plato research dialogue system
1.0.0

這是v0.3.1
柏拉圖研究對話系統是一個靈活的框架,可用於在各種環境中創建,訓練和評估對話性AI代理。它通過語音,文本或對話行為來支持互動,每個對話代理都可以與數據,人類用戶或其他對話代理(在多代理設置中)進行交互。只要粘貼柏拉圖的界面,每個代理商的每個組件都可以在線或離線獨立培訓或離線訓練,而Plato幾乎可以圍繞任何現有模型來包裹任何現有模型。
出版引用:
Alexandros Papangelis,Mahdi Namazifar,Chandra Khatri,Yi-Chia Wang,Piero Molino和Gokhan Tur,“柏拉圖對話系統:靈活的對話AI研究平台”,Arxiv Preprint [Paper [Paper] [Paper]
Alexandros Papangelis,Yi-Chia Wang,Piero Molino和Gokhan Tur,“通過強化學習的協作多代理對話模型培訓”,Sigdial 2019 [Paper]
柏拉圖通過提出問題來爭論主題的角色之間寫了幾次對話。這些對話中的許多以蘇格拉底的審判為特色。 (蘇格拉底在2012年5月25日在希臘雅典舉行的新試驗中無罪釋放)。
V0.2 :V0.1的主要更新是現在以包裹提供柏拉圖RDS。這使得創建和維護新的對話AI應用程序變得更加容易,並且所有教程都已更新以反映這一點。柏拉圖現在還帶有可選的GUI。享受!
從概念上講,對話代理需要進行各種步驟,以處理它作為輸入收到的信息(例如,“今天的天氣是什麼?”)並產生適當的輸出(“風吹過,但不太冷。”)。與標準體系結構的主要組成部分相對應的主要步驟(見圖1)是:
柏拉圖被設計為盡可能模塊化和靈活。它支持傳統和自定義的對話AI體系結構,重要的是,可以實現多方交互,其中有可能具有不同角色的多個代理可以相互互動,同時訓練並解決分佈式問題。
下面的圖1和2描繪了與人類用戶和模擬用戶進行交互時的示例柏拉圖對話代理體系結構。與模擬用戶進行互動是研究社區中使用的一種常見實踐,可以跳到啟動學習(即,在與人類互動之前學習一些基本行為)。可以使用任何機器學習庫(例如Ludwig,Tensorflow,Pytorch或您自己的實現)在線培訓每個單獨的組件,因為Plato是一個通用的框架。 Uber的開源深度學習工具箱路德維希(Ludwig)是一個不錯的選擇,因為它不需要編寫代碼,並且與柏拉圖完全兼容。
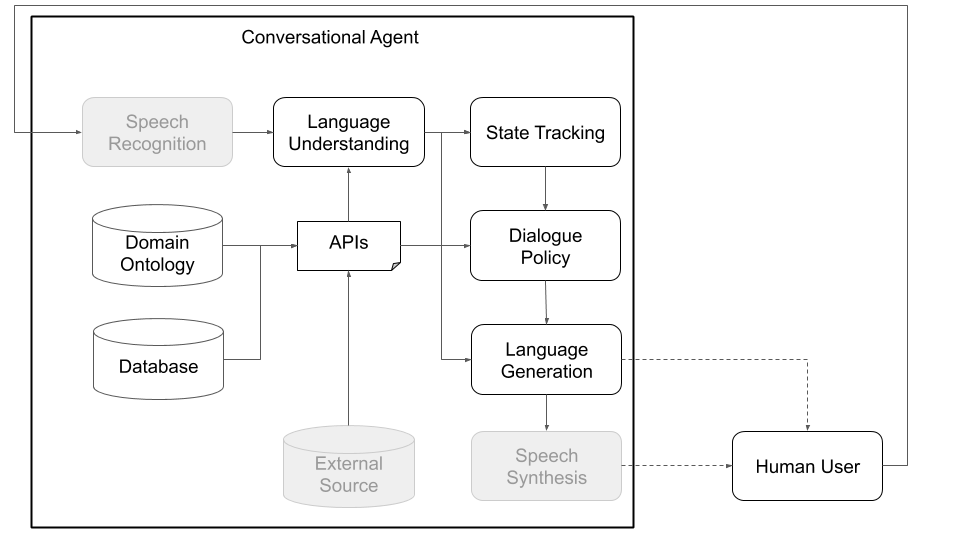 圖1:柏拉圖的模塊化體系結構意味著任何組件都可以在線或離線訓練,並且可以用自定義或預訓練的型號代替。 (此圖中的灰色組件不是核心柏拉圖組件。)
圖1:柏拉圖的模塊化體系結構意味著任何組件都可以在線或離線訓練,並且可以用自定義或預訓練的型號代替。 (此圖中的灰色組件不是核心柏拉圖組件。)
 圖2:使用模擬用戶而不是人類用戶,如圖1所示,我們可以為柏拉圖的各種組件預先培訓統計模型。然後,這些可以用於創建一個原型對話代理,該原型對話代理可以與人類用戶進行交互,以收集可以隨後用於訓練更好統計模型的自然數據。 (此圖中的灰色組件不是柏拉圖核心組件,因為它們可以作為Google ASR和Amazon Lex等開箱即用,或者特定於域和應用程序(例如自定義數據庫/API)。
圖2:使用模擬用戶而不是人類用戶,如圖1所示,我們可以為柏拉圖的各種組件預先培訓統計模型。然後,這些可以用於創建一個原型對話代理,該原型對話代理可以與人類用戶進行交互,以收集可以隨後用於訓練更好統計模型的自然數據。 (此圖中的灰色組件不是柏拉圖核心組件,因為它們可以作為Google ASR和Amazon Lex等開箱即用,或者特定於域和應用程序(例如自定義數據庫/API)。
除了單格交互之外,柏拉圖還支持多個柏拉圖代理可以與彼此互動和學習的多代理對話。具體來說,柏拉圖將產生對話代理,確保適當地傳遞給每個代理商的輸入和輸出(每個代理商聽到並說的話),並跟踪對話。
這種設置可以促進多學院學習的研究,在該學習中,代理需要學習如何生成語言以執行任務,以及在多方互動的子場(對話狀態跟踪,轉彎等)中進行研究。對話原則定義了每個代理可以理解的內容(實體或含義的本體論;例如:價格,位置,偏好,美食類型等)及其可以做什麼(要求提供更多信息,提供一些信息,調用API等)。代理可以通過語音,文本或結構化信息(對話行為)進行交流,並且每個代理都有其自己的配置。下面的圖3描繪了這種體系結構,概述了兩個代理與各種組成部分之間的通信:
 圖3:柏拉圖的體系結構允許對多種代理的同時培訓,每個代理具有潛在的角色和目標,並且可以促進多方相互作用和多機構學習等領域的研究。 (此圖中的灰色組件不是核心柏拉圖組件。)
圖3:柏拉圖的體系結構允許對多種代理的同時培訓,每個代理具有潛在的角色和目標,並且可以促進多方相互作用和多機構學習等領域的研究。 (此圖中的灰色組件不是核心柏拉圖組件。)
最後,柏拉圖支持自定義體系結構(例如將NLU分為多個獨立組件)和通過圖4所示的通用代理體系結構,如下所示。此模式從標準的對話代理體系結構移開,並支持任何類型的體系結構(例如,具有聯合組件,文本到文本或語音到語音的組件或任何其他設置),並允許將現有或預訓練的模型加載到Plato中。
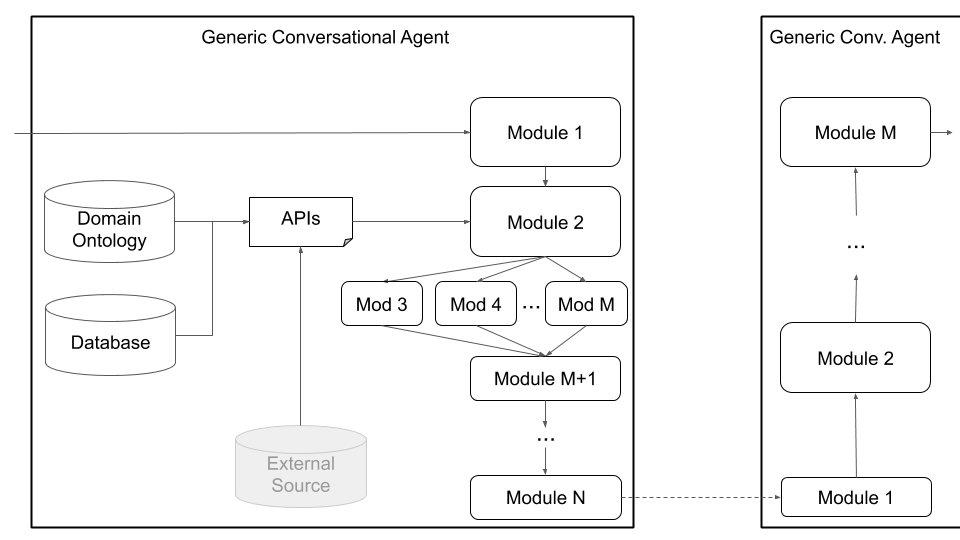 圖4:柏拉圖的通用代理體系結構支持廣泛的自定義,包括聯合組件,語音到語音組件以及文本到文本組件,所有這些組件都可以串行或併行執行。
圖4:柏拉圖的通用代理體系結構支持廣泛的自定義,包括聯合組件,語音到語音組件以及文本到文本組件,所有這些組件都可以串行或併行執行。
用戶可以通過簡單地提供Python類名稱和軟件包路徑以及模型的初始化參數來定義自己的體系結構和/或將自己的組件插入柏拉圖。用戶需要做的就是按照應執行的順序列出模塊,然後柏拉圖負責其餘的,包括包裝輸入/輸出,鏈接模塊和處理對話。柏拉圖支持模塊的串行和並行執行。
柏拉圖還通過貝葉斯優化組合結構(BOC)優化了對會話AI體系結構或單個模塊參數的貝葉斯優化的支持。
首先確保您的機器上安裝了3.6版或更高版本。接下來,您需要克隆柏拉圖存儲庫:
git clone [email protected]:uber-research/plato-research-dialogue-system.git
接下來,您需要安裝一些先決條件:
TensorFlow:
pip install tensorflow>=1.14.0
安裝語音認知庫以進行音頻支持:
pip install SpeechRecognition
對於MacOS:
brew install portaudio
brew install gmp
pip install pyaudio
對於Ubuntu/Debian:
sudo apt-get install python3-pyaudio
對於Windows:預裝不需要
下一步是安裝柏拉圖。要安裝柏拉圖,您應該直接從源代碼安裝它。
從源代碼安裝柏拉圖允許以可編輯模式安裝,這意味著如果您更改源代碼,它將直接影響執行。
導航到柏拉圖目錄(在上一步中克隆了柏拉圖存儲庫)。
我們建議創建一個新的Python環境。建立新的Python環境:
2.1安裝Virtualenv
sudo pip install virtualenv
2.2創建一個新的Python環境:
python3 -m venv </path/to/new/virtual/environment>
2.3激活新的Python環境:
source </path/to/new/virtual/environment/bin>/bin/activate
安裝柏拉圖:
pip install -e .
為了支持語音,有必要安裝Pyaudio,該Pyaudio具有許多可能在開發人員的機器上不存在的依賴項。如果以上步驟不成功,則有關Pyaudio安裝錯誤的文章包括有關如何獲得這些依賴項和安裝Pyaudio的說明。
CommonIssues.md文件包含常見問題及其在安裝時可能會遇到的解決方案。
要在安裝後運行柏拉圖,您只需在終端中運行plato命令即可。 plato命令收到4個子命令:
runguidomainparse這些子命令中的每一個都會收到一個指向配置文件的--config參數的值。 We will describe these configuration files in detail later in the document but remember that plato run --config and plato gui --config receive an application configuration file (examples could be found here: example/config/application/ ), plato domain --config receives a domain configuration (examples could be found here: example/config/parser/ / ), and plato parse --config receives a parser configuration file (examples could be found這裡: example/config/domain/ / )。
對於傳遞給--config Plato首先檢查的值,以查看該值是否是計算機上文件的地址。如果是這樣,則柏拉圖試圖解析該文件。如果不是這樣,Plato檢查值是否是example/config/<application, domain, or parser>目錄中文件的名稱。
有關一些快速示例,請嘗試以下劍橋餐廳域的配置文件:
plato run --config CamRest_user_simulator.yaml
plato run --config CamRest_text.yaml
plato run --config CamRest_speech.yaml
柏拉圖中的應用程序,即對話系統,包含三個主要部分:
這些零件在應用程序配置文件中聲明。可以在本節中的其餘部分中找到此類配置文件的示例example/config/application/我們將在本節中詳細描述每個部分。
為了在柏拉圖中實現面向任務的對話框系統,用戶需要指定構成對話框系統域的兩個組件:
柏拉圖提供了一個自動化這一構建本體和數據庫的過程的命令。假設您想為花店構建對話代理,並且在.csv中有以下物品(可以在example/data/flowershop.csv中找到此文件):
id,type,color,price,occasion
1,rose,red,cheap,any
2,rose,white,cheap,anniversary
3,rose,yellow,cheap,celebration
4,lilly,white,moderate,any
5,orchid,pink,expensive,any
6,dahlia,blue,expensive,any
要自動生成一個.DB SQL文件和.json本體論文件,您需要創建一個域配置文件,在其中您應在其中指定CSV文件,輸出路徑以及可用的,請求和系統提取example/config/domain/create_flowershop_domain.yaml路徑:
GENERAL:
csv_file_name: example/data/flowershop.csv
db_table_name: flowershop
db_file_path: example/domains/flowershop-dbase.db
ontology_file_path: example/domains/flowershop-rules.json
ONTOLOGY: # Optional
informable_slots: [type, price, occasion]
requestable_slots: [price, color]
System_requestable_slots: [type, price, occasion]
並運行命令:
plato domain --config create_flowershop_domain.yaml
如果一切順利,您應該在example/domains/目錄中有flowershop.json和flowershop.db 。
如果您收到此錯誤:
sqlite3.IntegrityError: UNIQUE constraint failed: flowershop.id
