствующие имена столбцов текста и знаков.
Третья строка указывает уровень обучения. Вы можете прочитать оригинальную статью, чтобы сделать попытку корректировки гиперпараметра. Или вы можете просто сохранить значение по умолчанию без изменений.
Строка 4, укажите количество учебных раундов. Запустите все данные в один раунд. Здесь используются 3 раунда.
Последняя строка показывает предварительно обученную модель BERT, которую вы хотите использовать. Мы хотим классифицировать китайский текст, поэтому мы используем этот китайский предварительно обученный адрес модели. Если вы хотите использовать английский, вы можете обратиться к моей средней пост в блоге и соответствующем примере английского языка.
На последнем шаге мы просто выполняем код по очереди.
result , estimator = run_on_dfs ( train , test , ** myparam )Обратите внимание, что для выполнения этого предложения может потребоваться некоторое время . Быть умственно подготовленным. Это связано с вашим объемом данных и настройками обучения.
В этом процессе вы можете видеть, что программа сначала поможет вам превратить исходный китайский текст в формат входных данных, который BERT может понять.
Когда вы видите текст, обведенный в красном на рисунке ниже, это означает, что учебный процесс наконец закончился.
Затем вы можете распечатать результаты теста.
pretty_print ( result )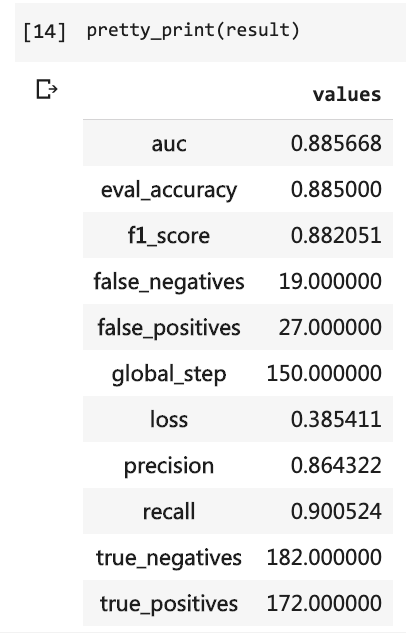
Сравните с нашим предыдущим учебником (с использованием того же набора данных).
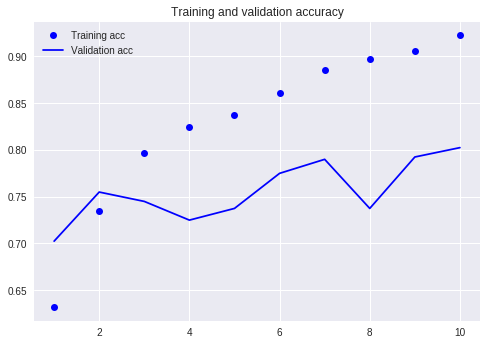
В то время мне пришлось написать так много строк кода, и мне пришлось запустить 10 раундов, но результат был все еще не более 80%. На этот раз, хотя я тренировался только в течение 3 раундов, уровень точности превысил 88%.
Нелегко достичь такой точности в таком небольшом наборе данных.
Производительность BERT очевидна.
Сказав это, вы научились использовать Bert для выполнения задачи бинарной классификации китайского текста. Я надеюсь, что вы будете так же счастливы, как и я.
Если вы старший энтузиаст Python, пожалуйста, сделайте мне одолжение.
Помните код до этой строки?
Вы можете помочь мне упаковать их? Таким образом, наш демонстрационный код может быть короче, более кратким, более четким и проще в использовании.
Добро пожаловать, чтобы отправить свой код в нашем проекте GitHub. Если вы найдете этот учебник полезным, добавьте звезды в этот проект GitHub. Спасибо!
Счастливого глубокого обучения!
Вы также можете быть заинтересованы в следующих темах. Нажмите на ссылку, чтобы просмотреть ее.
Если вам это нравится, пожалуйста, нравится и вознаградить. Вы также можете следовать и возглавить мой официальный аккаунт «Yushuzhilan» (Nkwangshuyi) на WeChat.
Если вы заинтересованы в Python и Data Science, вы можете также прочитать мою серию постов индекса учебных заведений «Как эффективно начать работу с наукой о данных?》, В нем есть более интересные вопросы и решения.
Вход в планету знаний здесь:


