demo chinese text binary classification with bert
1.0.0

El año pasado, estaba muy emocionado tan pronto como se lanzó el modelo Bert de Google.
Porque estaba usando Fast.Ai's Ulmfit para hacer tareas de clasificación de lenguaje natural en ese momento (también escribí un artículo especial "¿Cómo usar Python y Deep Transfer Learning para clasificar los textos?" Para compartir con usted). Ulmfit y Bert son modelos lingüísticos previamente capacitados y tienen muchas similitudes.
El llamado modelo de lenguaje utiliza una estructura de red neuronal profunda para entrenar en textos de idiomas masivos para comprender las características comunes de un idioma.
El trabajo anterior a menudo solo es posible para que las grandes instituciones completen. Porque el costo es demasiado grande.
Este costo incluye, pero no se limita a:
La capacitación previa significa que abren este resultado después de que se entrenen. Las personas comunes o las instituciones pequeñas también podemos pedir prestados los resultados y ajustar nuestros propios datos de texto en nuestros campos especializados para que el modelo pueda tener una comprensión muy clara del texto en este campo especializado.
La llamada comprensión se refiere principalmente al hecho de que bloquea ciertas palabras, y el modelo puede adivinar con mayor precisión lo que está ocultando.
Incluso si junta dos oraciones, el modelo puede determinar si son relaciones contextuales estrechamente conectadas.

¿Es útil este "conocimiento"?
Por supuesto que hay.
Bert probó en múltiples tareas de lenguaje natural, y muchos resultados han superado a los jugadores humanos.

Bert puede ayudar a resolver tareas, por supuesto, también incluye la clasificación de texto, como la clasificación de emociones. Este es también el problema que estoy estudiando actualmente.
Sin embargo, para usar Bert, esperé mucho tiempo.
El código oficial de Google ha sido abierto. Incluso la implementación en Pytorch ha sido iterada durante muchas rondas.
Pero solo necesito abrir la muestra que proporcionan y me mareo.
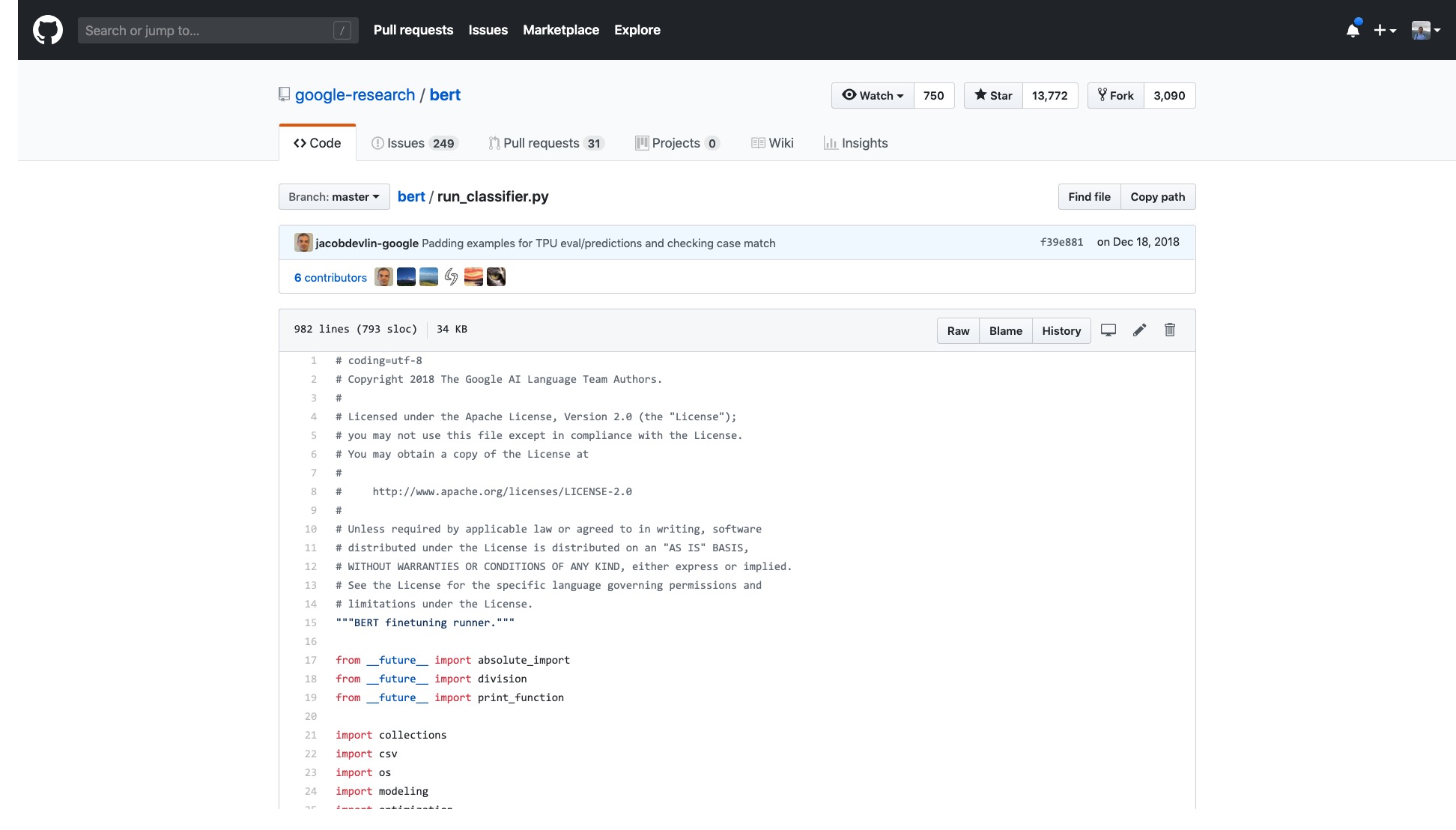
El número de líneas solo en ese código es muy aterrador.
Además, un montón de procesos de procesamiento de datos (procesadores de datos) llevan el nombre del nombre del conjunto de datos. Mis datos no pertenecen a ninguno de los anteriores, entonces, ¿cuál debería usar?

También hay innumerables banderas (banderas) que son inexplicablemente problemáticas.

Comparemos cómo se ve la estructura de sintaxis en Scikit-Learn al hacer tareas de clasificación.
from sklearn . datasets import load_iris
from sklearn import tree
iris = load_iris ()
clf = tree . DecisionTreeClassifier ()
clf = clf . fit ( iris . data , iris . target )Incluso si el rendimiento de datos de la clasificación de imágenes es grande y requiere muchos pasos, puede hacerlo fácilmente con algunas líneas de código usando Fast.ai.
!g it clone https : // github . com / wshuyi / demo - image - classification - fastai . git
from fastai . vision import *
path = Path ( "demo-image-classification-fastai/imgs/" )
data = ImageDataBunch . from_folder ( path , test = 'test' , size = 224 )
learn = cnn_learner ( data , models . resnet18 , metrics = accuracy )
learn . fit_one_cycle ( 1 )
interp = ClassificationInterpretation . from_learner ( learn )
interp . plot_top_losses ( 9 , figsize = ( 8 , 8 ))No subestimes estas líneas de código. No solo le ayuda a entrenar un clasificador de imagen, sino que también le dice dónde está prestando atención el modelo en esas imágenes con el error de clasificación más alto.

Comparación, ¿cuál crees que es la diferencia entre Bert Ejemplo y Fast.Ai Ejemplo?
Creo que esto último es que la gente lo use .
Siempre pensé que alguien refactoraba el código y escribiría un tutorial conciso.
Después de todo, las tareas de clasificación de texto son una aplicación de aprendizaje automático común. Hay muchos escenarios de aplicación y también son adecuados para principiantes.
Sin embargo, simplemente no esperé ese tutorial.
Por supuesto, durante este período, también he leído aplicaciones y tutoriales escritos por muchas personas.
Algunas personas pueden convertir una pieza de texto de lenguaje natural a codificación de Bert. Terminó abruptamente.
Algunas personas presentan cuidadosamente cómo usar Bert en los conjuntos de datos oficiales proporcionados. Todas las modificaciones se realizan en el script Python original. Todas las funciones y parámetros que no se utilizan en absoluto se conservan. ¿En cuanto a cómo otros reutilizan sus propios conjuntos de datos? La gente no mencionó esto en absoluto.
He pensado en masticar el código desde el principio. Recuerdo que cuando estudiaba para la escuela de posgrado, también leí todos los códigos C de las capas TCP e IP en la plataforma de simulación. Determiné la tarea frente a mí, lo cual fue menos difícil.
Pero realmente no quiero hacerlo. Siento que estoy mimado por Python Machine Learning Frameworks, especialmente Fast.Ai y Scikit-Learn.
Más tarde, los desarrolladores de Google llevaron a Bert al Hub TensorFlow. También escribí una muestra de cuaderno de Google Colab específicamente.
Estaba tan feliz de ver esta noticia.
He probado muchos otros modelos en TensorFlow Hub. Es muy conveniente de usar. ¿Y Google Colab he practicado Python con Google Colab? 》 Se le presenta en el artículo ", que es un muy buen entorno de demostración y ejercicio de aprendizaje profundo de Python. Pensé que las dos espadas podrían combinarse, y esta vez podría manejar mis propias tareas con algunas líneas de código.
Esperemos.
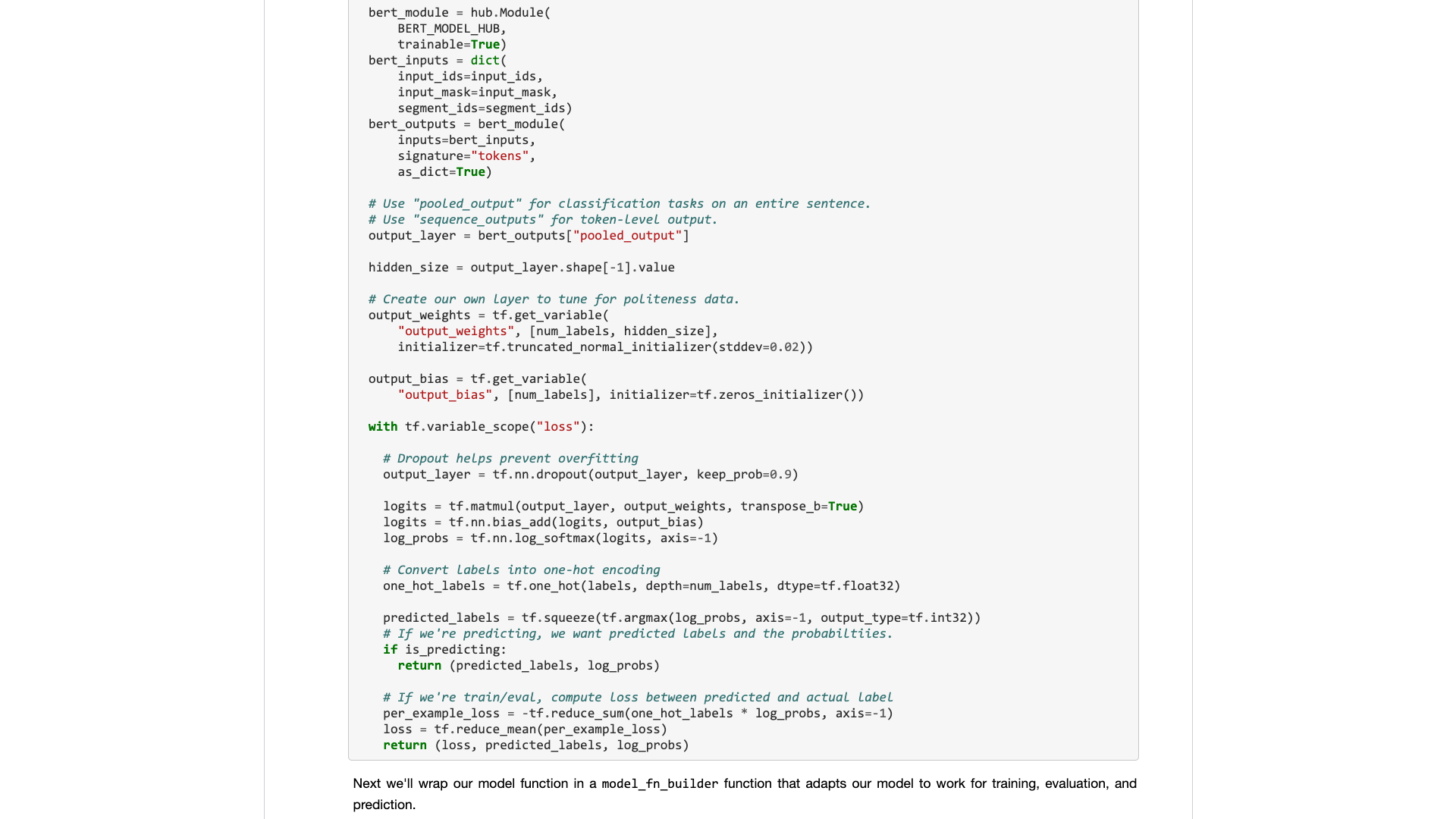
Cuando realmente lo abra, aún se centrará en los datos de la muestra.
¿Qué necesitan los usuarios ordinarios? Se requiere una interfaz.
Me dices las especificaciones estándar que ingresó y luego me dices cuáles pueden ser los resultados. Conecte y reproduce, y deja después de todo.
Una tarea de clasificación de texto originalmente le dio un conjunto de entrenamiento y un conjunto de pruebas, diciéndole qué tan rápido son las rondas de entrenamiento y luego me dicen la tasa de precisión y los resultados.
En cuanto a pedirme que lea cientos de líneas de código para una tarea tan simple y descubra dónde cambiarlo usted mismo.
Afortunadamente, con este ejemplo como base, es mejor que nada.
Tomé mi paciencia y la resolví.
Para afirmar, no hice ningún cambio importante en el código original.
Entonces, si no lo explica claramente, se sospechará de plagio y será despreciado.
Este tipo de organización no es técnicamente difícil para las personas que saben cómo usar Python.
Pero por esto, me enojo. ¿Es esto difícil de hacer? ¿Por qué el escritor de muestras de Bert de Google se negó a hacerlo?
¿Por qué hay un cambio tan grande de TensorFlow 1.0 a 2.0? ¿No es porque 2.0 es para que las personas lo usen?
No hará que la interfaz sea refrescante y simple, sus competidores (Turicreate y Fast.ai) lo hará, y lo harán muy bien. Solo cuando no puedo quedarme quieto, ¿puedo estar dispuesto a minimizar al noble y desarrollar una interfaz útil para la gente común?
¡Una lección! ¿Por qué no lo absorbes?
Le proporcionaré una muestra de cuaderno de Google Colab que puede reemplazar fácilmente en su propio conjunto de datos para ejecutar. Debe comprender (incluida la modificación) del código, no más de 10 líneas .
Probé por primera vez una tarea de clasificación de texto en inglés, y funcionó muy bien. Así que escribí un blog mediano, que se incluyó inmediatamente en la columna H para Data Science.
El editor de la columna de ciencia de datos de Data me envió un mensaje privado que decía:
Muy interesante, me gusta esto considerando que la implementación predeterminada no es muy amigable para el desarrollador con seguridad.
Hubo un lector que realmente dio este artículo 50 me gusta (aplausos) seguidos, y me sorprendió.

Parece que este punto de dolor de larga data no es solo yo.
Se estima que las tareas de clasificación china se pueden encontrar más en su investigación. Así que simplemente hice otro ejemplo de clasificación de texto chino y escribí este tutorial y lo compartí con usted.
Comencemos.
Haga clic en este enlace para ver el archivo del cuaderno de iPython que hice para usted en GitHub.
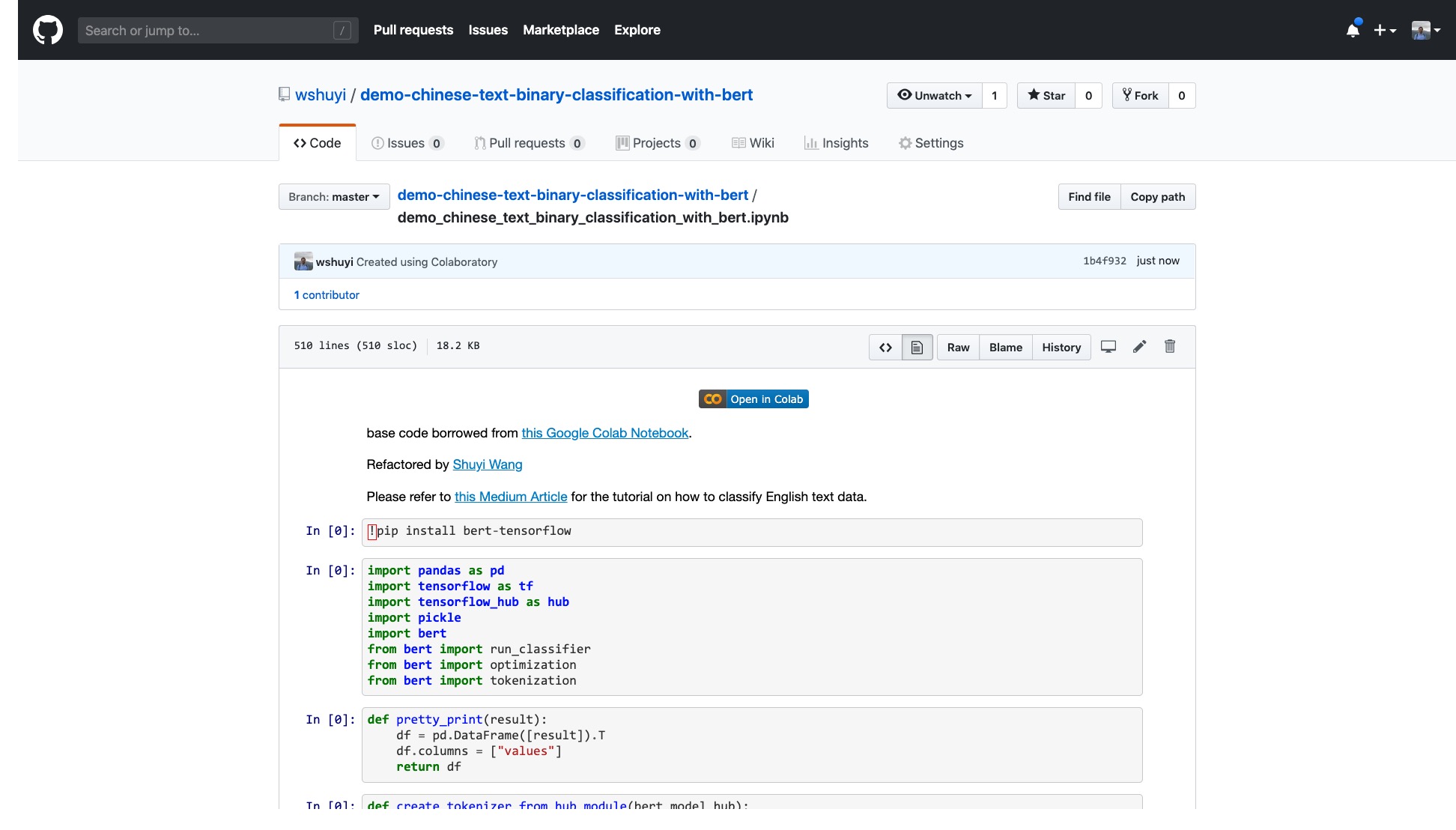
En la parte superior del cuaderno, hay un botón "Abierto en Colab" muy obvio. Haga clic en él y Google Colab activará automáticamente y cargará este cuaderno.
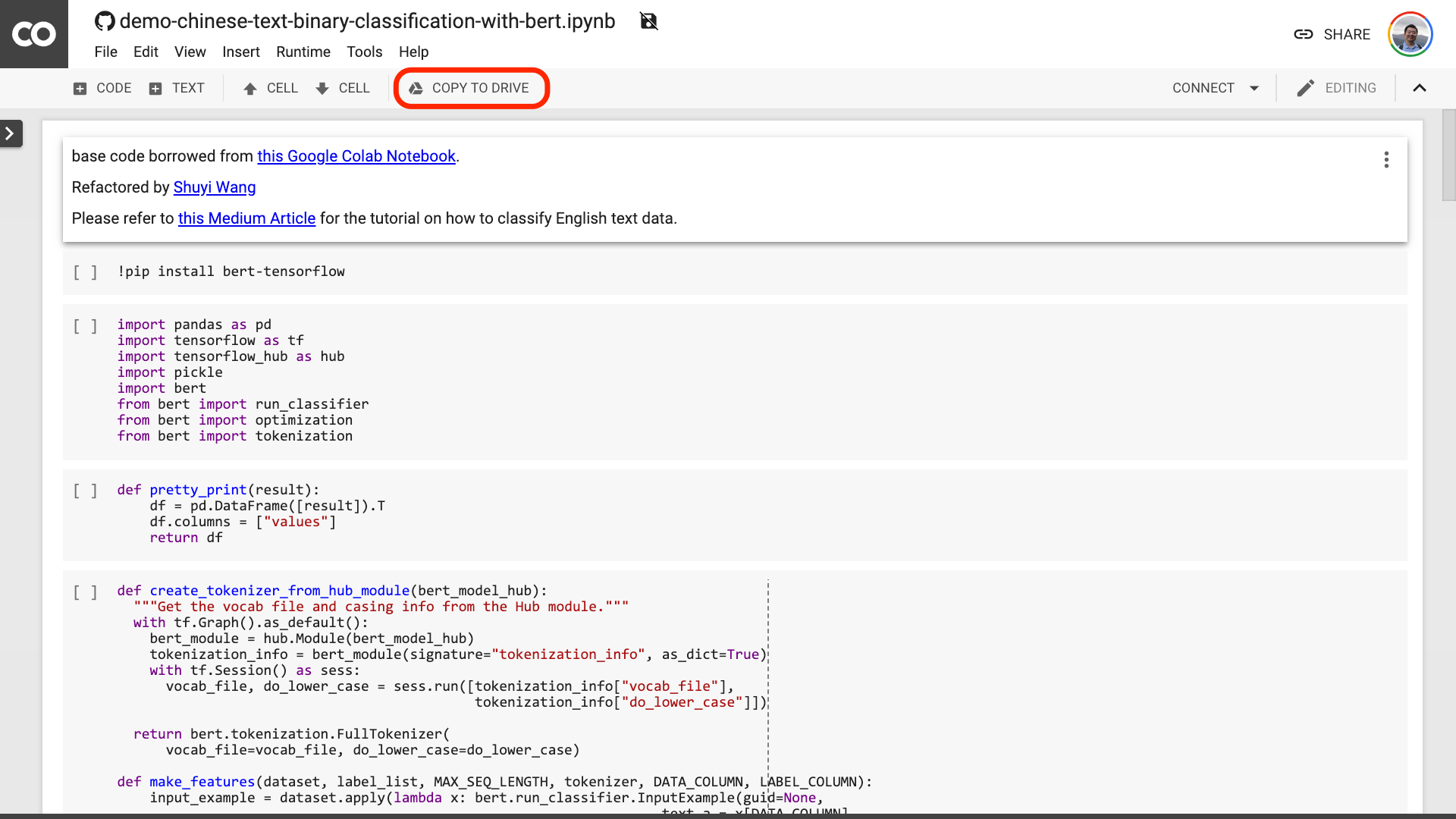
Le sugiero que haga clic en el botón "Copiar para conducir" en la imagen roja de arriba. Esto lo guardará primero en su propia unidad de Google Drive para su uso y revisión.
Una vez hecho esto, en realidad solo necesita realizar los siguientes tres pasos:
Después de guardar el cuaderno. Si miras de cerca, puedes sentirte engañado.
¡Maestro, mentiste! ¡Se acuerda que no más de 10 líneas de código!
No estés ansioso .
No necesita modificar nada antes de que la oración rodeara en el rojo en la imagen a continuación.
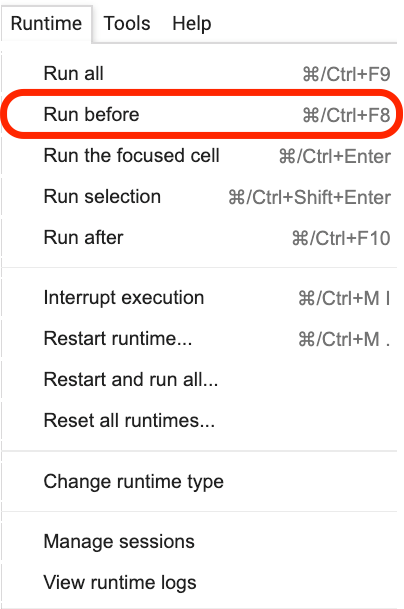
Haga clic donde se encuentra esta oración y luego seleccione Run before en el menú como se muestra en la siguiente figura.
Los siguientes son todos los enlaces importantes, Focus.
El primer paso es preparar los datos.
!w get https : // github . com / wshuyi / demo - chinese - text - binary - classification - with - bert / raw / master / dianping_train_test . pickle
with open ( "dianping_train_test.pickle" , 'rb' ) as f :
train , test = pickle . load ( f )Debe estar familiarizado con los datos utilizados aquí. Son los datos de anotación emocional de las revisiones de catering. Estoy en "¿Cómo entrenar el modelo de clasificación de emoción de texto chino con Python y el aprendizaje automático?》 Y" ¿Cómo usar Python y redes neuronales recurrentes para clasificar los textos chinos? 》 Lo ha usado. Sin embargo, para la comodidad de la demostración, lo llevo a cabo como formato de encurtido esta vez y lo pongo en la demostración GitHub Repo juntas para su descarga y uso.
El conjunto de entrenamiento contiene 1,600 datos de datos; El conjunto de pruebas contiene 400 datos. En la etiqueta, 1 representa emociones positivas y 0 representa emociones negativas.
Usando la siguiente declaración, barajamos el conjunto de capacitación e interrumpimos el pedido. Para evitar el sobreajuste.
train = train . sample ( len ( train ))Echemos un vistazo al contenido de la cabeza de nuestro conjunto de entrenamiento.
train . head ()
Si desea reemplazar su propio conjunto de datos más adelante, preste atención al formato. Los nombres de la columna de los conjuntos de entrenamiento y prueba deben ser consistentes.
En el segundo paso, estableceremos los parámetros.
myparam = {
"DATA_COLUMN" : "comment" ,
"LABEL_COLUMN" : "sentiment" ,
"LEARNING_RATE" : 2e-5 ,
"NUM_TRAIN_EPOCHS" : 3 ,
"bert_model_hub" : "https://tfhub.dev/google/bert_chinese_L-12_H-768_A-12/1"
}Las dos primeras líneas son indicar claramente los nombres de columna correspondientes del texto y las marcas.
La tercera línea especifica la tasa de entrenamiento. Puede leer el artículo original para hacer un intento de ajuste de hiperparameter. O bien, simplemente puede mantener el valor predeterminado sin cambios.
Línea 4, especifique el número de rondas de entrenamiento. Ejecute todos los datos en una ronda. Aquí se usan 3 rondas.
La última línea muestra el modelo previamente capacitado de Bert que desea usar. Queremos clasificar el texto chino, por lo que utilizamos esta dirección de modelo pre-entrenada china. Si desea usar el inglés, puede consultar mi publicación de blog Medium y el código de muestra de inglés correspondiente.
En el último paso, solo ejecutamos el código a su vez.
result , estimator = run_on_dfs ( train , test , ** myparam )Tenga en cuenta que puede llevar algún tiempo ejecutar esta oración. Estar preparado mentalmente. Esto está relacionado con el volumen de datos y la configuración de la ronda de capacitación.
En este proceso, puede ver que el programa primero lo ayuda a convertir el texto chino original en un formato de datos de entrada que Bert puede entender.
Cuando vea el texto rodeado en el rojo en la imagen a continuación, significa que el proceso de entrenamiento finalmente ha terminado.
Luego puede imprimir los resultados de la prueba.
pretty_print ( result )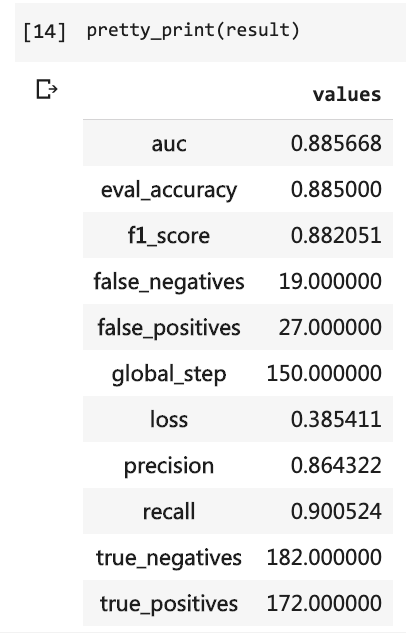
Compare con nuestro tutorial anterior (usando el mismo conjunto de datos).
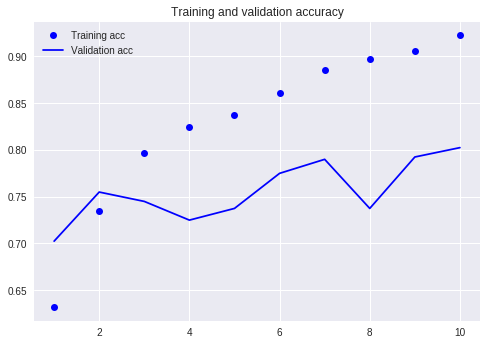
En ese momento, tuve que escribir tantas líneas de código y tuve que ejecutar 10 rondas, pero el resultado aún no era más del 80%. Esta vez, aunque solo entrené para 3 rondas, la tasa de precisión ha superado el 88%.
No es fácil lograr tal precisión en un conjunto de datos a escala tan pequeña.
El rendimiento de Bert es evidente.
Dicho esto, ha aprendido a usar Bert para hacer la tarea de clasificación binaria del texto chino. Espero que seas tan feliz como yo.
Si eres un entusiasta de Python senior, hazme un favor.
¿Recuerdas el código antes de esta línea?
¿Puedes ayudarme a empacarlos? De esta manera, nuestro código de demostración puede ser más corto, más conciso, más claro y más fácil de usar.
Bienvenido a enviar su código en nuestro proyecto GitHub. Si encuentra útil este tutorial, agregue estrellas a este proyecto GitHub. ¡Gracias!
¡Feliz aprendizaje profundo!
También puede estar interesado en los siguientes temas. Haga clic en el enlace para verlo.
Si te gusta, por favor me gusta y recompensa. También puede seguir y superar mi cuenta oficial "Yushuzhilan" (Nkwangshuyi) en WeChat.
Si está interesado en Python y Data Science, también podría leer mi serie de publicaciones de índice de tutoriales "¿Cómo comenzar con la ciencia de datos de manera eficiente?》, Hay preguntas y soluciones más interesantes en ella.
La entrada del planeta de conocimiento está aquí:


