LLM Shearing
1.0.0
? Arxiv Preprint | Blog -Beitrag
Basismodelle: Scherlama-1.3b | Scherte llama-2.7b | Scherte Pythie-160m
Beschnittene Modelle ohne fortgesetzte Voraussetzung: Scherte LLLAMA-1.3b-besiegte, gescherte Llama-2.7b-bevölkerte
Modelle mit Anleitungen abgestimmt: Scherlama-1.3b-Sharegpt | Scherte LLLAMA-2.7B-SHAREGPT
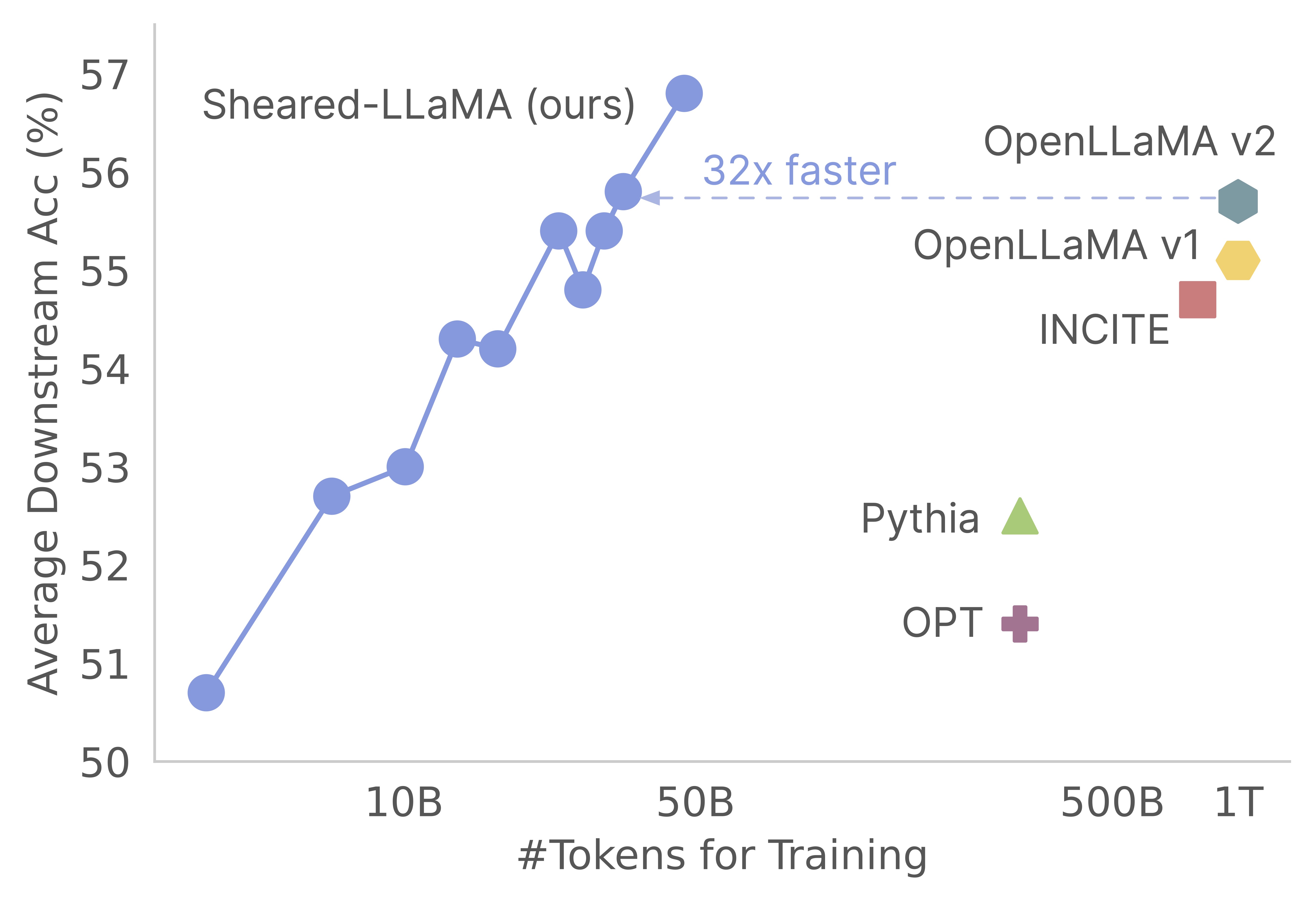
Vielen Dank für Ihr Interesse an unserer Arbeit! Dies ist eine gemeinsame Arbeit von Mengzhou Xia, Tianyu Gao, Zhiyuan Zeng und Danqi Chen. Hier bieten wir unsere Codebasis für Scherlamas Beschneidung und fortgesetzte Pre-Training-Algorithmen :) Wir stellen fest, dass das Beschneiden starker Basismodelle eine äußerst kostengünstige Möglichkeit ist, starke Sprachmodelle kleiner Maßstäbe im Vergleich zur Voraussetzung von Grund auf neu zu erhalten. Die folgende Grafik zeigt, dass angesichts der Existenz eines LLAMA-2-7B-Modells (mit 2T-Token) ein Modell so stark wie ein Openllama-Modell mit 3% seiner Kosten vor dem Training erzeugt.
Aktualisieren
Diese Codebasis basiert auf dem erstaunlichen Komponist-Paket von Mosaicml, das speziell für Großsprachenmodell vor der Training entwickelt und optimiert ist. Die gesamte Implementierung, einschließlich der pruning und der dynamic batch loading , werden als Rückruffunktionen implementiert, ohne den Vanille -Komponisten -Trainer zu berühren. Hier finden Sie einen kurzen Überblick über jeden Ordner in der Codebasis:
shearing.data : Enthält Beispieldaten und Skripte für die Datenverarbeitung.shearing.datasets : Implementiert kundenspezifische Datensätze, um dynamisches Datenladen zu aktivieren.shearing.callbacks : Implementiert dynamische Lade -Rückrufe und Beschneidungsrückrufe.shearing.models : Implementiert die Modelldateien.shearing.scripts : Enthält Skripte zum Ausführen des Code.shearing.utils : Enthält alle Dienstprogrammfunktionen wie Modellkonvertierung und Beschneidungstests.train.py : Haupteintrag beim Ausführen des Codes Schritt 1 : Um mit diesem Repository zu beginnen, müssen Sie diese Installationsschritte befolgen. Stellen Sie vor dem Fortfahren sicher, dass Sie Pytorch und Flash -Aufmerksamkeit installiert haben. Sie können dies über PIP mit den folgenden Befehlen tun:
pip install torch==2.0.1+cu118 torchvision==0.15.2+cu118 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu118
pip install flash-attn==1.0.3.post
Bitte beachten Sie, dass die Flash -Achtung Version 2 derzeit nicht unterstützt wird und möglicherweise manuelle Änderungen an der Modelldatei erfordern.
Schritt 2 : Dann installieren Sie den Rest der erforderlichen Pakete:
cd llmshearing
pip install -r requirement.txt
Schritt 3 : Installieren Sie schließlich das llmshearing -Paket im bearbeitbaren Modus, um es für Ihre Entwicklungsumgebung zugänglich zu machen:
pip install -e .
Weitere Informationen zum Streaming -Paket von Mosaicml finden Sie in LLMShearing/Daten.
Um umarmende Gesichtstransformatormodelle mit Komponisten zu verwenden, müssen Sie die Modellgewichte in das von Composer erwartete Schlüsselformat umwandeln. Hier ist ein Beispiel dafür, wie Sie die Gewichte aus dem umarmenden Gesichtsmodell 'LLAMA2' in ein kompatibles Format für Komponisten umwandeln:
# Define the Hugging Face model name and the output path
HF_MODEL_NAME=meta-llama/Llama-2-7b-hf
OUTPUT_PATH=models/Llama-2-7b-composer/state_dict.pt
# Create the necessary directory if it doesn't exist
mkdir -p $(dirname $OUTPUT_PATH)
# Convert the Hugging Face model to Composer key format
python3 -m llmshearing.utils.composer_to_hf save_hf_to_composer $HF_MODEL_NAME $OUTPUT_PATH
Darüber hinaus können Sie die folgende Nutzungsfunktion verwenden, um die Äquivalenz zwischen dem Umarmungsgesichtsmodell und dem konvertierten Komponistenmodell zu testen:
MODEL_SIZE=7B
python3 -m llmshearing.utils.test_composer_hf_eq $HF_MODEL_NAME $OUTPUT_PATH $MODEL_SIZE
Diese Funktionen funktionieren ausschließlich für Lama/Lama2 -Modelle. Es sollte jedoch unkompliziert sein, sie für die Verwendung mit anderen Modellen wie Mistral-7b anzupassen.
Zum Beschneiden können Sie ein Beispielskript in llmshearing/scripts/pruning.sh verweisen. In diesem Skript müssen Sie Anpassungen vornehmen, um Datenkonfigurationen, Grundschulkonfigurationen, Beschneidungskonfigurationen und dynamische Batch -Ladekonfigurationen einzubeziehen.
Aufgrund der relativ höheren Rechenkosten des Schnitts im Vergleich zu fortgesetzter Vorinstallation stoppen wir das Training nach einer bestimmten Anzahl von Schritten (typischerweise 3200 Schritte in allen unseren Experimenten). Anschließend fahren wir mit dem weiteren Vorbild des beschnittenen Modells fort. Um die Kompatibilität zu gewährleisten, ist es erforderlich, die staatlichen Wörterbuchschlüssel des Modells umzuwandeln, um mit einer Standard -Zielmodellstruktur ausgerichtet zu werden. Detaillierte Anweisungen für diese Konvertierung finden Sie im konvertierten beschnittenen Modell.
Nach Abschluss der Modellumwandlung können Sie mit der Vorausbildung des beschnittenen Modells fortfahren. Der Prozess ähnelt einem Standardmodell vor dem Training. Dazu können Sie sich auf ein Beispielskript unter llmshearing/scripts/continue_pretraining.sh verweisen. In diesem Skript werden die Beschneidungskonfigurationen beseitigt.
Nach dem Training des Modells können Sie das Conversion -Skript verwenden, um das Komponistenmodell in ein Transformers -Modell umzuwandeln. Weitere Informationen finden Sie im Abschnitt Composer -Modell auf das Huggingface -Modell.
Nach Abschluss des Trainings mithilfe von llmshearing/scripts/pruning.sh bestehen die gespeicherten Modelle aus den gesamten Parametern des Quellmodells, begleitet von einer Reihe von Masken. Wir reagieren dann auf die Maskierungsvariablen, indem wir die Unterstrukturen entfernen, in denen sich die Maskierungsvariablen in der Nähe befinden
MODEL_PATH=$MODEL_DIR/latest-rank0.pt
python3 -m llmshearing.utils.post_pruning_processing prune_and_save_model $MODEL_PATH
Das beschnittene Modell wird in $(dirname $MODEL_PATH)/pruned-latest-rank0.pt gespeichert.
Wenn Sie nach dem Training ein Huggingface für Inferenz oder Feinabstimmung verwenden möchten, können Sie Ihr Komponistenmodell mithilfe des Skripts llmshearing/scripts/composer_to_hf.py in ein umarmendes Gesichtsmodell verwandeln. Hier ist ein Beispiel für die Verwendung des Skripts:
MODEL_PATH=$MODEL_DIR/latest-rank0.pt
OUTPUT_PATH=$MODEL_DIR/hf-latest_rank0
MODEL_CLASS=LlamaForCausalLM
HIDDEN_SIZE=2048
NUM_ATTENTION_HEADS=16
NUM_HIDDEN_LAYERS=24
INTERMEDIATE_SIZE=5504
MODEL_NAME=Sheared-Llama-1.3B
python3 -m llmshearing.utils.composer_to_hf save_composer_to_hf $MODEL_PATH $OUTPUT_PATH
model_class=${MODEL_CLASS}
hidden_size=${HIDDEN_SIZE}
num_attention_heads=${NUM_ATTENTION_HEADS}
num_hidden_layers=${NUM_HIDDEN_LAYERS}
intermediate_size=${INTERMEDIATE_SIZE}
num_key_value_heads=${NUM_ATTENTION_HEADS}
_name_or_path=${MODEL_NAME}
Bitte beachten Sie, dass die hier genannten Parameternamen auf die umarmenden Gesichtskonfigurationen von LLAMA2 zugeschnitten sind und sich im Umgang mit anderen Modelltypen unterscheiden können.
In diesem Abschnitt bieten wir eine eingehende Anleitung zum Konfigurieren von Parametern in YAML-Konfigurationsdateien für das Training. Diese Konfigurationen umfassen mehrere wichtige Aspekte, einschließlich Datenaufbau, grundlegende Schulungseinstellungen, Beschneidungseinstellungen und dynamische Datenladenkonfigurationen.
data_local : Das lokale Verzeichnis, das die Daten enthält.eval_loader.dataset.split : Geben Sie zur Bewertung den Namen eines kombinierten Splits an, der Daten aus allen Domänen enthält.train_loader.dataset.split : Wenn dynamic=True (siehe den dynamischen Ladeabschnitt) in der dynamischen Ladekonfiguration, müssen diesen Wert nicht festgelegt werden. Wenn Sie jedoch dynamic=False , müssen Sie eine Trainingsaufteilung angeben. Die Grundschulkonfigurationen folgen weitgehend dem ursprünglichen Composer -Paket. Für umfassende Details zu diesen Konfigurationen finden Sie in der offiziellen Dokumentation des Komponisten. Hier sind einige wichtige Trainingsparameter, die Sie zur Kenntnis nehmen können:
max_duration : Dieser Parameter definiert die maximale Trainingsdauer und kann entweder in der Anzahl der Schritte (z. B. 3200ba ) oder Epochen (z. B. 1ep ) angegeben werden. In unseren Experimenten wurde die Beschneidungsdauer auf 3200ba eingestellt und die fortgesetzte Dauer vor der Schulung auf 48000ba eingestellt.save_interval : Dieser Parameter bestimmt, wie häufig der Modellzustand gespeichert wird. Wir haben es sowohl für das Beschneiden als auch für die Stadien vor dem Training auf 3200ba gesetzt.t_warmup : Dieser Parameter gibt die Dauer der Lernrate aufwärmen für den Scheduler für die Lernrate an. Im Falle des Schnitts ist es auf 320ba ( optimizer.lr : Dieser Parameter definiert die Lernrate für die Primärmodellparameter, wobei der Standardwert 1e-4 beträgt.max_seq_len : Nach der Lama -2 -Trainingsmethode berücksichtigen wir eine maximale Sequenzlänge von 4096.device_train_microbatch_size : Dieser Parameter bestimmt die Stapelgröße pro Gerät während des Trainings. Für die Beschneidungsstufe konfigurieren wir es auf 4 , während es für die fortgesetzte Vorinstallation auf 16 eingestellt ist.global_train_batch_size : Dieser Parameter gibt die globale Stapelgröße über alle GPUs während des Trainings an. Während der Beschneidungsstufe wird es als 32 konfiguriert, während es für die fortgesetzte Vorinstallation auf 256 erhöht wird.autoresume : Dieser Parameter kann aktiviert werden, indem er bei der Wiederaufnahme eines Laufs auf true eingestellt wird. Es ist jedoch wichtig anzumerken, dass es zwar erfolgreich in der fortgesetzten Vorabstufe verwendet hat, es jedoch keine Garantie für seine Kompatibilität mit der Beschneidungsstufe gibt.Aufgrund von rechnerischen Einschränkungen wurde keine umfassende Hyperparameter-Suche durchgeführt, und es kann möglicherweise bessere Hyperparameter für eine verbesserte Leistung existieren.
Der Beschneidungsprozess ermöglicht das Beschneiden eines Quellmodells in eine bestimmte Zielform, und das Skript enthält wesentliche Parameter wie:
from_model : Dieser Parameter gibt die Quellmodellgröße an und entspricht einer config_file.to_model : Dieser Parameter definiert die Zielmodellgröße, und das Quellmodell wird beschnitten, um der Zielkonfiguration zu entsprechen.optimizer.lag_lr : Dieser Parameter gibt die Lernrate an, um die Maskierungsvariablen und Lagrange -Multiplikatoren während des Beschneidens zu erlernen. Der Standardwert ist Die puningspezifischen Argumente sind alle unter model.l0_module gruppiert:
model.l0_module.lagrangian_warmup_steps : In der anfänglichen Aufwärmphase steigt die Schnittrate schrittweise von 0, um den gewünschten Zielwert zu erreichen. Der spezifische Zielwert wird durch die vordefinierte Struktur des Zielmodells bestimmt. Es ist wichtig zu beachten, dass dieser Wert von den mit den Lernraten verbundenen Aufwärmschritten abweist. Normalerweise zuordnen wir ungefähr 20% der Gesamtzahl der Schritte für diesen Schnittwärmprozess zu.model.l0_module.pruning_modules : standardmäßig beschnitten diese Einstellung verschiedene Aspekte des Modells, einschließlich Kopf, Zwischenabmessungen, versteckte Dimensionen und Schichten.model.l0_module.eval_target_model : Wenn auf true eingestellt ist, bewertet der Bewertungsprozess ein Submodel, das genau mit der Struktur des Zielmodells übereinstimmt. Wenn auf False festgelegt wird, berücksichtigt der Bewertungsprozess das aktuelle Modell unter Berücksichtigung der Maskierungswerte. Da die Maske möglicherweise einige Zeit in Anspruch nehmen kann, um in die Zielmodellform zu konvergieren, bewerten wir basierend auf der aktuellen Modellform und nicht auf der Zielstruktur während des Trainings.model.l0_module.target_model.d_model : Gibt die verborgene Dimension des Zielmodells an.model.l0_module.target_model.n_heads : Gibt die Anzahl der Köpfe im Zielmodell an.model.l0_module.target_model.n_layers : Gibt die Anzahl der Ebenen im Zielmodell an.model.l0_module.target_model.intermediate_size : Gibt die Anzahl der Zwischenabmessungen im Zielmodell an.Mit diesen Parametern können Sie den Beschneidungsvorgang gemäß Ihren spezifischen Anforderungen konfigurieren und steuern.
Wir erweitern das StreamingDataset von Steaming in Datasets/Streaming_Dataset.py, um das Laden von Daten dynamisch zu unterstützen. Die Parameter für die Konfiguration der dynamischen Stapelbelastung werden hauptsächlich im DynamicLoadingCallback definiert. Die meisten der folgenden Konfigurationen können in einer YAML -Konfigurationsdatei unter dem Abschnitt callbacks.data_loading " angegeben werden. Hier ist eine Erklärung für jeden Parameter:
callbacks.data_loading.dynamic : Dieser boolesche Parameter bestimmt, ob dynamisches Datenladen aktiviert ist. Wenn auf TRUE eingestellt wird, werden die Daten dynamisch aus verschiedenen Domänen oder Streams geladen. Wenn sie auf False eingestellt sind, ist das Laden der dynamischen Daten deaktiviert.callbacks.data_loading.set_names : Geben Sie die Domänennamen oder Streamnamen an, die für das Laden dynamischer Daten verwendet werden.callbacks.data_loading.proportion : Dieser Parameter definiert den anfänglichen Datenlastanteil für jede Domäne oder jeden Stream. Die Summe aller Anteile muss 1 entsprechen, was die relativen Gewichte jeder Quelle in der anfänglichen Datenbelastungskonfiguration anzeigt.callbacks.data_loading.update_type : Wählen Sie den Aktualisierungstyp zum Anpassen der Datenladungsanteile während des Trainings. Es gibt zwei Optionendoremi : In diesem Modus werden die Datenladenanteile mit einem exponentiellen Abstiegsansatz aktualisiert, ähnlich der in Doremi beschriebenen Methode. Dies ermöglicht die adaptive Anpassung der Datenbelastungsanteile im Laufe der Zeit.constant : Die Auswahl dieser Option hält die Datenladeverhältnisse während des gesamten Trainings konstant. Es entspricht der Deaktivierung der dynamischen Datenbelastung.callbacks.data_loading.target_loss : Geben Sie den Verlust der Zielvalidierung für den Schulungsprozess an. Dieser Zielverlustwert sollte vor Beginn des Trainings berechnet oder vorbestimmt werden. Die Ladeanteile werden basierend auf der Differenz zwischen dem aktuellen Verlust des Modells und dem Zielverlust dynamisch eingestellt. Diese Anpassung hilft dem Trainingsprozess in Richtung des gewünschten Leistungsniveaus.eval_interval : Stellen Sie fest, wie oft Bewertungen während des Trainings durchgeführt werden. Wenn dynamic=True , wird der Datenbelastungsanteil nach jeder Bewertung angepasst.Der Code soll ausschließlich lokale Daten berücksichtigen und keine Fernstreaming -Daten unterstützen. Darüber hinaus funktioniert es derzeit nur mit einem einzelnen Arbeiter für den Dataloader und bietet keine Unterstützung für Vorabschläge. Bei unseren Tests entspricht diese Einschränkung keinen zusätzlichen Rechenaufwand.
Hier ist der gesamte Durchlauf des Beschneidens und des fortgesetzten Vorbereitungsschritts mit A100 80 GB GPUs. Der Durchsatz wird in Bezug auf die pro Sekunde verarbeiteten Token quantifiziert. Bitte beachten Sie den Standarddurchsatz von LLM-Foundry.
| GPUS | Durchsatz pro Gerät | Durchsatz | |
|---|---|---|---|
| Beschneiden 7b | 8 | 1844 | 14750 |
| Vorausbildung 3b | 16 | 4957 | 79306 |
| 1,3b vor der Ausbildung | 16 | 8684 | 138945 |
Quellmodelle : Während große Modelle zweifellos leistungsfähig sind und in naher Zukunft stärker werden, glauben wir, dass kleine Modelle (diejenigen mit weniger als 7 Milliarden Parametern) ein unerschlossenes Potenzial haben. Es gibt jedoch kaum Anstrengungen, um kleine Modelle stärker zu machen, und unsere Arbeit drängt auf dieses Ziel. Eine natürliche Erweiterung dieser Arbeit besteht darin, die Codebasis auf Schnäppchen zu erweitern
Um die Codebasis an andere Modelle anzupassen, besteht eine Schlüsselkomponente darin, sicherzustellen, dass das Ausführen des Modells mit Masken dem Ausführen des beschnittenen Modells entspricht. Wir verwenden LLMShearing/utils/test_pruning.py, um solche Tests auszuführen, um die Richtigkeit der Funktion prune_params in Modelldateien sicherzustellen.
Datenquellen : Beachten Sie bitte, dass die Leistung des resultierenden Modells nicht nur vom Beschneidungsalgorithmus und dem Basismodell, sondern auch auf der Qualität der Daten abhängt. In unseren Experimenten haben wir hauptsächlich die Redpajama V1 -Daten bearbeitet. Hier sind jedoch einige zusätzliche Ressourcen, die für die Aufnahme berücksichtigt werden könnten:
Wenn Sie Fragen zu dem Code oder dem Papier haben, können Sie sich gerne an Mengzhou ([email protected]) senden. Wenn Sie bei der Verwendung des Code auf Probleme stoßen oder einen Fehler melden möchten, können Sie ein Problem öffnen. Bitte versuchen Sie, das Problem mit Details anzugeben, damit wir Ihnen besser und schneller helfen können!
Bitte zitieren Sie unser Papier, wenn Sie das Repo in Ihrer Arbeit hilfreich finden:
@article { xia2023sheared ,
title = { Sheared llama: Accelerating language model pre-training via structured pruning } ,
author = { Xia, Mengzhou and Gao, Tianyu and Zeng, Zhiyuan and Chen, Danqi } ,
journal = { arXiv preprint arXiv:2310.06694 } ,
year = { 2023 }
}

