LLM Shearing
1.0.0
? ARXIV Préimpression | Article de blog
Modèles de base: Cish-llama-1.3b | Cish-Llama-2.7b | Cisaillé-pythie-160m
Modèles élagués sans pré-formation continue: Carered-llama-1.3b époussé, cisaillé-llama-2.7b
Modèles réglés par l'instruction: Cish-Llama-1.3b-sharegpt | Citabe-Llama-2.7b-sharegpt
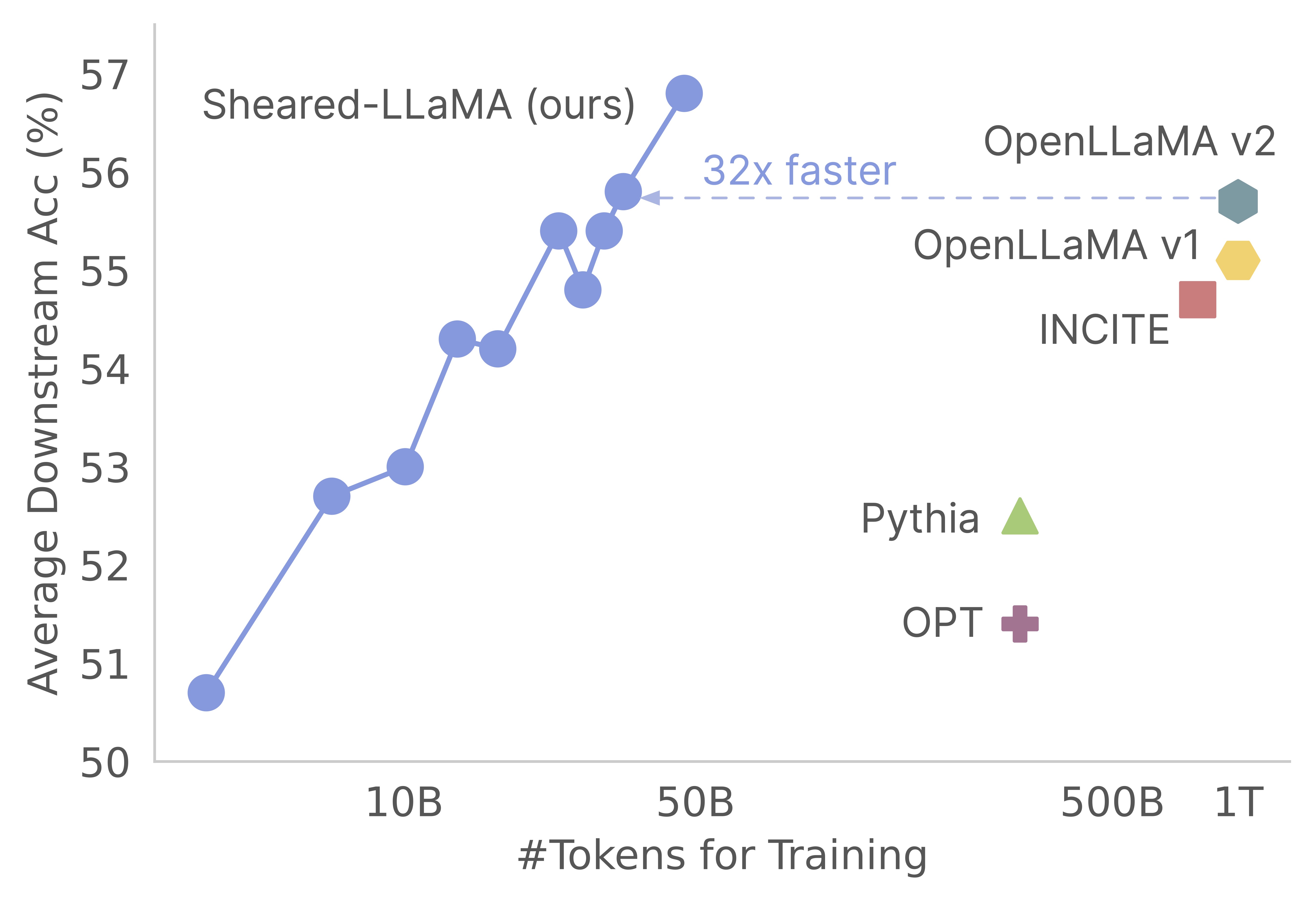
Merci pour votre intérêt pour notre travail! Il s'agit d'une œuvre commune de Mengzhou Xia, Tianyu Gao, Zhiyuan Zeng et Danqi Chen. Ici, nous fournissons notre base de code pour l'élagage de Sheed-Llama et les algorithmes de pré-formation continus :) Nous constatons que l'élagage des modèles de base solides est un moyen extrêmement rentable d'obtenir de solides modèles de langage à petite échelle par rapport à la pré-formation à partir de zéro. Le graphique suivant montre que compte tenu de l'existence du modèle LLAMA-2-7B (pré-formé avec des jetons 2T), il produit un modèle aussi fort qu'un modèle OpenLlama avec 3% de son coût préalable.
Mise à jour
Cette base de code est construite sur la base du package composé de Mosaicml, qui est spécialement conçu et optimisé pour la pré-formation de modèle de grande langue. L'implémentation complète, y compris la logique pruning et la logique dynamic batch loading , sont implémentées en fonction de fonctions de rappel sans toucher à l'entraîneur du compositeur Vanilla. Voici un aperçu concis de chaque dossier dans la base de code:
shearing.data : contient des exemples de données et de scripts pour le traitement des données.shearing.datasets : implémente des ensembles de données personnalisés pour activer le chargement dynamique des données.shearing.callbacks : implémente les rappels dynamiques de chargement et les rappels d'élagage.shearing.models : implémente les fichiers du modèle.shearing.scripts : contient des scripts pour exécuter le code.shearing.utils : comprend toutes les fonctions d'utilité, telles que les tests de conversion et d'élagage du modèle.train.py : entrée principale de l'exécution du code Étape 1 : Pour commencer ce référentiel, vous devrez suivre ces étapes d'installation. Avant de continuer, assurez-vous que l'attention du pytorch et du flash est installée. Vous pouvez le faire via PIP en utilisant les commandes suivantes:
pip install torch==2.0.1+cu118 torchvision==0.15.2+cu118 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu118
pip install flash-attn==1.0.3.post
Veuillez noter que la version 2 de l'attention Flash n'est pas actuellement prise en charge et peut nécessiter des modifications manuelles dans le fichier du modèle.
Étape 2 : puis installez le reste des packages requis:
cd llmshearing
pip install -r requirement.txt
Étape 3 : Enfin, installez le package llmshearing en mode modifiable pour le rendre accessible à votre environnement de développement:
pip install -e .
Veuillez vous référer à LLMShearing / données pour plus de détails sur la façon de préparer les données avec le package de streaming de Mosaicml.
Pour utiliser des modèles de transformateur de face étreintes avec Composer, vous devrez convertir les poids du modèle au format clé attendu par Composer. Voici un exemple de la façon de convertir les poids du modèle de visage étreint 'Llama2' en un format compatible pour le compositeur:
# Define the Hugging Face model name and the output path
HF_MODEL_NAME=meta-llama/Llama-2-7b-hf
OUTPUT_PATH=models/Llama-2-7b-composer/state_dict.pt
# Create the necessary directory if it doesn't exist
mkdir -p $(dirname $OUTPUT_PATH)
# Convert the Hugging Face model to Composer key format
python3 -m llmshearing.utils.composer_to_hf save_hf_to_composer $HF_MODEL_NAME $OUTPUT_PATH
De plus, vous pouvez utiliser la fonction d'utilité suivante pour tester l'équivalence entre le modèle de visage étreint et le modèle de compositeur converti:
MODEL_SIZE=7B
python3 -m llmshearing.utils.test_composer_hf_eq $HF_MODEL_NAME $OUTPUT_PATH $MODEL_SIZE
Ces fonctions fonctionnent exclusivement pour les modèles LLAMA / LLAMA2. Cependant, il devrait être simple de les adapter pour une utilisation avec d'autres modèles tels que Mistral-7B.
Pour l'élagage, vous pouvez faire référence à un exemple de script situé dans llmshearing/scripts/pruning.sh . Dans ce script, vous devrez effectuer des ajustements pour incorporer des configurations de données, des configurations de formation de base, des configurations d'élagage et des configurations de chargement par lots dynamiques.
En raison du coût de calcul relativement plus élevé de l'élagage par rapport à la pré-formation continue, nous arrêtons la formation avec l'objectif d'élagage après un nombre spécifique d'étapes (généralement 3200 étapes dans toutes nos expériences). Par la suite, nous procédons à la pré-formation supplémentaire du modèle taillé. Pour garantir la compatibilité, il est nécessaire de convertir les clés du dictionnaire d'État du modèle pour s'aligner sur une structure de modèle cible standard. Des instructions détaillées pour cette conversion peuvent être trouvées sur le modèle de tonnelle converti.
Après avoir terminé la conversion du modèle, vous pouvez continuer la pré-formation du modèle élagué. Le processus est similaire à pré-entraîner un modèle standard. Pour ce faire, vous pouvez vous référer à un exemple de script situé sur llmshearing/scripts/continue_pretraining.sh . Dans ce script, les configurations d'élagage sont éliminées.
Après avoir entraîné le modèle, vous pouvez utiliser le script de conversion pour convertir le modèle composé en un modèle Transformers. Veuillez vous référer à la section converti le modèle Composer en HuggingFace Model pour plus de détails.
Après l'achèvement de la formation à l'aide de llmshearing/scripts/pruning.sh , les modèles enregistrés sont constitués de l'ensemble des paramètres du modèle source, accompagnés d'un ensemble de masques. Nous agissons ensuite sur les variables de masquage en 1) en supprimant les sous-structures où les variables de masquage sont proches
MODEL_PATH=$MODEL_DIR/latest-rank0.pt
python3 -m llmshearing.utils.post_pruning_processing prune_and_save_model $MODEL_PATH
Le modèle taillé sera économisé dans $(dirname $MODEL_PATH)/pruned-latest-rank0.pt .
Après la formation, si vous souhaitez utiliser Utiliser HuggingFace pour une inférence ou un réglage fin, vous pouvez choisir de transformer votre modèle de compositeur en un modèle de visage étreint en utilisant le script llmshearing/scripts/composer_to_hf.py . Voici un exemple de la façon d'utiliser le script:
MODEL_PATH=$MODEL_DIR/latest-rank0.pt
OUTPUT_PATH=$MODEL_DIR/hf-latest_rank0
MODEL_CLASS=LlamaForCausalLM
HIDDEN_SIZE=2048
NUM_ATTENTION_HEADS=16
NUM_HIDDEN_LAYERS=24
INTERMEDIATE_SIZE=5504
MODEL_NAME=Sheared-Llama-1.3B
python3 -m llmshearing.utils.composer_to_hf save_composer_to_hf $MODEL_PATH $OUTPUT_PATH
model_class=${MODEL_CLASS}
hidden_size=${HIDDEN_SIZE}
num_attention_heads=${NUM_ATTENTION_HEADS}
num_hidden_layers=${NUM_HIDDEN_LAYERS}
intermediate_size=${INTERMEDIATE_SIZE}
num_key_value_heads=${NUM_ATTENTION_HEADS}
_name_or_path=${MODEL_NAME}
Veuillez noter que les noms de paramètres mentionnés ici sont adaptés aux configurations de visage étreintes de LLAMA2 et peuvent différer lorsqu'ils traitent d'autres types de modèles.
Dans cette section, nous fournissons un guide approfondi sur la configuration des paramètres dans les fichiers de configuration YAML pour la formation. Ces configurations englobent plusieurs aspects clés, y compris la configuration des données, les paramètres de formation fondamentaux, les paramètres d'élagage et les configurations de chargement de données dynamiques.
data_local : Le répertoire local contenant les données.eval_loader.dataset.split : Pour l'évaluation, fournissez le nom d'une scission combinée qui comprend des données de tous les domaines.train_loader.dataset.split : lorsque dynamic=True (veuillez vous référer à la section de chargement dynamique) Dans la configuration de chargement dynamique, il n'est pas nécessaire de définir cette valeur. Cependant, si dynamic=False , vous devez spécifier une division de formation. Les configurations de formation de base suivent en grande partie le package Composer d'origine. Pour plus de détails sur ces configurations, veuillez vous référer à la documentation officielle du compositeur. Voici quelques paramètres de formation clés pour prendre note de:
max_duration : Ce paramètre définit la durée de formation maximale et peut être spécifié dans le nombre d'étapes (par exemple, 3200ba ) ou des époques (par exemple, 1ep ). Dans nos expériences, la durée de l'élagage a été fixée à 3200ba et la durée de pré-formation continue a été fixée à 48000ba .save_interval : Ce paramètre détermine à quelle fréquence l'état du modèle est enregistré. Nous l'avons réglé sur 3200ba pour les étapes de l'élagage et de pré-formation continue.t_warmup : Ce paramètre spécifie la durée de l'échauffement du taux d'apprentissage pour le planificateur de taux d'apprentissage. Dans le cas de l'élagage, il est fixé à 320ba ( optimizer.lr : Ce paramètre définit le taux d'apprentissage des paramètres du modèle primaire, la valeur par défaut étant 1e-4 .max_seq_len : Suivant la méthodologie de formation LLAMA 2, nous avons accueilli une durée de séquence maximale de 4096.device_train_microbatch_size : Ce paramètre détermine la taille du lot par appareil pendant la formation. Pour l'étape d'élagage, nous le configurons à 4 , tandis que pour la pré-formation continue, il est défini sur 16 .global_train_batch_size : Ce paramètre spécifie la taille globale du lot dans tous les GPU pendant la formation. Pendant le stade de l'élagage, il est configuré comme 32 , tandis que pour la pré-formation continue, il est augmenté à 256 .autoresume : ce paramètre peut être activé en le définissant sur true lors de la reprise d'une exécution. Cependant, il est important de noter que même si nous l'avons utilisé avec succès pendant le stade continu de pré-formation, il n'y a aucune garantie de sa compatibilité avec le stade de l'élagage.En raison de contraintes de calcul, une recherche hyperparamètre exhaustive n'a pas été effectuée, et il peut exister de meilleurs hyper-paramètres pour améliorer des performances.
Le processus d'élagage permet d'élaguer un modèle source à une forme cible spécifique, et le script comprend des paramètres essentiels tels que:
from_model : Ce paramètre spécifie la taille du modèle source et correspond à un config_file.to_model : Ce paramètre définit la taille du modèle cible et le modèle source sera taillé pour correspondre à la configuration cible.optimizer.lag_lr : Ce paramètre spécifie le taux d'apprentissage pour apprendre les variables de masquage et les multiplicateurs lagrangiens pendant l'élagage. La valeur par défaut est Les arguments spécifiques à l'élagage sont tous regroupés sous model.l0_module :
model.l0_module.lagrangian_warmup_steps : Dans la phase d'échauffement initiale, le taux d'élagage passe progressivement de 0 pour atteindre la valeur cible souhaitée. La valeur cible spécifique est déterminée par la structure prédéfinie du modèle cible. Il est important de noter que cette valeur peut différer des étapes d'échauffement associées aux taux d'apprentissage. En règle générale, nous allouons environ 20% du nombre total d'étapes pour ce processus d'échauffement d'élagage.model.l0_module.pruning_modules : Par défaut, ce réglage émeut divers aspects du modèle, y compris la tête, les dimensions intermédiaires, les dimensions cachées et les couches.model.l0_module.eval_target_model : Lorsqu'il est défini sur true, le processus d'évaluation évalue un sous-modèle qui correspond exactement à la structure du modèle cible. S'il est défini sur False, le processus d'évaluation considère le modèle actuel, en tenant compte des valeurs de masquage. Étant donné que le masque peut prendre un certain temps pour converger vers la forme du modèle cible, nous évaluons en fonction de la forme du modèle actuel plutôt que de la structure cible pendant l'entraînement.model.l0_module.target_model.d_model : Spécifie la dimension cachée du modèle cible.model.l0_module.target_model.n_heads : Spécifie le nombre de têtes dans le modèle cible.model.l0_module.target_model.n_layers : Spécifie le nombre de couches dans le modèle cible.model.l0_module.target_model.intermediate_size : Spécifie le nombre de dimensions intermédiaires dans le modèle cible.Ces paramètres vous permettent de configurer et de contrôler le processus d'élagage en fonction de vos exigences spécifiques.
Nous étendons StreamingDataset de la vapeur dans DataSets / Streaming_dataset.py pour prendre en charge le chargement de données dynamiquement. Les paramètres de configuration du chargement par lots dynamiques sont principalement définis dans le DynamicLoadingCallback . La plupart des configurations suivantes peuvent être spécifiées dans un fichier de configuration YAML sous la section callbacks.data_loading . Voici une explication de chaque paramètre:
callbacks.data_loading.dynamic : ce paramètre booléen détermine si le chargement dynamique des données est activé. Lorsqu'il est défini sur true, les données sont chargées dynamiquement à partir de divers domaines ou flux. S'il est défini sur False, le chargement dynamique des données est désactivé.callbacks.data_loading.set_names : spécifiez les noms de domaine ou les noms de flux qui seront utilisés pour le chargement dynamique des données.callbacks.data_loading.proportion : ce paramètre définit la proportion de chargement de données initiale pour chaque domaine ou flux. La somme de toutes les proportions doit être égale à 1, indiquant les poids relatifs de chaque source dans la configuration de chargement de données initiale.callbacks.data_loading.update_type : choisissez le type de mise à jour pour ajuster les proportions de chargement de données pendant la formation. Il y a deux optionsdoremi : Dans ce mode, les proportions de chargement de données sont mises à jour à l'aide d'une approche de descente exponentielle, similaire à la méthode décrite dans Doremi. Cela permet un ajustement adaptatif des proportions de chargement de données au fil du temps.constant : la sélection de cette option maintient les proportions de chargement des données constantes tout au long de la formation. Il est équivalent à désactiver le chargement dynamique des données.callbacks.data_loading.target_loss : spécifiez la perte de validation cible pour le processus de formation. Cette valeur de perte cible doit être calculée ou prédéterminée avant le début de l'entraînement. Les proportions de chargement seront ajustées dynamiquement en fonction de la différence entre la perte actuelle du modèle et la perte cible. Cet ajustement aide à guider le processus de formation vers le niveau de performance souhaité.eval_interval : Déterminez la fréquence à laquelle les évaluations sont effectuées pendant la formation. Si dynamic=True , la proportion de chargement de données sera ajustée après chaque évaluation.Le code est conçu pour s'adapter exclusivement aux données locales et ne prend pas en charge les données de streaming à distance. De plus, il ne fonctionne actuellement qu'avec un seul travailleur pour le dataloader et n'offre pas de support préfectif. Dans nos tests, cette restriction n'a pas de frais de calcul supplémentaires.
Voici tout au long de l'exécution de l'élagage et du pas de prélèvement continu avec des GPU A100 80 Go. Le débit est quantifié en termes de jetons traités par seconde. Veuillez vous référer au débit standard de LLM-Foundry.
| GPUS | Débit par appareil | Déborder | |
|---|---|---|---|
| Élagage 7b | 8 | 1844 | 14750 |
| Pré-formation 3B | 16 | 4957 | 79306 |
| Pré-formation 1.3b | 16 | 8684 | 138945 |
Modèles source : Bien que les grands modèles soient sans aucun doute puissants et ont le potentiel de devenir plus fort dans un avenir proche, nous pensons que les modèles à petite échelle (ceux avec moins de 7 milliards de paramètres) ont un potentiel inexploité. Cependant, il y a peu d'efforts consacrés à la renforcement des petits modèles, et notre travail pousse vers cet objectif. Une extension naturelle de ce travail consiste à étendre la base de code pour tailler
Pour adapter la base de code à d'autres modèles, un composant clé consiste à s'assurer que l'exécution du modèle avec des masques équivaut à l'exécution du modèle élagué. Nous utilisons llmshearing / utils / test_pruning.py pour exécuter ces tests pour garantir l'exactitude de la fonction prune_params dans les fichiers du modèle.
Sources de données : veuillez garder à l'esprit que les performances du modèle résultant dépendent non seulement de l'algorithme d'élagage et du modèle de base mais également de la qualité des données. Dans nos expériences, nous avons principalement travaillé les données Redpajama V1. Cependant, voici quelques ressources supplémentaires qui pourraient être prises en compte pour l'inclusion:
Si vous avez des questions liées au code ou au journal, n'hésitez pas à envoyer un courriel à Mengzhou ([email protected]). Si vous rencontrez des problèmes lorsque vous utilisez le code ou souhaitez signaler un bogue, vous pouvez ouvrir un problème. Veuillez essayer de spécifier le problème avec les détails afin que nous puissions vous aider mieux et plus rapidement!
Veuillez citer notre article si vous trouvez le repo utile dans votre travail:
@article { xia2023sheared ,
title = { Sheared llama: Accelerating language model pre-training via structured pruning } ,
author = { Xia, Mengzhou and Gao, Tianyu and Zeng, Zhiyuan and Chen, Danqi } ,
journal = { arXiv preprint arXiv:2310.06694 } ,
year = { 2023 }
}

