demo chinese text binary classification with bert
1.0.0

ปีที่แล้วฉันตื่นเต้นมากทันทีที่รุ่น Bert ของ Google ได้รับการปล่อยตัว
เพราะฉันใช้ fast.ai ของ Ulmfit ในการทำงานการจำแนกภาษาธรรมชาติในเวลานั้น (ฉันยังเขียนบทความพิเศษ "วิธีใช้ Python และการเรียนรู้การถ่ายโอนอย่างลึกเพื่อจำแนกข้อความ?" เพื่อแบ่งปันกับคุณ) Ulmfit และ Bert เป็นทั้งแบบจำลองภาษาที่ผ่านการฝึกอบรมมาก่อนและมีความคล้ายคลึงกันมากมาย
รูปแบบภาษาที่เรียกว่าใช้โครงสร้างเครือข่ายประสาทลึกเพื่อฝึกฝนข้อความภาษาขนาดใหญ่เพื่อเข้าใจ คุณสมบัติทั่วไป ของภาษา
งานข้างต้นมักจะเป็นไปได้เท่านั้นที่สถาบันขนาดใหญ่จะเสร็จสมบูรณ์ เพราะ ค่าใช้จ่าย มากเกินไป
ค่าใช้จ่ายนี้รวมถึง แต่ไม่ จำกัด เพียง:
การฝึกอบรมล่วงหน้า หมายความว่าพวกเขาเปิดผลลัพธ์นี้หลังจากได้รับการฝึกฝน เราคนธรรมดาหรือสถาบันขนาดเล็กสามารถ ยืม ผลลัพธ์และ ปรับ ข้อมูลข้อความของเราเองในสาขาเฉพาะของเราเพื่อให้แบบจำลองสามารถมี ความเข้าใจ ที่ชัดเจนเกี่ยวกับข้อความในสาขาเฉพาะนี้
ความเข้าใจที่เรียกว่าส่วนใหญ่หมายถึงความจริงที่ว่าคุณบล็อกคำบางคำและแบบจำลองสามารถเดาได้อย่างแม่นยำยิ่งขึ้นว่าคุณกำลังซ่อนตัวอยู่
แม้ว่าคุณจะรวมสองประโยคเข้าด้วยกันโมเดลสามารถกำหนดได้ว่าพวกเขามีความสัมพันธ์เชิงบริบทที่เชื่อมโยงกันอย่างใกล้ชิดหรือไม่

"ความรู้" นี้มีประโยชน์หรือไม่?
แน่นอนว่ามี
เบิร์ตทดสอบงานภาษาธรรมชาติที่หลากหลายและผลลัพธ์หลายอย่างได้ผ่านผู้เล่นมนุษย์

แน่นอนว่าเบิร์ตสามารถช่วยในการแก้ปัญหางานรวมถึงการจำแนกประเภทข้อความเช่นการจำแนกอารมณ์ นี่เป็นปัญหาที่ฉันกำลังศึกษาอยู่
อย่างไรก็ตามเพื่อที่จะใช้เบิร์ตฉันรอเป็นเวลานาน
รหัส Google อย่างเป็นทางการเปิดแล้ว แม้แต่การใช้งานบน Pytorch ก็ยังได้รับการทำซ้ำหลายรอบ
แต่ฉันแค่ต้องเปิดตัวอย่างที่พวกเขาให้และฉันรู้สึกเวียนหัว
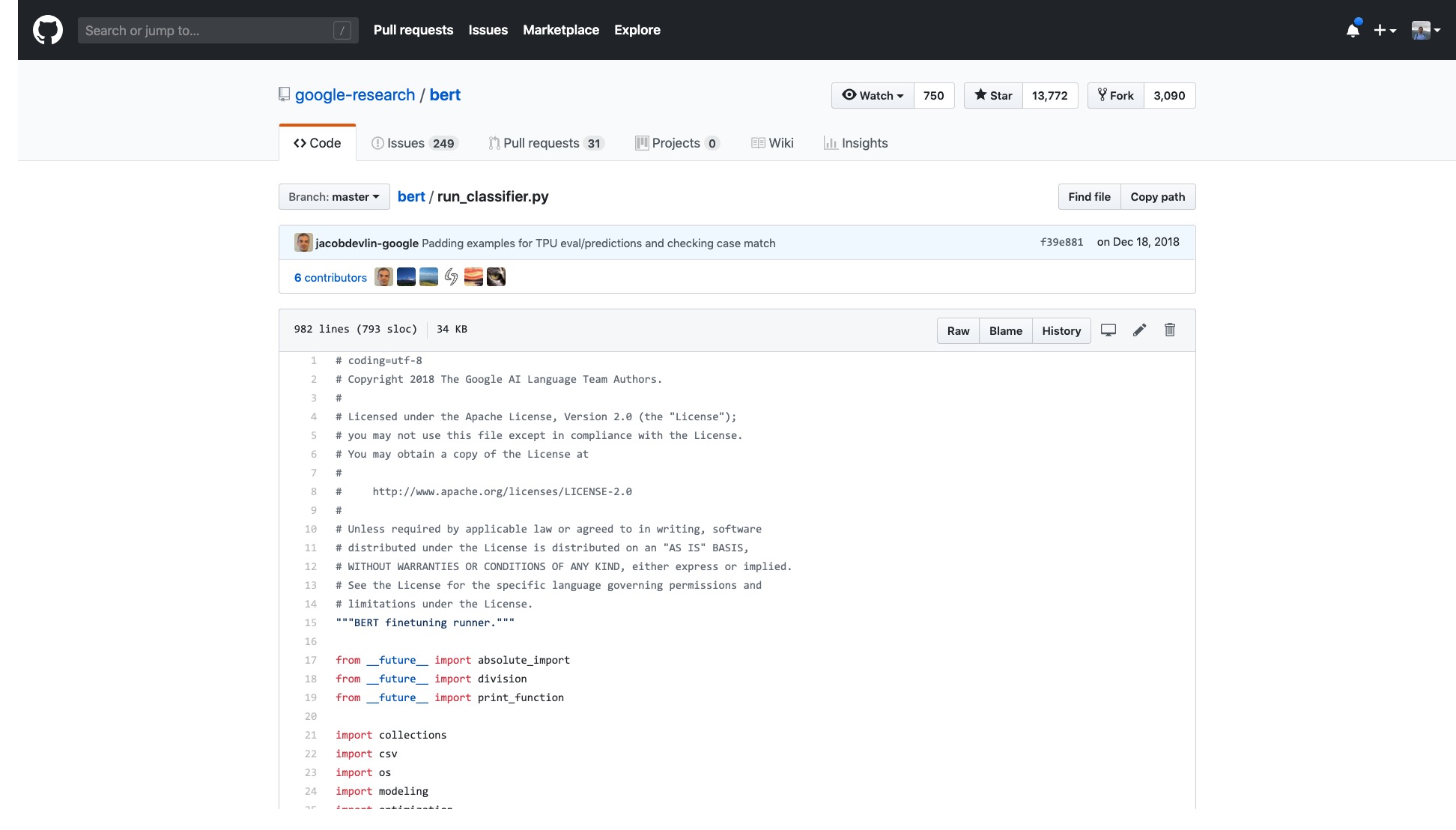
จำนวนบรรทัดในรหัสนั้นเพียงอย่างเดียวนั้นน่ากลัวมาก
ยิ่งไปกว่านั้นกระบวนการประมวลผลข้อมูลจำนวนมาก (ตัวประมวลผลข้อมูล) ได้รับการตั้งชื่อตามชื่อชุดข้อมูล ข้อมูลของฉันไม่ได้เป็นของใด ๆ ข้างต้นดังนั้นฉันควรใช้ข้อมูลใด

นอกจากนี้ยังมีธงจำนวนนับไม่ถ้วน (ธง) ที่ลำบากอย่างลึกลับ

ลองเปรียบเทียบสิ่งที่โครงสร้างไวยากรณ์ใน Scikit-learn ดูเหมือนเมื่อทำงานจำแนกประเภท
from sklearn . datasets import load_iris
from sklearn import tree
iris = load_iris ()
clf = tree . DecisionTreeClassifier ()
clf = clf . fit ( iris . data , iris . target )แม้ว่าข้อมูลปริมาณงานของการจำแนกภาพมีขนาดใหญ่และต้องใช้หลายขั้นตอนคุณสามารถทำได้อย่างง่ายดายด้วยรหัสสองสามบรรทัดโดยใช้ Fast.ai
!g it clone https : // github . com / wshuyi / demo - image - classification - fastai . git
from fastai . vision import *
path = Path ( "demo-image-classification-fastai/imgs/" )
data = ImageDataBunch . from_folder ( path , test = 'test' , size = 224 )
learn = cnn_learner ( data , models . resnet18 , metrics = accuracy )
learn . fit_one_cycle ( 1 )
interp = ClassificationInterpretation . from_learner ( learn )
interp . plot_top_losses ( 9 , figsize = ( 8 , 8 ))อย่าประมาทบรรทัดของรหัสเหล่านี้ ไม่เพียง แต่ช่วยให้คุณฝึกอบรมตัวจําแนกรูปภาพ แต่ยังบอกคุณว่าโมเดลนั้นให้ความสนใจกับภาพเหล่านั้นด้วยข้อผิดพลาดการจำแนกประเภทสูงสุด

การเปรียบเทียบคุณคิดว่าอะไรคือความแตกต่างระหว่างตัวอย่างของเบิร์ตและตัวอย่าง fast.ai?
ฉันคิดว่าหลังมีไว้ สำหรับคนที่จะใช้
ฉันคิดเสมอว่ามีคนจะสร้างรหัสใหม่และเขียนบทช่วยสอนที่กระชับ
ท้ายที่สุดงานการจำแนกประเภทข้อความเป็นแอปพลิเคชั่นการเรียนรู้ของเครื่องทั่วไป มีสถานการณ์แอปพลิเคชันมากมายและยังเหมาะสำหรับผู้เริ่มต้นที่จะเรียนรู้
อย่างไรก็ตามฉันไม่ได้รอการสอนแบบนี้
แน่นอนในช่วงเวลานี้ฉันได้อ่านแอปพลิเคชันและแบบฝึกหัดที่เขียนโดยคนจำนวนมาก
