LLM Shearing
1.0.0
? Arxiv预印本|博客文章
基本型号:剪切lallama-1.3b |剪切-LALA-2.7B |剪切薄膜160m
修剪模型没有继续进行预训练:剪切 - lllama-1.3b pruned,剪切-lalama-2.7b-pruned
指令调整模型:剪切lallama-1.3b sharegpt |剪切lalama-2.7b sharegpt
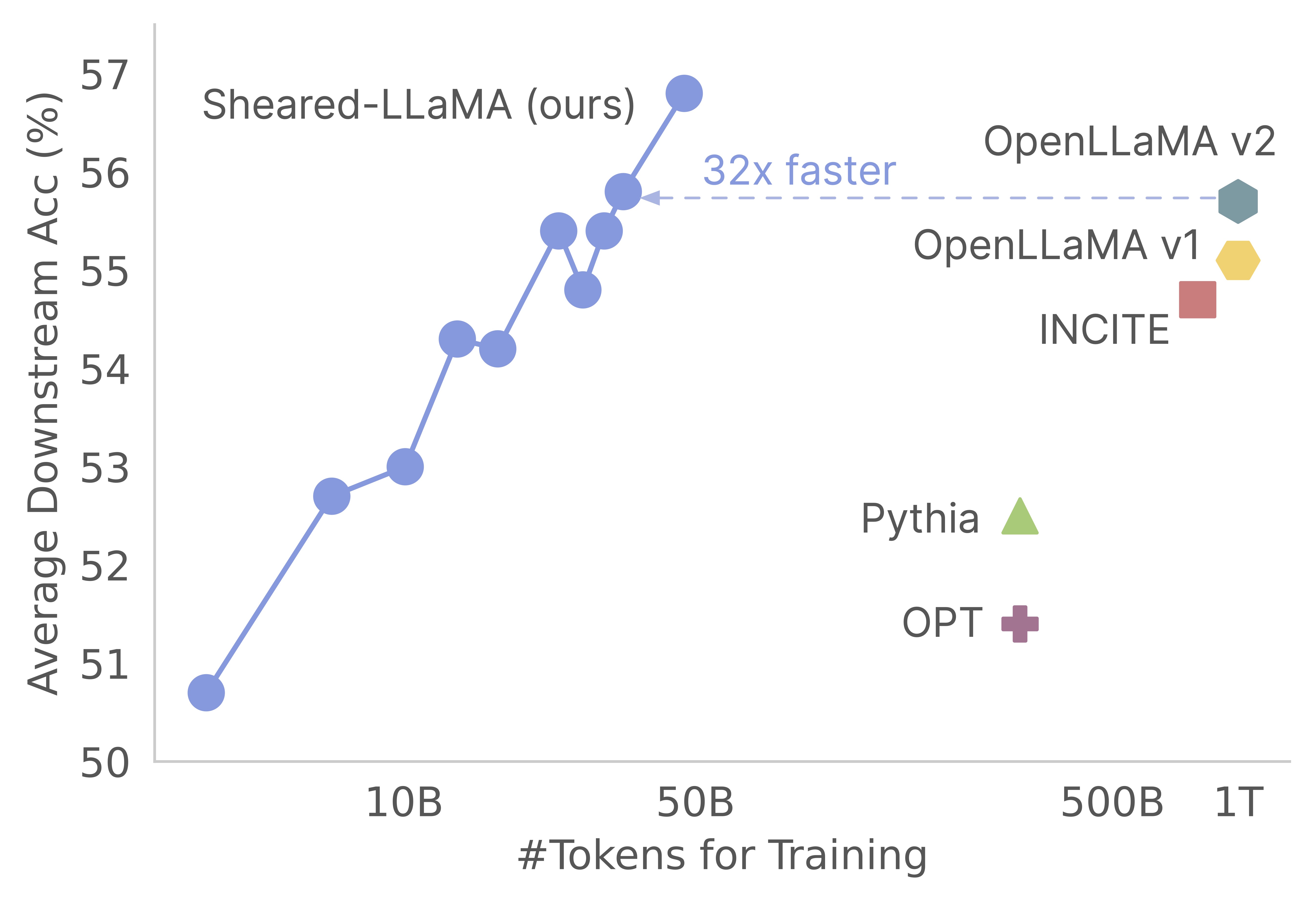
感谢您对我们的工作的兴趣!这是Mengzhou Xia,Tianyu Gao,Zhiyuan Zeng和Danqi Chen的联合作品。在这里,我们为剪切式的修剪和持续的预训练算法提供代码库:)我们发现,与从Scratch进行预训练相比,将强大的基本模型用于获得强大的小型语言模型,是一种获得强大的小型语言模型的极具成本效益的方法。以下图显示,鉴于存在Llama-2-7b模型(由2T代币进行了预训练),其修剪会产生与Openllama模型一样强的模型,其预培训成本的3%。
更新
该代码库是基于Mosaicml的惊人作曲家软件包构建的,该包装是专门设计和优化的,可用于大型语言模型预训练。包括pruning逻辑和dynamic batch loading逻辑在内的整个实现,无需触摸香草作曲家培训师而实现。这是代码库中每个文件夹的简明概述:
shearing.data :包含用于数据处理的示例数据和脚本。shearing.datasets :实现自定义数据集以启用动态数据加载。shearing.callbacks :实现动态加载回调和修剪回调。shearing.models :实现模型文件。shearing.scripts :包含用于运行代码的脚本。shearing.utils :包括所有实用程序功能,例如模型转换和修剪测试。train.py :运行代码的主要条目步骤1 :要开始使用此存储库,您需要遵循以下安装步骤。在继续之前,请确保安装了Pytorch和Flash注意力。您可以使用以下命令通过PIP执行此操作:
pip install torch==2.0.1+cu118 torchvision==0.15.2+cu118 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu118
pip install flash-attn==1.0.3.post
请注意,当前不支持Flash注意力版本2,可能需要对模型文件进行手动修改。
步骤2 :然后安装其余所需的软件包:
cd llmshearing
pip install -r requirement.txt
步骤3 :最后,以可编辑模式安装llmshearing软件包,以使其适合您的开发环境:
pip install -e .
有关如何使用Mosaicml的流式包装准备数据的详细信息,请参考LLMShearing/Data。
要利用与作曲家的拥抱面孔变压器模型,您需要将模型权重转换为作曲家预期的关键格式。这是一个示例,说明如何将拥抱面模型“ Llama2”转换为作曲家兼容格式的示例:
# Define the Hugging Face model name and the output path
HF_MODEL_NAME=meta-llama/Llama-2-7b-hf
OUTPUT_PATH=models/Llama-2-7b-composer/state_dict.pt
# Create the necessary directory if it doesn't exist
mkdir -p $(dirname $OUTPUT_PATH)
# Convert the Hugging Face model to Composer key format
python3 -m llmshearing.utils.composer_to_hf save_hf_to_composer $HF_MODEL_NAME $OUTPUT_PATH
此外,您可以使用以下实用程序函数来测试拥抱面模型与转换的作曲家模型之间的等效性:
MODEL_SIZE=7B
python3 -m llmshearing.utils.test_composer_hf_eq $HF_MODEL_NAME $OUTPUT_PATH $MODEL_SIZE
这些功能仅适用于Llama/Llama2模型。但是,将它们适应以与其他模型(例如Mistral-7b)一起使用应该是直接的。
对于修剪,您可以参考位于llmshearing/scripts/pruning.sh中的示例脚本。在此脚本中,您需要进行调整以结合数据配置,基本培训配置,修剪配置和动态批处理加载配置。
由于与持续的预训练相比,修剪的计算成本相对较高,因此在特定数量的步骤(通常在所有实验中,通常为3200个步骤),我们停止使用修剪目标进行训练。随后,我们继续对修剪模型进行进一步的预训练。为了确保兼容性,有必要将模型的状态字典键与标准目标模型结构保持一致。可以通过转换修剪模型找到此转换的详细说明。
完成模型转换后,您可以继续进行修剪模型的预培训。该过程类似于预训练的标准模型。为此,您可以参考一个位于llmshearing/scripts/continue_pretraining.sh的示例脚本。在此脚本中,消除了修剪配置。
训练模型后,您可以使用转换脚本将作曲家模型转换为变形金刚模型。有关更多详细信息,请参阅“转换作曲家”模型转换为拥抱面模型。
使用llmshearing/scripts/pruning.sh完成培训后,保存的模型由源模型的整个参数组成,并伴随一组掩码。然后,我们通过1)删除屏蔽变量接近的子结构的掩蔽变量
MODEL_PATH=$MODEL_DIR/latest-rank0.pt
python3 -m llmshearing.utils.post_pruning_processing prune_and_save_model $MODEL_PATH
修剪模型将保存在$(dirname $MODEL_PATH)/pruned-latest-rank0.pt中。
训练后,如果您想使用huggingface进行推理或微调,则可以选择使用llmshearing/scripts/composer_to_hf.py脚本将作曲家模型转换为拥抱面模型。这是如何使用脚本的示例:
MODEL_PATH=$MODEL_DIR/latest-rank0.pt
OUTPUT_PATH=$MODEL_DIR/hf-latest_rank0
MODEL_CLASS=LlamaForCausalLM
HIDDEN_SIZE=2048
NUM_ATTENTION_HEADS=16
NUM_HIDDEN_LAYERS=24
INTERMEDIATE_SIZE=5504
MODEL_NAME=Sheared-Llama-1.3B
python3 -m llmshearing.utils.composer_to_hf save_composer_to_hf $MODEL_PATH $OUTPUT_PATH
model_class=${MODEL_CLASS}
hidden_size=${HIDDEN_SIZE}
num_attention_heads=${NUM_ATTENTION_HEADS}
num_hidden_layers=${NUM_HIDDEN_LAYERS}
intermediate_size=${INTERMEDIATE_SIZE}
num_key_value_heads=${NUM_ATTENTION_HEADS}
_name_or_path=${MODEL_NAME}
请注意,此处提到的参数名称是针对Llama2的拥抱脸配置量身定制的,并且在处理其他型号类型时可能会有所不同。
在本节中,我们将提供有关在YAML配置文件中配置参数的深入指南,以供培训。这些配置包括几个关键方面,包括数据设置,基本培训设置,修剪设置和动态数据加载配置。
data_local :包含数据的本地目录。eval_loader.dataset.split :对于评估,提供包含来自所有域数据的组合拆分的名称。train_loader.dataset.split : dynamic=True时(请参阅动态加载配置中的动态加载部分),无需设置此值。但是,如果dynamic=False ,则必须指定培训拆分。基本培训配置在很大程度上遵循原始Composer包。有关这些配置的全面详细信息,请参阅作曲家的官方文档。以下是一些关键培训参数:
max_duration :此参数定义了最大训练持续时间,并且可以在步骤数(例如3200ba )或时期(例如1ep )中指定。在我们的实验中,修剪持续时间设置为3200ba ,持续的预培训持续时间设置为48000ba 。save_interval :此参数确定保存模型状态的频率。我们将其设置为3200ba ,用于修剪和持续的预训练阶段。t_warmup :此参数指定学习率调度程序的学习率热身持续时间。在修剪的情况下,将其设置为320ba ( optimizer.lr :此参数定义了主要模型参数的学习率,默认值为1e-4 。max_seq_len :遵循Llama 2训练方法,我们的最大序列长度为4096。device_train_microbatch_size :此参数确定训练期间每个设备的批处理大小。对于修剪阶段,我们将其配置为4 ,而对于持续的预训练,将其设置为16 。global_train_batch_size :此参数指定训练期间所有GPU的全局批次大小。在修剪阶段,将其配置为32 ,而对于持续的预训练,它增加到256 。autoresume :可以通过在恢复运行时将其设置为true来启用此参数。但是,重要的是要注意,尽管我们在持续的训练阶段成功使用了它,但不能保证它与修剪阶段的兼容性。由于计算限制,未进行详尽的超参数搜索,并且可能存在更好的超参数以改善性能。
修剪过程允许将源模型修剪为特定的目标形状,该脚本包括:诸如:
from_model :此参数指定源模型大小,并对应于config_file。to_model :此参数定义了目标模型大小,并且将修剪源模型以匹配目标配置。optimizer.lag_lr :此参数指定在修剪过程中学习掩盖变量和拉格朗日乘数的学习率。默认值是特定于修剪的参数均在model.l0_module下分组。L0_MODULE:
model.l0_module.lagrangian_warmup_steps :在初始热身阶段,修剪速率从0逐渐上升到达到所需的目标值。特定目标值由目标模型的预定义结构确定。重要的是要注意,此值可能与与学习率相关的热身步骤有所不同。通常,我们分配了该修剪预热过程的大约20%的步骤总数。model.l0_module.pruning_modules :默认情况下,此设置会预留模型的各个方面,包括头部,中间维度,隐藏尺寸和层。model.l0_module.eval_target_model :设置为true时,评估过程会评估与目标模型结构完全匹配的子模型。如果设置为false,则评估过程考虑了当前模型,考虑到掩盖值。由于蒙版可能需要一些时间才能收敛到目标模型形状,因此我们根据当前模型形状而不是训练过程中的目标结构进行评估。model.l0_module.target_model.d_model :指定目标模型的隐藏维度。model.l0_module.target_model.n_heads :指定目标模型中的头数。model.l0_module.target_model.n_layers :指定目标模型中的层数。model.l0_module.target_model.intermediate_size :指定目标模型中的中间维度的数量。这些参数允许您根据自己的特定要求配置和控制修剪过程。
我们在数据集/streaming_dataset.py中扩展了Steaming的SteamingDataSet,以动态支持加载数据。用于配置动态批处理加载的参数主要定义在DynamicLoadingCallback中。以下大多数配置可以在callbacks.data_loading部分下的YAML配置文件中指定。这是每个参数的解释:
callbacks.data_loading.dynamic :此布尔参数确定是否启用了动态数据加载。设置为True时,数据将从各个域或流动地加载。如果设置为false,则禁用动态数据加载。callbacks.data_loading.set_names :指定将用于动态数据加载的域名或流名称。callbacks.data_loading.proportion :此参数定义了每个域或流的初始数据加载比例。所有比例的总和必须等于1,表明初始数据加载配置中每个源的相对权重。callbacks.data_loading.update_type :选择用于调整培训期间数据加载比例的更新类型。有两个选择doremi :在此模式下,使用指数下降方法更新数据加载比例,类似于Doremi中描述的方法。这允许随着时间的推移自适应调整数据加载比例。constant :选择此选项可以使数据加载比例保持在整个培训过程中恒定。它等效于禁用动态数据加载。callbacks.data_loading.target_loss :指定培训过程的目标验证损失。该目标损失值应在训练开始之前计算或预定。负载比例将根据模型当前损失和目标损失之间的差异动态调整。此调整有助于指导培训过程达到所需的性能水平。eval_interval :确定在训练期间进行评估的频率。如果dynamic=True ,则每次评估后将调整数据加载比例。该代码旨在专门容纳本地数据,并且不支持远程流数据。此外,它目前仅与单个工人一起用于数据效力,并且不提供预取支持。在我们的测试中,该限制并未引起任何其他计算开销。
这是整个修剪的整个过程,并继续使用A100 80GB GPU进行预处理。按照每秒处理的令牌来量化吞吐量。请参阅LLM-foundry的标准吞吐量。
| GPU | 每个设备的吞吐量 | 吞吐量 | |
|---|---|---|---|
| 修剪7b | 8 | 1844年 | 14750 |
| 预训练3B | 16 | 4957 | 79306 |
| 预训练1.3b | 16 | 8684 | 138945 |
来源模型:虽然大型模型无疑具有强大的功能,并且有可能在不久的将来变得更强大,但我们认为,小型模型(少于70亿个参数的模型)没有开发的潜力。但是,几乎没有致力于使小型模型更强大的努力,我们的工作将朝着这一目标迈进。这项工作的自然扩展是将代码库扩展到修剪
为了使代码库适应其他模型,一个关键组件是确保用掩码运行模型等同于运行修剪模型。我们使用llmshearing/utils/test_pruning.py来运行此类测试,以确保模型文件中函数prune_params的正确性。
数据源:请记住,所得模型的性能不仅取决于修剪算法和基本模型,还取决于数据质量。在我们的实验中,我们主要使用Redpajama V1数据。但是,这里有一些可以考虑包含的其他资源:
如果您有与代码或论文有关的任何疑问,请随时发送电子邮件给Mengzhou([email protected])。如果使用代码时遇到任何问题或想报告错误,则可以打开问题。请尝试使用详细信息指定问题,以便我们可以更好,更快地帮助您!
如果您发现回购对您的工作有帮助,请引用我们的论文:
@article { xia2023sheared ,
title = { Sheared llama: Accelerating language model pre-training via structured pruning } ,
author = { Xia, Mengzhou and Gao, Tianyu and Zeng, Zhiyuan and Chen, Danqi } ,
journal = { arXiv preprint arXiv:2310.06694 } ,
year = { 2023 }
}

