LLM Shearing
1.0.0
- arxiv preprint | โพสต์บล็อก
โมเดลพื้นฐาน: Sheared-llama-1.3b | Sheared-llama-2.7b | Sheared-Pythia-160m
แบบจำลองการตัดแต่งโดยไม่ต้องฝึกอบรมอย่างต่อเนื่อง: sheared-llama-1.3b-gruned, sheared-llama-2.7b-huned
โมเดลที่ได้รับการปรับแต่ง: Sheared-llama-1.3b-Sharegpt | Sheared-llama-2.7b-sharegpt
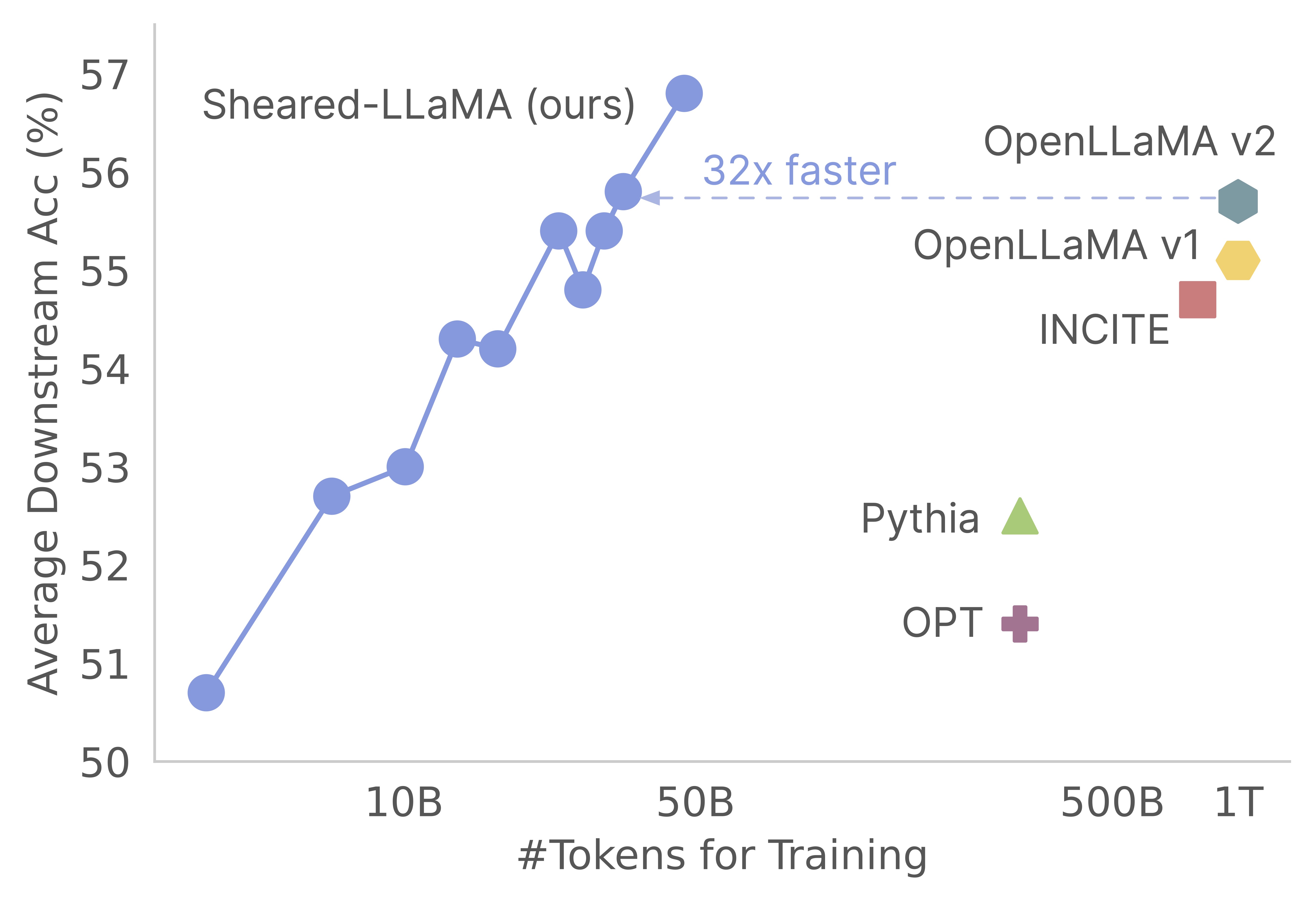
ขอบคุณสำหรับความสนใจในงานของเรา! นี่คืองานร่วมกันโดย Mengzhou Xia, Tianyu Gao, Zhiyuan Zeng และ Danqi Chen ที่นี่เราให้รหัสฐานของเราสำหรับการตัดแต่งกิ่งของ Sheared-Llama และอัลกอริทึมการฝึกอบรมล่วงหน้าอย่างต่อเนื่อง :) เราพบว่าการตัดแต่งกิ่งแบบจำลองที่แข็งแกร่งเป็นวิธีที่คุ้มค่าอย่างยิ่งในการรับรุ่นภาษาขนาดเล็กที่แข็งแกร่งเมื่อเทียบกับการฝึกอบรมก่อน กราฟต่อไปนี้แสดงให้เห็นว่าการมีอยู่ของโมเดล Llama-2-7B (ได้รับการฝึกอบรมล่วงหน้าด้วยโทเค็น 2T) การตัดแต่งมันสร้างแบบจำลองที่แข็งแกร่งเท่ากับโมเดล Openllama ที่มีค่าใช้จ่ายก่อนการฝึกอบรม 3%
อัปเดต
codebase นี้สร้างขึ้นตามแพ็คเกจนักแต่งเพลงที่น่าทึ่งของ MosaicML ซึ่งได้รับการออกแบบมาเป็นพิเศษและปรับให้เหมาะสมสำหรับแบบจำลองภาษาขนาดใหญ่ก่อนการฝึกอบรม การใช้งานทั้งหมดรวมถึงตรรกะ pruning และตรรกะ dynamic batch loading ถูกนำมาใช้เป็นฟังก์ชั่นการโทรกลับโดยไม่ต้องแตะต้องผู้ฝึกสอนนักแต่งเพลงวานิลลา นี่คือภาพรวมที่กระชับของแต่ละโฟลเดอร์ภายใน codebase:
shearing.data : มีข้อมูลตัวอย่างและสคริปต์สำหรับการประมวลผลข้อมูลshearing.datasets : ใช้ชุดข้อมูลที่กำหนดเองเพื่อเปิดใช้งานการโหลดข้อมูลแบบไดนามิกshearing.callbacks : ใช้การโหลดการเรียกกลับแบบไดนามิกและการตัดกลับการตัดแต่งกิ่งshearing.models : ใช้ไฟล์โมเดลshearing.scripts : มีสคริปต์สำหรับเรียกใช้รหัสshearing.utils : รวมฟังก์ชั่นยูทิลิตี้ทั้งหมดเช่นการแปลงแบบจำลองและการทดสอบการตัดแต่งกิ่งtrain.py : รายการหลักของการเรียกใช้รหัส ขั้นตอนที่ 1 : ในการเริ่มต้นกับที่เก็บนี้คุณจะต้องทำตามขั้นตอนการติดตั้งเหล่านี้ ก่อนที่จะดำเนินการตรวจสอบให้แน่ใจว่าคุณติดตั้ง Pytorch และ Flash Attention คุณสามารถทำได้ผ่าน PIP โดยใช้คำสั่งต่อไปนี้:
pip install torch==2.0.1+cu118 torchvision==0.15.2+cu118 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu118
pip install flash-attn==1.0.3.post
โปรดทราบว่าไม่รองรับ Flash Attention เวอร์ชัน 2 ในปัจจุบันและอาจต้องมีการแก้ไขด้วยตนเองในไฟล์โมเดล
ขั้นตอนที่ 2 : จากนั้นติดตั้งส่วนที่เหลือของแพ็คเกจที่ต้องการ:
cd llmshearing
pip install -r requirement.txt
ขั้นตอนที่ 3 : สุดท้ายติดตั้งแพ็คเกจ llmshearing ในโหมดแก้ไขได้เพื่อให้สามารถเข้าถึงได้สำหรับสภาพแวดล้อมการพัฒนาของคุณ:
pip install -e .
โปรดดูที่ LLMShearing/Data สำหรับรายละเอียดเกี่ยวกับวิธีการเตรียมข้อมูลด้วยแพ็คเกจสตรีมมิ่งของ MosaicML
ในการใช้โมเดลหม้อแปลงใบหน้ากอดด้วยนักแต่งเพลงคุณจะต้องแปลงน้ำหนักรุ่นเป็นรูปแบบคีย์ที่คาดหวังโดยนักแต่งเพลง นี่คือตัวอย่างของวิธีการแปลงน้ำหนักจากรูปแบบการกอดใบหน้า 'llama2' เป็นรูปแบบที่เข้ากันได้สำหรับนักแต่งเพลง:
# Define the Hugging Face model name and the output path
HF_MODEL_NAME=meta-llama/Llama-2-7b-hf
OUTPUT_PATH=models/Llama-2-7b-composer/state_dict.pt
# Create the necessary directory if it doesn't exist
mkdir -p $(dirname $OUTPUT_PATH)
# Convert the Hugging Face model to Composer key format
python3 -m llmshearing.utils.composer_to_hf save_hf_to_composer $HF_MODEL_NAME $OUTPUT_PATH
นอกจากนี้คุณสามารถใช้ฟังก์ชั่นยูทิลิตี้ต่อไปนี้เพื่อทดสอบความเท่าเทียมกันระหว่างโมเดลใบหน้ากอดและโมเดลนักแต่งเพลงที่แปลงแล้ว:
MODEL_SIZE=7B
python3 -m llmshearing.utils.test_composer_hf_eq $HF_MODEL_NAME $OUTPUT_PATH $MODEL_SIZE
ฟังก์ชั่นเหล่านี้ใช้งานได้เฉพาะสำหรับรุ่น LLAMA/LLAMA2 อย่างไรก็ตามมันควรจะตรงไปตรงมาเพื่อปรับให้เข้ากับรุ่นอื่น ๆ เช่น Mistral-7b
สำหรับการตัดแต่งกิ่งคุณสามารถอ้างอิงสคริปต์ตัวอย่างที่อยู่ใน llmshearing/scripts/pruning.sh ในสคริปต์นี้คุณจะต้องทำการปรับเปลี่ยนเพื่อรวมการกำหนดค่าข้อมูลการกำหนดค่าการฝึกอบรมขั้นพื้นฐานการกำหนดค่าการตัดแต่งกิ่งและการกำหนดค่าการโหลดแบทช์แบบไดนามิก
เนื่องจากค่าใช้จ่ายในการคำนวณที่ค่อนข้างสูงเมื่อเทียบกับการฝึกอบรมก่อนการฝึกอบรมอย่างต่อเนื่องเราจึงหยุดการฝึกอบรมด้วยวัตถุประสงค์การตัดแต่งกิ่งหลังจากขั้นตอนที่เฉพาะเจาะจง (โดยทั่วไปคือ 3200 ขั้นตอนในการทดลองทั้งหมดของเรา) ต่อจากนั้นเราดำเนินการต่อไปก่อนการฝึกอบรมแบบจำลองการตัดแต่งเพิ่มเติม เพื่อให้แน่ใจว่าเข้ากันได้จำเป็นต้องแปลงคีย์พจนานุกรมสถานะของแบบจำลองเพื่อให้สอดคล้องกับโครงสร้างโมเดลเป้าหมายมาตรฐาน คำแนะนำโดยละเอียดสำหรับการแปลงนี้สามารถพบได้ที่ Convert Pruned Model
หลังจากเสร็จสิ้นการแปลงโมเดลคุณสามารถดำเนินการต่อไปด้วยการฝึกอบรมก่อนการตัดแต่งแบบจำลอง กระบวนการนี้คล้ายกับการฝึกอบรมแบบจำลองมาตรฐานล่วงหน้า ในการทำเช่นนี้คุณสามารถอ้างถึงสคริปต์ตัวอย่างที่อยู่ที่ llmshearing/scripts/continue_pretraining.sh ในสคริปต์นี้การกำหนดค่าการตัดแต่งกิ่งจะถูกกำจัด
หลังจากฝึกอบรมโมเดลคุณสามารถใช้สคริปต์การแปลงเพื่อแปลงโมเดลนักแต่งเพลงให้เป็นโมเดล Transformers โปรดดูที่ Section Convert Composer Model เป็น HuggingFace Model สำหรับรายละเอียดเพิ่มเติม
หลังจากเสร็จสิ้นการฝึกอบรมโดยใช้ llmshearing/scripts/pruning.sh โมเดลที่บันทึกไว้ประกอบด้วยพารามิเตอร์ทั้งหมดของโมเดลแหล่งที่มาพร้อมกับชุดหน้ากาก จากนั้นเราจะดำเนินการกับตัวแปรการกำบังโดย 1) การลบโครงสร้างย่อยที่ตัวแปรการปิดบังอยู่ใกล้
MODEL_PATH=$MODEL_DIR/latest-rank0.pt
python3 -m llmshearing.utils.post_pruning_processing prune_and_save_model $MODEL_PATH
รูปแบบการตัดแต่งจะถูกบันทึกไว้ใน $(dirname $MODEL_PATH)/pruned-latest-rank0.pt
หลังจากการฝึกอบรมหากคุณต้องการใช้ HuggingFace สำหรับการอนุมานหรือการปรับแต่งคุณอาจเลือกที่จะแปลงโมเดลนักแต่งเพลงของคุณให้เป็นแบบจำลองการกอดโดยใช้สคริปต์ llmshearing/scripts/composer_to_hf.py นี่คือตัวอย่างของวิธีการใช้สคริปต์:
MODEL_PATH=$MODEL_DIR/latest-rank0.pt
OUTPUT_PATH=$MODEL_DIR/hf-latest_rank0
MODEL_CLASS=LlamaForCausalLM
HIDDEN_SIZE=2048
NUM_ATTENTION_HEADS=16
NUM_HIDDEN_LAYERS=24
INTERMEDIATE_SIZE=5504
MODEL_NAME=Sheared-Llama-1.3B
python3 -m llmshearing.utils.composer_to_hf save_composer_to_hf $MODEL_PATH $OUTPUT_PATH
model_class=${MODEL_CLASS}
hidden_size=${HIDDEN_SIZE}
num_attention_heads=${NUM_ATTENTION_HEADS}
num_hidden_layers=${NUM_HIDDEN_LAYERS}
intermediate_size=${INTERMEDIATE_SIZE}
num_key_value_heads=${NUM_ATTENTION_HEADS}
_name_or_path=${MODEL_NAME}
โปรดทราบว่าชื่อพารามิเตอร์ที่กล่าวถึงที่นี่ได้รับการปรับให้เหมาะกับการกำหนดค่าใบหน้ากอดของ Llama2 และอาจแตกต่างกันเมื่อจัดการกับรุ่นอื่น ๆ
ในส่วนนี้เรามีคู่มือเชิงลึกเกี่ยวกับการกำหนดค่าพารามิเตอร์ภายในไฟล์การกำหนดค่า YAML สำหรับการฝึกอบรม การกำหนดค่าเหล่านี้ครอบคลุมหลายแง่มุมที่สำคัญรวมถึงการตั้งค่าข้อมูลการตั้งค่าการฝึกอบรมขั้นพื้นฐานการตั้งค่าการตัดแต่งกิ่งและการกำหนดค่าการโหลดข้อมูลแบบไดนามิก
data_local : ไดเรกทอรีท้องถิ่นที่มีข้อมูลeval_loader.dataset.split : สำหรับการประเมินให้ระบุชื่อของการแยกรวมที่รวมข้อมูลจากโดเมนทั้งหมดtrain_loader.dataset.split : เมื่อ dynamic=True (โปรดดูส่วนการโหลดแบบไดนามิก) ในการกำหนดค่าการโหลดแบบไดนามิกไม่จำเป็นต้องตั้งค่านี้ อย่างไรก็ตามหาก dynamic=False คุณต้องระบุการแยกการฝึกอบรม การกำหนดค่าการฝึกอบรมขั้นพื้นฐานส่วนใหญ่ทำตามแพ็คเกจ Composer ดั้งเดิม สำหรับรายละเอียดที่ครอบคลุมเกี่ยวกับการกำหนดค่าเหล่านี้โปรดดูเอกสารอย่างเป็นทางการของนักแต่งเพลง นี่คือพารามิเตอร์การฝึกอบรมที่สำคัญบางประการที่จะจดบันทึก:
max_duration : พารามิเตอร์นี้กำหนดระยะเวลาการฝึกอบรมสูงสุดและสามารถระบุได้ในจำนวนขั้นตอน (เช่น 3200ba ) หรือยุค (เช่น 1ep ) ในการทดลองของเราระยะเวลาการตัดแต่งกิ่งถูกกำหนดเป็น 3200ba และระยะเวลาการฝึกอบรมก่อนการฝึกอบรมอย่างต่อเนื่องถูกกำหนดเป็น 48000basave_interval : พารามิเตอร์นี้กำหนดว่าสถานะโมเดลจะถูกบันทึกบ่อยแค่ไหน เราตั้งค่าเป็น 3200ba สำหรับทั้งการตัดแต่งกิ่งและขั้นตอนการฝึกอบรมล่วงหน้าต่อไป ..t_warmup : พารามิเตอร์นี้ระบุระยะเวลาของการอุ่นเครื่องอัตราการเรียนรู้สำหรับตัวกำหนดค่าอัตราการเรียนรู้ ในกรณีของการตัดแต่งกิ่งมันถูกตั้งค่าเป็น 320ba ( optimizer.lr : พารามิเตอร์นี้กำหนดอัตราการเรียนรู้สำหรับพารามิเตอร์โมเดลหลักโดยค่าเริ่มต้นคือ 1e-4max_seq_len : ตามวิธีการฝึกอบรม LLAMA 2 เรารองรับความยาวลำดับสูงสุด 4096device_train_microbatch_size : พารามิเตอร์นี้กำหนดขนาดแบทช์ต่ออุปกรณ์ในระหว่างการฝึกอบรม สำหรับขั้นตอนการตัดแต่งกิ่งเราจะกำหนดค่าเป็น 4 ในขณะที่การฝึกอบรมล่วงหน้าอย่างต่อเนื่องมันถูกตั้งค่าเป็น 16global_train_batch_size : พารามิเตอร์นี้ระบุขนาดแบทช์ทั่วโลกใน GPU ทั้งหมดในระหว่างการฝึกอบรม ในระหว่างขั้นตอนการตัดแต่งกิ่งมันถูกกำหนดค่าเป็น 32 ในขณะที่สำหรับการฝึกอบรมก่อนการฝึกอบรมอย่างต่อเนื่องมันจะเพิ่มขึ้นเป็น 256autoresume : พารามิเตอร์นี้สามารถเปิดใช้งานได้โดยการตั้งค่าเป็น true เมื่อกลับมาทำงานต่อ อย่างไรก็ตามเป็นสิ่งสำคัญที่จะต้องทราบว่าในขณะที่เราใช้มันสำเร็จในช่วงระยะเวลาการเตรียมการอย่างต่อเนื่องไม่มีการรับประกันความเข้ากันได้กับขั้นตอนการตัดแต่งกิ่งเนื่องจากข้อ จำกัด ด้านการคำนวณการค้นหาไฮเปอร์พารามิเตอร์ที่ละเอียดถี่ถ้วนจึงไม่ได้ดำเนินการและอาจมีพารามิเตอร์ไฮเปอร์ที่ดีกว่าสำหรับประสิทธิภาพที่ดีขึ้น
กระบวนการตัดแต่งกิ่งช่วยให้การตัดแต่งโมเดลต้นทางเป็นรูปร่างเป้าหมายเฉพาะและสคริปต์รวมถึงพารามิเตอร์ที่จำเป็นเช่น:
from_model : พารามิเตอร์นี้ระบุขนาดของรุ่นต้นทางและสอดคล้องกับ config_fileto_model : พารามิเตอร์นี้กำหนดขนาดโมเดลเป้าหมายและรุ่นต้นทางจะถูกตัดแต่งเพื่อให้ตรงกับการกำหนดค่าเป้าหมายoptimizer.lag_lr : พารามิเตอร์นี้ระบุอัตราการเรียนรู้เพื่อเรียนรู้ตัวแปรการกำบังและตัวทวีคูณลากรองจ์ในระหว่างการตัดแต่งกิ่ง ค่าเริ่มต้นคือ อาร์กิวเมนต์การตัดแต่งเฉพาะถูกจัดกลุ่มทั้งหมดภายใต้ model.l0_module :
model.l0_module.lagrangian_warmup_steps : ในขั้นตอนการอุ่นเครื่องเริ่มต้นอัตราการตัดแต่งเพิ่มขึ้นจาก 0 เพื่อไปยังค่าเป้าหมายที่ต้องการ ค่าเป้าหมายเฉพาะถูกกำหนดโดยโครงสร้างที่กำหนดไว้ล่วงหน้าของโมเดลเป้าหมาย สิ่งสำคัญคือต้องทราบว่าค่านี้อาจแตกต่างจากขั้นตอนการอุ่นเครื่องที่เกี่ยวข้องกับอัตราการเรียนรู้ โดยทั่วไปเราจัดสรรประมาณ 20% ของจำนวนขั้นตอนทั้งหมดสำหรับกระบวนการอุ่นเครื่องการตัดแต่งกิ่งนี้model.l0_module.pruning_modules : โดยค่าเริ่มต้นการตั้งค่านี้ prunes ด้านต่าง ๆ ของโมเดลรวมถึงหัวขนาดกลางขนาดที่ซ่อนอยู่และเลเยอร์model.l0_module.eval_target_model : เมื่อตั้งค่าเป็นจริงกระบวนการประเมินผลจะประเมิน submodel ที่ตรงกับโครงสร้างของโมเดลเป้าหมาย หากตั้งค่าเป็นเท็จกระบวนการประเมินผลจะพิจารณาโมเดลปัจจุบันโดยคำนึงถึงค่าการปิดบัง เนื่องจากหน้ากากอาจใช้เวลาพอสมควรในการบรรจบกันกับรูปร่างของโมเดลเป้าหมายเราจึงประเมินตามรูปร่างของโมเดลปัจจุบันมากกว่าโครงสร้างเป้าหมายในระหว่างการฝึกอบรมmodel.l0_module.target_model.d_model : ระบุมิติที่ซ่อนอยู่ของโมเดลเป้าหมายmodel.l0_module.target_model.n_heads : ระบุจำนวนหัวในรุ่นเป้าหมายmodel.l0_module.target_model.n_layers : ระบุจำนวนเลเยอร์ในโมเดลเป้าหมายmodel.l0_module.target_model.intermediate_size : ระบุจำนวนขนาดกลางในโมเดลเป้าหมายพารามิเตอร์เหล่านี้ช่วยให้คุณกำหนดค่าและควบคุมกระบวนการตัดแต่งกิ่งตามข้อกำหนดเฉพาะของคุณ
เราขยาย StreamingDataset ของ Steaming ในชุดข้อมูล/streaming_dataset.py เพื่อรองรับการโหลดข้อมูลแบบไดนามิก พารามิเตอร์สำหรับการกำหนดค่าการโหลดแบทช์แบบไดนามิกส่วนใหญ่จะถูกกำหนดไว้ใน DynamicLoadingCallback เป็นหลัก การกำหนดค่าส่วนใหญ่ต่อไปนี้สามารถระบุได้ในไฟล์การกำหนดค่า YAML ภายใต้ส่วน callbacks.data_loading นี่คือคำอธิบายของแต่ละพารามิเตอร์:
callbacks.data_loading.dynamic : พารามิเตอร์บูลีนนี้กำหนดว่าเปิดใช้งานการโหลดข้อมูลแบบไดนามิกหรือไม่ เมื่อตั้งค่าเป็นจริงข้อมูลจะถูกโหลดแบบไดนามิกจากโดเมนหรือสตรีมต่างๆ หากตั้งค่าเป็นเท็จการโหลดข้อมูลแบบไดนามิกจะถูกปิดใช้งานcallbacks.data_loading.set_names : ระบุชื่อโดเมนหรือชื่อสตรีมที่จะใช้สำหรับการโหลดข้อมูลแบบไดนามิกcallbacks.data_loading.proportion : พารามิเตอร์นี้กำหนดสัดส่วนการโหลดข้อมูลเริ่มต้นสำหรับแต่ละโดเมนหรือสตรีม ผลรวมของสัดส่วนทั้งหมดจะต้องเท่ากับ 1 แสดงน้ำหนักสัมพัทธ์ของแต่ละแหล่งในการกำหนดค่าการโหลดข้อมูลเริ่มต้นcallbacks.data_loading.update_type : เลือกประเภทการอัปเดตสำหรับการปรับสัดส่วนการโหลดข้อมูลระหว่างการฝึกอบรม มีสองตัวเลือกdoremi : ในโหมดนี้สัดส่วนการโหลดข้อมูลจะได้รับการปรับปรุงโดยใช้วิธีการสืบเชื้อสายแบบเอ็กซ์โปเนนเชียลคล้ายกับวิธีที่อธิบายไว้ใน Doremi สิ่งนี้ช่วยให้สามารถปรับสัดส่วนการโหลดข้อมูลได้เมื่อเวลาผ่านไปconstant : การเลือกตัวเลือกนี้ช่วยให้สัดส่วนการโหลดข้อมูลคงที่ตลอดการฝึกอบรม เทียบเท่ากับการปิดใช้งานการโหลดข้อมูลแบบไดนามิกcallbacks.data_loading.target_loss : ระบุการสูญเสียการตรวจสอบเป้าหมายสำหรับกระบวนการฝึกอบรม ค่าการสูญเสียเป้าหมายนี้ควรคำนวณหรือกำหนดไว้ล่วงหน้าก่อนเริ่มการฝึกอบรม สัดส่วนการโหลดจะถูกปรับแบบไดนามิกตามความแตกต่างระหว่างการสูญเสียปัจจุบันของโมเดลและการสูญเสียเป้าหมาย การปรับนี้ช่วยเป็นแนวทางในกระบวนการฝึกอบรมสู่ระดับประสิทธิภาพที่ต้องการeval_interval : กำหนดความถี่ในการประเมินระหว่างการฝึกอบรม หาก dynamic=True สัดส่วนการโหลดข้อมูลจะถูกปรับหลังจากการประเมินแต่ละครั้งรหัสได้รับการออกแบบมาเพื่อรองรับข้อมูลท้องถิ่นโดยเฉพาะและไม่รองรับข้อมูลการสตรีมระยะไกล นอกจากนี้ปัจจุบันมีเพียงฟังก์ชั่นที่มีผู้ปฏิบัติงานคนเดียวสำหรับ Dataloader และไม่ได้ให้การสนับสนุน Prefetch ในการทดสอบของเราข้อ จำกัด นี้ไม่ได้มีค่าใช้จ่ายเพิ่มเติมใด ๆ
นี่คือตลอดการดำเนินการตัดแต่งกิ่งและยังคงดำเนินต่อไปด้วย A100 80GB GPU ปริมาณงานจะถูกหาปริมาณในแง่ของโทเค็นที่ประมวลผลต่อวินาที โปรดดูปริมาณงานมาตรฐานของ LLM-foundry
| GPUs | ปริมาณงานต่ออุปกรณ์ | ปริมาณงาน | |
|---|---|---|---|
| การตัดแต่ง 7B | 8 | 2387 | 14750 |
| การฝึกอบรมล่วงหน้า 3B | 16 | 4957 | 79306 |
| การฝึกอบรมล่วงหน้า 1.3b | 16 | 8684 | 138945 |
แบบจำลองแหล่งที่มา : ในขณะที่โมเดลขนาดใหญ่มีประสิทธิภาพอย่างไม่ต้องสงสัยและมีศักยภาพที่จะแข็งแกร่งขึ้นในอนาคตอันใกล้เราเชื่อว่าโมเดลขนาดเล็ก (รุ่นที่มีพารามิเตอร์น้อยกว่า 7 พันล้าน) มีศักยภาพที่ไม่ได้ใช้ อย่างไรก็ตามมีความพยายามเพียงเล็กน้อยที่จะทำให้โมเดลเล็ก ๆ แข็งแกร่งขึ้นและงานของเราผลักดันไปสู่เป้าหมายนี้ ส่วนขยายตามธรรมชาติของงานนี้คือการขยายรหัสฐานไปยังการตัดแต่ง
ในการปรับ codebase ให้เข้ากับรุ่นอื่น ๆ องค์ประกอบสำคัญหนึ่งองค์ประกอบคือเพื่อให้แน่ใจว่าการใช้งานโมเดลด้วยหน้ากากนั้นเทียบเท่ากับการรันรุ่นตัดแต่ง เราใช้ llmshearing/utils/test_pruning.py เพื่อเรียกใช้การทดสอบดังกล่าวเพื่อให้แน่ใจว่าความถูกต้องของฟังก์ชั่น prune_params ในไฟล์รุ่น
แหล่งข้อมูล : โปรดทราบว่าประสิทธิภาพของโมเดลที่เกิดขึ้นนั้นไม่เพียง แต่ขึ้นอยู่กับอัลกอริทึมการตัดแต่งกิ่งและโมเดลพื้นฐาน แต่ยังรวมถึงคุณภาพของข้อมูลด้วย ในการทดลองของเราเราส่วนใหญ่ทำงานข้อมูล Redpajama v1 อย่างไรก็ตามนี่คือแหล่งข้อมูลเพิ่มเติมบางส่วนที่สามารถพิจารณาได้สำหรับการรวม:
หากคุณมีคำถามใด ๆ ที่เกี่ยวข้องกับรหัสหรือกระดาษอย่าลังเลที่จะส่งอีเมล mengzhou ([email protected]) หากคุณพบปัญหาใด ๆ เมื่อใช้รหัสหรือต้องการรายงานข้อบกพร่องคุณสามารถเปิดปัญหาได้ โปรดพยายามระบุปัญหาพร้อมรายละเอียดเพื่อให้เราสามารถช่วยคุณได้ดีขึ้นและเร็วขึ้น!
โปรดอ้างอิงกระดาษของเราหากคุณพบว่า repo มีประโยชน์ในงานของคุณ:
@article { xia2023sheared ,
title = { Sheared llama: Accelerating language model pre-training via structured pruning } ,
author = { Xia, Mengzhou and Gao, Tianyu and Zeng, Zhiyuan and Chen, Danqi } ,
journal = { arXiv preprint arXiv:2310.06694 } ,
year = { 2023 }
}

