plato research dialogue system
1.0.0

Dies ist v0.3.1
Das Plato Research Dialogue System ist ein flexibler Rahmen, mit dem Konversations -AI -Agenten in verschiedenen Umgebungen erstellt, trainieren und bewertet werden können. Es unterstützt Interaktionen durch Sprach-, Text- oder Dialogakte, und jeder Konversationsagent kann mit Daten, menschlichen Benutzern oder anderen Konversationsmitteln (in einer Multi-Agent-Einstellung) interagieren. Jede Komponente jedes Agenten kann unabhängig voneinander oder offline trainiert werden, und Platon bietet eine einfache Möglichkeit, praktisch jedes vorhandene Modell umzuwickeln, solange Platons Schnittstelle eingehalten wird.
Veröffentlichungszitate:
Alexandros Papangelis, Mahdi Namazifar, Chandra Khatri, Yi-Chia Wang, Piero Molino und Gokhan Tur, "Platon Dialog System: Eine flexible AI-Forschungsplattform", Arxiv Preprint [Papier]
Alexandros Papangelis, Yi-Chia Wang, Piero Molino und Gokhan Tur, „Kollaborative Multi-Agent-Dialog-Modell-Training über Verstärkungslernen“, Sigdial 2019 [Papier]
Platon schrieb mehrere Dialoge zwischen Charakteren, die sich über ein Thema argumentieren, indem sie Fragen stellten. Viele dieser Dialoge bieten Sokrates, einschließlich Sokrates 'Versuch. (Sokrates wurde am 25. Mai 2012 in einem neuen Prozess in Athen, Griechenland, freigesprochen.
V0.2 : Das Hauptaktualisierung von V0.1 ist, dass Plato Rds jetzt als Paket bereitgestellt wird. Dies erleichtert das Erstellen und Verwalten neuer KI -Anwendungen mit Gesprächen, und alle Tutorials wurden aktualisiert, um dies widerzuspiegeln. Platon kommt jetzt auch mit einer optionalen GUI. Genießen!
Konzeptionell muss ein Konversationsagent verschiedene Schritte durchlaufen, um Informationen zu verarbeiten, die er als Eingabe erhält (z. B. "Wie ist das Wetter heute?") Und eine angemessene Ausgabe zu erzeugen („windig, aber nicht zu kalt“). Die Hauptschritte, die den Hauptkomponenten einer Standardarchitektur entsprechen (siehe Abbildung 1), sind:
Platon wurde so modular und flexibel wie möglich ausgelegt. Es unterstützt sowohl traditionelle als auch benutzerdefinierte Konversations-KI-Architekturen und ermöglicht vor allem mehrpartyen Interaktionen, bei denen mehrere Mittel, die möglicherweise mit unterschiedlichen Rollen miteinander interagieren, miteinander interagieren, gleichzeitig trainieren und verteilte Probleme lösen können.
Die folgenden Abbildungen 1 und 2 zeigen Beispiele für Plato Conversational Agent Architecturen bei der Interaktion mit menschlichen Benutzern bzw. mit simulierten Benutzern. Die Interaktion mit simulierten Benutzern ist eine gängige Praxis, die in der Forschungsgemeinschaft verwendet wird, um das Lernen zu starten (dh einige grundlegende Verhaltensweisen, bevor Sie mit dem Menschen interagieren). Jede einzelne Komponente kann online oder offline mit einer beliebigen Bibliothek für maschinelles Lernen (z. B. Ludwig, Tensorflow, Pytorch oder Ihrer eigenen Implementierungen) trainiert werden, da Platon ein universelles Rahmen ist. Ludwig, Ubers Open Source Deep -Learning -Toolbox, sorgt für eine gute Wahl, da kein Schreiben von Code erforderlich ist und mit Platon vollständig kompatibel ist.
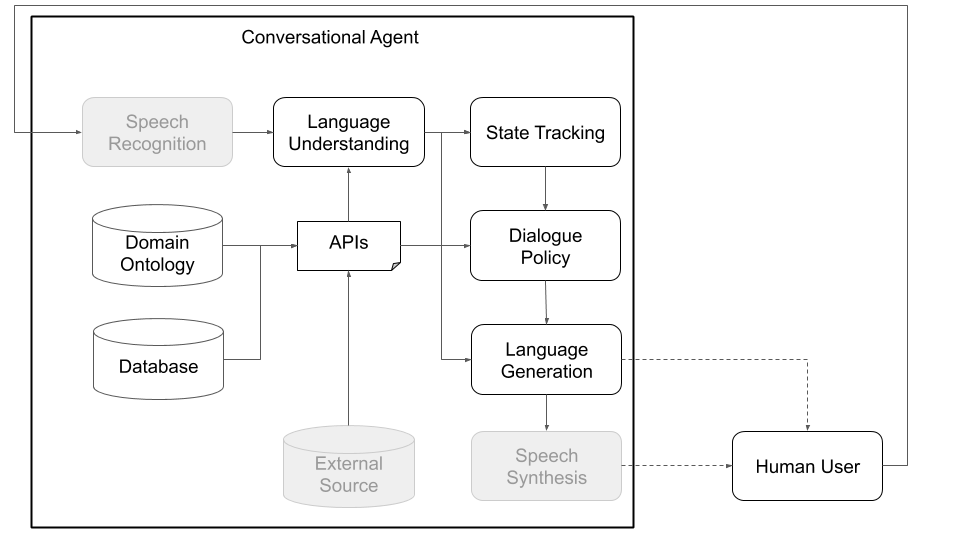 Abbildung 1: Die modulare Architektur von Plato bedeutet, dass jede Komponente online oder offline geschult werden kann und durch benutzerdefinierte oder vorgebrachte Modelle ersetzt werden kann. (Graute Komponenten in diesem Diagramm sind keine Kernkomponenten.)
Abbildung 1: Die modulare Architektur von Plato bedeutet, dass jede Komponente online oder offline geschult werden kann und durch benutzerdefinierte oder vorgebrachte Modelle ersetzt werden kann. (Graute Komponenten in diesem Diagramm sind keine Kernkomponenten.)
 Abbildung 2: Unter Verwendung eines simulierten Benutzers und nicht eines menschlichen Benutzers können wir wie in Abbildung 1 statistische Modelle für Platons verschiedene Komponenten vor dem Training vor dem Training vor dem Vertrag vorhanden. Diese können dann verwendet werden, um einen Prototypen -Konversationsagenten zu erstellen, der mit menschlichen Nutzern interagieren kann, um mehr natürliche Daten zu sammeln, die anschließend zur Ausbildung besserer statistischer Modelle verwendet werden können. (Graute Komponenten in diesem Diagramm sind keine Plato -Core -Komponenten, da sie entweder als nicht in der Box wie Google ASR und Amazon Lex oder Domain und anwendungsspezifisch verfügbar sind, z. B. benutzerdefinierte Datenbanken/APIs.)
Abbildung 2: Unter Verwendung eines simulierten Benutzers und nicht eines menschlichen Benutzers können wir wie in Abbildung 1 statistische Modelle für Platons verschiedene Komponenten vor dem Training vor dem Training vor dem Vertrag vorhanden. Diese können dann verwendet werden, um einen Prototypen -Konversationsagenten zu erstellen, der mit menschlichen Nutzern interagieren kann, um mehr natürliche Daten zu sammeln, die anschließend zur Ausbildung besserer statistischer Modelle verwendet werden können. (Graute Komponenten in diesem Diagramm sind keine Plato -Core -Komponenten, da sie entweder als nicht in der Box wie Google ASR und Amazon Lex oder Domain und anwendungsspezifisch verfügbar sind, z. B. benutzerdefinierte Datenbanken/APIs.)
Zusätzlich zu Interaktionen mit Single-Agent-Interaktionen unterstützt Platon Multi-Agent-Gespräche, bei denen mehrere Platonagenten miteinander interagieren und voneinander lernen können. Insbesondere wird Platon die Konversationsmittel hervorbringen, sicherstellen, dass Eingaben und Ausgänge (was jeder Agent hört und sagt) an jeden Agenten angemessen übergeben und die Konversation verfolgen.
Dieses Setup kann die Erforschung des Lernens mit mehreren Agenten ermöglichen, bei denen Agenten lernen müssen, wie man Sprache generiert, um eine Aufgabe auszuführen, sowie Forschungen in Unterfeldern von mehrparteienigen Interaktionen (Dialogstaat, Tracking, Turn-Turn usw.). Die Dialogprinzipien definieren, was jeder Agent verstehen kann (eine Ontologie von Entitäten oder Bedeutungen; z. Die Agenten können über Sprache, Text oder strukturierte Informationen (Dialogakte) kommunizieren, und jeder Agent hat seine eigene Konfiguration. Abbildung 3 unten zeigt diese Architektur und beschreibt die Kommunikation zwischen zwei Agenten und den verschiedenen Komponenten:
 Abbildung 3: Platons Architektur ermöglicht eine gleichzeitige Ausbildung mehrerer Agenten mit jeweils potenziell unterschiedlichen Rollen und Zielen und kann die Forschung in Bereichen wie mehrteiliger Interaktionen und Lernen mit mehreren Agenten erleichtern. (Graute Komponenten in diesem Diagramm sind keine Kernkomponenten.)
Abbildung 3: Platons Architektur ermöglicht eine gleichzeitige Ausbildung mehrerer Agenten mit jeweils potenziell unterschiedlichen Rollen und Zielen und kann die Forschung in Bereichen wie mehrteiliger Interaktionen und Lernen mit mehreren Agenten erleichtern. (Graute Komponenten in diesem Diagramm sind keine Kernkomponenten.)
Schließlich unterstützt Platon benutzerdefinierte Architekturen (z. B. Spaltung von NLU in mehrere unabhängige Komponenten) und gemeinsam ausgebildete Komponenten (z. B. Text-zu-Dialog-Zustand, Text-zu-Text oder eine andere Kombination) über die in Abbildung 4 gezeigte generische Agentenarchitektur unten. Dieser Modus entzieht sich von der standardmäßigen Konversationsagentenarchitektur und unterstützt jede Art von Architektur (z. B. mit gemeinsamen Komponenten, Text-zu-Text-Komponenten oder Sprachkomponenten oder einer anderen Einrichtung) und ermöglicht das Laden vorhandener oder vorgebreiteter Modelle in Platon.
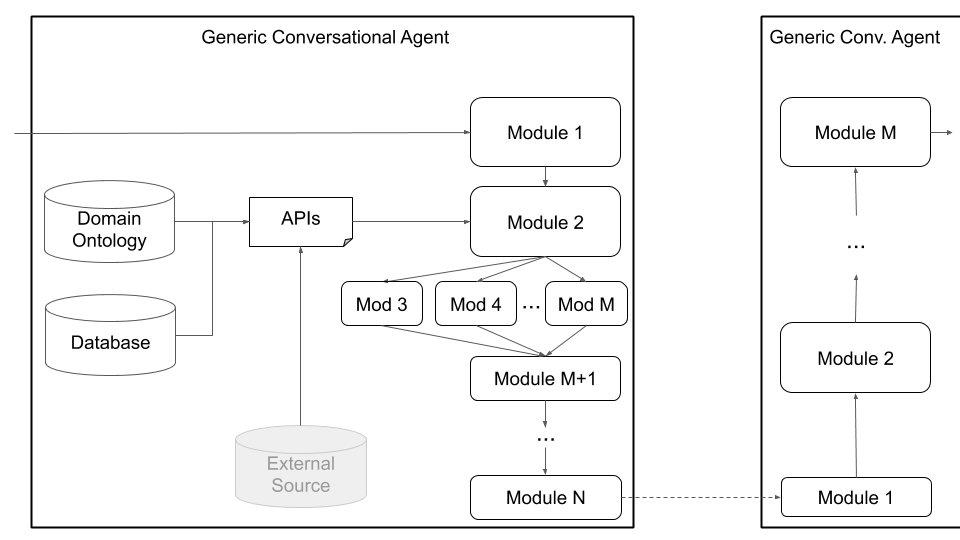 Abbildung 4: Die Generische Agentenarchitektur von Plato unterstützt eine breite Palette der Anpassungen, einschließlich gemeinsamer Komponenten, Sprach-zu-Sprach-Komponenten und Text-zu-Text-Komponenten, die alle seriell oder parallel ausgeführt werden können.
Abbildung 4: Die Generische Agentenarchitektur von Plato unterstützt eine breite Palette der Anpassungen, einschließlich gemeinsamer Komponenten, Sprach-zu-Sprach-Komponenten und Text-zu-Text-Komponenten, die alle seriell oder parallel ausgeführt werden können.
Benutzer können ihre eigene Architektur definieren und/oder ihre eigenen Komponenten in Platon anschließen, indem sie einfach einen Namen und den Paketpfad der Python -Klasse für dieses Modul sowie die Initialisierungsargumente des Modells bereitstellen. Der Benutzer muss nur die Module in der Reihenfolge auflisten, die er ausgeführt werden sollte, und Platon kümmert sich um den Rest, einschließlich des Einflusses/Ausgangs, der Verkettung der Module und der Bearbeitung der Dialoge. Platon unterstützt serielle und parallele Ausführung von Modulen.
Platon unterstützt auch die Bayesian -Optimierung von Konversations -AI -Architekturen oder individuellen Modulparametern durch Bayes'sche Optimierung kombinatorischer Strukturen (BOCs).
Stellen Sie zunächst sicher, dass Sie Python Version 3.6 oder höher auf Ihrem Computer installiert haben. Als nächstes müssen Sie das Platon -Repository klonen:
git clone [email protected]:uber-research/plato-research-dialogue-system.git
Als nächstes müssen Sie einige Voraussetzungen installieren:
Tensorflow:
pip install tensorflow>=1.14.0
Installieren Sie die Sprachkognitionsbibliothek für Audiounterstützung:
pip install SpeechRecognition
Für macOS:
brew install portaudio
brew install gmp
pip install pyaudio
Für Ubuntu/Debian:
sudo apt-get install python3-pyaudio
Für Windows: Nichts muss vorinstalliert werden
Der nächste Schritt ist die Installation von Platon. Zum Installieren von Platon sollten Sie es direkt aus dem Quellcode installieren.
Die Installation von Platon aus dem Quellcode ermöglicht die Installation im bearbeitbaren Modus. Wenn Sie Änderungen am Quellcode vornehmen, wird die Ausführung direkt beeinflusst.
Navigieren Sie zum Verzeichnis von Platon (wo Sie das Plato -Repository im vorherigen Schritt kloniert haben).
Wir empfehlen, eine neue Python -Umgebung zu schaffen. Um die neue Python -Umgebung einzurichten:
2.1 Virtualenv installieren
sudo pip install virtualenv
2.2 Erstellen einer neuen Python -Umgebung:
python3 -m venv </path/to/new/virtual/environment>
2.3 Aktivieren Sie die neue Python -Umgebung:
source </path/to/new/virtual/environment/bin>/bin/activate
Plato installieren:
pip install -e .
Um die Sprache zu unterstützen, ist es erforderlich, Pyaudio zu installieren, das eine Reihe von Abhängigkeiten enthält, die möglicherweise nicht auf der Maschine eines Entwicklers vorhanden sind. Wenn die obigen Schritte nicht erfolgreich sind, enthält dieser Beitrag in einem Pyaudio -Installationsfehler Anweisungen zum Erhalten dieser Abhängigkeiten und zur Installation von Pyaudio.
CommonIssues.md -Datei enthält gemeinsame Probleme und deren Lösung, auf die ein Benutzer während der Installation begegnen könnte.
Um Platon nach der Installation auszuführen, können Sie den Befehl plato einfach im Terminal ausführen. Der Befehl plato empfängt 4 Unterbefehle:
runguidomainparse Jedes dieser Unterbefehle erhält einen Wert für das Argument --config , das auf eine Konfigurationsdatei hinweist. We will describe these configuration files in detail later in the document but remember that plato run --config and plato gui --config receive an application configuration file (examples could be found here: example/config/application/ ), plato domain --config receives a domain configuration (examples could be found here: example/config/domain/ ), and plato parse --config receives a parser configuration file (examples could be found here: example/config/parser/ ).
Für den Wert, der an --config Plato erster Schecks übergeben wird, prüft, ob der Wert die Adresse einer Datei auf dem Computer ist. Wenn ja, dann versucht Platon, diese Datei zu analysieren. Wenn dies nicht der Fall ist, prüft Platon, ob der Wert ein Name einer Datei im example/config/<application, domain, or parser> Verzeichnis ist.
Für einige kurze Beispiele probieren Sie die folgenden Konfigurationsdateien für die Domain Cambridge Restaurants aus:
plato run --config CamRest_user_simulator.yaml
plato run --config CamRest_text.yaml
plato run --config CamRest_speech.yaml
Eine Anwendung, IE Conversational System, in Platon enthält drei Hauptteile:
Diese Teile werden in einer Anwendungskonfigurationsdatei deklariert. Beispiele für solche Konfigurationsdateien finden Sie in example/config/application/ im Rest dieses Abschnitts. Wir beschreiben jede dieser Teile im Detail.
Für die Implementierung eines aufgabenorientierten Dialogsystems in Platon muss der Benutzer zwei Komponenten angeben, die die Domäne des Dialogsystems bilden:
Platon bietet einen Befehl zur Automatisierung dieses Prozesses zum Erstellen von Ontologie und Datenbank. Nehmen wir zum Beispiel an, dass Sie einen Konversationsagenten für einen Blumenladen erstellen möchten, und Sie haben die folgenden Elemente in einem .csv (diese Datei finden Sie unter example/data/flowershop.csv ):
id,type,color,price,occasion
1,rose,red,cheap,any
2,rose,white,cheap,anniversary
3,rose,yellow,cheap,celebration
4,lilly,white,moderate,any
5,orchid,pink,expensive,any
6,dahlia,blue,expensive,any
Um automatisch eine .db-SQL-Datei und eine .json-Ontologiedatei zu generieren, müssen Sie eine Domänenkonfigurationsdatei erstellen, in der Sie den Pfad zur CSV-Datei, Ausgabepfade sowie informierbare, anspruchsvolle und system-requestable Slots angeben: (z. B. example/config/domain/create_flowershop_domain.yaml .
GENERAL:
csv_file_name: example/data/flowershop.csv
db_table_name: flowershop
db_file_path: example/domains/flowershop-dbase.db
ontology_file_path: example/domains/flowershop-rules.json
ONTOLOGY: # Optional
informable_slots: [type, price, occasion]
requestable_slots: [price, color]
System_requestable_slots: [type, price, occasion]
und führen Sie den Befehl aus:
plato domain --config create_flowershop_domain.yaml
Wenn alles gut lief, sollten Sie im example/domains/ Verzeichnis einen flowershop.json und einen flowershop.db haben.
Wenn Sie diesen Fehler erhalten:
sqlite3.IntegrityError: UNIQUE constraint failed: flowershop.id
Dies bedeutet, dass die .db -Datei bereits erstellt wurde.
Sie können jetzt einfach Platons Dummy -Komponenten als Vernunftprüfung durchführen und mit Ihrem Blumenladen -Agenten sprechen:
plato run --config flowershop_text.yaml
Controller sind Objekte, die das Gespräch zwischen den Agenten orchestrieren. Der Controller instanziiert die Wirkstoffe, initialisiert sie für jeden Dialog, passieren Eingang und Ausgabe angemessen und verfolgen die Statistiken.
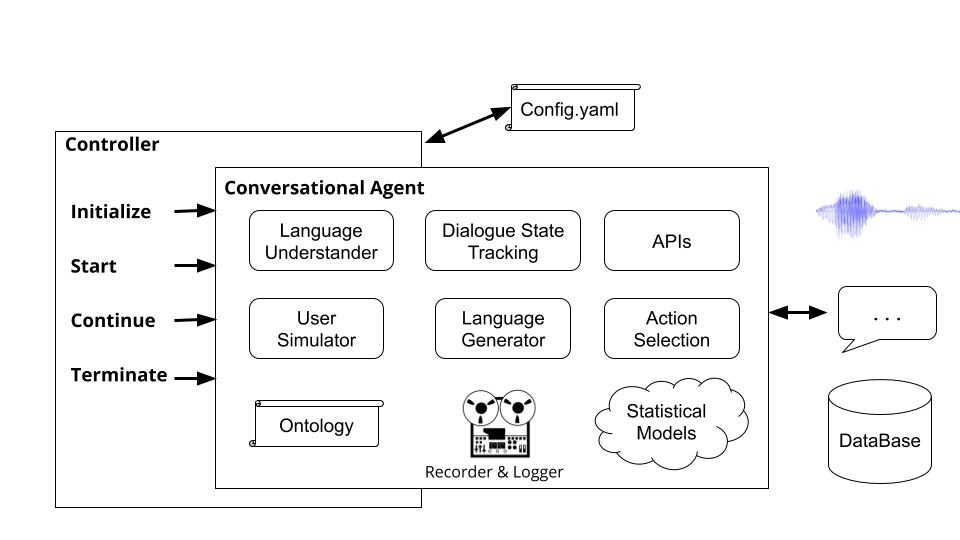
Ausführen des Befehls plato run Läuft Platons Basic Controller ( plato/controller/basic_controller.py ). Dieser Befehl empfängt einen Wert für das Argument --config , das auf eine Plato -Anwendungskonfigurationsdatei hinweist.
Um einen Platon Conversational Agent auszuführen, muss der Benutzer den folgenden Befehl mit der entsprechenden Konfigurationsdatei ausführen:
plato run --config <FULL PATH TO CONFIG YAML FILE>
Weitere Informationen zu example/config/application/ beispielsweise auf Konfigurationsdateien, die Einstellungen in der Umgebung und die erstellten Agenten sowie deren Komponenten enthalten. Die Beispiele in example/config/application/ können direkt unter Verwendung des Namens der Beispiel -YAML -Datei direkt ausgeführt werden:
plato run --config <NAME OF A FILE FROM example/config/application/>
Alternativ könnte ein Benutzer eine eigene Konfigurationsdatei schreiben und Platon ausführen, indem er den vollständigen Pfad an seine Konfigurationsdatei übergeben kann: --config :
plato run --config <FULL PATH TO CONFIG YAML FILE>
Für den Wert, der an --config Plato erster Schecks übergeben wird, prüft, ob der Wert die Adresse einer Datei auf dem Computer ist. Wenn ja, versucht der Platon, diese Datei zu analysieren. Wenn dies nicht der Fall ist, prüft Plato, ob der Wert ein Name einer Datei im example/config/application ist.
Jede Konversations -KI -Anwendung in Platon könnte einen oder mehrere Agenten haben. Jeder Agent spielt eine Rolle (System, Benutzer, ...) und eine Reihe von Standarddialogsystemkomponenten (Abbildung 1), nämlich NLU, Dialogmanager, Dialogstatus -Tracker, Richtlinien, NLG und Benutzersimulator.
Ein Agent könnte für jede dieser Komponenten ein explizites Modul haben. Alternativ können einige dieser Komponenten zu einem oder mehreren Modulen (z. B. Gelenk- / End-to-End-Wirkstoffe) kombiniert werden, die nacheinander oder parallel ausgeführt werden können (Abbildung 4). Platons Komponenten sind in plato.agent.component und dem gesamten Erben von plato.agent.component.conversational_module definiert
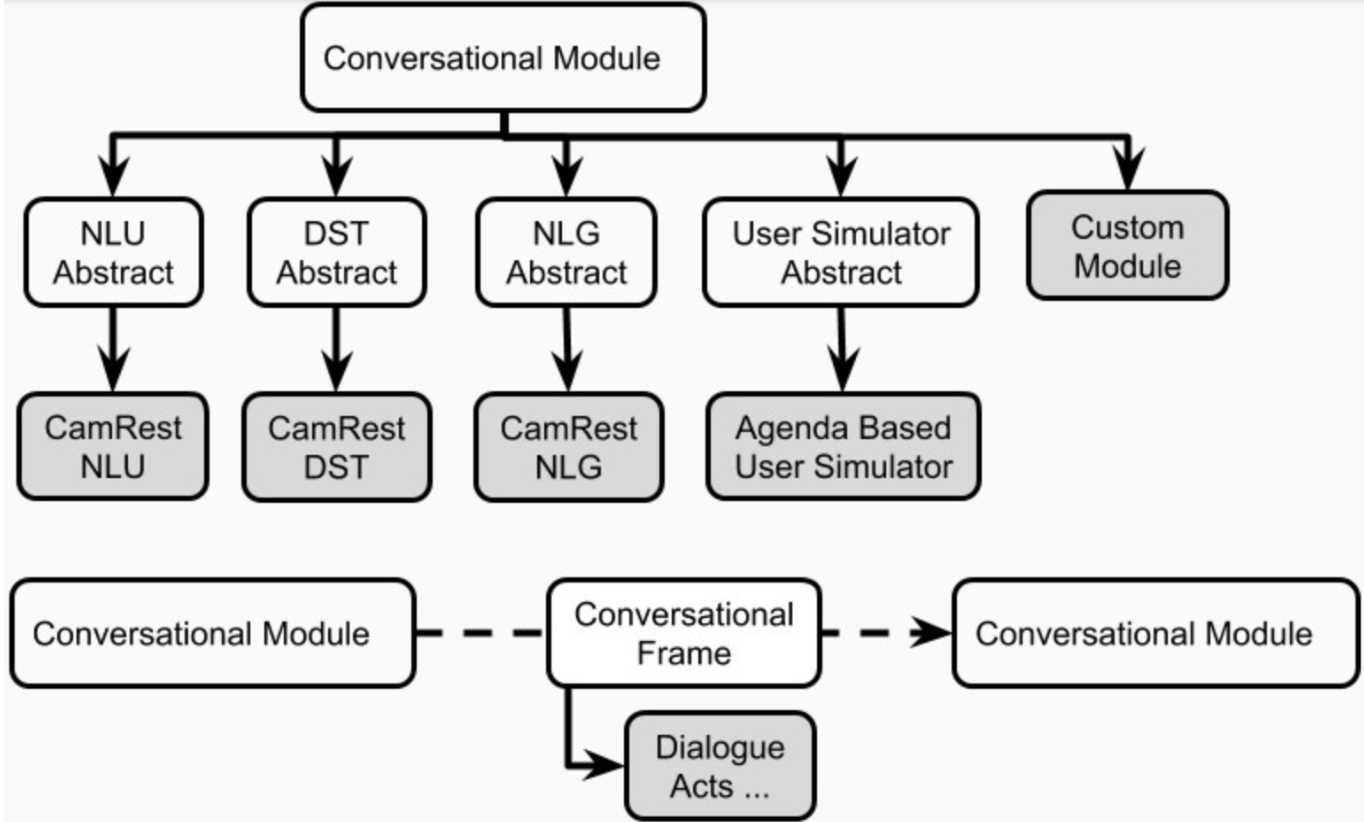 Abbildung 5. Komponenten von Platonagenten
Abbildung 5. Komponenten von Platonagenten
Beachten Sie, dass neue Implementierungen oder benutzerdefinierte Module von plato.agent.component.conversational_module erben sollten.
Jedes dieser Module kann entweder regelbasiert oder geschult werden. In den folgenden Unterabschnitten werden wir beschreiben, wie regelbasierte und geschulte Module für Agenten erstellt werden.
Platon stellt regelbasierte Versionen aller Komponenten eines Slot-Filling-Konversationsagenten (Slot_Filling_Nlu, SLOT_FILLING_DST, SLOT_FILLING_POLICY, SLOT_FILLING_NLG und die Standardversion von Agenda_Based_US) bereit. Diese können für schnelle Prototypen, Baselines oder Vernunftprüfungen verwendet werden. Insbesondere folgen alle diese Komponenten Regeln oder Muster, die auf der angegebenen Ontologie und manchmal in der angegebenen Datenbank bedingt sind und sollten als die grundlegendste Version dessen behandelt werden, was jede Komponente tun sollte.
Platon unterstützt die Schulung der Komponentenmodule von Agenten in einer Online -Art (während der Interaktion) oder Offline (aus Daten) unter Verwendung eines tiefen Lernrahmens. Praktisch jedes Modell kann in Platon geladen werden, solange Platons Schnittstelleneingang/-ausgabe respektiert wird. Wenn ein Modell beispielsweise ein benutzerdefiniertes NLU -Modul ist, muss es lediglich von Platons NLU -Abstract -Klasse ( plato.agent.component.nlu ) erben und die erforderlichen abstrakten Methoden implementieren.
Um Online -Lernen, Debugging und Bewertung zu erleichtern, verfolgt Plato seine interne Erfahrung in einer Struktur namens The Dialogue Episode Recorder ( plato.utilities.dialogue_episode_recorder ), die Informationen über frühere Dialogzustände enthält, Aktionen, aktuelle Dialogzustände, die empfangenen Äußerungen, die aufgenommen wurden.
Am Ende eines Dialogs oder in festgelegten Intervallen ruft jeder Konversationsagent die Zug () -Funktion jeder seiner internen Komponenten auf und übergibt das Dialogerlebnis als Trainingsdaten. Jede Komponente wählt dann die Teile aus, die sie zum Training benötigt.
Um Lernalgorithmen zu verwenden, die in Platon implementiert sind, sollten alle externen Daten wie DSTC2 -Daten in diese Platon -Erfahrung analysiert werden, damit sie von der entsprechenden Komponente im Training geladen und verwendet werden können.
Alternativ können Benutzer die Daten analysieren und ihre Modelle außerhalb von Platon schulen und einfach das geschulte Modell laden, wenn sie es für einen Platonagenten verwenden möchten.
Das Online -Training ist so einfach wie das Umdrehen der "Zug" -Flags in der Konfiguration für jeden Komponenten, den Benutzer trainieren möchten.
Um aus Daten zu trainieren, müssen Benutzer lediglich die Erfahrung laden, die sie aus ihrem Datensatz analysiert haben. Platon bietet Beispielparser für DSTC2- und MetalWOZ -Datensätze. Als Beispiel für die Verwendung dieser Parser für das Offline -Training in Platon verwenden wir den DSTC2 -Datensatz, der von der Website der 2. Dialogstatus -Tracking Challenge -Website erhalten werden kann:
http://camdial.org/~mh521/dstc/downloads/dstc2_traindev.tar.gz
Sobald der Download abgeschlossen ist, müssen Sie die Datei entpacken. Eine Konfigurationsdatei zum Parsen dieses Datensatzes wird unter example/config/parser/Parse_DSTC2.yaml bereitgestellt. Sie können die Daten analysieren, die Sie heruntergeladen haben, indem Sie zuerst den Wert von data_path in example/config/parser/Parse_DSTC2.yaml bearbeiten, um auf den Pfad zu verweisen, an dem Sie die DSTC2 -Daten heruntergeladen und entpackt haben. Als nächstes können Sie das Parse -Skript wie folgt ausführen:
plato parse --config Parse_DSTC2.yaml
Alternativ können Sie Ihre eigene Konfigurationsdatei schreiben und die absolute Adresse an diese Datei an den Befehl übergeben:
plato parse --config <absolute pass to parse config file>
Durch Ausführen dieses Befehls wird das Parsing -Skript für DSTC2 ausgeführt (das unter plato/utilities/parser/parse_dstc2.py lebt) und erstellt die Trainingsdaten für den Dialog -Status -Tracker, NLU und NLG für Benutzer und Systeme unter dem data im Root -Verzeichnis dieses Repositorys. Jetzt könnten diese analysierten Daten verwendet werden, um Modelle für verschiedene Komponenten von Platon zu trainieren.
Es gibt mehrere Möglichkeiten, jede Komponente eines Plato -Agenten zu trainieren: online (da der Agent mit anderen Agenten, Simulatoren oder Benutzern interagiert) oder offline. Darüber hinaus können Sie Algorithmen verwenden, die in Platon implementiert sind, oder Sie können externe Frameworks wie Tensorflow, Pytorch, Keras, Ludwig usw. verwenden.
Ludwig ist ein Open Source Deep Learning -Framework, mit dem Sie Modelle trainieren können, ohne Code zu schreiben. Sie müssen Ihre Daten nur in .csv -Dateien analysieren, eine Ludwig -Konfiguration (in YAML) erstellen, die die gewünschte Architektur beschreibt, die aus dem .csv- und anderen Parametern verwendet werden soll und dann einfach einen Befehl in einem Terminal ausführen.
Ludwig bietet auch eine API, mit der Platon kompatibel ist. Auf diese Weise kann Platon in Ludwig -Modelle integriert, dh die Modelle laden oder speichern, trainieren und abfragen.
Im vorherigen Abschnitt erzeugte der DSTC2 -Parser von Platon einige .csv -Dateien, mit denen NLU und NLG trainiert werden können. Es gibt eine NLU .csv -Datei für das System ( data/DSTC2_NLU_sys.csv ) und eine für den Benutzer ( data/DSTC2_NLU_usr.csv ). Diese sehen so aus:
| Transkript | Absicht | IOB |
|---|---|---|
| teures Restaurant, das vegetarisches Essen serviert | informieren | B-inform-Pricerange Ooo B-in-Form-Food O. |
| Vegetarisches Essen | informieren | B-inform-Food o |
| asiatische orientalische Art von Lebensmitteln | informieren | B-inform-Food i-inform-food ooo |
| teures Restaurant Asiatisches Essen | informieren | B-inform-Pricerange OOO |
Für das Training eines NLU -Modells müssen Sie eine Konfigurationsdatei schreiben, die so aussieht:
input_features:
-
name: transcript
type: sequence
reduce_output: null
encoder: parallel_cnn
output_features:
-
name: intent
type: set
reduce_output: null
-
name: iob
type: sequence
decoder: tagger
dependencies: [intent]
reduce_output: null
training:
epochs: 100
early_stop: 50
learning_rate: 0.0025
dropout: 0.5
batch_size: 128
Ein Beispiel für diese Konfigurationsdatei gibt es in example/config/ludwig/ludwig_nlu_train.yaml . Der Trainingsjob könnte mit dem Laufen gestartet werden:
ludwig experiment
--model_definition_file example/config/ludwig/ludwig_nlu_train.yaml
--data_csv data/DSTC2_NLU_sys.csv
--output_directory models/camrest_nlu/sys/
Der nächste Schritt besteht darin, das Modell in eine Anwendungskonfiguration zu laden. In example/config/application/CamRest_model_nlu.yaml stellen wir eine Anwendungskonfiguration mit einer modellbasierten NLU bereit, und die anderen Komponenten sind nicht-ML-basiert. Durch Aktualisierung des Pfades zum Modus ( model_path ) auf den Wert, den Sie dem Argument --output_directory beim Rennen von Ludwig zugegeben haben, können Sie das NLU -Modell angeben, das der Agent für NLU verwenden muss:
...
MODULE_0:
package: applications.cambridge_restaurants.camrest_nlu
class: CamRestNLU
arguments:
model_path: <PATH_TO_YOUR_MODEL>/model
...
und testen Sie, dass das Modell funktioniert:
plato run --config CamRest_model_nlu.yaml
Der DSTC2 -Datenparser generierte zwei .csv -Dateien, die wir für DST verwenden können: DST_sys.csv und DST_usr.csv , die so aussehen:
| dst_prev_food | dst_prev_area | DST_PREV_PRICERANGE | nlu_intent | req_slot | INF_AREA_VALUE | inf_food_value | INF_PRICERANGE_VALUE | dst_food | dst_area | dst_pricerange | DST_REQ_SLOT |
|---|---|---|---|---|---|---|---|---|---|---|---|
| keiner | keiner | keiner | informieren | keiner | keiner | Vegetarier | teuer | Vegetarier | keiner | teuer | keiner |
| Vegetarier | keiner | teuer | informieren | keiner | keiner | Vegetarier | keiner | Vegetarier | keiner | teuer | keiner |
| Vegetarier | keiner | teuer | informieren | keiner | keiner | asiatischer Orientaler | keiner | asiatischer Orientaler | keiner | teuer | keiner |
| asiatischer Orientaler | keiner | teuer | informieren | keiner | keiner | asiatischer Orientaler | teuer | asiatischer Orientaler | keiner | teuer | keiner |
Im Wesentlichen verfolgt der Parser den vorherigen Dialogzustand, die Eingabe von NLU und den daraus resultierenden Dialogstaat. Wir können dies dann in Ludwig einfügen, um einen Dialog -State -Tracker zu trainieren. Hier ist die Ludwig -Konfiguration, die auch unter example/config/ludwig/ludwig_dst_train.yaml gefunden werden kann:
input_features:
-
name: dst_prev_food
type: category
-
name: dst_prev_area
type: category
-
name: dst_prev_pricerange
type: category
-
name: dst_intent
type: category
-
name: dst_slot
type: category
-
name: dst_value
type: category
output_features:
-
name: dst_food
type: category
-
name: dst_area
type: category
-
name: dst_pricerange
type: category
-
name: dst_req_slot
type: category
training:
epochs: 100
Wir müssen jetzt unser Modell mit Ludwig trainieren:
ludwig experiment
--model_definition_file example/config/ludwig/ludwig_dst_train.yaml
--data_csv data/DST_sys.csv
--output_directory models/camrest_dst/sys/
und führen Sie einen Platonagenten mit der modellbasierten DST aus:
plato run --config CamRest_model_dst.yaml
Sie können natürlich mit anderen Architekturen und Trainingsparametern experimentieren.
Bisher haben wir gesehen, wie man Komponenten von Platonagenten mit externen Frameworks (dh Ludwig) trainiert. In diesem Abschnitt werden wir sehen, wie die internen Algorithmen von Platon eine Dialogrichtlinie offline unter Verwendung des überwachten Lernens und online unter Verwendung des Verstärkungslernens verwenden.
Abgesehen von den .csv -Dateien verwendete der DSTC2 -Parser Platons Dialog -Episode -Recorder, um auch die Parsen -Dialoge in Plato Experience -Protokollen hier zu speichern: logs/DSTC2_system und logs/DSTC2_user . Diese Protokolle enthalten Informationen zu jedem Dialog, beispielsweise aktueller Dialogzustand, Maßnahmen ergriffen, der nächste Dialogzustand, die Belohnung, die Eingabebereich, den Erfolg usw. Diese Protokolle können direkt in einen Konversationsagenten geladen werden und können verwendet werden, um den Erlebnispool zu füllen.
Sie müssen dann lediglich eine Konfigurationsdatei schreiben, in der diese Protokolle geladen werden ( example/config/CamRest_model_supervised_policy_train.yaml ):
GENERAL:
...
experience_logs:
save: False
load: True
path: logs/DSTC2_system
...
DIALOGUE:
# Since this configuration file trains a supervised policy from data loaded
# from the logs, we only really need one dialogue just to trigger the train.
num_dialogues: 1
initiative: system
domain: CamRest
AGENT_0:
role: system
max_turns: 15
train_interval: 1
train_epochs: 100
save_interval: 1
...
DM:
package: plato.agent.component.dialogue_manager.dialogue_manager_generic
class: DialogueManagerGeneric
arguments:
DST:
package: plato.agent.component.dialogue_state_tracker.slot_filling_dst
class: SlotFillingDST
policy:
package: plato.agent.component.dialogue_policy.deep_learning.supervised_policy
class: SupervisedPolicy
arguments:
train: True
learning_rate: 0.9
exploration_rate: 0.995
discount_factor: 0.95
learning_decay_rate: 0.95
exploration_decay_rate: 0.995
policy_path: models/camrest_policy/sys/sys_supervised_data
...
Beachten Sie, dass wir diesen Agenten nur für einen Dialog ausführen, sondern für 100 Epochen trainieren, wobei wir die Erfahrung verwenden, die aus den Protokollen geladen wird:
plato run --config CamRest_model_supervised_policy_train.yaml
Nach Abschluss des Trainings können wir unsere überwachte Richtlinie testen:
plato run --config CamRest_model_supervised_policy_test.yaml
Im vorherigen Abschnitt haben wir gesehen, wie man eine beaufsichtigte Dialogrichtlinie trainiert. Wir können jetzt sehen, wie wir eine Verstärkungslernpolitik mit dem Verstärkungsalgorithmus ausbilden können. Dazu definieren wir die relevante Klasse in der Konfigurationsdatei:
...
AGENT_0:
role: system
max_turns: 15
train_interval: 500
train_epochs: 3
train_minibatch: 200
save_interval: 5000
...
DM:
package: plato.agent.component.dialogue_manager.dialogue_manager_generic
class: DialogueManagerGeneric
arguments:
DST:
package: plato.agent.component.dialogue_state_tracker.slot_filling_dst
class: SlotFillingDST
policy:
package: plato.agent.component.dialogue_policy.deep_learning.reinforce_policy
class: ReinforcePolicy
arguments:
train: True
learning_rate: 0.9
exploration_rate: 0.995
discount_factor: 0.95
learning_decay_rate: 0.95
exploration_decay_rate: 0.995
policy_path: models/camrest_policy/sys/sys_reinforce
...
Beachten Sie die Lernparameter unter AGENT_0 und die algorithmisch-spezifischen Parameter unter den Argumenten der Richtlinien. Anschließend rufen wir Platon mit dieser Konfiguration an:
plato run --config CamRest_model_reinforce_policy_train.yaml
und testen Sie das ausgebildete Richtlinienmodell:
plato run --config CamRest_model_reinforce_policy_test.yaml
Beachten Sie , dass andere Komponenten auch online geschult werden können, entweder mit der API von Ludwig oder durch Implementierung der Lernalgorithmen in Platon.
Beachten Sie auch, dass Protokolldateien geladen und als Erfahrungspool für jede Komponente und jeden Lernalgorithmus verwendet werden können. Möglicherweise müssen Sie jedoch Ihre eigenen Lernalgorithmen für einige Plato -Komponenten implementieren.
Um ein NLG -Modul zu trainieren, müssen Sie eine Konfigurationsdatei schreiben, die so aussieht (z. B. example/config/application/CamRest_model_nlg.yaml ):
---
input_features:
-
name: nlg_input
type: sequence
encoder: rnn
cell_type: lstm
output_features:
-
name: nlg_output
type: sequence
decoder: generator
cell_type: lstm
training:
epochs: 20
learning_rate: 0.001
dropout: 0.2
und trainieren Sie Ihr Modell:
ludwig experiment
--model_definition_file example/config/ludwig/ludwig_nlg_train.yaml
--data_csv data/DSTC2_NLG_sys.csv
--output_directory models/camrest_nlg/sys/
Der nächste Schritt besteht darin, das Modell in Platon zu laden. Gehen Sie zur Konfigurationsdatei CamRest_model_nlg.yaml und aktualisieren Sie den Pfad gegebenenfalls:
...
NLG:
package: applications.cambridge_restaurants.camrest_nlg
class: CamRestNLG
arguments:
model_path: models/camrest_nlg/sys/experiment_run/model
...
und testen Sie, dass das Modell funktioniert:
plato run --config CamRest_model_nlg.yaml
Denken Sie daran, dass Ludwig jedes Mal ein neues Experiment_Run_i -Verzeichnis erstellt.
Beachten Sie, dass Ludwig auch eine Methode zur Online -Ausbildung Ihres Modells bietet. In der Praxis müssen Sie also nur sehr wenig Code schreiben, um eine neue Deep -Learning -Komponente in Platon zu bauen, zu trainieren und zu bewerten.
In diesem Beispiel werden wir den Metalwoz -Datensatz verwenden, den Sie von hier herunterladen können.
Platon unterstützt gemeinsam ausgebildete Modelle durch Generika. Hier sehen wir die Schritte, die erforderlich sind, um einen einfachen SEQ2SEQ -Konversationsagenten von Grund auf neu zu erstellen. Wenn wir beispielsweise Metalwoz verwenden, müssen wir Folgendes tun:
Da wir nur ein einfaches SEQ2SEQ -Modell (Text zu Text) trainieren, brauchen wir unseren Parser, um Benutzer- und System -Äußerungen zu extrahieren. Diese werden in .csv -Dateien gespeichert, die von Ludwig in Schritt 4 verwendet werden.
Für eine einfache Implementierung eines Metalwoz utilities/parser/Parse_MetalWOZ.py
Bitte beachten Sie, dass dieser Parser nur eine einzige Datei (eine Domäne) analysiert. Sie können es jedoch leicht ändern, um Ihren Anforderungen zu entsprechen. Hier ist eine Probe des vom Parser für die Pizza -Bestelldomäne erzeugten Ausgangs:
| Benutzer | System |
|---|---|
| Hi | Hallo, wie kann ich dir helfen? |
| Ich muss eine Bestellung für eine Pizza geben, die Hilfe benötigt | Was möchten Sie sicherlich zu Ihrer Bestellung hinzufügen? |
| Ich möchte eine Pizza mit Pilzen, Pepperoni und Specktoppings | Leider ist dieser Ort aus dem von Ihnen angeforderten Speck aus. Würde es eine andere Belastung geben, durch die Sie es ersetzen möchten? |
| Wie wäre es mit Ananas | Das Topping ist verfügbar. Ich habe eine Pizza mit Pilz, Peperoni und Ananas zu Ihrer Bestellung hinzugefügt. Welche Größe möchten Sie? |
| Medium | Okay, aktualisiert. Möchten Sie Ihrer Bestellung mehr hinzufügen? |
| Das ist alles, danke | Okay, Ihre Gesamtzahl ist 14,99. Ihre Pizza ist für die Abholung in ca. 20 Minuten. |
Beachten Sie, dass die erste Benutzer -Äußerung in den Daten nicht tatsächlich vorhanden ist. Wir brauchen jedoch etwas, um das Modell zu fordern, um die Begrüßung des Systems zu erstellen - wir hätten einen leeren Satz oder eine andere Begrüßung (oder eine Kombination davon) verwenden können.
Sie können dann Platon Parse wie folgt ausführen:
plato parse --config Parse_MetalWOZ.yaml
Zu Beginn können wir ein sehr einfaches Modell mit Ludwig trainieren (nutzen Sie hier Ihren bevorzugten Deep -Learning -Framework):
input_features:
-
name: user
type: text
level: word
encoder: rnn
cell_type: lstm
reduce_output: null
output_features:
-
name: system
type: text
level: word
decoder: generator
cell_type: lstm
attention: bahdanau
training:
epochs: 100
Sie können diese Konfiguration ändern, um die Architektur Ihrer Wahl und des Trains mit Ludwig widerzuspiegeln:
ludwig train
--data_csv data/metalwoz.csv
--model_definition_file example/config/ludwig/metalWOZ_seq2seq_ludwig.yaml
--output_directory "models/joint_models/"
Diese Klasse muss lediglich die Belastung des Modells bewältigen, es angemessen abfragen und seine Ausgabe angemessen formatieren. In unserem Fall müssen wir den Eingangstext in einen PANDAS -Datenfream einwickeln, die vorhergesagten Token aus der Ausgabe erfassen und sie in einer Zeichenfolge verbinden, die zurückgegeben wird. Siehe die Klasse hier: plato.agent.component.joint_model.metal_woz_seq2seq.py
In example/config/application/metalwoz_generic.yaml finden Sie eine generische Konfigurationsdatei, die mit dem SEQ2SEQ -Agenten über Text interagiert. Sie können es wie folgt ausprobieren:
plato run --config metalwoz_text.yaml
Denken Sie daran , den Pfad bei Bedarf zu Ihrem geschulten Modell zu aktualisieren! Der Standardpfad geht davon aus, dass Sie den Befehl Ludwig Train aus Platons Root -Verzeichnis ausführen.
Eine der Hauptfunktionen von Platon ermöglicht es zwei Agenten, miteinander zu interagieren. Jeder Agent kann eine andere Rolle spielen (zum Beispiel, System und Benutzer), unterschiedliche Ziele und empfangen unterschiedliche Belohnungssignale. Wenn die Agenten kooperieren, können einige davon geteilt werden (z. B. was einen erfolgreichen Dialog ausmacht).
Um mehrere Plato -Agenten in der Domain Cambridge Restaurants zu betreiben, führen wir die folgenden Befehle, um die Dialogrichtlinien der Agenten zu trainieren und sie zu testen:
Trainingsphase: 2 Richtlinien (1 für jeden Agenten) werden geschult. Diese Richtlinien werden mit dem Wolf -Algorithmus trainiert:
plato run --config MultiAgent_train.yaml
Testphase: Verwendet die in der Schulungsphase geschultes Richtlinien, um Dialoge zwischen zwei Agenten zu erstellen:
plato run --config MultiAgent_test.yaml
Während der Basic -Controller derzeit zwei Agenteninteraktion ermöglicht, ist es ziemlich einfach, ihn auf mehrere Agenten auszudehnen (z. B. mit einer Blackboard -Architektur, bei der jeder Agent seine Ausgabe an andere Agenten sendet). Dies kann Szenarien wie Smart Homes unterstützen, bei denen jedes Gerät ein Agent, Multi-User-Interaktionen mit verschiedenen Rollen und vieles mehr ist.
Platon bietet Implementierungen für zwei Arten von Benutzersimulatoren. Einer ist der sehr bekannte Agenda-basierte Benutzersimulator, der andere ist ein Simulator, der versucht, das in Daten beobachtete Benutzerverhalten nachzuahmen. Wir ermutigen jedoch die Forscher, zwei Konversationsmittel mit Platon (eines "Systems" und eines "Benutzer" einfach zu schulen, anstatt simulierte Benutzer zu verwenden, wenn möglich.
Der Agenda-basierte Benutzersimulator wurde von Schatzmann vorgeschlagen und wird in diesem Artikel ausführlich erläutert. Konzeptionell behält der Simulator eine "Agenda" von Dingen bei, die normalerweise als Stapel implementiert wird. Wenn der Simulator Eingaben erhält, konsultiert er seine Richtlinien (oder seine Regeln), um zu sehen, welche Inhalte als Antwort auf die Eingabe in die Agenda vorgehen sollen. Nach einiger Haushalt (zB Entfernen von Duplikaten oder Inhalten, die nicht mehr gültig sind) steckt der Simulator ein oder mehrere Elemente von der Tagesordnung, mit denen seine Antwort formuliert wird.
Der Agenda-basierte Benutzersimulator verfügt außerdem über ein Fehlersimulationsmodul, mit dem Spracherkennungs- / Sprachverständnisfehler simulieren können. Basierend auf einigen Wahrscheinlichkeiten verzerrt es den Ausgangsdialog des Simulators - die Absicht, den Schlitz oder den Wert (unterschiedliche Wahrscheinlichkeit für jeden). Hier ist ein Beispiel für die vollständige Liste der Parameter, die dieser Simulator empfängt:
patience: 5 # Stop after <patience> consecutive identical inputs received
pop_distribution: [0.8, 0.15, 0.05] # pop 1 act with 0.8 probability, 2 acts with 0.15, etc.
slot_confuse_prob: 0.05 # probability by which the error model will alter the output dact slot
op_confuse_prob: 0.01 # probability by which the error model will alter the output dact operator
value_confuse_prob: 0.01 # probability by which the error model will alter the output dact value
nlu: slot_filling # type of NLU the simulator will use
nlg: slot_filling # type of NLG the simulator will use
Dieser Simulator wurde als einfacher politischen Simulator ausgelegt, der auf der Dialog-Act-Ebene oder auf Äußerungsebene betrieben werden kann. Um zu demonstrieren, wie es funktioniert, hat der DSTC2 -Parser eine Richtliniendatei für diesen Simulator erstellt: user_policy_reactive.pkl (reaktiv, da es auf Systemdialog anstelle des Benutzer -Simulator -Status reagiert). Dies ist eigentlich ein einfaches Wörterbuch von:
System Dial. Act 1 --> {'dacts': {User Dial. Act 1: probability}
{User Dial. Act 2: probability}
...
'responses': {User utterance 1: probability}
{User utterance 2: probability}
...
System Dial. Act 2 --> ...
Der Schlüssel repräsentiert das Eingabedialoggesetz (z. B. vom system Conversational Agent). Der Wert jedes Schlüssels ist ein Wörterbuch von zwei Elementen, das Wahrscheinlichkeitsverteilungen über Dialogakte oder Äußerungsvorlagen darstellt, aus denen der Simulator probiert.
Um ein Beispiel zu sehen, können Sie die folgende Konfiguration ausführen:
plato run --config CamRest_dtl_simulator.yaml
Es gibt zwei Möglichkeiten, je nach Funktion ein neues Modul zu erstellen. Wenn beispielsweise ein Modul eine neue Art der Ausführung von NLU- oder Dialogrichtlinien implementiert, sollten Sie eine Klasse schreiben, die aus der entsprechenden abstrakten Klasse erbt.
Wenn ein Modul jedoch nicht zu einer der einzelnen Agenten -Grundkomponenten passt, wird beispielsweise die genannte Entitätserkennung durchgeführt oder Dialogakte aus dem Text vorausgesagt, dann müssen Sie eine Klasse schreiben, die direkt aus dem conversational_module erbt. Sie können das Modul dann über einen generischen Agenten laden, indem Sie den entsprechenden Paketpfad, Klassennamen und Argumente in der Konfiguration angeben.
...
MODULE_i:
package: my_package.my_module
Class: MyModule
arguments:
model_path: models/my_module/parameters/
...
...
Seien Sie vorsichtig! Sie sind dafür verantwortlich, dass das E/A dieses Moduls vor und nach dem Modulen angemessen verarbeitet und angemessen konsumiert werden kann, wie in Ihrer generischen Konfigurationsdatei enthalten.
Platon unterstützt auch (logisch) parallele Ausführung von Modulen. Um zu aktivieren, dass Sie die folgende Struktur in Ihrer Konfiguration benötigen:
...
MODULE_i:
parallel_modules: 5
PARALLEL_MODULE_0:
package: my_package.my_module
Class: MyModule
arguments:
model_path: models/myModule/parameters/
...
PARALLEL_MODULE_1:
package: my_package.my_module
Class: MyModule
arguments:
model_path: models/my_module/parameters/
...
...
...
Seien Sie vorsichtig! Ausgänge aus den parallel durchgeführten Modulen werden in eine Liste verpackt. Das nächste Modul (z. B. MODULE_i+1 ) muss in der Lage sein, diese Art von Eingabe zu verarbeiten. Die bereitgestellten Platon -Module sind nicht so konzipiert, dass Sie ein benutzerdefiniertes Modul schreiben müssen, um die Eingaben aus mehreren Quellen zu verarbeiten.
Platon ist so konzipiert, dass er erweiterbar ist. Erstellen Sie daher Ihre eigenen Dialogzustände, Aktionen, Belohnungsfunktionen, Algorithmen oder andere Komponenten, die Ihren spezifischen Anforderungen entsprechen. Sie müssen nur aus der entsprechenden Klasse erben, um sicherzustellen, dass Ihre Implementierung mit Platon kompatibel ist.
Platon verwendet PySimpelgui, um grafische Benutzeroberflächen zu verarbeiten. Ein Beispiel -GUI für Platon ist unter plato.controller.sgui_controller und Sie können es mit dem folgenden Befehl ausprobieren:
plato gui --config CamRest_GUI_speech.yaml
Special thanks to Mahdi Namazifar, Chandra Khatri, Yi-Chia Wang, Piero Molino, Michael Pearce, Zack Kaden, and Gokhan Tur for their contributions and support, and to studio FF3300 for allowing us to use the Messapia font.
Please understand that many features are still being implemented and some use cases may not be supported yet.
Genießen!


