LLM Shearing
1.0.0
? ARXIV Preprint | Posting Blog
Model Dasar: Sheared-Llama-1.3b | Sheared-llama-2.7b | Sheared-Pythia-160m
Model yang dipangkas tanpa lanjutan pra-pelatihan: sheared-llama-1.3b-pruned, sheared-llama-2.7b-pruned
Model Instruksi-Tuned: Sheared-Llama-1.3b-Sharegpt | Sheared-llama-2.7b-sharegpt
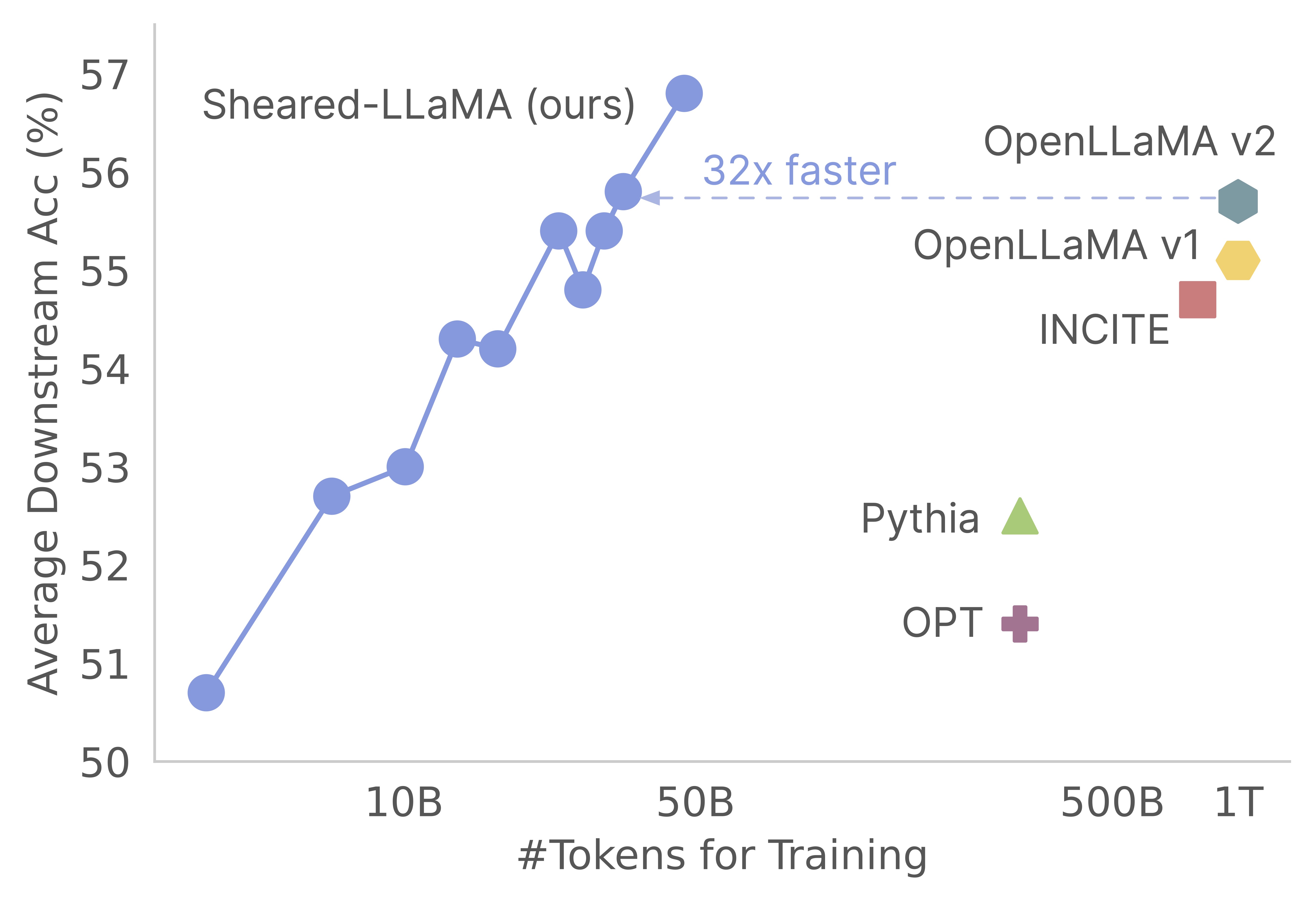
Terima kasih atas minat Anda pada pekerjaan kami! Ini adalah karya bersama oleh Mengzhou Xia, Tianyu Gao, Zhiyuan Zeng, dan Danqi Chen. Di sini, kami menyediakan basis kode kami untuk algoritma pemangkasan pra-pelatihan dan lanjutan yang dilanjutkan :) Kami menemukan bahwa pemangkasan model dasar yang kuat adalah cara yang sangat hemat biaya untuk mendapatkan model bahasa skala kecil yang kuat dibandingkan dengan pra-pelatihan mereka dari awal. Grafik berikut menunjukkan bahwa mengingat keberadaan model LLAMA-2-7B (terlatih dengan token 2T), pemangkasannya menghasilkan model sekuat model Openllama dengan 3% dari biaya pra-pelatihan.
Memperbarui
Basis kode ini dibangun berdasarkan paket komposer luar biasa MosaiCML, yang dirancang khusus dan dioptimalkan untuk pra-pelatihan model bahasa besar. Seluruh implementasi, termasuk logika pruning dan logika dynamic batch loading , diimplementasikan sebagai fungsi panggilan balik tanpa menyentuh pelatih komposer vanilla. Berikut adalah gambaran singkat dari setiap folder di dalam basis kode:
shearing.data : Berisi data sampel dan skrip untuk pemrosesan data.shearing.datasets : Menerapkan set data yang disesuaikan untuk mengaktifkan pemuatan data dinamis.shearing.callbacks : Menerapkan panggilan balik pemuatan dinamis dan panggilan balik pemangkasan.shearing.models : mengimplementasikan file model.shearing.scripts : Berisi skrip untuk menjalankan kode.shearing.utils : Termasuk semua fungsi utilitas, seperti konversi model dan tes pemangkasan.train.py : Entri utama menjalankan kode Langkah 1 : Untuk memulai dengan repositori ini, Anda harus mengikuti langkah -langkah instalasi ini. Sebelum melanjutkan, pastikan Anda memiliki pytorch dan perhatian flash terpasang. Anda dapat melakukan ini melalui PIP menggunakan perintah berikut:
pip install torch==2.0.1+cu118 torchvision==0.15.2+cu118 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu118
pip install flash-attn==1.0.3.post
Harap dicatat bahwa Flash Attention Version 2 saat ini tidak didukung dan mungkin memerlukan modifikasi manual untuk file model.
Langkah 2 : Kemudian pasang sisa paket yang diperlukan:
cd llmshearing
pip install -r requirement.txt
Langkah 3 : Akhirnya, instal Paket llmshearing dalam mode yang dapat diedit untuk membuatnya dapat diakses untuk lingkungan pengembangan Anda:
pip install -e .
Silakan merujuk ke LLMShearing/Data untuk detail tentang cara menyiapkan data dengan paket streaming MosaiCML.
Untuk memanfaatkan model transformator wajah memeluk dengan komposer, Anda harus mengonversi bobot model ke format utama yang diharapkan oleh komposer. Berikut adalah contoh cara mengubah bobot dari model wajah pelukan 'llama2' menjadi format yang kompatibel untuk komposer:
# Define the Hugging Face model name and the output path
HF_MODEL_NAME=meta-llama/Llama-2-7b-hf
OUTPUT_PATH=models/Llama-2-7b-composer/state_dict.pt
# Create the necessary directory if it doesn't exist
mkdir -p $(dirname $OUTPUT_PATH)
# Convert the Hugging Face model to Composer key format
python3 -m llmshearing.utils.composer_to_hf save_hf_to_composer $HF_MODEL_NAME $OUTPUT_PATH
Selain itu, Anda dapat menggunakan fungsi utilitas berikut untuk menguji kesetaraan antara model wajah pemeluk dan model komposer yang dikonversi:
MODEL_SIZE=7B
python3 -m llmshearing.utils.test_composer_hf_eq $HF_MODEL_NAME $OUTPUT_PATH $MODEL_SIZE
Fungsi -fungsi ini secara eksklusif berfungsi untuk model LLAMA/LLAMA2. Namun, harus langsung menyesuaikannya untuk digunakan dengan model lain seperti Mistral-7b.
Untuk pemangkasan, Anda dapat merujuk contoh skrip yang terletak di llmshearing/scripts/pruning.sh . Dalam skrip ini, Anda perlu melakukan penyesuaian untuk menggabungkan konfigurasi data, konfigurasi pelatihan dasar, konfigurasi pemangkasan dan konfigurasi pemuatan batch dinamis.
Karena biaya komputasi pemangkasan yang relatif lebih tinggi dibandingkan dengan lanjutan pra-pelatihan, kami menghentikan pelatihan dengan tujuan pemangkasan setelah sejumlah langkah tertentu (biasanya 3200 langkah dalam semua percobaan kami). Selanjutnya, kami melanjutkan dengan pra-pelatihan lebih lanjut dari model yang dipangkas. Untuk memastikan kompatibilitas, perlu untuk mengonversi tombol kamus negara dari model untuk menyelaraskan dengan struktur model target standar. Instruksi terperinci untuk konversi ini dapat ditemukan di Convert Pruned Model.
Setelah menyelesaikan konversi model, Anda dapat melanjutkan dengan pra-pelatihan model yang dipangkas. Prosesnya mirip dengan model standar pra-kereta. Untuk melakukan ini, Anda dapat merujuk pada contoh skrip yang terletak di llmshearing/scripts/continue_pretraining.sh . Dalam skrip ini, konfigurasi pemangkasan dihilangkan.
Setelah melatih model, Anda dapat menggunakan skrip konversi untuk mengubah model komposer menjadi model Transformers. Silakan merujuk ke bagian Model Convert Composer ke Model HuggingFace untuk lebih jelasnya.
Setelah penyelesaian pelatihan menggunakan llmshearing/scripts/pruning.sh , model yang disimpan terdiri dari seluruh parameter model sumber, disertai dengan satu set topeng. Kami kemudian bertindak berdasarkan variabel masking dengan 1) menghapus substruktur di mana variabel masking dekat
MODEL_PATH=$MODEL_DIR/latest-rank0.pt
python3 -m llmshearing.utils.post_pruning_processing prune_and_save_model $MODEL_PATH
Model yang dipangkas akan disimpan dalam $(dirname $MODEL_PATH)/pruned-latest-rank0.pt .
Setelah pelatihan, jika Anda ingin menggunakan HuggingFace menggunakan inferensi atau penyesuaian, Anda dapat memilih untuk mengubah model komposer Anda menjadi model wajah memeluk menggunakan skrip llmshearing/scripts/composer_to_hf.py . Berikut adalah contoh cara menggunakan skrip:
MODEL_PATH=$MODEL_DIR/latest-rank0.pt
OUTPUT_PATH=$MODEL_DIR/hf-latest_rank0
MODEL_CLASS=LlamaForCausalLM
HIDDEN_SIZE=2048
NUM_ATTENTION_HEADS=16
NUM_HIDDEN_LAYERS=24
INTERMEDIATE_SIZE=5504
MODEL_NAME=Sheared-Llama-1.3B
python3 -m llmshearing.utils.composer_to_hf save_composer_to_hf $MODEL_PATH $OUTPUT_PATH
model_class=${MODEL_CLASS}
hidden_size=${HIDDEN_SIZE}
num_attention_heads=${NUM_ATTENTION_HEADS}
num_hidden_layers=${NUM_HIDDEN_LAYERS}
intermediate_size=${INTERMEDIATE_SIZE}
num_key_value_heads=${NUM_ATTENTION_HEADS}
_name_or_path=${MODEL_NAME}
Perlu diketahui bahwa nama parameter yang disebutkan di sini dirancang untuk konfigurasi wajah pelukan Llama2 dan mungkin berbeda ketika berhadapan dengan jenis model lainnya.
Di bagian ini, kami memberikan panduan mendalam tentang mengkonfigurasi parameter dalam file konfigurasi YAML untuk pelatihan. Konfigurasi ini mencakup beberapa aspek utama, termasuk pengaturan data, pengaturan pelatihan mendasar, pengaturan pemangkasan, dan konfigurasi pemuatan data dinamis.
data_local : Direktori lokal yang berisi data.eval_loader.dataset.split : Untuk evaluasi, berikan nama perpecahan gabungan yang mencakup data dari semua domain.train_loader.dataset.split : when dynamic=True (silakan merujuk ke bagian pemuatan dinamis) dalam konfigurasi pemuatan dinamis, tidak perlu mengatur nilai ini. Namun, jika dynamic=False , Anda harus menentukan perpecahan pelatihan. Konfigurasi pelatihan dasar sebagian besar mengikuti paket Composer asli. Untuk detail komprehensif tentang konfigurasi ini, silakan merujuk ke dokumentasi resmi komposer. Berikut adalah beberapa parameter pelatihan utama yang perlu diperhatikan:
max_duration : Parameter ini mendefinisikan durasi pelatihan maksimum dan dapat ditentukan dalam jumlah langkah (misalnya, 3200ba ) atau zaman (misalnya, 1ep ). Dalam percobaan kami, durasi pemangkasan ditetapkan ke 3200ba , dan durasi pra-pelatihan yang berkelanjutan diatur ke 48000ba .save_interval : Parameter ini menentukan seberapa sering keadaan model disimpan. Kami mengaturnya ke 3200ba untuk tahap pemangkasan dan lanjutan pra-pelatihan ..t_warmup : Parameter ini menentukan durasi pemanasan tingkat pembelajaran untuk penjadwal tingkat pembelajaran. Dalam kasus pemangkasan, diatur ke 320ba ( optimizer.lr : Parameter ini mendefinisikan laju pembelajaran untuk parameter model primer, dengan nilai default menjadi 1e-4 .max_seq_len : Mengikuti metodologi pelatihan Llama 2, kami mengakomodasi panjang urutan maksimum 4096.device_train_microbatch_size : Parameter ini menentukan ukuran batch per perangkat selama pelatihan. Untuk tahap pemangkasan, kami mengonfigurasinya menjadi 4 , sedangkan untuk lanjutan pra-pelatihan, itu diatur ke 16 .global_train_batch_size : Parameter ini menentukan ukuran batch global di semua GPU selama pelatihan. Selama tahap pemangkasan, dikonfigurasi sebagai 32 , sedangkan untuk lanjutan pra-pelatihan, itu meningkat menjadi 256 .autoresume : Parameter ini dapat diaktifkan dengan mengaturnya ke true saat melanjutkan lari. Namun, penting untuk dicatat bahwa sementara kami telah menggunakannya dengan sukses selama tahap pretraining lanjutan, tidak ada jaminan kompatibilitasnya dengan tahap pemangkasan.Karena kendala komputasi, pencarian hiperparameter yang lengkap tidak dilakukan, dan mungkin ada hiper-parameter yang lebih baik untuk peningkatan kinerja.
Proses pemangkasan memungkinkan pemangkasan model sumber ke bentuk target tertentu, dan skrip mencakup parameter penting seperti:
from_model : Parameter ini menentukan ukuran model sumber dan sesuai dengan config_file.to_model : Parameter ini mendefinisikan ukuran model target, dan model sumber akan dipangkas agar sesuai dengan konfigurasi target.optimizer.lag_lr : Parameter ini menentukan tingkat pembelajaran untuk mempelajari variabel masking dan pengganda Lagrangian selama pemangkasan. Nilai defaultnya adalah Argumen spesifik pemangkasan semuanya dikelompokkan di bawah model.l0_module :
model.l0_module.lagrangian_warmup_steps : Pada fase pemanasan awal, laju pemangkasan secara bertahap naik dari 0 untuk mencapai nilai target yang diinginkan. Nilai target spesifik ditentukan oleh struktur yang telah ditentukan dari model target. Penting untuk dicatat bahwa nilai ini mungkin berbeda dari langkah pemanasan yang terkait dengan tingkat pembelajaran. Biasanya, kami mengalokasikan sekitar 20% dari jumlah total langkah untuk proses pemanasan pemangkasan ini.model.l0_module.pruning_modules : Secara default, pengaturan ini memangkas berbagai aspek model, termasuk kepala, dimensi menengah, dimensi tersembunyi, dan lapisan.model.l0_module.eval_target_model : Ketika diatur ke true, proses evaluasi menilai submodel yang persis cocok dengan struktur model target. Jika diatur ke False, proses evaluasi mempertimbangkan model saat ini, dengan mempertimbangkan nilai -nilai masking. Karena topeng mungkin membutuhkan waktu untuk menyatu dengan bentuk model target, kami mengevaluasi berdasarkan bentuk model saat ini daripada struktur target selama pelatihan.model.l0_module.target_model.d_model : Menentukan dimensi tersembunyi dari model target.model.l0_module.target_model.n_heads : Menentukan jumlah kepala dalam model target.model.l0_module.target_model.n_layers : Menentukan jumlah lapisan dalam model target.model.l0_module.target_model.intermediate_size : Menentukan jumlah dimensi perantara dalam model target.Parameter ini memungkinkan Anda untuk mengonfigurasi dan mengontrol proses pemangkasan sesuai dengan persyaratan spesifik Anda.
Kami memperpanjang streamingDataset menguap dalam dataset/streaming_dataset.py untuk mendukung memuat data secara dinamis. Parameter untuk mengkonfigurasi pemuatan batch dinamis terutama didefinisikan dalam DynamicLoadingCallback . Sebagian besar konfigurasi berikut dapat ditentukan dalam file konfigurasi YAML di bawah bagian callbacks.data_loading . Berikut penjelasan setiap parameter:
callbacks.data_loading.dynamic : Parameter boolean ini menentukan apakah pemuatan data dinamis diaktifkan. Saat diatur ke True, data dimuat secara dinamis dari berbagai domain atau aliran. Jika diatur ke false, pemuatan data dinamis dinonaktifkan.callbacks.data_loading.set_names : Tentukan nama domain atau nama aliran yang akan digunakan untuk pemuatan data dinamis.callbacks.data_loading.proportion : Parameter ini mendefinisikan proporsi pemuatan data awal untuk setiap domain atau aliran. Jumlah semua proporsi harus sama dengan 1, yang menunjukkan bobot relatif dari masing -masing sumber dalam konfigurasi pemuatan data awal.callbacks.data_loading.update_type : Pilih jenis pembaruan untuk menyesuaikan proporsi pemuatan data selama pelatihan. Ada dua opsidoremi : Dalam mode ini, proporsi pemuatan data diperbarui menggunakan pendekatan keturunan eksponensial, mirip dengan metode yang dijelaskan dalam Doremi. Ini memungkinkan penyesuaian adaptif proporsi pemuatan data dari waktu ke waktu.constant : Memilih opsi ini menjaga proporsi pemuatan data tetap konstan selama pelatihan. Ini setara dengan menonaktifkan pemuatan data dinamis.callbacks.data_loading.target_loss : Tentukan kerugian validasi target untuk proses pelatihan. Nilai kerugian target ini harus dihitung atau telah ditentukan sebelumnya sebelum pelatihan dimulai. Proporsi pemuatan akan disesuaikan secara dinamis berdasarkan perbedaan antara kehilangan model saat ini dan kehilangan target. Penyesuaian ini membantu memandu proses pelatihan menuju tingkat kinerja yang diinginkan.eval_interval : Tentukan seberapa sering evaluasi dilakukan selama pelatihan. Jika dynamic=True , proporsi pemuatan data akan disesuaikan setelah setiap evaluasi.Kode ini dirancang untuk secara eksklusif mengakomodasi data lokal dan tidak mendukung data streaming jarak jauh. Selain itu, saat ini hanya berfungsi dengan satu pekerja untuk Dataloader dan tidak menawarkan dukungan prefetch. Dalam pengujian kami, pembatasan ini tidak menimbulkan overhead komputasi tambahan.
Inilah sepanjang menjalankan pemangkasan dan lanjutan langkah pretraining dengan A100 80GB GPU. Throughput dikuantifikasi dalam hal token yang diproses per detik. Silakan merujuk ke throughput standar Foundry LLM.
| GPU | Throughput per perangkat | Throughput | |
|---|---|---|---|
| Pemangkasan 7b | 8 | 1844 | 14750 |
| Pra-pelatihan 3b | 16 | 4957 | 79306 |
| Pra-pelatihan 1.3b | 16 | 8684 | 138945 |
Model Sumber : Meskipun model besar tidak diragukan lagi kuat dan memiliki potensi untuk menjadi lebih kuat dalam waktu dekat, kami percaya bahwa model skala kecil (mereka yang memiliki parameter kurang dari 7 miliar) memiliki potensi yang belum dimanfaatkan. Namun, ada sedikit upaya yang didedikasikan untuk membuat model kecil lebih kuat, dan pekerjaan kami mendorong tujuan ini. Perpanjangan alami dari pekerjaan ini adalah untuk memperpanjang basis kode untuk memangkas
Untuk mengadaptasi basis kode ke model lain, satu komponen kunci adalah memastikan bahwa menjalankan model dengan topeng setara dengan menjalankan model yang dipangkas. Kami menggunakan llmshearing/utils/test_pruning.py untuk menjalankan tes tersebut untuk memastikan kebenaran fungsi prune_params dalam file model.
Sumber Data : Perlu diingat bahwa kinerja model yang dihasilkan tidak hanya pada algoritma pemangkasan dan model dasar tetapi juga pada kualitas data. Dalam percobaan kami, kami terutama mengerjakan data Redpajama V1. Namun, berikut adalah beberapa sumber daya tambahan yang dapat dipertimbangkan untuk dimasukkan:
Jika Anda memiliki pertanyaan yang terkait dengan kode atau kertas, jangan ragu untuk mengirim email ke Mengzhou ([email protected]). Jika Anda mengalami masalah saat menggunakan kode, atau ingin melaporkan bug, Anda dapat membuka masalah. Silakan coba tentukan masalah dengan detail sehingga kami dapat membantu Anda lebih baik dan lebih cepat!
Harap kutip makalah kami jika Anda menemukan repo bermanfaat dalam pekerjaan Anda:
@article { xia2023sheared ,
title = { Sheared llama: Accelerating language model pre-training via structured pruning } ,
author = { Xia, Mengzhou and Gao, Tianyu and Zeng, Zhiyuan and Chen, Danqi } ,
journal = { arXiv preprint arXiv:2310.06694 } ,
year = { 2023 }
}

