LLM Shearing
1.0.0
? Arxiv預印本|博客文章
基本型號:剪切lallama-1.3b |剪切-LALA-2.7B |剪切薄膜160m
修剪的模型沒有繼續預訓練:剪切lllama-1.3b pruned,剪切 - llama-2.7b prouned
指令調整模型:剪切lallama-1.3b sharegpt |剪切lalama-2.7b sharegpt
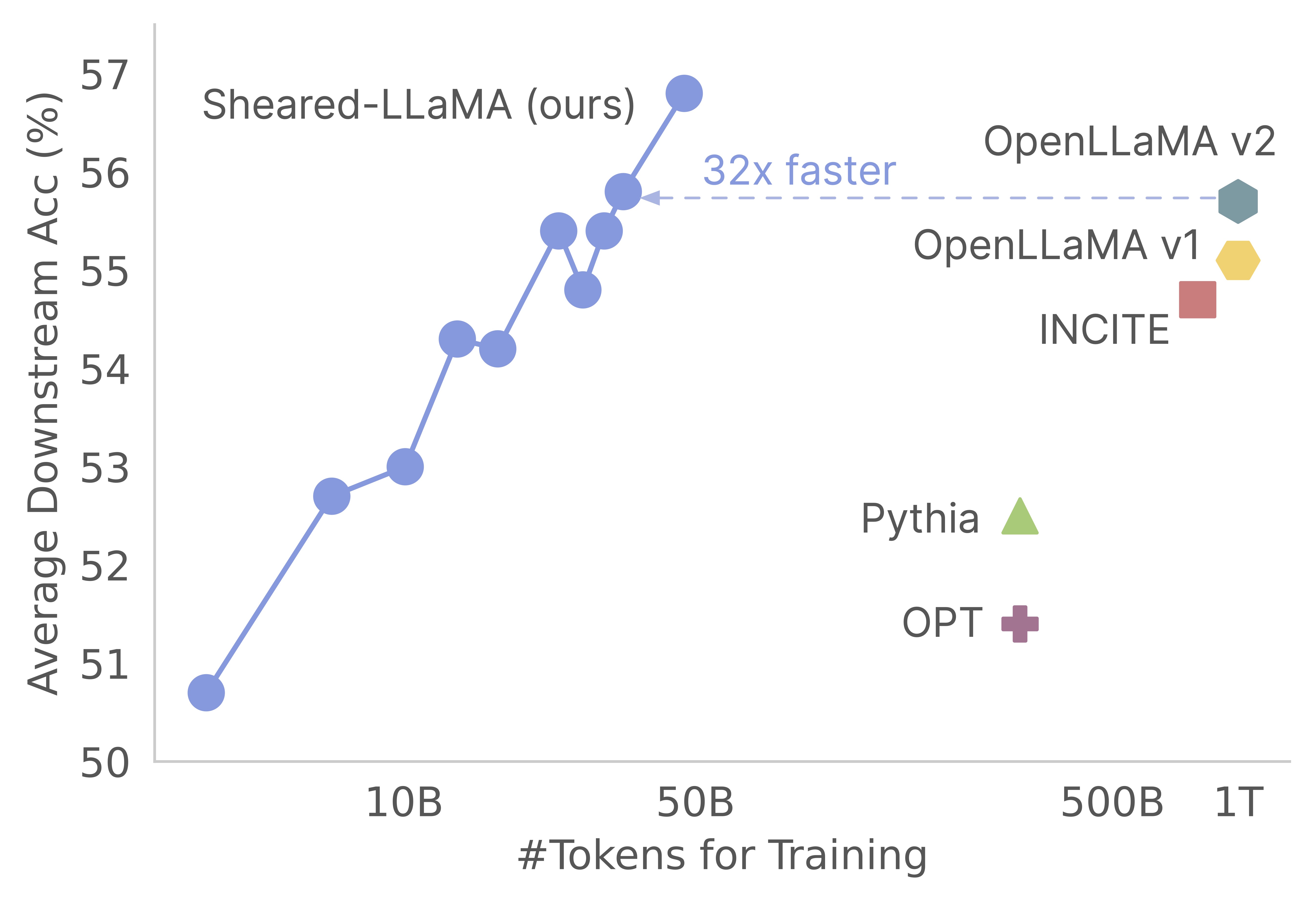
感謝您對我們的工作的興趣!這是Mengzhou Xia,Tianyu Gao,Zhiyuan Zeng和Danqi Chen的聯合作品。在這裡,我們為剪切式的修剪和持續的預訓練算法提供代碼庫:)我們發現,與從Scratch進行預訓練相比,將強大的基本模型用於獲得強大的小型語言模型,是一種獲得強大的小型語言模型的極具成本效益的方法。以下圖顯示,鑑於存在Llama-2-7b模型(由2T代幣進行預訓練),其修剪產生的模型與Openllama模型一樣強,其3%的預培訓成本。
更新
該代碼庫是基於Mosaicml的驚人作曲家軟件包構建的,該包裝是專門設計和優化的,可用於大型語言模型預訓練。包括pruning邏輯和dynamic batch loading邏輯在內的整個實現,無需觸摸香草作曲家培訓師而實現。這是代碼庫中每個文件夾的簡明概述:
shearing.data :包含用於數據處理的示例數據和腳本。shearing.datasets :實現自定義數據集以啟用動態數據加載。shearing.callbacks :實現動態加載回調和修剪回調。shearing.models :實現模型文件。shearing.scripts :包含用於運行代碼的腳本。shearing.utils :包括所有實用程序功能,例如模型轉換和修剪測試。train.py :運行代碼的主要條目步驟1 :要開始使用此存儲庫,您需要遵循以下安裝步驟。在繼續之前,請確保安裝了Pytorch和Flash注意力。您可以使用以下命令通過PIP執行此操作:
pip install torch==2.0.1+cu118 torchvision==0.15.2+cu118 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu118
pip install flash-attn==1.0.3.post
請注意,當前不支持Flash注意力版本2,可能需要對模型文件進行手動修改。
步驟2 :然後安裝其餘所需的軟件包:
cd llmshearing
pip install -r requirement.txt
步驟3 :最後,以可編輯模式安裝llmshearing軟件包,以使其適合您的開發環境:
pip install -e .
有關如何使用Mosaicml的流式包裝準備數據的詳細信息,請參考LLMShearing/Data。
要利用與作曲家的擁抱面孔變壓器模型,您需要將模型權重轉換為作曲家預期的關鍵格式。這是一個示例,說明如何將擁抱面模型“ Llama2”轉換為作曲家兼容格式的示例:
# Define the Hugging Face model name and the output path
HF_MODEL_NAME=meta-llama/Llama-2-7b-hf
OUTPUT_PATH=models/Llama-2-7b-composer/state_dict.pt
# Create the necessary directory if it doesn't exist
mkdir -p $(dirname $OUTPUT_PATH)
# Convert the Hugging Face model to Composer key format
python3 -m llmshearing.utils.composer_to_hf save_hf_to_composer $HF_MODEL_NAME $OUTPUT_PATH
此外,您可以使用以下實用程序函數來測試擁抱面模型與轉換的作曲家模型之間的等效性:
MODEL_SIZE=7B
python3 -m llmshearing.utils.test_composer_hf_eq $HF_MODEL_NAME $OUTPUT_PATH $MODEL_SIZE
這些功能僅適用於Llama/Llama2模型。但是,將它們適應以與其他模型(例如Mistral-7b)一起使用應該是直接的。
對於修剪,您可以參考位於llmshearing/scripts/pruning.sh中的示例腳本。在此腳本中,您需要進行調整以結合數據配置,基本培訓配置,修剪配置和動態批處理加載配置。
由於與持續的預訓練相比,修剪的計算成本相對較高,因此在特定數量的步驟(通常在所有實驗中,通常為3200個步驟),我們停止使用修剪目標進行訓練。隨後,我們繼續對修剪模型進行進一步的預訓練。為了確保兼容性,有必要將模型的狀態字典鍵與標準目標模型結構保持一致。可以通過轉換修剪模型找到此轉換的詳細說明。
完成模型轉換後,您可以繼續進行修剪模型的預培訓。該過程類似於預訓練的標準模型。為此,您可以參考一個位於llmshearing/scripts/continue_pretraining.sh的示例腳本。在此腳本中,消除了修剪配置。
訓練模型後,您可以使用轉換腳本將作曲家模型轉換為變形金剛模型。有關更多詳細信息,請參閱“轉換作曲家”模型轉換為擁抱面模型。
使用llmshearing/scripts/pruning.sh完成培訓後,保存的模型由源模型的整個參數組成,並伴隨一組掩碼。然後,我們通過1)刪除屏蔽變量接近的子結構的掩蔽變量
MODEL_PATH=$MODEL_DIR/latest-rank0.pt
python3 -m llmshearing.utils.post_pruning_processing prune_and_save_model $MODEL_PATH
修剪模型將保存在$(dirname $MODEL_PATH)/pruned-latest-rank0.pt中。
訓練後,如果您想使用huggingface進行推理或微調,則可以選擇使用llmshearing/scripts/composer_to_hf.py腳本將作曲家模型轉換為擁抱面模型。這是如何使用腳本的示例:
MODEL_PATH=$MODEL_DIR/latest-rank0.pt
OUTPUT_PATH=$MODEL_DIR/hf-latest_rank0
MODEL_CLASS=LlamaForCausalLM
HIDDEN_SIZE=2048
NUM_ATTENTION_HEADS=16
NUM_HIDDEN_LAYERS=24
INTERMEDIATE_SIZE=5504
MODEL_NAME=Sheared-Llama-1.3B
python3 -m llmshearing.utils.composer_to_hf save_composer_to_hf $MODEL_PATH $OUTPUT_PATH
model_class=${MODEL_CLASS}
hidden_size=${HIDDEN_SIZE}
num_attention_heads=${NUM_ATTENTION_HEADS}
num_hidden_layers=${NUM_HIDDEN_LAYERS}
intermediate_size=${INTERMEDIATE_SIZE}
num_key_value_heads=${NUM_ATTENTION_HEADS}
_name_or_path=${MODEL_NAME}
請注意,此處提到的參數名稱是針對Llama2的擁抱臉配置量身定制的,並且在處理其他型號類型時可能會有所不同。
在本節中,我們將提供有關在YAML配置文件中配置參數的深入指南,以供培訓。這些配置包括幾個關鍵方面,包括數據設置,基本培訓設置,修剪設置和動態數據加載配置。
data_local :包含數據的本地目錄。eval_loader.dataset.split :對於評估,提供包含來自所有域數據的組合拆分的名稱。train_loader.dataset.split : dynamic=True時(請參閱動態加載配置中的動態加載部分),無需設置此值。但是,如果dynamic=False ,則必須指定培訓拆分。基本培訓配置在很大程度上遵循原始Composer包。有關這些配置的全面詳細信息,請參閱作曲家的官方文檔。以下是一些關鍵培訓參數:
max_duration :此參數定義了最大訓練持續時間,並且可以在步驟數(例如3200ba )或時期(例如1ep )中指定。在我們的實驗中,修剪持續時間設置為3200ba ,持續的預培訓持續時間設置為48000ba 。save_interval :此參數確定保存模型狀態的頻率。我們將其設置為3200ba ,用於修剪和持續的預訓練階段。t_warmup :此參數指定學習率調度程序的學習率熱身持續時間。在修剪的情況下,將其設置為320ba ( optimizer.lr :此參數定義了主要模型參數的學習率,默認值為1e-4 。max_seq_len :遵循Llama 2訓練方法,我們的最大序列長度為4096。device_train_microbatch_size :此參數確定訓練期間每個設備的批處理大小。對於修剪階段,我們將其配置為4 ,而對於持續的預訓練,將其設置為16 。global_train_batch_size :此參數指定訓練期間所有GPU的全局批次大小。在修剪階段,將其配置為32 ,而對於持續的預訓練,它增加到256 。autoresume :可以通過在恢復運行時將其設置為true來啟用此參數。但是,重要的是要注意,儘管我們在持續的訓練階段成功使用了它,但不能保證它與修剪階段的兼容性。由於計算限制,未進行詳盡的超參數搜索,並且可能存在更好的超參數以改善性能。
修剪過程允許將源模型修剪為特定的目標形狀,該腳本包括:諸如:
from_model :此參數指定源模型大小,並對應於config_file。to_model :此參數定義了目標模型大小,並且將修剪源模型以匹配目標配置。optimizer.lag_lr :此參數指定在修剪過程中學習掩蓋變量和拉格朗日乘數的學習率。默認值是特定於修剪的參數均在model.l0_module下分組。 L0_MODULE:
model.l0_module.lagrangian_warmup_steps :在初始熱身階段,修剪速率從0逐漸上升到達到所需的目標值。特定目標值由目標模型的預定義結構確定。重要的是要注意,此值可能與與學習率相關的熱身步驟有所不同。通常,我們分配了該修剪預熱過程的大約20%的步驟總數。model.l0_module.pruning_modules :默認情況下,此設置會預留模型的各個方面,包括頭部,中間維度,隱藏尺寸和層。model.l0_module.eval_target_model :設置為true時,評估過程會評估與目標模型結構完全匹配的子模型。如果設置為false,則評估過程考慮了當前模型,考慮到掩蓋值。由於蒙版可能需要一些時間才能收斂到目標模型形狀,因此我們根據當前模型形狀而不是訓練過程中的目標結構進行評估。model.l0_module.target_model.d_model :指定目標模型的隱藏維度。model.l0_module.target_model.n_heads :指定目標模型中的頭數。model.l0_module.target_model.n_layers :指定目標模型中的層數。model.l0_module.target_model.intermediate_size :指定目標模型中的中間維度的數量。這些參數允許您根據自己的特定要求配置和控制修剪過程。
我們在數據集/streaming_dataset.py中擴展了Steaming的SteamingDataSet,以動態支持加載數據。用於配置動態批處理加載的參數主要定義在DynamicLoadingCallback中。以下大多數配置可以在callbacks.data_loading部分下的YAML配置文件中指定。這是每個參數的解釋:
callbacks.data_loading.dynamic :此佈爾參數確定是否啟用了動態數據加載。設置為True時,數據將從各個域或流動地加載。如果設置為false,則禁用動態數據加載。callbacks.data_loading.set_names :指定將用於動態數據加載的域名或流名稱。callbacks.data_loading.proportion :此參數定義了每個域或流的初始數據加載比例。所有比例的總和必須等於1,表明初始數據加載配置中每個源的相對權重。callbacks.data_loading.update_type :選擇用於調整培訓期間數據加載比例的更新類型。有兩個選擇doremi :在此模式下,使用指數下降方法更新數據加載比例,類似於Doremi中描述的方法。這允許隨著時間的推移自適應調整數據加載比例。constant :選擇此選項可以使數據加載比例保持在整個培訓過程中恆定。它等效於禁用動態數據加載。callbacks.data_loading.target_loss :指定培訓過程的目標驗證損失。該目標損失值應在訓練開始之前計算或預定。負載比例將根據模型當前損失和目標損失之間的差異動態調整。此調整有助於指導培訓過程達到所需的性能水平。eval_interval :確定在訓練期間進行評估的頻率。如果dynamic=True ,則每次評估後將調整數據加載比例。該代碼旨在專門容納本地數據,並且不支持遠程流數據。此外,它目前僅與單個工人一起用於數據效力,並且不提供預取支持。在我們的測試中,該限制並未引起任何其他計算開銷。
這是整個修剪的整個過程,並繼續使用A100 80GB GPU進行預處理。按照每秒處理的令牌來量化吞吐量。請參閱LLM-foundry的標準吞吐量。
| GPU | 每個設備的吞吐量 | 吞吐量 | |
|---|---|---|---|
| 修剪7b | 8 | 1844年 | 14750 |
| 預訓練3B | 16 | 4957 | 79306 |
| 預訓練1.3b | 16 | 8684 | 138945 |
來源模型:雖然大型模型無疑具有強大的功能,並且有可能在不久的將來變得更強大,但我們認為,小型模型(少於70億個參數的模型)沒有開發的潛力。但是,幾乎沒有致力於使小型模型更強大的努力,我們的工作將朝著這一目標邁進。這項工作的自然擴展是將代碼庫擴展到修剪
為了使代碼庫適應其他模型,一個關鍵組件是確保用掩碼運行模型等同於運行修剪模型。我們使用llmshearing/utils/test_pruning.py來運行此類測試,以確保模型文件中函數prune_params的正確性。
數據源:請記住,所得模型的性能不僅取決於修剪算法和基本模型,還取決於數據質量。在我們的實驗中,我們主要使用Redpajama V1數據。但是,這裡有一些可以考慮包含的其他資源:
如果您有與代碼或論文有關的任何疑問,請隨時發送電子郵件給Mengzhou([email protected])。如果使用代碼時遇到任何問題或想報告錯誤,則可以打開問題。請嘗試使用詳細信息指定問題,以便我們可以更好,更快地幫助您!
如果您發現回購對您的工作有幫助,請引用我們的論文:
@article { xia2023sheared ,
title = { Sheared llama: Accelerating language model pre-training via structured pruning } ,
author = { Xia, Mengzhou and Gao, Tianyu and Zeng, Zhiyuan and Chen, Danqi } ,
journal = { arXiv preprint arXiv:2310.06694 } ,
year = { 2023 }
}