這意味著已經創建了.db文件。
現在,您可以簡單地將柏拉圖的虛擬組件作為理智檢查並與您的花店經紀人交談:
plato run --config flowershop_text.yaml
控制器是協調代理之間對話的對象。控制器將實例化代理,為每次對話初始化它們,通過輸入並適當地輸出,並跟踪統計信息。
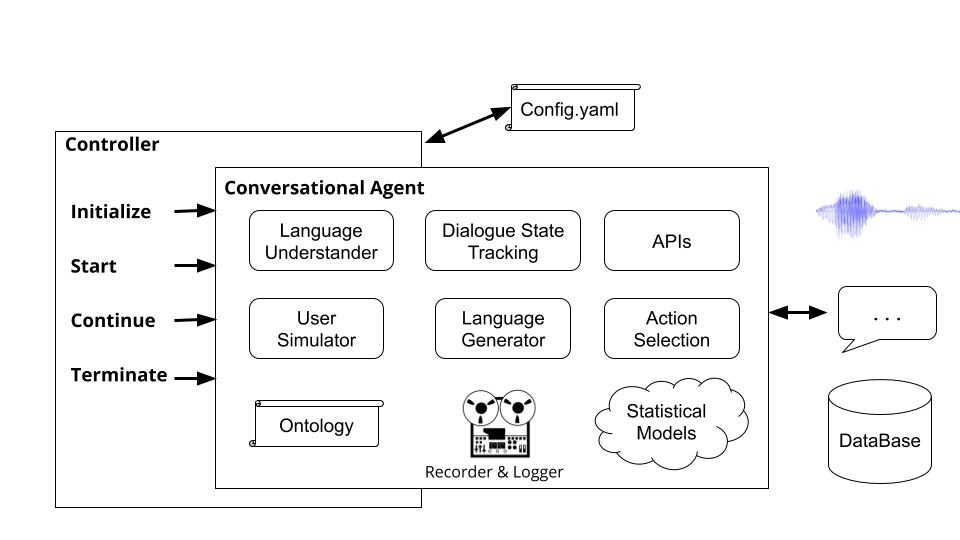
運行命令plato run柏拉圖的plato/controller/basic_controller.py basic_controller.py )。此命令將收到一個指向柏拉圖應用程序配置文件的--config參數的值。
要運行柏拉圖對話代理,用戶必須使用適當的配置文件運行以下命令:
plato run --config <FULL PATH TO CONFIG YAML FILE>
請參閱example/config/application/例如配置文件,其中包含環境上的設置以及要創建的代理以及其組件。 example/config/application/可以使用示例yaml文件的名稱直接運行的示例:
plato run --config <NAME OF A FILE FROM example/config/application/>
另外,用戶可以通過將完整的路徑傳遞到其配置文件到--config :Config:
plato run --config <FULL PATH TO CONFIG YAML FILE>
對於傳遞給--config Plato首先檢查的值,以查看該值是否是計算機上文件的地址。如果是這樣,柏拉圖試圖解析該文件。如果不是這樣,Plato檢查值是否是example/config/application目錄中文件的名稱。
柏拉圖中的每個會話AI應用程序都可以具有一個或多個代理。每個代理都有一個角色(系統,用戶,...)和一組標準對話框系統組件(圖1),即NLU,對話經理,對話狀態跟踪器,策略,NLG和用戶模擬器。
代理可以為這些組件中的每個組件具有一個顯式模塊。或者,其中一些組件可以合併為一個或多個模塊(例如接頭 /端到端代理)可以順序或併行運行(圖4)。柏拉圖的組件在plato.agent.component中定義,所有內容都來自plato.agent.component.conversational_module
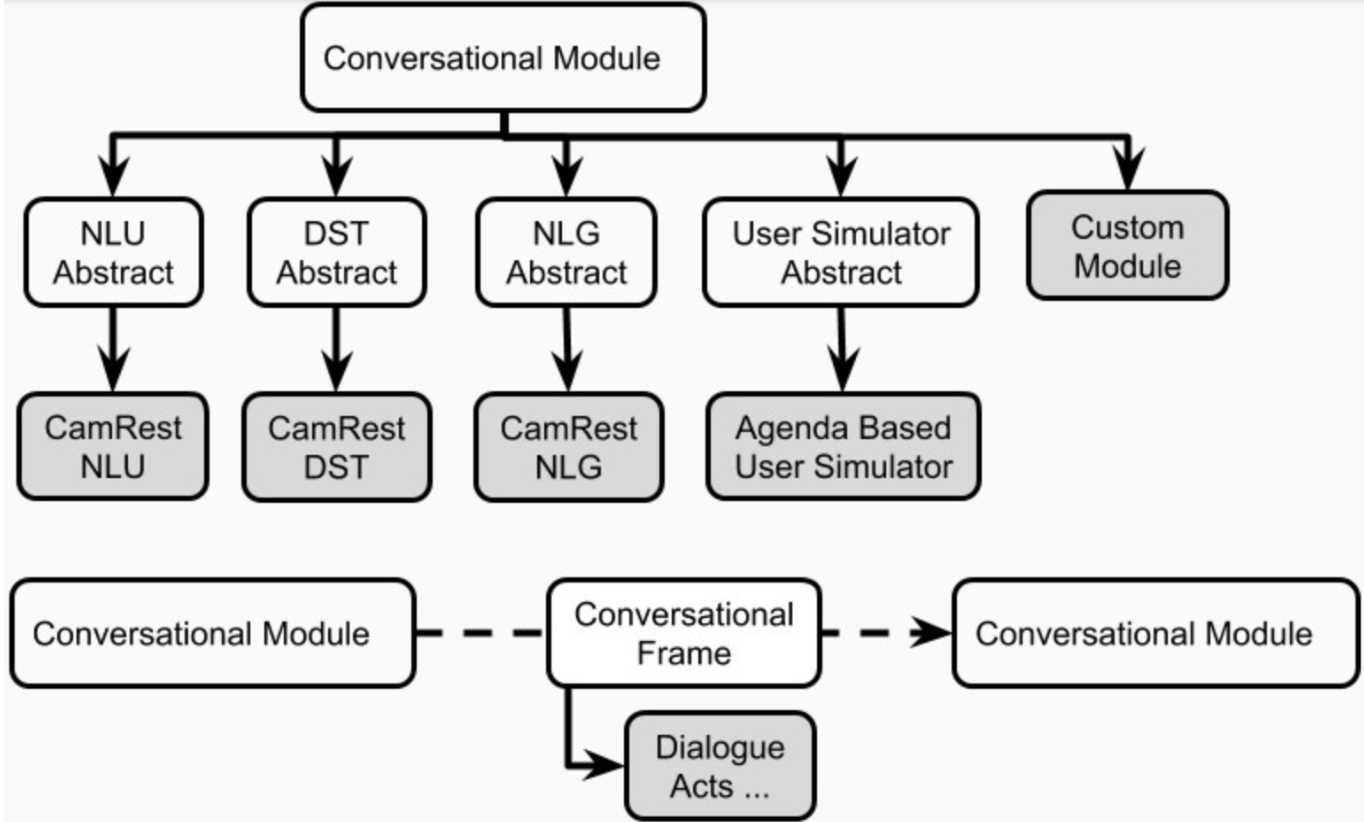 圖5。柏拉圖代理的組件
圖5。柏拉圖代理的組件
請注意,任何新的實現或自定義模塊都應從plato.agent.component.conversational_module繼承。
這些模塊中的每個模塊都可以是基於規則的或訓練的。在以下小節中,我們將描述如何為代理建立基於規則的和訓練有素的模塊。
Plato提供了插槽填充對話代理的所有組件的基於規則的版本(slot_filling_nlu,slot_filling_dst,slot_filling_policy,slot_filling_nlg和default版本的dartenda_based_based_us)。這些可用於快速原型製作,基准或理智檢查。具體而言,所有這些組件都遵循以給定本體論的規則或模式,有時在給定的數據庫上,應被視為每個組件應執行的最基本版本。
使用任何深度學習框架,柏拉圖支持在線(在互動)或離線(從數據中)方式(從數據)方式(在互動期間)中的組件模塊進行培訓。只要尊重柏拉圖的界面輸入/輸出,幾乎任何模型都可以加載到柏拉圖中。例如,如果模型是自定義NLU模塊,則只需從Plato的NLU摘要類( plato.agent.component.nlu )繼承並實現必要的抽象方法即可。
為了促進在線學習,調試和評估,柏拉圖在稱為對話劇集錄音機( plato.utilities.dialogue_episode_recorder )的結構中跟踪其內部經驗,其中包含有關以前的對話狀態,所採取的行動,當前的對話狀態,收到的當前對話狀態,接收到的內容,並收到了其他任何結構的信息,這些信息都無法與其他任何構成類別的結構相結合。
在對話或指定間隔結束時,每個對話代理將調用其每個內部組件的Train()功能,將對話體驗作為培訓數據。然後,每個組件選擇培訓所需的零件。
要使用在柏拉圖內實現的學習算法,應將任何外部數據(例如DSTC2數據)解析到該柏拉圖體驗中,以便在培訓下的相應組件可以加載和使用它們。
另外,用戶可以解析數據並在柏拉圖之外訓練其模型,並在想將其用於柏拉圖代理時加載訓練有素的模型。
在線培訓就像每個組件用戶希望培訓的配置中的“火車”標誌一樣容易。
要從數據訓練,用戶只需要加載他們從數據集中解釋的經驗即可。柏拉圖為DSTC2和MetalWoz數據集提供了示例解析器。作為如何使用這些解析器在柏拉圖進行離線培訓的一個示例,我們將使用DSTC2數據集,可以從第二個對話狀態跟踪挑戰網站上獲得。
http://camdial.org/~mh521/dstc/downloads/dstc2_traindev.tar.gz
下載完成後,您需要解壓縮文件。通過example/config/parser/Parse_DSTC2.yaml提供了用於解析此數據集的配置文件。您可以通過首先在example/config/parser/Parse_DSTC2.yaml中編輯data_path的值來解析您下載的數據,以指向您下載並解開DSTC2數據的路徑。接下來,您可以按以下方式運行解析腳本:
plato parse --config Parse_DSTC2.yaml
另外,您可以寫自己的配置文件,然後將絕對地址傳遞給該文件到命令:
plato parse --config <absolute pass to parse config file>
運行此命令將運行DSTC2的解析腳本(該命令(該命令均在plato/utilities/parser/parse_dstc2.py下居住在Plato/Utilities/parse_dstc2.py下),並將為Dialog Tracker,NLU,NLU和NLG創建培訓數據,並在此存儲庫的根目錄的data目錄中為用戶和系統中的NLG創建培訓數據。現在,該解析的數據可用於訓練柏拉圖不同組件的模型。
有多種方法可以訓練柏拉圖代理的每個組件:在線(由於代理與其他代理,模擬器或用戶互動)或離線。此外,您可以使用柏拉圖實現的算法,也可以使用tensorflow,pytorch,keras,ludwig等的外部框架。
路德維希(Ludwig)是一個開源深度學習框架,可讓您無需編寫任何代碼而訓練模型。您只需要將數據解析到.csv文件中,創建一個Ludwig Config(在YAML中),該config(在YAML中)描述了您想要的體系結構,哪些功能要在.csv和其他參數中使用,然後在終端中僅運行命令。
路德維希(Ludwig)還提供了一個API,柏拉圖與之兼容。這使柏拉圖可以與路德維希(Ludwig)型號集成,即負載或保存模型,訓練和查詢它們。
在上一節中,柏拉圖的DSTC2解析器生成了一些可用於訓練NLU和NLG的.csv文件。該系統有一個NLU .csv文件( data/DSTC2_NLU_sys.csv ),一個用於用戶( data/DSTC2_NLU_usr.csv )。這些看起來像這樣:
| 成績單 | 意圖 | IOB |
|---|---|---|
| 供素食的昂貴餐廳 | 通知 | b-inform-pricerange ooo b-inform Food o |
| 素食 | 通知 | B-形式食品o |
| 亞洲東方類型的食物 | 通知 | B-信息食品i-inform Food OOO |
| 昂貴的餐廳亞洲美食 | 通知 | b-form-pricerange ooo |
對於培訓NLU模型,您需要編寫一個看起來像這樣的配置文件:
input_features:
-
name: transcript
type: sequence
reduce_output: null
encoder: parallel_cnn
output_features:
-
name: intent
type: set
reduce_output: null
-
name: iob
type: sequence
decoder: tagger
dependencies: [intent]
reduce_output: null
training:
epochs: 100
early_stop: 50
learning_rate: 0.0025
dropout: 0.5
batch_size: 128
此配置文件的示例存在於example/config/ludwig/ludwig_nlu_train.yaml中。培訓工作可以從運行開始:
ludwig experiment
--model_definition_file example/config/ludwig/ludwig_nlu_train.yaml
--data_csv data/DSTC2_NLU_sys.csv
--output_directory models/camrest_nlu/sys/
下一步是將模型加載到應用程序配置中。在example/config/application/CamRest_model_nlu.yaml中,我們提供了一個基於模型NLU的應用程序配置,而其他組件則基於非ML。通過將通往模式( model_path )的路徑更新為您在運行Ludwig時提供給-ox --output_directory參數的值,您可以指定代理需要用於NLU的NLU模型:
...
MODULE_0:
package: applications.cambridge_restaurants.camrest_nlu
class: CamRestNLU
arguments:
model_path: <PATH_TO_YOUR_MODEL>/model
...
並測試該模型有效:
plato run --config CamRest_model_nlu.yaml
DSTC2數據解析器生成了兩個.csv文件,我們可以用於DST: DST_sys.csv和DST_usr.csv ,看起來像這樣:
| dst_prev_food | dst_prev_area | DST_PREV_PRICERANGE | nlu_intent | req_slot | inf_area_value | inf_food_value | inf_pricerange_value | dst_food | dst_area | DST_PRICERANGE | dst_req_slot |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 沒有任何 | 沒有任何 | 沒有任何 | 通知 | 沒有任何 | 沒有任何 | 素食主義者 | 昂貴的 | 素食主義者 | 沒有任何 | 昂貴的 | 沒有任何 |
| 素食主義者 | 沒有任何 | 昂貴的 | 通知 | 沒有任何 | 沒有任何 | 素食主義者 | 沒有任何 | 素食主義者 | 沒有任何 | 昂貴的 | 沒有任何 |
| 素食主義者 | 沒有任何 | 昂貴的 | 通知 | 沒有任何 | 沒有任何 | 亞洲東方 | 沒有任何 | 亞洲東方 | 沒有任何 | 昂貴的 | 沒有任何 |
| 亞洲東方 | 沒有任何 | 昂貴的 | 通知 | 沒有任何 | 沒有任何 | 亞洲東方 | 昂貴的 | 亞洲東方 | 沒有任何 | 昂貴的 | 沒有任何 |
本質上,解析器跟踪以前的對話狀態,NLU的意見以及由此產生的對話狀態。然後,我們可以將其餵入路德維希(Ludwig)來訓練對話狀態跟踪器。這example/config/ludwig/ludwig_dst_train.yaml Ludwig配置
input_features:
-
name: dst_prev_food
type: category
-
name: dst_prev_area
type: category
-
name: dst_prev_pricerange
type: category
-
name: dst_intent
type: category
-
name: dst_slot
type: category
-
name: dst_value
type: category
output_features:
-
name: dst_food
type: category
-
name: dst_area
type: category
-
name: dst_pricerange
type: category
-
name: dst_req_slot
type: category
training:
epochs: 100
現在,我們需要用路德維希(Ludwig)培訓我們的模型:
ludwig experiment
--model_definition_file example/config/ludwig/ludwig_dst_train.yaml
--data_csv data/DST_sys.csv
--output_directory models/camrest_dst/sys/
並使用基於模型的DST運行柏拉圖代理:
plato run --config CamRest_model_dst.yaml
您當然可以嘗試其他架構和培訓參數。
到目前為止,我們已經看到瞭如何使用外部框架(即路德維希)訓練柏拉圖代理的組件。在本節中,我們將看到如何使用柏拉圖的內部算法來離線訓練對話政策,使用監督學習和在線使用強化學習。
除了.csv文件外,DSTC2解析器還使用Plato的對話劇集記錄器還保存在柏拉圖體驗日誌中的對話: logs/DSTC2_system和logs/DSTC2_user 。這些日誌包含有關每個對話的信息,例如當前的對話狀態,採取的動作,下一個對話狀態,觀察到的獎勵,輸入話語,成功等。這些日誌可以直接加載到對話式代理中,可用於填充體驗池。
然後,您需要做的就是編寫一個加載這些日誌的配置文件( example/config/CamRest_model_supervised_policy_train.yaml ):
GENERAL:
...
experience_logs:
save: False
load: True
path: logs/DSTC2_system
...
DIALOGUE:
# Since this configuration file trains a supervised policy from data loaded
# from the logs, we only really need one dialogue just to trigger the train.
num_dialogues: 1
initiative: system
domain: CamRest
AGENT_0:
role: system
max_turns: 15
train_interval: 1
train_epochs: 100
save_interval: 1
...
DM:
package: plato.agent.component.dialogue_manager.dialogue_manager_generic
class: DialogueManagerGeneric
arguments:
DST:
package: plato.agent.component.dialogue_state_tracker.slot_filling_dst
class: SlotFillingDST
policy:
package: plato.agent.component.dialogue_policy.deep_learning.supervised_policy
class: SupervisedPolicy
arguments:
train: True
learning_rate: 0.9
exploration_rate: 0.995
discount_factor: 0.95
learning_decay_rate: 0.95
exploration_decay_rate: 0.995
policy_path: models/camrest_policy/sys/sys_supervised_data
...
請注意,我們只使用從日誌中加載的經驗來進行一次對話,但要訓練100個時期的訓練:
plato run --config CamRest_model_supervised_policy_train.yaml
培訓完成後,我們可以測試我們的監督政策:
plato run --config CamRest_model_supervised_policy_test.yaml
在上一節中,我們看到瞭如何培訓監督對話政策。現在,我們可以看到如何使用加強算法來培訓加強學習政策。為此,我們在配置文件中定義了相關類:
...
AGENT_0:
role: system
max_turns: 15
train_interval: 500
train_epochs: 3
train_minibatch: 200
save_interval: 5000
...
DM:
package: plato.agent.component.dialogue_manager.dialogue_manager_generic
class: DialogueManagerGeneric
arguments:
DST:
package: plato.agent.component.dialogue_state_tracker.slot_filling_dst
class: SlotFillingDST
policy:
package: plato.agent.component.dialogue_policy.deep_learning.reinforce_policy
class: ReinforcePolicy
arguments:
train: True
learning_rate: 0.9
exploration_rate: 0.995
discount_factor: 0.95
learning_decay_rate: 0.95
exploration_decay_rate: 0.995
policy_path: models/camrest_policy/sys/sys_reinforce
...
請注意,在策略的參數下, AGENT_0下的學習參數和算法特定參數。然後,我們使用此配置致電Plato:
plato run --config CamRest_model_reinforce_policy_train.yaml
並測試訓練有素的政策模型:
plato run --config CamRest_model_reinforce_policy_test.yaml
請注意,其他組件也可以在線培訓,要么使用路德維希的API或通過在柏拉圖中實施學習算法。
還請注意,日誌文件可以加載並用作任何組件和學習算法的體驗池。但是,您可能需要為某些柏拉圖組件實現自己的學習算法。
要訓練NLG模塊,您需要編寫一個看起來像這樣的配置文件(例如example/config/application/CamRest_model_nlg.yaml ):
---
input_features:
-
name: nlg_input
type: sequence
encoder: rnn
cell_type: lstm
output_features:
-
name: nlg_output
type: sequence
decoder: generator
cell_type: lstm
training:
epochs: 20
learning_rate: 0.001
dropout: 0.2
並訓練您的模型:
ludwig experiment
--model_definition_file example/config/ludwig/ludwig_nlg_train.yaml
--data_csv data/DSTC2_NLG_sys.csv
--output_directory models/camrest_nlg/sys/
下一步是將模型加載到柏拉圖中。轉到CamRest_model_nlg.yaml配置文件,並在必要時更新路徑:
...
NLG:
package: applications.cambridge_restaurants.camrest_nlg
class: CamRestNLG
arguments:
model_path: models/camrest_nlg/sys/experiment_run/model
...
並測試該模型有效:
plato run --config CamRest_model_nlg.yaml
請記住,路德維希(Ludwig)每次被調用時都會創建一個新的persiment_run_i目錄,因此請確保在Plato的配置中保留正確的路徑。
請注意,路德維希還提供了一種在線培訓模型的方法,因此實際上,您需要寫的很少的代碼來構建,訓練和評估柏拉圖的新深度學習組件。
對於此示例,我們將使用您可以從此處下載的MetalWoz數據集。
柏拉圖通過通用代理支持經過培訓的模型。在這裡,我們將看到從頭開始創建一個簡單的SEQ2SEQ對話代理所需的步驟。以MetalWoz為例,我們需要以以下方式進行以下操作:
由於我們只是訓練一個簡單的SEQ2SEQ模型(文本到文本),因此我們需要解析器來提取用戶和系統話語。這些將保存在Ludwig將在步驟4中使用的.CSV文件中。
有關Metalwoz解析器的簡單實現,請參見utilities/parser/Parse_MetalWOZ.py
請注意,該解析器只能解析一個文件(一個域)。但是,您可以輕鬆地修改它以滿足您的需求。這是解析器為披薩訂購域產生的輸出的樣本:
| 用戶 | 系統 |
|---|---|
| 你好 | 您好,我該如何幫助您? |
| 我需要下訂單披薩需要幫助 | 當然,您想添加什麼? |
| 我想要一個帶有蘑菇,意大利辣香腸和培根澆頭的披薩 | 不幸的是,這個位置是您要求的培根頂。您想替換有不同的頂部嗎? |
| 菠蘿怎麼樣 | 可以使用該餡料。我在您的訂單中添加了一個帶有蘑菇,意大利辣香腸和菠蘿的比薩餅。您想要什麼尺寸? |
| 中等的 | 好吧,更新了。您想在訂單中添加更多嗎? |
| 就這些了,謝謝 | 好吧,您的總數是14.99。您的披薩將大約可以拾取。 20分鐘。 |
注意數據中實際上不存在第一個用戶話語。但是,我們需要一些東西來提示模型產生系統的問候 - 我們可以使用一個空句子或任何其他問候(或這些結合)。
然後,您可以按照以下方式進行柏拉圖分析:
plato parse --config Parse_MetalWOZ.yaml
首先,我們可以使用路德維希(Ludwig)訓練非常簡單的模型(請隨時在此處使用您喜歡的深度學習框架):
input_features:
-
name: user
type: text
level: word
encoder: rnn
cell_type: lstm
reduce_output: null
output_features:
-
name: system
type: text
level: word
decoder: generator
cell_type: lstm
attention: bahdanau
training:
epochs: 100
您可以修改此配置,以反映您選擇的體系結構,並使用路德維格(Ludwig)進行訓練:
ludwig train
--data_csv data/metalwoz.csv
--model_definition_file example/config/ludwig/metalWOZ_seq2seq_ludwig.yaml
--output_directory "models/joint_models/"
該類只需要處理模型的加載,對其進行適當查詢並適當地格式化其輸出即可。在我們的情況下,我們需要將輸入文本包裝到熊貓數據框中,從輸出中獲取預測的令牌,然後將它們加入將返回的字符串。請參閱此處的類: plato.agent.component.joint_model.metal_woz_seq2seq.py
有關example/config/application/metalwoz_generic.yaml有關示例通用配置文件,該文件與文本通過文本與SEQ2SEQ代理進行交互。您可以嘗試如下:
plato run --config metalwoz_text.yaml
請記住,如有必要,請更新訓練有素的型號的路徑!默認路徑假設您從柏拉圖的根目錄運行路德維希火車命令。
柏拉圖的主要功能之一使兩個代理可以相互作用。每個代理可以具有不同的角色(例如,系統和用戶),不同的目標並接收不同的獎勵信號。如果代理商正在合作,則可以共享其中一些(例如,構成成功的對話)。
為了在劍橋餐廳域上運行多個柏拉圖特工,我們運行以下命令來訓練特工的對話政策並測試:
訓練階段:培訓2個政策(每個代理商1個)。這些政策是使用狼算法訓練的:
plato run --config MultiAgent_train.yaml
測試階段:使用在訓練階段訓練的策略來創建兩個代理之間的對話:
plato run --config MultiAgent_test.yaml
儘管基本控制器當前允許兩個代理交互,但將其擴展到多個代理非常簡單(例如,使用黑板架構,每個代理將其輸出廣播到其他代理)。這可以支持場景,例如智能家居,每個設備都是代理,具有各種角色的多用戶交互等等。
柏拉圖為兩種用戶模擬器提供了實現。一個是基於議程的用戶模擬器,另一個是一個模擬器,試圖模仿數據中觀察到的用戶行為。但是,我們鼓勵研究人員簡單地用柏拉圖(一個是“系統”,一個是“用戶”),而不是在可能的情況下使用模擬用戶。
基於議程的用戶模擬器是由Schatzmann提出的,並在本文中進行了詳細說明。從概念上講,模擬器保留要說的話的“議程”,通常將其作為堆棧實現。當模擬器收到輸入時,它會諮詢其策略(或一組規則),以查看將哪些內容推入議程,以作為對輸入的響應。經過一些管家(例如,刪除不再有效的重複或內容)之後,模擬器將彈出一個或多個項目,該項目將用於製定其響應。
基於議程的用戶模擬器還具有錯誤模擬模塊,可以模擬語音識別 /語言理解錯誤。基於某些概率,它將扭曲模擬器的輸出對話行為 - 意圖,插槽或值(每個概率不同)。這是該模擬器收到的全部參數列表的示例:
patience: 5 # Stop after <patience> consecutive identical inputs received
pop_distribution: [0.8, 0.15, 0.05] # pop 1 act with 0.8 probability, 2 acts with 0.15, etc.
slot_confuse_prob: 0.05 # probability by which the error model will alter the output dact slot
op_confuse_prob: 0.01 # probability by which the error model will alter the output dact operator
value_confuse_prob: 0.01 # probability by which the error model will alter the output dact value
nlu: slot_filling # type of NLU the simulator will use
nlg: slot_filling # type of NLG the simulator will use
該模擬器被設計為一個簡單的基於策略的模擬器,可以在對話級別或話語級別上操作。為了演示其工作原理,DSTC2解析器為此模擬器創建了一個策略文件: user_policy_reactive.pkl (反應性,因為它對系統對話的反應而不是用戶模擬器狀態)。這實際上是一個簡單的詞典:
System Dial. Act 1 --> {'dacts': {User Dial. Act 1: probability}
{User Dial. Act 2: probability}
...
'responses': {User utterance 1: probability}
{User utterance 2: probability}
...
System Dial. Act 2 --> ...
鍵代表“輸入對話法”(例如來自system對話代理)。每個密鑰的值是兩個元素的字典,代表模擬器將從對話行為或話語模板上進行採樣的概率分佈。
要查看示例,您可以運行以下配置:
plato run --config CamRest_dtl_simulator.yaml
有兩種方法可以根據其功能創建新模塊。例如,如果模塊實現了執行NLU或對話策略的新方法,則應編寫從相應的抽像類繼承的類。
但是,如果模塊不符合單個代理基本組件之一,例如,它執行命名實體識別或預測對話的行為,則必須編寫一個直接從conversational_module繼承的類。然後,您可以通過在配置中提供適當的軟件包路徑,類名和參數來通過通用代理加載模塊。
...
MODULE_i:
package: my_package.my_module
Class: MyModule
arguments:
model_path: models/my_module/parameters/
...
...
當心!您有責任確保可以按照您的通用配置文件中提供的模塊和之後的模塊適當地處理和處理此模塊的I/O。
柏拉圖還支持(邏輯上)模塊的並行執行。為了使您需要在配置中具有以下結構:
...
MODULE_i:
parallel_modules: 5
PARALLEL_MODULE_0:
package: my_package.my_module
Class: MyModule
arguments:
model_path: models/myModule/parameters/
...
PARALLEL_MODULE_1:
package: my_package.my_module
Class: MyModule
arguments:
model_path: models/my_module/parameters/
...
...
...
當心!並行執行的模塊的輸出將被包裝到列表中。下一個模塊(例如MODULE_i+1 )將需要能夠處理這種輸入。提供的柏拉圖模塊不是為處理此操作而設計的,您將需要編寫一個自定義模塊來處理多個來源的輸入。
柏拉圖的設計是可擴展的,因此請隨意創建自己的對話狀態,動作,獎勵功能,算法或任何其他組件,以滿足您的特定需求。您只需要從相應的類中繼承即可確保您的實現與柏拉圖兼容。
柏拉圖使用pysimplegui處理圖形用戶界面。 plato.controller.sgui_controller實現了柏拉圖的示例GUI,您可以使用以下命令嘗試一下:
plato gui --config CamRest_GUI_speech.yaml
Special thanks to Mahdi Namazifar, Chandra Khatri, Yi-Chia Wang, Piero Molino, Michael Pearce, Zack Kaden, and Gokhan Tur for their contributions and support, and to studio FF3300 for allowing us to use the Messapia font.
Please understand that many features are still being implemented and some use cases may not be supported yet.
享受!


