LLM Shearing
1.0.0
? ARXIV pré -impressão | Postagem do blog
Modelos básicos: cisalhamento-llama-1.3b | Lisão cisalhado-2.7b | Pythia-160m cisalhado
Modelos podados sem pré-treinamento continuado: cisalhado-llama-1.3b-punido, cisalhado-lama-2.7b-punido
Modelos ajustados para instrução: cisalhamento-llama-1.3b-sharegpt | Sheared-llama-2.7b-sharegpt
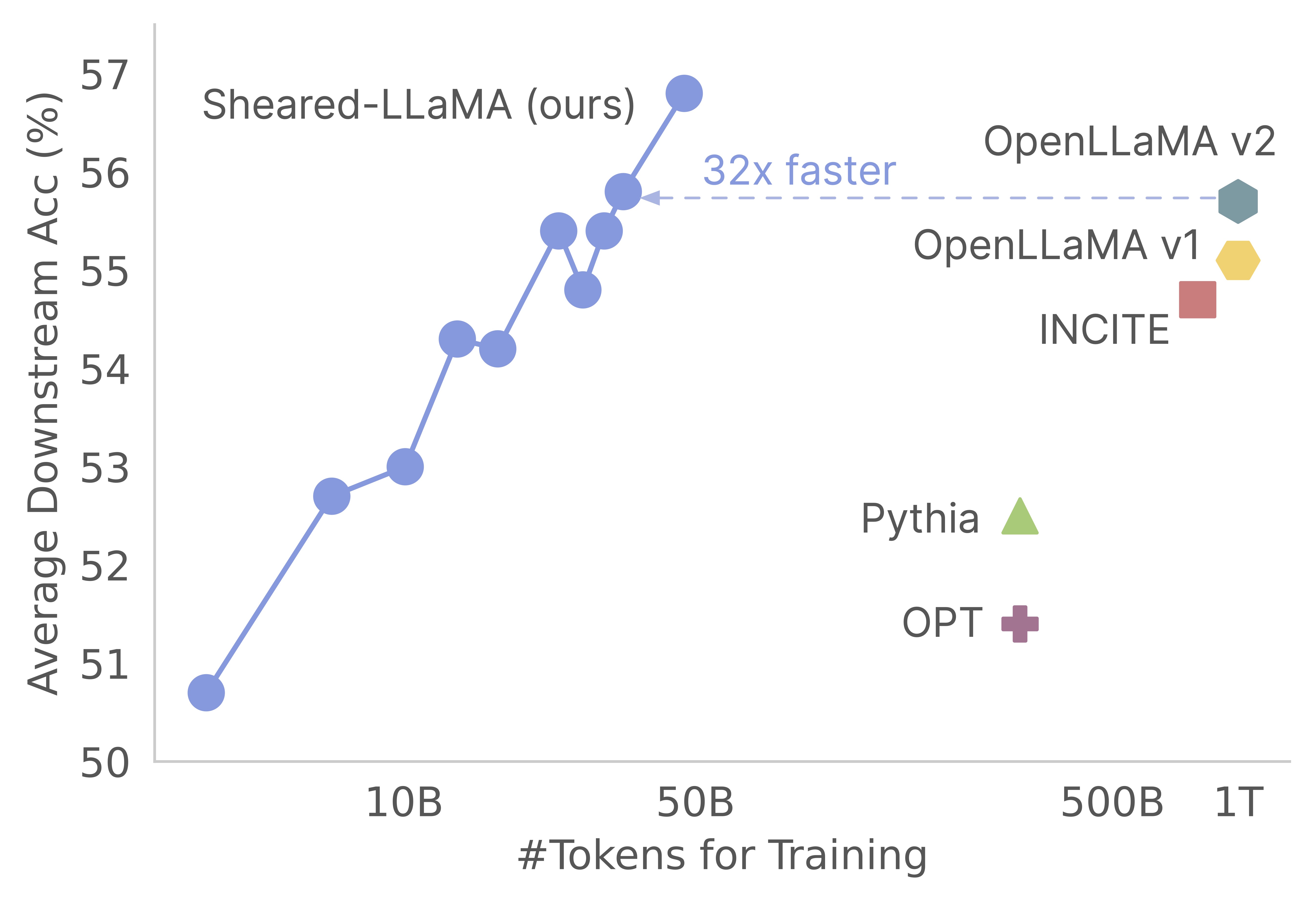
Obrigado pelo seu interesse em nosso trabalho! Este é um trabalho conjunto de Mengzhou Xia, Tianyu Gao, Zhiyuan Zeng e Danqi Chen. Aqui, fornecemos nossa base de código para os algoritmos de poda e pré-treinamento do Sheared-Llama :) Descobrimos que a poda dos modelos básicos fortes é uma maneira extremamente econômica de obter fortes modelos de linguagem em pequena escala em comparação com o pré-treinamento do zero. O gráfico a seguir mostra que, dada a existência do modelo LLAMA-2-7B (pré-treinado com tokens 2T), a poda produz um modelo tão forte quanto um modelo Openllama com 3% de seu custo de pré-treinamento.