บางคนสามารถแปลงข้อความภาษาธรรมชาติเป็นส่วนหนึ่งเป็นการเข้ารหัส Bert มันสิ้นสุดลงอย่างกะทันหัน
บางคนแนะนำวิธีใช้ Bert ในชุดข้อมูลอย่างเป็นทางการอย่างระมัดระวัง การแก้ไขทั้งหมดจะทำบนสคริปต์ Python ดั้งเดิม ฟังก์ชั่นและพารามิเตอร์ทั้งหมดที่ไม่ได้ใช้ทั้งหมดจะถูกเก็บไว้ สำหรับคนอื่น ๆ นำชุดข้อมูลของตัวเองกลับมาใช้ใหม่ได้อย่างไร? ผู้คนไม่ได้พูดถึงเรื่องนี้เลย
ฉันคิดเกี่ยวกับการเคี้ยวรหัสตั้งแต่ต้น ฉันจำได้ว่าตอนที่ฉันเรียนจบบัณฑิตวิทยาลัยฉันยังอ่านรหัส C ทั้งหมดของเลเยอร์ TCP และ IP บนแพลตฟอร์มการจำลอง ฉันพิจารณางานต่อหน้าฉันซึ่งยากน้อยกว่า
แต่ฉันไม่อยากทำจริงๆ ฉันรู้สึกว่าฉันถูกทำลายโดยเฟรมเวิร์กการเรียนรู้ของเครื่อง Python โดยเฉพาะอย่างยิ่ง fast.ai และ scikit-learn
ต่อมา Google Developers นำ Bert ไปที่ Tensorflow Hub ฉันยังเขียนตัวอย่างโน้ตบุ๊ก Google Colab โดยเฉพาะ
ฉันมีความสุขมากที่ได้เห็นข่าวนี้
ฉันได้ลองใช้รุ่นอื่น ๆ อีกมากมายบน Tensorflow Hub ใช้งานได้สะดวกมาก และ Google Colab ฉันได้ฝึก Python กับ Google Colab แล้วหรือยัง? 》 ได้รับการแนะนำให้รู้จักกับคุณในบทความ "ซึ่งเป็นแบบฝึกหัดการเรียนรู้เชิงลึกของ Python ที่ดีมากและสภาพแวดล้อมการสาธิตฉันคิดว่าดาบทั้งสองสามารถรวมกันได้และคราวนี้ฉันสามารถจัดการงานของตัวเองด้วยรหัสสองสามบรรทัด
รอกันเถอะ
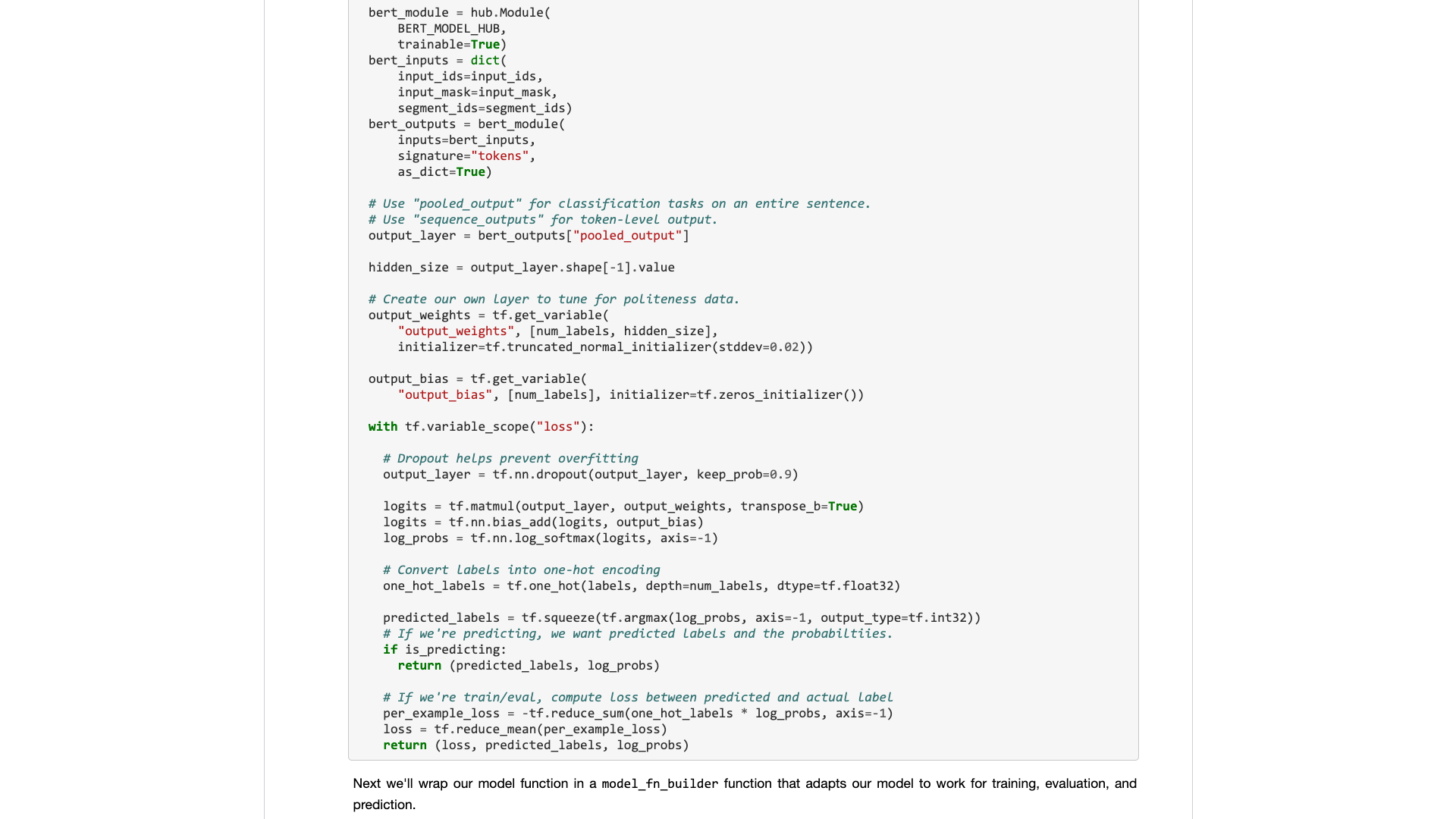
เมื่อคุณเปิดมันจริงๆคุณจะยังคงมุ่งเน้นไปที่ข้อมูลตัวอย่าง
ผู้ใช้ทั่วไปต้องการอะไร? จำเป็นต้องมีอินเทอร์เฟซ
คุณบอกข้อกำหนดมาตรฐานที่คุณป้อนแล้วบอกฉันว่าผลลัพธ์จะเป็นอย่างไร ปลั๊กและเล่นและทิ้งไว้หลังจากทั้งหมด
งานการจำแนกประเภทข้อความเดิมให้ชุดการฝึกอบรมและชุดทดสอบบอกคุณว่ารอบการฝึกซ้อมนั้นเร็วแค่ไหนแล้วบอกอัตราความแม่นยำและผลลัพธ์ให้ฉันฟัง
สำหรับการขอให้ฉันอ่านรหัสหลายร้อยบรรทัดสำหรับงานง่าย ๆ และค้นหาว่าจะเปลี่ยนด้วยตัวเองที่ไหน?
โชคดีที่ด้วยตัวอย่างนี้เป็นรากฐานมันดีกว่าไม่มีอะไรเลย
ฉันใช้ความอดทนและแยกออก
ในการระบุฉันไม่ได้ทำการเปลี่ยนแปลงที่สำคัญใด ๆ กับรหัสต้นฉบับ
ดังนั้นหากคุณไม่ได้อธิบายอย่างชัดเจนคุณจะต้องสงสัยว่าการลอกเลียนแบบและจะถูกดูหมิ่น
องค์กรประเภทนี้ไม่ยากสำหรับผู้ที่รู้วิธีใช้งูหลาม
แต่ด้วยเหตุนี้ฉันจึงโกรธ นี่เป็นเรื่องยากหรือไม่? เหตุใดนักเขียนตัวอย่าง Bert ของ Google จึงปฏิเสธที่จะทำ
เหตุใดจึงมีการเปลี่ยนแปลงครั้งใหญ่จาก TensorFlow 1.0 เป็น 2.0 ไม่ใช่เพราะ 2.0 สำหรับคนที่จะใช้หรือไม่
คุณจะไม่ทำให้อินเทอร์เฟซสดชื่นและเรียบง่ายคู่แข่งของคุณ (turicreate และ fast.ai) จะทำมันและพวกเขาทำได้ดีมาก เฉพาะเมื่อฉันไม่สามารถนั่งได้ฉันสามารถยินดีที่จะมองข้ามขุนนางและพัฒนาอินเทอร์เฟซที่มีประโยชน์สำหรับคนทั่วไป
