demo chinese text binary classification with bert
1.0.0

L'année dernière, j'étais très excité dès que le modèle Bert de Google a été publié.
Parce que j'utilisais Fast.ai's UlmFit pour effectuer des tâches de classification du langage naturel à ce moment-là (j'ai également écrit un article spécial "Comment utiliser Python et un apprentissage en transfert profond pour classer les textes?" Pour partager avec vous). Ulmfit et Bert sont tous deux des modèles de langage pré-formés et ont de nombreuses similitudes.
Le modèle soi-disant langage utilise une structure de réseau neuronal profonde pour s'entraîner sur des textes de langage massifs pour saisir les caractéristiques communes d'une langue.
Le travail ci-dessus n'est souvent possible que pour les grandes institutions. Parce que le coût est trop grand.
Ce coût comprend mais sans s'y limiter:
La pré-formation signifie qu'ils ouvrent ce résultat après leur formation. Nous, des personnes ou de petites institutions ordinaires, nous pouvons également emprunter les résultats et affiner nos propres données de texte sur nos domaines spécialisés afin que le modèle puisse avoir une compréhension très claire du texte dans ce domaine spécialisé.
La soi-disant compréhension se réfère principalement au fait que vous bloquez certains mots, et le modèle peut deviner plus précisément ce que vous cachez.
Même si vous mettez deux phrases ensemble, le modèle peut déterminer s'ils sont des relations contextuelles étroitement connectées.

Cette «connaissance» est-elle utile?
Bien sûr, il y en a.
Bert a testé plusieurs tâches en langage naturel, et de nombreux résultats ont dépassé les joueurs humains.

Bert peut aider à résoudre les tâches, bien sûr, inclure également la classification du texte, comme la classification des émotions. C'est aussi le problème que j'étudie actuellement.
Cependant, pour utiliser Bert, j'ai attendu longtemps.
Le code Google officiel a été ouvert. Même la mise en œuvre de Pytorch a été itérée pour de nombreux tours.
Mais j'ai juste besoin d'ouvrir l'échantillon qu'ils fournissent et je me sens étourdi.
Le nombre de lignes dans ce code seul est très effrayant.
De plus, un tas de processus de traitement des données (processeurs de données) sont nommés d'après le nom du jeu de données. Mes données n'appartiennent à aucun des éléments ci-dessus, alors lequel dois-je utiliser?

Il existe également d'innombrables drapeaux (drapeaux) qui sont inexplicablement gênants.

Comparons à quoi ressemble la structure de syntaxe dans Scikit-Learn lors des tâches de classification.
from sklearn . datasets import load_iris
from sklearn import tree
iris = load_iris ()
clf = tree . DecisionTreeClassifier ()
clf = clf . fit ( iris . data , iris . target )Même si le débit de données de la classification d'images est important et nécessite de nombreuses étapes, vous pouvez facilement le faire avec quelques lignes de code en utilisant Fast.ai.
!g it clone https : // github . com / wshuyi / demo - image - classification - fastai . git
from fastai . vision import *
path = Path ( "demo-image-classification-fastai/imgs/" )
data = ImageDataBunch . from_folder ( path , test = 'test' , size = 224 )
learn = cnn_learner ( data , models . resnet18 , metrics = accuracy )
learn . fit_one_cycle ( 1 )
interp = ClassificationInterpretation . from_learner ( learn )
interp . plot_top_losses ( 9 , figsize = ( 8 , 8 ))Ne sous-estimez pas ces lignes de code. Il vous aide non seulement à former un classificateur d'images, mais vous indique également où le modèle prête attention dans ces images avec l'erreur de classification la plus élevée.

Comparaison, quelle est la différence entre l'exemple Bert et l'exemple rapide.
Je pense que ce dernier est à utiliser les gens .
J'ai toujours pensé que quelqu'un refacter le code et écrire un tutoriel concis.
Après tout, les tâches de classification du texte sont une application d'apprentissage automatique courante. Il existe de nombreux scénarios d'application et conviennent également aux débutants à apprendre.
Cependant, je n'ai pas attendu un tel tutoriel.
Bien sûr, pendant cette période, j'ai également lu des applications et des tutoriels écrits par de nombreuses personnes.
Certaines personnes peuvent convertir un morceau de texte en langue naturelle en codage de Bert. Il s'est terminé brusquement.
Certaines personnes introduisent soigneusement la façon d'utiliser Bert sur les ensembles de données officiels fournis. Toutes les modifications sont effectuées sur le script Python original. Toutes les fonctions et paramètres qui ne sont pas utilisés du tout sont conservés. Quant à la façon dont les autres réutilisent leurs propres ensembles de données? Les gens n'ont pas du tout mentionné cela.
J'ai pensé à mâcher le code depuis le début. Je me souviens que lorsque j'étudiais pour des études supérieures, j'ai également lu tous les codes C des couches TCP et IP sur la plate-forme de simulation. J'ai déterminé la tâche devant moi, ce qui était moins difficile.
Mais je ne veux vraiment pas le faire. J'ai l'impression d'être gâté par les cadres d'apprentissage automatique Python, surtout rapidement.ai et Scikit-Learn.
Plus tard, les développeurs de Google ont amené Bert à TensorFlow Hub. J'ai également écrit un échantillon de Notebook Google Colab spécifiquement.
J'étais tellement heureux de voir cette nouvelle.
J'ai essayé beaucoup d'autres modèles sur TensorFlow Hub. C'est très pratique à utiliser. Et Google Colab J'ai pratiqué Python avec Google Colab? 》 Vous est présenté dans l'article ", qui est un très bon environnement d'exercice d'apprentissage en profondeur python et de démonstration. J'ai pensé que les deux épées pourraient être combinées, et cette fois, je pouvais gérer mes propres tâches avec quelques lignes de code.
Attendons.
Lorsque vous l'ouvrez vraiment, vous vous concentrerez toujours sur les exemples de données.
De quoi les utilisateurs ordinaires ont-ils besoin? Une interface est requise.
Vous me dites les spécifications standard que vous avez entrées, puis dites-moi quels peuvent être les résultats. Branchez et jouez et partez après tout.
Une tâche de classification de texte vous a initialement donné un ensemble de formation et un ensemble de tests, vous indiquant à quelle vitesse les rondes de formation sont, puis me disant le taux de précision et les résultats?
Quant à me demander de lire des centaines de lignes de code pour une tâche aussi simple et de savoir où la changer vous-même?
Heureusement, avec cet exemple comme fondation, il vaut mieux que rien.
J'ai pris ma patience et je l'ai réglé.
Pour dire, je n'ai apporté aucune modification majeure au code d'origine.
Donc, si vous ne l'expliquez pas clairement, vous serez soupçonné de plagiat et serez méprisé.
Ce type d'organisation n'est pas techniquement difficile pour les personnes qui savent utiliser Python.
Mais à cause de cela, je me fâche. Est-ce difficile à faire? Pourquoi l'écrivain d'échantillon de Bert de Google a-t-il refusé de le faire?
Pourquoi y a-t-il un si grand changement de TensorFlow 1.0 à 2.0? N'est-ce pas parce que 2.0 est pour les gens?
Vous ne rendra pas l'interface rafraîchissante et simple, vos concurrents (Turicreate et Fast.ai) le feront, et ils le feront très bien. Ce n'est que lorsque je ne peux pas m'asseoir que je peux encore être prêt à minimiser le noble et à développer une interface utile pour les gens ordinaires.
Une leçon! Pourquoi ne l’absorbez-vous pas?
Je vais vous fournir un échantillon de Notebook Google Colab que vous pouvez facilement remplacer dans votre propre ensemble de données pour s'exécuter. Vous devez comprendre (y compris la modification) le code, pas plus de 10 lignes .
J'ai d'abord testé une tâche de classification de texte en anglais, et cela a très bien fonctionné. J'ai donc écrit un blog Medium, qui a été immédiatement inclus dans la colonne de science des données.
L'éditeur de colonne de science de Data m'a envoyé un message privé disant:
Très intéressant, j'aime cela étant donné que l'implémentation par défaut n'est pas très adaptée aux développeurs.
Il y avait un lecteur qui a réellement donné à cet article 50 lik (Claps) d'affilée, et j'ai été stupéfait.

Il semble que ce point de douleur longue n'est pas seulement moi.
On estime que les tâches de classification chinoise peuvent être rencontrées davantage dans vos recherches. J'ai donc simplement fait un autre exemple de classification de texte chinois et j'ai écrit ce tutoriel et l'ai partagé avec vous.
Commençons.
Veuillez cliquer sur ce lien pour afficher le fichier IPython Notebook que j'ai fait pour vous sur GitHub.
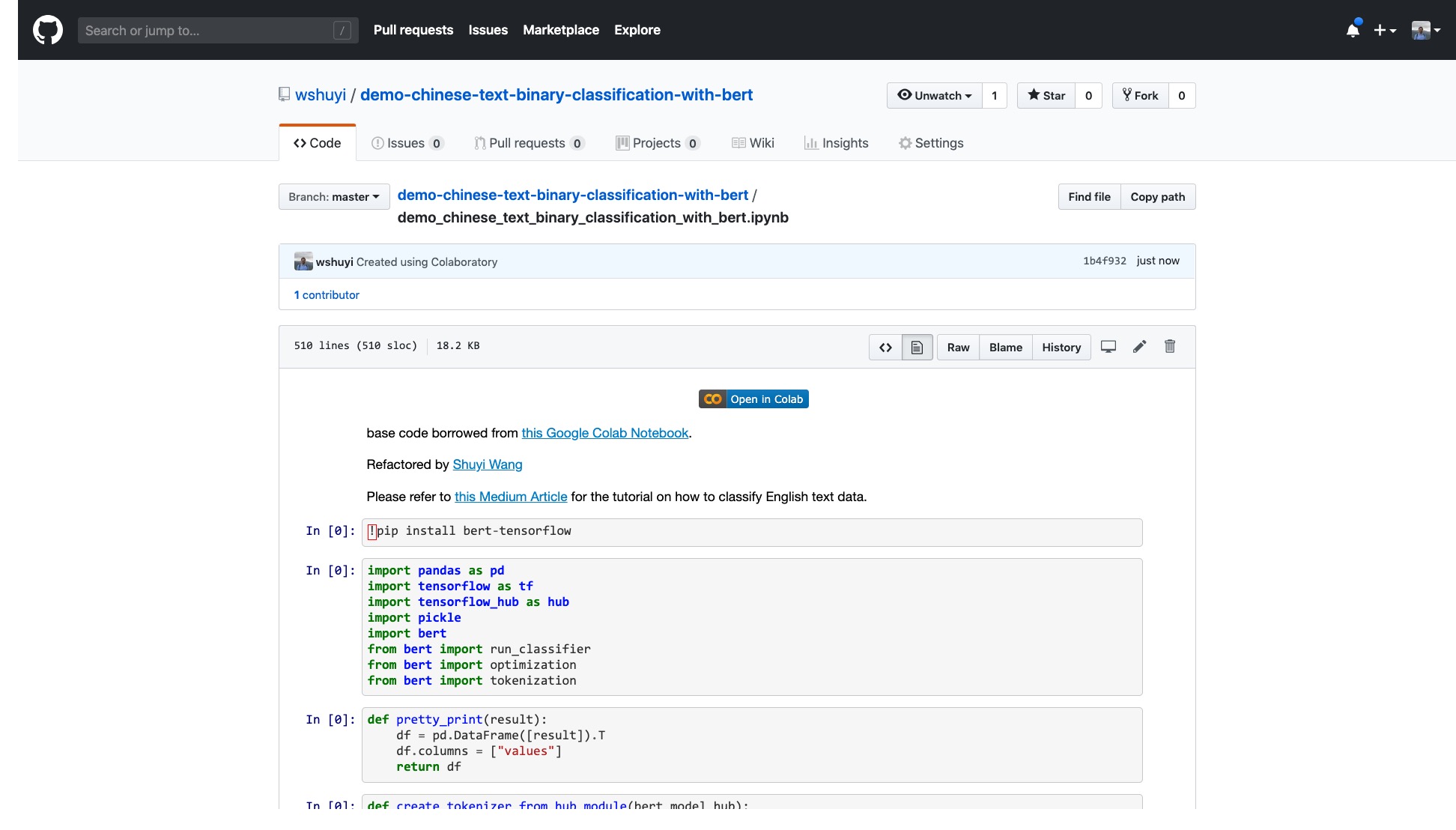
En haut du cahier, il y a un bouton "ouvert dans Colab" très évident. Cliquez dessus et Google Colab s'allumera automatiquement et chargera ce ordinateur portable.
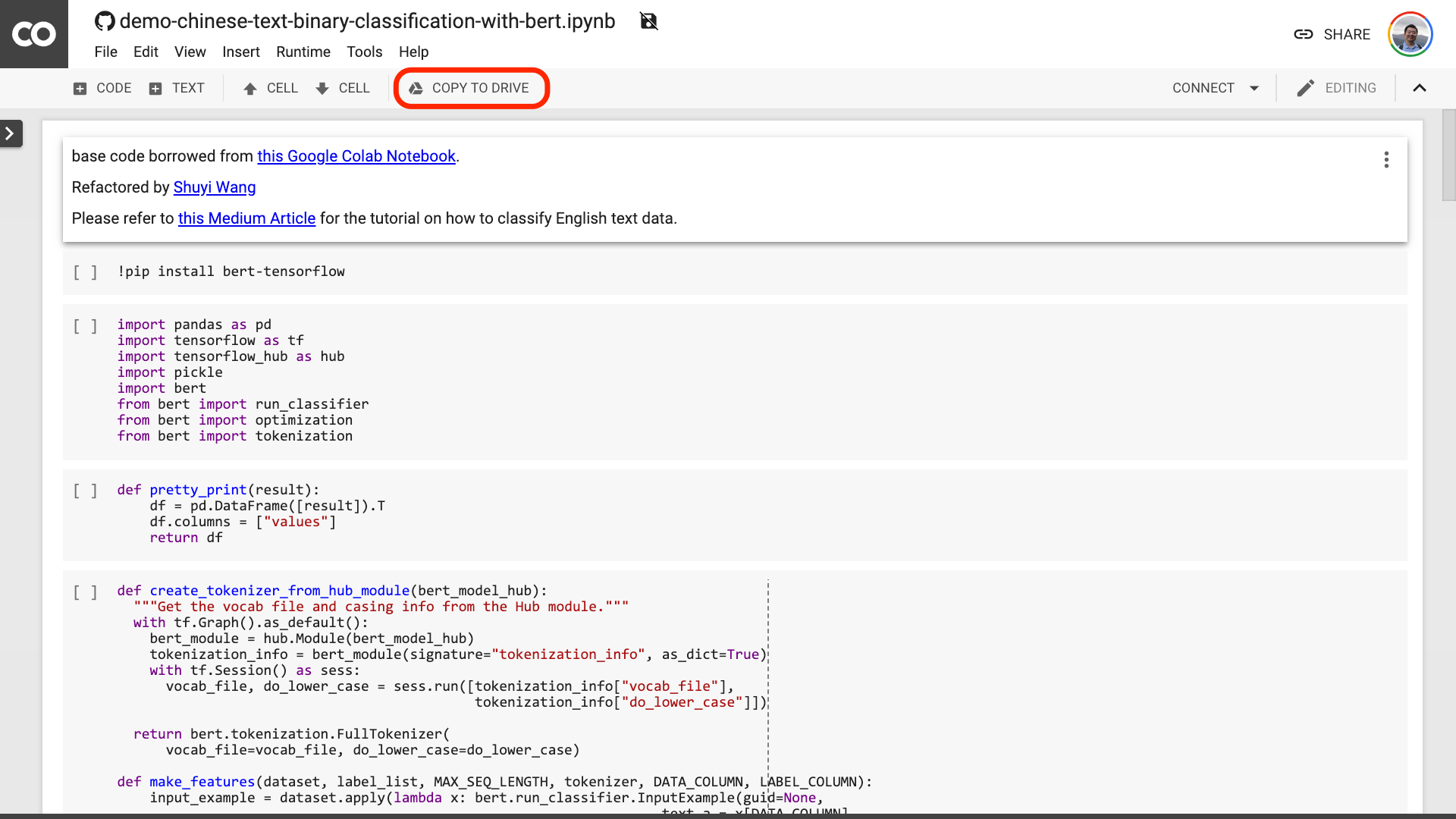
Je vous suggère de cliquer sur le bouton "Copier à conduire" encerclé dans l'image rouge ci-dessus. Cela l'économisera d'abord dans votre propre lecteur Google pour une utilisation et une révision.
Une fois cela fait, vous n'avez qu'à effectuer les trois étapes suivantes:
Après avoir enregistré le cahier. Si vous regardez attentivement, vous pouvez vous sentir dupé.
Professeur, tu as menti! Il est convenu que pas plus de 10 lignes de code!
Ne soyez pas anxieux .
Vous n'avez pas besoin de modifier quoi que ce soit avant que la phrase ne tourne dans le rouge dans l'image ci-dessous.
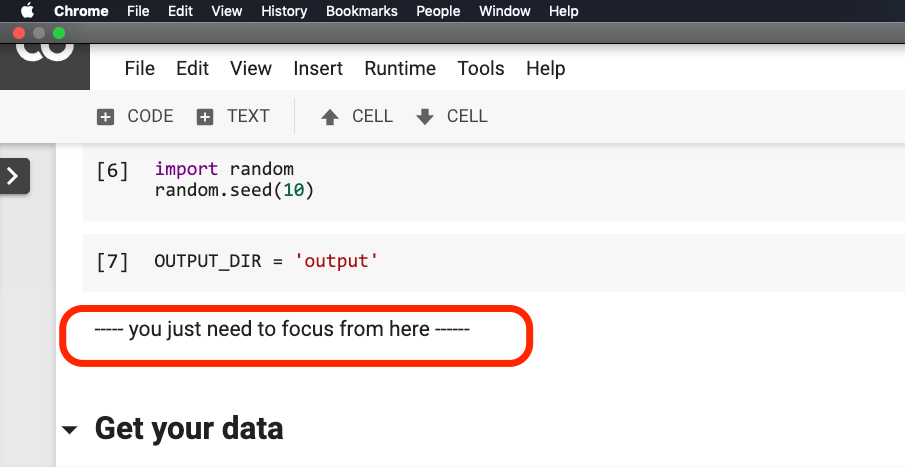
Veuillez cliquer sur où se trouve cette phrase, puis sélectionnez Run before dans le menu comme indiqué dans la figure suivante.
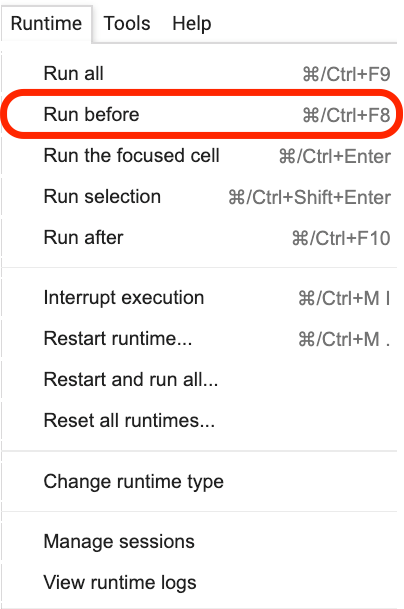
Les éléments suivants sont tous des liens importants, focus.
La première étape consiste à préparer les données.
!w get https : // github . com / wshuyi / demo - chinese - text - binary - classification - with - bert / raw / master / dianping_train_test . pickle
with open ( "dianping_train_test.pickle" , 'rb' ) as f :
train , test = pickle . load ( f )Vous devez être familier avec les données utilisées ici. Il s'agit des données d'annotation émotionnelle des revues de restauration. Je suis dans "Comment former le modèle de classification des émotions de texte chinois avec Python et Machine Learning?》 Et" Comment utiliser Python et les réseaux de neurones récurrents pour classer les textes chinois? 》 L'a utilisé. Cependant, pour la commodité de la démonstration, je la publie en format Pickle cette fois et je l'ai mise dans le dépôt de démonstration GitHub pour votre téléchargement et votre utilisation.
L'ensemble de formation contient 1 600 éléments de données; L'ensemble de test contient 400 éléments de données. Dans l'étiquette, 1 représente des émotions positives et 0 représente des émotions négatives.
En utilisant l'énoncé suivant, nous mélangeons l'ensemble de formation et perturbons la commande. Pour éviter un sur-ajustement.
train = train . sample ( len ( train ))Jetons un coup d'œil au contenu de notre ensemble de formation.
train . head ()
Si vous souhaitez remplacer votre propre ensemble de données plus tard, veuillez faire attention au format. Les noms de colonne des ensembles de formation et de test doivent être cohérents.
Dans la deuxième étape, nous définirons les paramètres.
myparam = {
"DATA_COLUMN" : "comment" ,
"LABEL_COLUMN" : "sentiment" ,
"LEARNING_RATE" : 2e-5 ,
"NUM_TRAIN_EPOCHS" : 3 ,
"bert_model_hub" : "https://tfhub.dev/google/bert_chinese_L-12_H-768_A-12/1"
}Les deux premières lignes doivent indiquer clairement les noms de colonne correspondants du texte et des marques.
La troisième ligne spécifie le taux de formation. Vous pouvez lire le papier d'origine pour faire une tentative de réglage hyperparamètre. Ou, vous pouvez simplement garder la valeur par défaut inchangée.
Ligne 4, spécifiez le nombre de tours de formation. Exécutez toutes les données en un seul tour. 3 tours sont utilisés ici.
La dernière ligne montre le modèle pré-formé Bert que vous souhaitez utiliser. Nous voulons classer le texte chinois, nous utilisons donc cette adresse de modèle chinoise pré-formée. Si vous souhaitez utiliser l'anglais, vous pouvez vous référer à mon article de blog moyen et à l'exemple de code d'anglais correspondant.
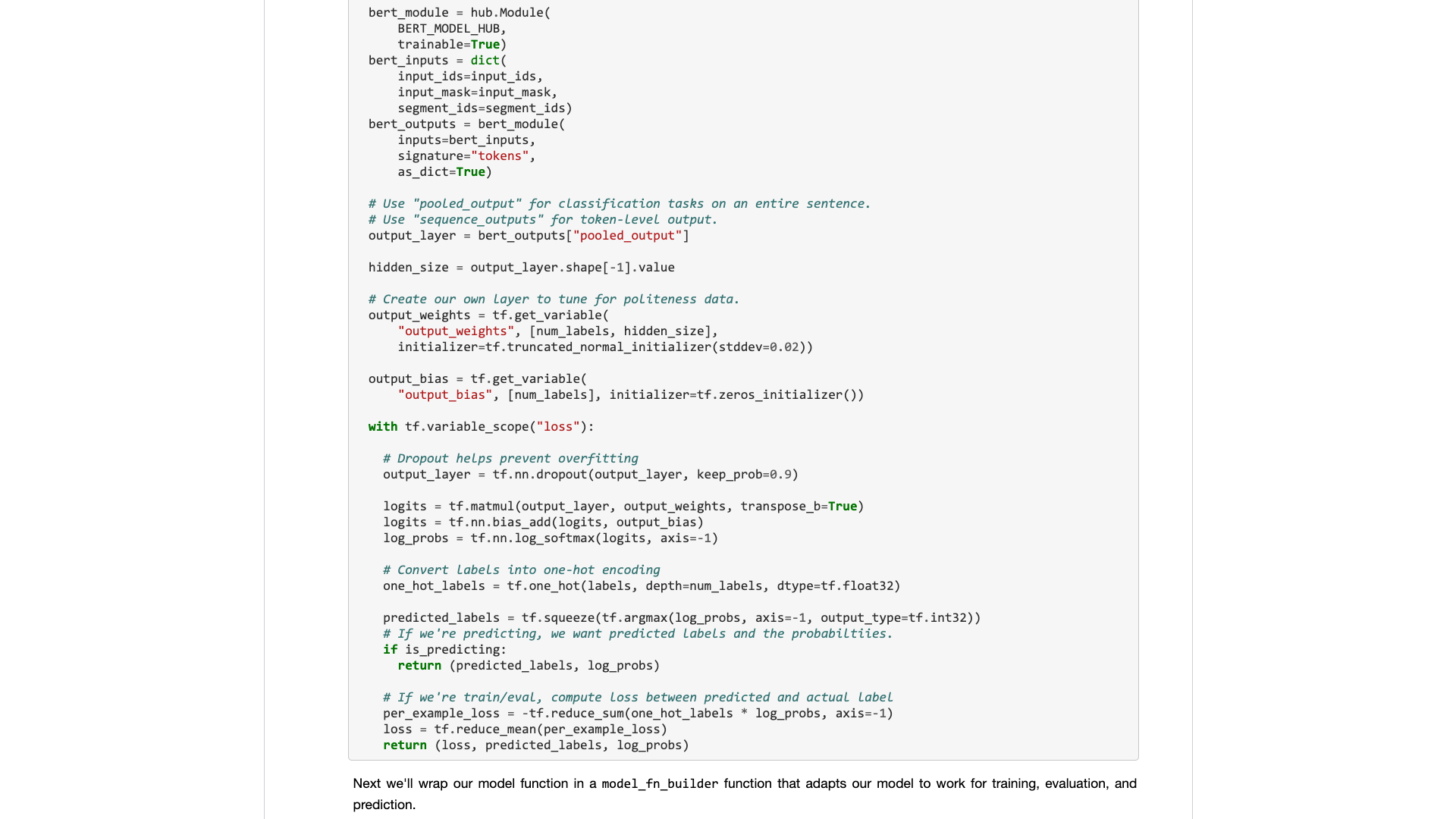
Dans la dernière étape, nous exécutons simplement le code à tour.
result , estimator = run_on_dfs ( train , test , ** myparam )Notez qu'il peut prendre un certain temps pour exécuter cette phrase. Être préparé mentalement. Ceci est lié à votre volume de données et à vos paramètres de formation.
Dans ce processus, vous pouvez voir que le programme vous aide d'abord à transformer le texte chinois d'origine en un format de données d'entrée que Bert peut comprendre.
Lorsque vous voyez le texte encerclé dans le rouge dans l'image ci-dessous, cela signifie que le processus de formation est enfin terminé.
Ensuite, vous pouvez imprimer les résultats du test.
pretty_print ( result )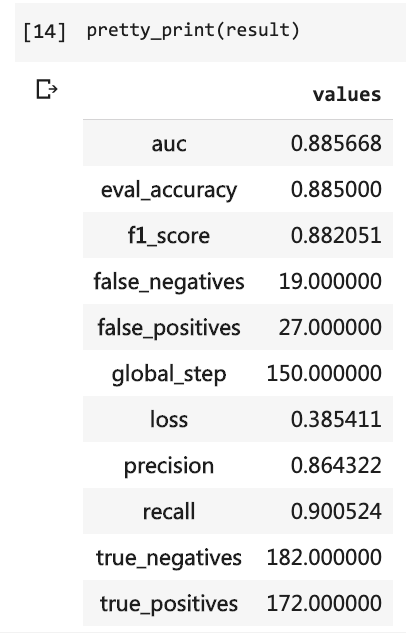
Comparez notre tutoriel précédent (en utilisant le même ensemble de données).
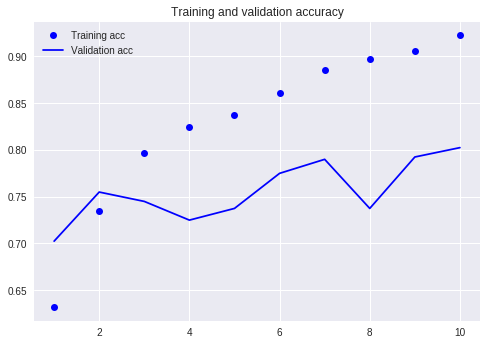
À ce moment-là, j'ai dû écrire autant de lignes de code et j'ai dû effectuer 10 tours, mais le résultat n'était toujours pas plus de 80%. Cette fois, même si je ne me suis entraîné que pour 3 rounds, le taux de précision a dépassé 88%.
Il n'est pas facile d'atteindre une telle précision sur un ensemble de données aussi à petite échelle.
La performance Bert est évidente.
Cela dit, vous avez appris à utiliser Bert pour effectuer la tâche de classification binaire du texte chinois. J'espère que vous serez aussi heureux que moi.
Si vous êtes un passionné de python senior, faites-moi une faveur.
Rappelez-vous le code avant cette ligne?
Pouvez-vous m'aider à les emballer? De cette façon, notre code de démonstration peut être plus court, plus concis, plus clair et plus facile à utiliser.
Bienvenue pour soumettre votre code sur notre projet GitHub. Si vous trouvez ce tutoriel utile, veuillez ajouter des étoiles à ce projet GitHub. Merci!
Bonne apprentissage en profondeur!
Vous pouvez également être intéressé par les sujets suivants. Cliquez sur le lien pour le voir.
Si vous l'aimez, veuillez aimer et récompenser. Vous pouvez également suivre et garnir mon compte officiel "Yushuzhilan" (Nkwangshuyi) sur WeChat.
Si vous êtes intéressé par Python et la science des données, vous pourriez aussi bien lire ma série de messages d'index de tutoriel "Comment démarrer efficacement la science des données?》, Il y a plus de questions et de solutions intéressantes.
L'entrée de la planète des connaissances est là:


