LLM Shearing
1.0.0
? arxiv preprint |ブログ投稿
ベースモデル:sheared-llama-1.3b |せん断されたラマ-2.7b |せん断 - ピティア-160m
トレーニング前の継続的な剪定モデル:せん断されたラマ-1.3Bプルーヌ、せん断型ラマ-2.7Bプルーヌ
命令チューニングモデル:sheared-llama-1.3b-sharegpt | sheared-llama-2.7b-sharegpt
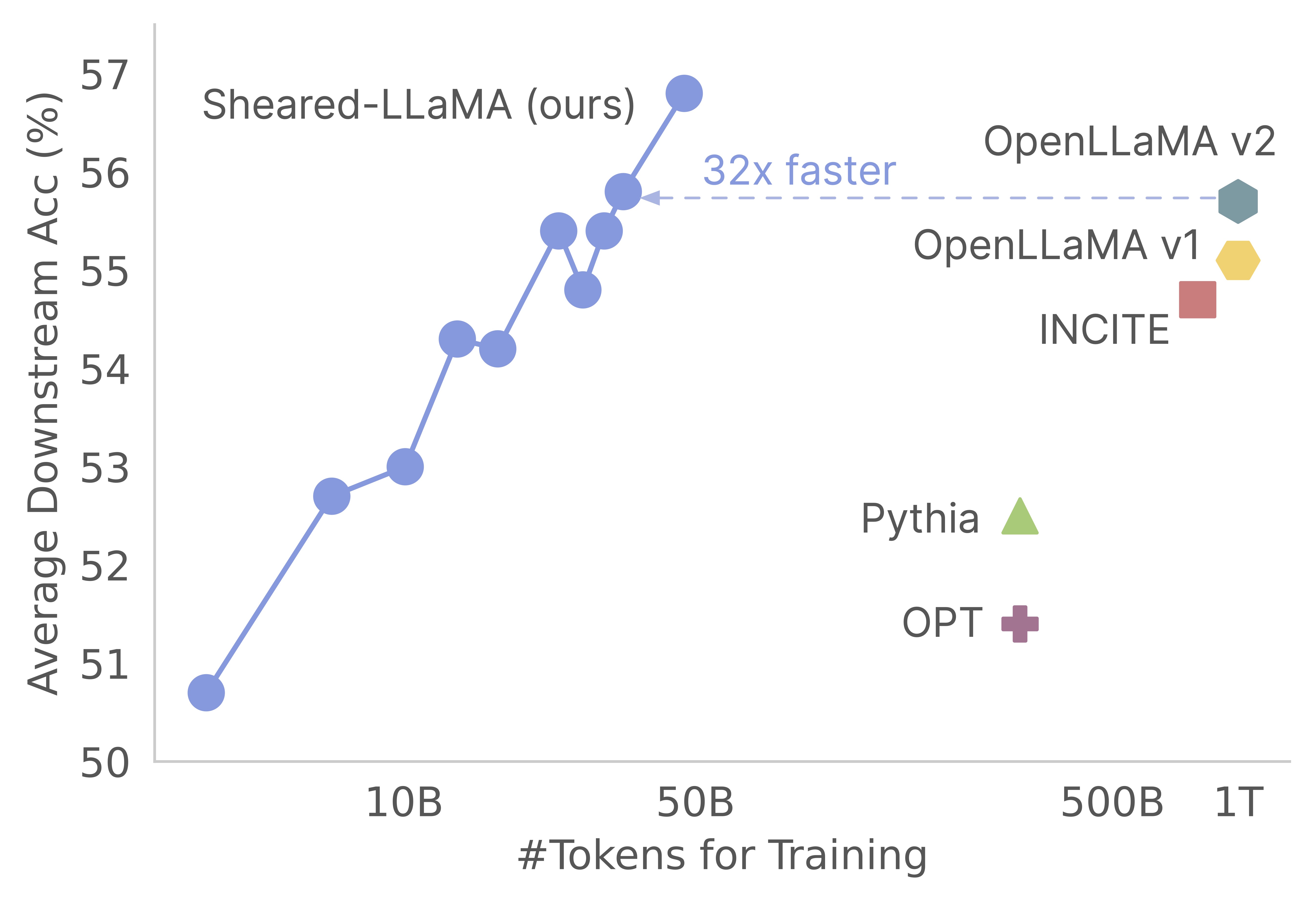
私たちの仕事にあなたの興味をありがとう!これは、Mengzhou Xia、Tianyu Gao、Zhiyuan Zeng、およびDanqi Chenによる共同作業です。ここでは、せん断されたラマの剪定と継続的なトレーニングアルゴリズムのコードベースを提供します:)剪定強力なベースモデルは、ゼロからプリトレーニングと比較して、強力な小規模な言語モデルを取得するための非常に費用対効果の高い方法であることがわかります。次のグラフは、llama-2-7bモデル(2tトークンで事前に訓練された)の存在を考えると、剪定することで、トレーニング前コストの3%を持つOpenllamaモデルと同じくらい強力なモデルを生成することを示しています。
アップデート
このコードベースは、MOSAICMLのAmazing Composer Packageに基づいて構築されています。 pruningロジックやdynamic batch loadingロジックを含む実装全体は、バニラ作曲家トレーナーに触れることなくコールバック関数として実装されます。コードベース内の各フォルダーの簡潔な概要を次に示します。
shearing.data :データ処理用のサンプルデータとスクリプトが含まれています。shearing.datasets :動的なデータ読み込みを有効にするために、カスタマイズされたデータセットを実装します。shearing.callbacks :動的読み込みコールバックと剪定コールバックを実装します。shearing.models :モデルファイルを実装します。shearing.scripts :コードを実行するためのスクリプトが含まれています。shearing.utils :モデル変換や剪定テストなど、すべてのユーティリティ関数が含まれます。train.py :コードの実行のメインエントリステップ1 :このリポジトリを開始するには、これらのインストール手順に従う必要があります。先に進む前に、PytorchとFlashの注意がインストールされていることを確認してください。これは、次のコマンドを使用してPIP経由で行うことができます。
pip install torch==2.0.1+cu118 torchvision==0.15.2+cu118 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu118
pip install flash-attn==1.0.3.post
Flash Attentionバージョン2は現在サポートされていないため、モデルファイルに手動で変更が必要になる場合があります。
ステップ2 :次に、必要なパッケージの残りをインストールします。
cd llmshearing
pip install -r requirement.txt
ステップ3 :最後に、 llmshearingパッケージを編集モードでインストールして、開発環境にアクセスできるようにします。
pip install -e .
MOSAICMLのストリーミングパッケージを使用してデータを準備する方法の詳細については、LLMShearing/Dataを参照してください。
Composerでフェイストランスモデルを抱き締めるには、モデルの重みをComposerが期待するキー形式に変換する必要があります。抱きしめる顔モデル「llama2」からのウェイトをコンポーザーの互換性のある形式に変換する方法の例を次に示します。
# Define the Hugging Face model name and the output path
HF_MODEL_NAME=meta-llama/Llama-2-7b-hf
OUTPUT_PATH=models/Llama-2-7b-composer/state_dict.pt
# Create the necessary directory if it doesn't exist
mkdir -p $(dirname $OUTPUT_PATH)
# Convert the Hugging Face model to Composer key format
python3 -m llmshearing.utils.composer_to_hf save_hf_to_composer $HF_MODEL_NAME $OUTPUT_PATH
さらに、次のユーティリティ関数を使用して、ハグする顔モデルと変換されたコンポーザーモデルの等価性をテストできます。
MODEL_SIZE=7B
python3 -m llmshearing.utils.test_composer_hf_eq $HF_MODEL_NAME $OUTPUT_PATH $MODEL_SIZE
これらの機能は、Llama/Llama2モデルでのみ機能します。ただし、Mistral-7Bなどの他のモデルで使用するためにそれらを適応させるのは簡単です。
剪定については、 llmshearing/scripts/pruning.shにある例を参照できます。このスクリプトでは、データ構成、基本的なトレーニング構成、剪定構成、動的バッチロード構成を組み込むための調整を行う必要があります。
継続的なトレーニングと比較して、剪定の計算コストが比較的高いため、特定の数のステップ(通常、すべての実験で3200ステップ)の後、剪定目標とのトレーニングを停止します。その後、剪定されたモデルのさらに事前トレーニングを進めます。互換性を確保するには、モデルの状態辞書キーを変換して、標準のターゲットモデル構造と整合する必要があります。この変換の詳細な指示は、剪定されたモデルの変換で見つけることができます。
モデル変換を完了した後、剪定モデルの事前トレーニングを続けることができます。このプロセスは、トレイン前の標準モデルに似ています。これを行うには、 llmshearing/scripts/continue_pretraining.shにある例を参照できます。このスクリプトでは、剪定構成が削除されます。
モデルをトレーニングした後、変換スクリプトを使用して、作曲家モデルをトランスモデルに変換できます。詳細については、セクションConcomert Composer Modelを参照してください。
llmshearing/scripts/pruning.shを使用したトレーニングの完了後、保存されたモデルは、マスクのセットを伴うソースモデルのパラメーター全体で構成されています。次に、1)マスキング変数が近くにある下部構造を削除することにより、マスキング変数に作用します
MODEL_PATH=$MODEL_DIR/latest-rank0.pt
python3 -m llmshearing.utils.post_pruning_processing prune_and_save_model $MODEL_PATH
プルーニドモデルは$(dirname $MODEL_PATH)/pruned-latest-rank0.ptで保存されます。
トレーニング後、推論または微調整にHuggingfaceを使用したい場合は、 llmshearing/scripts/composer_to_hf.pyスクリプトを使用して、作曲家モデルをハグするフェイスモデルに変換することを選択できます。スクリプトの使用方法の例は次のとおりです。
MODEL_PATH=$MODEL_DIR/latest-rank0.pt
OUTPUT_PATH=$MODEL_DIR/hf-latest_rank0
MODEL_CLASS=LlamaForCausalLM
HIDDEN_SIZE=2048
NUM_ATTENTION_HEADS=16
NUM_HIDDEN_LAYERS=24
INTERMEDIATE_SIZE=5504
MODEL_NAME=Sheared-Llama-1.3B
python3 -m llmshearing.utils.composer_to_hf save_composer_to_hf $MODEL_PATH $OUTPUT_PATH
model_class=${MODEL_CLASS}
hidden_size=${HIDDEN_SIZE}
num_attention_heads=${NUM_ATTENTION_HEADS}
num_hidden_layers=${NUM_HIDDEN_LAYERS}
intermediate_size=${INTERMEDIATE_SIZE}
num_key_value_heads=${NUM_ATTENTION_HEADS}
_name_or_path=${MODEL_NAME}
ここで説明したパラメーター名は、Llama2の抱き合った顔の構成に合わせて調整されており、他のモデルタイプを扱うときに異なる場合があることに注意してください。
このセクションでは、トレーニング用のYAML構成ファイル内のパラメーターの構成に関する詳細なガイドを提供します。これらの構成には、データセットアップ、基本的なトレーニング設定、剪定設定、動的なデータ読み込み構成など、いくつかの重要な側面が含まれます。
data_local :データを含むローカルディレクトリ。eval_loader.dataset.split :評価のために、すべてのドメインからのデータを含む複合分割の名前を提供します。train_loader.dataset.split : dynamic=True (動的荷重セクションを参照してください)の場合、動的荷重構成の場合、この値を設定する必要はありません。ただし、 dynamic=Falseの場合、トレーニングの分割を指定する必要があります。基本的なトレーニング構成は、主に元のComposerパッケージに従います。これらの構成の包括的な詳細については、Composerの公式ドキュメントを参照してください。次のことに注意するためのいくつかの重要なトレーニングパラメーターがあります。
max_duration :このパラメーターは、最大トレーニング期間を定義し、ステップ数( 3200baなど)またはエポック(例えば、 1ep )のいずれかで指定できます。実験では、剪定期間は3200baに設定され、継続的なトレーニング期間は48000baに設定されました。save_interval :このパラメーターは、モデル状態が保存される頻度を決定します。プルーニングと継続的なトレーニング段階の両方で3200baに設定しました。t_warmup :このパラメーターは、学習率スケジューラの学習率ウォームアップの期間を指定します。剪定の場合、 320baに設定されています( optimizer.lr :このパラメーターは、プライマリモデルパラメーターの学習レートを定義し、デフォルト値は1e-4です。max_seq_len :Llama 2トレーニング方法論に続いて、最大シーケンス長4096に対応します。device_train_microbatch_size :このパラメーターは、トレーニング中のデバイスごとのバッチサイズを決定します。剪定段階では、 4に設定しますが、継続的なトレーニングでは16に設定されます。global_train_batch_size :このパラメーターは、トレーニング中のすべてのGPUにわたってグローバルバッチサイズを指定します。剪定段階では、 32として構成されますが、継続的なトレーニングの場合、 256に増加します。autoresume :このパラメーターは、実行を再開するときにtrueに設定することで有効にできます。ただし、継続的な事前トレーニング段階でそれを正常に使用している間、剪定段階との互換性の保証はないことに注意することが重要です。計算上の制約により、徹底的なハイパーパラメーター検索は実施されておらず、パフォーマンスを改善するためにより良いハイパーパラメーターが存在する可能性があります。
剪定プロセスにより、ソースモデルを特定のターゲット形状に剪定することができ、スクリプトには次のような重要なパラメーターが含まれます。
from_model :このパラメーターはソースモデルサイズを指定し、config_fileに対応します。to_model :このパラメーターはターゲットモデルサイズを定義し、ソースモデルはターゲット構成に一致するように剪定されます。optimizer.lag_lr :このパラメーターは、剪定中にマスキング変数とラグランジアン乗数を学習するための学習レートを指定します。デフォルト値はです剪定固有の引数はすべて、 model.l0_moduleの下でグループ化されています。
model.l0_module.lagrangian_warmup_steps :最初のウォームアップフェーズでは、剪定速度が0から上昇して目的のターゲット値に達します。特定のターゲット値は、ターゲットモデルの事前定義された構造によって決定されます。この値は、学習率に関連するウォームアップステップとは異なる場合があることに注意することが重要です。通常、この剪定ウォームアッププロセスのステップの総数の約20%を割り当てます。model.l0_module.pruning_modules :デフォルトでは、この設定では、ヘッド、中間寸法、隠された寸法、レイヤーなど、モデルのさまざまな側面をプルーン化します。model.l0_module.eval_target_model :Trueに設定すると、評価プロセスはターゲットモデルの構造と正確に一致するサブモデルを評価します。 falseに設定されている場合、評価プロセスは、マスキング値を考慮して、現在のモデルを考慮します。マスクはターゲットモデルの形状に収束するのに時間がかかる場合があるため、トレーニング中のターゲット構造ではなく、現在のモデル形状に基づいて評価します。model.l0_module.target_model.d_model :ターゲットモデルの隠された次元を指定します。model.l0_module.target_model.n_heads :ターゲットモデルのヘッド数を指定します。model.l0_module.target_model.n_layers :ターゲットモデルのレイヤー数を指定します。model.l0_module.target_model.intermediate_size :ターゲットモデルの中間寸法の数を指定します。これらのパラメーターを使用すると、特定の要件に応じて剪定プロセスを構成および制御できます。
データセット/Streaming_Dataset.pyでSteamingのStreamingDatasetを拡張して、データを動的にサポートします。動的バッチロードを構成するためのパラメーターは、主にDynamicLoadingCallback内で定義されます。次の構成のほとんどは、 callbacks.data_loadingセクションの下のyaml構成ファイルで指定できます。各パラメーターの説明は次のとおりです。
callbacks.data_loading.dynamic :このブールパラメーターは、動的データの読み込みが有効かどうかを決定します。 Trueに設定すると、データはさまざまなドメインまたはストリームから動的にロードされます。 falseに設定すると、動的なデータ読み込みが無効になります。callbacks.data_loading.set_names :動的データの読み込みに使用されるドメイン名またはストリーム名を指定します。callbacks.data_loading.proportion :このパラメーターは、各ドメインまたはストリームの初期データ読み込み割合を定義します。すべての割合の合計は1に等しく、初期データ読み込み構成の各ソースの相対的な重みを示している必要があります。callbacks.data_loading.update_type :トレーニング中にデータを読み込むことを調整するための更新タイプを選択します。 2つのオプションがありますdoremi :このモードでは、Doremiで説明されている方法と同様に、データの負荷の割合が指数降下アプローチを使用して更新されます。これにより、時間の経過とともにデータを読み込むことの適応調整が可能になります。constant :このオプションを選択すると、トレーニング全体でデータの読み込み比率を一定に保ちます。動的なデータの読み込みを無効にするのと同等です。callbacks.data_loading.target_loss :トレーニングプロセスのターゲット検証損失を指定します。このターゲット損失値は、トレーニングが開始される前に計算または事前に決定される必要があります。負荷の割合は、モデルの現在の損失とターゲット損失の差に基づいて動的に調整されます。この調整は、トレーニングプロセスを望ましいパフォーマンスレベルに向けて導くのに役立ちます。eval_interval :トレーニング中に評価が実行される頻度を決定します。 dynamic=Trueの場合、データ読み込みの割合は各評価後に調整されます。このコードは、ローカルデータのみに対応するように設計されており、リモートストリーミングデータをサポートしていません。さらに、現在、Dataloaderの1人のワーカーとのみ機能しており、Prefetchサポートは提供していません。私たちのテストでは、この制限では、追加の計算オーバーヘッドは発生しません。
剪定を実行し、A100 80GB GPUで継続前の前提条件を実行しています。スループットは、毎秒処理されたトークンの観点から定量化されます。 LLM-Foundryの標準スループットを参照してください。
| GPU | デバイスごとのスループット | スループット | |
|---|---|---|---|
| 剪定7b | 8 | 1844年 | 14750 |
| トレーニング前3b | 16 | 4957 | 79306 |
| トレーニング前1.3b | 16 | 8684 | 138945 |
ソースモデル:大規模なモデルは間違いなく強力であり、近い将来に強くなる可能性がありますが、小規模モデル(70億パラメーター未満のパラメーター)が未開発の可能性があると考えています。しかし、小さなモデルをより強くすることに専念する努力はほとんどなく、私たちの仕事はこの目標に向かってプッシュされます。この作業の自然な拡張は、コードベースを拡張して剪定することです
コードベースを他のモデルに適応させるために、1つの重要なコンポーネントは、マスクでモデルを実行することが剪定モデルの実行と同等であることを確認することです。 llmshearing/utils/utils/test_pruning.pyを使用して、そのようなテストを実行して、モデルファイルの関数prune_paramsの正しさを確保します。
データソース:結果のモデルのパフォーマンスは、剪定アルゴリズムとベースモデルだけでなく、データの品質についても偶発的であることに留意してください。実験では、主にRedpajama V1データを使用しました。ただし、包含のために考慮される可能性のある追加のリソースを次に示します。
コードや論文に関連する質問がある場合は、Mengzhou([email protected])にメールしてください。コードを使用するときに問題が発生した場合、またはバグを報告する場合は、問題を開くことができます。私たちがあなたをより良く、より迅速に助けることができるように、詳細とともに問題を指定してみてください!
仕事で役立つレポを見つけた場合は、私たちの論文を引用してください。
@article { xia2023sheared ,
title = { Sheared llama: Accelerating language model pre-training via structured pruning } ,
author = { Xia, Mengzhou and Gao, Tianyu and Zeng, Zhiyuan and Chen, Danqi } ,
journal = { arXiv preprint arXiv:2310.06694 } ,
year = { 2023 }
}

