plato research dialogue system
1.0.0

Это V0.3.1
Система диалога Plato Research - это гибкая структура, которую можно использовать для создания, обучения и оценки разговорных агентов ИИ в различных средах. Он поддерживает взаимодействия с помощью речевых, текстовых или диалоговых актов, и каждый разговорной агент может взаимодействовать с данными, пользователями человека или другими разговорными агентами (в многоагентных настройках). Каждый компонент каждого агента может быть обучен независимо онлайн или офлайн, а Платон обеспечивает простой способ обертывания практически любой существующей модели, если придерживается интерфейс Платона.
СИТАЦИЯ СИТАЦИИ:
Александрос Папангелис, Махди Намазифар, Чандра Хатри, И-Чиа Ванг, Пьеро Молино и Гохан Тур, «Система диалога Платона: гибкая платформа для исследований в области разговоров», Arxiv Preprint [Paper]
Александрос Папангелис, Йи-Чиа Ван, Пьеро Молино и Гохан Тур, «Совместная многоагентная модель диалога с помощью обучения подкреплению», Sigdial 2019 [Paper]
Платон написал несколько диалогов между персонажами, которые спорят по теме, задавая вопросы. Многие из этих диалогов показывают Сократ, включая испытание Сократа. (Сократ был оправдан в новом судебном процессе, состоявшемся в Афинах, Греция, 25 мая 2012 года).
v0.2 : Основное обновление от V0.1 заключается в том, что Plato RDS теперь предоставляется в качестве пакета. Это облегчает создание и поддержание новых приложений для разговорных ИИ, и все учебники были обновлены, чтобы отразить это. Платон теперь также поставляется с дополнительным графическим интерфейсом. Наслаждаться!
Концептуально, разговорной агент должен пройти различные шаги, чтобы обработать информацию, которую она получает как входная (например, «Какая погода сегодня?») И создать соответствующий результат («ветреный, но не слишком холодный».). Основные шаги, которые соответствуют основным компонентам стандартной архитектуры (см. Рисунок 1), являются:
Платон был спроектирован так, чтобы быть максимально модульным и гибким; Он поддерживает как традиционные, так и пользовательские архитектуры ИИ и, что важно, позволяет многопартийным взаимодействиям, где несколько агентов, потенциально с различными ролями, могут взаимодействовать друг с другом, тренироваться одновременно и решать распределенные задачи.
На рисунках 1 и 2, ниже, изображают пример архитектуры разговорных агентов Платона при взаимодействии с людьми и с моделируемыми пользователями, соответственно. Взаимодействие с моделируемыми пользователями-это обычная практика, используемая в исследовательском сообществе для прыжков в обучении (то есть изучает некоторые основные поведения, прежде чем взаимодействовать с людьми). Каждый отдельный компонент может быть обучен онлайн или в автономном режиме, используя любую библиотеку машинного обучения (например, Ludwig, Tensorflow, Pytorch или ваши собственные реализации), поскольку Платон является универсальной структурой. Ludwig, набор инструментов с открытым исходным кодом Uber, делает хороший выбор, поскольку он не требует написания кода и полностью совместим с Платоном.
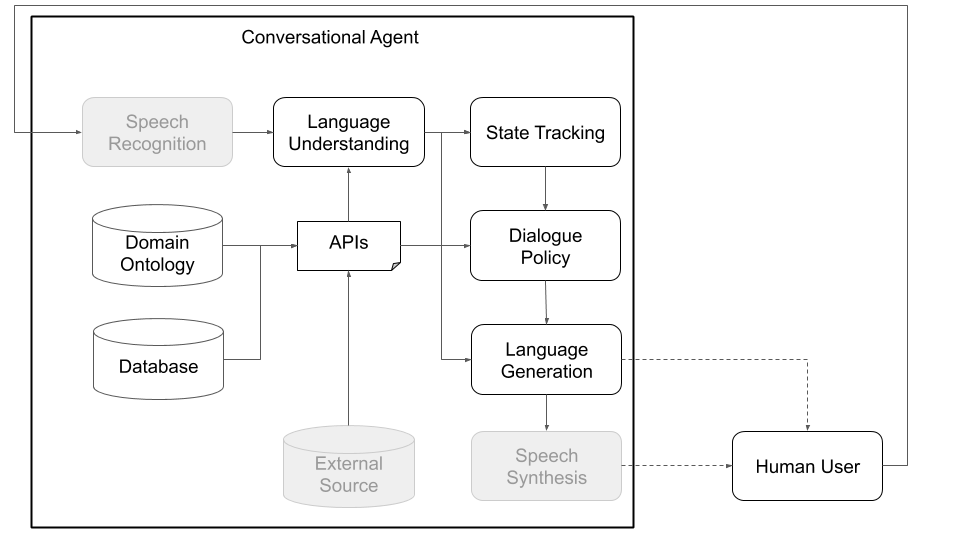 Рисунок 1: Модульная архитектура Платона означает, что любой компонент может быть обучен онлайн или в автономном режиме и может быть заменен на пользовательские или предварительно обученные модели. (Серые компоненты на этой диаграмме не являются основными компонентами Платона.)
Рисунок 1: Модульная архитектура Платона означает, что любой компонент может быть обучен онлайн или в автономном режиме и может быть заменен на пользовательские или предварительно обученные модели. (Серые компоненты на этой диаграмме не являются основными компонентами Платона.)
 Рисунок 2: Используя моделируемого пользователя, а не человеческого пользователя, как на рисунке 1, мы можем предварительно обучать статистические модели для различных компонентов Платона. Затем их можно использовать для создания прототипа разговорного агента, который может взаимодействовать с пользователями человека для сбора более естественных данных, которые впоследствии могут быть использованы для обучения лучших статистических моделей. (Серые компоненты на этой диаграмме не являются компонентами Plato Core, поскольку они либо доступны в качестве из коробки, таких как Google ASR и Amazon Lex, либо домен и приложение, такие как пользовательские базы данных/API.)
Рисунок 2: Используя моделируемого пользователя, а не человеческого пользователя, как на рисунке 1, мы можем предварительно обучать статистические модели для различных компонентов Платона. Затем их можно использовать для создания прототипа разговорного агента, который может взаимодействовать с пользователями человека для сбора более естественных данных, которые впоследствии могут быть использованы для обучения лучших статистических моделей. (Серые компоненты на этой диаграмме не являются компонентами Plato Core, поскольку они либо доступны в качестве из коробки, таких как Google ASR и Amazon Lex, либо домен и приложение, такие как пользовательские базы данных/API.)
В дополнение к взаимодействию с одним агентом, Платон поддерживает многоагентные разговоры, где несколько агентов Платона могут взаимодействовать и учиться друг у друга. В частности, Платон появит разговорные агенты, убедитесь, что входные данные и выходы (то, что слышит каждый агент и говорит) передаются каждому агенту надлежащим образом, и следите за разговором.
Эта настройка может облегчить исследование в области многоагентного обучения, где агенты должны научиться генерировать язык для выполнения задачи, а также исследования в суб-полях многопартийных взаимодействий (отслеживание состояния диалога, принятие поворота и т. Д.). Принципы диалога определяют, что может понять каждый агент (онтология объектов или значений; например: цена, местоположение, предпочтения, типы кухни и т. Д.) И что он может сделать (попросите дополнительную информацию, предоставить некоторую информацию, позвонить в API и т. Д.). Агенты могут общаться по речи, текстовой или структурированной информации (диалог), и каждый агент имеет свою собственную конфигурацию. Рисунок 3, ниже, изображает эту архитектуру, излагая связь между двумя агентами и различными компонентами:
 Рисунок 3: Архитектура Платона позволяет одновременно обучать несколько агентов, каждая из которых имеет потенциально разные роли и цели, и может облегчить исследования в таких областях, как многопартийные взаимодействия и многоагентное обучение. (Серые компоненты на этой диаграмме не являются основными компонентами Платона.)
Рисунок 3: Архитектура Платона позволяет одновременно обучать несколько агентов, каждая из которых имеет потенциально разные роли и цели, и может облегчить исследования в таких областях, как многопартийные взаимодействия и многоагентное обучение. (Серые компоненты на этой диаграмме не являются основными компонентами Платона.)
Наконец, Платон поддерживает пользовательские архитектуры (например, разделение NLU на несколько независимых компонентов) и совместно обученные компоненты (например, состояние текста в диалогу, текст в текст или любая другая комбинация) через общий архитектуру агента, показанную на рисунке 4 ниже. Этот режим уходит от стандартной архитектуры разговорного агента и поддерживает любую архитектуру (например, с компонентами совместных, компонентами текста в текст или речи в речь или любой другой настройке) и позволяет загружать существующие или предварительно обученные модели в Платон.
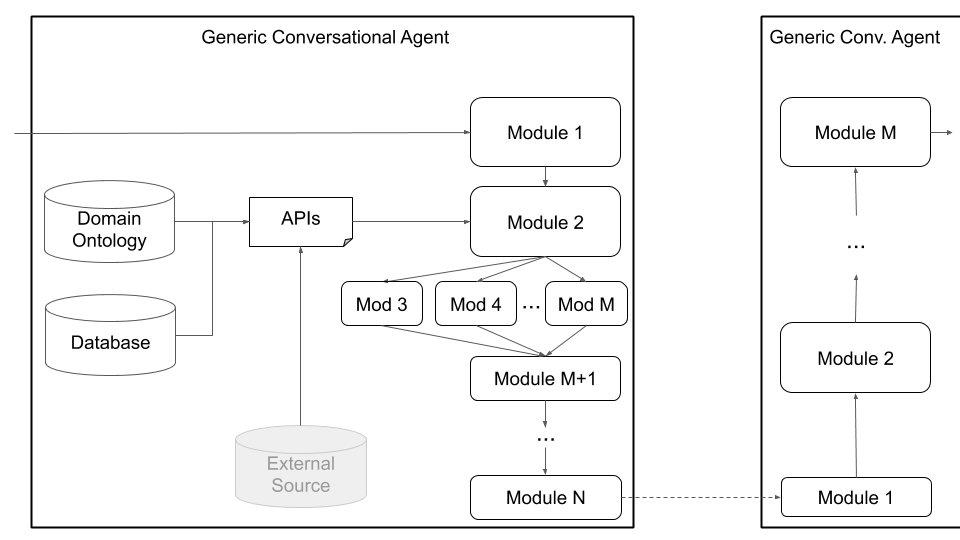 Рисунок 4: Общая архитектура агента Платона поддерживает широкий спектр настройки, включая совместные компоненты, компоненты речи до речи и компоненты текста в текст, которые можно выполнить последовательно или параллельно.
Рисунок 4: Общая архитектура агента Платона поддерживает широкий спектр настройки, включая совместные компоненты, компоненты речи до речи и компоненты текста в текст, которые можно выполнить последовательно или параллельно.
Пользователи могут определить свою собственную архитектуру и/или подключить свои собственные компоненты к Платону, просто предоставив имя класса Python и путь к этому модулю, а также аргументы инициализации модели. Все, что нужно сделать, - это перечислить модули в порядке, который они должны выполнять, и Платон заботится об остальном, включая обертку ввода/вывода, цепляние модулей и обработку диалогов. Платон поддерживает последовательное и параллельное выполнение модулей.
Платон также обеспечивает поддержку байесовской оптимизации разговорных архитектур ИИ или параметров отдельных модулей посредством байесовской оптимизации комбинаторных структур (BOCS).
Сначала убедитесь, что у вас есть Python версия 3.6 или выше на вашем компьютере. Далее вам нужно клонировать репозиторий Платона:
git clone [email protected]:uber-research/plato-research-dialogue-system.git
Далее вам нужно установить некоторые предварительные условия:
Tensorflow:
pip install tensorflow>=1.14.0
Установите библиотеку речевого признания для поддержки аудио:
pip install SpeechRecognition
Для macOS:
brew install portaudio
brew install gmp
pip install pyaudio
Для Ubuntu/Debian:
sudo apt-get install python3-pyaudio
Для Windows: ничего не нужно быть предварительно установленным
Следующим шагом является установка Платона. Чтобы установить Платона, вы должны напрямую установить его из исходного кода.
Установка Платона из исходного кода позволяет устанавливать в редактируемом режиме, что означает, что если вы внесете изменения в исходный код, он будет напрямую повлиять на выполнение.
Перейдите к каталогу Платона (где вы клонировали репозиторий Платона на предыдущем этапе).
Мы рекомендуем создать новую среду Python. Чтобы настроить новую среду Python:
2.1 Установить VirtualEnv
sudo pip install virtualenv
2.2 Создайте новую среду Python:
python3 -m venv </path/to/new/virtual/environment>
2.3 Активируйте новую среду Python:
source </path/to/new/virtual/environment/bin>/bin/activate
Установите Платон:
pip install -e .
Для поддержки речи необходимо установить Pyaudio, который имеет ряд зависимостей, которые могут не существовать на машине разработчика. Если приведенные выше шаги не удастся, этот пост по ошибке установки Pyaudio включает в себя инструкции о том, как получить эти зависимости и установить Pyaudio.
Файл CommonIssues.md содержит общие проблемы и их разрешение, с которым пользователь может столкнуться при установке.
Чтобы запустить Платон после установки, вы можете просто запустить команду plato в терминале. Команда plato получает 4 подкоманда:
runguidomainparse Каждый из этих подкомандов получает значение для аргумента --config , который указывает на файл конфигурации. Мы подробно опишем эти файлы конфигурации позже в документе, но помним, что plato run --config и plato domain --config plato gui --config получает файл конфигурации приложения (примеры можно найти здесь: Пример/ example/config/application/ example/config/domain/ , plato parse --config example/config/parser/ ).
На значение, которое передается в --config Plato, сначала проверяет, является ли значение адресом файла на машине. Если это так, то Платон пытается проанализировать этот файл. Если это не так, Платон проверяет, чтобы увидеть, является ли значение именем файла в example/config/<application, domain, or parser> .
Для некоторых быстрых примеров, попробуйте следующие файлы конфигурации для домена Cambridge Restaurants:
plato run --config CamRest_user_simulator.yaml
plato run --config CamRest_text.yaml
plato run --config CamRest_speech.yaml
Приложение, то есть разговорная система, в Платоне содержит три основные части:
Эти части объявляются в файле конфигурации приложения. Примеры таких файлов конфигурации могут быть найдены в example/config/application/ В остальной части этого раздела мы описываем более подробную информацию о каждой из этих частей.
Для реализации ориентированной на задача системы диалоговой работы в Платоне необходимо указать два компонента, которые составляют домен диалоговой системы:
Платон предоставляет команду для автоматизации этого процесса создания онтологии и базы данных. Допустим, например, что вы хотите построить разговорной агент для цветочного магазина, и example/data/flowershop.csv вас есть следующие элементы в.
id,type,color,price,occasion
1,rose,red,cheap,any
2,rose,white,cheap,anniversary
3,rose,yellow,cheap,celebration
4,lilly,white,moderate,any
5,orchid,pink,expensive,any
6,dahlia,blue,expensive,any
Чтобы автоматически генерировать файл SQL .db и example/config/domain/create_flowershop_domain.yaml .
GENERAL:
csv_file_name: example/data/flowershop.csv
db_table_name: flowershop
db_file_path: example/domains/flowershop-dbase.db
ontology_file_path: example/domains/flowershop-rules.json
ONTOLOGY: # Optional
informable_slots: [type, price, occasion]
requestable_slots: [price, color]
System_requestable_slots: [type, price, occasion]
и запустите команду:
plato domain --config create_flowershop_domain.yaml
Если все прошло хорошо, у вас должен быть flowershop.json и flowershop.db в example/domains/ каталоге.
Если вы получите эту ошибку:
sqlite3.IntegrityError: UNIQUE constraint failed: flowershop.id
Это означает, что файл .db уже был создан.
Теперь вы можете просто запустить фиктивные компоненты Платона в качестве проверки здравомыслия и поговорить со своим агентом цветов:
plato run --config flowershop_text.yaml
Контроллеры - это объекты, которые организуют разговор между агентами. Контроллер создаст экземпляры агентов, инициализирует их для каждого диалога, надлежащим образом передает ввод и вывод и отслеживает статистику.
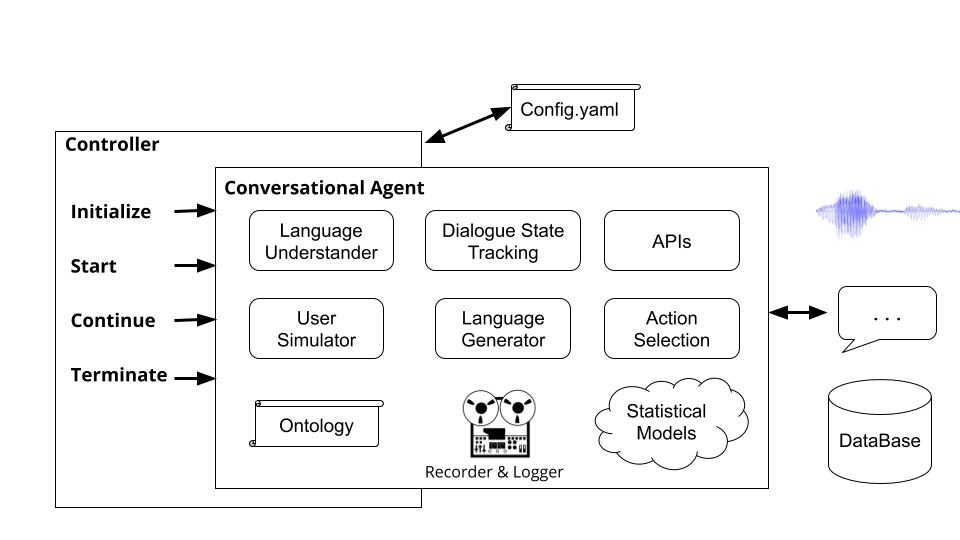
Запуск команды plato run запускает базовый контроллер Платона ( plato/controller/basic_controller.py ). Эта команда получает значение для аргумента --config , который указывает на файл конфигурации приложения Платона.
Чтобы запустить агент по разговору Платона, пользователь должен запустить следующую команду с соответствующим файлом конфигурации:
plato run --config <FULL PATH TO CONFIG YAML FILE>
Пожалуйста, обратитесь к example/config/application/ например, файлы конфигурации, которые содержат настройки в среде и создании агента, а также их компоненты. Примеры в example/config/application/ можно запустить напрямую, используя только имя примера файла YAML:
plato run --config <NAME OF A FILE FROM example/config/application/>
В качестве альтернативы пользователь может написать свой собственный файл конфигурации и запустить Plato, пройдя полный путь к своему файлу конфигурации в --config :
plato run --config <FULL PATH TO CONFIG YAML FILE>
На значение, которое передается в --config Plato, сначала проверяет, является ли значение адресом файла на машине. Если это так, Платон пытается проанализировать этот файл. Если это не так, Платон проверяет, чтобы увидеть, является ли значение именем файла в каталоге example/config/application .
Каждое разговорное приложение ИИ в Платоне может иметь одного или нескольких агентов. Каждый агент играет роль (система, пользователь, ...) и набор стандартных компонентов диалога (рис. 1), а именно NLU, менеджер диалога, трекер состояния диалога, политика, NLG и пользовательский симулятор.
Агент может иметь один явный модуль для каждого из этих компонентов. Альтернативно, некоторые из этих компонентов могут быть объединены в один или несколько модулей (например, соединения / сквозные агенты), которые могут работать последовательно или параллельно (рис. 4). Компоненты Платона определены в plato.agent.component и все наследуют от plato.agent.component.conversational_module
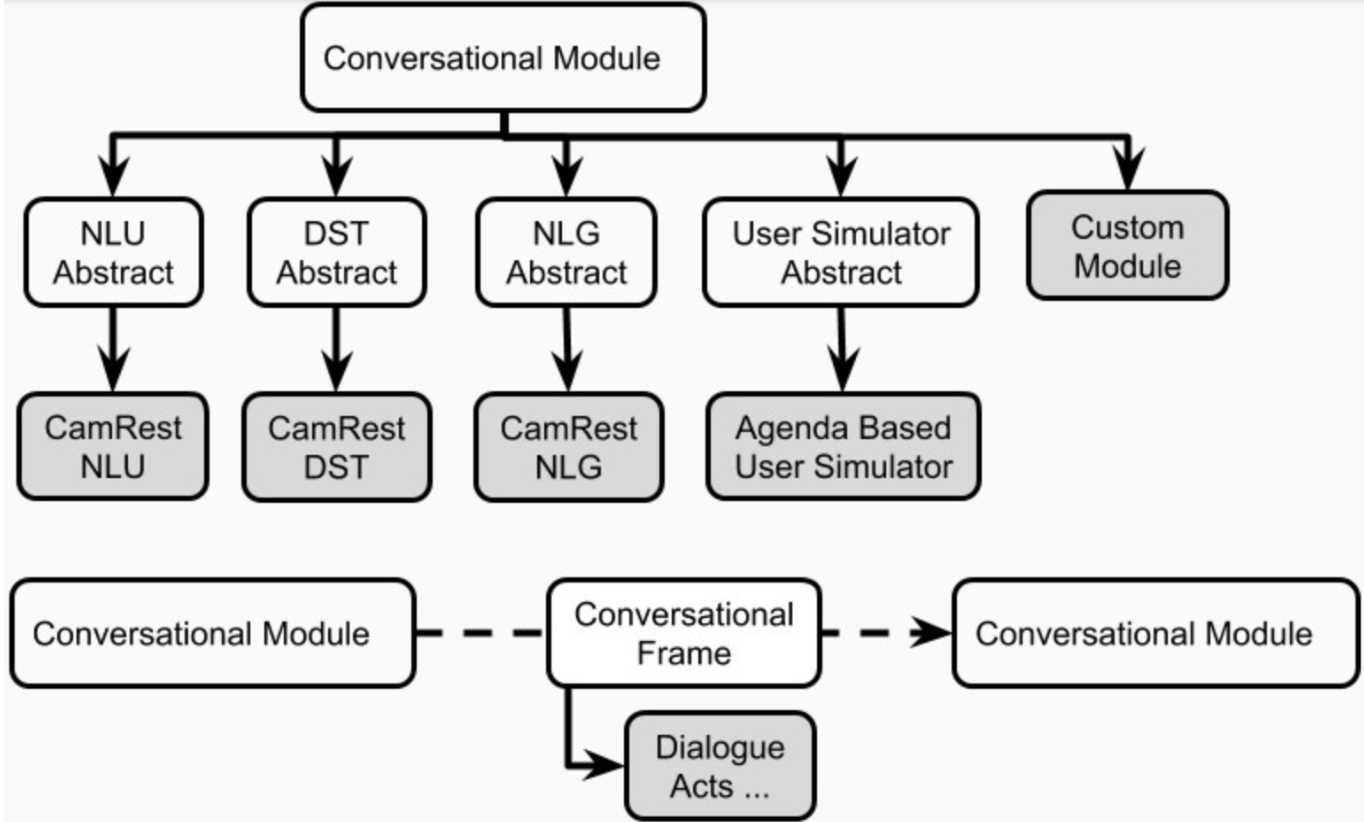 Рисунок 5. Компоненты агентов Платона
Рисунок 5. Компоненты агентов Платона
Обратите внимание, что любые новые реализации или пользовательские модули должны наследовать от plato.agent.component.conversational_module .
Каждый из этих модулей может быть либо на основе правил, либо обученных. В следующих подразделах мы опишем, как создавать на основе правил и обученные модули для агентов.
Платон предоставляет версии на основе правил всех компонентов разговорного агента, заполняющего слот (SLOT_FILLIG_NLU, SLOT_FILLY_DST, SLOT_FILLICE_POLICY, SLOT_FILLY_NLG и версия по умолчанию AUGENDA_BADE_US). Они могут быть использованы для быстрого прототипирования, базовых показателей или проверки здравомыслия. В частности, все эти компоненты следуют правилам или шаблонам, обусловленным данной онтологией, а иногда и в данной базе данных, и должны рассматриваться как самая основная версия того, что должен делать каждый компонент.
Платон поддерживает обучение модулей компонентов агентов в онлайн (во время взаимодействия) или в автономном режиме (из данных), используя любую структуру глубокого обучения. Практически любая модель может быть загружена в Платон, если соблюдается вход/вывод интерфейса Платона. Например, если модель - это пользовательский модуль NLU, она просто необходимо наследовать от абстрактного класса NLU Plato ( plato.agent.component.nlu ) и реализовать необходимые абстрактные методы.
Чтобы облегчить онлайн -обучение, отладку и оценку, Платон отслеживает свой внутренний опыт в структуре под названием «Рекордер эпизода диалога» ( plato.utilities.dialogue_episode_recorder категории.
В конце диалога или через указанные интервалы каждый разговорной агент будет вызывать функцию Train () каждого из его внутренних компонентов, передавая опыт диалога в качестве учебных данных. Каждый компонент затем выбирает необходимые для обучения детали.
Чтобы использовать алгоритмы обучения, которые реализованы внутри Платона, любые внешние данные, такие как данные DSTC2, должны быть проанализированы в этот опыт Платона, чтобы они могли загружаться и использовать соответствующим компонентом под тренировкой.
В качестве альтернативы пользователи могут анализировать данные и обучать свои модели за пределами Платона и просто загружать обученную модель, когда они хотят использовать их для агента Платона.
Обучение онлайн так же просто, как и флаги «поезда» в «Истину» в конфигурации для каждого компонента, которые пользователи хотят тренироваться.
Чтобы тренироваться из данных, пользователям просто нужно загрузить опыт, который они проанализировали из своего набора данных. Платон предоставляет примеры анализаторов для наборов данных DSTC2 и Metalwoz. В качестве примера того, как использовать эти анализаторы для автономного обучения в Платоне, мы будем использовать набор данных DSTC2, который можно получить на веб -сайте 2 -го состояния диалога.
http://camdial.org/~mh521/dstc/downloads/dstc2_traindev.tar.gz
После завершения загрузки вам необходимо расслабиться на разарнике файла. Файл конфигурации для анализа этого набора данных предоставляется в example/config/parser/Parse_DSTC2.yaml . Вы можете проанализировать данные, которые вы загрузили, сначала редактируя значение data_path в example/config/parser/Parse_DSTC2.yaml чтобы указать на путь, куда вы загрузили, и раскрыли данные DSTC2. Далее вы можете запустить сценарий Parse следующим образом:
plato parse --config Parse_DSTC2.yaml
В качестве альтернативы вы можете написать свой собственный файл конфигурации и передать абсолютный адрес этому файлу в команду:
plato parse --config <absolute pass to parse config file>
Запуск этой команды запустит сценарий анализа для DSTC2 (который живет в рамках plato/utilities/parser/parse_dstc2.py ) и создаст учебные данные для диалогового состояния, NLU и NLG как для пользователя, так и для системы в каталоге data в корневом каталоге этого репозитория. Теперь эти проанализированные данные могут быть использованы для обучения моделей для различных компонентов Платона.
Существует несколько способов обучения каждого компонента агента Платона: онлайн (как агент взаимодействует с другими агентами, симуляторами или пользователями) или офлайн. Кроме того, вы можете использовать алгоритмы, реализованные в Платоне, или вы можете использовать внешние рамки, такие как Tensorflow, Pytorch, Keras, Ludwig и т. Д.
Ludwig - это структура глубокого обучения с открытым исходным кодом, которая позволяет вам обучать модели без написания кода. Вам нужно только анализировать ваши данные в файлы .csv , создать конфигурацию Ludwig (в YAML), которая описывает нужную архитектуру, какие функции для использования из .csv и других параметров, а затем просто запустите команду в терминале.
Людвиг также предоставляет API, с которым Платон совместим. Это позволяет Платону интегрироваться с моделями Ludwig, т.е. нагрузка или сохранять модели, тренировать и запрашивать их.
В предыдущем разделе анализатор DSTC2 Платона сгенерировал некоторые файлы .csv , которые можно использовать для обучения NLU и NLG. Существует один файл nlu .csv для системы ( data/DSTC2_NLU_sys.csv ) и один для пользователя ( data/DSTC2_NLU_usr.csv ). Они выглядят так:
| транскрипт | намерение | IOB |
|---|---|---|
| дорогой ресторан, который подает вегетарианскую еду | информировать | B-Inform-Pricerange Ooo B-Inform-Food O |
| вегетарианская еда | информировать | B-Inform-Food o |
| Азиатский восточный тип пищи | информировать | B-Inform-Food I-Inform-Food OOO |
| Дорогая ресторан азиатская еда | информировать | B-Inform-Pricerange OOO |
Для обучения модели NLU вам нужно написать файл конфигурации, который выглядит так:
input_features:
-
name: transcript
type: sequence
reduce_output: null
encoder: parallel_cnn
output_features:
-
name: intent
type: set
reduce_output: null
-
name: iob
type: sequence
decoder: tagger
dependencies: [intent]
reduce_output: null
training:
epochs: 100
early_stop: 50
learning_rate: 0.0025
dropout: 0.5
batch_size: 128
Пример этого файла конфигурации существует в example/config/ludwig/ludwig_nlu_train.yaml . Учебная работа может быть начата с работы:
ludwig experiment
--model_definition_file example/config/ludwig/ludwig_nlu_train.yaml
--data_csv data/DSTC2_NLU_sys.csv
--output_directory models/camrest_nlu/sys/
Следующим шагом является загрузка модели в конфигурации приложения. В example/config/application/CamRest_model_nlu.yaml мы предоставляем конфигурацию приложения, которая имеет модель NLU, а другие компоненты не основаны на M-ML. Обновляя путь к режиму ( model_path ) до значения, которое вы предоставили аргументу --output_directory , когда вы запускаете Ludwig, вы можете указать модель NLU, которую агент должен использовать для NLU:
...
MODULE_0:
package: applications.cambridge_restaurants.camrest_nlu
class: CamRestNLU
arguments:
model_path: <PATH_TO_YOUR_MODEL>/model
...
и проверить, что модель работает:
plato run --config CamRest_model_nlu.yaml
Сиарсер данных DSTC2 сгенерировал два файла .csv , которые мы можем использовать для DST: DST_sys.csv и DST_usr.csv , которые выглядят так:
| dst_prev_food | dst_prev_area | DST_PREV_PRICERANGE | nlu_intent | req_slot | inf_area_value | inf_food_value | inf_pricerange_value | dst_food | dst_area | DST_PRICERANGE | DST_REQ_SLOT |
|---|---|---|---|---|---|---|---|---|---|---|---|
| никто | никто | никто | информировать | никто | никто | вегетарианский | дорогой | вегетарианский | никто | дорогой | никто |
| вегетарианский | никто | дорогой | информировать | никто | никто | вегетарианский | никто | вегетарианский | никто | дорогой | никто |
| вегетарианский | никто | дорогой | информировать | никто | никто | Азиатский восток | никто | Азиатский восток | никто | дорогой | никто |
| Азиатский восток | никто | дорогой | информировать | никто | никто | Азиатский восток | дорогой | Азиатский восток | никто | дорогой | никто |
По сути, анализатор отслеживает предыдущее состояние диалога, вход NLU и результирующее состояние диалога. Затем мы можем подарить это в Людвиг, чтобы обучить государственный трекер диалога. Вот конфигурация Ludwig, которую также можно найти в example/config/ludwig/ludwig_dst_train.yaml :
input_features:
-
name: dst_prev_food
type: category
-
name: dst_prev_area
type: category
-
name: dst_prev_pricerange
type: category
-
name: dst_intent
type: category
-
name: dst_slot
type: category
-
name: dst_value
type: category
output_features:
-
name: dst_food
type: category
-
name: dst_area
type: category
-
name: dst_pricerange
type: category
-
name: dst_req_slot
type: category
training:
epochs: 100
Теперь нам нужно обучить нашу модель с Людвигом:
ludwig experiment
--model_definition_file example/config/ludwig/ludwig_dst_train.yaml
--data_csv data/DST_sys.csv
--output_directory models/camrest_dst/sys/
и запустите агент Платона с моделью DST:
plato run --config CamRest_model_dst.yaml
Конечно, вы можете экспериментировать с другими архитектурами и параметрами обучения.
До сих пор мы видели, как обучать компоненты агентов Платона, используя внешние рамки (то есть Людвиг). В этом разделе мы увидим, как использовать внутренние алгоритмы Платона для обучения политики диалога, используя контролируемое обучение и онлайн, используя обучение подкреплению.
logs/DSTC2_system logs/DSTC2_user .csv Эти журналы содержат информацию о каждом диалоге, например, текущем состоянии диалога, принятом действии, следующем состоянии диалога, наблюдаемом вознаграждении, входном высказывании, успехе и т. Д. Эти журналы могут быть непосредственно загружены в разговорной агент и могут использоваться для заполнения пула опыта.
Все, что вам нужно сделать, это написать файл конфигурации, который загружает эти журналы ( example/config/CamRest_model_supervised_policy_train.yaml ):
GENERAL:
...
experience_logs:
save: False
load: True
path: logs/DSTC2_system
...
DIALOGUE:
# Since this configuration file trains a supervised policy from data loaded
# from the logs, we only really need one dialogue just to trigger the train.
num_dialogues: 1
initiative: system
domain: CamRest
AGENT_0:
role: system
max_turns: 15
train_interval: 1
train_epochs: 100
save_interval: 1
...
DM:
package: plato.agent.component.dialogue_manager.dialogue_manager_generic
class: DialogueManagerGeneric
arguments:
DST:
package: plato.agent.component.dialogue_state_tracker.slot_filling_dst
class: SlotFillingDST
policy:
package: plato.agent.component.dialogue_policy.deep_learning.supervised_policy
class: SupervisedPolicy
arguments:
train: True
learning_rate: 0.9
exploration_rate: 0.995
discount_factor: 0.95
learning_decay_rate: 0.95
exploration_decay_rate: 0.995
policy_path: models/camrest_policy/sys/sys_supervised_data
...
Обратите внимание, что мы запускаем этот агент только для одного диалога, но тренируемся на 100 эпох, используя опыт, который загружается из журналов:
plato run --config CamRest_model_supervised_policy_train.yaml
После завершения обучения мы можем проверить нашу контролируемую политику:
plato run --config CamRest_model_supervised_policy_test.yaml
В предыдущем разделе мы увидели, как обучить контролируемую политику диалога. Теперь мы можем увидеть, как мы можем обучить политику подкрепления обучения, используя алгоритм подкрепления. Для этого мы определяем соответствующий класс в файле конфигурации:
...
AGENT_0:
role: system
max_turns: 15
train_interval: 500
train_epochs: 3
train_minibatch: 200
save_interval: 5000
...
DM:
package: plato.agent.component.dialogue_manager.dialogue_manager_generic
class: DialogueManagerGeneric
arguments:
DST:
package: plato.agent.component.dialogue_state_tracker.slot_filling_dst
class: SlotFillingDST
policy:
package: plato.agent.component.dialogue_policy.deep_learning.reinforce_policy
class: ReinforcePolicy
arguments:
train: True
learning_rate: 0.9
exploration_rate: 0.995
discount_factor: 0.95
learning_decay_rate: 0.95
exploration_decay_rate: 0.995
policy_path: models/camrest_policy/sys/sys_reinforce
...
Обратите внимание на параметры обучения в AGENT_0 и алгоритмические параметры в соответствии с аргументами политики. Затем мы называем Платона с этой конфигурацией:
plato run --config CamRest_model_reinforce_policy_train.yaml
и проверить обученную модель политики:
plato run --config CamRest_model_reinforce_policy_test.yaml
Обратите внимание , что другие компоненты также могут быть обучены онлайн, либо с использованием API Людвига, либо путем реализации алгоритмов обучения в Платоне.
Также обратите внимание , что файлы журнала могут быть загружены и использованы в качестве пула опыта для любого компонента и алгоритма обучения. Тем не менее, вам может потребоваться внедрить свои собственные алгоритмы обучения для некоторых компонентов Платона.
Для обучения модуля NLG вам нужно написать файл конфигурации, который выглядит так (например example/config/application/CamRest_model_nlg.yaml ):
---
input_features:
-
name: nlg_input
type: sequence
encoder: rnn
cell_type: lstm
output_features:
-
name: nlg_output
type: sequence
decoder: generator
cell_type: lstm
training:
epochs: 20
learning_rate: 0.001
dropout: 0.2
и тренировать свою модель:
ludwig experiment
--model_definition_file example/config/ludwig/ludwig_nlg_train.yaml
--data_csv data/DSTC2_NLG_sys.csv
--output_directory models/camrest_nlg/sys/
Следующим шагом является загрузка модели в Платоне. Перейдите в файл конфигурации CamRest_model_nlg.yaml и при необходимости обновите путь:
...
NLG:
package: applications.cambridge_restaurants.camrest_nlg
class: CamRestNLG
arguments:
model_path: models/camrest_nlg/sys/experiment_run/model
...
и проверить, что модель работает:
plato run --config CamRest_model_nlg.yaml
Помните, что Ludwig будет создавать новый каталог Experiment_run_i каждый раз, когда он будет вызван, поэтому, пожалуйста, убедитесь, что вы сохраняете правильный путь в конфигурации Платона.
Обратите внимание, что Ludwig также предлагает метод обучения вашей модели онлайн, поэтому на практике вам нужно написать очень мало кода для создания, обучения и оценки нового компонента глубокого обучения в Платоне.
Для этого примера мы будем использовать набор данных Metalwoz, который вы можете скачать отсюда.
Платон поддерживает совместно обученные модели через общие агенты. Здесь мы увидим шаги, необходимые для создания простого разговорного агента SEQ2SEQ с нуля. Используя Metalwoz в качестве примера, нам нужно сделать следующее:
Поскольку мы обучаем только простую модель SEQ2SEQ (текст на текст), нам нужен наш анализатор, чтобы извлечь пользовательские и системные высказывания. Они будут сохранены в файлах .csv, которые будут использоваться Людвигом на шаге 4.
Для простой реализации анализатора Metalwoz см. utilities/parser/Parse_MetalWOZ.py
Обратите внимание, что этот анализатор будет анализировать только один файл (один домен). Однако вы можете легко изменить его, чтобы соответствовать вашим потребностям. Вот образец вывода, произведенного анализатором для домена заказа пиццы:
| пользователь | система |
|---|---|
| привет | Привет, как я могу вам помочь? |
| Мне нужно разместить заказ на пиццу, нужна помощь | Конечно, что бы вы хотели добавить в свой заказ? |
| Я хочу пиццу с грибами, пепперони и начинками бекона | К сожалению, это место вышло из запрашиваемого вами бекона. Будет ли другой топпинг, который вы хотели бы заменить его? |
| Как насчет ананаса | Эта топпинг доступен. Я добавил пиццу с грибами, пепперони и ананасом в ваш заказ. Какой размер вы бы хотели? |
| Середина | Хорошо, обновлено. Хотели бы вы добавить больше в свой заказ? |
| Спасибо, достаточно | Хорошо, ваша общая сумма 14,99. Ваша пицца будет готова к получению в ок. 20 минут. |
Обратите внимание, что высказывание первого пользователя на самом деле не существует в данных. Тем не менее, нам нужно что -то, чтобы побудить модель для создания приветствия системы - мы могли бы использовать пустое предложение или любое другое приветствие (или их комбинацию).
Затем вы можете запустить Plato Parse следующим образом:
plato parse --config Parse_MetalWOZ.yaml
Чтобы начать, мы можем обучить очень простую модель, используя Ludwig (не стесняйтесь использовать свою любимую структуру глубокого обучения здесь):
input_features:
-
name: user
type: text
level: word
encoder: rnn
cell_type: lstm
reduce_output: null
output_features:
-
name: system
type: text
level: word
decoder: generator
cell_type: lstm
attention: bahdanau
training:
epochs: 100
Вы можете изменить эту конфигурацию, чтобы отразить архитектуру по вашему выбору и поезда, используя Ludwig:
ludwig train
--data_csv data/metalwoz.csv
--model_definition_file example/config/ludwig/metalWOZ_seq2seq_ludwig.yaml
--output_directory "models/joint_models/"
Этот класс просто должен обрабатывать загрузку модели, соответствующим образом запросить ее и правильно форматировать его вывод. В нашем случае нам нужно обернуть входной текст в DataFrame Pandas, взять прогнозируемые токены с вывода и присоединиться к ним в строке, которая будет возвращена. Смотрите класс здесь: plato.agent.component.joint_model.metal_woz_seq2seq.py
См example/config/application/metalwoz_generic.yaml для примера общего файла конфигурации, который взаимодействует с агентом SEQ2Seq через текст. Вы можете попробовать это следующим образом:
plato run --config metalwoz_text.yaml
Не забудьте обновить путь к вашей обученной модели, если это необходимо! Путь по умолчанию предполагает, что вы запускаете команду поезда Ludwig от корневого каталога Платона.
Одна из основных функций Платона позволяет двум агентам взаимодействовать друг с другом. Каждый агент может играть другую роль (например, систему и пользователь), разные цели и получать различные сигналы вознаграждения. Если агенты сотрудничают, некоторые из них могут быть разделены (например, что представляет собой успешный диалог).
Чтобы запустить несколько агентов Платона в домене ресторанов Cambridge, мы выполняем следующие команды, чтобы обучить политику диалога агентов и проверить их:
Фаза обучения: 2 политики (1 для каждого агента) обучаются. Эти политики обучаются с использованием алгоритма Волка:
plato run --config MultiAgent_train.yaml
Этап тестирования: использует политику, обученную на этапе обучения для создания диалогов между двумя агентами:
plato run --config MultiAgent_test.yaml
В то время как базовый контроллер в настоящее время допускает два агента взаимодействие, довольно просто расширить его до нескольких агентов (например, с архитектурой доски, где каждый агент транслирует свои выводы другим агентам). Это может поддерживать сценарии, такие как Smart Homes, где каждое устройство является агентом, многопользовательские взаимодействия с различными ролями и многое другое.
Платон предоставляет реализации для двух видов пользовательских симуляторов. Одним из них является очень известный симулятор пользователей на основе программы, а другой-симулятор, который пытается имитировать поведение пользователей, наблюдаемое в данных. Тем не менее, мы призываем исследователей просто обучать двух разговорных агентов с Платоном (один из которых является «системой», а одним является «пользователем») вместо того, чтобы использовать моделируемых пользователей, когда это возможно.
Пользовательский симулятор, основанный на повестке дня, был предложен Шацманном и подробно объясняется в этой статье. Концептуально, симулятор поддерживает «повестку дня» вещей, которые обычно реализуются как стек. Когда симулятор получает вход, он консультируется с его политикой (или своей набором правил), чтобы увидеть, какой контент вставать в повестку дня, как ответ на вход. После некоторого домашнего хозяйства (например, удаление дубликатов или контента, которое больше не является действительным), симулятор выберет один или несколько элементов из повестки дня, которые будут использоваться для сформулирования его ответа.
Пользовательский симулятор, основанный на повестке дня, также имеет модуль моделирования ошибок, который может имитировать ошибки распознавания речи / понимание языка. Основываясь на некоторых вероятностях, он исказит выходные диалоги -акты симулятора - намерение, слот или значение (различная вероятность для каждого). Вот пример полного списка параметров, которые получает этот симулятор:
patience: 5 # Stop after <patience> consecutive identical inputs received
pop_distribution: [0.8, 0.15, 0.05] # pop 1 act with 0.8 probability, 2 acts with 0.15, etc.
slot_confuse_prob: 0.05 # probability by which the error model will alter the output dact slot
op_confuse_prob: 0.01 # probability by which the error model will alter the output dact operator
value_confuse_prob: 0.01 # probability by which the error model will alter the output dact value
nlu: slot_filling # type of NLU the simulator will use
nlg: slot_filling # type of NLG the simulator will use
Этот симулятор был разработан, чтобы быть простым политическим симулятором, который может работать на уровне закона о диалоге или на уровне высказывания. Чтобы продемонстрировать, как это работает, анализатор DSTC2 создал файл политики для этого симулятора: user_policy_reactive.pkl (реактивный, потому что он реагирует на системные диалоги, вместо состояния имитатора пользователя). Это на самом деле простой словарь:
System Dial. Act 1 --> {'dacts': {User Dial. Act 1: probability}
{User Dial. Act 2: probability}
...
'responses': {User utterance 1: probability}
{User utterance 2: probability}
...
System Dial. Act 2 --> ...
Ключ представляет Закон о входных диалогах (например, от system разговорного агента). Значение каждого ключа представляет собой словарь двух элементов, представляющих распределения вероятностей по поводу диалога или шаблонов высказывания, из которых будет выбирать симулятор.
Чтобы увидеть пример, вы можете запустить следующую конфигурацию:
plato run --config CamRest_dtl_simulator.yaml
Есть два способа создания нового модуля в зависимости от его функции. Если модуль, например, реализует новый способ выполнения NLU или политики диалога, то вам следует написать класс, который наследует от соответствующего абстрактного класса.
Однако, если модуль не соответствует одному из основных компонентов единого агента, например, он выполняет именованное распознавание сущности или предсказывает диалог из текста, то вы должны написать класс, который наследует от conversational_module напрямую. Затем вы можете загрузить модуль через универсальный агент, предоставив соответствующий путь пакета, имя класса и аргументы в конфигурации.
...
MODULE_i:
package: my_package.my_module
Class: MyModule
arguments:
model_path: models/my_module/parameters/
...
...
Будь осторожен! Вы несете ответственность за гарантирование того, что ввод -вывод этого модуля может быть обработан и потребляется надлежащим образом модулями до и после, как указано в вашем общем файле конфигурации.
Платон также поддерживает (логически) параллельное выполнение модулей. Чтобы позволить вам иметь следующую структуру в вашей конфигурации:
...
MODULE_i:
parallel_modules: 5
PARALLEL_MODULE_0:
package: my_package.my_module
Class: MyModule
arguments:
model_path: models/myModule/parameters/
...
PARALLEL_MODULE_1:
package: my_package.my_module
Class: MyModule
arguments:
model_path: models/my_module/parameters/
...
...
...
Будь осторожен! Выходы из модулей, выполненных параллельными, будут упакованы в список. Следующий модуль (например, MODULE_i+1 ) должен иметь возможность обрабатывать этот вид ввода. Предоставленные модули Платона не предназначены для обработки этого, вам нужно будет написать пользовательский модуль для обработки ввода из нескольких источников.
Платон предназначен для расширения, поэтому не стесняйтесь создавать свои собственные состояния диалога, действия, функции вознаграждения, алгоритмы или любой другой компонент в соответствии с вашими конкретными потребностями. Вам нужно только унаследовать от соответствующего класса, чтобы убедиться, что ваша реализация совместима с Платоном.
Платон использует Pysimplegui для обработки графических пользовательских интерфейсов. Пример графического интерфейса для Платона реализован по адресу plato.controller.sgui_controller , и вы можете попробовать его, используя следующую команду:
plato gui --config CamRest_GUI_speech.yaml
Special thanks to Mahdi Namazifar, Chandra Khatri, Yi-Chia Wang, Piero Molino, Michael Pearce, Zack Kaden, and Gokhan Tur for their contributions and support, and to studio FF3300 for allowing us to use the Messapia font.
Please understand that many features are still being implemented and some use cases may not be supported yet.
Наслаждаться!


