demo chinese text binary classification with bert
1.0.0

Letztes Jahr war ich sehr aufgeregt, sobald das Bert -Modell von Google veröffentlicht wurde.
Weil ich Fast.ais Ulmfit zu diesem Zeitpunkt für natürliche Sprachklassifizierungsaufgaben verwendet habe (ich habe auch einen speziellen Artikel "Wie man Python und Deep Transfer Learning verwendet, um Texte zu klassifizieren?", Um mit Ihnen zu teilen). Ulmfit und Bert sind beide vorgeschriebene Sprachmodelle und haben viele Ähnlichkeiten.
Das sogenannte Sprachmodell verwendet eine tiefe neuronale Netzwerkstruktur, um in massiven Sprachtexten zu trainieren, um die gemeinsamen Merkmale einer Sprache zu erfassen.
Die obigen Arbeiten sind oft nur für große Institutionen möglich. Weil die Kosten zu groß sind.
Diese Kosten beinhalten, sind aber nicht beschränkt auf:
Vorausbildung bedeutet, dass sie dieses Ergebnis nach dem Training öffnen. Wir haben gewöhnliche Personen oder kleine Institutionen auch die Ergebnisse ausleihen und unsere eigenen Textdaten auf unseren speziellen Feldern fein abteilen , damit das Modell ein klares Verständnis des Textes in diesem speziellen Bereich haben kann.
Das sogenannte Verständnis bezieht sich hauptsächlich auf die Tatsache, dass Sie bestimmte Wörter blockieren, und das Modell kann genauer erraten, was Sie verstecken.
Selbst wenn Sie zwei Sätze zusammenfügen, kann das Modell bestimmen, ob es sich um eng verbundene kontextbezogene Beziehungen handelt.

Ist das "Wissen" nützlich?
Natürlich gibt es.
Bert wurde an mehreren natürlichen Sprachaufgaben getestet, und viele Ergebnisse haben menschliche Spieler übertroffen.

Bert kann dazu beitragen, Aufgaben zu lösen, auch bei der Klassifizierung der Textklassifizierung wie der Emotionsklassifizierung. Dies ist auch das Problem, das ich gerade studiere.
Um Bert zu verwenden, habe ich jedoch lange gewartet.
Der offizielle Google -Code war geöffnet. Sogar die Implementierung auf Pytorch wurde für viele Runden iteriert.
Aber ich muss nur die Probe öffnen, die sie zur Verfügung stellen, und ich fühle mich schwindelig.
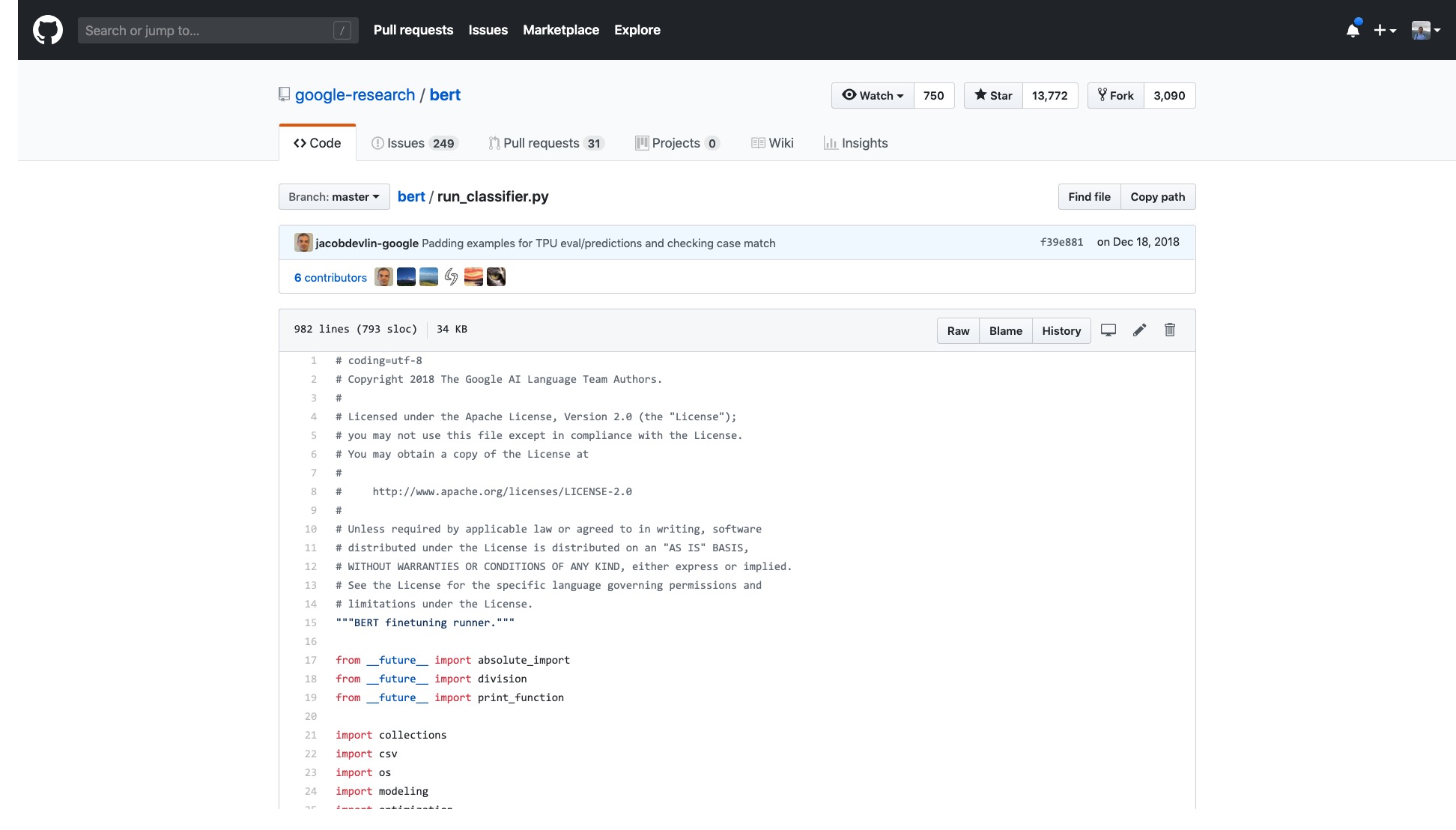
Die Anzahl der Zeilen in diesem Code allein ist sehr beängstigend.
Darüber hinaus werden eine Reihe von Datenverarbeitungsprozessen (Datenprozessoren) nach dem Datensatznamen benannt. Meine Daten gehören nicht zu einem der oben genannten. Welches soll ich verwenden?

Es gibt auch unzählige Flaggen (Flags), die unerklärlicherweise problematisch sind.

Vergleichen wir, wie die Syntaxstruktur in Scikit-Learn bei Klassifizierungsaufgaben aussieht.
from sklearn . datasets import load_iris
from sklearn import tree
iris = load_iris ()
clf = tree . DecisionTreeClassifier ()
clf = clf . fit ( iris . data , iris . target )Selbst wenn der Datendurchsatz der Bildklassifizierung groß ist und viele Schritte erfordert, können Sie dies problemlos mit einigen Codezeilen mit Fast.ai tun.
!g it clone https : // github . com / wshuyi / demo - image - classification - fastai . git
from fastai . vision import *
path = Path ( "demo-image-classification-fastai/imgs/" )
data = ImageDataBunch . from_folder ( path , test = 'test' , size = 224 )
learn = cnn_learner ( data , models . resnet18 , metrics = accuracy )
learn . fit_one_cycle ( 1 )
interp = ClassificationInterpretation . from_learner ( learn )
interp . plot_top_losses ( 9 , figsize = ( 8 , 8 ))Unterschätzen Sie diese Codezeilen nicht. Es hilft Ihnen nicht nur, einen Image -Klassifizierer zu trainieren, sondern auch sagt, wo das Modell in diesen Bildern mit dem höchsten Klassifizierungsfehler achtet.

Vergleich, was ist Ihrer Meinung nach der Unterschied zwischen Bert -Beispiel und Fast.ai -Beispiel?
Ich denke, letztere sind für Menschen, die sie verwenden können .
Ich dachte immer, dass jemand den Code neu umsetzt und ein prägnantes Tutorial schreibt.
Schließlich sind Textklassifizierungsaufgaben eine gemeinsame Anwendung für maschinelles Lernen. Es gibt viele Anwendungsszenarien und eignen sich auch für Anfänger zum Lernen.
Ich habe jedoch einfach nicht auf ein solches Tutorial gewartet.
Natürlich habe ich in dieser Zeit auch Bewerbungen und Tutorials gelesen, die von vielen Personen geschrieben wurden.
Einige Leute können einen Text mit natürlichen Sprachtext in Bert Coding umwandeln. Es endete abrupt.
Einige Leute stellen sorgfältig vor, wie Bert die offiziellen Datensätze verwendet werden. Alle Modifikationen finden Sie im ursprünglichen Python -Skript. Alle Funktionen und Parameter, die überhaupt nicht verwendet werden, werden beibehalten. Wie andere ihre eigenen Datensätze wiederverwenden? Die Leute haben das überhaupt nicht erwähnt.
Ich habe von Anfang an darüber nachgedacht, den Code zu kauen. Ich erinnere mich, als ich für die Graduiertenschule studierte, habe ich auch alle C -Codes der TCP- und IP -Ebenen auf der Simulationsplattform gelesen. Ich habe die Aufgabe vor mir festgestellt, was weniger schwierig war.
Aber ich will es wirklich nicht tun. Ich fühle mich von Python maschinellem Lernrahmen verwöhnt, insbesondere von Fast.ai und Scikit-Learn.
Später brachten Google -Entwickler Bert in den TensorFlow Hub. Ich habe auch speziell ein Google Colab -Notebook -Beispiel geschrieben.
Ich war so froh, diese Nachrichten zu sehen.
Ich habe viele andere Modelle auf TensorFlow Hub ausprobiert. Es ist sehr bequem zu bedienen. Und Google Colab habe ich Python mit Google Colab geübt? 》 Wird Ihnen in dem Artikel vorgestellt ", einer sehr guten Python Deep Learning -Übung und Demonstrationsumgebung. Ich dachte, dass die beiden Schwerter kombiniert werden könnten, und diesmal konnte ich meine eigenen Aufgaben mit ein paar Codezeilen erledigen.
Warten wir.
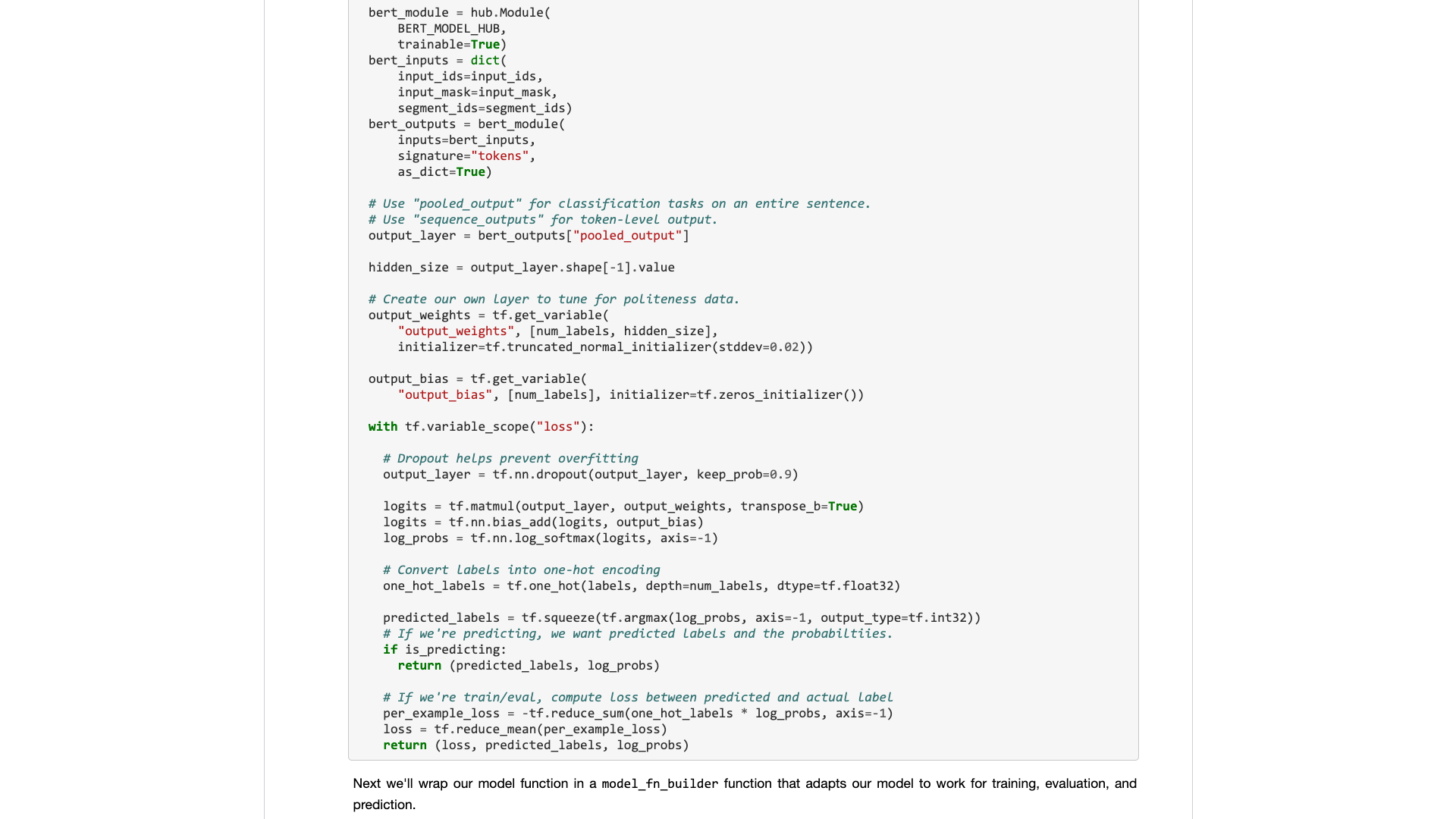
Wenn Sie es wirklich öffnen, werden Sie sich weiterhin auf die Beispieldaten konzentrieren.
Was brauchen gewöhnliche Benutzer? Eine Schnittstelle ist erforderlich.
Sie sagen mir die Standardspezifikationen, die Sie eingegeben haben, und sagen mir dann, wie die Ergebnisse aussehen können. Stecker und spielen und doch gehen.
Eine Textklassifizierungsaufgabe gab Ihnen ursprünglich einen Trainingssatz und einen Testsatz, in dem Sie mitgeteilt haben, wie schnell die Trainingsrunden sind, und dann die Genauigkeitsrate und die Ergebnisse mitzuteilen?
Was mich bittet, Hunderte von Codezeilen für eine so einfache Aufgabe zu lesen und herauszufinden, wo ich es selbst ändern soll?
Glücklicherweise ist es mit diesem Beispiel als Stiftung besser als nichts.
Ich nahm meine Geduld und sortierte sie aus.
Um zu sagen, habe ich keine wesentlichen Änderungen am ursprünglichen Code vorgenommen.
Wenn Sie es also nicht klar erklären, werden Sie des Plagiats verdächtigt und werden verachtet.
Diese Art von Organisation ist für Menschen, die wissen, wie man Python benutzt, technisch nicht schwierig.
Aber deshalb werde ich wütend. Ist das schwer zu tun? Warum hat sich der Bert -Beispielschreiber von Google geweigert, dies zu tun?
Warum gibt es eine so große Veränderung von TensorFlow 1.0 auf 2.0? Liegt es nicht daran, dass 2.0 für Menschen verwendet werden kann?
Sie werden die Schnittstelle nicht erfrischend und einfach machen, Ihre Konkurrenten (Turicreate und Fast.ai) werden es tun, und sie machen es sehr gut. Nur wenn ich nicht still sitzen kann, kann ich bereit sein, den Adligen herunterzuspielen und eine nützliche Schnittstelle für normale Menschen zu entwickeln.
Eine Lektion! Warum nehmen Sie es nicht auf?
Ich werde Ihnen ein Google Colab -Notebook -Beispiel zur Verfügung stellen, das Sie auf Ihrem eigenen Datensatz problemlos ersetzen können. Sie müssen den Code nicht mehr als 10 Zeilen verstehen (einschließlich Änderungen).
Ich habe zuerst eine englische Textklassifizierungsaufgabe getestet und es hat sehr gut funktioniert. Also schrieb ich einen mittleren Blog, der sofort in die Spalte in Richtung Data Science aufgenommen wurde.
Der Column -Editor in Richtung Data Science hat mir eine private Nachricht gesendet, in der es heißt:
Sehr interessant, ich mag dies, wenn man bedenkt, dass die Standardimplementierung mit Sicherheit nicht sehr entwicklerfreundlich ist.
Es gab einen Leser, der diesen Artikel tatsächlich 50 Likes (Klatschen) hintereinander gab, und ich war fassungslos.

Es scheint, dass dieser lang tragende Schmerzpunkt nicht nur ich ist.
Es wird geschätzt, dass die chinesischen Klassifizierungsaufgaben in Ihrer Forschung mehr auftreten können. Also habe ich einfach ein weiteres Beispiel für die chinesische Textklassifizierung gemacht und dieses Tutorial geschrieben und es mit Ihnen geteilt.
Fangen wir an.
Bitte klicken Sie auf diesen Link, um die ipython -Notebook -Datei anzuzeigen, die ich für Sie auf GitHub erstellt habe.
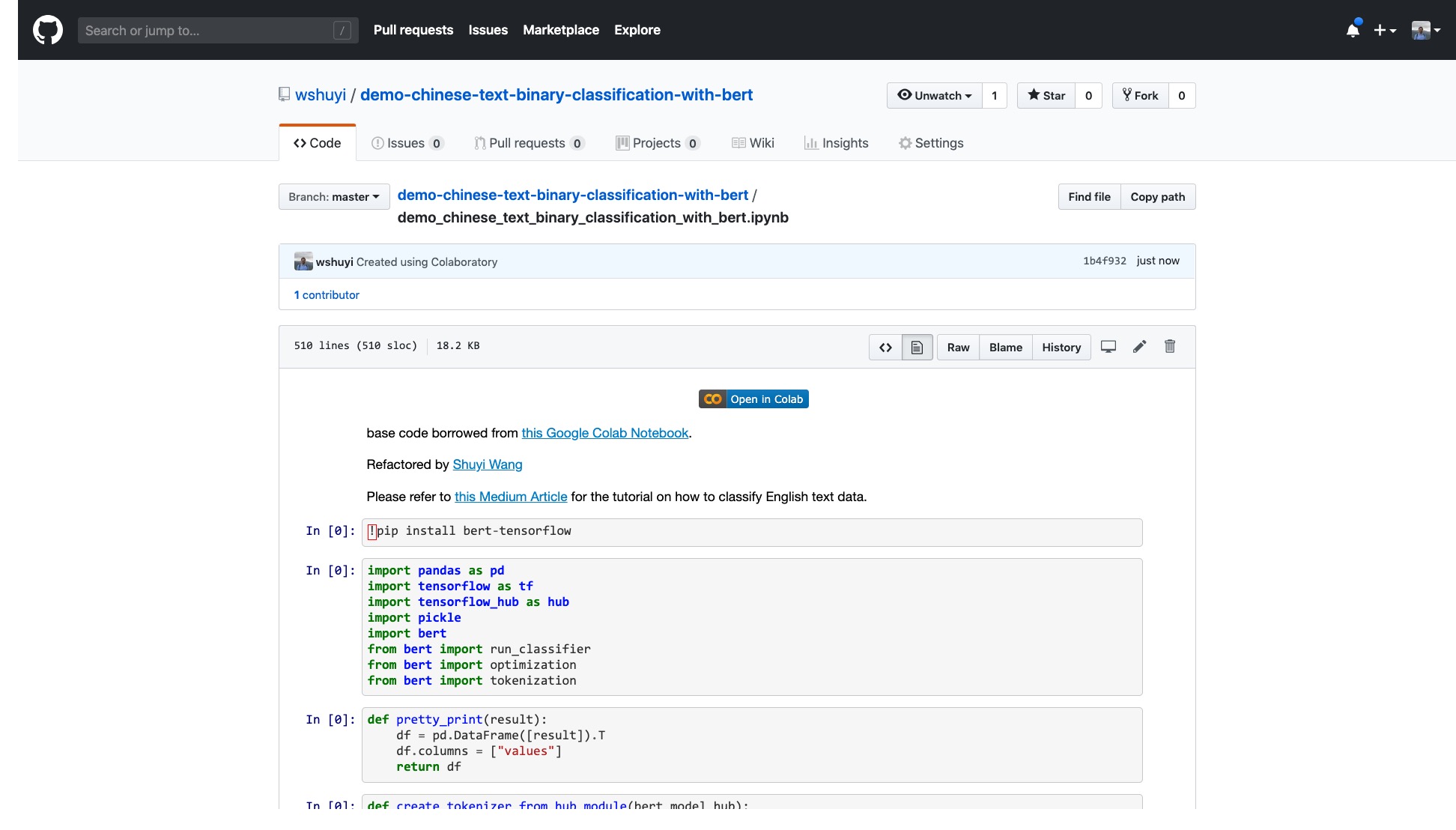
Oben im Notizbuch befindet sich eine sehr offensichtliche "Open in Colab" -Taste. Klicken Sie darauf und Google Colab wird automatisch eingeschaltet und dieses Notebook geladen.
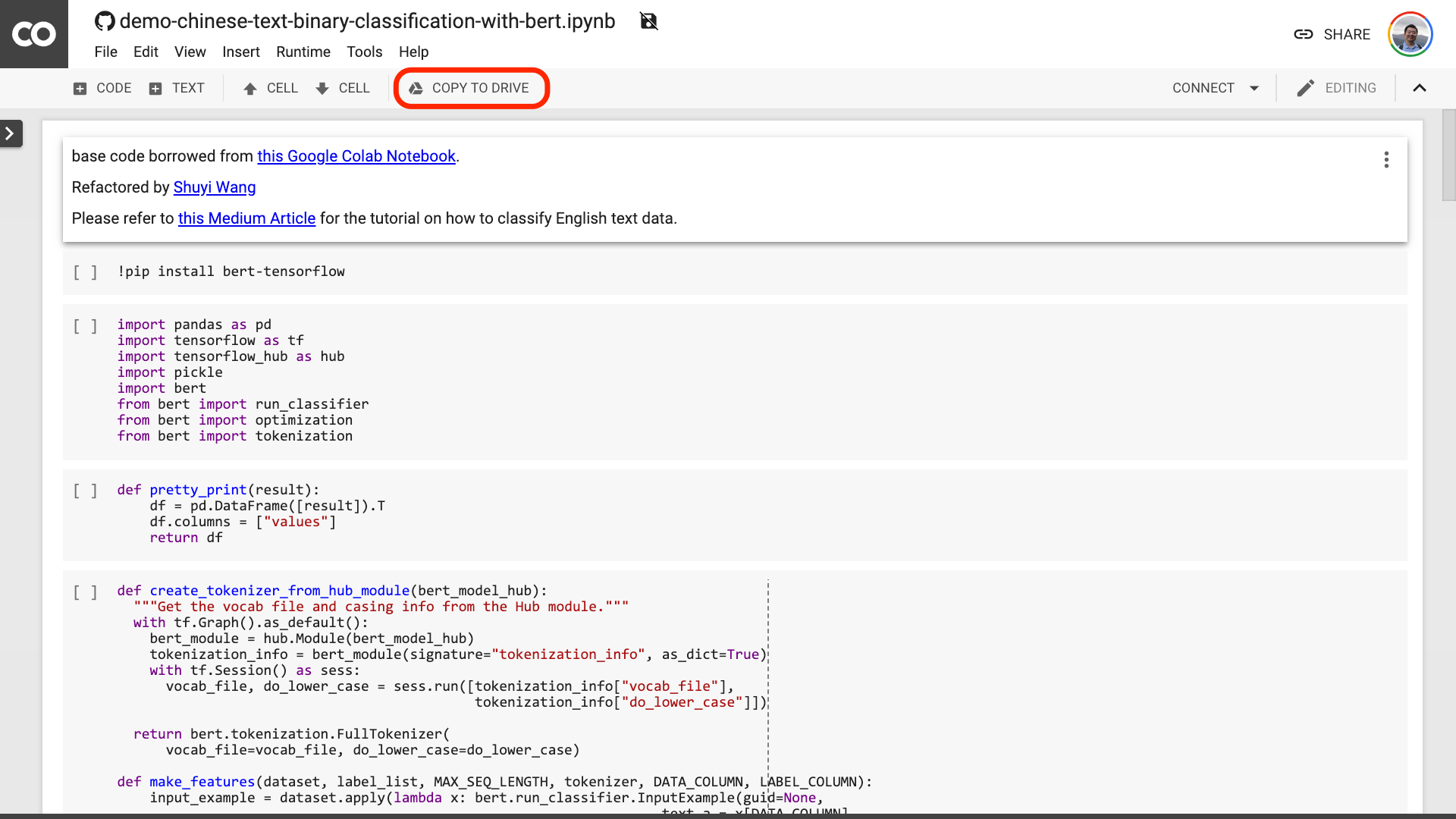
Ich schlage vor, Sie klicken auf die Schaltfläche "zum Laufwerk kopieren", die im obigen roten Bild eingekreist sind. Dies speichert es zuerst in Ihrem eigenen Google Drive, um sie zu verwenden und zu überprüfen.
Nachdem dies erledigt ist, müssen Sie tatsächlich nur die folgenden drei Schritte ausführen:
Nachdem Sie das Notizbuch gespeichert haben. Wenn Sie genau hinschauen, fühlen Sie sich möglicherweise täuschen.
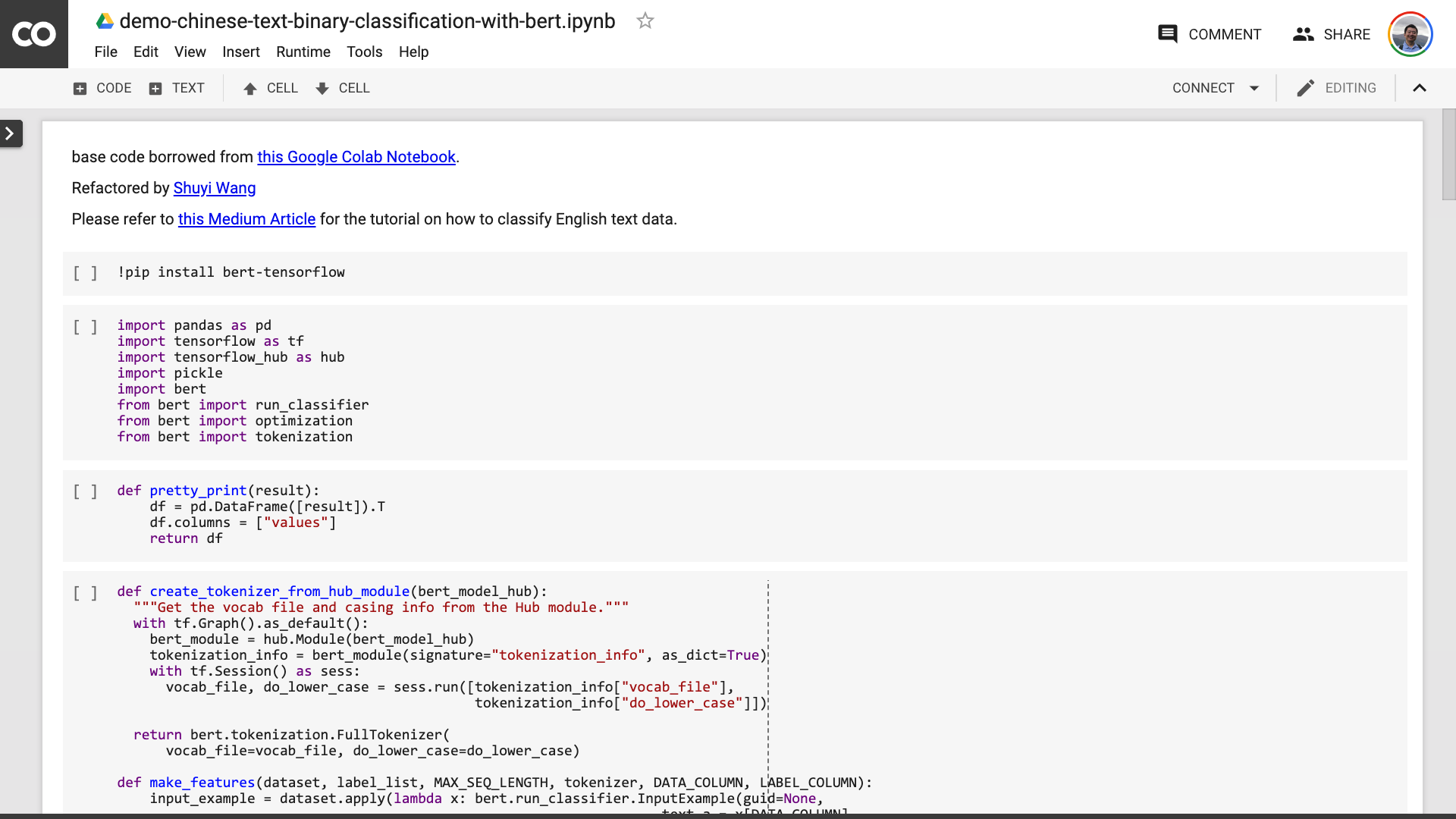
Lehrer, du hast gelogen! Es ist vereinbart, dass nicht mehr als 10 Codezeilen!
Sei nicht besorgt .
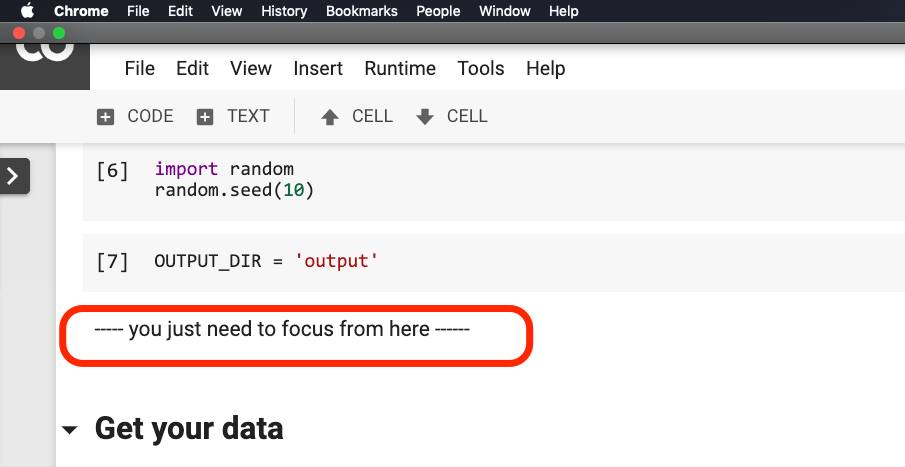
Sie müssen nichts ändern, bevor der Satz im Bild unten im Rot eingekreist ist.
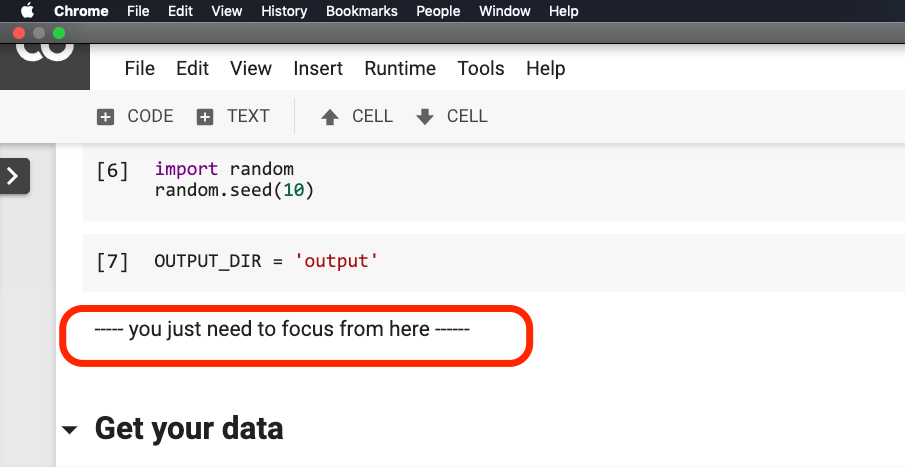
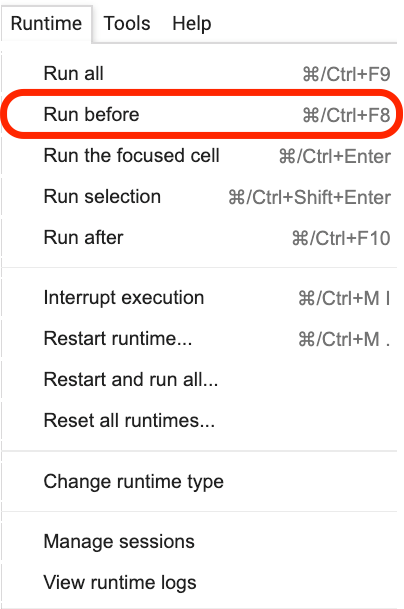
Bitte klicken Sie auf dort, wo sich dieser Satz befindet, und wählen Sie dann im Menü Run before , wie in der folgenden Abbildung gezeigt.
Das Folgende sind alles wichtige Links, Focus.
Der erste Schritt besteht darin, die Daten vorzubereiten.
!w get https : // github . com / wshuyi / demo - chinese - text - binary - classification - with - bert / raw / master / dianping_train_test . pickle
with open ( "dianping_train_test.pickle" , 'rb' ) as f :
train , test = pickle . load ( f )Sie sollten mit den hier verwendeten Daten vertraut sein. Es sind die emotionalen Annotationsdaten von Catering -Bewertungen. Ich bin in "Wie trainiere ich chinesisches Text -Emotionsklassifizierungsmodell mit Python und maschinellem Lernen? 》 Hat es benutzt. Für die Bequemlichkeit der Demonstration habe ich es diesmal jedoch als Gurkenformat ausgeben und für Ihren Download und Gebrauch in das Demonstration Github Repo zusammengefügt.
Das Trainingssatz enthält 1.600 Datenstücke; Der Testsatz enthält 400 Datenstücke. Im Etikett stellt 1 positive Emotionen dar und 0 repräsentiert negative Emotionen.
Mit der folgenden Erklärung mischen wir das Trainingssatz und stören die Reihenfolge. Um eine Überanpassung zu vermeiden.
train = train . sample ( len ( train ))Schauen wir uns den Kopfinhalt unseres Trainingssatzes an.
train . head ()
Wenn Sie später Ihren eigenen Datensatz ersetzen möchten, achten Sie bitte auf das Format. Die Spaltennamen der Trainings- und Testsätze sollten konsistent sein.
Im zweiten Schritt setzen wir die Parameter ein.
myparam = {
"DATA_COLUMN" : "comment" ,
"LABEL_COLUMN" : "sentiment" ,
"LEARNING_RATE" : 2e-5 ,
"NUM_TRAIN_EPOCHS" : 3 ,
"bert_model_hub" : "https://tfhub.dev/google/bert_chinese_L-12_H-768_A-12/1"
}Die ersten beiden Zeilen sollen die entsprechenden Spaltennamen des Textes und der Markierungen klar angeben.
Die dritte Zeile gibt die Trainingsrate an. Sie können das Originalpapier lesen, um einen Hyperparameteranpassungsversuch durchzuführen. Oder Sie können den Standardwert einfach unverändert halten.
Zeile 4 Geben Sie die Anzahl der Trainingsrunden an. Führen Sie alle Daten in eine Runde aus. Hier werden 3 Runden verwendet.
Die letzte Zeile zeigt das Bert-Vorausgebildete Modell, das Sie verwenden möchten. Wir möchten den chinesischen Text klassifizieren, daher verwenden wir diese chinesische vorgebrachte Modelladresse. Wenn Sie Englisch verwenden möchten, können Sie sich auf meinen mittleren Blog -Beitrag und den entsprechenden englischen Beispielcode beziehen.
Im letzten Schritt führen wir den Code nacheinander aus.
result , estimator = run_on_dfs ( train , test , ** myparam )Beachten Sie, dass es einige Zeit dauern kann, um diesen Satz auszuführen. Mental vorbereitet sein. Dies bezieht sich auf Ihre Datenvolumen- und Trainingsrundeinstellungen.
In diesem Prozess können Sie sehen, dass das Programm Sie zuerst hilft, den ursprünglichen chinesischen Text in ein Eingabedatenformat zu verwandeln, das Bert verstehen kann.
Wenn Sie den im Bild unten kreisten Text im Rot eingekreist sehen, bedeutet dies, dass der Trainingsprozess endlich vorbei ist.
Dann können Sie die Testergebnisse ausdrucken.
pretty_print ( result )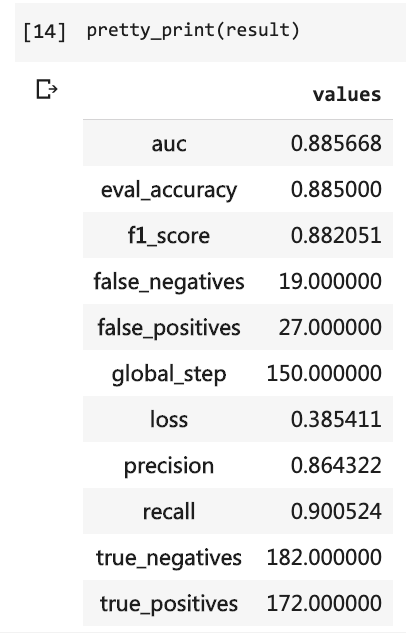
Vergleichen Sie mit unserem vorherigen Tutorial (mit demselben Datensatz).
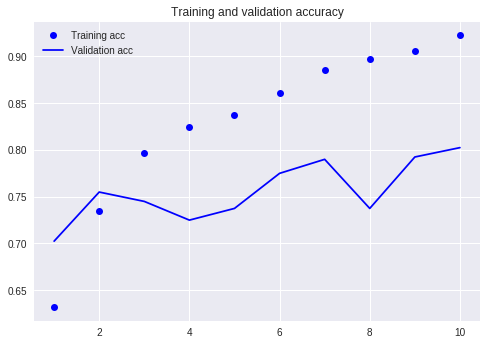
Zu dieser Zeit musste ich so viele Codezeilen schreiben und ich musste 10 Runden ausführen, aber das Ergebnis war immer noch nicht mehr als 80%. Obwohl ich nur 3 Runden trainiert habe, hat die Genauigkeitsrate 88%überschritten.
Es ist nicht einfach, eine solche Genauigkeit auf einem so kleinen Datensatz zu erreichen.
Die Bert -Leistung ist offensichtlich.
Trotzdem haben Sie gelernt, wie man Bert verwendet, um die binäre Klassifizierungsaufgabe des chinesischen Textes zu erledigen. Ich hoffe du wirst so glücklich sein wie ich.
Wenn Sie ein hochrangiger Python -Enthusiast sind, tun Sie mir bitte einen Gefallen.
Erinnerst du dich an den Code vor dieser Zeile?
Kannst du mir helfen, sie zu packen? Auf diese Weise kann unser Demo -Code kürzer, prägnanter, klarer und einfacher sein.
Willkommen, Ihren Code in unserem GitHub -Projekt einzureichen. Wenn Sie dieses Tutorial hilfreich finden, fügen Sie diesem GitHub -Projekt Sterne hinzu. Danke!
Happy Deep Learning!
Möglicherweise interessieren Sie sich auch für die folgenden Themen. Klicken Sie auf den Link, um ihn anzuzeigen.
Wenn es Ihnen gefällt, mögen und belohnen Sie es. Sie können auch meinen offiziellen Account "Yushuzhilan" (Nkwangshuyi) auf WeChat folgen und übertreffen.
Wenn Sie an Python und Data Science interessiert sind, können Sie auch meine Reihe von Tutorial -Index -Posts lesen. "Wie Sie mit Data Science effizient beginnen?
Der Wissensplaneteingang ist hier:


