LLM Shearing
1.0.0
? Arxiv Preprint | Пост в блоге
Базовые модели: сдвиг-лама-1,3b | Сдвиг-лама-2,7b | Сдвиг-питс-160 м
Обрезки модели без продолжающейся предварительной тренировки: сдвиг-лотама-1,3B, сдвиг
Модели настройки инструкций: сдвиг-лама-1.3b-sharegpt | Сдвиг-лама-2,7b-sharegpt
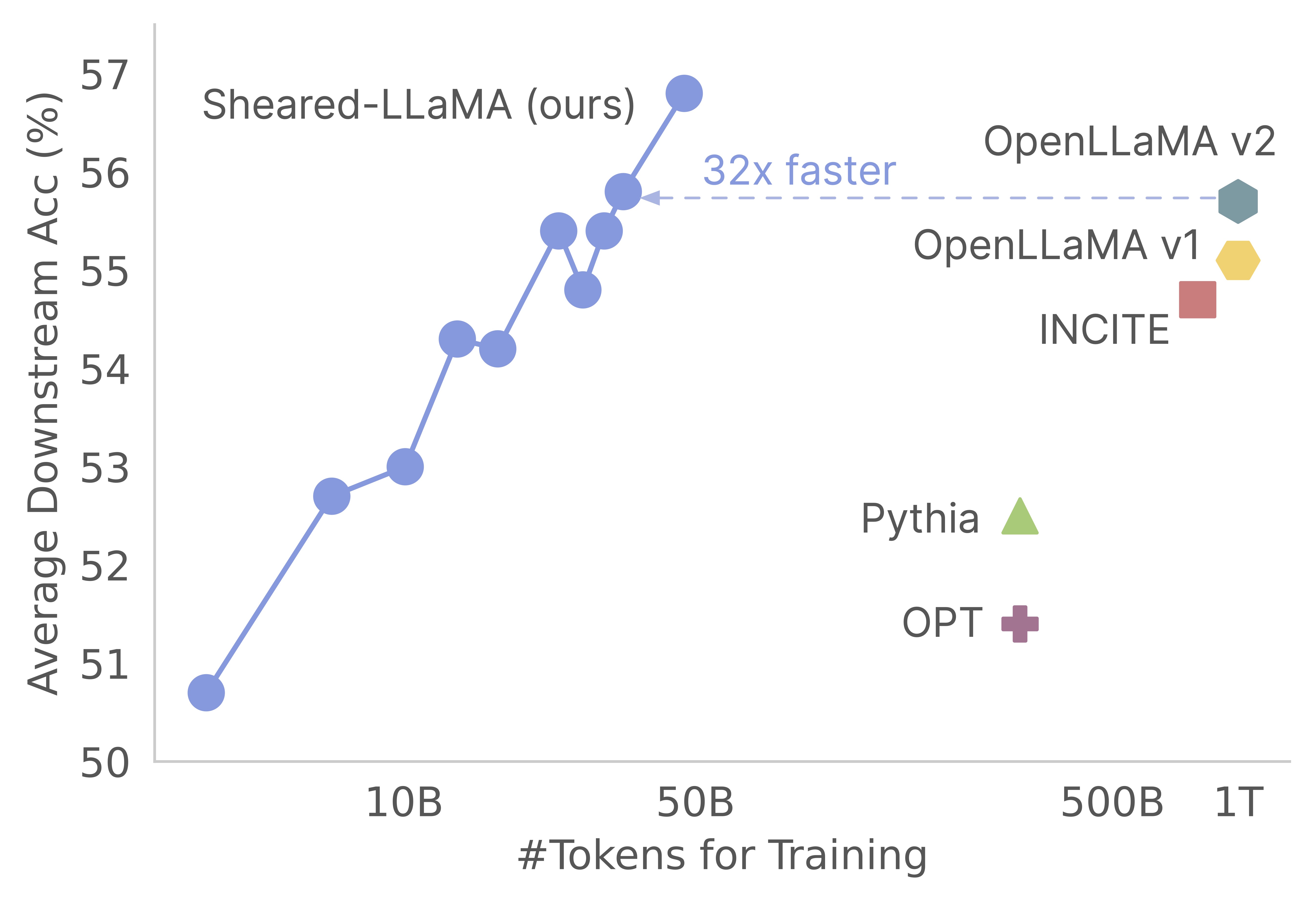
Спасибо за ваш интерес к нашей работе! Это совместная работа Mengzhou Sia, Tianyu Gao, Zhiyuan Zeng и Danqi Chen. Здесь мы предоставляем нашу кодовую базу для обрезки и дальнейших алгоритмов предварительного обучения на сдвигах :) Мы находим, что обрезка сильных базовых моделей является чрезвычайно экономически эффективным способом получения сильных мелкомасштабных языковых моделей по сравнению с предварительным обучением с нуля. Следующий график показывает, что, учитывая существование модели Llama-2-7B (предварительно обученной 2T токенами), обрезка ее производит модель, столь же сильную, как и модель Openllama с 3% от его стоимости предварительного обучения.
Обновлять
Эта кодовая база построена на основе удивительного пакета композиторов Mosaicml, который специально разработан и оптимизирован для предварительной тренировки с крупным языком. Вся реализация, включая логику pruning и логику dynamic batch loading , реализована как функции обратного вызова, не касаясь тренера ванильного композитора. Вот краткий обзор каждой папки в кодовой базе:
shearing.data : содержит образцы данных и сценарии для обработки данных.shearing.datasets : реализует настраиваемые наборы данных, чтобы включить динамическую загрузку данных.shearing.callbacks : реализует динамическую загрузку обратных вызовов и обрезки обратных вызовов.shearing.models : реализует модели файлы.shearing.scripts : содержит сценарии для запуска кода.shearing.utils : включает все функции утилиты, такие как тесты на преобразование модели и обрезка.train.py : основная запись запуска кода Шаг 1 : Чтобы начать с этого репозитория, вам нужно будет выполнить эти этапы установки. Прежде чем продолжить, убедитесь, что у вас установлена Pytorch и Flash Hite. Вы можете сделать это через PIP, используя следующие команды:
pip install torch==2.0.1+cu118 torchvision==0.15.2+cu118 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu118
pip install flash-attn==1.0.3.post
Обратите внимание, что версия 2 Версии 2 в настоящее время не поддерживается и может потребовать ручных изменений в файле модели.
Шаг 2 : Затем установите остальные необходимые пакеты:
cd llmshearing
pip install -r requirement.txt
Шаг 3 : Наконец, установите пакет llmshearing в редактируемом режиме, чтобы сделать его доступным для вашей среды разработки:
pip install -e .
Пожалуйста, обратитесь к LLMShearing/Data для получения подробной информации о том, как подготовить данные с потоковым пакетом MosaICML.
Чтобы использовать модели трансформаторов обнимающегося лица с композитором, вам нужно преобразовать веса модели в ключевой формат, ожидаемый композитором. Вот пример того, как преобразовать веса из модели обнимающего лица «llama2» в совместимый формат для композитора:
# Define the Hugging Face model name and the output path
HF_MODEL_NAME=meta-llama/Llama-2-7b-hf
OUTPUT_PATH=models/Llama-2-7b-composer/state_dict.pt
# Create the necessary directory if it doesn't exist
mkdir -p $(dirname $OUTPUT_PATH)
# Convert the Hugging Face model to Composer key format
python3 -m llmshearing.utils.composer_to_hf save_hf_to_composer $HF_MODEL_NAME $OUTPUT_PATH
Кроме того, вы можете использовать следующую функцию утилиты для проверки эквивалентности между моделью обнимающего лица и конвертированной моделью композитора:
MODEL_SIZE=7B
python3 -m llmshearing.utils.test_composer_hf_eq $HF_MODEL_NAME $OUTPUT_PATH $MODEL_SIZE
Эти функции работают исключительно для моделей Llama/Llama2. Тем не менее, должно быть просто адаптировать их для использования с другими моделями, такими как Mistral-7B.
Для обрезки вы можете ссылаться на пример сценария, расположенный в llmshearing/scripts/pruning.sh . В этом сценарии вам необходимо будет внести коррективы для включения конфигураций данных, базовых тренировочных конфигураций, конфигураций обрезки и конфигураций динамической загрузки пакетов.
Из-за относительно более высокой вычислительной стоимости обрезки по сравнению с продолжающимся предварительным тренировком мы останавливаем обучение с целью обрезки после определенного количества шагов (обычно 3200 шагов во всех наших экспериментах). Впоследствии мы переживаем дальнейшее предварительное обучение обрезенной модели. Чтобы обеспечить совместимость, необходимо преобразовать клавиши словаря состояния модели, чтобы соответствовать стандартной структуре целевой модели. Подробные инструкции для этого преобразования можно найти в конверт -обрезке.
После завершения конверсии модели вы можете продолжить предварительное обучение модели с обрезкой. Процесс аналогичен предварительному обучению стандартной модели. Для этого вы можете обратиться к примеру скрипта, расположенного по адресу llmshearing/scripts/continue_pretraining.sh . В этом сценарии устранены конфигурации обрезки.
После обучения модели вы можете использовать скрипт преобразования для преобразования модели композитора в модель трансформаторов. Пожалуйста, обратитесь к разделу «Преобразовать модель композитора» в модель Huggingface для получения более подробной информации.
После завершения обучения с использованием llmshearing/scripts/pruning.sh сохраненные модели состоят из всего параметров модели исходной модели, сопровождаемых набором масок. Затем мы действуем на маскирующих переменных путем 1) удаления подструктур, где маскирующие переменные рядом
MODEL_PATH=$MODEL_DIR/latest-rank0.pt
python3 -m llmshearing.utils.post_pruning_processing prune_and_save_model $MODEL_PATH
Модель обрезка будет сохранена в $(dirname $MODEL_PATH)/pruned-latest-rank0.pt .
После обучения, если вы хотите использовать использование Huggingface для вывода или тонкой настройки, вы можете преобразовать модель композитора в модель обнимающего лица, используя скрипт llmshearing/scripts/composer_to_hf.py . Вот пример того, как использовать скрипт:
MODEL_PATH=$MODEL_DIR/latest-rank0.pt
OUTPUT_PATH=$MODEL_DIR/hf-latest_rank0
MODEL_CLASS=LlamaForCausalLM
HIDDEN_SIZE=2048
NUM_ATTENTION_HEADS=16
NUM_HIDDEN_LAYERS=24
INTERMEDIATE_SIZE=5504
MODEL_NAME=Sheared-Llama-1.3B
python3 -m llmshearing.utils.composer_to_hf save_composer_to_hf $MODEL_PATH $OUTPUT_PATH
model_class=${MODEL_CLASS}
hidden_size=${HIDDEN_SIZE}
num_attention_heads=${NUM_ATTENTION_HEADS}
num_hidden_layers=${NUM_HIDDEN_LAYERS}
intermediate_size=${INTERMEDIATE_SIZE}
num_key_value_heads=${NUM_ATTENTION_HEADS}
_name_or_path=${MODEL_NAME}
Имейте в виду, что упомянутые здесь имена параметров приспособились к конфигурациям обнимающего лица Llama2 и могут отличаться при работе с другими типами моделей.
В этом разделе мы предоставляем углубленное руководство по настройке параметров в файлах конфигурации YAML для обучения. Эти конфигурации охватывают несколько ключевых аспектов, включая настройку данных, фундаментальные настройки обучения, настройки обрезки и конфигурации динамической загрузки данных.
data_local : локальный каталог, содержащий данные.eval_loader.dataset.split : для оценки предоставьте имя комбинированного разделения, которое включает данные из всех доменов.train_loader.dataset.split : когда dynamic=True (пожалуйста, см. В разделе динамической загрузки) в конфигурации динамической загрузки нет необходимости устанавливать это значение. Однако, если dynamic=False , вы должны указать разделение обучения. Основные тренировочные конфигурации в значительной степени следуют исходному пакету Composer . Для получения дополнительной информации об этих конфигурациях, пожалуйста, обратитесь к официальной документации Composer. Вот несколько ключевых параметров обучения, чтобы принять к сведению:
max_duration : этот параметр определяет максимальную продолжительность обучения и может быть указан либо по количеству шагов (например, 3200ba ) или эпох (например, 1ep ). В наших экспериментах продолжительность обрезки была установлена на 3200ba , а продолжительная продолжительность предварительной тренировки была установлена на 48000ba .save_interval : этот параметр определяет, как часто сохраняется состояние модели. Мы установили его на 3200bat_warmup : Этот параметр указывает продолжительность прогрева скорости обучения для планировщика скорости обучения. В случае обрезки, он установлен на 320ba ( optimizer.lr : Этот параметр определяет скорость обучения для параметров первичной модели, причем значение по умолчанию составляет 1e-4 .max_seq_len : Следуя методологии обучения Llama 2, мы приспосабливаем максимальную длину последовательности 4096.device_train_microbatch_size : этот параметр определяет размер партии на устройство во время обучения. Для этапа обрезки мы настраиваем его на 4 , тогда как для дальнейшего предварительного обучения он установлен на 16 .global_train_batch_size : этот параметр определяет глобальный размер партии во всех графических процессорах во время обучения. На этапе обрезки он настроен как 32 , в то время как для дальнейшего предварительного обучения он увеличивается до 256 .autoresume : этот параметр может быть включен, установив его на true при возобновлении запуска. Тем не менее, важно отметить, что, хотя мы успешно использовали его во время продолжающегося этапа предварительной подготовки, нет никакой гарантии его совместимости с этапом обрезки.Из-за вычислительных ограничений исчерпывающий поиск гиперпараметра не проводился, и может существовать лучшие гиперпараметры для повышения производительности.
Процесс обрезки позволяет обрезать модель исходной модели к определенной форме цели, а сценарий включает в себя важные параметры, такие как:
from_model : этот параметр определяет размер источника и соответствует config_file.to_model : Этот параметр определяет размер целевой модели, и исходная модель будет обрезана в соответствии с целевой конфигурацией.optimizer.lag_lr : Этот параметр указывает скорость обучения, чтобы изучить переменные маскировки и лагранжианские множители во время обрезки. Значение по умолчанию Аргументы, специфичные для обрезки, все сгруппированы по model.l0_module :
model.l0_module.lagrangian_warmup_steps : на начальной фазе прогрева скорость обрезки постепенно повышается с 0, чтобы достичь желаемого целевого значения. Конкретное целевое значение определяется предопределенной структурой целевой модели. Важно отметить, что это значение может отличаться от шагов разминки, связанных с показателями обучения. Как правило, мы выделяем приблизительно 20% от общего количества шагов для этого процесса прогрева.model.l0_module.pruning_modules : По умолчанию эта настройка торгует различные аспекты модели, включая голову, промежуточные измерения, скрытые измерения и слои.model.l0_module.eval_target_model : при установке True процесс оценки оценивает подмодель, которая точно соответствует структуре целевой модели. Если установить FALSE, процесс оценки рассматривает текущую модель, принимая во внимание значения маскировки. Поскольку маска может занять некоторое время, чтобы сходиться к форме целевой модели, мы оцениваем на основе текущей формы модели, а не на целевой структуре во время обучения.model.l0_module.target_model.d_model : указывает скрытое измерение целевой модели.model.l0_module.target_model.n_heads : указывает количество голов в целевой модели.model.l0_module.target_model.n_layers : указывает количество слоев в целевой модели.model.l0_module.target_model.intermediate_size : указывает количество промежуточных измерений в целевой модели.Эти параметры позволяют вам настроить и управлять процессом обрезки в соответствии с вашими конкретными требованиями.
Мы расширяем Steaming StreamingDataset в наборах данных/Streaming_dataset.py, чтобы динамически поддержать загрузку данных. Параметры для настройки динамической загрузки партии в основном определяются в DynamicLoadingCallback . Большинство из следующих конфигураций могут быть указаны в файле конфигурации YAML в разделе callbacks.data_loading . Вот объяснение каждого параметра:
callbacks.data_loading.dynamic : этот логический параметр определяет, включена ли динамическая загрузка данных. При установлении true данные загружаются динамически из различных доменов или потоков. Если установить на FALSE, динамическая загрузка данных отключена.callbacks.data_loading.set_names : укажите доменные имена или имена потоков, которые будут использоваться для динамической загрузки данных.callbacks.data_loading.proportion : Этот параметр определяет начальную пропорцию загрузки данных для каждого домена или потока. Сумма всех пропорций должна равняться 1, указывая на относительные веса каждого источника в начальной конфигурации загрузки данных.callbacks.data_loading.update_type : выберите тип обновления для настройки пропорций загрузки данных во время обучения. Есть два вариантаdoremi : В этом режиме продовольствия загрузки данных обновляются с использованием экспоненциального подхода спуска, аналогичного методу, описанному в Doremi. Это обеспечивает адаптивную корректировку пропорций загрузки данных с течением времени.constant : Выбор этой опции поддерживает пропорции загрузки данных постоянным на протяжении всего обучения. Это эквивалентно отключению динамической загрузки данных.callbacks.data_loading.target_loss : укажите целевую потерю проверки для обучающего процесса. Это значение целевого потери должно быть рассчитано или предопределено до начала обучения. Пропорции загрузки будут динамически скорректированы на основе разницы между текущей потерей модели и целевым потерей. Эта корректировка помогает направлять процесс обучения к желаемому уровню производительности.eval_interval : Определите, как часто проводятся оценки во время обучения. Если dynamic=True , пропорция загрузки данных будет скорректирована после каждой оценки.Код предназначен исключительно для размещения локальных данных и не поддерживает удаленные данные потоковой передачи. Кроме того, в настоящее время он функционирует только с одним работником для DataLoader и не предлагает поддержку предварительной фикса. В нашем тестировании это ограничение не понесло никаких дополнительных вычислительных накладных расходов.
Вот на протяжении всего запуска обрезки и продолжающегося шага предварительного подготовки с графическими процессорами A100 80 ГБ. Пропускная способность количественно определяется с токенами, обрабатываемыми в секунду. Пожалуйста, обратитесь к стандартной пропускной способности LLM-Foundry.
| Графические процессоры | Пропускная пропускная способность на устройство | Пропускная способность | |
|---|---|---|---|
| Обрезка 7b | 8 | 1844 | 14750 |
| Предварительная тренировка 3b | 16 | 4957 | 79306 |
| Предварительная тренировка 1,3 б | 16 | 8684 | 138945 |
Источники : Хотя крупные модели, несомненно, являются мощными и могут стать сильнее в ближайшем будущем, мы считаем, что мелкие модели (модели с менее чем 7 миллиардами параметров) имеют неиспользованный потенциал. Тем не менее, существует мало усилий, посвященных укреплению небольших моделей, и наша работа продвигается к этой цели. Естественным расширением этой работы является расширение кодовой базы на обрезку
Чтобы адаптировать кодовую базу к другим моделям, один из ключевых компонентов - убедиться, что запуск модели с масками эквивалентен запуска модели с обрезкой. Мы используем llmshearing/utils/test_pruning.py для запуска таких тестов, чтобы обеспечить правильность функции prune_params в файлах модели.
Источники данных : Пожалуйста, имейте в виду, что производительность полученной модели зависит не только от алгоритма обрезки и базовой модели, но и в качестве качества данных. В наших экспериментах мы в основном работали с данными Redpajama V1. Однако вот некоторые дополнительные ресурсы, которые можно рассмотреть для включения:
Если у вас есть какие -либо вопросы, связанные с кодом или статьей, не стесняйтесь написать по электронной почте Mengzhou ([email protected]). Если вы сталкиваетесь с какими -либо проблемами при использовании кода или хотите сообщить об ошибке, вы можете открыть проблему. Пожалуйста, попробуйте указать проблему с деталями, чтобы мы могли помочь вам лучше и быстрее!
Пожалуйста, процитируйте нашу газету, если вы найдете репо полезным в своей работе:
@article { xia2023sheared ,
title = { Sheared llama: Accelerating language model pre-training via structured pruning } ,
author = { Xia, Mengzhou and Gao, Tianyu and Zeng, Zhiyuan and Chen, Danqi } ,
journal = { arXiv preprint arXiv:2310.06694 } ,
year = { 2023 }
}