บทเรียน! ทำไมคุณไม่ดูดซับ
ฉันจะให้ตัวอย่างโน้ตบุ๊ก Google Colab ที่คุณสามารถแทนที่ชุดข้อมูลของคุณเองเพื่อเรียกใช้ได้อย่างง่ายดาย คุณต้องเข้าใจ (รวมถึงการแก้ไข) รหัส ไม่เกิน 10 บรรทัด
ฉันทดสอบงานการจำแนกประเภทข้อความภาษาอังกฤษเป็นครั้งแรกและทำงานได้ดีมาก ดังนั้นฉันจึงเขียนบล็อกกลางซึ่งรวมอยู่ในคอลัมน์ Data Science ทันที
ตัวแก้ไขคอลัมน์ Data Science ส่งข้อความส่วนตัวถึงฉันว่า:
น่าสนใจมากฉันชอบสิ่งนี้เมื่อพิจารณาว่าการใช้งานเริ่มต้นนั้นไม่ได้เป็นมิตรกับนักพัฒนาที่แน่นอน
มีผู้อ่านคนหนึ่งที่ให้มาบทความ 50 ไลค์ (ปรบมือ) ติดต่อกันและฉันก็ตกตะลึง

ดูเหมือนว่าจุดปวดที่ยาวนานนี้ไม่ใช่แค่ฉัน
คาดว่างานการจำแนกประเภทจีนอาจพบได้มากขึ้นในการวิจัยของคุณ ดังนั้นฉันจึงทำตัวอย่างอีกครั้งของการจำแนกข้อความภาษาจีนและเขียนบทช่วยสอนนี้และแบ่งปันกับคุณ
เริ่มกันเถอะ
โปรดคลิกลิงก์นี้เพื่อดูไฟล์สมุดบันทึก ipython ที่ฉันทำเพื่อคุณบน GitHub
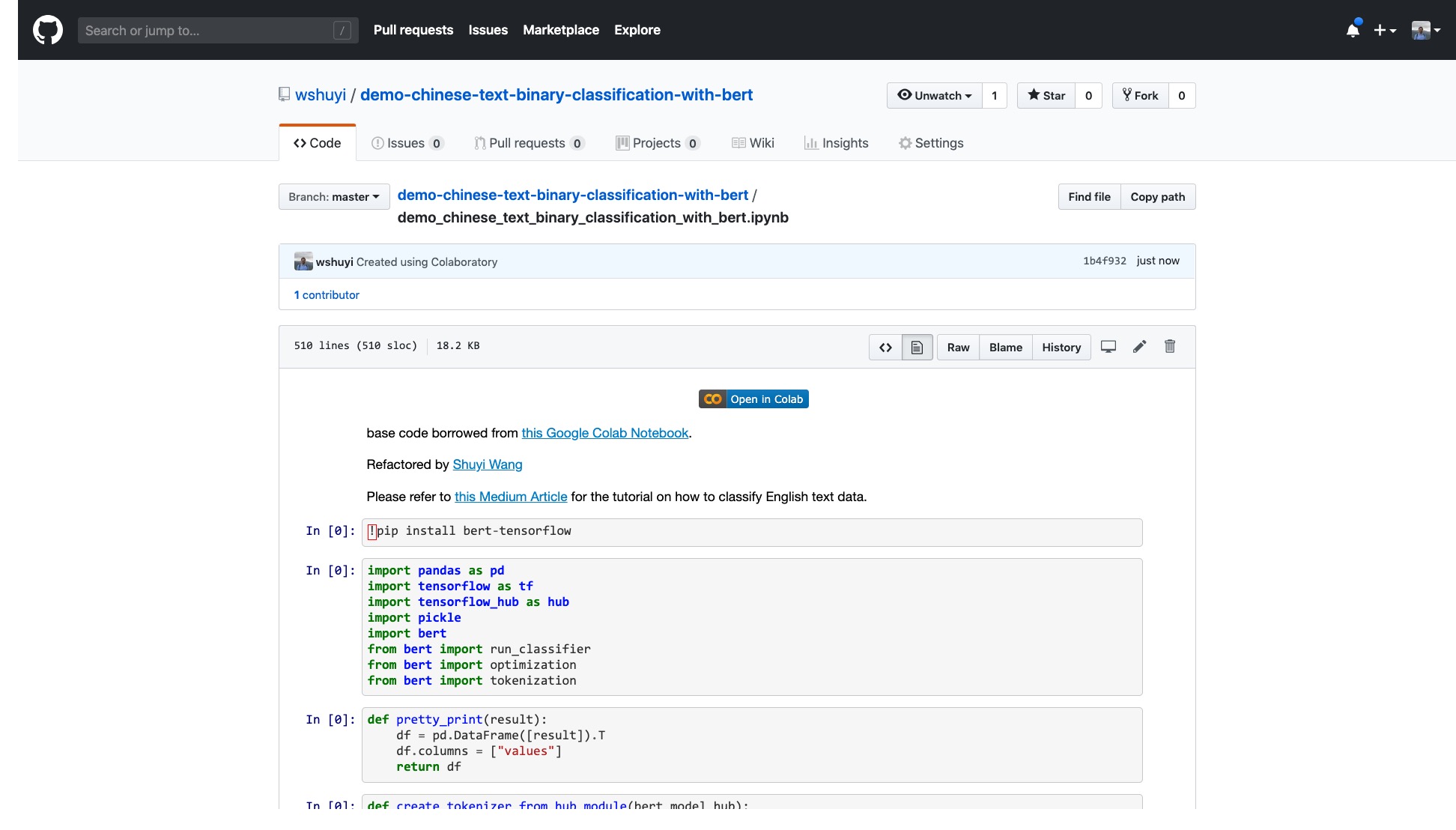
ที่ด้านบนของโน้ตบุ๊กมีปุ่ม "เปิดใน Colab" ที่ชัดเจนมาก คลิกที่ Google Colab จะเปิดและโหลดสมุดบันทึกนี้โดยอัตโนมัติ
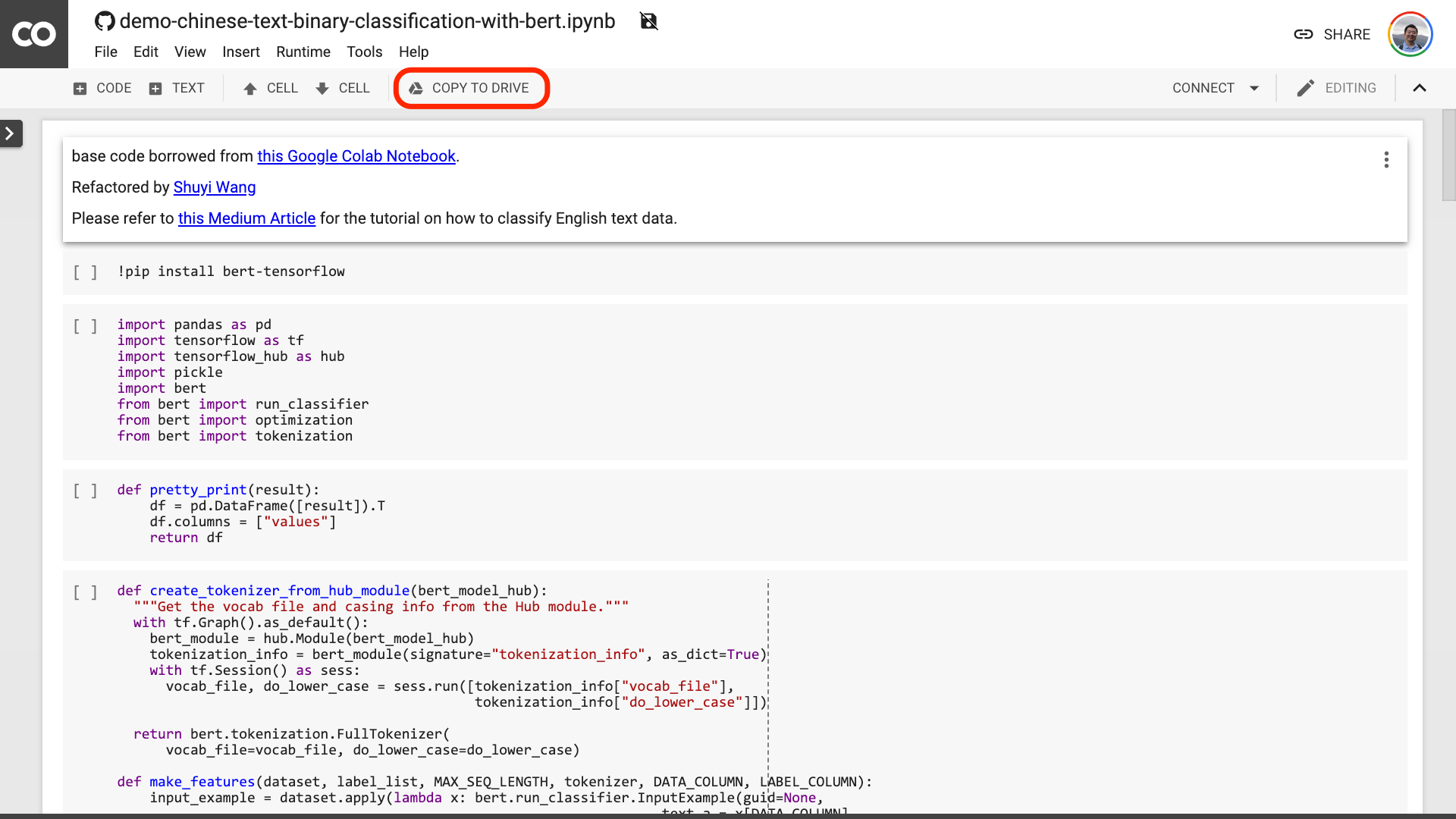
ฉันขอแนะนำให้คุณคลิกปุ่ม "Copy to Drive" วงกลมในภาพสีแดงด้านบน สิ่งนี้จะบันทึกไว้ใน Google Drive ของคุณเองก่อนใช้งานและตรวจสอบ
หลังจากทำสิ่งนี้เสร็จแล้วคุณจะต้องดำเนินการสามขั้นตอนต่อไปนี้เท่านั้น:
หลังจากที่คุณบันทึกสมุดบันทึก หากคุณมองอย่างใกล้ชิดคุณอาจรู้สึกหลงผิด
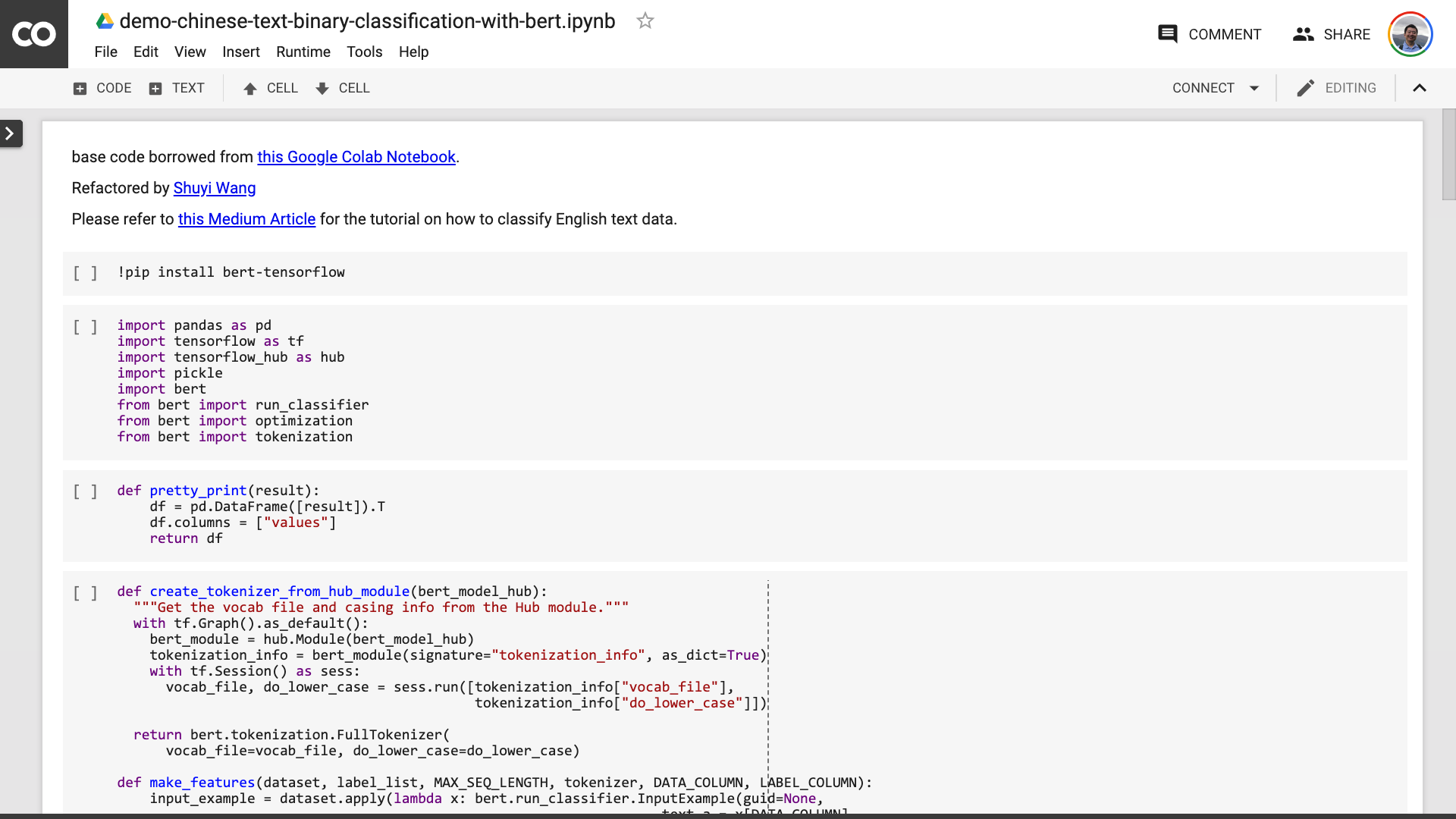
ครูคุณโกหก! ตกลงกันว่ารหัสไม่เกิน 10 บรรทัด!