Atualizar
Esta base de código é construída com base no incrível pacote de compositores do Mosaicml, que é especialmente projetado e otimizado para o pré-treinamento de modelos de idiomas de grande linguagem. Toda a implementação, incluindo a lógica pruning e a lógica dynamic batch loading , é implementada como funções de retorno de chamada sem tocar no treinador de compositor de baunilha. Aqui está uma visão geral concisa de cada pasta dentro da base de código:
shearing.data : contém dados de amostra e scripts para processamento de dados.shearing.datasets : implementa conjuntos de dados personalizados para ativar o carregamento dinâmico de dados.shearing.callbacks : implementa retornos de chamada de carregamento dinâmico e retorno de chamada de poda.shearing.models : implementa os arquivos do modelo.shearing.scripts : contém scripts para executar o código.shearing.utils : Inclui todas as funções de utilidade, como testes de conversão e poda de modelo.train.py : Entrada principal da execução do código Etapa 1 : para começar com este repositório, você precisará seguir estas etapas de instalação. Antes de prosseguir, verifique se você tem Pytorch e atenção flash instalada. Você pode fazer isso via PIP usando os seguintes comandos:
pip install torch==2.0.1+cu118 torchvision==0.15.2+cu118 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu118
pip install flash-attn==1.0.3.post
Observe que o Flash Ateption Atenção 2 não é suportado no momento e pode exigir modificações manuais no arquivo de modelo.
Etapa 2 : depois instale o restante dos pacotes necessários:
cd llmshearing
pip install -r requirement.txt
Etapa 3 : Finalmente, instale o pacote llmshearing em modo editável para torná -lo acessível para o seu ambiente de desenvolvimento:
pip install -e .
Consulte o LLMSHEELING/DATOS Para obter detalhes sobre como preparar dados com o pacote de streaming do MosaicML.
Para utilizar os modelos Hugging Face Transformer com o Composer, você precisará converter os pesos do modelo no formato -chave esperado pelo compositor. Aqui está um exemplo de como converter os pesos do Modelo de Abraço de Abraço 'Llama2' em um formato compatível para o compositor:
# Define the Hugging Face model name and the output path
HF_MODEL_NAME=meta-llama/Llama-2-7b-hf
OUTPUT_PATH=models/Llama-2-7b-composer/state_dict.pt
# Create the necessary directory if it doesn't exist
mkdir -p $(dirname $OUTPUT_PATH)
# Convert the Hugging Face model to Composer key format
python3 -m llmshearing.utils.composer_to_hf save_hf_to_composer $HF_MODEL_NAME $OUTPUT_PATH
Além disso, você pode usar a seguinte função de utilidade para testar a equivalência entre o modelo de face abraça e o modelo de compositor convertido:
MODEL_SIZE=7B
python3 -m llmshearing.utils.test_composer_hf_eq $HF_MODEL_NAME $OUTPUT_PATH $MODEL_SIZE
Essas funções funcionam exclusivamente para modelos de llama/llama2. No entanto, deve ser simples adaptá-los para uso em outros modelos, como o Mistral-7b.
Para poda, você pode fazer referência a um script de exemplo localizado em llmshearing/scripts/pruning.sh . Neste script, você precisará fazer ajustes para incorporar configurações de dados, configurações básicas de treinamento, configurações de poda e configurações de carregamento de lote dinâmico.
Devido ao custo computacional relativamente mais alto da poda em comparação com o pré-treinamento contínuo, interrompemos o treinamento com o objetivo de poda após um número específico de etapas (normalmente 3200 etapas em todos os nossos experimentos). Posteriormente, prosseguimos com o pré-treinamento adicional do modelo podado. Para garantir a compatibilidade, é necessário converter as teclas de dicionário de estado do modelo para se alinhar com uma estrutura de modelo de destino padrão. Instruções detalhadas para essa conversão podem ser encontradas no modelo de poda convertido.
Depois de concluir a conversão do modelo, você pode continuar com o pré-treinamento do modelo podado. O processo é semelhante ao pré-treino de um modelo padrão. Para fazer isso, você pode consultar um script de exemplo localizado em llmshearing/scripts/continue_pretraining.sh . Neste script, as configurações de poda são eliminadas.
Depois de treinar o modelo, você pode usar o script de conversão para converter o modelo do compositor em um modelo Transformers. Consulte a seção Converter Modelo do Composer em Modelo Huggingface para obter mais detalhes.
Após a conclusão do treinamento usando llmshearing/scripts/pruning.sh , os modelos salvos consistem em todos os parâmetros do modelo de origem, acompanhados por um conjunto de máscaras. Em seguida, agimos sobre as variáveis de mascaramento em 1) removendo as subestruturas onde as variáveis de mascaramento estão próximas
MODEL_PATH=$MODEL_DIR/latest-rank0.pt
python3 -m llmshearing.utils.post_pruning_processing prune_and_save_model $MODEL_PATH
O modelo podado será salvo em $(dirname $MODEL_PATH)/pruned-latest-rank0.pt .
Após o treinamento, se você quiser usar o Use HuggingFace para inferência ou ajuste fino, poderá optar por transformar seu modelo compositor em um modelo de rosto abraçando usando o script llmshearing/scripts/composer_to_hf.py . Aqui está um exemplo de como usar o script:
MODEL_PATH=$MODEL_DIR/latest-rank0.pt
OUTPUT_PATH=$MODEL_DIR/hf-latest_rank0
MODEL_CLASS=LlamaForCausalLM
HIDDEN_SIZE=2048
NUM_ATTENTION_HEADS=16
NUM_HIDDEN_LAYERS=24
INTERMEDIATE_SIZE=5504
MODEL_NAME=Sheared-Llama-1.3B
python3 -m llmshearing.utils.composer_to_hf save_composer_to_hf $MODEL_PATH $OUTPUT_PATH
model_class=${MODEL_CLASS}
hidden_size=${HIDDEN_SIZE}
num_attention_heads=${NUM_ATTENTION_HEADS}
num_hidden_layers=${NUM_HIDDEN_LAYERS}
intermediate_size=${INTERMEDIATE_SIZE}
num_key_value_heads=${NUM_ATTENTION_HEADS}
_name_or_path=${MODEL_NAME}
Esteja ciente de que os nomes dos parâmetros mencionados aqui são adaptados às configurações de rosto abraçando do LLAMA2 e podem diferir ao lidar com outros tipos de modelo.
Nesta seção, fornecemos um guia detalhado sobre a configuração de parâmetros nos arquivos de configuração da YAML para treinamento. Essas configurações abrangem vários aspectos -chave, incluindo configuração de dados, configurações de treinamento fundamental, configurações de poda e configurações dinâmicas de carregamento de dados.
data_local : o diretório local que contém os dados.eval_loader.dataset.split : Para avaliação, forneça o nome de uma divisão combinada que inclui dados de todos os domínios.train_loader.dataset.split : Quando dynamic=True (consulte a seção de carregamento dinâmico) Na configuração de carregamento dinâmico, não há necessidade de definir esse valor. No entanto, se dynamic=False , você deve especificar uma divisão de treinamento. As configurações de treinamento básico seguem amplamente o pacote Composer original. Para detalhes abrangentes sobre essas configurações, consulte a documentação oficial do Composer. Aqui estão alguns parâmetros importantes de treinamento para anotar:
max_duration : Este parâmetro define a duração máxima do treinamento e pode ser especificado no número de etapas (por exemplo, 3200ba ) ou épocas (por exemplo, 1ep ). Em nossos experimentos, a duração da poda foi definida como 3200ba e a duração continuada de pré-treinamento foi definida como 48000ba .save_interval : este parâmetro determina com que frequência o estado do modelo é salvo. Definimos para 3200ba para as etapas de poda e pré-treinamento continuado.t_warmup : Este parâmetro especifica a duração do aquecimento da taxa de aprendizado para o agendador da taxa de aprendizado. No caso de poda, é definido como 320ba ( optimizer.lr : Este parâmetro define a taxa de aprendizado para os parâmetros do modelo primário, com o valor padrão sendo 1e-4 .max_seq_len : Seguindo a metodologia de treinamento LLAMA 2, acomodamos um comprimento máximo de sequência de 4096.device_train_microbatch_size : Este parâmetro determina o tamanho do lote por dispositivo durante o treinamento. Para o estágio de poda, configuramos-o para 4 , enquanto que para o pré-treinamento contínuo, é definido como 16 .global_train_batch_size : Este parâmetro especifica o tamanho do lote global em todas as GPUs durante o treinamento. Durante o estágio de poda, é configurado como 32 , enquanto para o pré-treinamento contínuo, é aumentado para 256 .autoresume : Este parâmetro pode ser ativado configurando -o como true ao retomar uma execução. No entanto, é importante observar que, embora o tenha usado com sucesso durante o estágio de pré -treinamento contínuo, não há garantia de sua compatibilidade com o estágio de poda.Devido a restrições computacionais, uma pesquisa exaustiva de hiperparâmetro não foi realizada e pode existir melhores hiper-parâmetros para melhorar o desempenho.
O processo de poda permite a poda de um modelo de origem a uma forma de destino específica, e o script inclui parâmetros essenciais, como:
from_model : este parâmetro especifica o tamanho do modelo de origem e corresponde a um config_file.to_model : Este parâmetro define o tamanho do modelo de destino, e o modelo de origem será podado para corresponder à configuração de destino.optimizer.lag_lr : Este parâmetro especifica a taxa de aprendizado para aprender as variáveis de mascaramento e os multiplicadores Lagrangianos durante a poda. O valor padrão é Os argumentos específicos da poda estão todos agrupados em model.l0_module :
model.l0_module.lagrangian_warmup_steps : Na fase de aquecimento inicial, a taxa de poda aumenta de 0 para atingir o valor alvo desejado. O valor alvo específico é determinado pela estrutura predefinida do modelo de destino. É importante observar que esse valor pode diferir das etapas de aquecimento associadas às taxas de aprendizado. Normalmente, alocamos aproximadamente 20% do número total de etapas para esse processo de aquecimento da poda.model.l0_module.pruning_modules : Por padrão, essa configuração remonta vários aspectos do modelo, incluindo a cabeça, dimensões intermediárias, dimensões ocultas e camadas.model.l0_module.eval_target_model : Quando definido como true, o processo de avaliação avalia um submodelo que corresponde exatamente à estrutura do modelo de destino. Se definido como false, o processo de avaliação considera o modelo atual, levando em consideração os valores de mascaramento. Como a máscara pode levar algum tempo para convergir para a forma do modelo de destino, avaliamos com base na forma atual do modelo, e não na estrutura de destino durante o treinamento.model.l0_module.target_model.d_model : especifica a dimensão oculta do modelo de destino.model.l0_module.target_model.n_heads : especifica o número de cabeças no modelo de destino.model.l0_module.target_model.n_layers : especifica o número de camadas no modelo de destino.model.l0_module.target_model.intermediate_size : Especifica o número de dimensões intermediárias no modelo de destino.Esses parâmetros permitem configurar e controlar o processo de poda de acordo com seus requisitos específicos.
Estendemos o StreamingDataSet do Steaming em DataSets/streaming_dataset.py para suportar o carregamento de dados dinamicamente. Os parâmetros para configurar o carregamento dinâmico em lote são definidos principalmente no DynamicLoadingCallback . A maioria das configurações a seguir pode ser especificada em um arquivo de configuração da YAML na seção callbacks.data_loading . Aqui está uma explicação de cada parâmetro:
callbacks.data_loading.dynamic : Este parâmetro booleano determina se o carregamento dinâmico de dados está ativado. Quando definido como true, os dados são carregados dinamicamente de vários domínios ou fluxos. Se definido como false, o carregamento dinâmico de dados está desativado.callbacks.data_loading.set_names : Especifique os nomes de domínio ou nomes de fluxo que serão usados para carregamento dinâmico de dados.callbacks.data_loading.proportion : Este parâmetro define a proporção inicial de carregamento de dados para cada domínio ou fluxo. A soma de todas as proporções deve ser igual a 1, indicando os pesos relativos de cada fonte na configuração inicial de carregamento de dados.callbacks.data_loading.update_type : Escolha o tipo de atualização para ajustar as proporções de carregamento de dados durante o treinamento. Existem duas opçõesdoremi : Nesse modo, as proporções de carregamento de dados são atualizadas usando uma abordagem de descida exponencial, semelhante ao método descrito em Doremi. Isso permite o ajuste adaptativo das proporções de carregamento de dados ao longo do tempo.constant : a seleção desta opção mantém as proporções de carregamento de dados constantes ao longo do treinamento. É equivalente a desativar o carregamento dinâmico de dados.callbacks.data_loading.target_loss : Especifique a perda de validação de destino para o processo de treinamento. Esse valor de perda de destino deve ser calculado ou predeterminado antes do início do treinamento. As proporções de carregamento serão ajustadas dinamicamente com base na diferença entre a perda atual do modelo e a perda de destino. Esse ajuste ajuda a orientar o processo de treinamento em direção ao nível de desempenho desejado.eval_interval : determine com que frequência as avaliações são realizadas durante o treinamento. Se dynamic=True , a proporção de carregamento de dados será ajustada após cada avaliação.O código foi projetado para acomodar exclusivamente dados locais e não suporta dados de streaming remoto. Além disso, atualmente funciona apenas com um único trabalhador para o Dataloader e não oferece suporte de pré -busca. Em nossos testes, essa restrição não incorre em uma sobrecarga adicional de computação.
Aqui está a execução da poda e continuou a etapa de pré -treinamento com GPUs A100 80 GB. A taxa de transferência é quantificada em termos de tokens processados por segundo. Consulte a taxa de transferência padrão da LLM-Foundry.
| GPUs | Taxa de transferência por dispositivo | Taxa de transferência | |
|---|---|---|---|
| Podando 7b | 8 | 1844 | 14750 |
| Pré-treinamento 3b | 16 | 4957 | 79306 |
| Pré-treinamento 1,3b | 16 | 8684 | 138945 |
Modelos de origem : Enquanto modelos grandes são, sem dúvida, poderosos e têm o potencial de se tornar mais fortes em um futuro próximo, acreditamos que os modelos de pequena escala (aqueles com menos de 7 bilhões de parâmetros) têm potencial inexplorado. No entanto, há pouco esforço dedicado a tornar pequenos modelos mais fortes, e nosso trabalho impulsiona para esse objetivo. Uma extensão natural deste trabalho é estender a base de código para podar
Para adaptar a base de código a outros modelos, um componente -chave é garantir que a execução do modelo com máscaras seja equivalente à execução do modelo podado. Utilizamos llmshearing/utils/test_pruning.py para executar esses testes para garantir a correção da função prune_params nos arquivos de modelo.
Fontes de dados : Lembre -se de que o desempenho do modelo resultante depende não apenas do algoritmo de poda e do modelo básico, mas também da qualidade dos dados. Em nossos experimentos, trabalhamos principalmente os dados Redpajama V1. No entanto, aqui estão alguns recursos adicionais que podem ser considerados para inclusão:
Se você tiver alguma dúvida relacionada ao código ou ao artigo, sinta -se à vontade para enviar um e -mail para Mengzhou ([email protected]). Se você encontrar algum problema ao usar o código ou deseja relatar um bug, poderá abrir um problema. Tente especificar o problema com detalhes para que possamos ajudá -lo melhor e mais rápido!
Cite nosso artigo se achar o repositório útil em seu trabalho:
@article { xia2023sheared ,
title = { Sheared llama: Accelerating language model pre-training via structured pruning } ,
author = { Xia, Mengzhou and Gao, Tianyu and Zeng, Zhiyuan and Chen, Danqi } ,
journal = { arXiv preprint arXiv:2310.06694 } ,
year = { 2023 }
}

