LLM Shearing
1.0.0
؟ Arxiv preprint | منشور المدونة
النماذج الأساسية: القص-llama-1.3b | القص-لاما -2.7B | القص بيثيا-160 متر
النماذج المشذبة دون استمرار التدريب قبل التدريب: القصاص-llama-1.3b ، مقص ، llama-2.7b
نماذج تعليمات: القص-llama-1.3b-sharegpt | القص-llama-2.7b-sharegpt
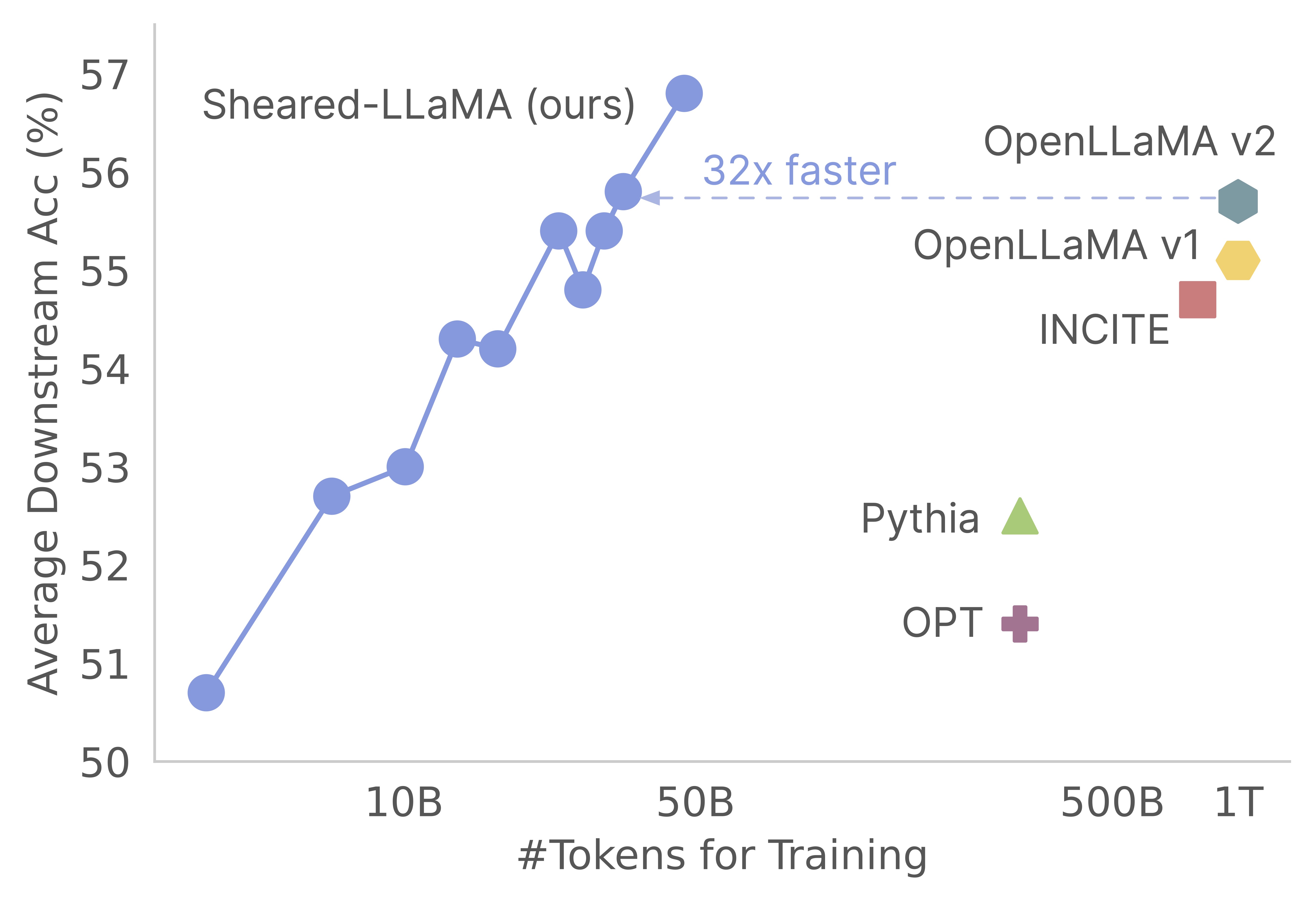
شكرا لك على اهتمامك بعملنا! هذا عمل مشترك من قبل Mengzhou Xia و Tianyu Gao و Zhiyuan Zeng و Danqi Chen. هنا ، نحن نقدم قاعدة الكود الخاصة بنا لخوارزميات التقليم والمستمرة للتدريب المستمرة قبل التدريب :) نجد أن النماذج الأساسية التقليدية هي وسيلة فعالة من حيث التكلفة للغاية للحصول على نماذج لغة صغيرة الحجم قوية مقارنة بتدريبها مسبقًا من نقطة الصفر. يوضح الرسم البياني التالي أنه نظرًا لوجود نموذج LLAMA-2-7B (تم تدريبه مسبقًا مع رموز 2T) ، فإن تقليمه ينتج نموذجًا قويًا مثل نموذج Openllama مع 3 ٪ من تكلفة التدريب قبل التدريب.
تحديث
تم تصميم قاعدة البيانات هذه استنادًا إلى حزمة الملحن المذهلة من Mosaicml ، والتي تم تصميمها وتحسينها خصيصًا لتدريب نموذج اللغة الكبيرة المسبقة. يتم تنفيذ التطبيق بالكامل ، بما في ذلك منطق pruning ومنطق dynamic batch loading ، كوظائف رد الاتصال دون لمس مدرب الملحن الفانيليا. فيما يلي نظرة عامة موجزة على كل مجلد داخل قاعدة الشفرة:
shearing.data : يحتوي على نموذج بيانات ونصوص لمعالجة البيانات.shearing.datasets : ينفذ مجموعات بيانات مخصصة لتمكين تحميل البيانات الديناميكية.shearing.callbacks : ينفذ عمليات الاسترجاعات الديناميكية التحميل وعمليات الاسترجاعات التقليدية.shearing.models : ينفذ ملفات النموذج.shearing.scripts .shearing.utils : يشمل جميع وظائف الأداة المساعدة ، مثل تحويل النماذج واختبارات التقليم.train.py : الدخول الرئيسي لتشغيل الرمز الخطوة 1 : للبدء في هذا المستودع ، ستحتاج إلى اتباع خطوات التثبيت هذه. قبل المتابعة ، تأكد من تثبيت Pytorch و flash الانتباه. يمكنك القيام بذلك عبر PIP باستخدام الأوامر التالية:
pip install torch==2.0.1+cu118 torchvision==0.15.2+cu118 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu118
pip install flash-attn==1.0.3.post
يرجى ملاحظة أن Flash Lunk Version 2 غير مدعوم حاليًا وقد تتطلب تعديلات يدوية على ملف النموذج.
الخطوة 2 : ثم قم بتثبيت بقية الحزم المطلوبة:
cd llmshearing
pip install -r requirement.txt
الخطوة 3 : أخيرًا ، قم بتثبيت حزمة llmshearing في الوضع القابل للتحرير لجعلها في متناول بيئة التطوير الخاصة بك:
pip install -e .
يرجى الرجوع إلى LLMSHEARING/بيانات للحصول على تفاصيل حول كيفية إعداد البيانات باستخدام حزمة دفق MOSAICML.
لاستخدام نماذج محول الوجه المعانقة مع الملحن ، ستحتاج إلى تحويل أوزان النموذج إلى التنسيق الرئيسي المتوقع بواسطة الملحن. فيما يلي مثال على كيفية تحويل الأوزان من نموذج الوجه المعانقة "Llama2" إلى تنسيق متوافق للملحن:
# Define the Hugging Face model name and the output path
HF_MODEL_NAME=meta-llama/Llama-2-7b-hf
OUTPUT_PATH=models/Llama-2-7b-composer/state_dict.pt
# Create the necessary directory if it doesn't exist
mkdir -p $(dirname $OUTPUT_PATH)
# Convert the Hugging Face model to Composer key format
python3 -m llmshearing.utils.composer_to_hf save_hf_to_composer $HF_MODEL_NAME $OUTPUT_PATH
بالإضافة إلى ذلك ، يمكنك استخدام وظيفة الأداة المساعدة التالية لاختبار التكافؤ بين نموذج الوجه المعانقة ونموذج الملحن المحول:
MODEL_SIZE=7B
python3 -m llmshearing.utils.test_composer_hf_eq $HF_MODEL_NAME $OUTPUT_PATH $MODEL_SIZE
هذه الوظائف تعمل بشكل حصري لنماذج LLAMA/LLAMA2. ومع ذلك ، يجب أن يكون من السهل تكييفها للاستخدام مع نماذج أخرى مثل Mistral-7B.
للتقليم ، يمكنك الرجوع إلى برنامج نصي مثال موجود في llmshearing/scripts/pruning.sh . في هذا البرنامج النصي ، ستحتاج إلى إجراء تعديلات لدمج تكوينات البيانات وتكوينات التدريب الأساسية وتكوينات التقليم وتكوينات تحميل الدُفعات الديناميكية.
نظرًا للتكلفة الحسابية المرتفعة نسبيًا للتقليم مقارنة باستمرار التدريب ، فإننا نوقف التدريب مع هدف التقليم بعد عدد محدد من الخطوات (عادةً 3200 خطوة في جميع تجاربنا). بعد ذلك ، نمتلك مزيد من التدريب المسبق للنموذج المشذب. لضمان التوافق ، من الضروري تحويل مفاتيح قاموس الدولة للنموذج للتوافق مع بنية النموذج الهدف القياسية. يمكن العثور على إرشادات مفصلة لهذا التحويل في تحويل النموذج المشذب.
بعد الانتهاء من تحويل النموذج ، يمكنك متابعة تدريب النموذج المسبق. تشبه العملية نموذجًا قياسيًا مسبقًا. للقيام بذلك ، يمكنك الرجوع إلى برنامج نصي مثال موجود في llmshearing/scripts/continue_pretraining.sh . في هذا البرنامج النصي ، يتم القضاء على تكوينات التقليم.
بعد تدريب النموذج ، يمكنك استخدام البرنامج النصي للتحويل لتحويل نموذج الملحن إلى نموذج محولات. يرجى الرجوع إلى القسم تحويل نموذج الملحن إلى نموذج HuggingFace لمزيد من التفاصيل.
بعد الانتهاء من التدريب باستخدام llmshearing/scripts/pruning.sh ، تتكون النماذج المحفوظة من المعلمات الكاملة لنموذج المصدر ، مصحوبة بمجموعة من الأقنعة. نتصرف بعد ذلك على متغيرات التقنيع بحلول 1) إزالة البنى التحتية حيث تقترب متغيرات التقني
MODEL_PATH=$MODEL_DIR/latest-rank0.pt
python3 -m llmshearing.utils.post_pruning_processing prune_and_save_model $MODEL_PATH
سيتم حفظ النموذج المشذب في $(dirname $MODEL_PATH)/pruned-latest-rank0.pt .
بعد التدريب ، إذا كنت ترغب في استخدام HuggingFace للاستدلال أو التغلب ، فيمكنك اختيار تحويل نموذج الملحن الخاص بك إلى نموذج وجه معانقة باستخدام برنامج llmshearing/scripts/composer_to_hf.py . إليك مثال على كيفية استخدام البرنامج النصي:
MODEL_PATH=$MODEL_DIR/latest-rank0.pt
OUTPUT_PATH=$MODEL_DIR/hf-latest_rank0
MODEL_CLASS=LlamaForCausalLM
HIDDEN_SIZE=2048
NUM_ATTENTION_HEADS=16
NUM_HIDDEN_LAYERS=24
INTERMEDIATE_SIZE=5504
MODEL_NAME=Sheared-Llama-1.3B
python3 -m llmshearing.utils.composer_to_hf save_composer_to_hf $MODEL_PATH $OUTPUT_PATH
model_class=${MODEL_CLASS}
hidden_size=${HIDDEN_SIZE}
num_attention_heads=${NUM_ATTENTION_HEADS}
num_hidden_layers=${NUM_HIDDEN_LAYERS}
intermediate_size=${INTERMEDIATE_SIZE}
num_key_value_heads=${NUM_ATTENTION_HEADS}
_name_or_path=${MODEL_NAME}
يرجى العلم أن أسماء المعلمات المذكورة هنا مصممة لتكوينات وجه LLAMA2 وقد تختلف عند التعامل مع أنواع النماذج الأخرى.
في هذا القسم ، نقدم دليلًا متعمقًا على تكوين المعلمات داخل ملفات تكوين YAML للتدريب. تشمل هذه التكوينات العديد من الجوانب الرئيسية ، بما في ذلك إعداد البيانات ، وإعدادات التدريب الأساسية ، وإعدادات التقليم ، وتكوينات تحميل البيانات الديناميكية.
data_local : الدليل المحلي يحتوي على البيانات.eval_loader.dataset.split : للتقييم ، قم بتوفير اسم الانقسام المشترك الذي يتضمن بيانات من جميع المجالات.train_loader.dataset.split : عندما يكون dynamic=True (يرجى الرجوع إلى قسم التحميل الديناميكي) في تكوين التحميل الديناميكي ، فلا داعي لضبط هذه القيمة. ومع ذلك ، إذا كان dynamic=False ، فيجب عليك تحديد تقسيم التدريب. تتبع تكوينات التدريب الأساسية حزمة Composer الأصلية إلى حد كبير. للحصول على تفاصيل شاملة حول هذه التكوينات ، يرجى الرجوع إلى الوثائق الرسمية للملحن. فيما يلي بعض معلمات التدريب الرئيسية التي يجب علماها عن:
max_duration : تحدد هذه المعلمة الحد الأقصى مدة التدريب ويمكن تحديدها في عدد الخطوات (على سبيل المثال ، 3200ba ) أو الحقبة (على سبيل المثال ، 1ep ). في تجاربنا ، تم تعيين مدة التقليم على 3200ba ، وتم تعيين مدة ما قبل التدريب المستمرة على 48000ba .save_interval : تحدد هذه المعلمة مدى تواتر حالة النموذج. لقد وضعناها على 3200ba لكل من مراحل التقليم والمستمرة قبل التدريب ..t_warmup : تحدد هذه المعلمة مدة معدل الاحماء في معدل التعلم لجدولة معدل التعلم. في حالة التقليم ، يتم تعيينه على 320ba ( optimizer.lr : تحدد هذه المعلمة معدل التعلم لمعلمات النموذج الأساسي ، مع القيمة الافتراضية هي 1e-4 .max_seq_len : بعد منهجية التدريب LLAMA 2 ، نستوعب طول تسلسل أقصى قدره 4096.device_train_microbatch_size : تحدد هذه المعلمة حجم الدُفعة لكل جهاز أثناء التدريب. بالنسبة لمرحلة التقليم ، نقوم بتكوينه إلى 4 ، في حين يتم تعيينه إلى 16 .global_train_batch_size : تحدد هذه المعلمة حجم الدفعة العالمية عبر جميع وحدات معالجة الرسومات أثناء التدريب. خلال مرحلة التقليم ، تم تكوينه على أنه 32 ، بينما يتم زيادة التدريب المسبق ، إلى 256 .autoresume : يمكن تمكين هذه المعلمة عن طريق تعيينها على true عند استئناف التشغيل. ومع ذلك ، من المهم أن نلاحظ أنه على الرغم من أننا استخدمناها بنجاح خلال مرحلة التدريب المستمر ، لا يوجد أي ضمان لتوافقه مع مرحلة التقليم.بسبب القيود الحسابية ، لم يتم إجراء بحث شامل في مقياس الفائقة ، وقد توجد معلمات كبيرة بشكل أفضل لتحسين الأداء.
تسمح عملية التقليم بتقليم نموذج المصدر إلى شكل مستهدف محدد ، ويتضمن البرنامج النصي معلمات أساسية مثل:
from_model : تحدد هذه المعلمة حجم نموذج المصدر وتتوافق مع config_file.to_model : تحدد هذه المعلمة حجم النموذج الهدف ، وسيتم تقليم النموذج المصدر لمطابقة التكوين الهدف.optimizer.lag_lr : تحدد هذه المعلمة معدل التعلم لتعلم متغيرات التقنيع ومضاعفات Lagrangian أثناء التقليم. القيمة الافتراضية هي يتم تجميع جميع الوسائط الخاصة بالتقليم بموجب model.l0_module :
model.l0_module.lagrangian_warmup_steps : في مرحلة الاحماء الأولية ، يرتفع معدل التقليم بشكل تدريجي من 0 للوصول إلى القيمة الهدف المطلوبة. يتم تحديد القيمة المستهدفة المحددة بواسطة الهيكل المحدد مسبقًا للنموذج الهدف. من المهم أن نلاحظ أن هذه القيمة قد تختلف عن خطوات الاحماء المرتبطة بمعدلات التعلم. عادةً ما نخصص ما يقرب من 20 ٪ من إجمالي عدد الخطوات لعملية الاحماء التقليدية هذه.model.l0_module.pruning_modules : افتراضيًا ، يتقدم هذا الإعداد جوانب مختلفة من النموذج ، بما في ذلك الرأس ، والأبعاد الوسيطة ، والأبعاد المخفية ، والطبقات.model.l0_module.eval_target_model : عند ضبطه على صواب ، تقوم عملية التقييم بتقييم نموذج فرعي يطابق بنية النموذج الهدف بالضبط. إذا تم ضبطها على خطأ ، فإن عملية التقييم تنظر في النموذج الحالي ، مع مراعاة قيم التقنيع. نظرًا لأن القناع قد يستغرق بعض الوقت للتقارب مع شكل النموذج المستهدف ، فإننا نقوم بتقييمه بناءً على شكل النموذج الحالي بدلاً من الهيكل المستهدف أثناء التدريب.model.l0_module.target_model.d_model : يحدد البعد المخفي للنموذج الهدف.model.l0_module.target_model.n_heads : يحدد عدد الرؤوس في النموذج الهدف.model.l0_module.target_model.n_layers : يحدد عدد الطبقات في النموذج الهدف.model.l0_module.target_model.intermediate_size : يحدد عدد الأبعاد الوسيطة في النموذج الهدف.تتيح لك هذه المعلمات تكوين عملية التقليم والتحكم فيها وفقًا لمتطلباتك المحددة.
نقوم بتمديد StreamingDatAset من Streaming في مجموعات البيانات/treaming_dataset.py لدعم تحميل البيانات ديناميكيًا. يتم تعريف المعلمات لتكوين تحميل الدُفعات الديناميكية بشكل أساسي داخل DynamicLoadingCallback . يمكن تحديد معظم التكوينات التالية في ملف تكوين YAML ضمن قسم callbacks.data_loading . إليك شرح لكل معلمة:
callbacks.data_loading.dynamic : تحدد هذه المعلمة المنطقية ما إذا كان يتم تمكين تحميل البيانات الديناميكية. عند التعيين على صحيح ، يتم تحميل البيانات ديناميكيًا من مختلف المجالات أو التدفقات. إذا تم ضبط تحميل البيانات الديناميكية ، يتم تعطيل تحميل البيانات الديناميكية.callbacks.data_loading.set_names : حدد أسماء المجال أو أسماء الدفق التي سيتم استخدامها لتحميل البيانات الديناميكية.callbacks.data_loading.proportion : تحدد هذه المعلمة نسبة تحميل البيانات الأولية لكل مجال أو دفق. يجب أن يساوي مجموع جميع النسب 1 ، مما يشير إلى الأوزان النسبية لكل مصدر في تكوين تحميل البيانات الأولي.callbacks.data_loading.update_type : اختر نوع التحديث لضبط نسب تحميل البيانات أثناء التدريب. هناك خيارانdoremi : في هذا الوضع ، يتم تحديث نسب تحميل البيانات باستخدام نهج النسب الأسي ، على غرار الطريقة الموضحة في Doremi. هذا يسمح بالتعديل التكيفي لنسب تحميل البيانات مع مرور الوقت.constant : تحديد هذا الخيار يبقي نسب تحميل البيانات ثابتة طوال التدريب. يعادل تعطيل تحميل البيانات الديناميكية.callbacks.data_loading.target_loss : حدد خسارة التحقق من الصحة الهدف لعملية التدريب. يجب حساب قيمة الخسارة المستهدفة هذه أو محددة مسبقًا قبل بدء التدريب. سيتم ضبط نسب التحميل ديناميكيًا بناءً على الفرق بين الخسارة الحالية للنموذج والخسارة المستهدفة. يساعد هذا التعديل في توجيه عملية التدريب نحو مستوى الأداء المطلوب.eval_interval : حدد عدد المرات التي يتم فيها إجراء التقييمات أثناء التدريب. إذا كان dynamic=True ، فسيتم تعديل نسبة تحميل البيانات بعد كل تقييم.تم تصميم الرمز لاستيعاب البيانات المحلية بشكل حصري ولا يدعم بيانات البث عن بُعد. بالإضافة إلى ذلك ، تعمل حاليًا فقط مع عامل واحد لـ Dataloader ولا يقدم دعمًا مسبقًا. في اختباراتنا ، لا يتحمل هذا التقييد أي نقاط حسابية إضافية.
هنا هو في جميع أنحاء تشغيل خطوة التقليم والمستمرة قبل معالجة الرسومات A100 80GB. يتم قياس الإنتاجية كمية من حيث الرموز التي تمت معالجتها في الثانية. يرجى الرجوع إلى الإنتاجية القياسية لـ LLM-Foundry.
| وحدات معالجة الرسومات | إنتاجية لكل جهاز | إنتاجية | |
|---|---|---|---|
| التقليم 7 ب | 8 | 1844 | 14750 |
| قبل التدريب 3B | 16 | 4957 | 79306 |
| قبل التدريب 1.3B | 16 | 8684 | 138945 |
نماذج المصدر : على الرغم من أن النماذج الكبيرة قوية بلا شك ولديها القدرة على أن تصبح أقوى في المستقبل القريب ، فإننا نعتقد أن النماذج الصغيرة (تلك التي لديها أقل من 7 مليارات معلمات) لها إمكانات غير مستغلة. ومع ذلك ، هناك القليل من الجهد المخصص لجعل نماذج صغيرة أقوى ، ويدفع عملنا نحو هذا الهدف. امتداد طبيعي لهذا العمل هو تمديد قاعدة الشفرة إلى التقليم
لتكييف قاعدة الشفرة مع النماذج الأخرى ، يتمثل أحد مكونات المفاتيح في التأكد من أن تشغيل النموذج بالأقنعة يعادل تشغيل النموذج المشقوق. نحن نستخدم llmshearing/utils/test_pruning.py لتشغيل مثل هذه الاختبارات لضمان صحة الوظيفة prune_params في ملفات النماذج.
مصادر البيانات : يرجى مراعاة أن أداء النموذج الناتج لا يتوقف فقط على خوارزمية التقليم والنموذج الأساسي ولكن أيضًا على جودة البيانات. في تجاربنا ، عملنا بشكل أساسي على بيانات Redpajama V1. ومع ذلك ، إليك بعض الموارد الإضافية التي يمكن اعتبارها لإدراجها:
إذا كانت لديك أي أسئلة تتعلق بالرمز أو الورقة ، فلا تتردد في إرسال بريد إلكتروني إلى Mengzhou ([email protected]). إذا واجهت أي مشاكل عند استخدام الرمز ، أو ترغب في الإبلاغ عن خطأ ، فيمكنك فتح مشكلة. يرجى محاولة تحديد المشكلة مع التفاصيل حتى نتمكن من مساعدتك بشكل أفضل وأسرع!
يرجى الاستشهاد بالورقة إذا وجدت أن الريبو مفيد في عملك:
@article { xia2023sheared ,
title = { Sheared llama: Accelerating language model pre-training via structured pruning } ,
author = { Xia, Mengzhou and Gao, Tianyu and Zeng, Zhiyuan and Chen, Danqi } ,
journal = { arXiv preprint arXiv:2310.06694 } ,
year = { 2023 }
}