อย่ากังวล
คุณ ไม่จำเป็นต้องแก้ไขอะไร ก่อนที่ประโยคจะวนเวียนอยู่ในสีแดงในภาพด้านล่าง
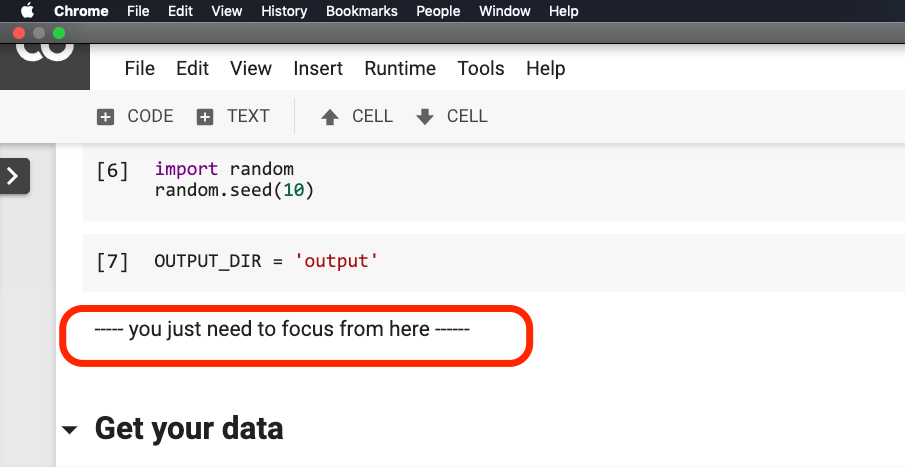
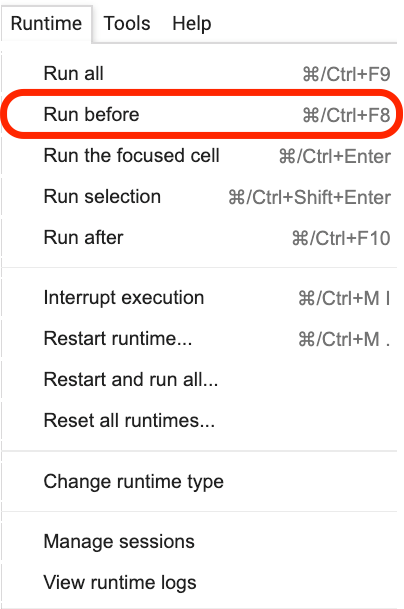
โปรดคลิกที่ประโยคนี้อยู่ที่ใดแล้วเลือก Run before จากเมนูดังที่แสดงในรูปต่อไปนี้
ต่อไปนี้เป็นลิงค์ที่สำคัญทั้งหมดโฟกัส
ขั้นตอนแรกคือการเตรียมข้อมูล
!w get https : // github . com / wshuyi / demo - chinese - text - binary - classification - with - bert / raw / master / dianping_train_test . pickle
with open ( "dianping_train_test.pickle" , 'rb' ) as f :
train , test = pickle . load ( f )คุณควรคุ้นเคยกับข้อมูลที่ใช้ที่นี่ มันเป็นข้อมูลคำอธิบายประกอบอารมณ์ของบทวิจารณ์การจัดเลี้ยง ฉันอยู่ใน "วิธีการฝึกอบรมรูปแบบการจำแนกอารมณ์ความรู้สึกของข้อความภาษาจีนด้วยการเรียนรู้ของ Python และ Machine?》 และ" วิธีใช้ Python และเครือข่ายประสาทที่เกิดขึ้นอีกเพื่อจำแนกตำราภาษาจีนได้อย่างไร 》 ใช้มัน อย่างไรก็ตามเพื่อความสะดวกของการสาธิตฉันส่งออกเป็นรูปแบบดองในครั้งนี้และนำไปใช้ในการสาธิต gitHub repo ร่วมกันสำหรับการดาวน์โหลดและการใช้งานของคุณ
ชุดการฝึกอบรมมีข้อมูล 1,600 ชิ้น ชุดทดสอบมีข้อมูล 400 ชิ้น ในฉลาก 1 แสดงถึงอารมณ์เชิงบวกและ 0 แสดงถึงอารมณ์เชิงลบ
การใช้ข้อความต่อไปนี้เราสลับชุดการฝึกอบรมและขัดขวางการสั่งซื้อ เพื่อหลีกเลี่ยงการ overfitting
train = train . sample ( len ( train ))มาดูเนื้อหาหัวของชุดการฝึกอบรมของเรา
train . head ()
หากคุณต้องการแทนที่ชุดข้อมูลของคุณเองในภายหลังโปรดให้ความสนใจกับรูปแบบ ชื่อคอลัมน์ของชุดการฝึกอบรมและชุดทดสอบควรสอดคล้องกัน
ในขั้นตอนที่สองเราจะตั้งค่าพารามิเตอร์
myparam = {
"DATA_COLUMN" : "comment" ,
"LABEL_COLUMN" : "sentiment" ,
"LEARNING_RATE" : 2e-5 ,
"NUM_TRAIN_EPOCHS" : 3 ,
"bert_model_hub" : "https://tfhub.dev/google/bert_chinese_L-12_H-768_A-12/1"
}สองบรรทัดแรกคือการระบุชื่อคอลัมน์ที่สอดคล้องกันของข้อความและเครื่องหมาย
บรรทัดที่สามระบุอัตราการฝึกอบรม คุณสามารถอ่านกระดาษต้นฉบับเพื่อทำการปรับเปลี่ยนพารามิเตอร์ หรือคุณสามารถรักษาค่าเริ่มต้นไม่เปลี่ยนแปลง
บรรทัดที่ 4 ระบุจำนวนรอบการฝึกอบรม เรียกใช้ข้อมูลทั้งหมดในรอบเดียว 3 รอบถูกใช้ที่นี่
บรรทัดสุดท้ายแสดงรุ่น Bert ที่ผ่านการฝึกอบรมล่วงหน้าที่คุณต้องการใช้ เราต้องการจำแนกข้อความภาษาจีนดังนั้นเราจึงใช้ที่อยู่รุ่นที่ผ่านการฝึกอบรมมาก่อนภาษาจีน หากคุณต้องการใช้ภาษาอังกฤษคุณสามารถอ้างอิงโพสต์บล็อกกลางของฉันและรหัสตัวอย่างภาษาอังกฤษที่เกี่ยวข้อง
ในขั้นตอนสุดท้ายเราเพิ่งเรียกใช้รหัสในทางกลับกัน
result , estimator = run_on_dfs ( train , test , ** myparam )โปรดทราบว่าอาจใช้ เวลาพอสมควร ในการดำเนินการประโยคนี้ เตรียมพร้อมทางจิตใจ สิ่งนี้เกี่ยวข้องกับปริมาณข้อมูลของคุณและการตั้งค่ารอบการฝึกอบรม
ในกระบวนการนี้คุณจะเห็นว่าโปรแกรมก่อนช่วยให้คุณเปลี่ยนข้อความภาษาจีนดั้งเดิมเป็นรูปแบบข้อมูลอินพุตที่เบิร์ตสามารถเข้าใจได้
เมื่อคุณเห็นข้อความวนเป็นสีแดงในภาพด้านล่างนั่นหมายความว่ากระบวนการฝึกอบรมสิ้นสุดลงในที่สุด
จากนั้นคุณสามารถพิมพ์ผลการทดสอบได้
pretty_print ( result )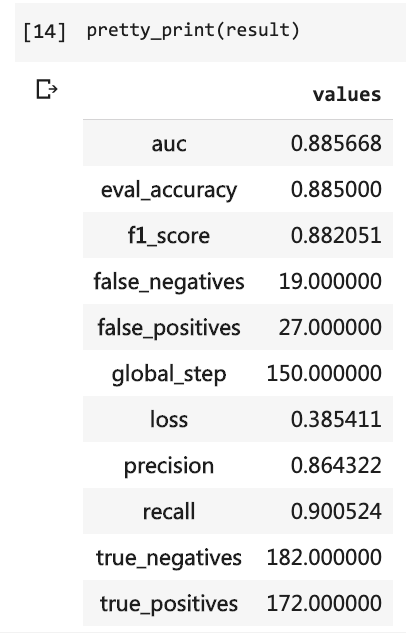
เปรียบเทียบกับบทช่วยสอนก่อนหน้าของเรา (ใช้ชุดข้อมูลเดียวกัน)
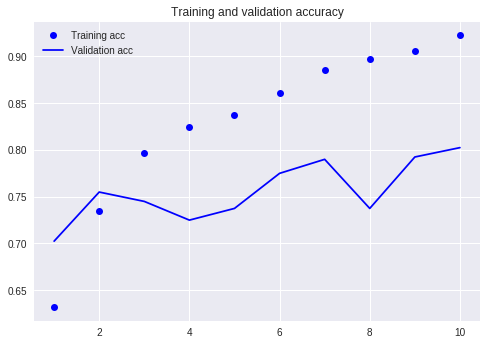
ในเวลานั้นฉันต้องเขียนโค้ดจำนวนมากและฉันต้องวิ่ง 10 รอบ แต่ผลลัพธ์ก็ยังไม่เกิน 80% คราวนี้แม้ว่าฉันจะได้รับการฝึกฝนเพียง 3 รอบ แต่อัตราความแม่นยำสูงกว่า 88%
ไม่ใช่เรื่องง่ายที่จะบรรลุความแม่นยำดังกล่าวในชุดข้อมูลขนาดเล็ก
ประสิทธิภาพ ของเบิร์ตนั้นเห็นได้ชัด
ต้องบอกว่าคุณได้เรียนรู้วิธีการใช้ Bert เพื่อทำภารกิจการจำแนกแบบไบนารีของข้อความภาษาจีน ฉันหวังว่าคุณจะมีความสุขเหมือนฉัน
หากคุณเป็นผู้ที่ชื่นชอบงูเหลือมอาวุโสโปรดทำสิ่งที่ฉันโปรดปราน
จำรหัสก่อนบรรทัดนี้ได้หรือไม่?
คุณช่วยฉันแพ็คได้ไหม ด้วยวิธีนี้รหัสตัวอย่างของเราอาจสั้นลงกระชับชัดเจนขึ้นชัดเจนและใช้งานง่ายขึ้น
ยินดีต้อนรับสู่การส่งรหัสของคุณในโครงการ GitHub ของเรา หากคุณพบว่าบทช่วยสอนนี้มีประโยชน์โปรดเพิ่มดาวในโครงการ GitHub นี้ ขอบคุณ!
มีความสุขในการเรียนรู้อย่างลึกซึ้ง!
คุณอาจสนใจในหัวข้อต่อไปนี้ คลิกลิงก์เพื่อดู
ถ้าคุณชอบโปรดชอบและให้รางวัล นอกจากนี้คุณยังสามารถติดตามและด้านบนบัญชีอย่างเป็นทางการของฉัน "Yushuzhilan" (Nkwangshuyi) บน WeChat
หากคุณมีความสนใจใน Python และ Data Science คุณอาจอ่านโพสต์ดัชนีการสอนของฉัน "วิธีเริ่มต้นใช้งานกับวิทยาศาสตร์ข้อมูลได้อย่างมีประสิทธิภาพ?》 มีคำถามและวิธีแก้ปัญหาที่น่าสนใจมากขึ้น
ทางเข้าดาวเคราะห์แห่งความรู้อยู่ที่นี่:


