demo chinese text binary classification with bert
1.0.0

昨年、GoogleのBertモデルがリリースされるとすぐに、私は非常に興奮しました。
私はFast.aiのulmfitを使用して、その時点で自然言語分類タスクを実行していたためです(テキストを分類するためにPythonとDeep Transfer Learningを使用する方法?」という特別な記事も書きました)。 UlmfitとBertはどちらも事前に訓練された言語モデルであり、多くの類似点があります。
いわゆる言語モデルは、深いニューラルネットワーク構造を使用して、言語の共通の特徴を把握するために、大規模な言語テキストを訓練します。
上記の作業は、多くの場合、大規模な機関が完了することしかできません。コストが大きすぎるからです。
このコストには以下が含まれますが、これらに限定されません。
トレーニング前とは、訓練された後にこの結果を開くことを意味します。私たち普通の人々や小規模機関は、結果を借りて、専門分野の独自のテキストデータを微調整して、この専門分野のテキストを非常に明確に理解できるようにすることもできます。
いわゆる理解は、主に特定の単語をブロックするという事実を指し、モデルはあなたが隠しているものをより正確に推測できます。
2つの文章をまとめた場合でも、モデルはコンテキスト関係が密接に接続されているかどうかを判断できます。

この「知識」は有用ですか?
もちろんあります。
Bertは複数の自然言語タスクでテストされており、多くの結果が人間のプレイヤーを上回っています。

Bertは、タスクの解決を支援できます。もちろん、感情分類などのテキスト分類も含まれます。これは私が現在勉強している問題でもあります。
しかし、バートを使用するために、私は長い間待ちました。
Googleコードが公開されています。 Pytorchの実装でさえ、多くのラウンドで繰り返されてきました。
しかし、私は彼らが提供するサンプルを開く必要があり、私はめまいを感じます。
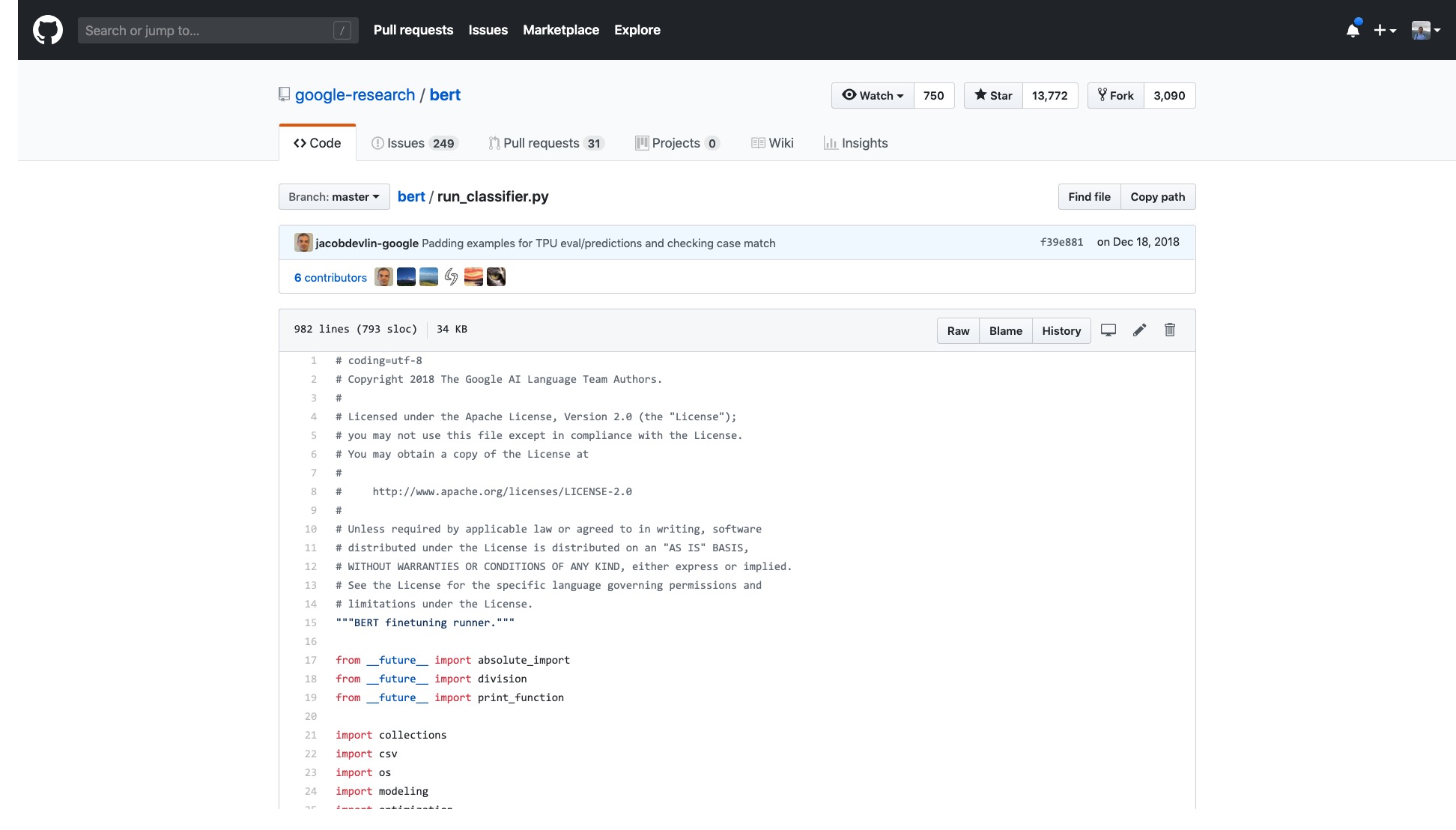
そのコードだけの行の数は非常に怖いです。
さらに、多数のデータ処理プロセス(データプロセッサ)には、データセット名にちなんで命名されます。私のデータは上記のいずれにも属していないので、どちらを使用する必要がありますか?

また、不可解に厄介な数え切れないほどのフラグ(フラグ)があります。

Scikit-Learnの構文構造が、分類タスクを実行するときにどのように見えるかを比較しましょう。
from sklearn . datasets import load_iris
from sklearn import tree
iris = load_iris ()
clf = tree . DecisionTreeClassifier ()
clf = clf . fit ( iris . data , iris . target )画像分類のデータスループットが大きく、多くのステップが必要な場合でも、fast.aiを使用して数行のコードで簡単に実行できます。
!g it clone https : // github . com / wshuyi / demo - image - classification - fastai . git
from fastai . vision import *
path = Path ( "demo-image-classification-fastai/imgs/" )
data = ImageDataBunch . from_folder ( path , test = 'test' , size = 224 )
learn = cnn_learner ( data , models . resnet18 , metrics = accuracy )
learn . fit_one_cycle ( 1 )
interp = ClassificationInterpretation . from_learner ( learn )
interp . plot_top_losses ( 9 , figsize = ( 8 , 8 ))これらのコード行を過小評価しないでください。画像分類子を訓練するのに役立つだけでなく、最大の分類エラーを持つ画像のモデルがどこに注意を払っているかを示します。

比較、Bertの例とFast.aiの例の違いは何だと思いますか?
後者は人々が使用するためのものだと思います。
私はいつも誰かがコードをリファクタリングし、簡潔なチュートリアルを書くと思っていました。
結局のところ、テキスト分類タスクは一般的な機械学習アプリケーションです。多くのアプリケーションシナリオがあり、初心者が学習するのにも適しています。
しかし、私はそのようなチュートリアルを待っていませんでした。
もちろん、この期間中、私は多くの人々によって書かれたアプリケーションとチュートリアルも読みました。
一部の人々は、自然言語のテキストをバートエンコーディングに変換できます。突然終了しました。
一部の人々は、提供されている公式のデータセットでBertの使用方法を注意深く紹介します。すべての変更は、元のPythonスクリプトで行われます。まったく使用されていないすべての機能とパラメーターが保持されます。他の人が自分のデータセットをどのように再利用するかについては?人々はこれについてまったく言及しませんでした。
私は最初からコードを噛むことを考えました。大学院で勉強していたときに、シミュレーションプラットフォーム上のTCPレイヤーとIPレイヤーのすべてのCコードも読みました。目の前でタスクを決定しましたが、それほど難しくありませんでした。
しかし、私は本当にそれをしたくありません。 Python Machine Learning Frameworks、特にFast.aiとScikit-Learnに甘やかされているように感じます。
その後、Googleの開発者はBertをTensorflow Hubに持ち込みました。また、Google Colabノートブックのサンプルも具体的に書きました。
このニュースを見てとても嬉しかったです。
Tensorflow Hubで他の多くのモデルを試しました。使用するのはとても便利です。そして、Google Colab私はGoogle ColabでPythonを練習しましたか? 》は記事で紹介されています。これは非常に優れたPython Deep Learning Exercise and Deding環境です。2つの剣を組み合わせることができると思いました。今回は、数行のコードで自分のタスクを処理できました。
待ってみましょう。
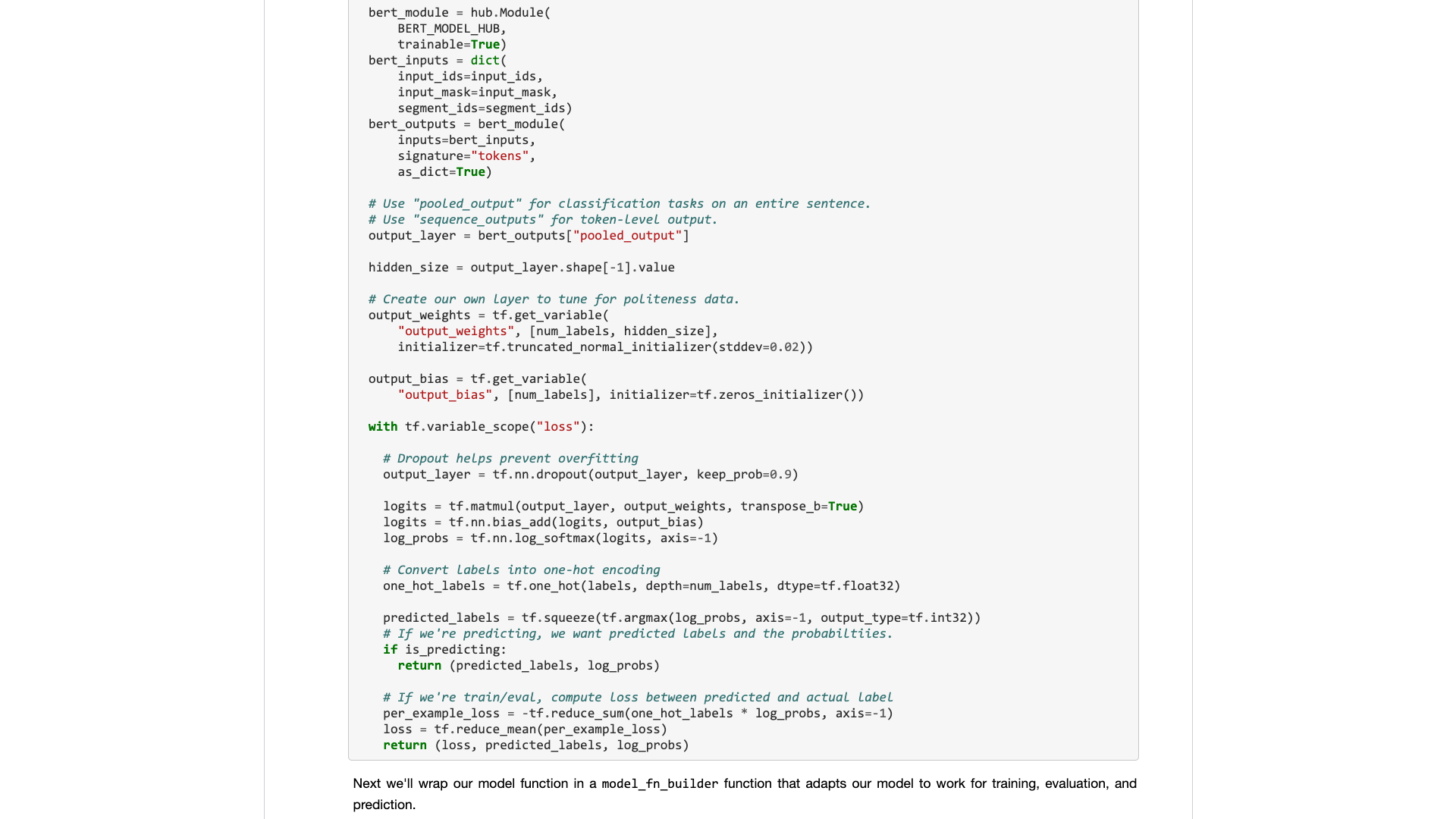
本当に開くと、サンプルデータに焦点を当てます。
通常のユーザーには何が必要ですか?インターフェイスが必要です。
入力した標準仕様を教えてから、結果がどうなるか教えてください。プラグアンドプレイ、そして結局のところ出発します。
テキスト分類タスクはもともとトレーニングセットとテストセットを提供し、トレーニングラウンドがどれだけ速いかを示し、精度と結果を伝えてくれますか?
このような単純なタスクのために何百行のコードを読んで、自分でどこに変更するかを調べるように頼むことについては?
幸いなことに、この例を基盤として、それは何もないよりはましです。
私は忍耐を取り、それを整理しました。
述べて、私は元のコードに大きな変更を加えませんでした。
したがって、明確に説明しないと、盗作が疑われ、軽spされます。
この種の組織は、Pythonの使用方法を知っている人にとっては技術的に困難ではありません。
しかし、このため、私は怒ります。これを行うのは難しいですか? GoogleのBertサンプルライターがそれを拒否したのはなぜですか?
Tensorflow 1.0から2.0から2.0に大きな変化があるのはなぜですか? 2.0が人々が使用するためではないからですか?
インターフェイスをさわやかでシンプルにすることはできません。競合他社(Turicreateとfast.ai)がそれを行い、非常にうまくいきます。私がじっと座っていないときにのみ、私は貴族を軽視し、普通の人々のために有用なインターフェイスを開発することができます。
レッスン!なぜあなたはそれを吸収しませんか?
Google Colabノートブックのサンプルを提供します。これにより、独自のデータセットに簡単に交換して実行できます。コードを10行以内に理解する(変更を含む)必要があります。
私は最初に英語のテキスト分類タスクをテストしましたが、それは非常にうまく機能しました。そこで、私は中程度のブログを書きました。これはすぐにData Scienceコラムに含まれていました。
Toster Data Science Column Editorは、私に次のように言ってプライベートメッセージを送ってくれました。
非常に興味深いのは、デフォルトの実装が確かに開発者に優しいものではないことを考えると、これが好きです。
実際にこの記事50のいいね(拍手)を連続して与えた読者がいましたが、私はun然としました。

この長年の痛みのポイントは私だけではないようです。
中国の分類タスクは、あなたの研究でもっと遭遇する可能性があると推定されています。だから私は単に中国のテキスト分類の別の例を作成し、このチュートリアルを書き、それをあなたと共有しました。
始めましょう。
このリンクをクリックして、GitHubで作成したIPythonノートブックファイルを表示してください。
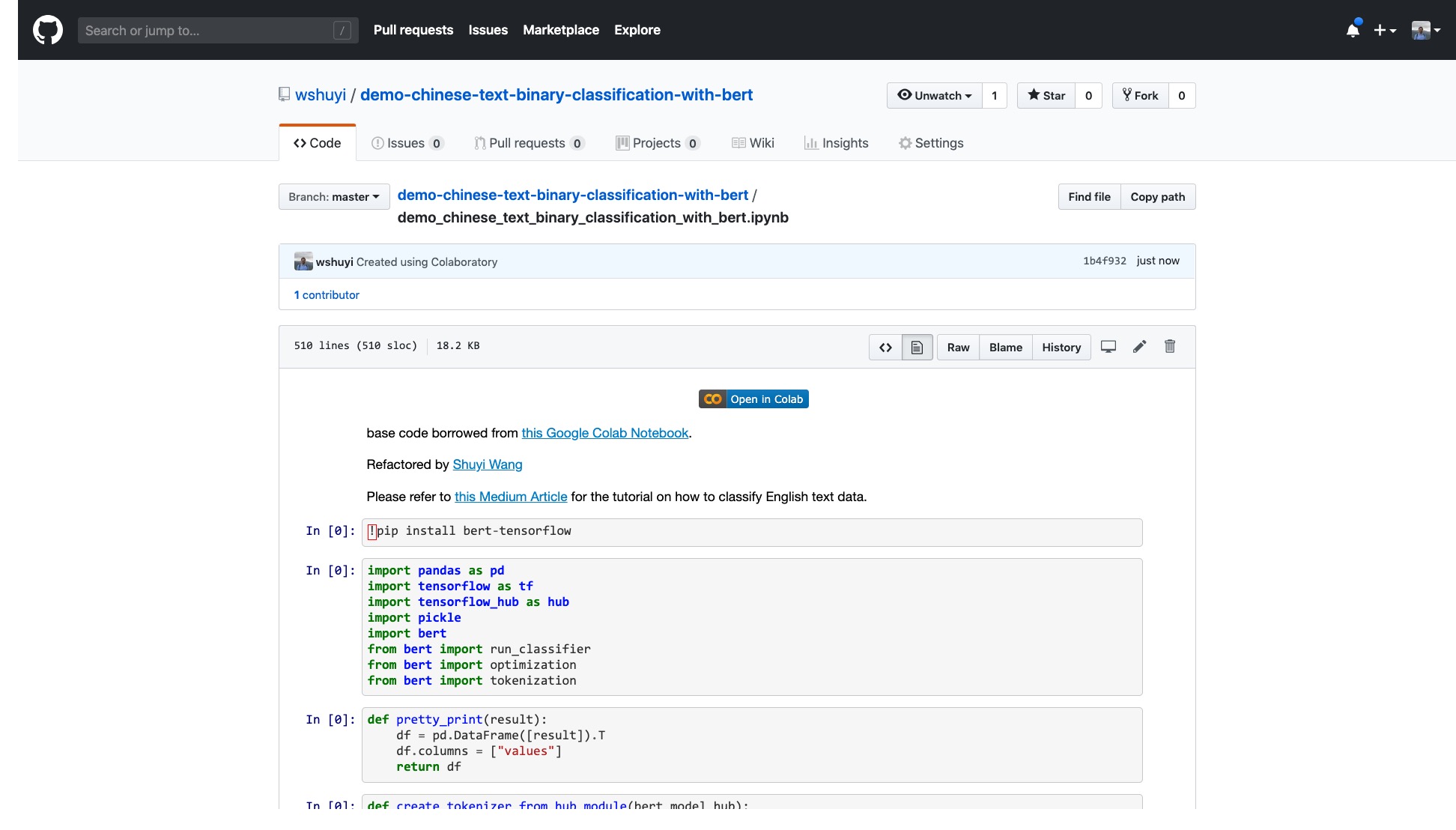
ノートブックの上部には、非常に明白な「Colabで開いている」ボタンがあります。それをクリックすると、Google Colabが自動的にオンになり、このノートブックをロードします。
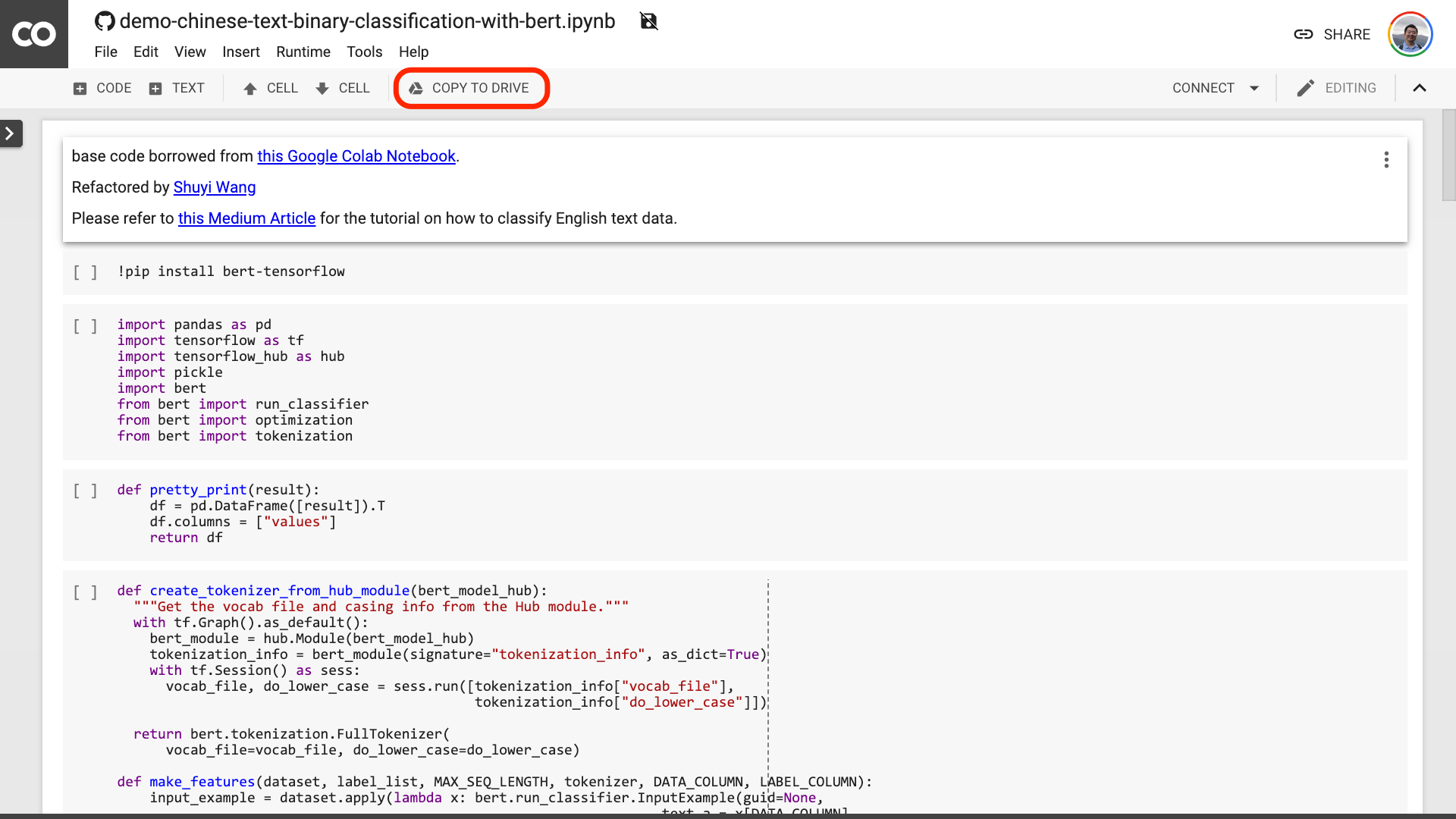
上の赤い画像に囲まれた[ドライブにコピー]ボタンをクリックすることをお勧めします。これにより、最初に自分のGoogleドライブに保存して使用してレビューします。
これが完了した後、実際には次の3つのステップを実行する必要があります。
ノートを保存した後。よく見ると、だまされていると感じるかもしれません。
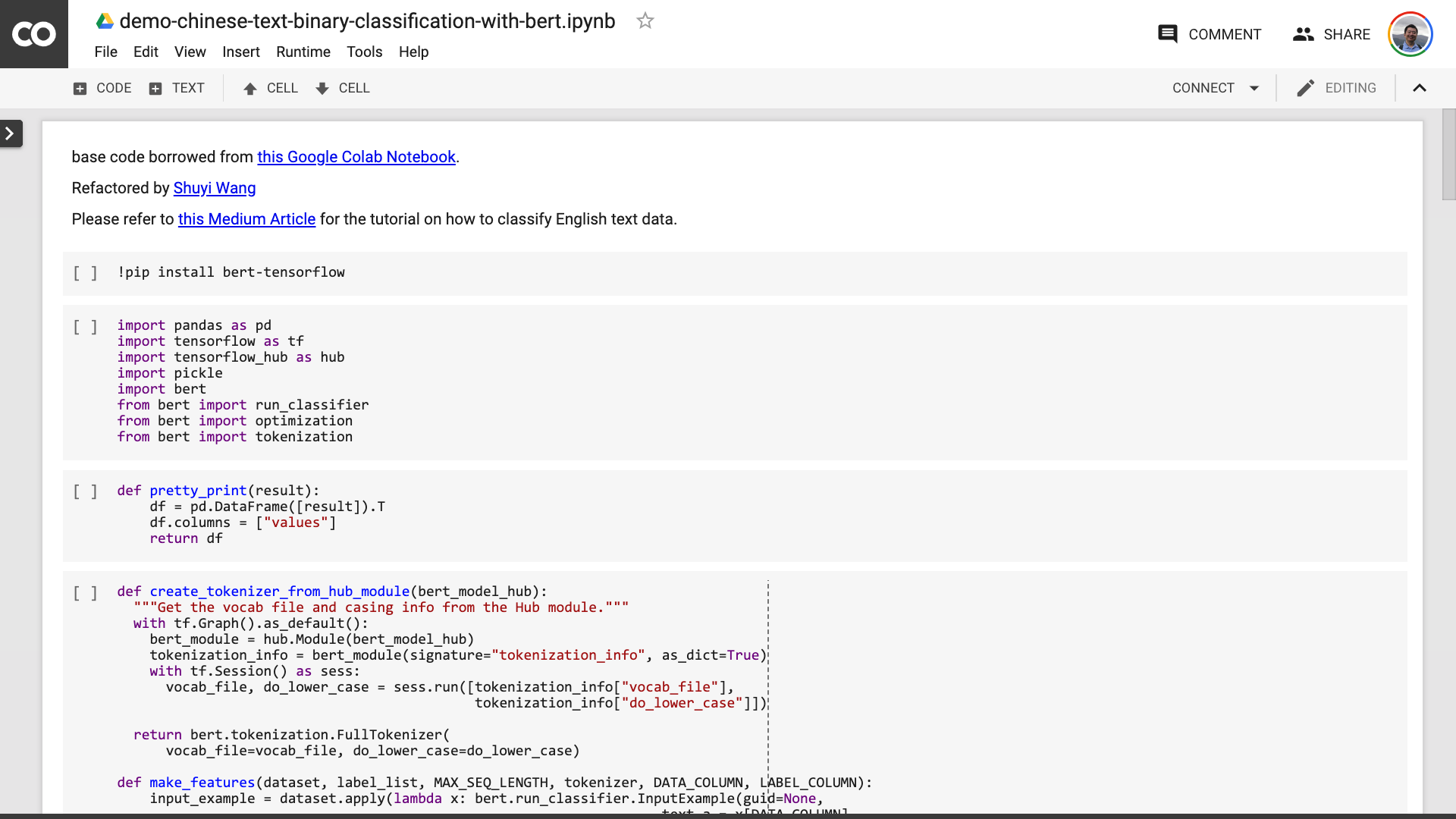
先生、あなたは嘘をついた! 10行以内のコードがないことに同意します!
心配しないでください。
下の写真では、文が赤に囲まれる前に何も変更する必要はありません。
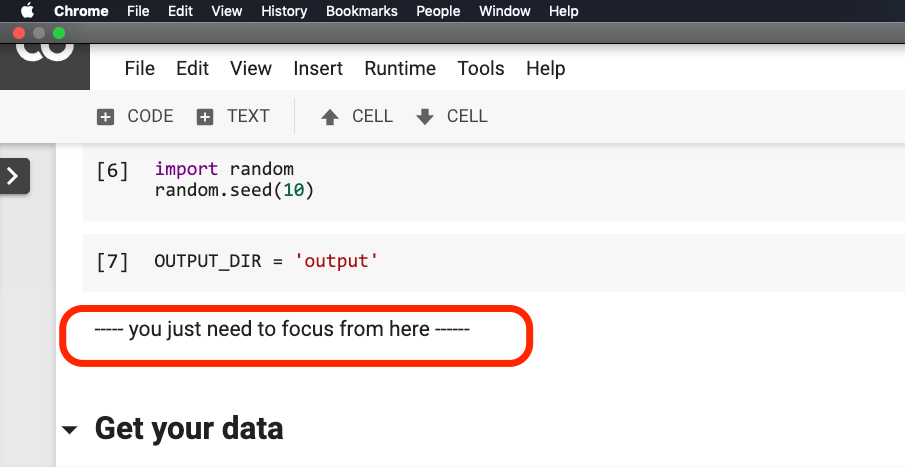
次の図に示すように、この文がある場所をクリックしてから、メニューから[ Run beforeを選択します。
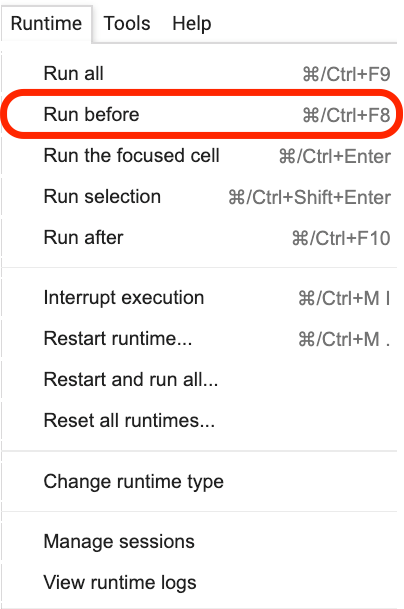
以下はすべて重要なリンク、フォーカスです。
最初のステップは、データを準備することです。
!w get https : // github . com / wshuyi / demo - chinese - text - binary - classification - with - bert / raw / master / dianping_train_test . pickle
with open ( "dianping_train_test.pickle" , 'rb' ) as f :
train , test = pickle . load ( f )ここで使用されているデータに精通している必要があります。これは、ケータリングレビューの感情的な注釈データです。私は「Pythonと機械学習で中国のテキスト感情分類モデルをトレーニングする方法?》」と「Pythonと再発性のニューラルネットワークを使用して中国のテキストを分類する方法は? 》がそれを使用しました。ただし、デモンストレーションの便利さのために、今回はピクルス形式として出力し、ダウンロードと使用のためにデモンストレーションGitHubリポジトリにまとめます。
トレーニングセットには、1,600個のデータが含まれています。テストセットには400個のデータが含まれています。ラベルでは、1は肯定的な感情を表し、0は否定的な感情を表します。
次のステートメントを使用して、トレーニングセットをシャッフルして順序を破壊します。過剰な適合を避けるため。
train = train . sample ( len ( train ))トレーニングセットのヘッドコンテンツを見てみましょう。
train . head ()
後で独自のデータセットを交換したい場合は、フォーマットに注意してください。トレーニングセットとテストセットの列名は一貫している必要があります。
2番目のステップでは、パラメーターを設定します。
myparam = {
"DATA_COLUMN" : "comment" ,
"LABEL_COLUMN" : "sentiment" ,
"LEARNING_RATE" : 2e-5 ,
"NUM_TRAIN_EPOCHS" : 3 ,
"bert_model_hub" : "https://tfhub.dev/google/bert_chinese_L-12_H-768_A-12/1"
}最初の2行は、テキストとマークの対応する列名を明確に示すことです。
3行目は、トレーニングレートを指定します。元の論文を読んで、ハイパーパラメーターの調整を試みることができます。または、デフォルト値を変更しておくことができます。
4行目は、トレーニングラウンドの数を指定します。すべてのデータを1ラウンドに実行します。ここでは3ラウンドが使用されます。
最後の行は、使用するBert Pre-Trainedモデルを示しています。中国のテキストを分類したいので、この中国の事前訓練を受けたモデルアドレスを使用します。英語を使用する場合は、私の中程度のブログ投稿と対応する英語のサンプルコードを参照できます。
最後のステップでは、コードを順番に実行するだけです。
result , estimator = run_on_dfs ( train , test , ** myparam )この文を実行するのに時間がかかる場合があることに注意してください。精神的に準備してください。これは、データボリュームとトレーニングラウンド設定に関連しています。
このプロセスでは、プログラムが最初に元の中国のテキストをBertが理解できる入力データ形式に変えるのに役立つことがわかります。
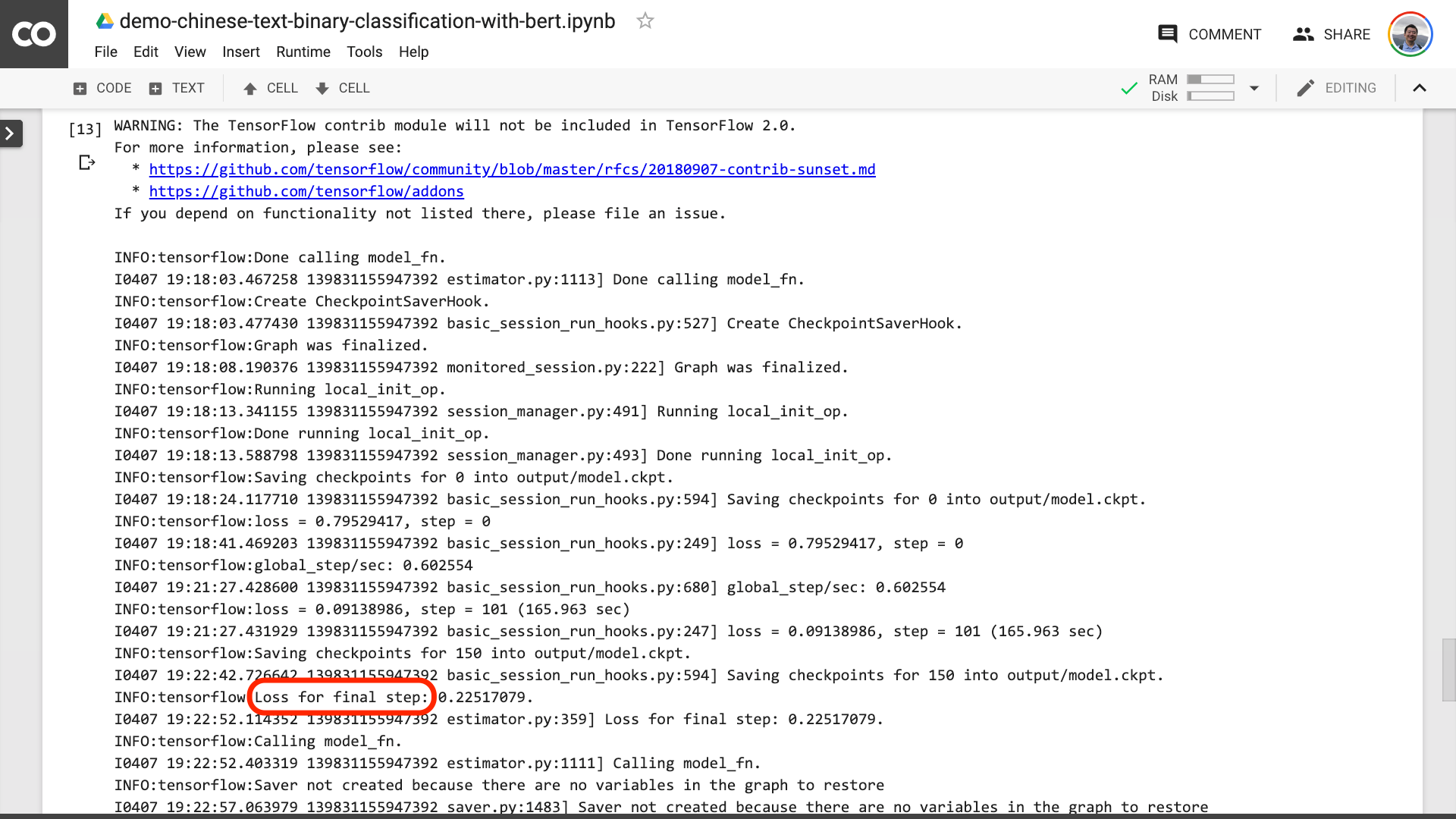
下の写真でテキストが赤に囲まれているのを見ると、トレーニングプロセスが最終的に終了したことを意味します。
次に、テスト結果を印刷できます。
pretty_print ( result )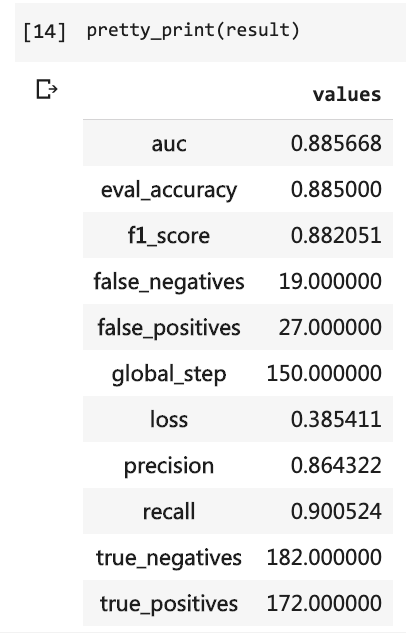
以前のチュートリアルと比較してください(同じデータセットを使用)。
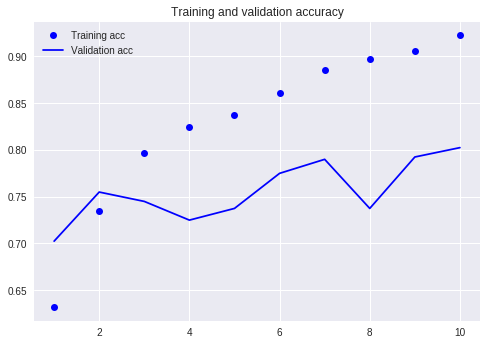
当時、私は非常に多くのコードを書く必要があり、10ラウンドを実行する必要がありましたが、結果はまだ80%以下でした。今回は、私は3ラウンドだけトレーニングしましたが、精度は88%を超えています。
このような小規模データセットでこのような精度を達成するのは容易ではありません。
バートのパフォーマンスは明らかです。
そうは言っても、Bertを使用して中国のテキストのバイナリ分類タスクを実行する方法を学びました。私と同じくらい幸せになることを願っています。
あなたがシニアのPython愛好家なら、私にお願いしてください。
この行の前のコードを覚えていますか?
私がそれらを詰めるのを手伝ってもらえますか?このようにして、デモコードはより短く、より簡潔で、より明確で、使いやすくなります。
GitHubプロジェクトでコードを送信してください。このチュートリアルが役立つ場合は、このGitHubプロジェクトに星を追加してください。ありがとう!
幸せな深い学習!
また、次のトピックに興味があるかもしれません。リンクをクリックして表示します。
気に入ったら、気に入って報酬を与えてください。また、WeChatの公式アカウント「Youshuzhilan」(nkwangshuyi)をフォローしてトップすることもできます。
PythonとData Scienceに興味がある場合は、「データサイエンスを効率的に始める方法」という私の一連のチュートリアルインデックス投稿を読むこともできます。
ナレッジプラネットの入り口はこちらです:


