demo chinese text binary classification with bert
1.0.0

No ano passado, fiquei muito empolgado assim que o modelo Bert do Google foi lançado.
Porque eu estava usando o Ulmfit do Fast.Ai para realizar tarefas de classificação de linguagem natural na época (também escrevi um artigo especial "Como usar o aprendizado de Python e transferência profunda para classificar textos?" Para compartilhar com você). Ulmfit e Bert são modelos de idiomas pré-treinados e têm muitas semelhanças.
O chamado modelo de linguagem usa uma estrutura de rede neural profunda para treinar em textos de linguagem maciços para entender os recursos comuns de um idioma.
O trabalho acima geralmente é possível apenas para a conclusão das grandes instituições. Porque o custo é muito grande.
Este custo inclui, mas não está limitado a:
O pré-treinamento significa que eles abrem esse resultado depois de serem treinados. Nós, pessoas comuns ou pequenas instituições, também podem emprestar os resultados e ajustar nossos próprios dados de texto em nossos campos especializados para que o modelo possa ter uma compreensão muito clara do texto neste campo especializado.
O chamado entendimento refere-se principalmente ao fato de você bloquear certas palavras, e o modelo pode adivinhar com mais precisão o que você está escondendo.
Mesmo se você reunir duas frases, o modelo poderá determinar se eles estão intimamente conectados relacionamentos contextuais.

Este "conhecimento" é útil?
Claro que existe.
Bert testou em várias tarefas de linguagem natural e muitos resultados superaram os jogadores humanos.

O BERT pode ajudar na solução de tarefas, é claro, também inclui classificação de texto, como classificação de emoção. Este também é o problema que estou estudando atualmente.
No entanto, para usar Bert, esperei muito tempo.
O código oficial do Google foi aberto. Até a implementação do Pytorch foi iterada para muitas rodadas.
Mas eu só preciso abrir a amostra que eles fornecem e me sinto tonto.
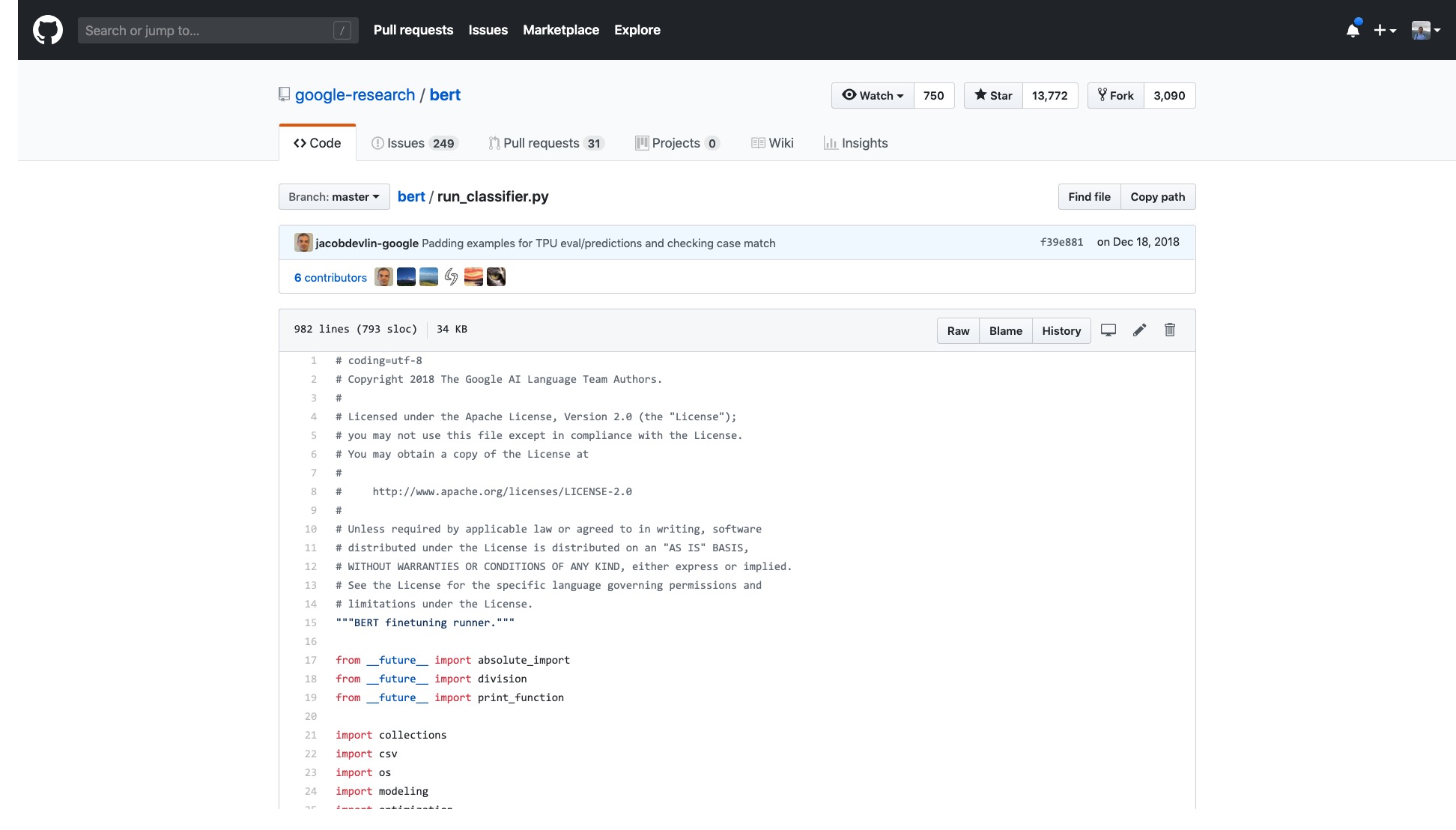
O número de linhas nesse código sozinho é muito assustador.
Além disso, vários processos de processamento de dados (processadores de dados) recebem o nome do nome do conjunto de dados. Meus dados não pertencem a nenhum dos itens acima, então qual devo usar?

Também existem inúmeras bandeiras (sinalizadores) que são inexplicavelmente problemáticas.

Vamos comparar como é a estrutura de sintaxe no Scikit-Learn ao executar tarefas de classificação.
from sklearn . datasets import load_iris
from sklearn import tree
iris = load_iris ()
clf = tree . DecisionTreeClassifier ()
clf = clf . fit ( iris . data , iris . target )Mesmo que a taxa de transferência de dados da classificação da imagem seja grande e exija muitas etapas, você pode fazê -lo facilmente com algumas linhas de código usando o Fast.ai.
!g it clone https : // github . com / wshuyi / demo - image - classification - fastai . git
from fastai . vision import *
path = Path ( "demo-image-classification-fastai/imgs/" )
data = ImageDataBunch . from_folder ( path , test = 'test' , size = 224 )
learn = cnn_learner ( data , models . resnet18 , metrics = accuracy )
learn . fit_one_cycle ( 1 )
interp = ClassificationInterpretation . from_learner ( learn )
interp . plot_top_losses ( 9 , figsize = ( 8 , 8 ))Não subestime essas linhas de código. Ele não apenas ajuda a treinar um classificador de imagem, mas também informa onde o modelo está prestando atenção nessas imagens com o maior erro de classificação.

Comparação, qual você acha que é a diferença entre o exemplo de Bert e o exemplo rápido.ai?
Eu acho que o último é para as pessoas usarem .
Eu sempre pensei que alguém refatoraria o código e escrevia um tutorial conciso.
Afinal, as tarefas de classificação de texto são um aplicativo comum de aprendizado de máquina. Existem muitos cenários de aplicação e também são adequados para os iniciantes aprenderem.
No entanto, eu simplesmente não esperei por esse tutorial.
Obviamente, durante esse período, também li aplicativos e tutoriais escritos por muitas pessoas.
Algumas pessoas podem converter um pedaço de texto de linguagem natural para a codificação de Bert. Terminou abruptamente.
Algumas pessoas apresentam cuidadosamente como usar o BERT nos conjuntos de dados oficiais fornecidos. Todas as modificações são feitas no script Python original. Todas as funções e parâmetros que não são usados são mantidos. Quanto à maneira como os outros reutilizam seus próprios conjuntos de dados? As pessoas não mencionaram isso.
Pensei em mastigar o código desde o início. Lembro -me de quando estava estudando para a pós -graduação, também li todos os códigos C das camadas TCP e IP na plataforma de simulação. Eu determinei a tarefa na minha frente, o que foi menos difícil.
Mas eu realmente não quero fazer isso. Sinto que sou mimada por estruturas de aprendizado de máquina Python, especialmente rápido.ai e scikit-learn.
Mais tarde, os desenvolvedores do Google trouxeram Bert para o Tensorflow Hub. Também escrevi uma amostra do Google Colab Notebook especificamente.
Fiquei tão feliz em ver essas notícias.
Eu tentei muitos outros modelos no Tensorflow Hub. É muito conveniente usar. E Google Colab que pratiquei Python com o Google Colab? 》 É apresentado a você no artigo ", que é um exercício de aprendizado profundo e muito bom, pensei que as duas espadas poderiam ser combinadas, e desta vez eu poderia lidar com minhas próprias tarefas com algumas linhas de código.
Vamos esperar.
Quando você realmente o abrir, você ainda se concentrará nos dados de amostra.
O que os usuários comuns precisam? Uma interface é necessária.
Você me diz as especificações padrão que você inseriu e depois me diz quais podem ser os resultados. Conecte e jogue, e deixe, afinal.
Uma tarefa de classificação de texto originalmente forneceu um conjunto de treinamento e um conjunto de testes, dizendo a rapidez com que as rodadas de treinamento são e, em seguida, me dizendo a taxa de precisão e os resultados?
Quanto a me pedir para ler centenas de linhas de código para uma tarefa tão simples e descobrir onde alterá -lo você mesmo?
Felizmente, com este exemplo como base, é melhor do que nada.
Peguei minha paciência e resolvi isso.
Para afirmar, não fiz nenhuma alteração importante no código original.
Portanto, se você não explicar claramente, será suspeito de plágio e será desprezado.
Esse tipo de organização não é tecnicamente difícil para pessoas que sabem usar o Python.
Mas por causa disso, fico com raiva. Isso é difícil de fazer? Por que o escritor de amostra de Bert do Google se recusou a fazer isso?
Por que há uma mudança tão grande do Tensorflow 1.0 para 2.0? Não é porque 2.0 é para as pessoas usarem?
Você não tornará a interface refrescante e simples, seus concorrentes (turicreados e fast.ai) farão isso, e eles o fazem muito bem. Somente quando não consigo me sentar, posso estar disposto a subestimar o nobre e desenvolver uma interface útil para pessoas comuns.
Uma lição! Por que você não o absorve?
Fornecerei a você uma amostra de notebook do Google Colab que você pode substituir facilmente em seu próprio conjunto de dados para executar. Você precisa entender (incluindo modificar) o código, não mais que 10 linhas .
Eu testei uma tarefa de classificação de texto em inglês e funcionou muito bem. Por isso, escrevi um blog médio, que foi imediatamente incluído na coluna de ciência de dados.
O editor de colunas de ciência de dados me enviou uma mensagem privada dizendo:
Muito interessante, eu gosto disso, considerando que a implementação padrão não é muito amigável ao desenvolvedor, com certeza.
Havia um leitor que realmente deu este artigo 50 curtidas (palmas) seguidas, e fiquei surpreso.

Parece que esse ponto de dor por muito tempo não é apenas eu.
Estima -se que as tarefas de classificação chinesa possam ser encontradas mais em sua pesquisa. Então, eu simplesmente fiz outro exemplo de classificação de texto chinês e escrevi este tutorial e compartilhei com você.
Vamos começar.
Clique neste link para visualizar o arquivo de notebook Ipython que fiz para você no Github.
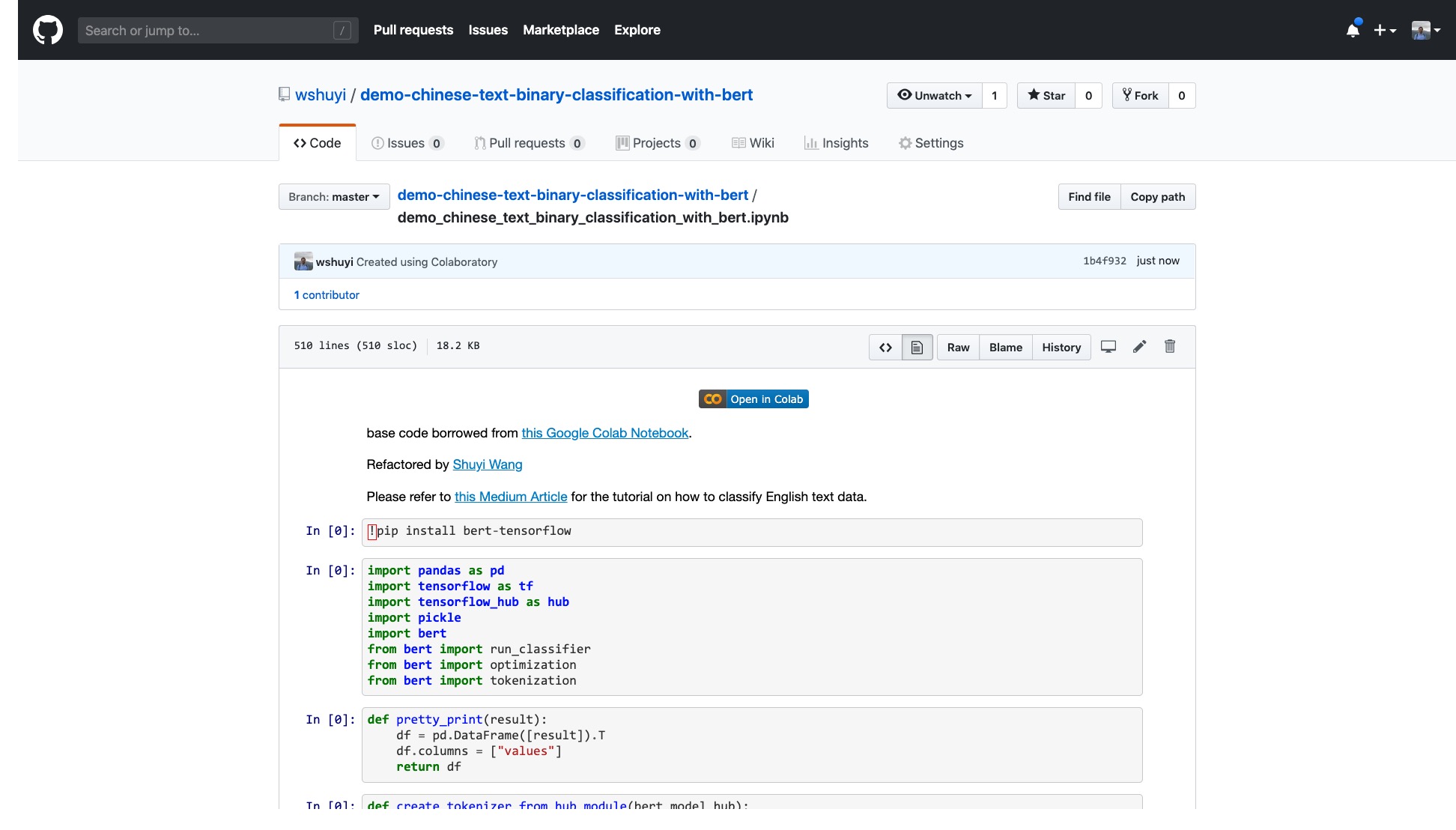
Na parte superior do notebook, há um botão "aberto em colab" muito óbvio. Clique nele e o Google Colab ligará automaticamente e carregará este notebook.
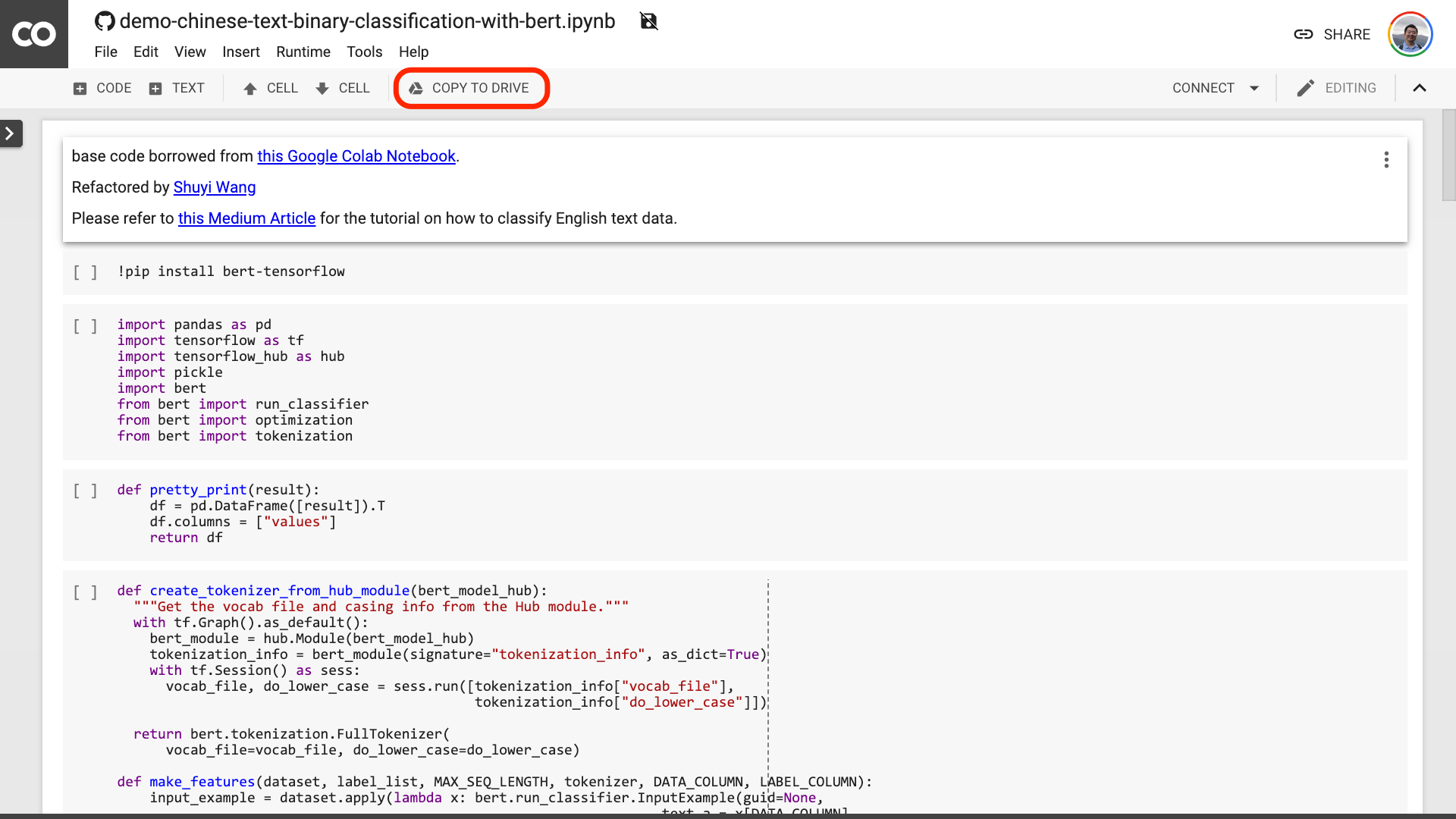
Eu sugiro que você clique no botão "Copiar para acionar" circulado na imagem vermelha acima. Isso o salvará em seu próprio Google Drive primeiro para uso e revisão.
Depois disso, você realmente só precisa executar as três etapas a seguir:
Depois de salvar o caderno. Se você olhar de perto, poderá se sentir enganado.
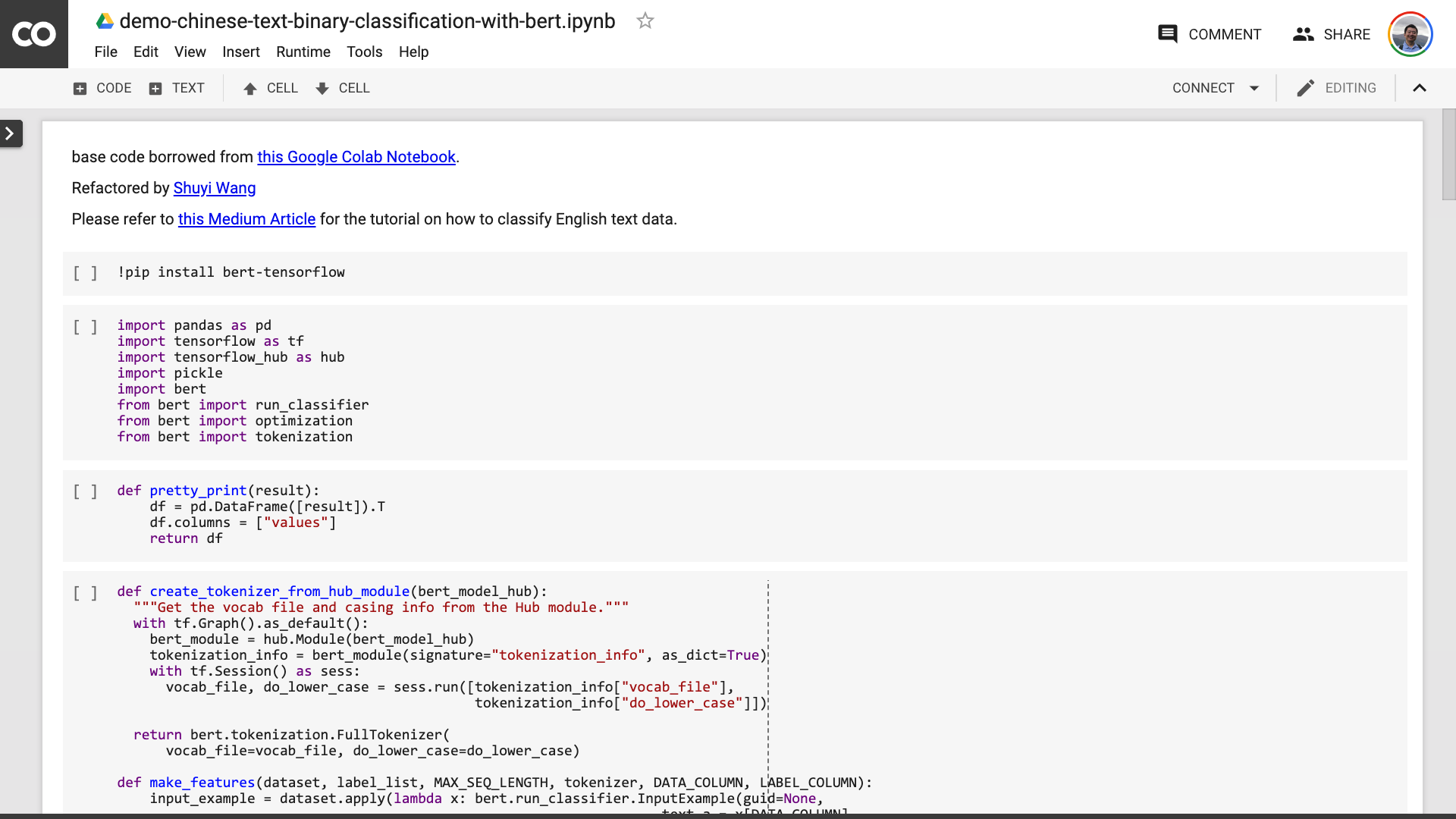
Professor, você mentiu! É concordado que não mais que 10 linhas de código!
Não fique ansioso .
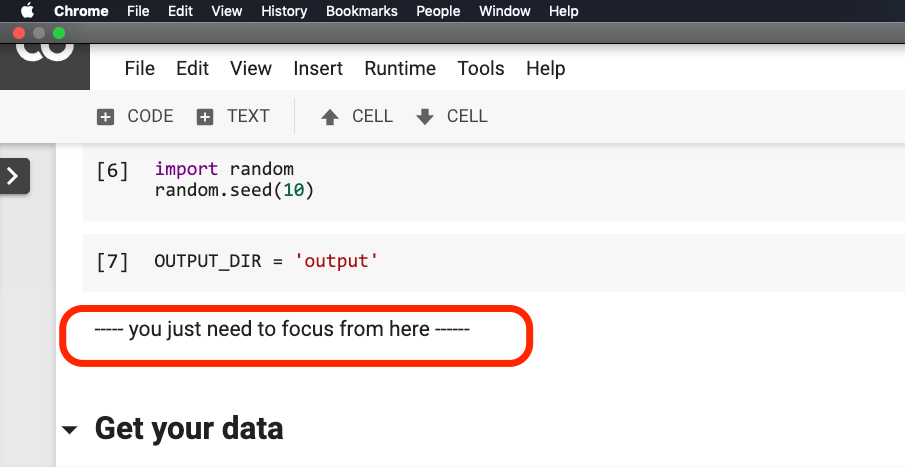
Você não precisa modificar nada antes da frase circular no vermelho na figura abaixo.
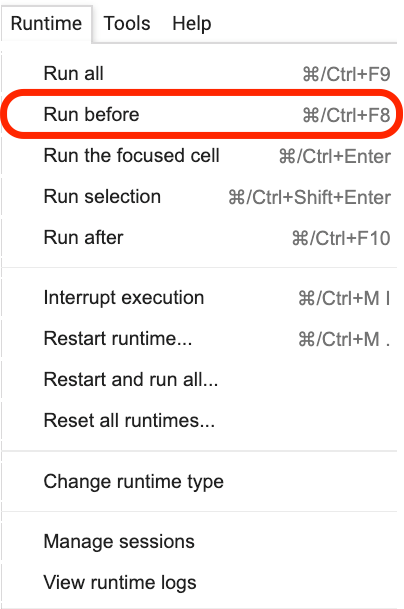
Clique onde esta frase está localizada e selecione Run before no menu, como mostrado na figura a seguir.
A seguir, são todos os links importantes, foco.
O primeiro passo é preparar os dados.
!w get https : // github . com / wshuyi / demo - chinese - text - binary - classification - with - bert / raw / master / dianping_train_test . pickle
with open ( "dianping_train_test.pickle" , 'rb' ) as f :
train , test = pickle . load ( f )Você deve estar familiarizado com os dados usados aqui. São os dados de anotação emocional das revisões de catering. Estou no modelo de classificação de emoção de texto chinês com python e aprendizado de máquina?》 E "Como usar as redes neurais Python e recorrentes para classificar textos chineses? 》 Usou. No entanto, para a conveniência da demonstração, eu a produzi como formato de picles desta vez e o coloco no repo do GitHub de demonstração para o seu download e uso.
O conjunto de treinamento contém 1.600 dados; O conjunto de testes contém 400 dados. No rótulo, 1 representa emoções positivas e 0 representa emoções negativas.
Usando a seguinte declaração, embaralhamos o conjunto de treinamento e interrompemos o pedido. Para evitar o excesso de ajuste.
train = train . sample ( len ( train ))Vamos dar uma olhada no conteúdo da cabeça do nosso conjunto de treinamento.
train . head ()
Se você deseja substituir seu próprio conjunto de dados posteriormente, preste atenção ao formato. Os nomes das colunas dos conjuntos de treinamento e teste devem ser consistentes.
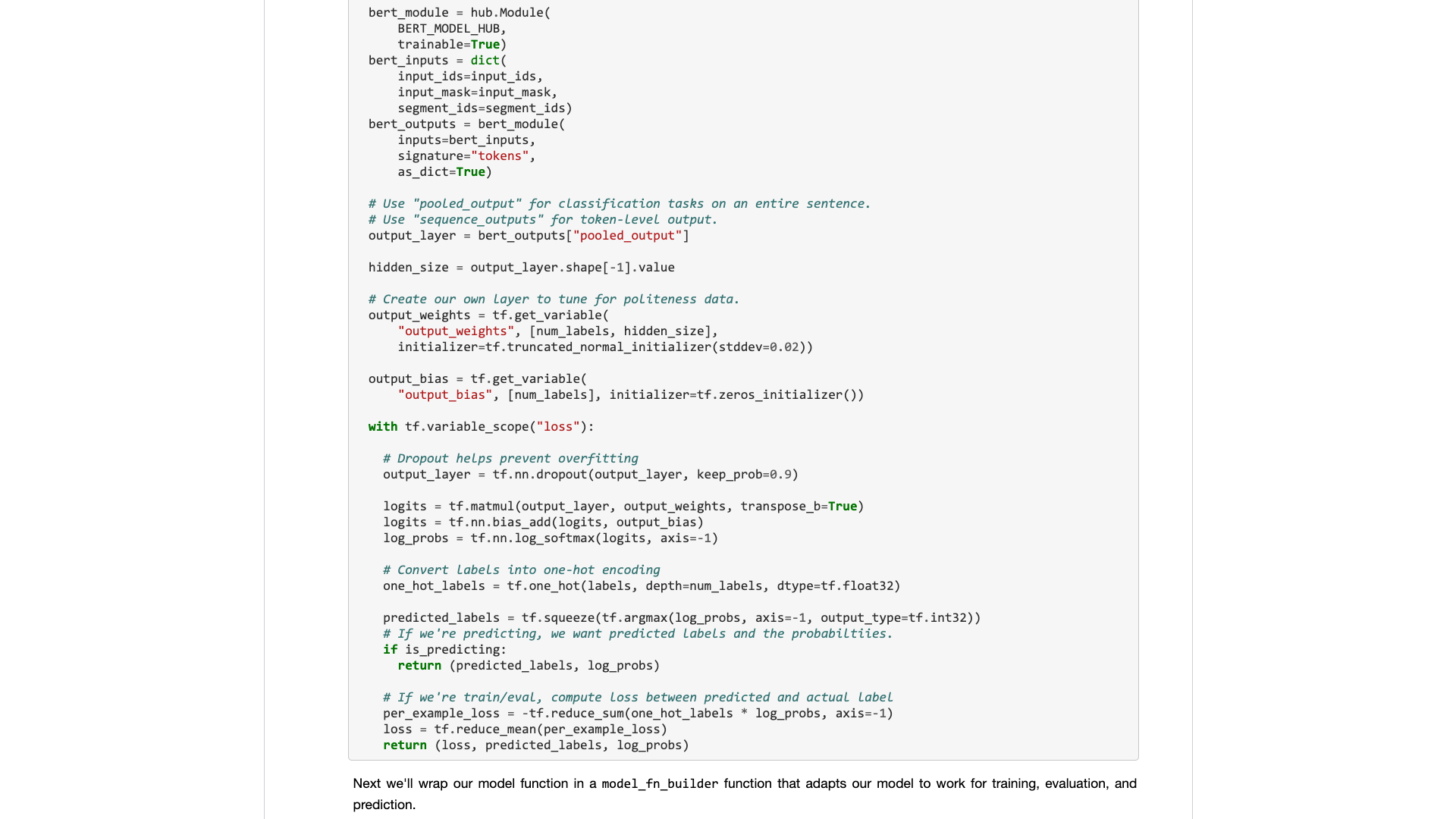
Na segunda etapa, definiremos os parâmetros.
myparam = {
"DATA_COLUMN" : "comment" ,
"LABEL_COLUMN" : "sentiment" ,
"LEARNING_RATE" : 2e-5 ,
"NUM_TRAIN_EPOCHS" : 3 ,
"bert_model_hub" : "https://tfhub.dev/google/bert_chinese_L-12_H-768_A-12/1"
}As duas primeiras linhas são indicar claramente os nomes de colunas correspondentes do texto e das marcas.
A terceira linha especifica a taxa de treinamento. Você pode ler o papel original para fazer uma tentativa de ajuste de hiperparâmetro. Ou você pode simplesmente manter o valor padrão inalterado.
Linha 4, especifique o número de rodadas de treinamento. Execute todos os dados em uma rodada. 3 rodadas são usadas aqui.
A última linha mostra o modelo pré-treinado BERT que você deseja usar. Queremos classificar o texto chinês, por isso usamos este endereço de modelo pré-treinado chinês. Se você deseja usar o inglês, pode consultar a minha postagem de blog médio e o código de amostra em inglês correspondente.
Na última etapa, apenas executamos o código por sua vez.
result , estimator = run_on_dfs ( train , test , ** myparam )Observe que pode levar algum tempo para executar esta frase. Estar mentalmente preparado. Isso está relacionado ao volume de dados e às configurações da rodada de treinamento.
Nesse processo, você pode ver que o programa primeiro ajuda a transformar o texto chinês original em um formato de dados de entrada que Bert pode entender.
Quando você vê o texto circulado no vermelho na figura abaixo, significa que o processo de treinamento finalmente acabou.
Então você pode imprimir os resultados do teste.
pretty_print ( result )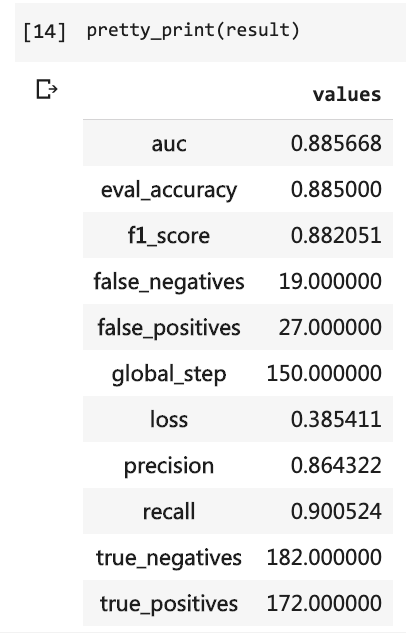
Compare com o nosso tutorial anterior (usando o mesmo conjunto de dados).
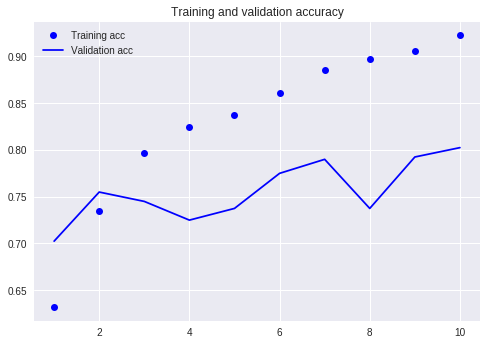
Naquela época, tive que escrever tantas linhas de código e tive que executar 10 rodadas, mas o resultado ainda não era superior a 80%. Desta vez, embora eu tenha treinado apenas por 3 rodadas, a taxa de precisão excedeu 88%.
Não é fácil obter essa precisão em um conjunto de dados de pequena escala.
O desempenho de Bert é evidente.
Dito isto, você aprendeu a usar Bert para realizar a tarefa de classificação binária do texto chinês. Espero que você seja tão feliz quanto eu.
Se você é um entusiasta sênior do Python, faça -me um favor.
Lembra do código antes desta linha?
Você pode me ajudar a embalá -los? Dessa forma, nosso código de demonstração pode ser mais curto, mais conciso, mais claro e mais fácil de usar.
Bem -vindo a enviar seu código em nosso projeto GitHub. Se você achar útil este tutorial, adicione estrelas a este projeto do GitHub. Obrigado!
Happy Deep Learning!
Você também pode estar interessado nos seguintes tópicos. Clique no link para visualizá -lo.
Se você gosta, por favor, goste e recompense. Você também pode seguir e superar minha conta oficial "Yushuzhilan" (Nkwangshuyi) no WeChat.
Se você estiver interessado em Python e Science de dados, também pode ler minha série de postagens de índices tutoriais "Como começar com a ciência de dados com eficiência?》, Há perguntas e soluções mais interessantes nele.
A entrada do planeta de conhecimento está aqui:


