plato research dialogue system
1.0.0

这是v0.3.1
柏拉图研究对话系统是一个灵活的框架,可用于在各种环境中创建,训练和评估对话性AI代理。它通过语音,文本或对话行为来支持互动,每个对话代理都可以与数据,人类用户或其他对话代理(在多代理设置中)进行交互。只要粘贴柏拉图的界面,每个代理商的每个组件都可以在线或离线独立培训或离线训练,而Plato几乎可以围绕任何现有模型来包裹任何现有模型。
出版引用:
Alexandros Papangelis,Mahdi Namazifar,Chandra Khatri,Yi-Chia Wang,Piero Molino和Gokhan Tur,“柏拉图对话系统:灵活的对话AI研究平台”,Arxiv Preprint [Paper [Paper] [Paper]
Alexandros Papangelis,Yi-Chia Wang,Piero Molino和Gokhan Tur,“通过强化学习的协作多代理对话模型培训”,Sigdial 2019 [Paper]
柏拉图通过提出问题来争论主题的角色之间写了几次对话。这些对话中的许多以苏格拉底的审判为特色。 (苏格拉底在2012年5月25日在希腊雅典举行的新试验中无罪释放)。
V0.2 :V0.1的主要更新是现在以包裹提供柏拉图RDS。这使得创建和维护新的对话AI应用程序变得更加容易,并且所有教程都已更新以反映这一点。柏拉图现在还带有可选的GUI。享受!
从概念上讲,对话代理需要进行各种步骤,以处理它作为输入收到的信息(例如,“今天的天气是什么?”)并产生适当的输出(“风吹过,但不太冷。”)。与标准体系结构的主要组成部分相对应的主要步骤(见图1)是:
柏拉图被设计为尽可能模块化和灵活。它支持传统和自定义的对话AI体系结构,重要的是,可以实现多方交互,其中有可能具有不同角色的多个代理可以相互互动,同时训练并解决分布式问题。
下面的图1和2描绘了与人类用户和模拟用户进行交互时的示例柏拉图对话代理体系结构。与模拟用户进行互动是研究社区中使用的一种常见实践,可以跳到启动学习(即,在与人类互动之前学习一些基本行为)。可以使用任何机器学习库(例如Ludwig,Tensorflow,Pytorch或您自己的实现)在线培训每个单独的组件,因为Plato是一个通用的框架。 Uber的开源深度学习工具箱路德维希(Ludwig)是一个不错的选择,因为它不需要编写代码,并且与柏拉图完全兼容。
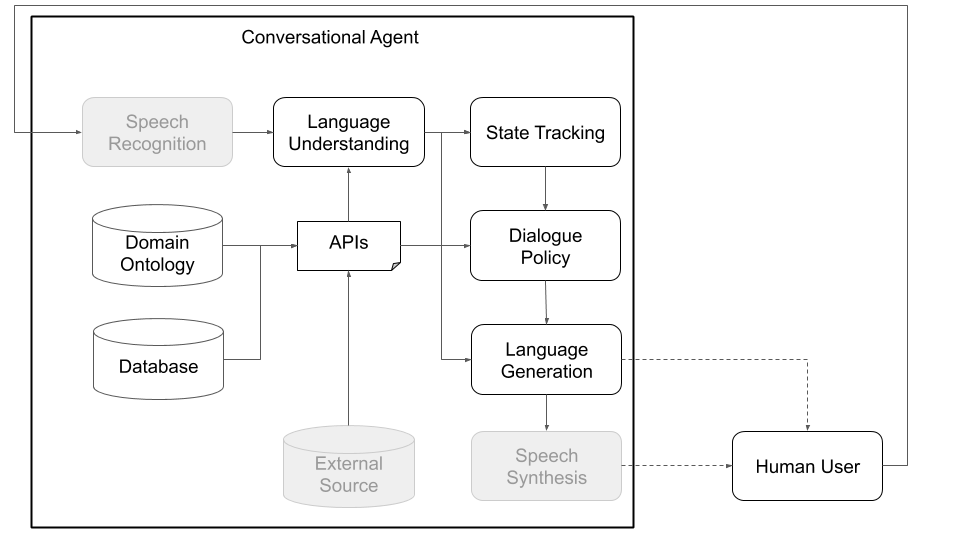 图1:柏拉图的模块化体系结构意味着任何组件都可以在线或离线训练,并且可以用自定义或预训练的型号代替。 (此图中的灰色组件不是核心柏拉图组件。)
图1:柏拉图的模块化体系结构意味着任何组件都可以在线或离线训练,并且可以用自定义或预训练的型号代替。 (此图中的灰色组件不是核心柏拉图组件。)
 图2:使用模拟用户而不是人类用户,如图1所示,我们可以为柏拉图的各种组件预先培训统计模型。然后,这些可以用于创建一个原型对话代理,该原型对话代理可以与人类用户进行交互,以收集可以随后用于训练更好统计模型的自然数据。 (此图中的灰色组件不是柏拉图核心组件,因为它们可以作为Google ASR和Amazon Lex等开箱即用,或者特定于域和应用程序(例如自定义数据库/API)。
图2:使用模拟用户而不是人类用户,如图1所示,我们可以为柏拉图的各种组件预先培训统计模型。然后,这些可以用于创建一个原型对话代理,该原型对话代理可以与人类用户进行交互,以收集可以随后用于训练更好统计模型的自然数据。 (此图中的灰色组件不是柏拉图核心组件,因为它们可以作为Google ASR和Amazon Lex等开箱即用,或者特定于域和应用程序(例如自定义数据库/API)。
除了单格交互之外,柏拉图还支持多个柏拉图代理可以与彼此互动和学习的多代理对话。具体来说,柏拉图将产生对话代理,确保适当地传递给每个代理商的输入和输出(每个代理商听到并说的话),并跟踪对话。
这种设置可以促进多学院学习的研究,在该学习中,代理需要学习如何生成语言以执行任务,以及在多方互动的子场(对话状态跟踪,转弯等)中进行研究。对话原则定义了每个代理可以理解的内容(实体或含义的本体论;例如:价格,位置,偏好,美食类型等)及其可以做什么(要求提供更多信息,提供一些信息,调用API等)。代理可以通过语音,文本或结构化信息(对话行为)进行交流,并且每个代理都有其自己的配置。下面的图3描绘了这种体系结构,概述了两个代理与各种组成部分之间的通信:
 图3:柏拉图的体系结构允许对多种代理的同时培训,每个代理具有潜在的角色和目标,并且可以促进多方相互作用和多机构学习等领域的研究。 (此图中的灰色组件不是核心柏拉图组件。)
图3:柏拉图的体系结构允许对多种代理的同时培训,每个代理具有潜在的角色和目标,并且可以促进多方相互作用和多机构学习等领域的研究。 (此图中的灰色组件不是核心柏拉图组件。)
最后,柏拉图支持自定义体系结构(例如将NLU分为多个独立组件)和通过图4所示的通用代理体系结构,如下所示。此模式从标准的对话代理体系结构移开,并支持任何类型的体系结构(例如,具有联合组件,文本到文本或语音到语音的组件或任何其他设置),并允许将现有或预训练的模型加载到Plato中。
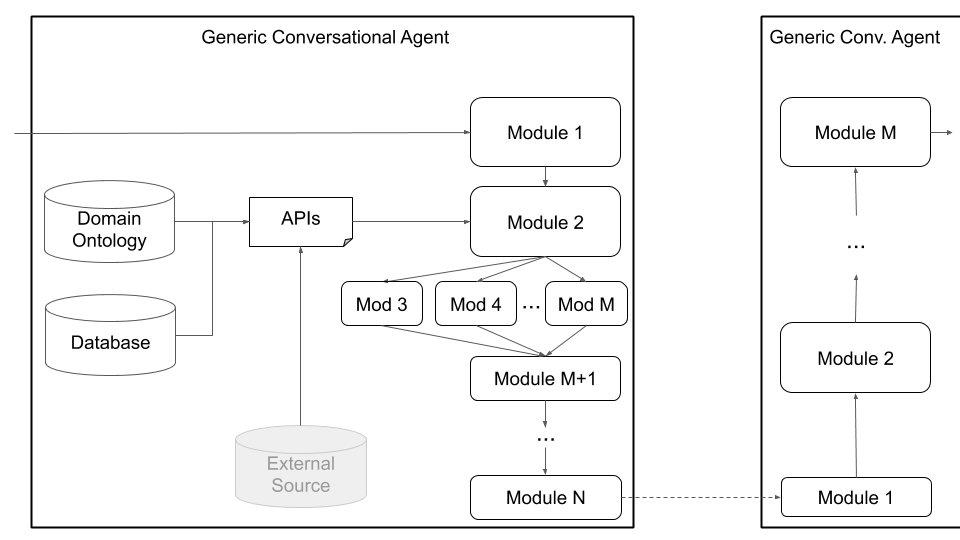 图4:柏拉图的通用代理体系结构支持广泛的自定义,包括联合组件,语音到语音组件以及文本到文本组件,所有这些组件都可以串行或并行执行。
图4:柏拉图的通用代理体系结构支持广泛的自定义,包括联合组件,语音到语音组件以及文本到文本组件,所有这些组件都可以串行或并行执行。
用户可以通过简单地提供Python类名称和软件包路径以及模型的初始化参数来定义自己的体系结构和/或将自己的组件插入柏拉图。用户需要做的就是按照应执行的顺序列出模块,然后柏拉图负责其余的,包括包装输入/输出,链接模块和处理对话。柏拉图支持模块的串行和并行执行。
柏拉图还通过贝叶斯优化组合结构(BOC)优化了对会话AI体系结构或单个模块参数的贝叶斯优化的支持。
首先确保您的机器上安装了3.6版或更高版本。接下来,您需要克隆柏拉图存储库:
git clone [email protected]:uber-research/plato-research-dialogue-system.git
接下来,您需要安装一些先决条件:
TensorFlow:
pip install tensorflow>=1.14.0
安装语音认知库以进行音频支持:
pip install SpeechRecognition
对于MacOS:
brew install portaudio
brew install gmp
pip install pyaudio
对于Ubuntu/Debian:
sudo apt-get install python3-pyaudio
对于Windows:预装不需要
下一步是安装柏拉图。要安装柏拉图,您应该直接从源代码安装它。
从源代码安装柏拉图允许以可编辑模式安装,这意味着如果您更改源代码,它将直接影响执行。
导航到柏拉图目录(在上一步中克隆了柏拉图存储库)。
我们建议创建一个新的Python环境。建立新的Python环境:
2.1安装Virtualenv
sudo pip install virtualenv
2.2创建一个新的Python环境:
python3 -m venv </path/to/new/virtual/environment>
2.3激活新的Python环境:
source </path/to/new/virtual/environment/bin>/bin/activate
安装柏拉图:
pip install -e .
为了支持语音,有必要安装Pyaudio,该Pyaudio具有许多可能在开发人员的机器上不存在的依赖项。如果以上步骤不成功,则有关Pyaudio安装错误的文章包括有关如何获得这些依赖项和安装Pyaudio的说明。
CommonIssues.md文件包含常见问题及其在安装时可能会遇到的解决方案。
要在安装后运行柏拉图,您只需在终端中运行plato命令即可。 plato命令收到4个子命令:
runguidomainparse这些子命令中的每一个都会收到一个指向配置文件的--config参数的值。 We will describe these configuration files in detail later in the document but remember that plato run --config and plato gui --config receive an application configuration file (examples could be found here: example/config/application/ ), plato domain --config receives a domain configuration (examples could be found here: example/config/domain/ ), and plato parse --config receives a parser configuration file (examples could be found这里: example/config/parser/ )。
对于传递给--config Plato首先检查的值,以查看该值是否是计算机上文件的地址。如果是这样,则柏拉图试图解析该文件。如果不是这样,Plato检查值是否是example/config/<application, domain, or parser>目录中文件的名称。
有关一些快速示例,请尝试以下剑桥餐厅域的配置文件:
plato run --config CamRest_user_simulator.yaml
plato run --config CamRest_text.yaml
plato run --config CamRest_speech.yaml
柏拉图中的应用程序,即对话系统,包含三个主要部分:
这些零件在应用程序配置文件中声明。可以在本节中的其余部分中找到此类配置文件的示例example/config/application/我们将在本节中详细描述每个部分。
为了在柏拉图中实现面向任务的对话框系统,用户需要指定构成对话框系统域的两个组件:
柏拉图提供了一个自动化这一构建本体和数据库的过程的命令。假设您想为花店构建对话代理,并且在.csv中有以下物品(可以在example/data/flowershop.csv中找到此文件):
id,type,color,price,occasion
1,rose,red,cheap,any
2,rose,white,cheap,anniversary
3,rose,yellow,cheap,celebration
4,lilly,white,moderate,any
5,orchid,pink,expensive,any
6,dahlia,blue,expensive,any
要自动生成一个.DB SQL文件和.json本体论文件,您需要创建一个域配置文件,在其中您应在其中指定CSV文件,输出路径以及可用的,请求和系统提取example/config/domain/create_flowershop_domain.yaml路径:
GENERAL:
csv_file_name: example/data/flowershop.csv
db_table_name: flowershop
db_file_path: example/domains/flowershop-dbase.db
ontology_file_path: example/domains/flowershop-rules.json
ONTOLOGY: # Optional
informable_slots: [type, price, occasion]
requestable_slots: [price, color]
System_requestable_slots: [type, price, occasion]
并运行命令:
plato domain --config create_flowershop_domain.yaml
如果一切顺利,您应该在example/domains/目录中有flowershop.json和flowershop.db 。
如果您收到此错误:
sqlite3.IntegrityError: UNIQUE constraint failed: flowershop.id
这意味着已经创建了.db文件。
现在,您可以简单地将柏拉图的虚拟组件作为理智检查并与您的花店经纪人交谈:
plato run --config flowershop_text.yaml
控制器是协调代理之间对话的对象。控制器将实例化代理,为每次对话初始化它们,通过输入并适当地输出,并跟踪统计信息。
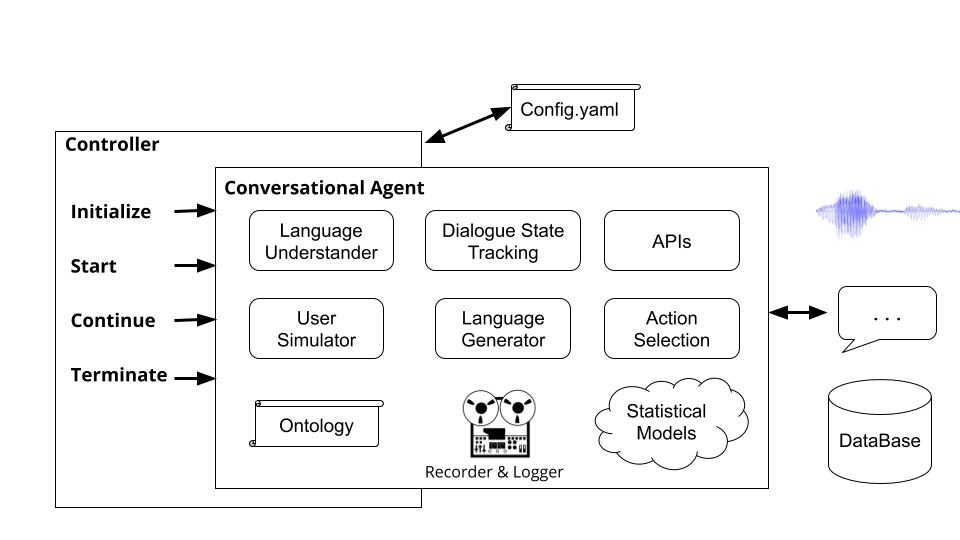
运行命令plato run柏拉图的基本控制器( plato/controller/basic_controller.py )。此命令将收到一个指向柏拉图应用程序配置文件的--config参数的值。
要运行柏拉图对话代理,用户必须使用适当的配置文件运行以下命令:
plato run --config <FULL PATH TO CONFIG YAML FILE>
请参阅example/config/application/例如配置文件,其中包含环境上的设置以及要创建的代理以及其组件。 example/config/application/可以使用示例yaml文件的名称直接运行的示例:
plato run --config <NAME OF A FILE FROM example/config/application/>
另外,用户可以通过将完整的路径传递到其配置文件到--config :Config:
plato run --config <FULL PATH TO CONFIG YAML FILE>
对于传递给--config Plato首先检查的值,以查看该值是否是计算机上文件的地址。如果是这样,柏拉图试图解析该文件。如果不是这样,Plato检查值是否是example/config/application目录中文件的名称。
柏拉图中的每个会话AI应用程序都可以具有一个或多个代理。每个代理都有一个角色(系统,用户,...)和一组标准对话框系统组件(图1),即NLU,对话经理,对话状态跟踪器,策略,NLG和用户模拟器。
代理可以为这些组件中的每个组件具有一个显式模块。或者,其中一些组件可以合并为一个或多个模块(例如接头 /端到端代理)可以顺序或并行运行(图4)。柏拉图的组件在plato.agent.component中定义,所有内容都来自plato.agent.component.conversational_module
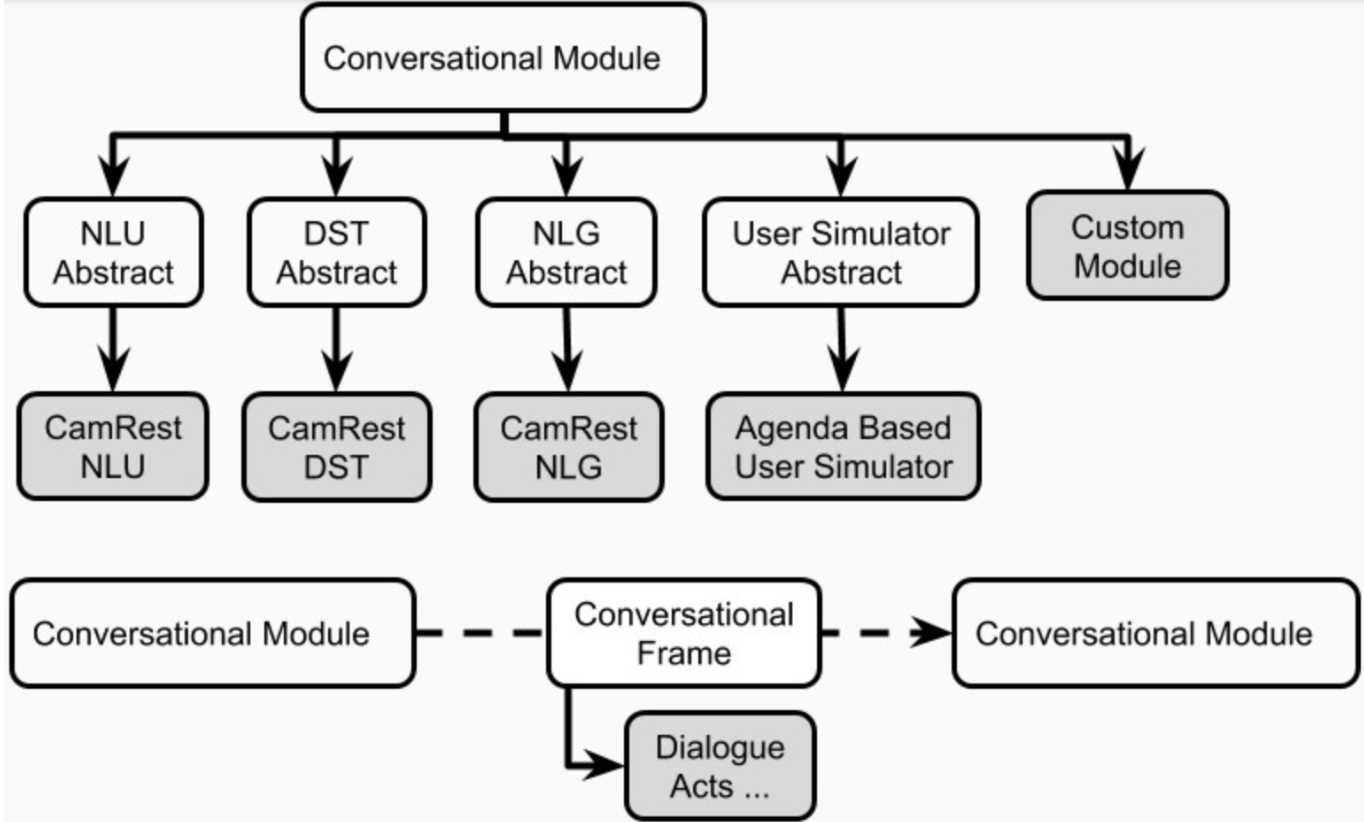 图5。柏拉图代理的组件
图5。柏拉图代理的组件
请注意,任何新的实现或自定义模块都应从plato.agent.component.conversational_module继承。
这些模块中的每个模块都可以是基于规则的或训练的。在以下小节中,我们将描述如何为代理建立基于规则的和训练有素的模块。
Plato提供了插槽填充对话代理的所有组件的基于规则的版本(slot_filling_nlu,slot_filling_dst,slot_filling_policy,slot_filling_nlg和default版本的dartenda_based_based_us)。这些可用于快速原型制作,基准或理智检查。具体而言,所有这些组件都遵循以给定本体论的规则或模式,有时在给定的数据库上,应被视为每个组件应执行的最基本版本。
使用任何深度学习框架,柏拉图支持在线(在互动)或离线(从数据中)方式(从数据)方式(在互动期间)中的组件模块进行培训。只要尊重柏拉图的界面输入/输出,几乎任何模型都可以加载到柏拉图中。例如,如果模型是自定义NLU模块,则只需从Plato的NLU摘要类( plato.agent.component.nlu )继承并实现必要的抽象方法即可。
为了促进在线学习,调试和评估,柏拉图在称为对话剧集录音机( plato.utilities.dialogue_episode_recorder )的结构中跟踪其内部经验,其中包含有关以前的对话状态,所采取的行动,当前的对话状态,收到的当前对话状态,接收到的内容,并收到了其他任何结构的信息,这些信息都无法与其他任何构成类别的结构相结合。
在对话或指定间隔结束时,每个对话代理将调用其每个内部组件的Train()功能,将对话体验作为培训数据。然后,每个组件选择培训所需的零件。
要使用在柏拉图内实现的学习算法,应将任何外部数据(例如DSTC2数据)解析到该柏拉图体验中,以便在培训下的相应组件可以加载和使用它们。
另外,用户可以解析数据并在柏拉图之外训练其模型,并在想将其用于柏拉图代理时加载训练有素的模型。
在线培训就像每个组件用户希望培训的配置中的“火车”标志一样容易。
要从数据训练,用户只需要加载他们从数据集中解释的经验即可。柏拉图为DSTC2和MetalWoz数据集提供了示例解析器。作为如何使用这些解析器在柏拉图进行离线培训的一个示例,我们将使用DSTC2数据集,可以从第二个对话状态跟踪挑战网站上获得。
http://camdial.org/~mh521/dstc/downloads/dstc2_traindev.tar.gz
下载完成后,您需要解压缩文件。通过example/config/parser/Parse_DSTC2.yaml提供了用于解析此数据集的配置文件。您可以通过首先在example/config/parser/Parse_DSTC2.yaml中编辑data_path的值来解析您下载的数据,以指向您下载并解开DSTC2数据的路径。接下来,您可以按以下方式运行解析脚本:
plato parse --config Parse_DSTC2.yaml
另外,您可以写自己的配置文件,然后将绝对地址传递给该文件到命令:
plato parse --config <absolute pass to parse config file>
运行此命令将运行DSTC2的解析脚本(该命令(该命令均在plato/utilities/parser/parse_dstc2.py下居住在Plato/Utilities/parse_dstc2.py下),并将为Dialog Tracker,NLU,NLU和NLG创建培训数据,并在此存储库的根目录的data目录中为用户和系统中的NLG创建培训数据。现在,该解析的数据可用于训练柏拉图不同组件的模型。
有多种方法可以训练柏拉图代理的每个组件:在线(由于代理与其他代理,模拟器或用户互动)或离线。此外,您可以使用柏拉图实现的算法,也可以使用tensorflow,pytorch,keras,ludwig等的外部框架。
路德维希(Ludwig)是一个开源深度学习框架,可让您无需编写任何代码而训练模型。您只需要将数据解析到.csv文件中,创建一个Ludwig Config(在YAML中),该config(在YAML中)描述了您想要的体系结构,哪些功能要在.csv和其他参数中使用,然后在终端中仅运行命令。
路德维希(Ludwig)还提供了一个API,柏拉图与之兼容。这使柏拉图可以与路德维希(Ludwig)型号集成,即负载或保存模型,训练和查询它们。
在上一节中,柏拉图的DSTC2解析器生成了一些可用于训练NLU和NLG的.csv文件。该系统有一个NLU .csv文件( data/DSTC2_NLU_sys.csv ),一个用于用户( data/DSTC2_NLU_usr.csv )。这些看起来像这样:
| 成绩单 | 意图 | IOB |
|---|---|---|
| 供素食的昂贵餐厅 | 通知 | b-inform-pricerange ooo b-inform Food o |
| 素食 | 通知 | B-形式食品o |
| 亚洲东方类型的食物 | 通知 | B-信息食品i-inform Food OOO |
| 昂贵的餐厅亚洲美食 | 通知 | b-form-pricerange ooo |
对于培训NLU模型,您需要编写一个看起来像这样的配置文件:
input_features:
-
name: transcript
type: sequence
reduce_output: null
encoder: parallel_cnn
output_features:
-
name: intent
type: set
reduce_output: null
-
name: iob
type: sequence
decoder: tagger
dependencies: [intent]
reduce_output: null
training:
epochs: 100
early_stop: 50
learning_rate: 0.0025
dropout: 0.5
batch_size: 128
此配置文件的示例存在于example/config/ludwig/ludwig_nlu_train.yaml中。培训工作可以从运行开始:
ludwig experiment
--model_definition_file example/config/ludwig/ludwig_nlu_train.yaml
--data_csv data/DSTC2_NLU_sys.csv
--output_directory models/camrest_nlu/sys/
下一步是将模型加载到应用程序配置中。在example/config/application/CamRest_model_nlu.yaml中,我们提供了一个基于模型NLU的应用程序配置,而其他组件则基于非ML。通过将通往模式( model_path )的路径更新为您在运行Ludwig时提供给-ox --output_directory参数的值,您可以指定代理需要用于NLU的NLU模型:
...
MODULE_0:
package: applications.cambridge_restaurants.camrest_nlu
class: CamRestNLU
arguments:
model_path: <PATH_TO_YOUR_MODEL>/model
...
并测试该模型有效:
plato run --config CamRest_model_nlu.yaml
DSTC2数据解析器生成了两个.csv文件,我们可以用于DST: DST_sys.csv和DST_usr.csv ,看起来像这样:
| dst_prev_food | dst_prev_area | DST_PREV_PRICERANGE | nlu_intent | req_slot | inf_area_value | inf_food_value | inf_pricerange_value | dst_food | dst_area | DST_PRICERANGE | dst_req_slot |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 没有任何 | 没有任何 | 没有任何 | 通知 | 没有任何 | 没有任何 | 素食主义者 | 昂贵的 | 素食主义者 | 没有任何 | 昂贵的 | 没有任何 |
| 素食主义者 | 没有任何 | 昂贵的 | 通知 | 没有任何 | 没有任何 | 素食主义者 | 没有任何 | 素食主义者 | 没有任何 | 昂贵的 | 没有任何 |
| 素食主义者 | 没有任何 | 昂贵的 | 通知 | 没有任何 | 没有任何 | 亚洲东方 | 没有任何 | 亚洲东方 | 没有任何 | 昂贵的 | 没有任何 |
| 亚洲东方 | 没有任何 | 昂贵的 | 通知 | 没有任何 | 没有任何 | 亚洲东方 | 昂贵的 | 亚洲东方 | 没有任何 | 昂贵的 | 没有任何 |
本质上,解析器跟踪以前的对话状态,NLU的意见以及由此产生的对话状态。然后,我们可以将其喂入路德维希(Ludwig)来训练对话状态跟踪器。这example/config/ludwig/ludwig_dst_train.yaml Ludwig配置
input_features:
-
name: dst_prev_food
type: category
-
name: dst_prev_area
type: category
-
name: dst_prev_pricerange
type: category
-
name: dst_intent
type: category
-
name: dst_slot
type: category
-
name: dst_value
type: category
output_features:
-
name: dst_food
type: category
-
name: dst_area
type: category
-
name: dst_pricerange
type: category
-
name: dst_req_slot
type: category
training:
epochs: 100
现在,我们需要用路德维希(Ludwig)培训我们的模型:
ludwig experiment
--model_definition_file example/config/ludwig/ludwig_dst_train.yaml
--data_csv data/DST_sys.csv
--output_directory models/camrest_dst/sys/
并使用基于模型的DST运行柏拉图代理:
plato run --config CamRest_model_dst.yaml
您当然可以尝试其他架构和培训参数。
到目前为止,我们已经看到了如何使用外部框架(即路德维希)训练柏拉图代理的组件。在本节中,我们将看到如何使用柏拉图的内部算法来离线训练对话政策,使用监督学习和在线使用强化学习。
除了.csv文件外,DSTC2解析器还使用Plato的对话剧集记录器还保存在柏拉图体验日志中的对话: logs/DSTC2_system和logs/DSTC2_user 。这些日志包含有关每个对话的信息,例如当前的对话状态,采取的动作,下一个对话状态,观察到的奖励,输入话语,成功等。这些日志可以直接加载到对话式代理中,可用于填充体验池。
然后,您需要做的就是编写一个加载这些日志的配置文件( example/config/CamRest_model_supervised_policy_train.yaml ):
GENERAL:
...
experience_logs:
save: False
load: True
path: logs/DSTC2_system
...
DIALOGUE:
# Since this configuration file trains a supervised policy from data loaded
# from the logs, we only really need one dialogue just to trigger the train.
num_dialogues: 1
initiative: system
domain: CamRest
AGENT_0:
role: system
max_turns: 15
train_interval: 1
train_epochs: 100
save_interval: 1
...
DM:
package: plato.agent.component.dialogue_manager.dialogue_manager_generic
class: DialogueManagerGeneric
arguments:
DST:
package: plato.agent.component.dialogue_state_tracker.slot_filling_dst
class: SlotFillingDST
policy:
package: plato.agent.component.dialogue_policy.deep_learning.supervised_policy
class: SupervisedPolicy
arguments:
train: True
learning_rate: 0.9
exploration_rate: 0.995
discount_factor: 0.95
learning_decay_rate: 0.95
exploration_decay_rate: 0.995
policy_path: models/camrest_policy/sys/sys_supervised_data
...
请注意,我们只使用从日志中加载的经验来进行一次对话,但要训练100个时期的训练:
plato run --config CamRest_model_supervised_policy_train.yaml
培训完成后,我们可以测试我们的监督政策:
plato run --config CamRest_model_supervised_policy_test.yaml
在上一节中,我们看到了如何培训监督对话政策。现在,我们可以看到如何使用加强算法来培训加强学习政策。为此,我们在配置文件中定义了相关类:
...
AGENT_0:
role: system
max_turns: 15
train_interval: 500
train_epochs: 3
train_minibatch: 200
save_interval: 5000
...
DM:
package: plato.agent.component.dialogue_manager.dialogue_manager_generic
class: DialogueManagerGeneric
arguments:
DST:
package: plato.agent.component.dialogue_state_tracker.slot_filling_dst
class: SlotFillingDST
policy:
package: plato.agent.component.dialogue_policy.deep_learning.reinforce_policy
class: ReinforcePolicy
arguments:
train: True
learning_rate: 0.9
exploration_rate: 0.995
discount_factor: 0.95
learning_decay_rate: 0.95
exploration_decay_rate: 0.995
policy_path: models/camrest_policy/sys/sys_reinforce
...
请注意,在策略的参数下, AGENT_0下的学习参数和算法特定参数。然后,我们使用此配置致电Plato:
plato run --config CamRest_model_reinforce_policy_train.yaml
并测试训练有素的政策模型:
plato run --config CamRest_model_reinforce_policy_test.yaml
请注意,其他组件也可以在线培训,要么使用路德维希的API或通过在柏拉图中实施学习算法。
还请注意,日志文件可以加载并用作任何组件和学习算法的体验池。但是,您可能需要为某些柏拉图组件实现自己的学习算法。
要训练NLG模块,您需要编写一个看起来像这样的配置文件(例如example/config/application/CamRest_model_nlg.yaml ):
---
input_features:
-
name: nlg_input
type: sequence
encoder: rnn
cell_type: lstm
output_features:
-
name: nlg_output
type: sequence
decoder: generator
cell_type: lstm
training:
epochs: 20
learning_rate: 0.001
dropout: 0.2
并训练您的模型:
ludwig experiment
--model_definition_file example/config/ludwig/ludwig_nlg_train.yaml
--data_csv data/DSTC2_NLG_sys.csv
--output_directory models/camrest_nlg/sys/
下一步是将模型加载到柏拉图中。转到CamRest_model_nlg.yaml配置文件,并在必要时更新路径:
...
NLG:
package: applications.cambridge_restaurants.camrest_nlg
class: CamRestNLG
arguments:
model_path: models/camrest_nlg/sys/experiment_run/model
...
并测试该模型有效:
plato run --config CamRest_model_nlg.yaml
请记住,路德维希(Ludwig)每次被调用时都会创建一个新的persiment_run_i目录,因此请确保在Plato的配置中保留正确的路径。
请注意,路德维希还提供了一种在线培训模型的方法,因此实际上,您需要写的很少的代码来构建,训练和评估柏拉图的新深度学习组件。
对于此示例,我们将使用您可以从此处下载的MetalWoz数据集。
柏拉图通过通用代理支持经过培训的模型。在这里,我们将看到从头开始创建一个简单的SEQ2SEQ对话代理所需的步骤。以MetalWoz为例,我们需要以以下方式进行以下操作:
由于我们只是训练一个简单的SEQ2SEQ模型(文本到文本),因此我们需要解析器来提取用户和系统话语。这些将保存在Ludwig将在步骤4中使用的.CSV文件中。
有关Metalwoz解析器的简单实现,请参见utilities/parser/Parse_MetalWOZ.py
请注意,该解析器只能解析一个文件(一个域)。但是,您可以轻松地修改它以满足您的需求。这是解析器为披萨订购域产生的输出的样本:
| 用户 | 系统 |
|---|---|
| 你好 | 您好,我该如何帮助您? |
| 我需要下订单披萨需要帮助 | 当然,您想添加什么? |
| 我想要一个带有蘑菇,意大利辣香肠和培根浇头的披萨 | 不幸的是,这个位置是您要求的培根顶。您想替换有不同的顶部吗? |
| 菠萝怎么样 | 可以使用该馅料。我在您的订单中添加了一个带有蘑菇,意大利辣香肠和菠萝的比萨饼。您想要什么尺寸? |
| 中等的 | 好吧,更新了。您想在订单中添加更多吗? |
| 就这些了,谢谢 | 好吧,您的总数是14.99。您的披萨将大约可以拾取。 20分钟。 |
注意数据中实际上不存在第一个用户话语。但是,我们需要一些东西来提示模型产生系统的问候 - 我们可以使用一个空句子或任何其他问候(或这些结合)。
然后,您可以按照以下方式进行柏拉图分析:
plato parse --config Parse_MetalWOZ.yaml
首先,我们可以使用路德维希(Ludwig)训练非常简单的模型(请随时在此处使用您喜欢的深度学习框架):
input_features:
-
name: user
type: text
level: word
encoder: rnn
cell_type: lstm
reduce_output: null
output_features:
-
name: system
type: text
level: word
decoder: generator
cell_type: lstm
attention: bahdanau
training:
epochs: 100
您可以修改此配置,以反映您选择的体系结构,并使用路德维格(Ludwig)进行训练:
ludwig train
--data_csv data/metalwoz.csv
--model_definition_file example/config/ludwig/metalWOZ_seq2seq_ludwig.yaml
--output_directory "models/joint_models/"
该类只需要处理模型的加载,对其进行适当查询并适当地格式化其输出即可。在我们的情况下,我们需要将输入文本包装到熊猫数据框中,从输出中获取预测的令牌,然后将它们加入将返回的字符串。请参阅此处的类: plato.agent.component.joint_model.metal_woz_seq2seq.py
有关example/config/application/metalwoz_generic.yaml有关示例通用配置文件,该文件与文本通过文本与SEQ2SEQ代理进行交互。您可以尝试如下:
plato run --config metalwoz_text.yaml
请记住,如有必要,请更新训练有素的型号的路径!默认路径假设您从柏拉图的根目录运行路德维希火车命令。
柏拉图的主要功能之一使两个代理可以相互作用。每个代理可以具有不同的角色(例如,系统和用户),不同的目标并接收不同的奖励信号。如果代理商正在合作,则可以共享其中一些(例如,构成成功的对话)。
为了在剑桥餐厅域上运行多个柏拉图特工,我们运行以下命令来训练特工的对话政策并测试:
训练阶段:培训2个政策(每个代理商1个)。这些政策是使用狼算法训练的:
plato run --config MultiAgent_train.yaml
测试阶段:使用在训练阶段训练的策略来创建两个代理之间的对话:
plato run --config MultiAgent_test.yaml
尽管基本控制器当前允许两个代理交互,但将其扩展到多个代理非常简单(例如,使用黑板架构,每个代理将其输出广播到其他代理)。这可以支持场景,例如智能家居,每个设备都是代理,具有各种角色的多用户交互等等。
柏拉图为两种用户模拟器提供了实现。一个是基于议程的用户模拟器,另一个是一个模拟器,试图模仿数据中观察到的用户行为。但是,我们鼓励研究人员简单地用柏拉图(一个是“系统”,一个是“用户”),而不是在可能的情况下使用模拟用户。
基于议程的用户模拟器是由Schatzmann提出的,并在本文中进行了详细说明。从概念上讲,模拟器保留要说的话的“议程”,通常将其作为堆栈实现。当模拟器收到输入时,它会咨询其策略(或一组规则),以查看将哪些内容推入议程,以作为对输入的响应。经过一些管家(例如,删除不再有效的重复或内容)之后,模拟器将弹出一个或多个项目,该项目将用于制定其响应。
基于议程的用户模拟器还具有错误模拟模块,可以模拟语音识别 /语言理解错误。基于某些概率,它将扭曲模拟器的输出对话行为 - 意图,插槽或值(每个概率不同)。这是该模拟器收到的全部参数列表的示例:
patience: 5 # Stop after <patience> consecutive identical inputs received
pop_distribution: [0.8, 0.15, 0.05] # pop 1 act with 0.8 probability, 2 acts with 0.15, etc.
slot_confuse_prob: 0.05 # probability by which the error model will alter the output dact slot
op_confuse_prob: 0.01 # probability by which the error model will alter the output dact operator
value_confuse_prob: 0.01 # probability by which the error model will alter the output dact value
nlu: slot_filling # type of NLU the simulator will use
nlg: slot_filling # type of NLG the simulator will use
该模拟器被设计为一个简单的基于策略的模拟器,可以在对话级别或话语级别上操作。为了演示其工作原理,DSTC2解析器为此模拟器创建了一个策略文件: user_policy_reactive.pkl (反应性,因为它对系统对话的反应而不是用户模拟器状态)。这实际上是一个简单的词典:
System Dial. Act 1 --> {'dacts': {User Dial. Act 1: probability}
{User Dial. Act 2: probability}
...
'responses': {User utterance 1: probability}
{User utterance 2: probability}
...
System Dial. Act 2 --> ...
键代表“输入对话法”(例如来自system对话代理)。每个密钥的值是两个元素的字典,代表模拟器将从对话行为或话语模板上进行采样的概率分布。
要查看示例,您可以运行以下配置:
plato run --config CamRest_dtl_simulator.yaml
有两种方法可以根据其功能创建新模块。例如,如果模块实现了执行NLU或对话策略的新方法,则应编写从相应的抽象类继承的类。
但是,如果模块不符合单个代理基本组件之一,例如,它执行命名实体识别或预测对话的行为,则必须编写一个直接从conversational_module继承的类。然后,您可以通过在配置中提供适当的软件包路径,类名和参数来通过通用代理加载模块。
...
MODULE_i:
package: my_package.my_module
Class: MyModule
arguments:
model_path: models/my_module/parameters/
...
...
当心!您有责任确保可以按照您的通用配置文件中提供的模块和之后的模块适当地处理和处理此模块的I/O。
柏拉图还支持(逻辑上)模块的并行执行。为了使您需要在配置中具有以下结构:
...
MODULE_i:
parallel_modules: 5
PARALLEL_MODULE_0:
package: my_package.my_module
Class: MyModule
arguments:
model_path: models/myModule/parameters/
...
PARALLEL_MODULE_1:
package: my_package.my_module
Class: MyModule
arguments:
model_path: models/my_module/parameters/
...
...
...
当心!并行执行的模块的输出将被包装到列表中。下一个模块(例如MODULE_i+1 )将需要能够处理这种输入。提供的柏拉图模块不是为处理此操作而设计的,您将需要编写一个自定义模块来处理多个来源的输入。
柏拉图的设计是可扩展的,因此请随意创建自己的对话状态,动作,奖励功能,算法或任何其他组件,以满足您的特定需求。您只需要从相应的类中继承即可确保您的实现与柏拉图兼容。
柏拉图使用pysimplegui处理图形用户界面。 plato.controller.sgui_controller实现了柏拉图的示例GUI,您可以使用以下命令尝试一下:
plato gui --config CamRest_GUI_speech.yaml
Special thanks to Mahdi Namazifar, Chandra Khatri, Yi-Chia Wang, Piero Molino, Michael Pearce, Zack Kaden, and Gokhan Tur for their contributions and support, and to studio FF3300 for allowing us to use the Messapia font.
Please understand that many features are still being implemented and some use cases may not be supported yet.
享受!


