demo chinese text binary classification with bert
1.0.0

في العام الماضي ، كنت متحمسًا جدًا بمجرد إصدار طراز Bert من Google.
لأنني كنت أستخدم Fast.ai's Ulmfit للقيام بمهام تصنيف اللغة الطبيعية في ذلك الوقت (كتبت أيضًا مقالًا خاصًا "كيفية استخدام Python والتعلم العميق لتصنيف النصوص؟" للمشاركة معك). Ulmfit و Bert كلاهما نماذج لغة مدربة مسبقًا ولديهما العديد من أوجه التشابه.
يستخدم نموذج اللغة المزعوم بنية الشبكة العصبية العميقة للتدريب على نصوص لغوية ضخمة لفهم الميزات المشتركة للغة.
غالبًا ما يكون العمل أعلاه ممكنًا فقط للمؤسسات الكبيرة لإكمالها. لأن التكلفة كبيرة جدا.
تشمل هذه التكلفة على سبيل المثال لا الحصر:
ما قبل التدريب يعني أنهم يفتحون هذه النتيجة بعد تدريبهم. يمكن لنا نحن الأشخاص العاديون أو المؤسسات الصغيرة أيضًا استعارة النتائج وضبط بيانات النص لدينا في حقولنا المتخصصة بحيث يمكن للنموذج أن يكون له فهم واضح للغاية للنص في هذا المجال المتخصص.
يشير الفهم المزعوم بشكل أساسي إلى حقيقة أنك تمنع كلمات معينة ، ويمكن للنموذج أن يخمن بشكل أكثر دقة ما تخفيه.
حتى لو وضعت جملتين معًا ، يمكن للنموذج تحديد ما إذا كانت العلاقات السياقية المرتبطة ارتباطًا وثيقًا.

هل هذه "المعرفة" مفيدة؟
بالطبع هناك.
اختبر بيرت مهام اللغة الطبيعية المتعددة ، وقد تجاوزت العديد من النتائج اللاعبين البشر.

يمكن لـ BERT المساعدة في حل المهام ، بالطبع ، تشمل أيضًا تصنيف النص ، مثل تصنيف العاطفة. هذه هي أيضًا المشكلة التي أدرسها حاليًا.
ومع ذلك ، من أجل استخدام Bert ، انتظرت لفترة طويلة.
تم فتح رمز Google الرسمي. حتى التنفيذ على Pytorch قد تم تكراره في العديد من الجولات.
لكنني فقط بحاجة إلى فتح العينة التي يقدمونها وأشعر بالدوار.
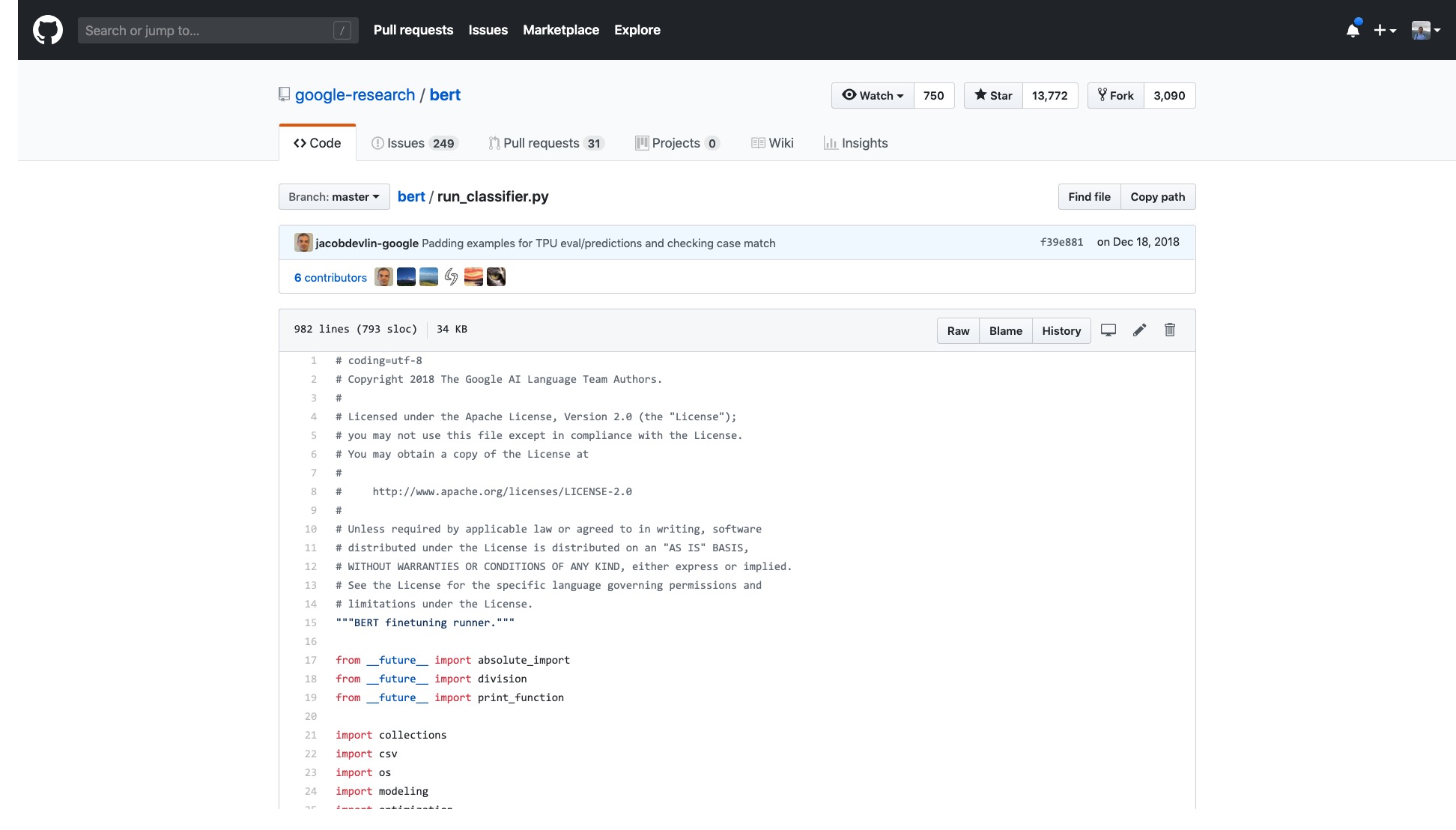
عدد الخطوط في هذا الرمز وحده أمر مخيف للغاية.
علاوة على ذلك ، تتم تسمية مجموعة من عمليات معالجة البيانات (معالجات البيانات) على اسم مجموعة البيانات. لا تنتمي بياناتي إلى أي مما سبق ، فمنذ ما يجب أن أستخدمه؟

هناك أيضًا عدد لا يحصى من الأعلام (الأعلام) التي هي مزعجة بشكل غير مفهوم.

دعنا نقارن كيف تبدو بنية بناء الجملة في Scikit-Learn عند القيام بمهام التصنيف.
from sklearn . datasets import load_iris
from sklearn import tree
iris = load_iris ()
clf = tree . DecisionTreeClassifier ()
clf = clf . fit ( iris . data , iris . target )حتى إذا كانت إنتاجية بيانات تصنيف الصور كبيرة وتتطلب العديد من الخطوات ، فيمكنك القيام بذلك بسهولة مع بضعة أسطر من التعليمات البرمجية باستخدام Fast.ai.
!g it clone https : // github . com / wshuyi / demo - image - classification - fastai . git
from fastai . vision import *
path = Path ( "demo-image-classification-fastai/imgs/" )
data = ImageDataBunch . from_folder ( path , test = 'test' , size = 224 )
learn = cnn_learner ( data , models . resnet18 , metrics = accuracy )
learn . fit_one_cycle ( 1 )
interp = ClassificationInterpretation . from_learner ( learn )
interp . plot_top_losses ( 9 , figsize = ( 8 , 8 ))لا تقلل من شأن هذه الخطوط من الكود. إنه لا يساعدك فقط على تدريب مصنف الصور ، ولكنه يخبرك أيضًا بالمكان الذي ينتبه فيه النموذج في تلك الصور بأعلى خطأ في التصنيف.

مقارنة ، ما رأيك هو الفرق بين مثال Bert و Fast.ai مثال؟
أعتقد أن الأخير هو أن يستخدم الناس .
اعتقدت دائمًا أن شخصًا ما سيعيد إعادة تشكيل الكود ويكتب برنامجًا تعليميًا موجزًا.
بعد كل شيء ، تعد مهام تصنيف النصية تطبيقًا شائعًا للتعلم الآلي. هناك العديد من سيناريوهات التطبيق وهي مناسبة أيضًا للمبتدئين للتعلم.
ومع ذلك ، لم أكن أنتظر مثل هذا البرنامج التعليمي.
بالطبع ، خلال هذه الفترة ، قرأت أيضًا التطبيقات والدروس التعليمية التي كتبها العديد من الأشخاص.
يمكن لبعض الأشخاص تحويل نص اللغة الطبيعية إلى ترميز بيرت. انتهى الأمر بشكل مفاجئ.
يقدم بعض الأشخاص بعناية كيفية استخدام BERT على مجموعات البيانات الرسمية المقدمة. تتم جميع التعديلات على نص Python الأصلي. يتم الاحتفاظ بجميع الوظائف والمعلمات التي لا يتم استخدامها على الإطلاق. أما بالنسبة لكيفية إعادة استخدام الآخرين لمجموعات البيانات الخاصة بهم؟ لم يذكر الناس هذا على الإطلاق.
لقد فكرت في مضغ الرمز من البداية. أتذكر عندما كنت أدرس لمدرسة الدراسات العليا ، قرأت أيضًا جميع رموز C لطبقات TCP و IP على منصة المحاكاة. لقد قررت المهمة أمامي ، والتي كانت أقل صعوبة.
لكنني حقا لا أريد أن أفعل ذلك. أشعر أنني مدلل من أطر عمل التعلم الآلي Python ، وخاصة Fast.ai و Scikit-Learn.
في وقت لاحق ، أحضر مطورو Google Bert إلى TensorFlow Hub. لقد كتبت أيضًا نموذج دفتر Google Colab على وجه التحديد.
كنت سعيدًا جدًا برؤية هذا الخبر.
لقد جربت الكثير من النماذج الأخرى على مركز TensorFlow. إنه مناسب جدًا للاستخدام. و Google Colab لقد مارست Python مع Google Colab؟ 》 يتم تقديمه لك في المقالة "، وهو تمرين تعليمي عميق للغاية للبيثون وبيئة العرض التوضيحي. اعتقدت أنه يمكن دمج السيوفان ، وهذه المرة يمكنني التعامل مع مهامي الخاصة مع بضعة أسطر من التعليمات البرمجية.
دعنا ننتظر.
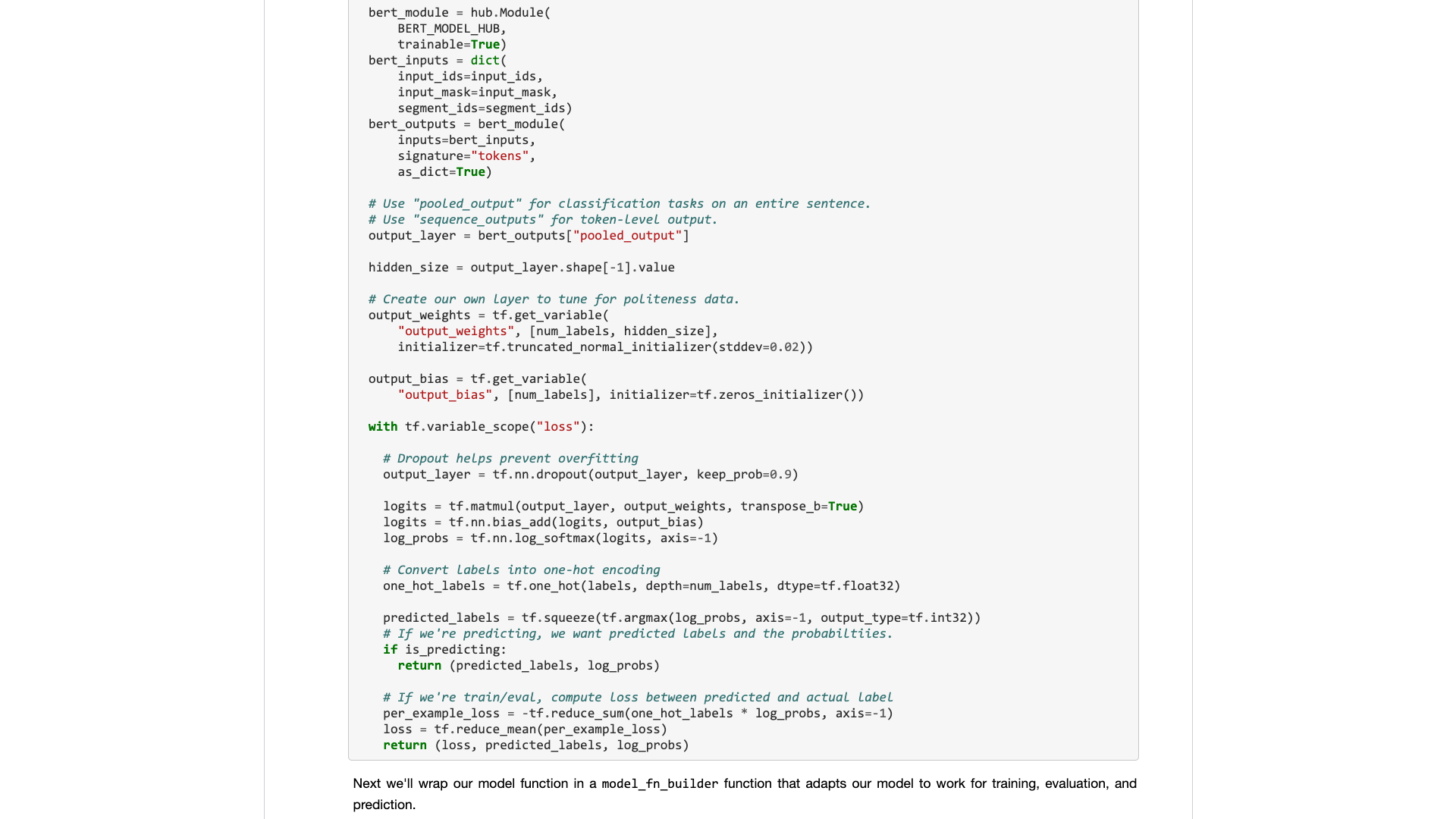
عندما تفتحه حقًا ، ستظل تركز على بيانات العينة.
ماذا يحتاج المستخدمون العاديون؟ واجهة مطلوبة.
تخبرني بالمواصفات القياسية التي أدخلتها ، ثم أخبرني بما يمكن أن تكون عليه النتائج. التوصيل والتشغيل ، واتركه بعد كل شيء.
أعطتك مهمة تصنيف النص في الأصل مجموعة تدريب ومجموعة اختبار ، وتخبرك بمدى سرعة جولات التدريب ، ثم تخبرني بمعدل الدقة والنتائج؟
أما بالنسبة لمطالبةني بقراءة مئات خطوط التعليمات البرمجية لمثل هذه المهمة البسيطة ، ومعرفة مكان تغييرها بنفسك؟
لحسن الحظ ، مع هذا المثال كأساس ، هو أفضل من لا شيء.
أخذت صدري وفرزته.
إلى الولاية ، لم أقم بأي تغييرات كبيرة على الكود الأصلي.
لذا ، إذا لم تشرح ذلك بوضوح ، فسيشتبه في وجود انتحال وسيحتقر.
هذا النوع من التنظيم ليس من الصعب تقنيًا للأشخاص الذين يعرفون كيفية استخدام Python.
ولكن بسبب هذا ، أغضب. هل من الصعب القيام بذلك؟ لماذا رفض كاتب عينة بيرت من Google القيام بذلك؟
لماذا هناك تغيير كبير من TensorFlow 1.0 إلى 2.0؟ أليس كذلك لأن 2.0 هو أن يستخدم الناس؟
لن تجعل الواجهة منعشة وبسيطة ، فإن منافسيك (TuricReate و Fast.ai) سيفعلون ذلك ، ويفعلون ذلك جيدًا. فقط عندما لا أستطيع الجلوس ، لا يزال بإمكاني أن أكون على استعداد للتقليل من شأن النبيلة وتطوير واجهة مفيدة للأشخاص العاديين.
درس! لماذا لا تمتصه؟
سأقدم لك نموذج دفتر Google Colab الذي يمكنك استبداله بسهولة على مجموعة البيانات الخاصة بك لتشغيله. تحتاج إلى فهم (بما في ذلك تعديل) الكود ، لا يزيد عن 10 أسطر .
لقد اختبرت أولاً مهمة تصنيف النص الإنجليزية ، وقد عملت بشكل جيد للغاية. لذلك كتبت مدونة متوسطة ، تم تضمينها على الفور في عمود علوم البيانات.
أرسل لي محرر عمود علوم البيانات رسالة خاصة تقول:
مثيرة للاهتمام للغاية ، أحب هذا النظر في التنفيذ الافتراضي ليس صديقًا للغاية بالتأكيد.
كان هناك قارئ أعطى بالفعل هذه المادة 50 إعجابات (Claps) على التوالي ، وقد صدمت.

يبدو أن نقطة الألم الطويلة هذه ليست أنا فقط.
تشير التقديرات إلى أن مهام التصنيف الصينية قد تتم مواجهة المزيد في بحثك. لذلك قمت ببساطة بتقديم مثال آخر على تصنيف النص الصيني وكتبت هذا البرنامج التعليمي وشاركته معك.
لنبدأ.
يرجى النقر فوق هذا الرابط لعرض ملف دفتر Ipython الذي قمت بإنشائه لك على Github.
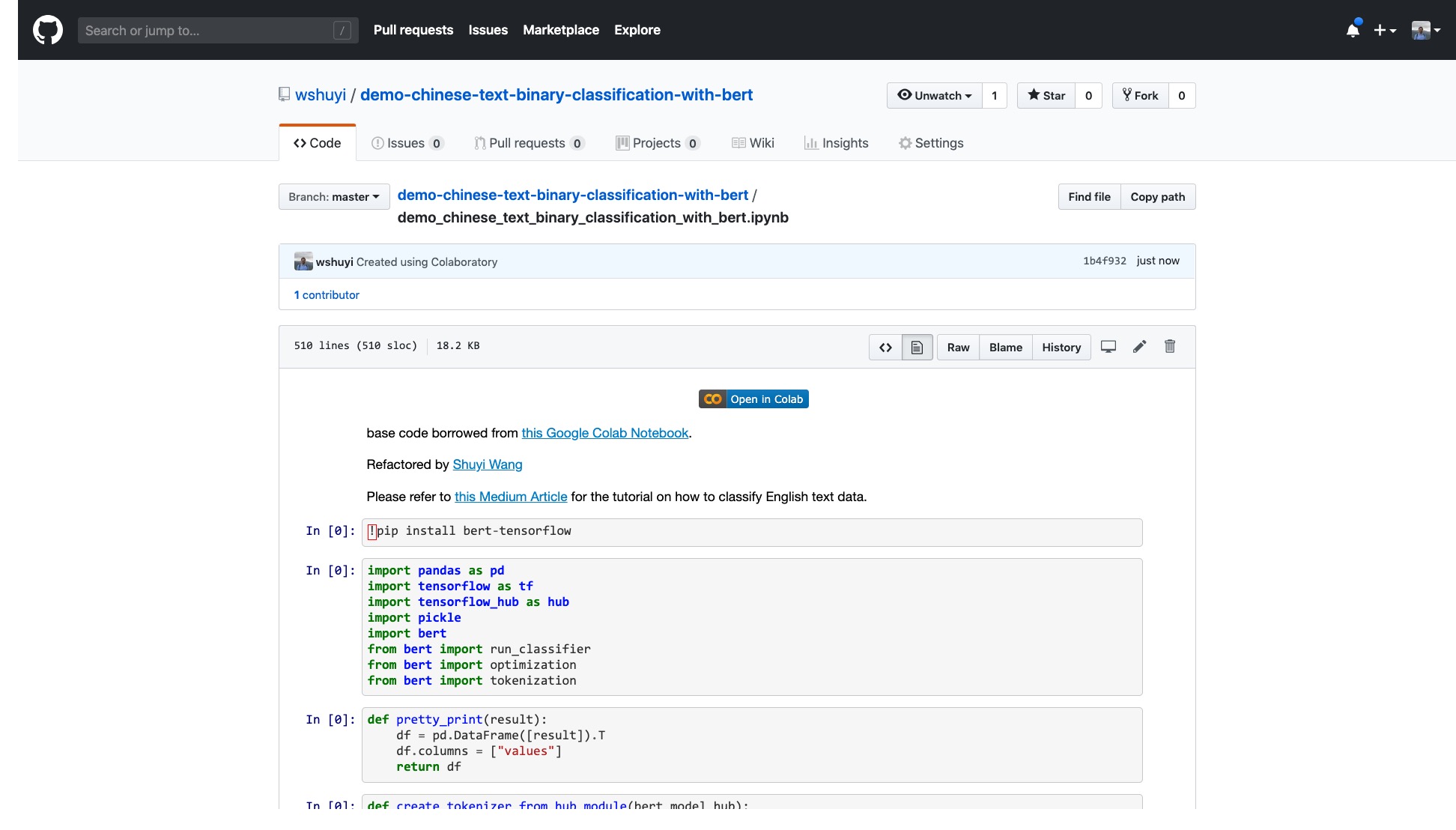
في الجزء العلوي من دفتر الملاحظات ، يوجد زر "Open in Colab" واضح للغاية. انقر فوقه وسيقوم Google Colab تلقائيًا بتشغيل هذا الكمبيوتر الدفتري وتحميله.
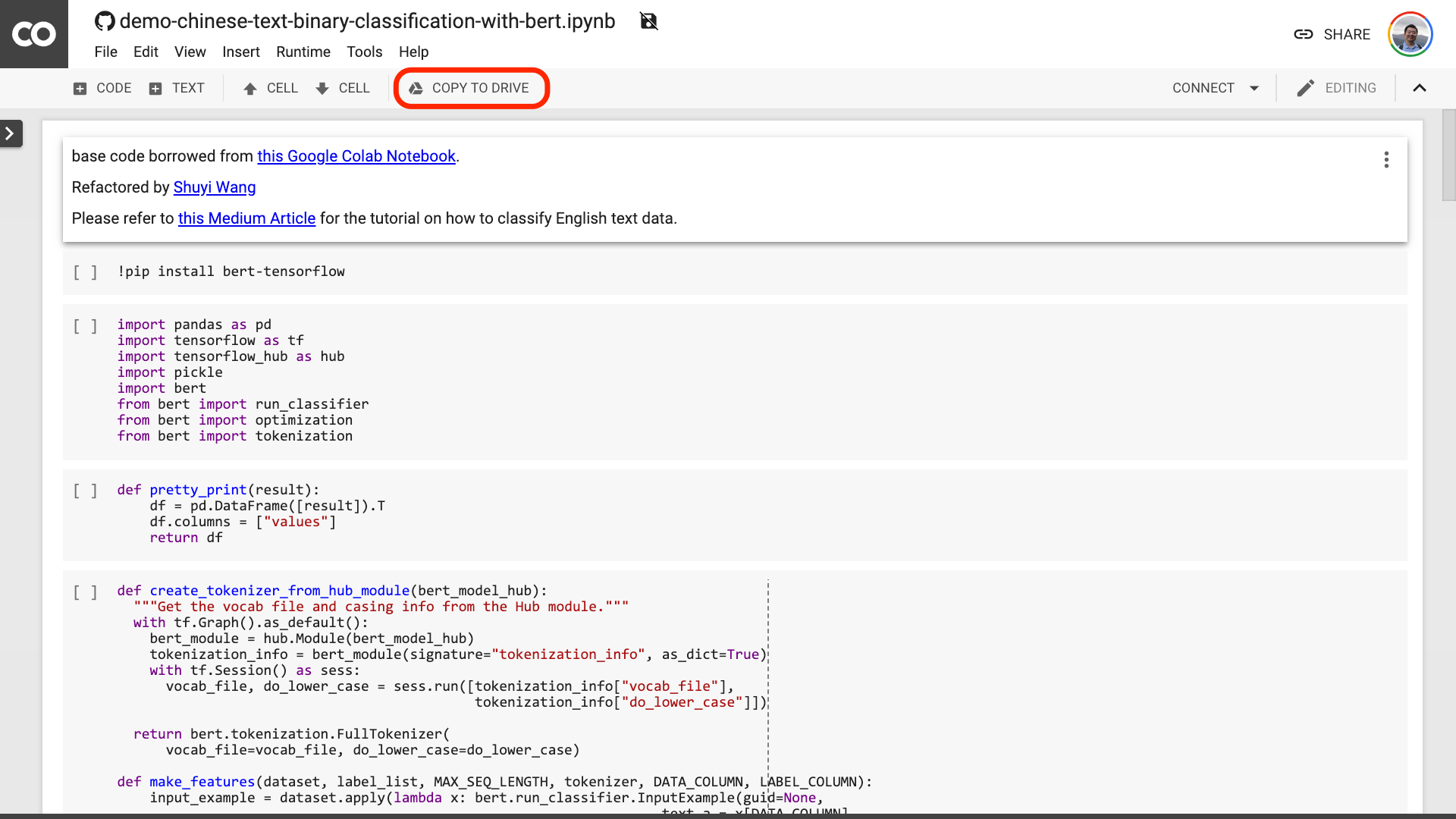
أقترح عليك النقر فوق الزر "نسخ إلى محرك الأقراص" محدودًا في الصورة الحمراء أعلاه. سيؤدي ذلك إلى حفظه في Google Drive أولاً للاستخدام والمراجعة.
بعد الانتهاء من ذلك ، تحتاج في الواقع فقط إلى إجراء الخطوات الثلاث التالية:
بعد حفظ دفتر الملاحظات. إذا نظرت عن كثب ، فقد تشعر بالخداع.
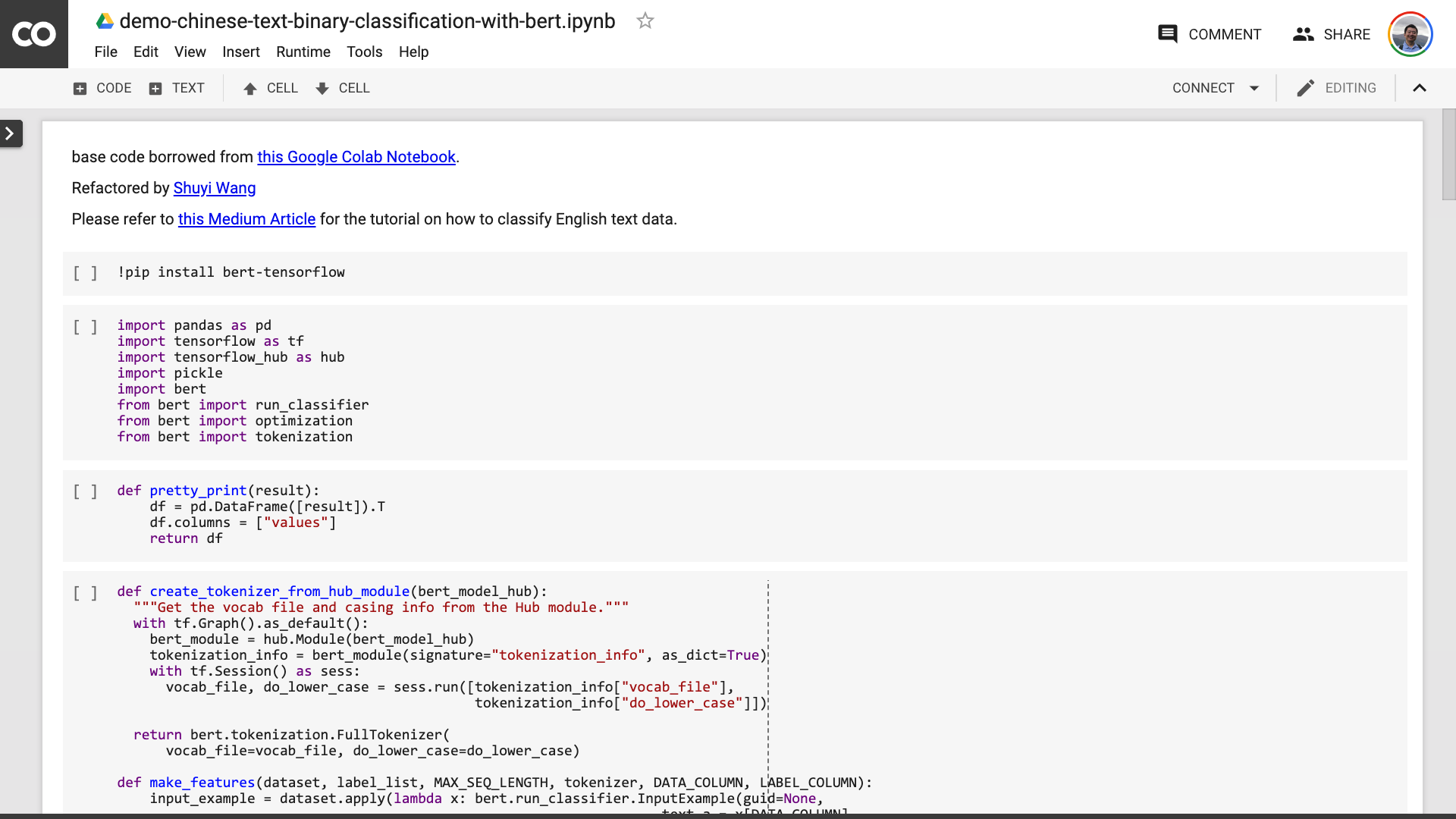
المعلم ، لقد كذبت! تم الاتفاق على أنه لا يوجد أكثر من 10 أسطر من الكود!
لا تقلق .
لا تحتاج إلى تعديل أي شيء قبل أن تدور حول الجملة باللون الأحمر في الصورة أدناه.
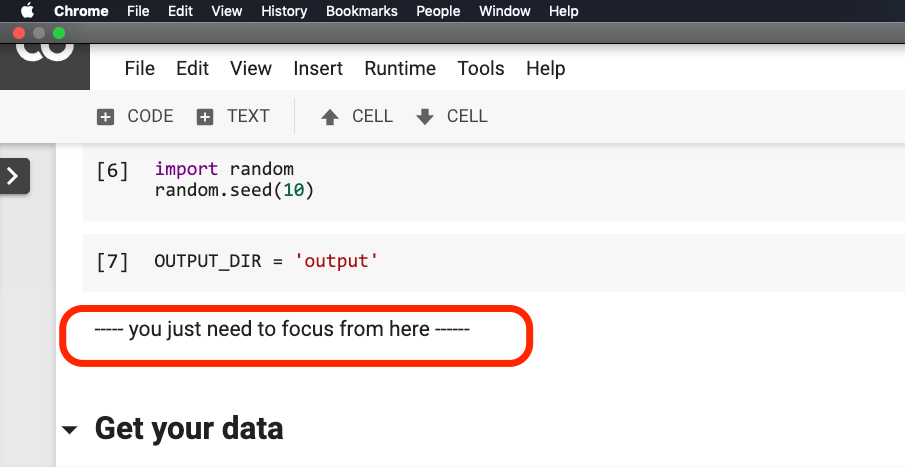
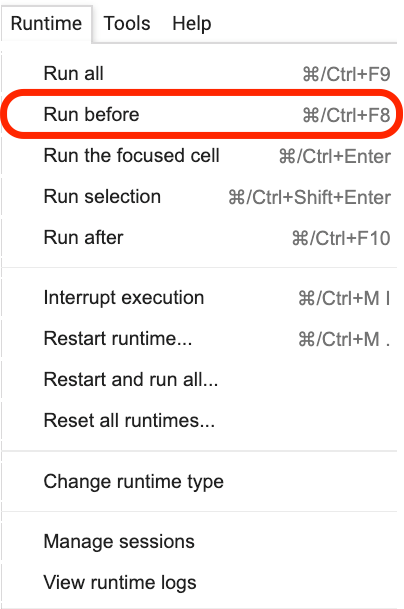
يرجى النقر فوق مكان وجود هذه الجملة ، ثم حدد Run before من القائمة كما هو موضح في الشكل التالي.
فيما يلي جميع الروابط المهمة ، التركيز.
الخطوة الأولى هي إعداد البيانات.
!w get https : // github . com / wshuyi / demo - chinese - text - binary - classification - with - bert / raw / master / dianping_train_test . pickle
with open ( "dianping_train_test.pickle" , 'rb' ) as f :
train , test = pickle . load ( f )يجب أن تكون على دراية بالبيانات المستخدمة هنا. إنها بيانات التعليقات العاطفية لمراجعات تقديم الطعام. أنا في "كيفية تدريب نموذج تصنيف المشاعر الصينية مع Python والتعلم الآلي؟》 و" كيفية استخدام بيثون والشبكات العصبية المتكررة لتصنيف النصوص الصينية؟ 》 استخدمه. ومع ذلك ، من أجل راحة العرض التوضيحي ، أقوم بإخراجها كتنسيق المخلل هذه المرة ووضعها في العرض التوضيحي Github repo معًا للتنزيل والاستخدام.
تحتوي مجموعة التدريب على 1600 قطعة من البيانات ؛ تحتوي مجموعة الاختبار على 400 قطعة من البيانات. في الملصق ، يمثل 1 المشاعر الإيجابية و 0 يمثل المشاعر السلبية.
باستخدام البيان التالي ، نخلط مجموعة التدريب ونتعطش الطلب. لتجنب التغطية الزائدة.
train = train . sample ( len ( train ))دعنا نلقي نظرة على محتوى رأس مجموعة التدريب لدينا.
train . head ()
إذا كنت ترغب في استبدال مجموعة البيانات الخاصة بك لاحقًا ، فيرجى الانتباه إلى التنسيق. يجب أن تكون أسماء الأعمدة لمجموعات التدريب والاختبار متسقة.
في الخطوة الثانية ، سنقوم بتعيين المعلمات.
myparam = {
"DATA_COLUMN" : "comment" ,
"LABEL_COLUMN" : "sentiment" ,
"LEARNING_RATE" : 2e-5 ,
"NUM_TRAIN_EPOCHS" : 3 ,
"bert_model_hub" : "https://tfhub.dev/google/bert_chinese_L-12_H-768_A-12/1"
}يهدف الخطان الأولين إلى الإشارة بوضوح إلى أسماء الأعمدة المقابلة للنص والعلامات.
السطر الثالث يحدد معدل التدريب. يمكنك قراءة الورقة الأصلية لإجراء محاولة تعديل Hyperparameter. أو يمكنك ببساطة الحفاظ على القيمة الافتراضية دون تغيير.
السطر 4 ، حدد عدد جولات التدريب. تشغيل جميع البيانات في جولة واحدة. 3 جولات تستخدم هنا.
يعرض السطر الأخير النموذج الذي تم تدريبه مسبقًا Bert الذي تريد استخدامه. نريد تصنيف النص الصيني ، لذلك نستخدم عنوان النموذج الصيني الذي تم تدريبه قبل التدريب. إذا كنت ترغب في استخدام اللغة الإنجليزية ، فيمكنك الرجوع إلى منشور مدونتي المتوسط ورمز نموذج اللغة الإنجليزية المقابل.
في الخطوة الأخيرة ، نقوم بتنفيذ الكود بدوره.
result , estimator = run_on_dfs ( train , test , ** myparam )لاحظ أنه قد يستغرق الأمر بعض الوقت لتنفيذ هذه الجملة. كن مستعدًا عقلياً. يرتبط هذا بإعدادات حجم البيانات وإعدادات التدريب.
في هذه العملية ، يمكنك أن ترى أن البرنامج يساعدك أولاً في تحويل النص الصيني الأصلي إلى تنسيق لبيانات الإدخال الذي يمكن أن يفهمه Bert.
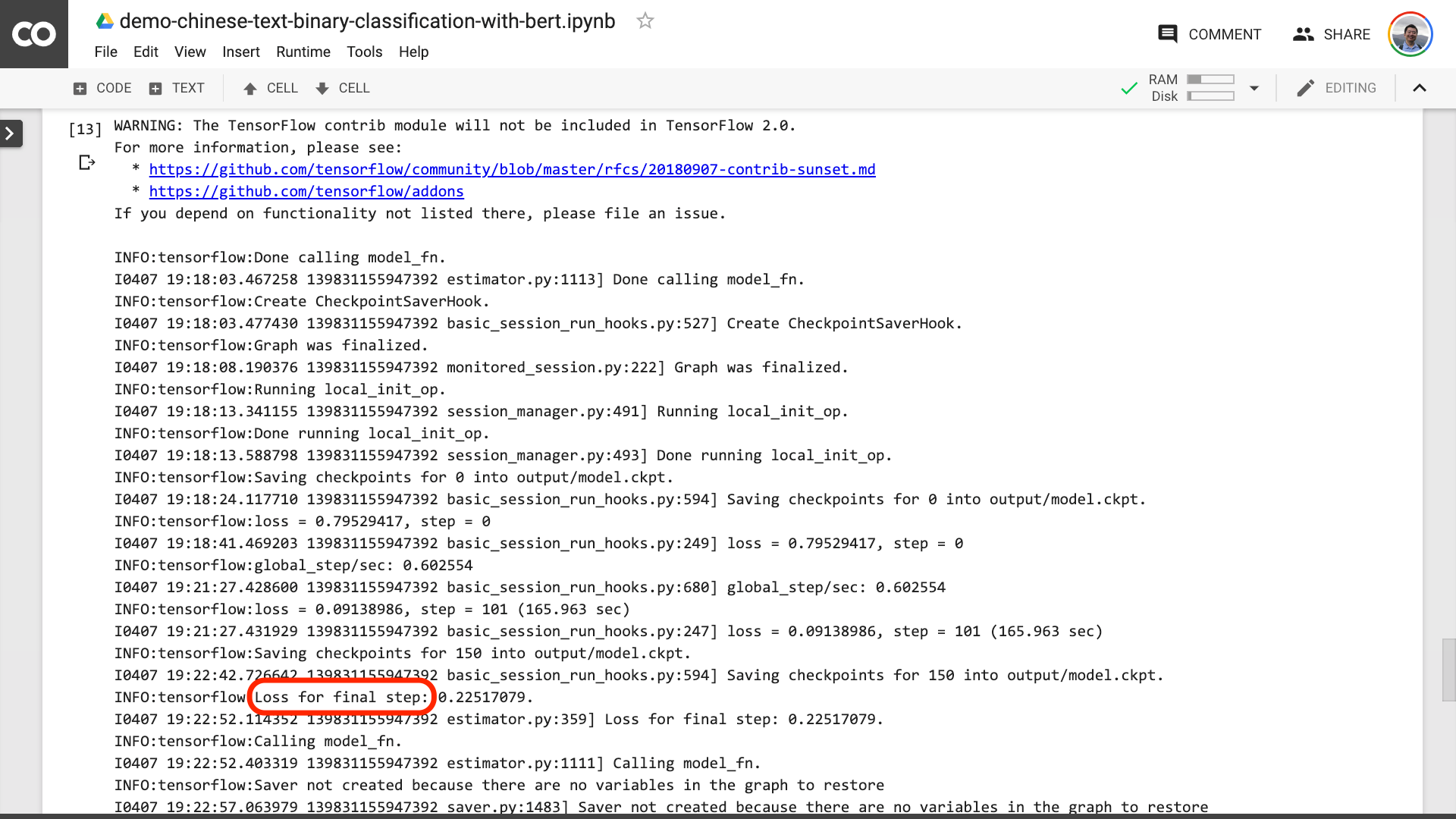
عندما ترى النص محاطًا باللون الأحمر في الصورة أدناه ، فهذا يعني أن عملية التدريب قد انتهت أخيرًا.
ثم يمكنك طباعة نتائج الاختبار.
pretty_print ( result )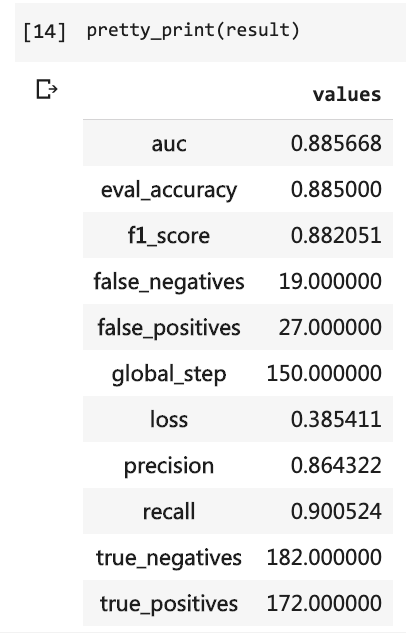
قارن مع البرنامج التعليمي السابق (باستخدام نفس مجموعة البيانات).
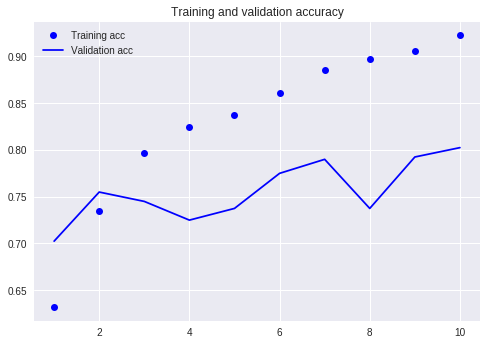
في ذلك الوقت ، اضطررت إلى كتابة العديد من خطوط التعليمات البرمجية واضطررت إلى تشغيل 10 جولات ، لكن النتيجة لم تكن أكثر من 80 ٪. هذه المرة ، على الرغم من أنني تدربت فقط على 3 جولات ، فقد تجاوز معدل الدقة 88 ٪.
ليس من السهل تحقيق هذه الدقة على مجموعة بيانات صغيرة الحجم هذه.
أداء بيرت واضح.
بعد قولي هذا ، لقد تعلمت كيفية استخدام Bert للقيام بمهمة التصنيف الثنائي للنص الصيني. أتمنى أن تكون سعيدًا مثلي.
إذا كنت من عشاق بيثون كبير ، فالرجاء أن تقدم لي معروفًا.
تذكر الرمز قبل هذا السطر؟
هل يمكنك مساعدتي في تعبئتهم؟ وبهذه الطريقة ، يمكن أن يكون الرمز التجريبي الخاص بنا أقصر وأكثر إيجازًا وأكثر وضوحًا وأسهل في الاستخدام.
مرحبًا بك في إرسال الرمز الخاص بك في مشروع GitHub الخاص بنا. إذا وجدت هذا البرنامج التعليمي مفيدًا ، فيرجى إضافة نجوم إلى مشروع GitHub. شكرًا!
تعلم عميق سعيد!
قد تكون مهتمًا أيضًا بالمواضيع التالية. انقر على الرابط لعرضه.
إذا أعجبك ذلك ، فالرجاء إعجاب ومكافأة. يمكنك أيضًا متابعة حسابي الرسمي "Yushuzhilan" (Nkwangshuyi) على WeChat.
إذا كنت مهتمًا بعلوم Python وعلم البيانات ، فيمكنك أيضًا قراءة سلسلة من مشاركات فهرس البرنامج التعليمي "كيفية البدء في علوم البيانات بكفاءة؟》 ، هناك أسئلة وحلول أكثر إثارة للاهتمام فيها.
مدخل كوكب المعرفة هنا:


