demo chinese text binary classification with bert
1.0.0

작년에 Google의 Bert 모델이 출시 되 자마자 매우 흥분했습니다.
당시 Fast.ai의 Ulmfit을 사용하여 자연어 분류 작업을 수행했기 때문에 (저는 또한 "Python과 Deep Transfer Learning을 사용하여 텍스트를 분류하는 방법"을 썼습니다. Ulmfit과 Bert는 모두 훈련 된 언어 모델이며 많은 유사점이 있습니다.
소위 언어 모델은 깊은 신경망 구조를 사용하여 언어의 일반적인 특징을 파악하기 위해 거대한 언어 텍스트를 훈련시킵니다.
위의 작업은 종종 대규모 기관이 완료 될 수 있습니다. 비용이 너무 크기 때문에.
이 비용은 다음을 포함하지만 이에 국한되지는 않습니다.
사전 훈련은 훈련 후이 결과를 열어 준 것을 의미합니다. 우리는 평범한 사람들이나 소규모 기관이 결과를 빌려서 전문 분야에서 자신의 텍스트 데이터를 미세 조정하여 모델 이이 전문 분야에서 텍스트를 매우 명확하게 이해할 수 있도록 할 수 있습니다.
소위 이해는 주로 특정 단어를 차단한다는 사실을 말하며, 모델은 숨어있는 것을보다 정확하게 추측 할 수 있습니다.
두 문장을 정리하더라도 모델은 맥락 관계가 밀접하게 연결되어 있는지 여부를 결정할 수 있습니다.

이 "지식"이 유용합니까?
물론 있습니다.
버트는 여러 자연 언어 작업에 대해 테스트했으며 많은 결과가 인간 플레이어를 능가했습니다.

Bert는 물론 과제 해결에 도움을 줄 수 있습니다. 물론 감정 분류와 같은 텍스트 분류도 포함됩니다. 이것은 또한 내가 현재 공부하고있는 문제이기도합니다.
그러나 Bert를 사용하기 위해 오랫동안 기다렸습니다.
공식 Google 코드가 열렸습니다. Pytorch의 구현조차도 많은 라운드에서 반복되었습니다.
그러나 나는 그들이 제공하는 샘플을 열어야하며 현기증을 느낍니다.
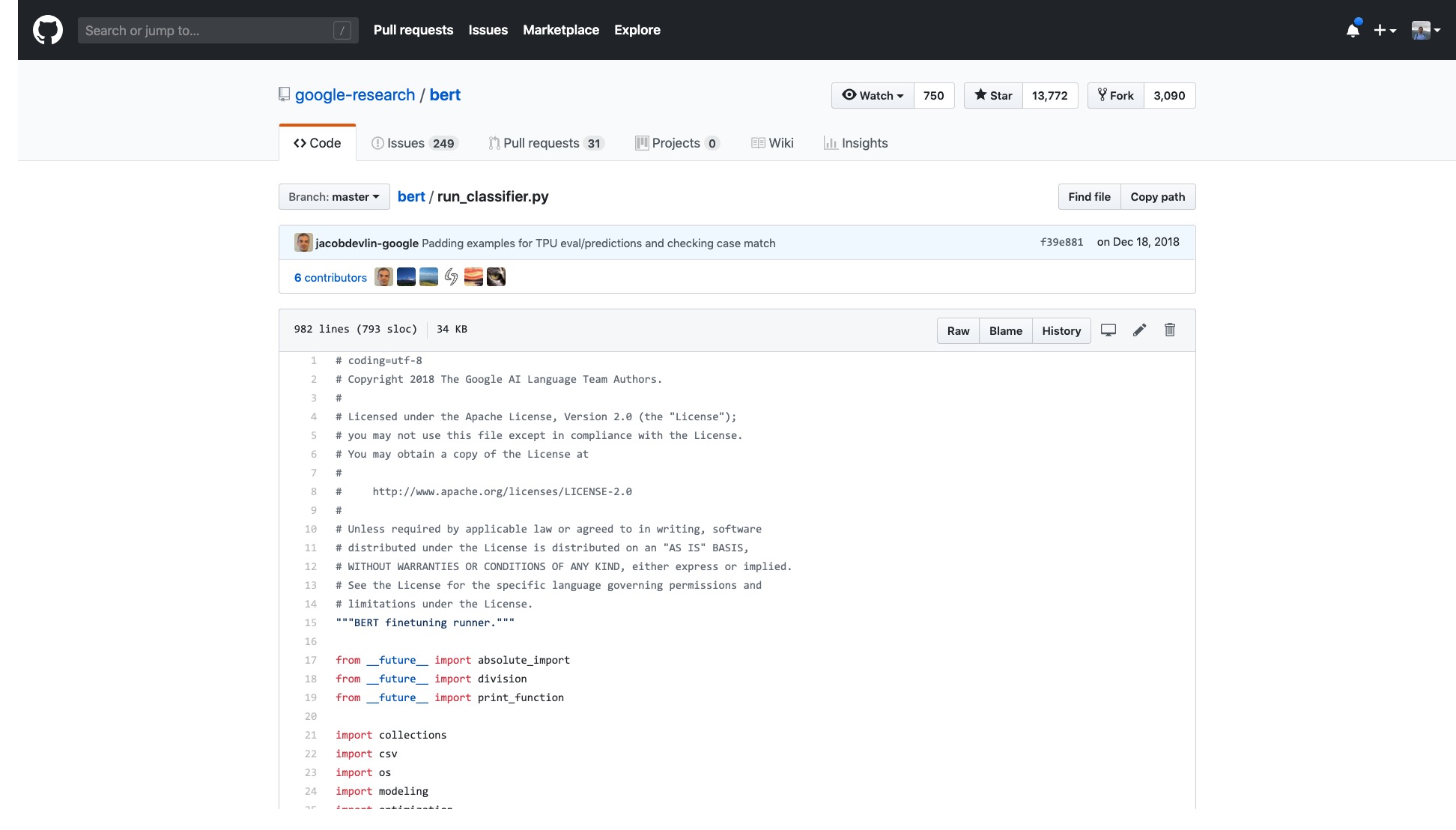
해당 코드의 줄 수는 매우 무섭습니다.
또한 다양한 데이터 처리 프로세스 (데이터 프로세서)의 이름이 데이터 세트 이름의 이름을 따서 명명되었습니다. 내 데이터는 위의 것 중 어느 것도 속하지 않으므로 어떤 것을 사용해야합니까?

설명 할 수 없을 정도로 귀찮은 수많은 깃발 (깃발)도 있습니다.

분류 작업을 수행 할 때 Scikit-Learn의 구문 구조가 어떻게 보이는지 비교해 봅시다.
from sklearn . datasets import load_iris
from sklearn import tree
iris = load_iris ()
clf = tree . DecisionTreeClassifier ()
clf = clf . fit ( iris . data , iris . target )이미지 분류의 데이터 처리량이 크고 많은 단계가 필요하더라도 Fast.ai를 사용하여 몇 줄의 코드로 쉽게 수행 할 수 있습니다.
!g it clone https : // github . com / wshuyi / demo - image - classification - fastai . git
from fastai . vision import *
path = Path ( "demo-image-classification-fastai/imgs/" )
data = ImageDataBunch . from_folder ( path , test = 'test' , size = 224 )
learn = cnn_learner ( data , models . resnet18 , metrics = accuracy )
learn . fit_one_cycle ( 1 )
interp = ClassificationInterpretation . from_learner ( learn )
interp . plot_top_losses ( 9 , figsize = ( 8 , 8 ))이러한 코드 라인을 과소 평가하지 마십시오. 이미지 분류기를 훈련시키는 데 도움이 될뿐만 아니라 분류 오류가 가장 높은 이미지에서 모델이 어디에주의를 기울이고 있는지 알려줍니다.

비교, Bert 예제와 Fast.ai 예제의 차이점은 무엇이라고 생각하십니까?
후자는 사람들이 사용하는 것이라고 생각합니다.
나는 항상 누군가가 코드를 리팩토링하고 간결한 튜토리얼을 작성할 것이라고 생각했습니다.
결국 텍스트 분류 작업은 일반적인 기계 학습 응용 프로그램입니다. 응용 프로그램 시나리오가 많이 있으며 초보자가 배우는 데 적합합니다.
그러나 나는 그러한 튜토리얼을 기다리지 않았습니다.
물론이 기간 동안 나는 많은 사람들이 작성한 응용 프로그램과 튜토리얼도 읽었습니다.
어떤 사람들은 자연어 텍스트를 Bert 인코딩으로 변환 할 수 있습니다. 갑자기 끝났습니다.
일부 사람들은 제공된 공식 데이터 세트에서 Bert를 사용하는 방법을 신중하게 소개합니다. 모든 수정은 원래 Python 스크립트에서 수행됩니다. 전혀 사용되지 않는 모든 기능과 매개 변수가 유지됩니다. 다른 사람들이 자신의 데이터 세트를 재사용하는 방법에 관해서는? 사람들은 이것을 전혀 언급하지 않았습니다.
처음부터 코드를 씹는 것에 대해 생각했습니다. 대학원에서 공부할 때 시뮬레이션 플랫폼에서 TCP 및 IP 계층의 모든 C 코드도 읽었습니다. 나는 내 앞에있는 과제를 결정했는데, 그것은 덜 어려웠다.
그러나 나는 정말로 그것을하고 싶지 않습니다. Python Machine Learning Frameworks, 특히 Fast.ai 및 Scikit-Learn에 의해 망친 것 같습니다.
나중에 Google 개발자들은 Bert를 Tensorflow Hub로 가져 왔습니다. 또한 Google Colab 노트북 샘플을 구체적으로 썼습니다.
이 소식을 보니 너무 기뻤습니다.
Tensorflow Hub에서 다른 많은 모델을 시도했습니다. 사용하기가 매우 편리합니다. 그리고 Google Colab 나는 Google Colab과 함께 Python을 연습 했습니까? 》이 기사에서 "매우 훌륭한 파이썬 딥 러닝 운동 및 데모 환경 인 기사에서 소개됩니다. 두 개의 검이 결합 될 수 있다고 생각했으며 이번에는 몇 줄의 코드로 내 자신의 작업을 처리 할 수있었습니다.
기다리겠습니다.
실제로 열면 여전히 샘플 데이터에 중점을 둘 것입니다.
일반 사용자는 무엇이 필요합니까? 인터페이스가 필요합니다.
입력 한 표준 사양을 알려주고 결과가 무엇인지 알려주세요. 플러그 앤 플레이를하고 결국 떠나십시오.
텍스트 분류 작업은 원래 교육 세트 및 테스트 세트를 제공하여 교육 라운드가 얼마나 빠른지 알려주고 정확도 속도와 결과를 알려 주시겠습니까?
그런 간단한 작업을 위해 수백 줄의 코드를 읽고 직접 변경 해야하는 곳을 찾으라고 요청하는 것입니다.
다행히도이 예제는 기초로서 아무것도 아닌 것보다 낫습니다.
나는 인내심을 가져다가 정리했다.
말하자면, 나는 원래 코드를 크게 변경하지 않았다.
따라서 명확하게 설명하지 않으면 표절이 의심되고 멸시 될 것입니다.
이러한 종류의 조직은 파이썬 사용 방법을 아는 사람들에게는 기술적으로 어렵지 않습니다.
그러나이 때문에 나는 화를 낸다. 이것이 어렵습니까? Google의 Bert 샘플 작가가 왜 그렇게하지 않았습니까?
텐서 플로에서 1.0에서 2.0에서 큰 변화가있는 이유는 무엇입니까? 2.0이 사람들이 사용하기 때문에 그렇지 않습니까?
인터페이스를 상쾌하게 만들고 간단하게 만들지 않으면 경쟁사 (Turicreate and Fast.ai)가 그렇게 할 것입니다. 내가 여전히 앉을 수없는 경우에만 고귀한 사람들을 기꺼이 내리고 평범한 사람들에게 유용한 인터페이스를 개발할 수 있습니다.
수업! 왜 흡수하지 않습니까?
자체 데이터 세트에서 쉽게 교체 할 수있는 Google Colab 노트북 샘플을 제공하겠습니다. 코드를 이해하고 (수정 포함) 10 줄을 넘지 않아야 합니다.
먼저 영어 텍스트 분류 작업을 테스트했으며 매우 잘 작동했습니다. 그래서 나는 데이터 과학에 즉시 포함 된 중간 블로그를 썼습니다.
The Teat Data Science 열 편집자는 나에게 개인 메시지를 보냈다.
매우 흥미 롭습니다. 기본 구현이 개발자 친화적이지 않다는 점을 고려하면이 마음이 마음에 듭니다.
실제로이 기사 50 좋아요 (박수)를 연속으로 한 독자가 있었고 나는 기절했습니다.

이 긴 장수의 고통 지점은 나만이 아니라는 것 같습니다.
중국 분류 작업이 연구에서 더 많이 발생할 수있는 것으로 추정됩니다. 그래서 나는 단순히 중국어 텍스트 분류의 또 다른 예를 만들었고이 튜토리얼을 작성하고 당신과 공유했습니다.
시작합시다.
이 링크를 클릭하여 GitHub에서 제가 만든 IPYTHON 노트북 파일을보십시오.
노트북 상단에는 매우 명백한 "Colab in Colab"버튼이 있습니다. 클릭하면 Google Colab이 자동으로 켜지고이 노트북을로드합니다.
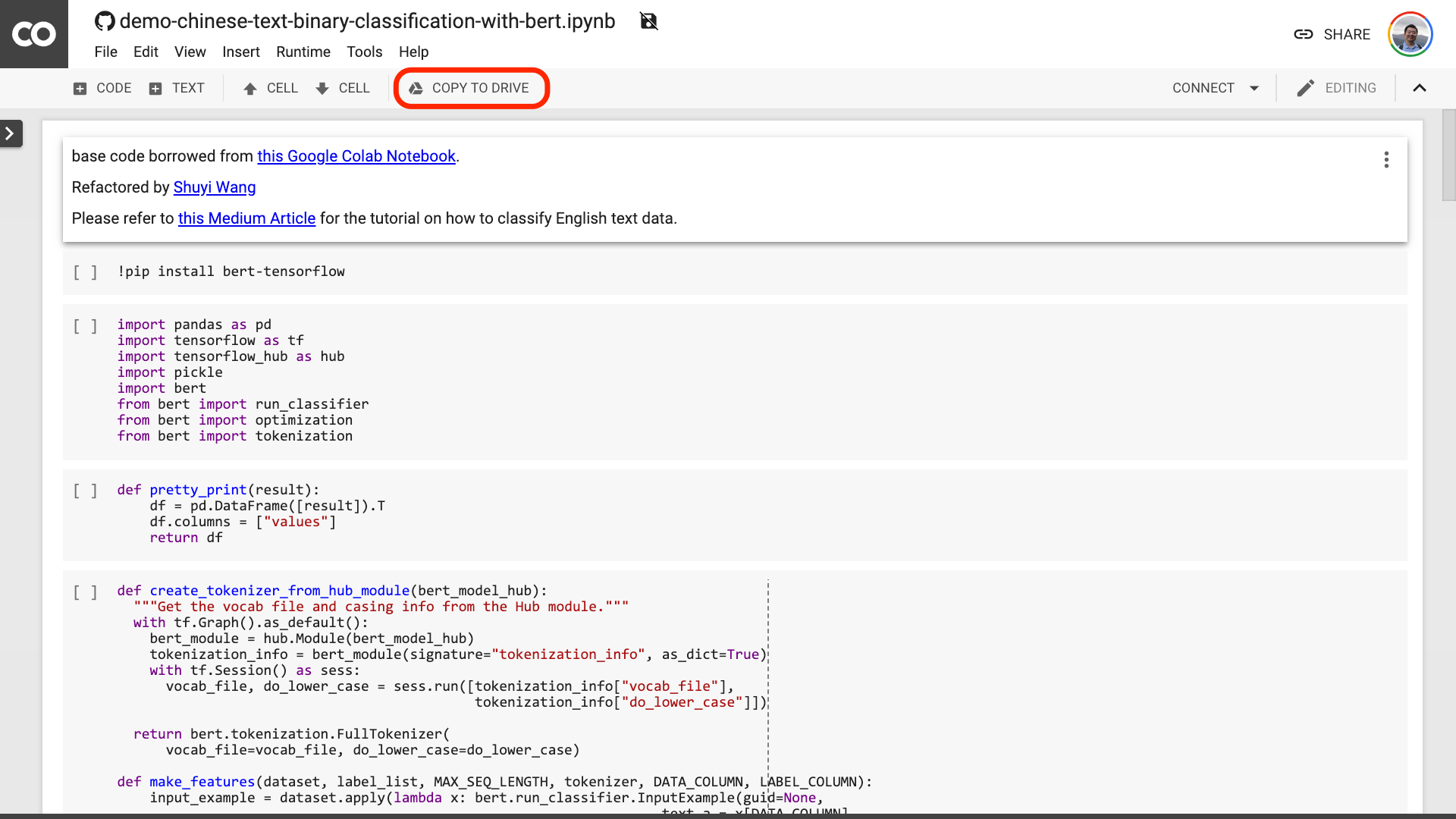
위의 빨간색 그림에 모인 "드라이브 복사"버튼을 클릭하는 것이 좋습니다. 이렇게하면 사용 및 검토를 위해 먼저 Google 드라이브에 저장됩니다.
이 작업이 완료되면 실제로 다음 세 단계 만 수행하면됩니다.
노트북을 저장 한 후. 자세히 보면 바보가 될 수 있습니다.
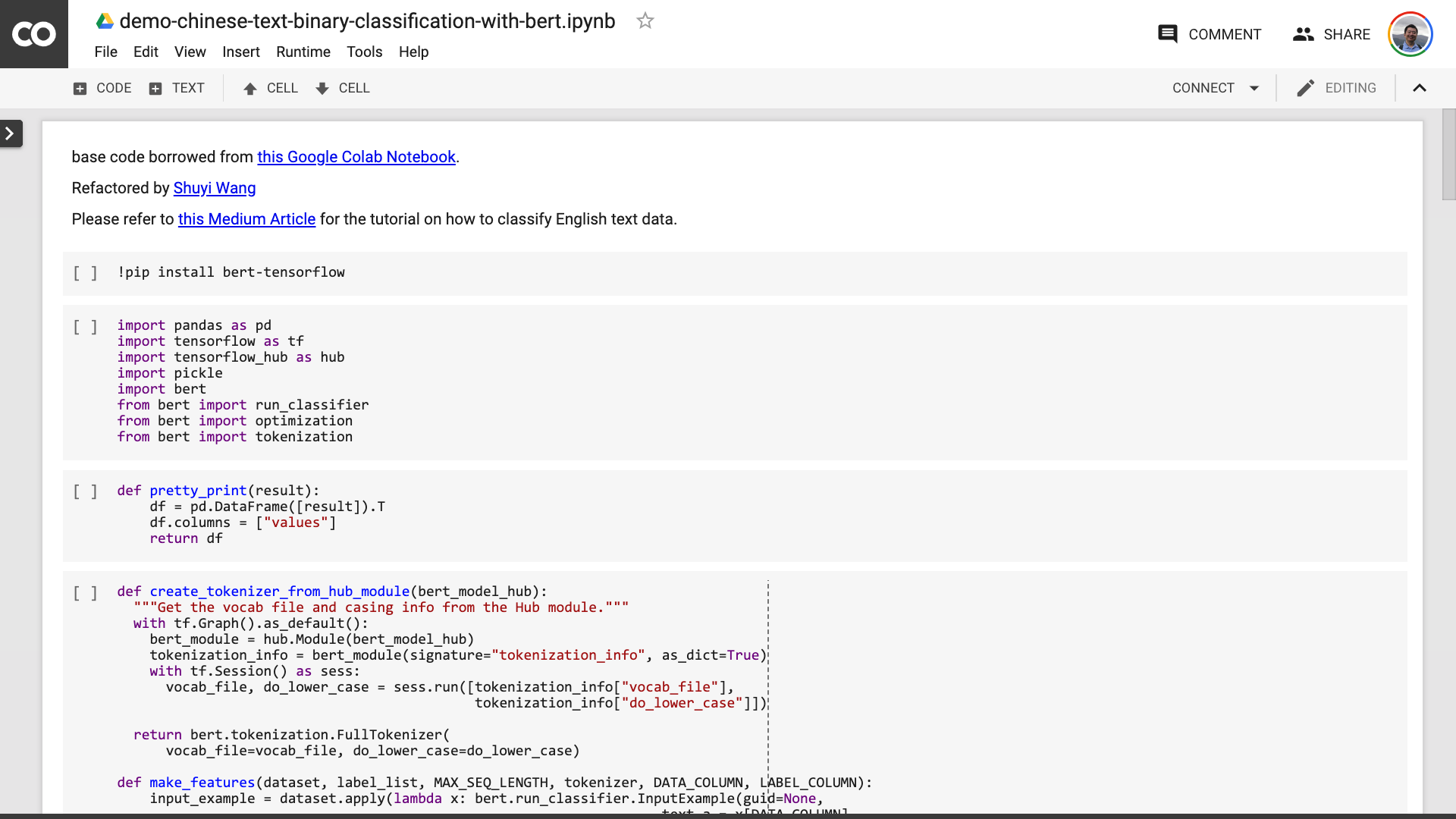
선생님, 당신은 거짓말을했습니다! 10 줄의 코드 라인은 동의합니다!
불안하지 마십시오 .
아래 그림에서 문장이 빨간색으로 연결되기 전에 아무것도 수정할 필요가 없습니다 .
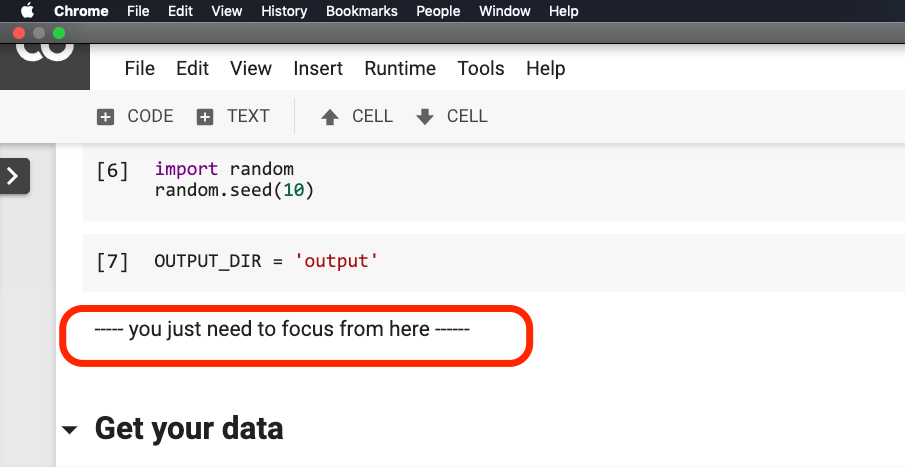
이 문장이있는 곳을 클릭 한 다음 다음 그림과 같이 메뉴에서 Run before 선택하십시오.
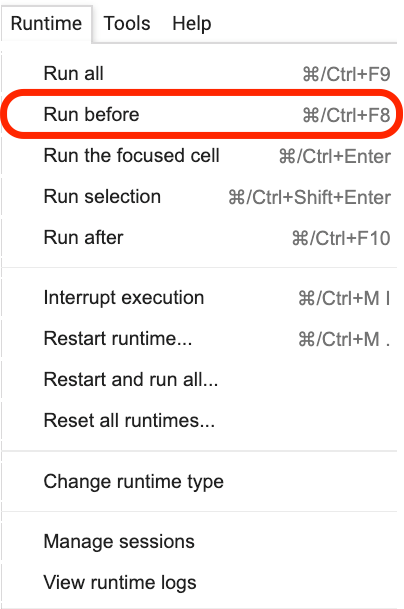
다음은 모두 중요한 링크, 초점입니다.
첫 번째 단계는 데이터를 준비하는 것입니다.
!w get https : // github . com / wshuyi / demo - chinese - text - binary - classification - with - bert / raw / master / dianping_train_test . pickle
with open ( "dianping_train_test.pickle" , 'rb' ) as f :
train , test = pickle . load ( f )여기에 사용 된 데이터에 익숙해야합니다. 케이터링 리뷰의 정서적 주석 데이터입니다. 나는 "파이썬 및 기계 학습으로 중국어 텍스트 감정 분류 모델을 훈련시키는 방법과"파이썬과 반복적 인 신경망을 사용하여 중국어 텍스트를 분류하는 방법은 무엇입니까? 》 그것을 사용했습니다. 그러나 시연의 편의를 위해 이번에는 피클 형식으로 출력하여 시연 Github Repo에 함께 다운로드 및 사용을 위해 함께 넣습니다.
교육 세트에는 1,600 개의 데이터가 포함되어 있습니다. 테스트 세트에는 400 개의 데이터가 포함되어 있습니다. 라벨에서 1은 긍정적 감정을 나타내고 0은 부정적인 감정을 나타냅니다.
다음 진술을 사용하여 훈련 세트를 셔플하고 주문을 방해합니다. 오버 피트팅을 피하기 위해.
train = train . sample ( len ( train ))훈련 세트의 헤드 내용을 살펴 보겠습니다.
train . head ()
나중에 자신의 데이터 세트를 교체하려면 형식에주의를 기울이십시오. 교육 및 시험 세트의 열 이름은 일관성이 있어야합니다.
두 번째 단계에서는 매개 변수를 설정합니다.
myparam = {
"DATA_COLUMN" : "comment" ,
"LABEL_COLUMN" : "sentiment" ,
"LEARNING_RATE" : 2e-5 ,
"NUM_TRAIN_EPOCHS" : 3 ,
"bert_model_hub" : "https://tfhub.dev/google/bert_chinese_L-12_H-768_A-12/1"
}처음 두 줄은 텍스트와 마크의 해당 열 이름을 명확하게 나타내는 것입니다.
세 번째 줄은 훈련 속도를 지정합니다. 원래 용지를 읽고 과잉 파라미터 조정 시도를 할 수 있습니다. 또는 단순히 기본값을 변경하지 않도록 유지할 수 있습니다.
4 행, 훈련 라운드 수를 지정합니다. 모든 데이터를 한 라운드로 실행하십시오. 여기에는 3 라운드가 사용됩니다.
마지막 줄은 사용하려는 Bert 미리 훈련 된 모델을 보여줍니다. 우리는 중국어 텍스트를 분류하려고 하므로이 중국의 미리 훈련 된 모델 주소를 사용합니다. 영어를 사용하려면 내 중간 블로그 게시물과 해당 영어 샘플 코드를 참조하십시오.
마지막 단계에서는 코드를 차례로 실행합니다.
result , estimator = run_on_dfs ( train , test , ** myparam )이 문장을 실행하는 데 시간이 좀 걸릴 수 있습니다. 정신적으로 준비하십시오. 이것은 데이터 볼륨 및 교육 라운드 설정과 관련이 있습니다.
이 과정 에서이 프로그램이 먼저 원래 중국어 텍스트를 Bert가 이해할 수있는 입력 데이터 형식으로 전환하는 데 도움이된다는 것을 알 수 있습니다.
아래 그림에서 텍스트가 빨간색으로 연결된 것을 보면 훈련 과정이 마침내 끝났음을 의미합니다.
그런 다음 테스트 결과를 인쇄 할 수 있습니다.
pretty_print ( result )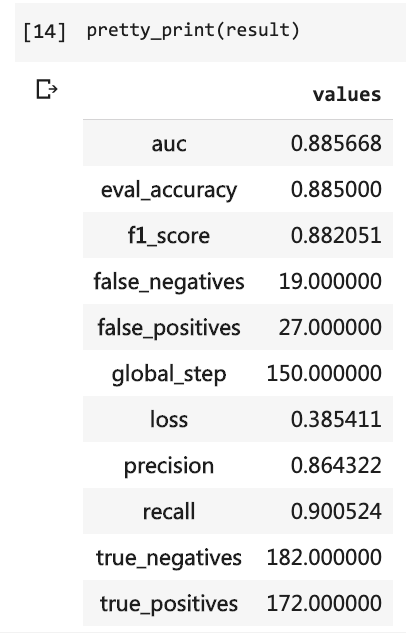
이전 자습서 (동일한 데이터 세트 사용)와 비교하십시오.
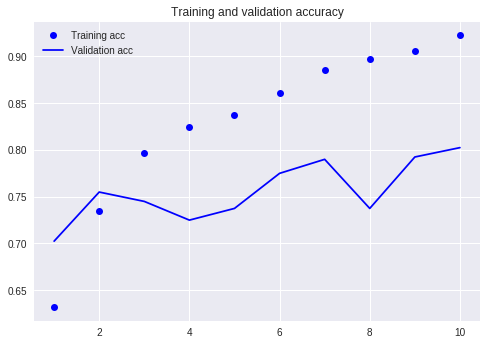
당시에는 너무 많은 코드 라인을 작성해야했고 10 라운드를 실행해야했지만 결과는 여전히 80%를 넘지 않았습니다. 이번에는 3 라운드 만 훈련했지만 정확도는 88%를 초과했습니다.
이러한 소규모 데이터 세트에서 이러한 정확도를 달성하는 것은 쉽지 않습니다.
버트 성능 이 분명합니다.
말하자면, 당신은 Bert를 사용하여 중국어 텍스트의 이진 분류 작업을 수행하는 방법을 배웠습니다. 나는 당신이 나만큼 행복하기를 바랍니다.
당신이 선임 파이썬 애호가라면, 부탁 해주세요.
이 라인 앞의 코드를 기억하십니까?
내가 그들을 포장하도록 도와 줄 수 있습니까? 이런 식으로 데모 코드는 더 짧고 간결하며 명확하며 사용하기 쉽습니다.
GitHub 프로젝트에서 코드를 제출하는 데 오신 것을 환영합니다. 이 튜토리얼이 도움이되면이 GitHub 프로젝트에 별을 추가하십시오. 감사해요!
행복한 딥 러닝!
다음 주제에 관심이있을 수도 있습니다. 링크를 클릭하여 볼 수 있습니다.
당신이 그것을 좋아한다면, 좋아하고 보상하십시오. 당신은 또한 Wechat에서 내 공식 계정 "Yushuzhilan"(Nkwangshuyi)을 팔로우 할 수 있습니다.
Python 및 Data Science에 관심이 있다면 내 일련의 튜토리얼 인덱스 게시물을 읽을 수도 있습니다. "데이터 과학을 효율적으로 시작하는 방법?》에 더 흥미로운 질문과 솔루션이 있습니다.
지식 행성 입구는 여기에 있습니다.


