demo chinese text binary classification with bert
1.0.0

Tahun lalu, saya sangat bersemangat segera setelah model Google Bert dirilis.
Karena saya menggunakan Ulmfit Fast.ai untuk melakukan tugas -tugas klasifikasi bahasa alami pada waktu itu (saya juga menulis artikel khusus "Cara menggunakan Python dan Transfer Deep Learning untuk mengklasifikasikan teks?" Untuk berbagi dengan Anda). Ulmfit dan Bert keduanya adalah model bahasa pra-terlatih dan memiliki banyak kesamaan.
Model bahasa yang disebut menggunakan struktur jaringan saraf yang dalam untuk melatih teks bahasa besar-besaran untuk memahami fitur umum suatu bahasa.
Pekerjaan di atas seringkali hanya mungkin untuk diselesaikan lembaga besar. Karena biayanya terlalu besar.
Biaya ini termasuk tetapi tidak terbatas pada:
Pra-pelatihan berarti mereka membuka hasil ini setelah mereka dilatih. Kami orang biasa atau lembaga kecil juga dapat meminjam hasil dan menyempurnakan data teks kami sendiri di bidang khusus kami sehingga model dapat memiliki pemahaman yang sangat jelas tentang teks di bidang khusus ini.
Yang disebut pemahaman terutama mengacu pada fakta bahwa Anda memblokir kata-kata tertentu, dan model dapat menebak dengan lebih akurat apa yang Anda sembunyikan.
Bahkan jika Anda menyatukan dua kalimat, model dapat menentukan apakah mereka terhubung erat hubungan kontekstual.

Apakah ini "pengetahuan" bermanfaat?
Tentu saja ada.
Bert menguji beberapa tugas bahasa alami, dan banyak hasil telah melampaui pemain manusia.

Bert dapat membantu menyelesaikan tugas, tentu saja, juga termasuk klasifikasi teks, seperti klasifikasi emosi. Ini juga masalah yang sedang saya pelajari.
Namun, untuk menggunakan Bert, saya menunggu lama.
Kode Google resmi telah terbuka. Bahkan implementasi di Pytorch telah diulangi untuk banyak putaran.
Tapi saya hanya perlu membuka sampel yang mereka berikan dan saya merasa pusing.
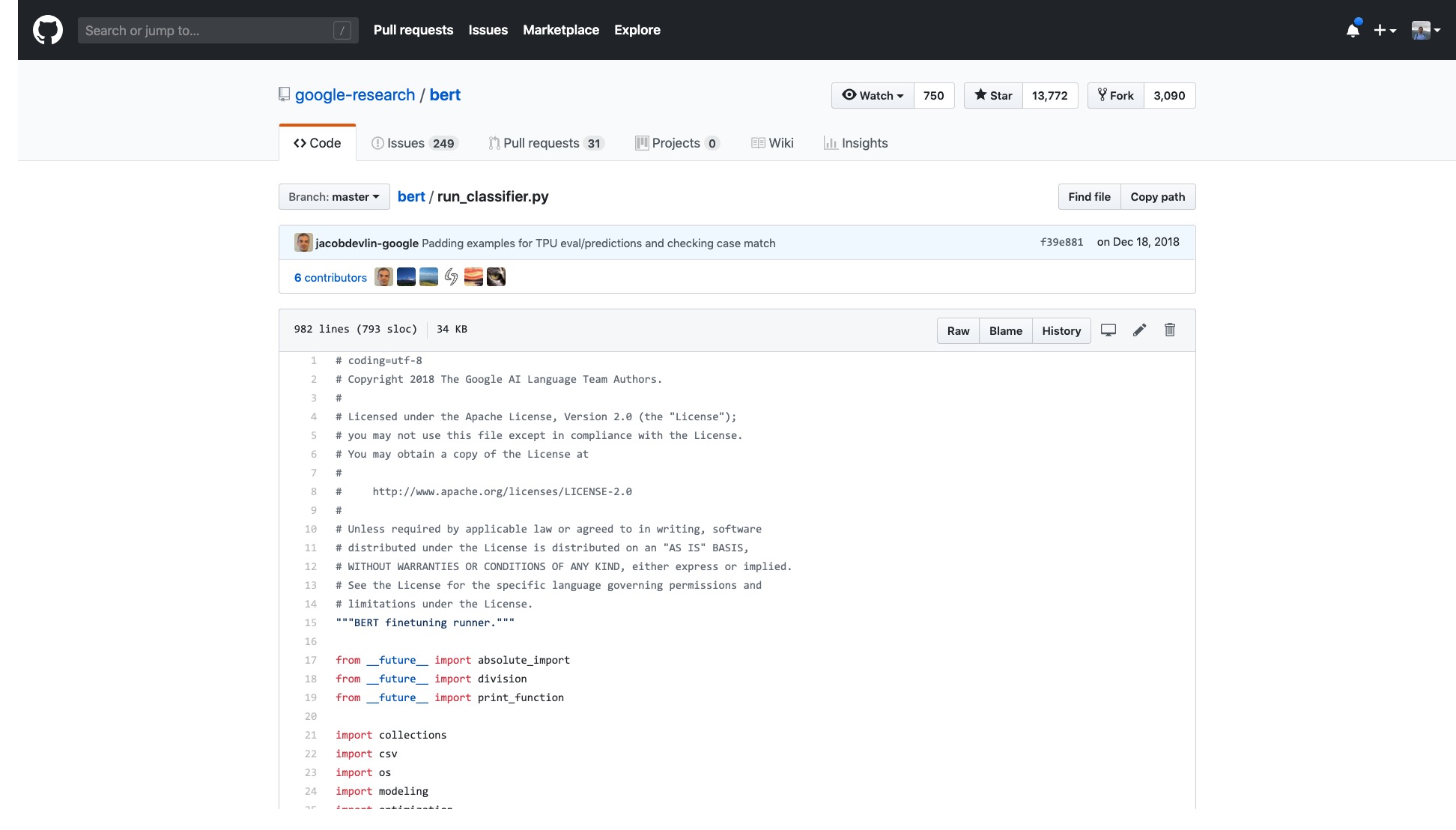
Jumlah baris dalam kode itu saja sangat menakutkan.
Selain itu, sekelompok proses pemrosesan data (pemroses data) dinamai berdasarkan nama set data. Data saya bukan milik salah satu di atas, jadi mana yang harus saya gunakan?

Ada juga bendera (bendera) yang tak terhitung jumlahnya yang sangat merepotkan.

Mari kita bandingkan seperti apa struktur sintaks di scikit-learn saat melakukan tugas klasifikasi.
from sklearn . datasets import load_iris
from sklearn import tree
iris = load_iris ()
clf = tree . DecisionTreeClassifier ()
clf = clf . fit ( iris . data , iris . target )Bahkan jika throughput data klasifikasi gambar besar dan membutuhkan banyak langkah, Anda dapat dengan mudah melakukannya dengan beberapa baris kode menggunakan Fast.ai.
!g it clone https : // github . com / wshuyi / demo - image - classification - fastai . git
from fastai . vision import *
path = Path ( "demo-image-classification-fastai/imgs/" )
data = ImageDataBunch . from_folder ( path , test = 'test' , size = 224 )
learn = cnn_learner ( data , models . resnet18 , metrics = accuracy )
learn . fit_one_cycle ( 1 )
interp = ClassificationInterpretation . from_learner ( learn )
interp . plot_top_losses ( 9 , figsize = ( 8 , 8 ))Jangan meremehkan baris kode ini. Ini tidak hanya membantu Anda melatih classifier gambar, tetapi juga memberi tahu Anda di mana model memperhatikan gambar -gambar itu dengan kesalahan klasifikasi tertinggi.

Perbandingan, menurut Anda apa perbedaan antara contoh Bert dan contoh fast.ai?
Saya pikir yang terakhir adalah untuk digunakan orang .
Saya selalu berpikir bahwa seseorang akan memperbaiki kode dan menulis tutorial ringkas.
Bagaimanapun, tugas klasifikasi teks adalah aplikasi pembelajaran mesin yang umum. Ada banyak skenario aplikasi dan juga cocok untuk dipelajari pemula.
Namun, saya hanya tidak menunggu tutorial seperti itu.
Tentu saja, selama periode ini, saya juga telah membaca aplikasi dan tutorial yang ditulis oleh banyak orang.
Beberapa orang dapat mengubah sepotong teks bahasa alami menjadi penyandian Bert. Itu berakhir tiba -tiba.
Beberapa orang dengan hati -hati memperkenalkan cara menggunakan Bert pada set data resmi yang disediakan. Semua modifikasi dilakukan pada skrip Python asli. Semua fungsi dan parameter yang tidak digunakan sama sekali dipertahankan. Adapun bagaimana orang lain menggunakan kembali kumpulan data mereka sendiri? Orang tidak menyebutkan ini sama sekali.
Saya sudah berpikir untuk mengunyah kode dari awal. Saya ingat ketika saya belajar untuk sekolah pascasarjana, saya juga membaca semua kode C dari lapisan TCP dan IP pada platform simulasi. Saya menentukan tugas di depan saya, yang kurang sulit.
Tapi saya benar -benar tidak ingin melakukannya. Saya merasa seperti dimanja oleh kerangka kerja pembelajaran mesin Python, terutama Fast.ai dan Scikit-learn.
Kemudian, pengembang Google membawa Bert ke TensorFlow Hub. Saya juga menulis sampel notebook Google Colab secara khusus.
Saya sangat senang melihat berita ini.
Saya sudah mencoba banyak model lain di TensorFlow Hub. Sangat nyaman untuk digunakan. Dan Google Colab Saya telah berlatih Python dengan Google Colab? 》 Diperkenalkan kepada Anda dalam artikel ", yang merupakan latihan pembelajaran mendalam Python yang sangat baik. Lingkungan demonstrasi. Saya pikir kedua pedang itu dapat digabungkan, dan kali ini saya bisa menangani tugas saya sendiri dengan beberapa baris kode.
Mari kita tunggu.
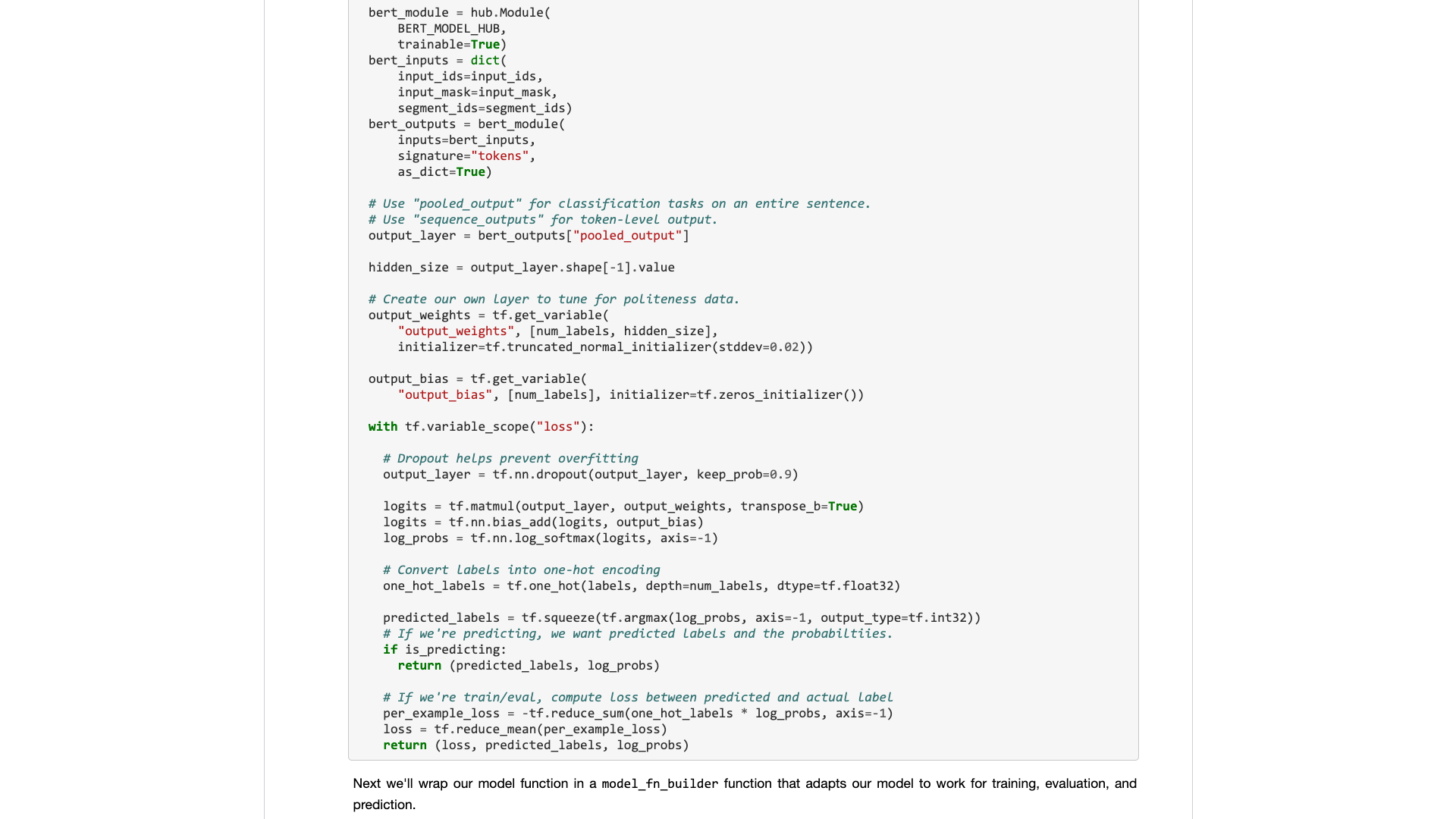
Ketika Anda benar -benar membukanya, Anda masih akan fokus pada data sampel.
Apa yang dibutuhkan pengguna biasa? Antarmuka diperlukan.
Anda memberi tahu saya spesifikasi standar yang Anda masukkan, dan kemudian beri tahu saya apa hasilnya. Pasang dan mainkan, dan tinggalkan.
Tugas klasifikasi teks awalnya memberi Anda satu set pelatihan dan tes, memberi tahu Anda seberapa cepat putaran pelatihan, dan kemudian memberi tahu saya tingkat akurasi dan hasilnya?
Adapun meminta saya untuk membaca ratusan baris kode untuk tugas yang begitu sederhana, dan mencari tahu di mana mengubahnya sendiri?
Untungnya, dengan contoh ini sebagai fondasi, lebih baik daripada tidak sama sekali.
Saya mengambil kesabaran dan menyelesaikannya.
Untuk menyatakan, saya tidak membuat perubahan besar pada kode asli.
Jadi, jika Anda tidak menjelaskannya dengan jelas, Anda akan dicurigai plagiarisme dan akan dibenci.
Organisasi semacam ini secara teknis tidak sulit bagi orang yang tahu cara menggunakan Python.
Tetapi karena ini, saya marah. Apakah ini sulit dilakukan? Mengapa penulis sampel Bert Google menolak untuk melakukannya?
Mengapa ada perubahan besar dari TensorFlow 1.0 ke 2.0? Bukankah karena 2.0 adalah untuk digunakan orang?
Anda tidak akan membuat antarmuka menyegarkan dan sederhana, pesaing Anda (Turicreate dan Fast.ai) akan melakukannya, dan mereka melakukannya dengan sangat baik. Hanya ketika saya tidak bisa duduk, saya masih bisa bersedia meremehkan yang mulia dan mengembangkan antarmuka yang berguna untuk orang biasa.
Pelajaran! Mengapa Anda tidak menyerapnya?
Saya akan memberi Anda sampel notebook Google Colab yang dapat dengan mudah Anda ganti pada dataset Anda sendiri untuk dijalankan. Anda perlu memahami (termasuk memodifikasi) kode, tidak lebih dari 10 baris .
Saya pertama kali menguji tugas klasifikasi teks bahasa Inggris, dan itu bekerja dengan sangat baik. Jadi saya menulis blog sedang, yang segera termasuk dalam kolom Data Science.
Editor Kolom Ilmu Data menuju saya mengirimi saya pesan pribadi yang mengatakan:
Sangat menarik, saya suka ini mengingat implementasi default tidak terlalu ramah pengembang.
Ada seorang pembaca yang benar -benar memberikan artikel 50 ini suka (bertepuk tangan) berturut -turut, dan saya terpana.

Tampaknya titik nyeri yang tahan lama ini bukan hanya saya.
Diperkirakan bahwa tugas klasifikasi Cina mungkin lebih banyak ditemui dalam penelitian Anda. Jadi saya hanya membuat contoh lain dari klasifikasi teks Cina dan menulis tutorial ini dan membaginya dengan Anda.
Mari kita mulai.
Silakan klik tautan ini untuk melihat file notebook ipython yang saya buat untuk Anda di github.
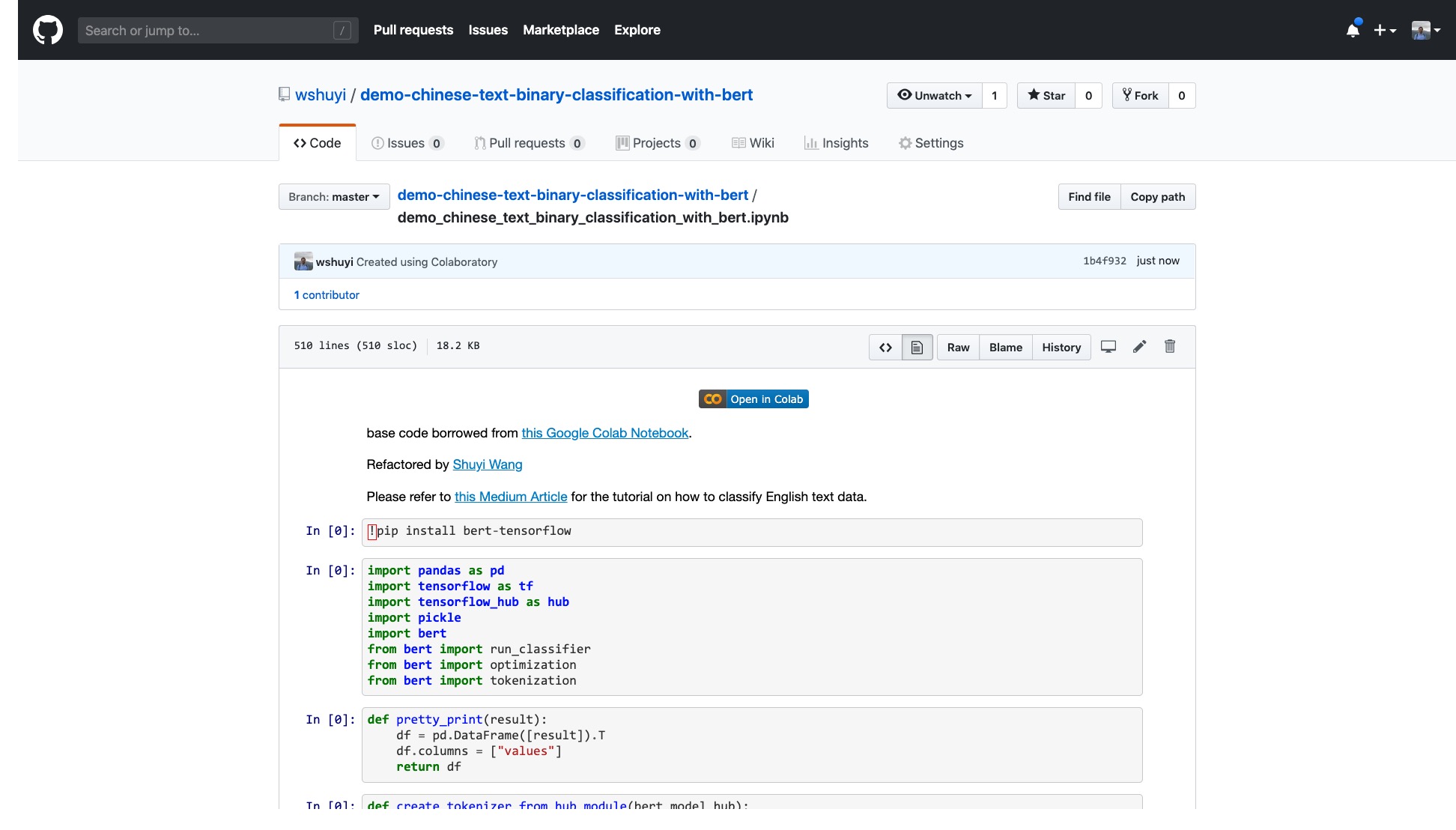
Di bagian atas notebook, ada tombol "Open in Colab" yang sangat jelas. Klik dan Google Colab akan secara otomatis menyala dan memuat buku catatan ini.
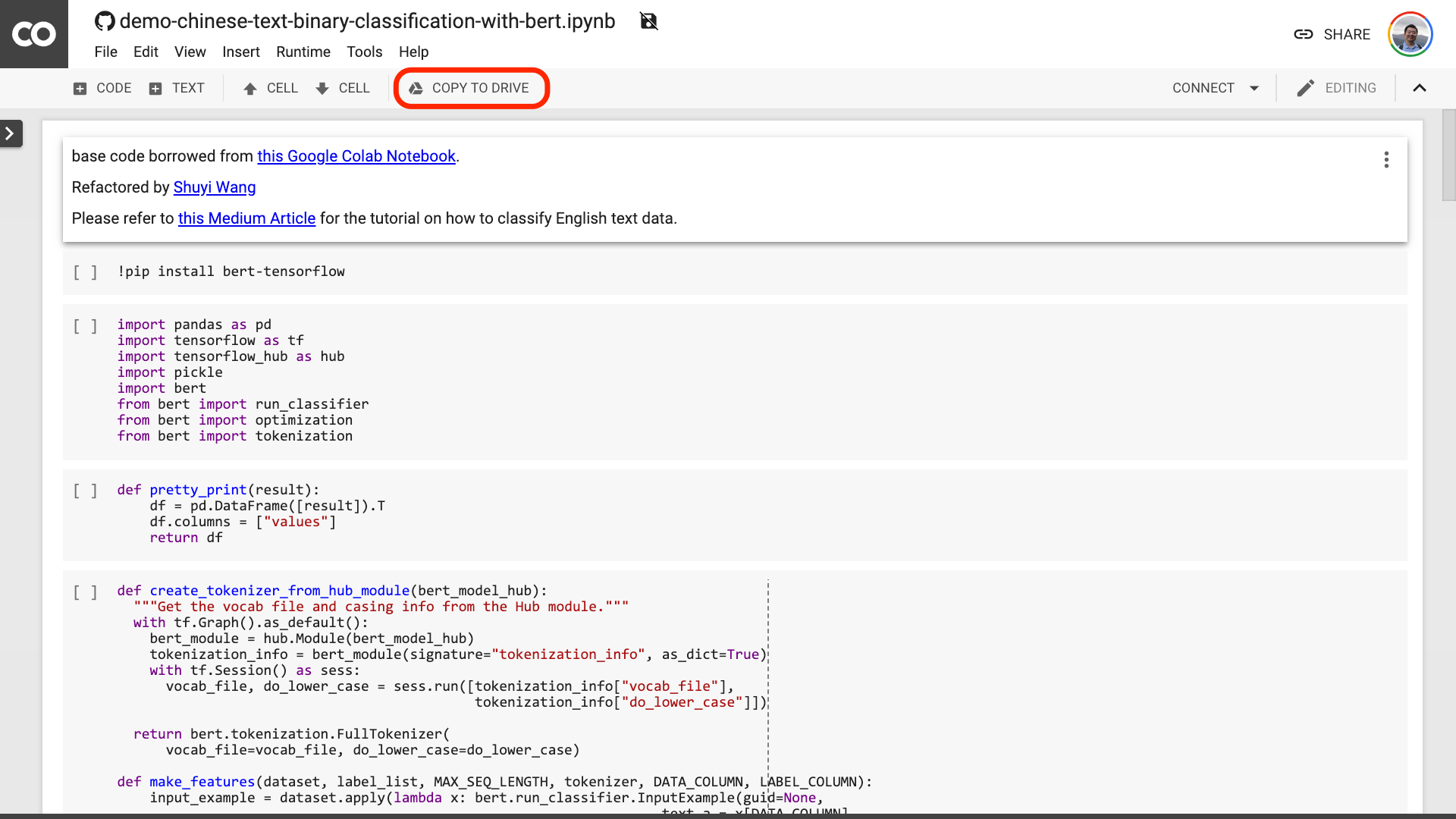
Saya sarankan Anda mengklik tombol "Salin ke Drive" yang dilingkari di gambar merah di atas. Ini akan menyimpannya di Google Drive Anda sendiri terlebih dahulu untuk digunakan dan ditinjau.
Setelah ini selesai, Anda sebenarnya hanya perlu melakukan tiga langkah berikut:
Setelah Anda menyimpan buku catatan. Jika Anda melihat lebih dekat, Anda mungkin merasa tertipu.
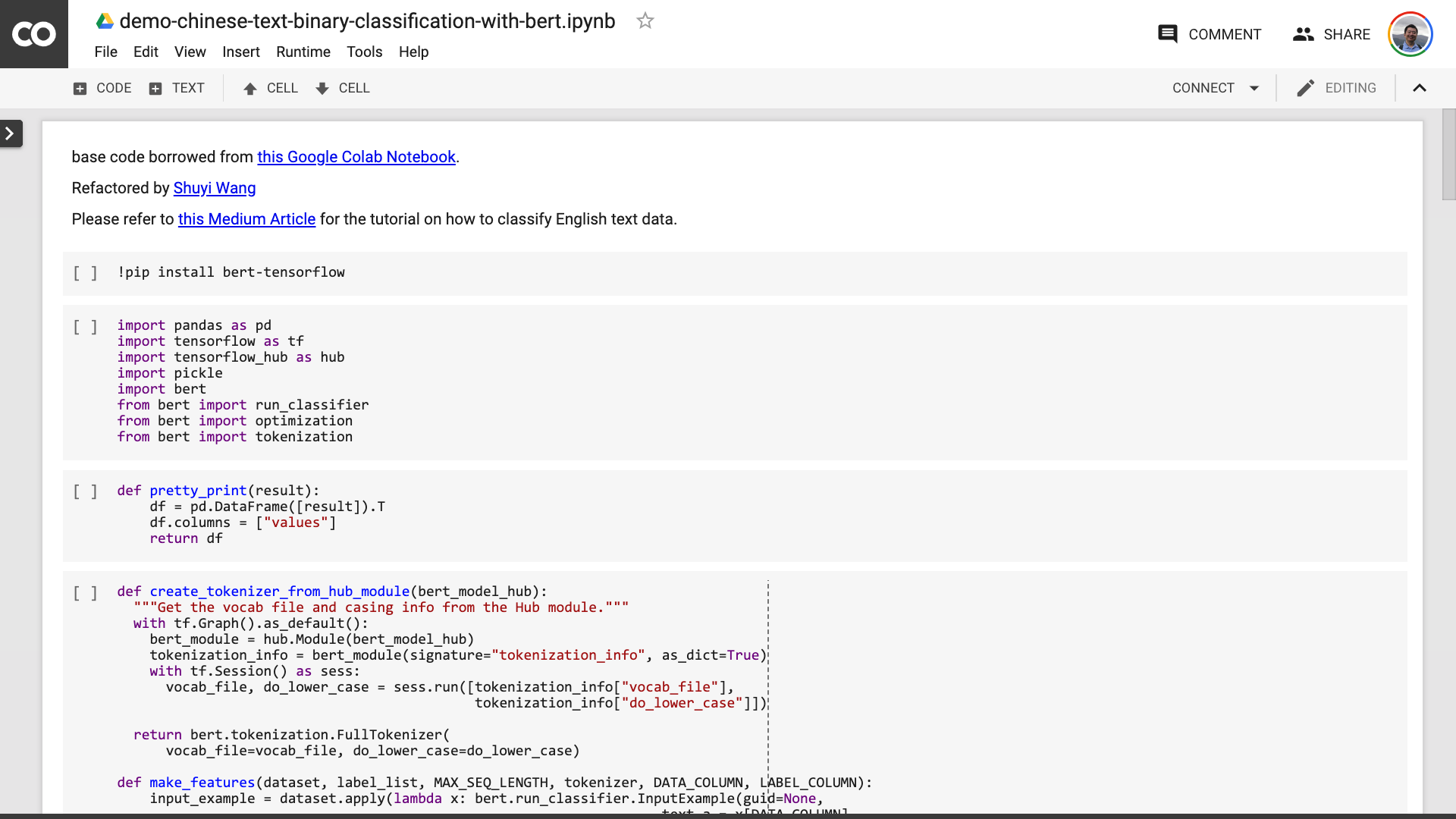
Guru, Anda berbohong! Disetujui bahwa tidak lebih dari 10 baris kode!
Jangan cemas .
Anda tidak perlu memodifikasi apa pun sebelum kalimat yang dilingkari merah pada gambar di bawah ini.
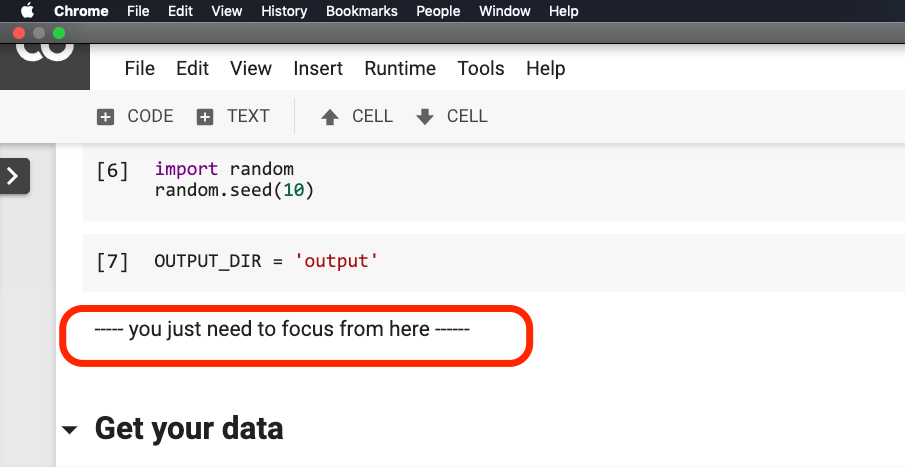
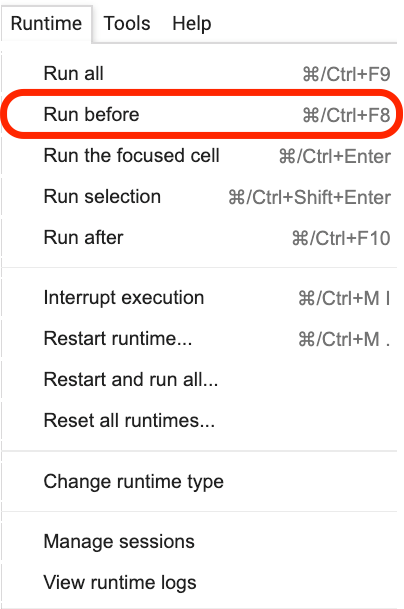
Silakan klik di mana kalimat ini berada, dan kemudian pilih Run before dari menu seperti yang ditunjukkan pada gambar berikut.
Berikut ini adalah semua tautan penting, fokus.
Langkah pertama adalah menyiapkan data.
!w get https : // github . com / wshuyi / demo - chinese - text - binary - classification - with - bert / raw / master / dianping_train_test . pickle
with open ( "dianping_train_test.pickle" , 'rb' ) as f :
train , test = pickle . load ( f )Anda harus terbiasa dengan data yang digunakan di sini. Ini adalah data anotasi emosional dari ulasan katering. Saya berada di "Cara Melatih Model Klasifikasi Emosi Teks Teks dengan Python dan Pembelajaran Mesin?》 Dan" Bagaimana cara menggunakan jaringan python dan berulang untuk mengklasifikasikan teks Cina? 》 Telah menggunakannya. Namun, untuk kenyamanan demonstrasi, saya menampilkannya sebagai pickle format kali ini dan memasukkannya ke dalam demonstrasi github repo bersama -sama untuk unduhan dan penggunaan Anda.
Set pelatihan berisi 1.600 lembar data; Set tes berisi 400 lembar data. Dalam label, 1 mewakili emosi positif dan 0 mewakili emosi negatif.
Dengan menggunakan pernyataan berikut, kami mengocok set pelatihan dan mengganggu pesanan. Untuk menghindari overfitting.
train = train . sample ( len ( train ))Mari kita lihat konten kepala dari set pelatihan kami.
train . head ()
Jika Anda ingin mengganti dataset Anda sendiri nanti, harap perhatikan formatnya. Nama kolom pelatihan dan set tes harus konsisten.
Pada langkah kedua, kami akan mengatur parameter.
myparam = {
"DATA_COLUMN" : "comment" ,
"LABEL_COLUMN" : "sentiment" ,
"LEARNING_RATE" : 2e-5 ,
"NUM_TRAIN_EPOCHS" : 3 ,
"bert_model_hub" : "https://tfhub.dev/google/bert_chinese_L-12_H-768_A-12/1"
}Dua baris pertama adalah untuk secara jelas menunjukkan nama kolom yang sesuai dari teks dan tanda.
Baris ketiga menentukan tingkat pelatihan. Anda dapat membaca kertas asli untuk melakukan upaya penyesuaian hiperparameter. Atau, Anda bisa menjaga nilai default tidak berubah.
Baris 4, tentukan jumlah putaran pelatihan. Jalankan semua data menjadi satu putaran. 3 putaran digunakan di sini.
Baris terakhir menunjukkan model pra-terlatih Bert yang ingin Anda gunakan. Kami ingin mengklasifikasikan teks Cina, jadi kami menggunakan alamat model pra-terlatih Cina ini. Jika Anda ingin menggunakan bahasa Inggris, Anda dapat merujuk ke posting blog medium saya dan kode sampel bahasa Inggris yang sesuai.
Pada langkah terakhir, kami hanya menjalankan kode secara bergantian.
result , estimator = run_on_dfs ( train , test , ** myparam )Perhatikan bahwa mungkin perlu waktu untuk menjalankan kalimat ini. Dipersiapkan secara mental. Ini terkait dengan volume data Anda dan pengaturan putaran pelatihan.
Dalam proses ini, Anda dapat melihat bahwa program pertama membantu Anda mengubah teks Cina asli menjadi format data input yang dapat dipahami oleh Bert.
Ketika Anda melihat teks dilingkari merah pada gambar di bawah ini, itu berarti proses pelatihan akhirnya berakhir.
Kemudian Anda dapat mencetak hasil tes.
pretty_print ( result )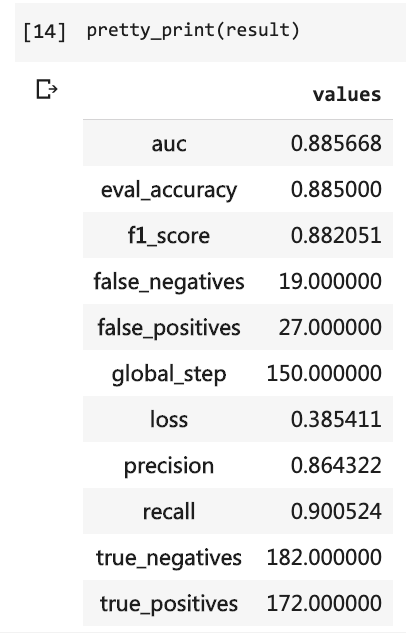
Bandingkan dengan tutorial kami sebelumnya (menggunakan dataset yang sama).
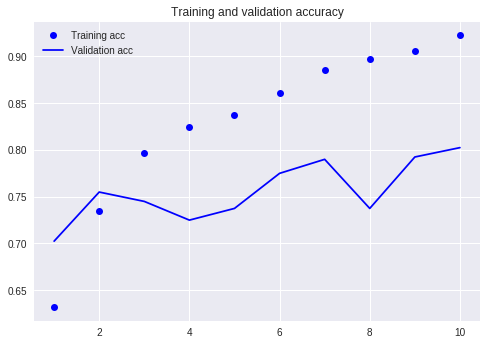
Pada saat itu, saya harus menulis begitu banyak baris kode dan saya harus menjalankan 10 putaran, tetapi hasilnya masih tidak lebih dari 80%. Kali ini, meskipun saya hanya berlatih selama 3 putaran, tingkat akurasi telah melebihi 88%.
Tidak mudah untuk mencapai akurasi seperti itu pada dataset skala kecil seperti itu.
Kinerja Bert terbukti.
Karena itu, Anda telah belajar cara menggunakan Bert untuk melakukan tugas klasifikasi biner dari teks Cina. Saya harap Anda akan bahagia seperti saya.
Jika Anda seorang penggemar Python senior, tolong bantu saya.
Ingat kode sebelum baris ini?
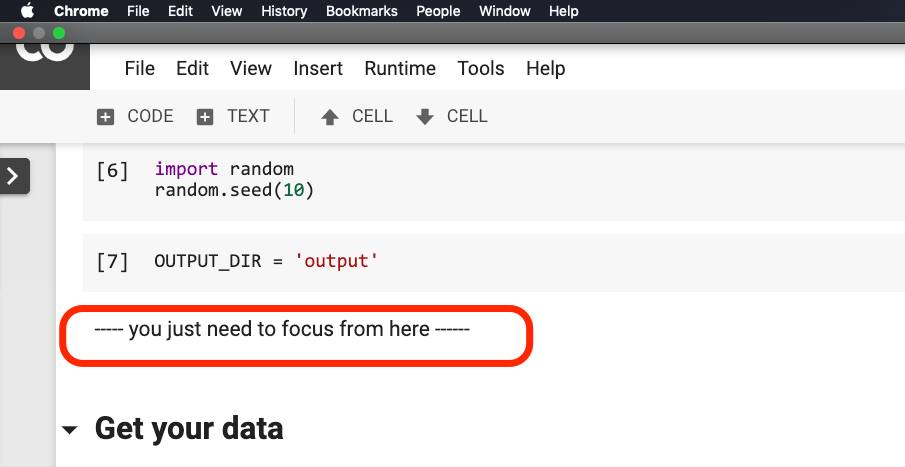
Bisakah Anda membantu saya mengemasnya? Dengan cara ini, kode demo kami bisa lebih pendek, lebih ringkas, lebih jelas dan lebih mudah digunakan.
Selamat datang untuk mengirimkan kode Anda di proyek GitHub kami. Jika Anda menemukan tutorial ini bermanfaat, silakan tambahkan bintang ke proyek GitHub ini. Terima kasih!
Pembelajaran yang dalam!
Anda mungkin juga tertarik dengan topik berikut. Klik tautan untuk melihatnya.
Jika Anda suka, silakan suka dan hadiah. Anda juga dapat mengikuti dan melampaui akun resmi saya "Yushuzhilan" (Nkwangshuyi) di WeChat.
Jika Anda tertarik pada python dan ilmu data, Anda mungkin juga membaca serangkaian posting indeks tutorial saya "Cara memulai dengan ilmu data secara efisien?》, Ada pertanyaan dan solusi yang lebih menarik di dalamnya.
Pintu masuk planet pengetahuan ada di sini:


