LLM Shearing
1.0.0
? Preimpresión arxiv | Blog
Modelos base: Sheared-Llama-1.3b | Sheared-llama-2.7b | Cizallado-pythia-160m
Modelos podados sin pretruamiento continuo: cizallado-llama-1.3b-premiado, cizallado-llama-2.7b-premiado
Modelos ajustados a instrucciones: Sheared-llama-1.3b-sharegpt | Sheared-llama-2.7b-sharegpt
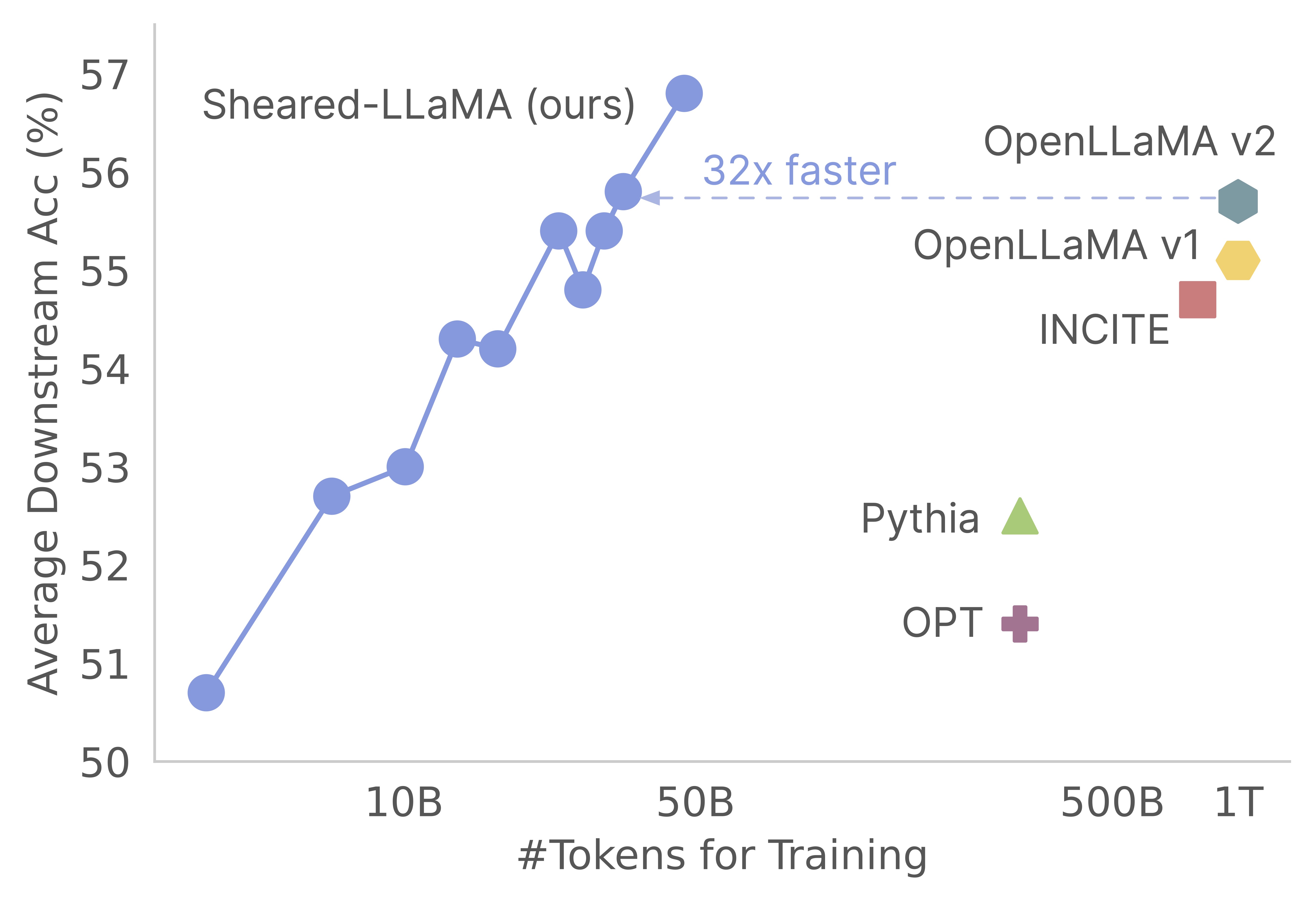
¡Gracias por su interés en nuestro trabajo! Este es un trabajo conjunto de Mengzhou Xia, Tianyu Gao, Zhiyuan Zeng y Danqi Chen. Aquí, proporcionamos nuestra base de código para la poda de Sheared-Llama y los continuos algoritmos de pre-entrenamiento :) Encontramos que la poda de modelos de base fuertes es una forma extremadamente rentable de obtener modelos de lenguaje a pequeña escala fuertes en comparación con los priorizados desde cero. El siguiente gráfico muestra que, dada la existencia del modelo LLAMA-2-7B (previamente capacitado con tokens 2T), la poda produce un modelo tan fuerte como un modelo Openllama con el 3% de su costo previo a la capacitación.
Actualizar
Esta base de código está construida en base al paquete de compositor increíble de MOSAICML, que está especialmente diseñado y optimizado para el pre-entrenamiento del modelo de lenguaje grande. Toda la implementación, incluida la lógica pruning y la lógica dynamic batch loading , se implementan como funciones de devolución de llamada sin tocar el entrenador de compositor de vainilla. Aquí hay una descripción general concisa de cada carpeta dentro de la base de código:
shearing.data : contiene datos de muestra y scripts para el procesamiento de datos.shearing.datasets : implementa conjuntos de datos personalizados para habilitar la carga de datos dinámicos.shearing.callbacks : implementa la carga dinámica de devoluciones de llamada y las devoluciones de llamada de poda.shearing.models : implementa los archivos del modelo.shearing.scripts : contiene scripts para ejecutar el código.shearing.utils : incluye todas las funciones de utilidad, como las pruebas de conversión y poda del modelo.train.py : Entrada principal de ejecutar el código Paso 1 : Para comenzar con este repositorio, deberá seguir estos pasos de instalación. Antes de continuar, asegúrese de tener instalación de Pytorch y Flash Atention. Puede hacer esto a través de PIP usando los siguientes comandos:
pip install torch==2.0.1+cu118 torchvision==0.15.2+cu118 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu118
pip install flash-attn==1.0.3.post
Tenga en cuenta que Flash Atture Versión 2 no es compatible actualmente y puede requerir modificaciones manuales al archivo modelo.
Paso 2 : luego instale el resto de los paquetes requeridos:
cd llmshearing
pip install -r requirement.txt
Paso 3 : Finalmente, instale el paquete llmshearing en modo editable para que sea accesible para su entorno de desarrollo:
pip install -e .
Consulte LLMShearing/Data para obtener detalles sobre cómo preparar datos con el paquete de transmisión de MosaicML.
Para utilizar los modelos de transformadores faciales abrazados con el compositor, deberá convertir los pesos del modelo en el formato clave esperado por el compositor. Aquí hay un ejemplo de cómo convertir los pesos del modelo de la cara abrazada 'Llama2' en un formato compatible para el compositor:
# Define the Hugging Face model name and the output path
HF_MODEL_NAME=meta-llama/Llama-2-7b-hf
OUTPUT_PATH=models/Llama-2-7b-composer/state_dict.pt
# Create the necessary directory if it doesn't exist
mkdir -p $(dirname $OUTPUT_PATH)
# Convert the Hugging Face model to Composer key format
python3 -m llmshearing.utils.composer_to_hf save_hf_to_composer $HF_MODEL_NAME $OUTPUT_PATH
Además, puede usar la siguiente función de utilidad para probar la equivalencia entre el modelo de cara de abrazo y el modelo compositor convertido:
MODEL_SIZE=7B
python3 -m llmshearing.utils.test_composer_hf_eq $HF_MODEL_NAME $OUTPUT_PATH $MODEL_SIZE
Estas funciones funcionan exclusivamente para los modelos LLAMA/LLAMA2. Sin embargo, debería ser sencillo adaptarlos para su uso con otros modelos como Mistral-7B.
Para la poda, puede hacer referencia a un script de ejemplo ubicado en llmshearing/scripts/pruning.sh . En este script, deberá realizar ajustes para incorporar configuraciones de datos, configuraciones de entrenamiento básicas, configuraciones de poda y configuraciones de carga de lotes dinámicos.
Debido al costo computacional relativamente más alto de la poda en comparación con el pretruento continuo, detenemos el entrenamiento con el objetivo de la poda después de un número específico de pasos (típicamente 3200 pasos en todos nuestros experimentos). Posteriormente, procedemos con una mayor pretruación del modelo podado. Para garantizar la compatibilidad, es necesario convertir las claves de diccionario estatal del modelo para alinearse con una estructura de modelo de destino estándar. Las instrucciones detalladas para esta conversión se pueden encontrar en el modelo de podado convertir.
Después de completar la conversión del modelo, puede continuar con el pre-entrenamiento del modelo podado. El proceso es similar a un modelo estándar previo al entrenamiento. Para hacer esto, puede consultar un script de ejemplo ubicado en llmshearing/scripts/continue_pretraining.sh . En este script, se eliminan las configuraciones de poda.
Después de entrenar el modelo, puede usar el script de conversión para convertir el modelo compositor en un modelo de transformadores. Consulte la sección Convertir el modelo compositor al modelo Huggingface para obtener más detalles.
Tras la finalización de la capacitación utilizando llmshearing/scripts/pruning.sh , los modelos guardados consisten en los parámetros completos del modelo de origen, acompañado de un conjunto de máscaras. Luego actuamos sobre las variables de enmascaramiento por 1) eliminando las subestructuras donde las variables de enmascaramiento están cerca
MODEL_PATH=$MODEL_DIR/latest-rank0.pt
python3 -m llmshearing.utils.post_pruning_processing prune_and_save_model $MODEL_PATH
El modelo podado se ahorrará en $(dirname $MODEL_PATH)/pruned-latest-rank0.pt .
Después del entrenamiento, si desea usar Usar Huggingface para inferencia o ajuste fino, puede optar por transformar su modelo de compositor en un modelo de cara abrazada utilizando el script llmshearing/scripts/composer_to_hf.py . Aquí hay un ejemplo de cómo usar el script:
MODEL_PATH=$MODEL_DIR/latest-rank0.pt
OUTPUT_PATH=$MODEL_DIR/hf-latest_rank0
MODEL_CLASS=LlamaForCausalLM
HIDDEN_SIZE=2048
NUM_ATTENTION_HEADS=16
NUM_HIDDEN_LAYERS=24
INTERMEDIATE_SIZE=5504
MODEL_NAME=Sheared-Llama-1.3B
python3 -m llmshearing.utils.composer_to_hf save_composer_to_hf $MODEL_PATH $OUTPUT_PATH
model_class=${MODEL_CLASS}
hidden_size=${HIDDEN_SIZE}
num_attention_heads=${NUM_ATTENTION_HEADS}
num_hidden_layers=${NUM_HIDDEN_LAYERS}
intermediate_size=${INTERMEDIATE_SIZE}
num_key_value_heads=${NUM_ATTENTION_HEADS}
_name_or_path=${MODEL_NAME}
Tenga en cuenta que los nombres de parámetros mencionados aquí están adaptados a las configuraciones faciales de abrazo de LLAMA2 y pueden diferir cuando se trata de otros tipos de modelos.
En esta sección, proporcionamos una guía en profundidad sobre la configuración de parámetros dentro de los archivos de configuración YAML para capacitación. Estas configuraciones abarcan varios aspectos clave, incluida la configuración de datos, la configuración de capacitación fundamental, la poda y las configuraciones de carga de datos dinámicos.
data_local : el directorio local que contiene los datos.eval_loader.dataset.split : para la evaluación, proporcione el nombre de una división combinada que incluye datos de todos los dominios.train_loader.dataset.split : When dynamic=True (consulte la sección de carga dinámica) En la configuración de carga dinámica, no es necesario establecer este valor. Sin embargo, si dynamic=False , debe especificar una división de entrenamiento. Las configuraciones de entrenamiento básicas siguen en gran medida el paquete Composer original. Para obtener detalles completos sobre estas configuraciones, consulte la documentación oficial del compositor. Aquí hay algunos parámetros clave de entrenamiento para tomar nota de:
max_duration : este parámetro define la duración máxima del entrenamiento y se puede especificar en el número de pasos (p. Ej., 3200ba ) o épocas (por ejemplo, 1ep ). En nuestros experimentos, la duración de la poda se estableció en 3200ba , y la duración continua previa al entrenamiento se estableció en 48000ba .save_interval : este parámetro determina con qué frecuencia se guarda el estado del modelo. Lo colocamos en 3200ba tanto para la poda como para las etapas continuas de pre-entrenamiento.t_warmup : este parámetro especifica la duración del calentamiento de la tasa de aprendizaje para el programador de tasas de aprendizaje. En el caso de la poda, se establece en 320ba ( optimizer.lr : este parámetro define la tasa de aprendizaje para los parámetros del modelo primario, con el valor predeterminado de 1e-4 .max_seq_len : después de la metodología de entrenamiento LLAMA 2, acomodamos una longitud de secuencia máxima de 4096.device_train_microbatch_size : este parámetro determina el tamaño de lotes por dispositivo durante el entrenamiento. Para la etapa de poda, la configuramos en 4 , mientras que para la capacitación continua, se establece en 16 .global_train_batch_size : este parámetro especifica el tamaño del lote global en todas las GPU durante el entrenamiento. Durante la etapa de poda, se configura como 32 , mientras que para la pretruación continua, se incrementa a 256 .autoresume : este parámetro se puede habilitar configurándolo en true al reanudar una ejecución. Sin embargo, es importante tener en cuenta que, si bien lo hemos usado con éxito durante la etapa continua de pre -proyectos, no hay garantía de su compatibilidad con la etapa de poda.Debido a las limitaciones computacionales, no se realizó una búsqueda exhaustiva de hiperparámetro, y puede existir mejores hiperparametros para mejorar el rendimiento.
El proceso de poda permite la poda de un modelo de origen a una forma de destino específica, y el script incluye parámetros esenciales como:
from_model : este parámetro especifica el tamaño del modelo de origen y corresponde a una config_file.to_model : este parámetro define el tamaño del modelo de destino, y el modelo de origen se poda para que coincida con la configuración de destino.optimizer.lag_lr : este parámetro especifica la tasa de aprendizaje para aprender las variables de enmascaramiento y los multiplicadores lagrangianos durante la poda. El valor predeterminado es Los argumentos específicos de la poda se agrupan en model.l0_module :
model.l0_module.lagrangian_warmup_steps : en la fase de calentamiento inicial, la tasa de poda aumenta incrementalmente de 0 para alcanzar el valor objetivo deseado. El valor objetivo específico está determinado por la estructura predefinida del modelo objetivo. Es importante tener en cuenta que este valor podría diferir de los pasos de calentamiento asociados con las tasas de aprendizaje. Por lo general, asignamos aproximadamente el 20% del número total de pasos para este proceso de calentamiento de poda.model.l0_module.pruning_modules : de forma predeterminada, esta configuración poda varios aspectos del modelo, incluida la cabeza, las dimensiones intermedias, las dimensiones ocultas y las capas.model.l0_module.eval_target_model : cuando se establece en True, el proceso de evaluación evalúa un submodelo que coincide exactamente con la estructura del modelo de destino. Si se establece en False, el proceso de evaluación considera el modelo actual, teniendo en cuenta los valores de enmascaramiento. Dado que la máscara puede tomar algún tiempo para converger a la forma del modelo objetivo, evaluamos en función de la forma del modelo actual en lugar de la estructura objetivo durante el entrenamiento.model.l0_module.target_model.d_model : Especifica la dimensión oculta del modelo de destino.model.l0_module.target_model.n_heads : especifica el número de cabezas en el modelo de destino.model.l0_module.target_model.n_layers : especifica el número de capas en el modelo de destino.model.l0_module.target_model.intermediate_size : especifica el número de dimensiones intermedias en el modelo de destino.Estos parámetros le permiten configurar y controlar el proceso de poda de acuerdo con sus requisitos específicos.
Extendemos el streamingdataset de Steaming en los conjuntos de datos/streaming_dataset.py para admitir la carga de datos dinámicamente. Los parámetros para configurar la carga de lotes dinámicos se definen principalmente dentro del DynamicLoadingCallback . La mayoría de las siguientes configuraciones se pueden especificar en un archivo de configuración YAML en la sección callbacks.data_loading . Aquí hay una explicación de cada parámetro:
callbacks.data_loading.dynamic : este parámetro booleano determina si la carga de datos dinámicos está habilitada. Cuando se establece en True, los datos se cargan dinámicamente desde varios dominios o transmisiones. Si se establece en False, la carga de datos dinámicos está deshabilitado.callbacks.data_loading.set_names : especifique los nombres de dominio o los nombres de transmisión que se utilizarán para la carga de datos dinámicos.callbacks.data_loading.proportion : este parámetro define la proporción de carga de datos inicial para cada dominio o secuencia. La suma de todas las proporciones debe igualar 1, lo que indica los pesos relativos de cada fuente en la configuración de carga de datos inicial.callbacks.data_loading.update_type : elija el tipo de actualización para ajustar las proporciones de carga de datos durante el entrenamiento. Hay dos opcionesdoremi : en este modo, las proporciones de carga de datos se actualizan utilizando un enfoque de descenso exponencial, similar al método descrito en Doremi. Esto permite el ajuste adaptativo de las proporciones de carga de datos a lo largo del tiempo.constant : la selección de esta opción mantiene constantes las proporciones de carga de datos durante la capacitación. Es equivalente a deshabilitar la carga de datos dinámicos.callbacks.data_loading.target_loss : especifique la pérdida de validación de destino para el proceso de entrenamiento. Este valor de pérdida de objetivo debe calcularse o predeterminarse antes de que comience el entrenamiento. Las proporciones de carga se ajustarán dinámicamente en función de la diferencia entre la pérdida de corriente del modelo y la pérdida objetivo. Este ajuste ayuda a guiar el proceso de capacitación hacia el nivel de rendimiento deseado.eval_interval : determine con qué frecuencia se realizan las evaluaciones durante el entrenamiento. Si dynamic=True , la proporción de carga de datos se ajustará después de cada evaluación.El código está diseñado para acomodar exclusivamente los datos locales y no admite datos de transmisión remota. Además, actualmente solo funciona con un solo trabajador para el dataLoader y no ofrece soporte previo a la captura. En nuestras pruebas, esta restricción no incurre en ninguna sobrecarga de cómputo adicional.
Aquí está el paso de ejecutar la poda y el paso de previación continuo con las GPU A100 80GB. El rendimiento se cuantifica en términos de tokens procesados por segundo. Consulte el rendimiento estándar de LLM-Fundry.
| GPU | Rendimiento por dispositivo | Rendimiento | |
|---|---|---|---|
| Poda 7b | 8 | 1844 | 14750 |
| Pretración 3B | 16 | 4957 | 79306 |
| Pretruamiento 1.3b | 16 | 8684 | 138945 |
Modelos de origen : si bien los modelos grandes son indudablemente potentes y tienen el potencial de fortalecerse en el futuro cercano, creemos que los modelos a pequeña escala (aquellos con menos de 7 mil millones de parámetros) tienen un potencial sin explotar. Sin embargo, hay poco esfuerzo dedicado a hacer que los modelos pequeños sean más fuertes, y nuestro trabajo empuja hacia este objetivo. Una extensión natural de este trabajo es extender la base de código para podar
Para adaptar la base de código a otros modelos, un componente clave es asegurarse de que ejecutar el modelo con máscaras sea equivalente a ejecutar el modelo podado. Usamos llmshearing/utils/test_pruning.py para ejecutar tales pruebas para garantizar la corrección de la función prune_params en los archivos de modelo.
Fuentes de datos : tenga en cuenta que el rendimiento del modelo resultante depende no solo del algoritmo de poda y el modelo base, sino también en la calidad de los datos. En nuestros experimentos, trabajamos principalmente los datos de Redpajama V1. Sin embargo, aquí hay algunos recursos adicionales que podrían considerarse para su inclusión:
Si tiene alguna pregunta relacionada con el código o el documento, no dude en enviar un correo electrónico a Mengzhou ([email protected]). Si encuentra algún problema al usar el código o desea informar un error, puede abrir un problema. ¡Intente especificar el problema con los detalles para que podamos ayudarlo mejor y más rápido!
Por favor, cite nuestro documento si encuentra útil el repositorio en su trabajo:
@article { xia2023sheared ,
title = { Sheared llama: Accelerating language model pre-training via structured pruning } ,
author = { Xia, Mengzhou and Gao, Tianyu and Zeng, Zhiyuan and Chen, Danqi } ,
journal = { arXiv preprint arXiv:2310.06694 } ,
year = { 2023 }
}

