LLM Shearing
1.0.0
? arxiv preprint | 블로그 게시물
기본 모델 : Sheared-Llama-1.3b | 전단-줄마마 -2.7b | 전단-파시 티아 -160m
지속적인 사전 훈련없이 가지 치기 모델 : 전단-롤라마 -1.3b- 가식, 전단-줄마마 -2.7b 프론
지시 조정 모델 : 전단-롤라마 -1.3b-sharegpt | 전단-줄마마 -2.7B-sharegpt
우리의 일에 관심을 가져 주셔서 감사합니다! 이것은 Mengzhou Xia, Tianyu Gao, Zhiyuan Zeng 및 Danqi Chen의 공동 작업입니다. 여기서, 우리는 전단-롤라마의 가지 치기 및 지속적인 사전 훈련 알고리즘에 대한 코드베이스를 제공합니다. :) 우리는 치기 강력한 기본 모델을 정리하는 것이 처음부터 미리 훈련하는 것과 비교하여 강력한 소규모 언어 모델을 얻는 매우 비용 효율적인 방법이라는 것을 발견했습니다. 다음 그래프는 LLAMA-2-7B 모델 (2T 토큰으로 미리 훈련 된)의 존재를 감안할 때, 치기는 사전 훈련 비용의 3%를 가진 Openllama 모델만큼 강력한 모델을 생성한다는 것을 보여줍니다.
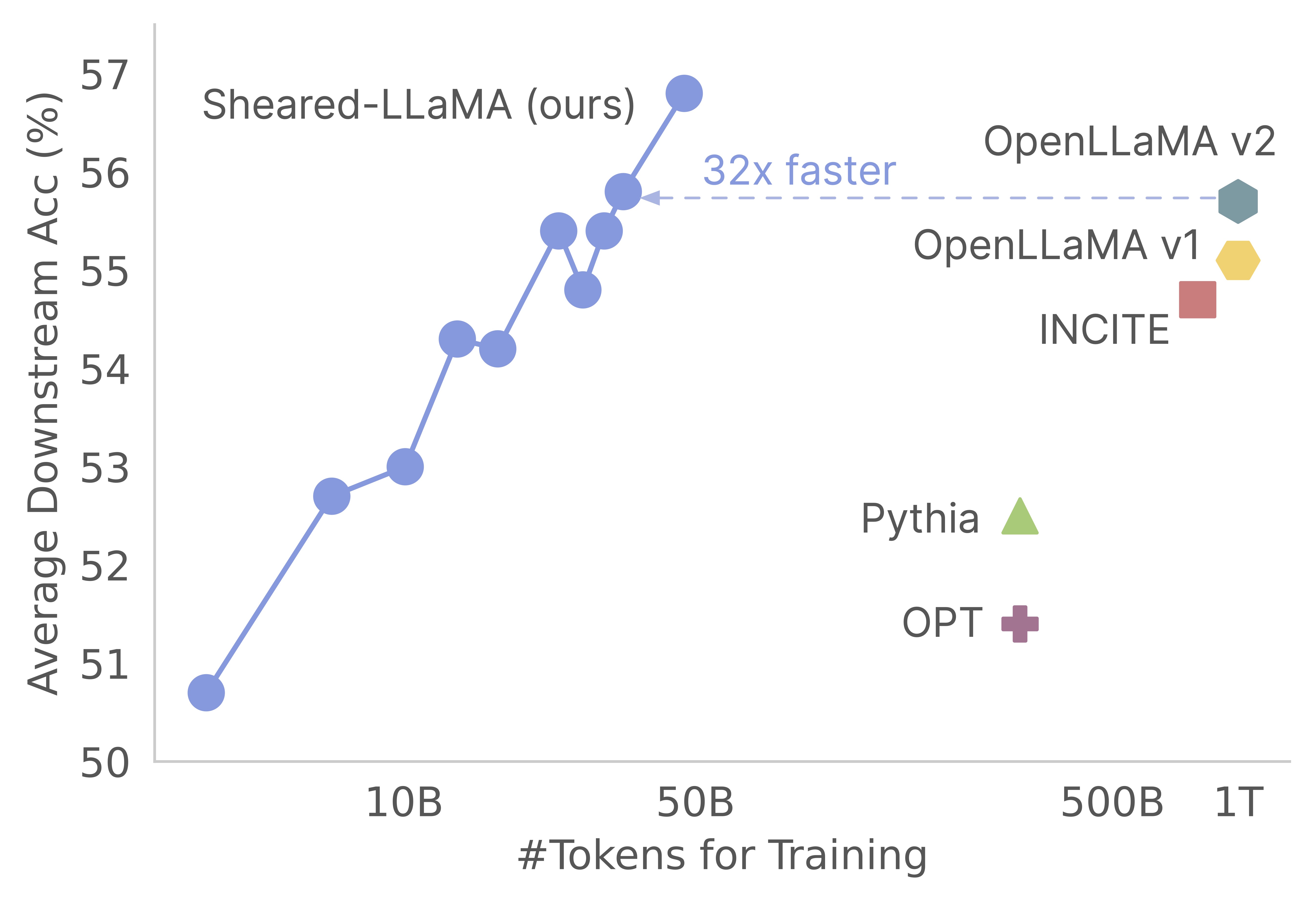
업데이트
이 코드베이스는 대형 언어 모델 사전 훈련을 위해 특별히 설계되고 최적화 된 MosaicML의 Amazing Composer 패키지를 기반으로 구축되었습니다. pruning 로직 및 dynamic batch loading 로직을 포함한 전체 구현은 바닐라 작곡가 트레이너에 닿지 않고 콜백 기능으로 구현됩니다. 다음은 코드베이스 내 각 폴더에 대한 간결한 개요입니다.
shearing.data : 데이터 처리를위한 샘플 데이터 및 스크립트가 포함되어 있습니다.shearing.datasets : 동적 데이터로드를 활성화하기 위해 맞춤형 데이터 세트를 구현합니다.shearing.callbacks : 동적로드 콜백 및 가지 치기 콜백을 구현합니다.shearing.models : 모델 파일을 구현합니다.shearing.scripts : 코드를 실행하기위한 스크립트가 포함되어 있습니다.shearing.utils : 모델 변환 및 가지 치기 테스트와 같은 모든 유틸리티 기능이 포함되어 있습니다.train.py : 코드 실행 메인 항목 1 단계 :이 저장소를 시작하려면 다음을 따라야합니다. 진행하기 전에 Pytorch와 플래시주의가 설치되어 있는지 확인하십시오. 다음 명령을 사용하여 PIP를 통해이 작업을 수행 할 수 있습니다.
pip install torch==2.0.1+cu118 torchvision==0.15.2+cu118 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu118
pip install flash-attn==1.0.3.post
플래시주의 버전 2는 현재 지원되지 않으며 모델 파일에 수동 수정이 필요할 수 있습니다.
2 단계 : 필요한 나머지 패키지를 설치하십시오.
cd llmshearing
pip install -r requirement.txt
3 단계 : 마지막으로 llmshearing 패키지를 편집 가능한 모드로 설치하여 개발 환경에 액세스 할 수 있도록하십시오.
pip install -e .
MosaicML의 스트리밍 패키지로 데이터를 준비하는 방법에 대한 자세한 내용은 LLMShearing/Data를 참조하십시오.
작곡가와 함께 포옹 얼굴 변압기 모델을 사용하려면 컴포저가 예상하는 주요 형식으로 모델 가중치를 변환해야합니다. 다음은 Hugging Face Model 'Llama2'에서 가중치를 작곡가와 호환 형식으로 변환하는 방법의 예입니다.
# Define the Hugging Face model name and the output path
HF_MODEL_NAME=meta-llama/Llama-2-7b-hf
OUTPUT_PATH=models/Llama-2-7b-composer/state_dict.pt
# Create the necessary directory if it doesn't exist
mkdir -p $(dirname $OUTPUT_PATH)
# Convert the Hugging Face model to Composer key format
python3 -m llmshearing.utils.composer_to_hf save_hf_to_composer $HF_MODEL_NAME $OUTPUT_PATH
또한 다음 유틸리티 기능을 사용하여 Hugging Face 모델과 변환 된 작곡가 모델 사이의 동등성을 테스트 할 수 있습니다.
MODEL_SIZE=7B
python3 -m llmshearing.utils.test_composer_hf_eq $HF_MODEL_NAME $OUTPUT_PATH $MODEL_SIZE
이러한 기능은 LLAMA/LLAMA2 모델에서만 작동합니다. 그러나 Mistral-7B와 같은 다른 모델과 함께 사용하기 위해 적응하는 것이 간단해야합니다.
가지 치기의 경우 llmshearing/scripts/pruning.sh 에있는 예제 스크립트를 참조 할 수 있습니다. 이 스크립트에서는 데이터 구성, 기본 교육 구성, 가지 치기 구성 및 동적 배치로드 구성을 통합하기 위해 조정해야합니다.
지속적인 사전 훈련과 비교하여 비교적 높은 계산 비용으로 인해, 우리는 특정 수의 단계 (일반적으로 모든 실험에서 3200 단계) 후에 치기 목표로 훈련을 중단시킵니다. 그 후, 우리는 가지 치기 모델의 추가 사전 훈련을 진행합니다. 호환성을 보장하기 위해서는 표준 대상 모델 구조와 정렬되도록 모델의 상태 사전 키를 변환해야합니다. 이 변환에 대한 자세한 지침은 Convert Pruned 모델에서 찾을 수 있습니다.
모델 변환을 완료 한 후에는 가지 치기 모델의 사전 훈련을 계속할 수 있습니다. 프로세스는 표준 모델 사전 트레인과 유사합니다. 이를 위해 llmshearing/scripts/continue_pretraining.sh 이 스크립트에서는 가지 치기 구성이 제거됩니다.
모델을 훈련 한 후 변환 스크립트를 사용하여 작곡가 모델을 변압기 모델로 변환 할 수 있습니다. 자세한 내용은 Composer Model을 Huggingface 모델로 변환하는 섹션을 참조하십시오.
llmshearing/scripts/pruning.sh 사용한 교육이 완료된 후, 저장된 모델은 소스 모델의 전체 매개 변수로 구성되며 마스크 세트와 함께 구성됩니다. 그런 다음 1) 마스킹 변수가 근처에있는 하위 구조를 제거하는 마스킹 변수에 작용합니다.
MODEL_PATH=$MODEL_DIR/latest-rank0.pt
python3 -m llmshearing.utils.post_pruning_processing prune_and_save_model $MODEL_PATH
가지 치기 모델은 $(dirname $MODEL_PATH)/pruned-latest-rank0.pt 로 저장됩니다.
훈련 후 유추 또는 미세 조정에 HuggingFace를 사용하려면 llmshearing/scripts/composer_to_hf.py 스크립트를 사용하여 Composer 모델을 Hugging Face 모델로 변환 할 수 있습니다. 다음은 스크립트 사용 방법의 예입니다.
MODEL_PATH=$MODEL_DIR/latest-rank0.pt
OUTPUT_PATH=$MODEL_DIR/hf-latest_rank0
MODEL_CLASS=LlamaForCausalLM
HIDDEN_SIZE=2048
NUM_ATTENTION_HEADS=16
NUM_HIDDEN_LAYERS=24
INTERMEDIATE_SIZE=5504
MODEL_NAME=Sheared-Llama-1.3B
python3 -m llmshearing.utils.composer_to_hf save_composer_to_hf $MODEL_PATH $OUTPUT_PATH
model_class=${MODEL_CLASS}
hidden_size=${HIDDEN_SIZE}
num_attention_heads=${NUM_ATTENTION_HEADS}
num_hidden_layers=${NUM_HIDDEN_LAYERS}
intermediate_size=${INTERMEDIATE_SIZE}
num_key_value_heads=${NUM_ATTENTION_HEADS}
_name_or_path=${MODEL_NAME}
여기에 언급 된 매개 변수 이름은 LLAMA2의 포옹 얼굴 구성에 맞게 조정되며 다른 모델 유형을 처리 할 때 다를 수 있습니다.
이 섹션에서는 훈련을 위해 Yaml 구성 파일 내에서 매개 변수 구성에 대한 심층적 인 안내서를 제공합니다. 이러한 구성에는 데이터 설정, 기본 교육 설정, 가지 치기 설정 및 동적 데이터로드 구성을 포함한 몇 가지 주요 측면이 포함됩니다.
data_local : 데이터가 포함 된 로컬 디렉토리.eval_loader.dataset.split : 평가를 위해 모든 도메인의 데이터를 포함하는 결합 된 분할 이름을 제공하십시오.train_loader.dataset.split : 동적로드 구성에서 dynamic=True (동적로드 섹션을 참조하십시오).이 값을 설정할 필요가 없습니다. 그러나 dynamic=False 인 경우 교육 분할을 지정해야합니다. 기본 교육 구성은 원래 Composer 패키지를 크게 따릅니다. 이러한 구성에 대한 포괄적 인 세부 정보는 Composer의 공식 문서를 참조하십시오. 다음은 다음 사항에 유의해야 할 몇 가지 주요 교육 매개 변수입니다.
max_duration :이 매개 변수는 최대 훈련 기간을 정의하고 단계 수 (예 : 3200ba ) 또는 epochs (예 : 1ep )로 지정할 수 있습니다. 우리의 실험에서, 가지 치기 지속 시간은 3200ba 로 설정되었고, 지속적인 사전 훈련 기간은 48000ba 로 설정되었습니다.save_interval :이 매개 변수는 모델 상태가 얼마나 자주 저장되는지를 결정합니다. 우리는 가지 치기 및 지속적인 사전 훈련 단계 모두에 대해 3200ba 로 설정했습니다 ..t_warmup :이 매개 변수는 학습 속도 스케줄러의 학습 속도 워밍업 기간을 지정합니다. 가지 치기의 경우 320ba 로 설정됩니다. optimizer.lr :이 매개 변수는 기본 모델 매개 변수의 학습 속도를 정의하고 기본값은 1e-4 입니다.max_seq_len : LLAMA 2 교육 방법론에 따라 최대 시퀀스 길이 4096을 수용합니다.device_train_microbatch_size :이 매개 변수는 훈련 중에 장치 당 배치 크기를 결정합니다. 가지 치기 단계의 경우 4 로 구성하는 반면, 계속 사전 훈련을 위해서는 16 으로 설정됩니다.global_train_batch_size :이 매개 변수는 교육 중 모든 GPU의 글로벌 배치 크기를 지정합니다. 가지 치기 단계에서는 32 로 구성되며, 계속 사전 훈련을 위해서는 256 으로 증가합니다.autoresume :이 매개 변수는 실행을 재개 할 때 true 로 설정하여 활성화 할 수 있습니다. 그러나 지속적인 전 사전 조정 단계에서 성공적으로 사용했지만 가지 치기 단계와의 호환성을 보장 할 수는 없습니다.계산 제약으로 인해 철저한 하이퍼 파라미터 검색이 수행되지 않았으며 성능 향상을 위해 더 나은 하이퍼 파라미터가 존재할 수 있습니다.
가지 치기 프로세스를 사용하면 소스 모델을 특정 대상 형태로 잘라낼 수 있으며 스크립트에는 다음과 같은 필수 매개 변수가 포함됩니다.
from_model :이 매개 변수는 소스 모델 크기를 지정하고 config_file에 해당합니다.to_model :이 매개 변수는 대상 모델 크기를 정의하고 소스 모델은 대상 구성과 일치하도록 정리됩니다.optimizer.lag_lr :이 매개 변수는 가지 치기 중에 마스킹 변수와 Lagrangian 승수를 학습하는 학습 속도를 지정합니다. 기본값은입니다 가지 치기 특정 인수는 모두 model.l0_module 로 그룹화됩니다. L0_Module :
model.l0_module.lagrangian_warmup_steps : 초기 워밍업 단계에서 가지 치기 속도는 0에서 증가하여 원하는 대상 값에 도달합니다. 특정 목표 값은 대상 모델의 사전 정의 된 구조에 의해 결정됩니다. 이 값은 학습 속도와 관련된 워밍업 단계와 다를 수 있습니다. 일반적으로, 우리는이 가지 치기 워밍업 프로세스에 대한 총 단계 수의 약 20%를 할당합니다.model.l0_module.pruning_modules : 기본적 으로이 설정은 헤드, 중간 크기, 숨겨진 치수 및 레이어를 포함한 모델의 다양한 측면을 정리합니다.model.l0_module.eval_target_model : true로 설정하면 평가 프로세스는 대상 모델의 구조와 정확히 일치하는 서브 모델을 평가합니다. False로 설정된 경우 평가 프로세스는 마스킹 값을 고려하여 현재 모델을 고려합니다. 마스크는 대상 모델 모양으로 수렴하는 데 약간의 시간이 걸릴 수 있으므로 훈련 중 대상 구조보다는 현재 모델 모양을 기반으로 평가합니다.model.l0_module.target_model.d_model : 대상 모델의 숨겨진 차원을 지정합니다.model.l0_module.target_model.n_heads : 대상 모델의 헤드 수를 지정합니다.model.l0_module.target_model.n_layers : 대상 모델의 레이어 수를 지정합니다.model.l0_module.target_model.intermediate_size : 대상 모델의 중간 치수 수를 지정합니다.이 매개 변수를 사용하면 특정 요구 사항에 따라 가지 치기 프로세스를 구성하고 제어 할 수 있습니다.
데이터 세트/streaming_dataset.py에서 Steaming의 StreamingDataset을 확장하여 데이터로드를 동적으로 지원합니다. 동적 배치 로딩을 구성하기위한 매개 변수는 주로 DynamicLoadingCallback 내에서 정의됩니다. 다음 구성의 대부분은 callbacks.data_loading 섹션의 Yaml 구성 파일에 지정할 수 있습니다. 각 매개 변수에 대한 설명은 다음과 같습니다.
callbacks.data_loading.dynamic :이 부울 매개 변수는 동적 데이터로드가 활성화되는지 여부를 결정합니다. true로 설정되면 데이터가 다양한 도메인 또는 스트림에서 동적으로로드됩니다. False로 설정된 경우 동적 데이터로드가 비활성화됩니다.callbacks.data_loading.set_names : 동적 데이터로드에 사용될 도메인 이름 또는 스트림 이름을 지정합니다.callbacks.data_loading.proportion :이 매개 변수는 각 도메인 또는 스트림의 초기 데이터로드 비율을 정의합니다. 모든 비율의 합은 1과 같아야하며, 초기 데이터 로딩 구성에서 각 소스의 상대적 가중치를 나타냅니다.callbacks.data_loading.update_type : 교육 중에 데이터로드 비율을 조정할 업데이트 유형을 선택하십시오. 두 가지 옵션이 있습니다doremi :이 모드에서 데이터 로딩 비율은 Doremi에 설명 된 방법과 유사한 지수 하강 접근법을 사용하여 업데이트됩니다. 이를 통해 시간이 지남에 따라 데이터로드 비율을 적응 형 조정할 수 있습니다.constant :이 옵션을 선택하면 교육 전반에 걸쳐 데이터로드 비율이 일정하게 유지됩니다. 동적 데이터로드를 비활성화하는 것과 같습니다.callbacks.data_loading.target_loss : 교육 프로세스의 대상 유효성 검사 손실을 지정하십시오. 이 목표 손실 값은 훈련이 시작되기 전에 계산되거나 미리 결정되어야합니다. 로딩 비율은 모델의 전류 손실과 목표 손실의 차이에 따라 동적으로 조정됩니다. 이 조정은 교육 프로세스를 원하는 성능 수준으로 안내하는 데 도움이됩니다.eval_interval : 훈련 중에 평가가 얼마나 자주 수행되는지 결정하십시오. dynamic=True 인 경우 각 평가 후에 데이터로드 비율이 조정됩니다.이 코드는 로컬 데이터를 독점적으로 수용하도록 설계되었으며 원격 스트리밍 데이터를 지원하지 않습니다. 또한 현재 Dataloader의 단일 작업자와 만 기능하며 프리 페치 지원을 제공하지 않습니다. 테스트 에서이 제한은 추가 컴퓨팅 오버 헤드가 발생하지 않습니다.
다음은 A100 80GB GPU로 가지 치기 및 지속적인 사전 계통 단계입니다. 처리량은 초당 처리 된 토큰 측면에서 정량화됩니다. LLM-Foundry의 표준 처리량을 참조하십시오.
| gpus | 장치 당 처리량 | 처리량 | |
|---|---|---|---|
| 가지 치기 7b | 8 | 1844 | 14750 |
| 사전 훈련 3b | 16 | 4957 | 79306 |
| 사전 훈련 1.3b | 16 | 8684 | 138945 |
소스 모델 : 대형 모델은 의심 할 여지없이 강력하고 가까운 시일 내에 더 강해질 수있는 잠재력을 가지고 있지만 소규모 모델 (70 억 미만의 매개 변수를 가진 모델)이 잠재력을 발휘하지 못한다고 생각합니다. 그러나 소규모 모델을 강하게 만드는 데 전념하는 노력은 거의 없으며, 우리의 작업은이 목표를 향해 추진합니다. 이 작업의 자연스러운 확장은 Codebase를 Prune으로 확장하는 것입니다.
코드베이스를 다른 모델에 조정하려면 하나의 주요 구성 요소는 마스크로 모델을 실행하는 것이 가지 치기 모델을 실행하는 것과 같습니다. 우리는 LLMSHEARING/UTILS/TEST_PRUNING.PY를 사용하여 이러한 테스트를 실행하여 모델 파일에서 prune_params 기능의 정확성을 보장합니다.
데이터 소스 : 결과 모델의 성능은 가지 치기 알고리즘과 기본 모델뿐만 아니라 데이터의 품질에도 달라집니다. 실험에서 우리는 주로 Redpajama V1 데이터를 작업했습니다. 그러나 다음은 포함을 고려할 수있는 몇 가지 추가 리소스가 있습니다.
코드 나 논문과 관련된 궁금한 점이 있으면 mengzhou ([email protected])에게 이메일을 보내주십시오. 코드를 사용할 때 문제가 발생하거나 버그를보고하려면 문제를 열 수 있습니다. 세부 사항으로 문제를 지정하여 더 나은 시간을 더 빨리 도와 줄 수 있습니다!
작업에 도움이되면 저희 논문을 인용하십시오.
@article { xia2023sheared ,
title = { Sheared llama: Accelerating language model pre-training via structured pruning } ,
author = { Xia, Mengzhou and Gao, Tianyu and Zeng, Zhiyuan and Chen, Danqi } ,
journal = { arXiv preprint arXiv:2310.06694 } ,
year = { 2023 }
}

