plato research dialogue system
1.0.0

นี่คือ v0.3.1
ระบบบทสนทนาการวิจัยของเพลโตเป็นกรอบความยืดหยุ่นที่สามารถใช้ในการสร้างฝึกอบรมและประเมินตัวแทน AI สนทนาในสภาพแวดล้อมที่หลากหลาย รองรับการโต้ตอบผ่านการพูดข้อความหรือบทสนทนาและตัวแทนการสนทนาแต่ละรายการสามารถโต้ตอบกับข้อมูลผู้ใช้มนุษย์หรือตัวแทนการสนทนาอื่น ๆ (ในการตั้งค่าหลายตัวแทน) ทุกองค์ประกอบของเอเจนต์ทุกคนสามารถได้รับการฝึกฝนออนไลน์หรือออฟไลน์อย่างอิสระและเพลโตเป็นวิธีที่ง่ายในการห่อหุ้มแบบแทบทุกรุ่นที่มีอยู่ตราบใดที่อินเทอร์เฟซของเพลโตยึดติดอยู่
การอ้างอิงสิ่งพิมพ์:
Alexandros Papangelis, Mahdi Namazifar, Chandra Khatri, Yi-Chia Wang, Piero Molino และ Gokhan Tur, "ระบบบทสนทนาเพลโต: แพลตฟอร์มการวิจัย AI การสนทนาที่ยืดหยุ่น"
Alexandros Papangelis, Yi-Chia Wang, Piero Molino และ Gokhan Tur,“ การฝึกอบรมรูปแบบการสนทนาหลายตัวแทนร่วมกันผ่านการเรียนรู้การเสริมแรง”, Sigdial 2019 [กระดาษ]
เพลโตเขียนบทสนทนาหลายอย่างระหว่างตัวละครที่โต้แย้งในหัวข้อโดยถามคำถาม บทสนทนาเหล่านี้จำนวนมากมีคุณสมบัติโสกราตีสรวมถึงการทดลองใช้โสกราตีส (โสกราตีสถูกปล่อยตัวในการทดลองใหม่ที่จัดขึ้นในกรุงเอเธนส์ประเทศกรีซเมื่อวันที่ 25 พฤษภาคม 2555)
v0.2 : การอัปเดตหลักจาก v0.1 คือตอนนี้ Plato RDS มีให้เป็นแพ็คเกจ สิ่งนี้ทำให้ง่ายต่อการสร้างและบำรุงรักษาแอปพลิเคชัน AI การสนทนาใหม่และบทเรียนทั้งหมดได้รับการปรับปรุงเพื่อสะท้อนสิ่งนี้ ตอนนี้เพลโตก็มาพร้อมกับ GUI เสริม สนุก!
แนวคิดตัวแทนการสนทนาต้องผ่านขั้นตอนต่าง ๆ เพื่อประมวลผลข้อมูลที่ได้รับเป็นอินพุต (เช่น“ วันนี้สภาพอากาศเป็นอย่างไร”) และสร้างผลลัพธ์ที่เหมาะสม (“ ลมแรง แต่ไม่เย็นเกินไป”) ขั้นตอนหลักซึ่งสอดคล้องกับองค์ประกอบหลักของสถาปัตยกรรมมาตรฐาน (ดูรูปที่ 1) คือ:
เพลโตได้รับการออกแบบให้มีความยืดหยุ่นและยืดหยุ่นมากที่สุด รองรับสถาปัตยกรรม AI การสนทนาแบบดั้งเดิมและแบบกำหนดเองและที่สำคัญช่วยให้การโต้ตอบหลายพรรคซึ่งตัวแทนหลายคนอาจมีบทบาทที่แตกต่างกันสามารถโต้ตอบกันฝึกฝนพร้อมกันและแก้ปัญหาการกระจาย
รูปที่ 1 และ 2 ด้านล่างแสดงตัวอย่างสถาปัตยกรรมตัวแทนการสนทนา PLATO เมื่อมีปฏิสัมพันธ์กับผู้ใช้มนุษย์และกับผู้ใช้จำลองตามลำดับ การมีปฏิสัมพันธ์กับผู้ใช้จำลองเป็นวิธีปฏิบัติทั่วไปที่ใช้ในชุมชนการวิจัยเพื่อเริ่มการเรียนรู้เริ่มต้น (เช่นเรียนรู้พฤติกรรมพื้นฐานบางอย่างก่อนที่จะโต้ตอบกับมนุษย์) แต่ละองค์ประกอบสามารถได้รับการฝึกอบรมออนไลน์หรือออฟไลน์โดยใช้ไลบรารีการเรียนรู้ของเครื่องใด ๆ (ตัวอย่างเช่น Ludwig, Tensorflow, Pytorch หรือการใช้งานของคุณเอง) เนื่องจาก Plato เป็นกรอบสากล Ludwig กล่องเครื่องมือการเรียนรู้ลึกของ Uber ของ Uber ทำให้เป็นทางเลือกที่ดีเนื่องจากไม่จำเป็นต้องมีการเขียนโค้ดและเข้ากันได้อย่างเต็มที่กับเพลโต
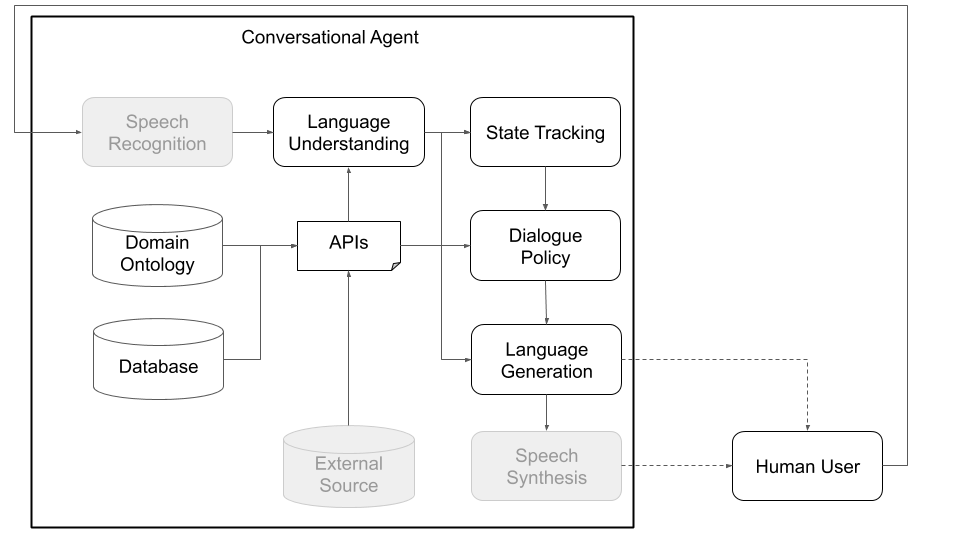 รูปที่ 1: สถาปัตยกรรมแบบแยกส่วนของเพลโตหมายความว่าส่วนประกอบใด ๆ สามารถฝึกอบรมออนไลน์หรือออฟไลน์และสามารถแทนที่ด้วยโมเดลที่กำหนดเองหรือได้รับการฝึกฝนมาก่อน (ส่วนประกอบสีเทาในแผนภาพนี้ไม่ใช่ส่วนประกอบหลักของเพลโต)
รูปที่ 1: สถาปัตยกรรมแบบแยกส่วนของเพลโตหมายความว่าส่วนประกอบใด ๆ สามารถฝึกอบรมออนไลน์หรือออฟไลน์และสามารถแทนที่ด้วยโมเดลที่กำหนดเองหรือได้รับการฝึกฝนมาก่อน (ส่วนประกอบสีเทาในแผนภาพนี้ไม่ใช่ส่วนประกอบหลักของเพลโต)
 รูปที่ 2: การใช้ผู้ใช้จำลองมากกว่าผู้ใช้มนุษย์ดังในรูปที่ 1 เราสามารถสร้างแบบจำลองทางสถิติล่วงหน้าสำหรับส่วนประกอบต่าง ๆ ของเพลโต สิ่งเหล่านี้สามารถใช้ในการสร้างตัวแทนการสนทนาต้นแบบที่สามารถโต้ตอบกับผู้ใช้มนุษย์เพื่อรวบรวมข้อมูลที่เป็นธรรมชาติมากขึ้นซึ่งสามารถนำมาใช้ในการฝึกอบรมแบบจำลองทางสถิติที่ดีกว่า (ส่วนประกอบสีเทาในแผนภาพนี้ไม่ใช่ส่วนประกอบของเพลโตคอร์เนื่องจากมีให้เลือกทั้งนอกกรอบเช่น Google ASR และ Amazon Lex หรือโดเมนและแอปพลิเคชันเฉพาะเช่นฐานข้อมูลที่กำหนดเอง/APIs)
รูปที่ 2: การใช้ผู้ใช้จำลองมากกว่าผู้ใช้มนุษย์ดังในรูปที่ 1 เราสามารถสร้างแบบจำลองทางสถิติล่วงหน้าสำหรับส่วนประกอบต่าง ๆ ของเพลโต สิ่งเหล่านี้สามารถใช้ในการสร้างตัวแทนการสนทนาต้นแบบที่สามารถโต้ตอบกับผู้ใช้มนุษย์เพื่อรวบรวมข้อมูลที่เป็นธรรมชาติมากขึ้นซึ่งสามารถนำมาใช้ในการฝึกอบรมแบบจำลองทางสถิติที่ดีกว่า (ส่วนประกอบสีเทาในแผนภาพนี้ไม่ใช่ส่วนประกอบของเพลโตคอร์เนื่องจากมีให้เลือกทั้งนอกกรอบเช่น Google ASR และ Amazon Lex หรือโดเมนและแอปพลิเคชันเฉพาะเช่นฐานข้อมูลที่กำหนดเอง/APIs)
นอกเหนือจากการโต้ตอบแบบตัวแทนเดี่ยวเพลโตยังสนับสนุนการสนทนาหลายตัวแทนที่ตัวแทนเพลโตหลายคนสามารถโต้ตอบและเรียนรู้จากกันและกัน โดยเฉพาะอย่างยิ่งเพลโตจะวางไข่ตัวแทนการสนทนาตรวจสอบให้แน่ใจว่าอินพุตและเอาต์พุต (สิ่งที่ตัวแทนแต่ละคนได้ยินและพูดว่า) จะถูกส่งไปยังตัวแทนแต่ละตัวอย่างเหมาะสมและติดตามการสนทนา
การตั้งค่านี้สามารถอำนวยความสะดวกในการวิจัยในการเรียนรู้หลายตัวแทนซึ่งตัวแทนจำเป็นต้องเรียนรู้วิธีการสร้างภาษาเพื่อทำงานรวมถึงการวิจัยในสาขาย่อยของการโต้ตอบหลายพรรค (การติดตามสถานะบทสนทนาการเลี้ยว ฯลฯ ) หลักการสนทนากำหนดสิ่งที่ตัวแทนแต่ละคนสามารถเข้าใจได้ (อภิปรัชญาของหน่วยงานหรือความหมาย; ตัวอย่างเช่นราคาสถานที่ตั้งค่าการตั้งค่าประเภทอาหาร ฯลฯ ) และสิ่งที่สามารถทำได้ (ขอข้อมูลเพิ่มเติมให้ข้อมูลบางอย่างโทร API ฯลฯ ) ตัวแทนสามารถสื่อสารผ่านคำพูดข้อความหรือข้อมูลที่มีโครงสร้าง (การสนทนาการสนทนา) และแต่ละตัวแทนมีการกำหนดค่าของตัวเอง รูปที่ 3 ด้านล่างแสดงให้เห็นถึงสถาปัตยกรรมนี้โดยสรุปการสื่อสารระหว่างตัวแทนสองตัวและส่วนประกอบต่าง ๆ :
 รูปที่ 3: สถาปัตยกรรมของเพลโตช่วยให้การฝึกอบรมพร้อมกันของตัวแทนหลายตัวแต่ละคนมีบทบาทและวัตถุประสงค์ที่แตกต่างกันและสามารถอำนวยความสะดวกในการวิจัยในสาขาต่าง ๆ เช่นปฏิสัมพันธ์หลายฝ่ายและการเรียนรู้หลายตัวแทน (ส่วนประกอบสีเทาในแผนภาพนี้ไม่ใช่ส่วนประกอบหลักของเพลโต)
รูปที่ 3: สถาปัตยกรรมของเพลโตช่วยให้การฝึกอบรมพร้อมกันของตัวแทนหลายตัวแต่ละคนมีบทบาทและวัตถุประสงค์ที่แตกต่างกันและสามารถอำนวยความสะดวกในการวิจัยในสาขาต่าง ๆ เช่นปฏิสัมพันธ์หลายฝ่ายและการเรียนรู้หลายตัวแทน (ส่วนประกอบสีเทาในแผนภาพนี้ไม่ใช่ส่วนประกอบหลักของเพลโต)
ในที่สุดเพลโตสนับสนุนสถาปัตยกรรมที่กำหนดเอง (เช่นการแยก NLU ออกเป็นส่วนประกอบอิสระหลายส่วน) และส่วนประกอบที่ได้รับการฝึกฝนร่วมกัน (เช่นสถานะข้อความไปยัง-ข้อความ, ข้อความเป็นข้อความหรือชุดค่าผสมอื่น ๆ ) ผ่านสถาปัตยกรรมตัวแทนทั่วไปที่แสดงในรูปที่ 4 ด้านล่าง โหมดนี้ย้ายออกไปจากสถาปัตยกรรมตัวแทนการสนทนามาตรฐานและรองรับสถาปัตยกรรมทุกชนิด (เช่นส่วนประกอบร่วมข้อความเป็นข้อความหรือคำพูดเป็นคำพูดหรือการตั้งค่าอื่น ๆ ) และอนุญาตให้โหลดโมเดลที่มีอยู่หรือได้รับการฝึกฝนไว้ล่วงหน้าลงในเพลโต
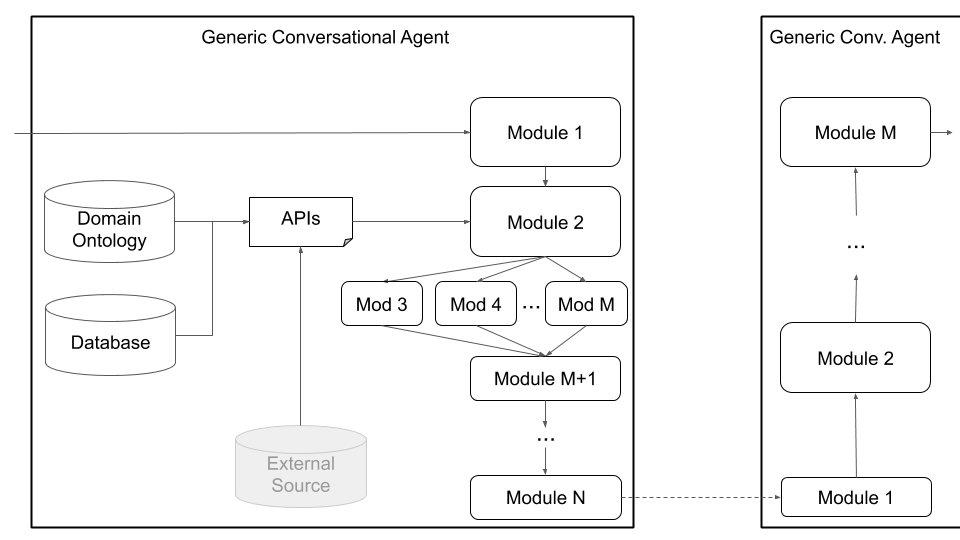 รูปที่ 4: สถาปัตยกรรมตัวแทนทั่วไปของ Plato รองรับการปรับแต่งที่หลากหลายรวมถึงส่วนประกอบร่วมส่วนประกอบคำพูดกับคำพูดและส่วนประกอบข้อความเป็นข้อความซึ่งทั้งหมดสามารถดำเนินการได้แบบอนุกรมหรือแบบขนาน
รูปที่ 4: สถาปัตยกรรมตัวแทนทั่วไปของ Plato รองรับการปรับแต่งที่หลากหลายรวมถึงส่วนประกอบร่วมส่วนประกอบคำพูดกับคำพูดและส่วนประกอบข้อความเป็นข้อความซึ่งทั้งหมดสามารถดำเนินการได้แบบอนุกรมหรือแบบขนาน
ผู้ใช้สามารถกำหนดสถาปัตยกรรมของตนเองและ/หรือเสียบส่วนประกอบของตัวเองเข้ากับเพลโตได้เพียงแค่ให้ชื่อคลาส Python และเส้นทางแพ็คเกจไปยังโมดูลนั้นรวมถึงข้อโต้แย้งการเริ่มต้นของโมเดล ผู้ใช้ทั้งหมดต้องทำคือแสดงรายการโมดูลตามลำดับที่ควรดำเนินการและเพลโตจะดูแลส่วนที่เหลือรวมถึงการห่ออินพุต/เอาท์พุทการผูกมัดโมดูลและการจัดการบทสนทนา เพลโตสนับสนุนการดำเนินการแบบอนุกรมและแบบขนานของโมดูล
เพลโตยังให้การสนับสนุนการเพิ่มประสิทธิภาพแบบเบย์ของสถาปัตยกรรม AI การสนทนาหรือพารามิเตอร์แต่ละโมดูลผ่านการเพิ่มประสิทธิภาพแบบเบย์ของโครงสร้าง combinatorial (BOCs)
ก่อนอื่นตรวจสอบให้แน่ใจว่าคุณติดตั้ง Python เวอร์ชัน 3.6 หรือสูงกว่าบนเครื่องของคุณ ถัดไปคุณต้องโคลนที่เก็บเพลโต:
git clone [email protected]:uber-research/plato-research-dialogue-system.git
ถัดไปคุณต้องติดตั้งสิ่งที่จำเป็นต้องมีบางอย่าง:
Tensorflow:
pip install tensorflow>=1.14.0
ติดตั้งไลบรารีคำพูดสำหรับการสนับสนุนเสียง:
pip install SpeechRecognition
สำหรับ macOS:
brew install portaudio
brew install gmp
pip install pyaudio
สำหรับ Ubuntu/Debian:
sudo apt-get install python3-pyaudio
สำหรับ Windows: ไม่จำเป็นต้องติดตั้งไว้ล่วงหน้า
ขั้นตอนต่อไปคือการติดตั้งเพลโต ในการติดตั้ง Plato คุณควรติดตั้งโดยตรงจากซอร์สโค้ด
การติดตั้ง PLATO จากซอร์สโค้ดช่วยให้การติดตั้งในโหมดแก้ไขได้ซึ่งหมายความว่าหากคุณทำการเปลี่ยนแปลงซอร์สโค้ดมันจะส่งผลโดยตรง
นำทางไปยังไดเรกทอรีของเพลโต (ที่คุณโคลนที่เก็บเพลโตในขั้นตอนก่อนหน้า)
เราแนะนำให้สร้างสภาพแวดล้อม Python ใหม่ ในการตั้งค่าสภาพแวดล้อม Python ใหม่:
2.1 ติดตั้ง virtualenv
sudo pip install virtualenv
2.2 สร้างสภาพแวดล้อม Python ใหม่:
python3 -m venv </path/to/new/virtual/environment>
2.3 เปิดใช้งานสภาพแวดล้อม Python ใหม่:
source </path/to/new/virtual/environment/bin>/bin/activate
ติดตั้ง Plato:
pip install -e .
เพื่อสนับสนุนการพูดมีความจำเป็นในการติดตั้ง Pyaudio ซึ่งมีการอ้างอิงจำนวนมากที่อาจไม่มีอยู่ในเครื่องของนักพัฒนา หากขั้นตอนข้างต้นไม่ประสบความสำเร็จโพสต์นี้ในข้อผิดพลาดในการติดตั้ง Pyaudio จะมีคำแนะนำเกี่ยวกับวิธีรับการอ้างอิงเหล่านี้และติดตั้ง Pyaudio
ไฟล์ CommonIssues.md มีปัญหาทั่วไปและความละเอียดที่ผู้ใช้อาจพบในขณะที่การติดตั้ง
ในการเรียกใช้เพลโตหลังจากการติดตั้งคุณสามารถเรียกใช้คำสั่ง plato ในเทอร์มินัล คำสั่ง plato ได้รับ 4 คำสั่งย่อย:
runguidomainparse คำสั่งย่อยเหล่านี้แต่ละคนจะได้รับค่าสำหรับอาร์กิวเมนต์ --config ที่ชี้ไปที่ไฟล์การกำหนดค่า เราจะอธิบายไฟล์การกำหนดค่าเหล่านี้โดยละเอียดในเอกสาร แต่โปรดจำไว้ว่า plato run --config และ Plato plato domain --config plato gui --config ได้รับไฟล์การกำหนดค่าแอปพลิเคชัน (ตัวอย่างสามารถพบได้ที่นี่: example/config/application/ example/config/domain/ ), plato parse --config ได้รับการกำหนดค่าโดเมน example/config/parser/ )
สำหรับค่าที่ส่งผ่านไปยัง --config Plato ก่อนตรวจสอบเพื่อดูว่าค่าเป็นที่อยู่ของไฟล์บนเครื่องหรือไม่ ถ้าเป็นเช่นนั้นเพลโตก็พยายามแยกวิเคราะห์ไฟล์นั้น หากไม่เป็นเช่นนั้นเพลโตจะตรวจสอบเพื่อดูว่าค่าเป็นชื่อของไฟล์ภายในไดเรกทอรี example/config/<application, domain, or parser>
สำหรับตัวอย่างด่วนลองใช้ไฟล์กำหนดค่าต่อไปนี้สำหรับโดเมนร้านอาหารเคมบริดจ์:
plato run --config CamRest_user_simulator.yaml
plato run --config CamRest_text.yaml
plato run --config CamRest_speech.yaml
แอปพลิเคชันคือระบบการสนทนาในเพลโตมีสามส่วนหลัก:
ชิ้นส่วนเหล่านี้ถูกประกาศในไฟล์การกำหนดค่าแอปพลิเคชัน ตัวอย่างของไฟล์การกำหนดค่าดังกล่าวสามารถพบได้ที่ example/config/application/ ในส่วนที่เหลือของส่วนนี้เราอธิบายรายละเอียดแต่ละส่วนเหล่านี้ในรายละเอียด
สำหรับการใช้ระบบโต้ตอบที่มุ่งเน้นงานใน Plato ผู้ใช้จำเป็นต้องระบุสององค์ประกอบที่เป็น โดเมน ของระบบโต้ตอบ:
เพลโตให้คำสั่งสำหรับการสร้างกระบวนการในการสร้างอภิปรัชญาและฐานข้อมูลโดยอัตโนมัติ สมมติว่าคุณต้องการสร้างตัวแทนการสนทนาสำหรับร้านดอกไม้และคุณมีรายการต่อไปนี้ใน. csv (ไฟล์นี้สามารถพบได้ที่ example/data/flowershop.csv ):
id,type,color,price,occasion
1,rose,red,cheap,any
2,rose,white,cheap,anniversary
3,rose,yellow,cheap,celebration
4,lilly,white,moderate,any
5,orchid,pink,expensive,any
6,dahlia,blue,expensive,any
ในการสร้างไฟล์. db SQL โดยอัตโนมัติและไฟล์. ontology .json คุณต้องสร้างไฟล์การกำหนดค่าโดเมนภายในซึ่งคุณควรระบุเส้นทางไปยังไฟล์ CSV, เส้นทางเอาต์พุตรวมถึงสล็อต example/config/domain/create_flowershop_domain.yaml สามารถร้องขอได้
GENERAL:
csv_file_name: example/data/flowershop.csv
db_table_name: flowershop
db_file_path: example/domains/flowershop-dbase.db
ontology_file_path: example/domains/flowershop-rules.json
ONTOLOGY: # Optional
informable_slots: [type, price, occasion]
requestable_slots: [price, color]
System_requestable_slots: [type, price, occasion]
และเรียกใช้คำสั่ง:
plato domain --config create_flowershop_domain.yaml
หากทุกอย่างเป็นไปด้วยดีคุณควรมี flowershop.json และ flowershop.db ใน example/domains/ ไดเรกทอรี
หากคุณได้รับข้อผิดพลาดนี้:
sqlite3.IntegrityError: UNIQUE constraint failed: flowershop.id
หมายความว่าไฟล์. db ได้ถูกสร้างขึ้นแล้ว
ตอนนี้คุณสามารถเรียกใช้ส่วนประกอบจำลองของเพลโตเพื่อตรวจสอบสติและพูดคุยกับตัวแทนร้านดอกไม้ของคุณ:
plato run --config flowershop_text.yaml
คอนโทรลเลอร์เป็นวัตถุที่จัดบทสนทนาระหว่างตัวแทน คอนโทรลเลอร์จะยกตัวอย่างเอเจนต์เริ่มต้นสำหรับการสนทนาแต่ละครั้งส่งผ่านอินพุตและเอาต์พุตอย่างเหมาะสมและติดตามสถิติ
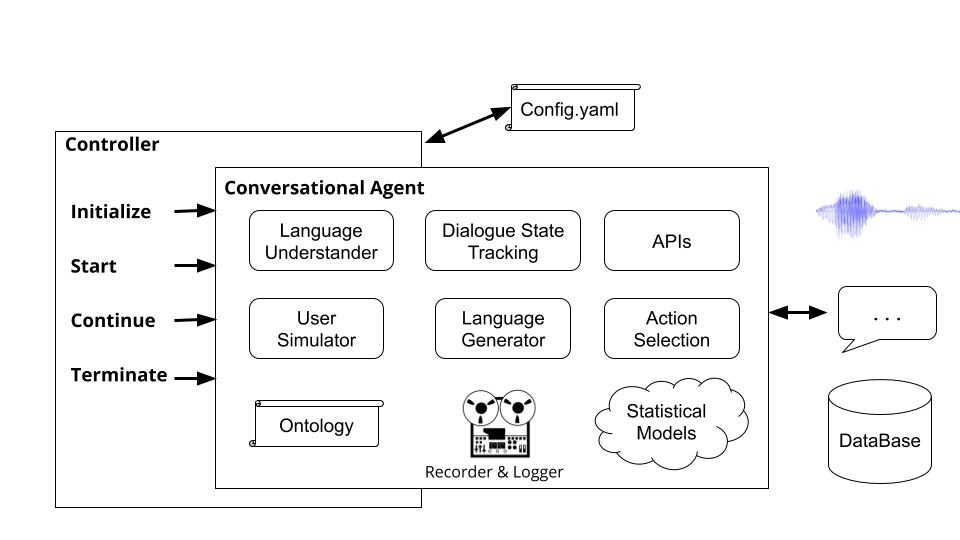
การรันคำสั่ง plato run Runs Controller พื้นฐานของ Plato ( plato/controller/basic_controller.py ) คำสั่งนี้ได้รับค่าสำหรับ --config อาร์กิวเมนต์ซึ่งชี้ไปที่ไฟล์การกำหนดค่าแอปพลิเคชันเพลโต
ในการเรียกใช้ตัวแทนการสนทนาของเพลโตผู้ใช้จะต้องเรียกใช้คำสั่งต่อไปนี้ด้วยไฟล์การกำหนดค่าที่เหมาะสม:
plato run --config <FULL PATH TO CONFIG YAML FILE>
โปรดดู example/config/application/ ตัวอย่างไฟล์การกำหนดค่าที่มีการตั้งค่าบนสภาพแวดล้อมและตัวแทนที่จะสร้างเช่นเดียวกับส่วนประกอบของพวกเขา ตัวอย่างใน example/config/application/ สามารถเรียกใช้โดยตรงโดยใช้เพียงชื่อของตัวอย่างไฟล์ YAML:
plato run --config <NAME OF A FILE FROM example/config/application/>
อีกทางเลือกหนึ่งผู้ใช้สามารถเขียนไฟล์กำหนดค่าของตัวเองและเรียกใช้ PLATO โดยส่งเส้นทางเต็มไปยังไฟล์กำหนดค่าของพวกเขาไปยัง --config :
plato run --config <FULL PATH TO CONFIG YAML FILE>
สำหรับค่าที่ส่งผ่านไปยัง --config Plato ก่อนตรวจสอบเพื่อดูว่าค่าเป็นที่อยู่ของไฟล์บนเครื่องหรือไม่ ถ้าเป็นเช่นนั้นเพลโตพยายามแยกวิเคราะห์ไฟล์นั้น หากไม่เป็นเช่นนั้นเพลโตจะตรวจสอบเพื่อดูว่าค่าเป็นชื่อของไฟล์ภายในไดเรกทอรี example/config/application หรือไม่
แอปพลิเคชั่น AI การสนทนาแต่ละครั้งในเพลโตอาจมีตัวแทนหนึ่งตัวขึ้นไป แต่ละเอเจนต์มีบทบาท (ระบบผู้ใช้ ... ) และชุดของส่วนประกอบระบบโต้ตอบมาตรฐาน (รูปที่ 1) คือ NLU, ตัวจัดการการสนทนา, ตัวติดตามสถานะการสนทนา, นโยบาย, NLG และผู้ใช้เครื่องจำลอง
เอเจนต์อาจมีหนึ่งโมดูลที่ชัดเจนสำหรับแต่ละส่วนประกอบเหล่านี้ อีกทางเลือกหนึ่งส่วนประกอบเหล่านี้บางส่วนอาจรวมกันเป็นหนึ่งโมดูลหรือมากกว่า (เช่นข้อต่อ / end-to-end) ที่สามารถทำงานตามลำดับหรือขนานกัน (รูปที่ 4) ส่วนประกอบของเพลโตถูกกำหนดไว้ใน plato.agent.component และทั้งหมดได้รับมรดกจาก plato.agent.component.conversational_module
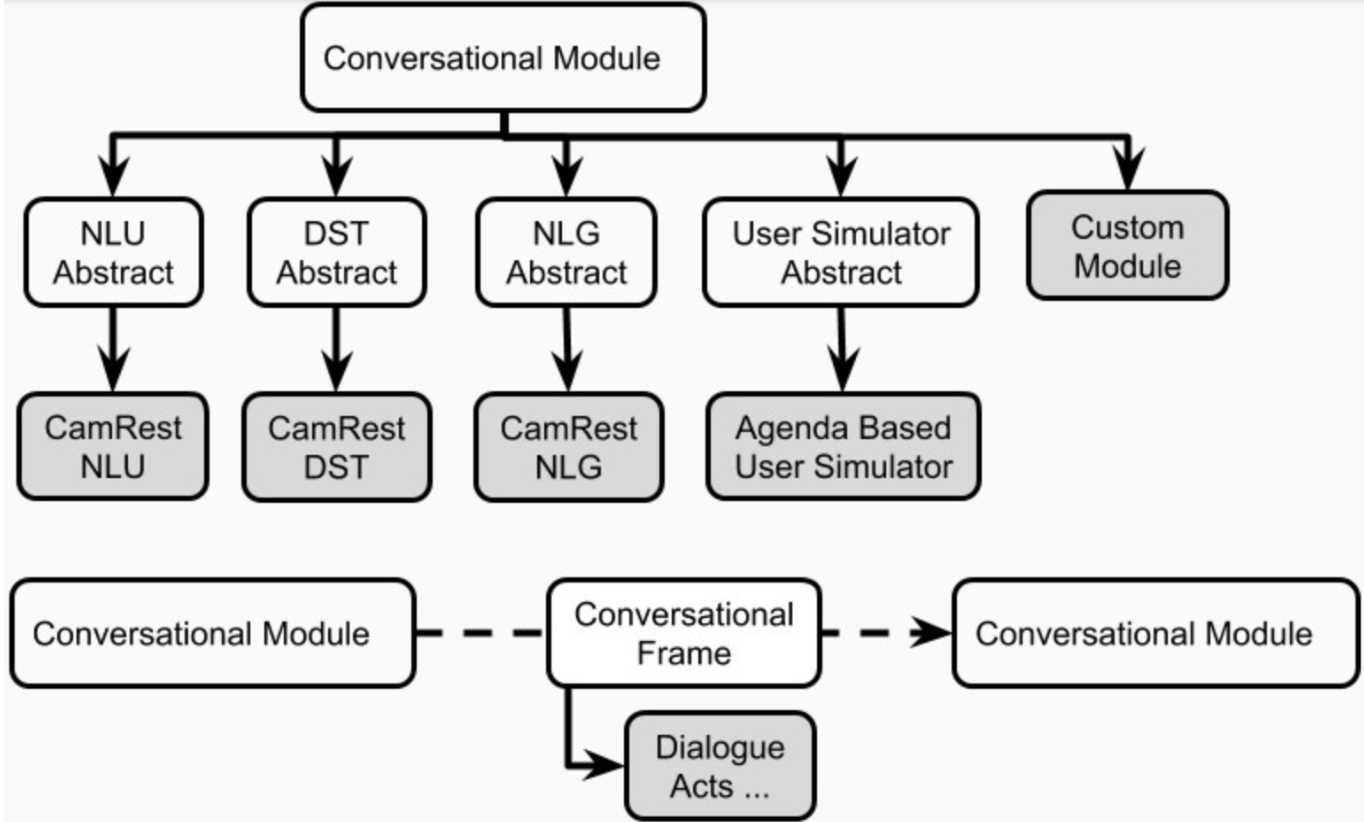 รูปที่ 5. ส่วนประกอบของตัวแทนเพลโต
รูปที่ 5. ส่วนประกอบของตัวแทนเพลโต
โปรดทราบว่าการใช้งานใหม่หรือโมดูลที่กำหนดเองควรสืบทอดจาก plato.agent.component.conversational_module
แต่ละโมดูลเหล่านี้อาจเป็นทั้งกฎหรือผ่านการฝึกอบรม ในส่วนย่อยต่อไปนี้เราจะอธิบายวิธีการสร้างโมดูลตามกฎและการฝึกอบรมสำหรับตัวแทน
Plato จัดเตรียมเวอร์ชันตามกฎของส่วนประกอบทั้งหมดของตัวแทนการสนทนาแบบเติมสล็อต (slot_filling_nlu, slot_filling_dst, slot_filling_policy, slot_filling_nlg และรุ่นเริ่มต้นของวาระการประชุม _based_us) สิ่งเหล่านี้สามารถใช้สำหรับการสร้างต้นแบบอย่างรวดเร็ว baselines หรือการตรวจสอบสติ โดยเฉพาะอย่างยิ่งส่วนประกอบเหล่านี้ทั้งหมดเป็นไปตามกฎหรือรูปแบบที่กำหนดไว้ใน ontology ที่ได้รับและบางครั้งในฐานข้อมูลที่กำหนดและควรได้รับการปฏิบัติเป็นเวอร์ชันพื้นฐานที่สุดของสิ่งที่แต่ละองค์ประกอบควรทำ
เพลโตสนับสนุนการฝึกอบรมโมดูลส่วนประกอบของตัวแทนในลักษณะออนไลน์ (ระหว่างการโต้ตอบ) หรือลักษณะออฟไลน์ (จากข้อมูล) โดยใช้กรอบการเรียนรู้เชิงลึกใด ๆ แทบทุกรุ่นสามารถโหลดลงในเพลโตได้ตราบใดที่อินพุต/เอาต์พุตของอินเทอร์เฟซของเพลโตได้รับการเคารพ ตัวอย่างเช่นหากโมเดลเป็นโมดูล NLU แบบกำหนดเองมันก็จำเป็นต้องได้รับการสืบทอดจากคลาสนามธรรม NLU ของ Plato ( plato.agent.component.nlu ) และใช้วิธีนามธรรมที่จำเป็น
เพื่ออำนวยความสะดวกในการเรียนรู้ออนไลน์การดีบักและการประเมินผลเพลโตติดตามประสบการณ์ภายในในโครงสร้างที่เรียกว่าเครื่องบันทึกบทสนทนา ( plato.utilities.dialogue_episode_recorder ) ซึ่งมีข้อมูลเกี่ยวกับสถานะการสนทนาก่อนหน้านี้
ในตอนท้ายของบทสนทนาหรือตามช่วงเวลาที่กำหนดตัวแทนการสนทนาแต่ละคนจะเรียกฟังก์ชั่นรถไฟ () ของแต่ละองค์ประกอบภายในของแต่ละส่วนโดยผ่านประสบการณ์การสนทนาเป็นข้อมูลการฝึกอบรม แต่ละองค์ประกอบจะเลือกชิ้นส่วนที่ต้องการสำหรับการฝึกอบรม
ในการใช้อัลกอริทึมการเรียนรู้ที่นำไปใช้ภายใน PLATO ข้อมูลภายนอกใด ๆ เช่นข้อมูล DSTC2 ควรแยกวิเคราะห์ประสบการณ์ PLATO นี้เพื่อให้พวกเขาสามารถโหลดและใช้งานโดยองค์ประกอบที่เกี่ยวข้องภายใต้การฝึกอบรม
อีกทางเลือกหนึ่งผู้ใช้อาจแยกวิเคราะห์ข้อมูลและฝึกอบรมแบบจำลองของพวกเขานอก Plato และเพียงแค่โหลดโมเดลที่ผ่านการฝึกอบรมเมื่อพวกเขาต้องการใช้สำหรับตัวแทนเพลโต
การฝึกอบรมออนไลน์นั้นง่ายพอ ๆ กับการพลิกธง 'รถไฟ' เป็น 'จริง' ในการกำหนดค่าสำหรับผู้ใช้ส่วนประกอบแต่ละคนที่ต้องการฝึกอบรม
ในการฝึกอบรมจากข้อมูลผู้ใช้เพียงแค่ต้องโหลดประสบการณ์ที่พวกเขาแยกวิเคราะห์จากชุดข้อมูลของพวกเขา Plato ให้ตัวอย่างตัวแยกวิเคราะห์สำหรับชุดข้อมูล DSTC2 และ Metalwoz เป็นตัวอย่างของวิธีการใช้พาร์สเซอร์เหล่านี้สำหรับการฝึกอบรมออฟไลน์ในเพลโตเราจะใช้ชุดข้อมูล DSTC2 ซึ่งสามารถรับได้จากเว็บไซต์การติดตามสถานะการติดตามการสนทนาครั้งที่ 2:
http://camdial.org/~mh521/dstc/downloads/dstc2_traindev.tar.gz
เมื่อการดาวน์โหลดเสร็จสมบูรณ์คุณจะต้องคลายซิปไฟล์ ไฟล์กำหนดค่าสำหรับการแยกวิเคราะห์ชุดข้อมูลนี้มีให้ที่ example/config/parser/Parse_DSTC2.yaml คุณสามารถแยกวิเคราะห์ข้อมูลที่คุณดาวน์โหลดได้โดยการแก้ไขค่าของ data_path เป็นครั้งแรกใน example/config/parser/Parse_DSTC2.yaml เพื่อชี้ไปที่เส้นทางไปยังที่ที่คุณดาวน์โหลดและยกเลิกซิปข้อมูล DSTC2 ถัดไปคุณสามารถเรียกใช้สคริปต์แยกวิเคราะห์ได้ดังนี้:
plato parse --config Parse_DSTC2.yaml
หรือคุณสามารถเขียนไฟล์กำหนดค่าของคุณเองและส่งที่อยู่สัมบูรณ์ไปยังไฟล์นั้นไปยังคำสั่ง:
plato parse --config <absolute pass to parse config file>
การเรียกใช้คำสั่งนี้จะเรียกใช้สคริปต์การแยกวิเคราะห์สำหรับ DSTC2 (ซึ่งอยู่ภายใต้ plato/utilities/parser/parse_dstc2.py ) และจะสร้างข้อมูลการฝึกอบรมสำหรับตัวติดตามสถานะการโต้ตอบ NLU และ NLG สำหรับทั้งผู้ใช้และระบบภายใต้ไดเรกทอรี data ตอนนี้ข้อมูลที่แยกวิเคราะห์นี้สามารถใช้ในการฝึกอบรมโมเดลสำหรับส่วนประกอบต่าง ๆ ของเพลโต
มีหลายวิธีในการฝึกอบรมแต่ละองค์ประกอบของตัวแทนเพลโต: ออนไลน์ (เป็นตัวแทนโต้ตอบกับตัวแทนอื่น ๆ เครื่องจำลองหรือผู้ใช้) หรือออฟไลน์ นอกจากนี้คุณสามารถใช้อัลกอริทึมที่ใช้ใน Plato หรือคุณสามารถใช้เฟรมเวิร์กภายนอกเช่น Tensorflow, Pytorch, Keras, Ludwig ฯลฯ
Ludwig เป็นกรอบการเรียนรู้ที่ลึกล้ำของโอเพ่นซอร์สที่ช่วยให้คุณฝึกอบรมโมเดลโดยไม่ต้องเขียนรหัสใด ๆ คุณจะต้องแยกวิเคราะห์ข้อมูลของคุณเป็นไฟล์ .csv สร้างการกำหนดค่า Ludwig (ใน Yaml) ซึ่งอธิบายถึงสถาปัตยกรรมที่คุณต้องการซึ่งคุณสมบัติที่จะใช้จาก. csv และพารามิเตอร์อื่น ๆ จากนั้นเพียงเรียกใช้คำสั่งในเทอร์มินัล
ลุดวิกยังให้ API ซึ่งเพลโตนั้นเข้ากันได้กับ สิ่งนี้ช่วยให้เพลโตสามารถรวมเข้ากับรุ่นลุดวิกได้เช่นโหลดหรือบันทึกรุ่นฝึกอบรมและสอบถามพวกเขา
ในส่วนก่อนหน้าตัวแยกวิเคราะห์ DSTC2 ของเพลโตสร้างไฟล์ .csv บางไฟล์ที่สามารถใช้ในการฝึกอบรม NLU และ NLG มีไฟล์ NLU .csv หนึ่งไฟล์สำหรับระบบ ( data/DSTC2_NLU_sys.csv ) และอีกอันสำหรับผู้ใช้ ( data/DSTC2_NLU_usr.csv ) ดูเหมือนว่า:
| การถอดเสียง | ความตั้งใจ | IOB |
|---|---|---|
| ร้านอาหารราคาแพงที่ให้บริการอาหารมังสวิรัติ | แจ้ง | b-inform-pricerange ooo b-inform-food o |
| อาหารมังสวิรัติ | แจ้ง | b-inform-food o |
| อาหารโอเรียนเต็ลเอเชีย | แจ้ง | b-inform-food i-inform-food ooo |
| ร้านอาหารราคาแพงเอเชีย | แจ้ง | b-inform-pricerange ooo |
สำหรับการฝึกอบรมโมเดล NLU คุณต้องเขียนไฟล์กำหนดค่าที่มีลักษณะเช่นนี้:
input_features:
-
name: transcript
type: sequence
reduce_output: null
encoder: parallel_cnn
output_features:
-
name: intent
type: set
reduce_output: null
-
name: iob
type: sequence
decoder: tagger
dependencies: [intent]
reduce_output: null
training:
epochs: 100
early_stop: 50
learning_rate: 0.0025
dropout: 0.5
batch_size: 128
ตัวอย่างของไฟล์กำหนดค่านี้มีอยู่ใน example/config/ludwig/ludwig_nlu_train.yaml งานฝึกอบรมอาจเริ่มต้นด้วยการวิ่ง:
ludwig experiment
--model_definition_file example/config/ludwig/ludwig_nlu_train.yaml
--data_csv data/DSTC2_NLU_sys.csv
--output_directory models/camrest_nlu/sys/
ขั้นตอนต่อไปคือการโหลดโมเดลในการกำหนดค่าแอปพลิเคชัน ใน example/config/application/CamRest_model_nlu.yaml เรามีการกำหนดค่าแอปพลิเคชันที่มี NLU ที่ใช้โมเดลและส่วนประกอบอื่น ๆ นั้นไม่ได้ใช้ ML โดยการอัปเดตพา ธ ไปยังโหมด ( model_path ) เป็นค่าที่คุณให้ไว้กับอาร์กิวเมนต์ --output_directory เมื่อคุณวิ่ง LUDWIG คุณสามารถระบุโมเดล NLU ที่ตัวแทนต้องการใช้สำหรับ NLU:
...
MODULE_0:
package: applications.cambridge_restaurants.camrest_nlu
class: CamRestNLU
arguments:
model_path: <PATH_TO_YOUR_MODEL>/model
...
และทดสอบว่าโมเดลใช้งานได้:
plato run --config CamRest_model_nlu.yaml
ตัวแยกวิเคราะห์ข้อมูล DSTC2 สร้างไฟล์ .csv สองไฟล์ที่เราสามารถใช้สำหรับ DST: DST_sys.csv และ DST_usr.csv ซึ่งมีลักษณะเช่นนี้:
| dst_prev_food | dst_prev_area | dst_prev_pricerange | nlu_intent | req_slot | inf_area_value | inf_food_value | inf_pricerange_value | dst_food | dst_area | dst_pricerange | dst_req_slot |
|---|---|---|---|---|---|---|---|---|---|---|---|
| ไม่มี | ไม่มี | ไม่มี | แจ้ง | ไม่มี | ไม่มี | มังสวิรัติ | แพง | มังสวิรัติ | ไม่มี | แพง | ไม่มี |
| มังสวิรัติ | ไม่มี | แพง | แจ้ง | ไม่มี | ไม่มี | มังสวิรัติ | ไม่มี | มังสวิรัติ | ไม่มี | แพง | ไม่มี |
| มังสวิรัติ | ไม่มี | แพง | แจ้ง | ไม่มี | ไม่มี | โอเรียนเต็ลเอเชีย | ไม่มี | โอเรียนเต็ลเอเชีย | ไม่มี | แพง | ไม่มี |
| โอเรียนเต็ลเอเชีย | ไม่มี | แพง | แจ้ง | ไม่มี | ไม่มี | โอเรียนเต็ลเอเชีย | แพง | โอเรียนเต็ลเอเชีย | ไม่มี | แพง | ไม่มี |
โดยพื้นฐานแล้วตัวแยกวิเคราะห์จะติดตามสถานะการสนทนาก่อนหน้าอินพุตจาก NLU และสถานะการสนทนาที่เกิดขึ้น จากนั้นเราสามารถป้อนสิ่งนี้ลงในลุดวิกเพื่อฝึกฝนผู้ติดตามบทสนทนา นี่คือการกำหนดค่า ludwig ซึ่งสามารถพบได้ที่ example/config/ludwig/ludwig_dst_train.yaml :
input_features:
-
name: dst_prev_food
type: category
-
name: dst_prev_area
type: category
-
name: dst_prev_pricerange
type: category
-
name: dst_intent
type: category
-
name: dst_slot
type: category
-
name: dst_value
type: category
output_features:
-
name: dst_food
type: category
-
name: dst_area
type: category
-
name: dst_pricerange
type: category
-
name: dst_req_slot
type: category
training:
epochs: 100
ตอนนี้เราจำเป็นต้องฝึกอบรมแบบจำลองของเราด้วย Ludwig:
ludwig experiment
--model_definition_file example/config/ludwig/ludwig_dst_train.yaml
--data_csv data/DST_sys.csv
--output_directory models/camrest_dst/sys/
และเรียกใช้ตัวแทนเพลโตด้วย DST ที่ใช้โมเดล:
plato run --config CamRest_model_dst.yaml
คุณสามารถทดลองกับสถาปัตยกรรมและพารามิเตอร์การฝึกอบรมอื่น ๆ ได้แน่นอน
จนถึงตอนนี้เราได้เห็นวิธีการฝึกอบรมส่วนประกอบของตัวแทนเพลโตโดยใช้เฟรมเวิร์กภายนอก (เช่นลุดวิก) ในส่วนนี้เราจะเห็นวิธีการใช้อัลกอริทึมภายในของ Plato เพื่อฝึกอบรมนโยบายการสนทนาออฟไลน์โดยใช้การเรียนรู้ภายใต้การดูแลและออนไลน์โดยใช้การเรียนรู้การเสริมแรง
นอกเหนือจากไฟล์ .csv แล้วตัวแยกวิเคราะห์ DSTC2 ยังใช้เครื่องบันทึกบทสนทนาของ Plato เพื่อบันทึกบทสนทนาที่แยกวิเคราะห์ในบันทึกประสบการณ์เพลโตที่นี่: logs/DSTC2_system และ logs/DSTC2_user บันทึกเหล่านี้มีข้อมูลเกี่ยวกับบทสนทนาแต่ละครั้งตัวอย่างเช่นสถานะการสนทนาปัจจุบันการดำเนินการ, สถานะการสนทนาถัดไป, รางวัลที่สังเกต, คำพูดอินพุต, ความสำเร็จ ฯลฯ บันทึกเหล่านี้สามารถโหลดลงในตัวแทนสนทนาโดยตรงและสามารถใช้เพื่อเติมเต็มกลุ่มประสบการณ์
สิ่งที่คุณต้องทำคือเขียนไฟล์กำหนดค่าที่โหลดบันทึกเหล่านี้ ( example/config/CamRest_model_supervised_policy_train.yaml ):
GENERAL:
...
experience_logs:
save: False
load: True
path: logs/DSTC2_system
...
DIALOGUE:
# Since this configuration file trains a supervised policy from data loaded
# from the logs, we only really need one dialogue just to trigger the train.
num_dialogues: 1
initiative: system
domain: CamRest
AGENT_0:
role: system
max_turns: 15
train_interval: 1
train_epochs: 100
save_interval: 1
...
DM:
package: plato.agent.component.dialogue_manager.dialogue_manager_generic
class: DialogueManagerGeneric
arguments:
DST:
package: plato.agent.component.dialogue_state_tracker.slot_filling_dst
class: SlotFillingDST
policy:
package: plato.agent.component.dialogue_policy.deep_learning.supervised_policy
class: SupervisedPolicy
arguments:
train: True
learning_rate: 0.9
exploration_rate: 0.995
discount_factor: 0.95
learning_decay_rate: 0.95
exploration_decay_rate: 0.995
policy_path: models/camrest_policy/sys/sys_supervised_data
...
โปรดทราบว่าเราเรียกใช้เอเจนต์นี้สำหรับบทสนทนาเดียวเท่านั้น แต่ฝึกฝนสำหรับ 100 ยุคโดยใช้ประสบการณ์ที่โหลดจากบันทึก:
plato run --config CamRest_model_supervised_policy_train.yaml
หลังจากการฝึกอบรมเสร็จสมบูรณ์เราสามารถทดสอบนโยบายภายใต้การดูแลของเรา:
plato run --config CamRest_model_supervised_policy_test.yaml
ในส่วนก่อนหน้านี้เราเห็นวิธีการฝึกอบรมนโยบายการสนทนาภายใต้การดูแล ตอนนี้เราสามารถดูได้ว่าเราสามารถฝึกอบรมนโยบายการเรียนรู้เสริมแรงได้อย่างไรโดยใช้อัลกอริทึมเสริมกำลัง ในการทำเช่นนี้เรากำหนดคลาสที่เกี่ยวข้องในไฟล์กำหนดค่า:
...
AGENT_0:
role: system
max_turns: 15
train_interval: 500
train_epochs: 3
train_minibatch: 200
save_interval: 5000
...
DM:
package: plato.agent.component.dialogue_manager.dialogue_manager_generic
class: DialogueManagerGeneric
arguments:
DST:
package: plato.agent.component.dialogue_state_tracker.slot_filling_dst
class: SlotFillingDST
policy:
package: plato.agent.component.dialogue_policy.deep_learning.reinforce_policy
class: ReinforcePolicy
arguments:
train: True
learning_rate: 0.9
exploration_rate: 0.995
discount_factor: 0.95
learning_decay_rate: 0.95
exploration_decay_rate: 0.995
policy_path: models/camrest_policy/sys/sys_reinforce
...
หมายเหตุพารามิเตอร์การเรียนรู้ภายใต้ AGENT_0 และพารามิเตอร์เฉพาะอัลกอริทึมภายใต้ข้อโต้แย้งของนโยบาย จากนั้นเราเรียกเพลโตด้วยการกำหนดค่านี้:
plato run --config CamRest_model_reinforce_policy_train.yaml
และทดสอบรูปแบบนโยบายที่ผ่านการฝึกอบรม:
plato run --config CamRest_model_reinforce_policy_test.yaml
โปรดทราบ ว่าส่วนประกอบอื่น ๆ สามารถได้รับการฝึกฝนออนไลน์ไม่ว่าจะใช้ API ของ Ludwig หรือโดยใช้อัลกอริทึมการเรียนรู้ในเพลโต
โปรดทราบ ว่าไฟล์บันทึกสามารถโหลดและใช้เป็นกลุ่มประสบการณ์สำหรับส่วนประกอบและอัลกอริทึมการเรียนรู้ใด ๆ อย่างไรก็ตามคุณอาจต้องใช้อัลกอริทึมการเรียนรู้ของคุณเองสำหรับส่วนประกอบเพลโต
ในการฝึกอบรมโมดูล NLG คุณต้องเขียนไฟล์กำหนดค่าที่มีลักษณะเช่นนี้ (เช่น example/config/application/CamRest_model_nlg.yaml ):
---
input_features:
-
name: nlg_input
type: sequence
encoder: rnn
cell_type: lstm
output_features:
-
name: nlg_output
type: sequence
decoder: generator
cell_type: lstm
training:
epochs: 20
learning_rate: 0.001
dropout: 0.2
และฝึกอบรมแบบจำลองของคุณ:
ludwig experiment
--model_definition_file example/config/ludwig/ludwig_nlg_train.yaml
--data_csv data/DSTC2_NLG_sys.csv
--output_directory models/camrest_nlg/sys/
ขั้นตอนต่อไปคือการโหลดโมเดลในเพลโต ไปที่ไฟล์กำหนดค่า CamRest_model_nlg.yaml และอัปเดตเส้นทางหากจำเป็น:
...
NLG:
package: applications.cambridge_restaurants.camrest_nlg
class: CamRestNLG
arguments:
model_path: models/camrest_nlg/sys/experiment_run/model
...
และทดสอบว่าโมเดลใช้งานได้:
plato run --config CamRest_model_nlg.yaml
โปรดจำไว้ว่า Ludwig จะสร้างไดเรกทอรี Experiment_run_i ใหม่ทุกครั้งที่มีการเรียกดังนั้นโปรดตรวจสอบให้แน่ใจว่าคุณเก็บเส้นทางที่ถูกต้องไว้ในการกำหนดค่าของเพลโต
โปรดทราบว่าลุดวิกยังเสนอวิธีการฝึกอบรมแบบจำลองของคุณทางออนไลน์ดังนั้นในทางปฏิบัติคุณต้องเขียนรหัสน้อยมากเพื่อสร้างฝึกอบรมและประเมินองค์ประกอบการเรียนรู้ลึกใหม่ในเพลโต
สำหรับตัวอย่างนี้เราจะใช้ชุดข้อมูล MetalWoz ที่คุณสามารถดาวน์โหลดได้จากที่นี่
เพลโตสนับสนุนแบบจำลองที่ได้รับการฝึกฝนร่วมกันผ่านตัวแทนทั่วไป ที่นี่เราจะเห็นขั้นตอนที่จำเป็นในการสร้างตัวแทนการสนทนา SEQ2SEQ อย่างง่ายตั้งแต่เริ่มต้น การใช้ Metalwoz เป็นตัวอย่างเราต้องทำสิ่งต่อไปนี้:
เนื่องจากเราเป็นเพียงการฝึกอบรมแบบจำลอง SEQ2SEQ อย่างง่าย (ข้อความถึงข้อความ) เราจำเป็นต้องใช้ตัวแยกวิเคราะห์ของเราเพื่อแยกคำพูดของผู้ใช้และระบบ สิ่งเหล่านี้จะถูกบันทึกในไฟล์. csv ที่จะใช้โดย Ludwig ในขั้นตอนที่ 4
สำหรับการใช้งาน Parser Metalwoz อย่างง่ายให้ดู utilities/parser/Parse_MetalWOZ.py
โปรดทราบว่าตัวแยกวิเคราะห์นี้จะแยกวิเคราะห์ไฟล์เดียวเท่านั้น (หนึ่งโดเมน) อย่างไรก็ตามคุณสามารถปรับเปลี่ยนได้อย่างง่ายดายเพื่อให้เหมาะกับความต้องการของคุณ นี่คือตัวอย่างของผลลัพธ์ที่ผลิตโดยตัวแยกวิเคราะห์สำหรับโดเมนการสั่งซื้อพิซซ่า:
| ผู้ใช้ | ระบบ |
|---|---|
| สวัสดี | สวัสดีฉันจะช่วยคุณได้อย่างไร? |
| ฉันต้องการการสั่งซื้อพิซซ่าต้องการความช่วยเหลือ | แน่นอนว่าคุณต้องการเพิ่มอะไรในการสั่งซื้อของคุณ? |
| ฉันต้องการพิซซ่ากับเห็ดเป็ปเปอร์โรนีและท็อปปิ้งเบคอน | น่าเสียดายที่ตำแหน่งนี้อยู่นอกเบคอนที่คุณร้องขอ จะมีท็อปปิ้งที่แตกต่างกันที่คุณต้องการแทนที่ด้วยหรือไม่? |
| วิธีการเกี่ยวกับสับปะรด | ท็อปปิ้งนั้นมีอยู่ ฉันได้เพิ่มพิซซ่าด้วยเห็ดเป็ปเปอร์โรนีและสับปะรดในการสั่งซื้อของคุณ คุณต้องการขนาดไหน? |
| ปานกลาง | เอาล่ะอัปเดต คุณต้องการเพิ่มคำสั่งซื้อเพิ่มเติมหรือไม่? |
| นั่นคือทั้งหมดขอบคุณ | เอาล่ะทั้งหมดของคุณคือ 14.99 พิซซ่าของคุณจะพร้อมสำหรับรถกระบะโดยประมาณ 20 นาที |
หมายเหตุคำพูดของผู้ใช้คนแรกไม่มีอยู่จริงในข้อมูล อย่างไรก็ตามเราต้องการบางสิ่งบางอย่างเพื่อกระตุ้นให้โมเดลสร้างคำทักทายของระบบ - เราอาจใช้ประโยคที่ว่างเปล่าหรือคำทักทายอื่น ๆ (หรือการรวมกันของสิ่งเหล่านี้)
จากนั้นคุณสามารถใช้ Plato Parse ดังนี้:
plato parse --config Parse_MetalWOZ.yaml
ในการเริ่มต้นเราสามารถฝึกอบรมแบบง่าย ๆ โดยใช้ Ludwig (อย่าลังเลที่จะใช้กรอบการเรียนรู้ลึกที่คุณชื่นชอบที่นี่):
input_features:
-
name: user
type: text
level: word
encoder: rnn
cell_type: lstm
reduce_output: null
output_features:
-
name: system
type: text
level: word
decoder: generator
cell_type: lstm
attention: bahdanau
training:
epochs: 100
คุณสามารถแก้ไขการกำหนดค่านี้เพื่อสะท้อนสถาปัตยกรรมที่คุณเลือกและฝึกอบรมโดยใช้ Ludwig:
ludwig train
--data_csv data/metalwoz.csv
--model_definition_file example/config/ludwig/metalWOZ_seq2seq_ludwig.yaml
--output_directory "models/joint_models/"
คลาสนี้จำเป็นต้องจัดการกับการโหลดของโมเดลสอบถามอย่างเหมาะสมและจัดรูปแบบเอาต์พุตอย่างเหมาะสม ในกรณีของเราเราจำเป็นต้องห่อข้อความอินพุตลงในแพนด้า dataframe คว้าโทเค็นที่คาดการณ์ไว้จากเอาต์พุตและเข้าร่วมในสตริงที่จะส่งคืน ดูคลาสที่นี่: plato.agent.component.joint_model.metal_woz_seq2seq.py
ดู example/config/application/metalwoz_generic.yaml สำหรับตัวอย่างไฟล์การกำหนดค่าทั่วไปที่โต้ตอบกับตัวแทน SEQ2SEQ ผ่านข้อความ คุณสามารถลองใช้ดังนี้:
plato run --config metalwoz_text.yaml
อย่าลืม อัปเดตเส้นทางไปยังรูปแบบที่ผ่านการฝึกอบรมของคุณหากจำเป็น! เส้นทางเริ่มต้นจะถือว่าคุณเรียกใช้คำสั่ง Ludwig Train จากไดเรกทอรีรากของเพลโต
หนึ่งในคุณสมบัติหลักของเพลโตช่วยให้ตัวแทนสองคนสามารถโต้ตอบกันได้ ตัวแทนแต่ละคนสามารถมีบทบาทที่แตกต่างกัน (ตัวอย่างเช่นระบบและผู้ใช้) วัตถุประสงค์ที่แตกต่างกันและรับสัญญาณรางวัลที่แตกต่างกัน หากตัวแทนร่วมมือกันบางส่วนสามารถแบ่งปันได้ (เช่นสิ่งที่ถือเป็นบทสนทนาที่ประสบความสำเร็จ)
ในการเรียกใช้ตัวแทนเพลโตหลายตัวในโดเมนร้านอาหารเคมบริดจ์เราใช้คำสั่งต่อไปนี้เพื่อฝึกอบรมนโยบายการสนทนาของตัวแทนและทดสอบพวกเขา:
ขั้นตอนการฝึกอบรม: 2 นโยบาย (1 สำหรับแต่ละตัวแทน) ได้รับการฝึกอบรม นโยบายเหล่านี้ได้รับการฝึกฝนโดยใช้อัลกอริทึม Wolf:
plato run --config MultiAgent_train.yaml
ขั้นตอนการทดสอบ: ใช้นโยบายที่ผ่านการฝึกอบรมในขั้นตอนการฝึกอบรมเพื่อสร้างกล่องโต้ตอบระหว่างตัวแทนสองคน:
plato run --config MultiAgent_test.yaml
ในขณะที่คอนโทรลเลอร์พื้นฐานในปัจจุบันอนุญาตให้มีการโต้ตอบกับเอเจนต์สองตัว แต่ก็ค่อนข้างตรงไปตรงมาที่จะขยายไปยังเอเจนต์หลายตัว (เช่นสถาปัตยกรรมกระดานดำซึ่งตัวแทนแต่ละตัวออกอากาศเอาต์พุตไปยังตัวแทนอื่น ๆ ) สิ่งนี้สามารถรองรับสถานการณ์ต่าง ๆ เช่นบ้านอัจฉริยะซึ่งอุปกรณ์ทุกตัวเป็นตัวแทนการโต้ตอบกับผู้ใช้หลายคนกับบทบาทต่าง ๆ และอื่น ๆ
PLATO ให้การใช้งานสำหรับเครื่องจำลองผู้ใช้สองประเภท หนึ่งคือตัวจำลองผู้ใช้ตามวาระที่รู้จักกันดีและอื่น ๆ เป็นเครื่องจำลองที่พยายามเลียนแบบพฤติกรรมผู้ใช้ที่สังเกตได้ในข้อมูล อย่างไรก็ตามเราสนับสนุนให้นักวิจัยเพียงแค่ฝึกอบรมตัวแทนการสนทนาสองคนด้วยเพลโต (หนึ่งเป็น 'ระบบ' และอีกหนึ่งเป็น 'ผู้ใช้') แทนที่จะใช้ผู้ใช้จำลองเมื่อเป็นไปได้
การจำลองผู้ใช้ตามวาระถูกเสนอโดย Schatzmann และมีการอธิบายอย่างละเอียดในบทความนี้ แนวคิดการจำลองจะรักษา "วาระ" ของสิ่งที่จะพูดซึ่งมักจะนำไปใช้เป็นสแต็ก เมื่อเครื่องจำลองได้รับอินพุตจะปรึกษานโยบาย (หรือชุดของกฎ) เพื่อดูว่าเนื้อหาใดที่จะผลักดันเข้าไปในวาระการประชุมเพื่อตอบสนองต่ออินพุต หลังจากการดูแลทำความสะอาดบางอย่าง (เช่นการลบซ้ำหรือเนื้อหาที่ไม่ถูกต้องอีกต่อไป) ตัวจำลองจะปรากฏรายการหนึ่งรายการขึ้นไปนอกวาระการประชุมที่จะใช้ในการกำหนดการตอบสนอง
ตัวจำลองผู้ใช้ตามวาระยังมีโมดูลการจำลองข้อผิดพลาดซึ่งสามารถจำลองข้อผิดพลาดการรู้จำเสียงพูด / การทำความเข้าใจภาษา ขึ้นอยู่กับความน่าจะเป็นบางอย่างมันจะบิดเบือนการกระทำของบทสนทนาของตัวจำลอง - ความตั้งใจสล็อตหรือค่า (ความน่าจะเป็นที่แตกต่างกันสำหรับแต่ละคน) นี่คือตัวอย่างของรายการทั้งหมดของพารามิเตอร์ที่ตัวจำลองนี้ได้รับ:
patience: 5 # Stop after <patience> consecutive identical inputs received
pop_distribution: [0.8, 0.15, 0.05] # pop 1 act with 0.8 probability, 2 acts with 0.15, etc.
slot_confuse_prob: 0.05 # probability by which the error model will alter the output dact slot
op_confuse_prob: 0.01 # probability by which the error model will alter the output dact operator
value_confuse_prob: 0.01 # probability by which the error model will alter the output dact value
nlu: slot_filling # type of NLU the simulator will use
nlg: slot_filling # type of NLG the simulator will use
เครื่องจำลองนี้ได้รับการออกแบบให้เป็นตัวจำลองตามนโยบายอย่างง่ายซึ่งสามารถทำงานได้ในระดับพระราชบัญญัติการสนทนาหรือในระดับคำพูด เพื่อแสดงให้เห็นว่ามันทำงานอย่างไร DSTC2 Parser ได้สร้างไฟล์นโยบายสำหรับตัวจำลองนี้: user_policy_reactive.pkl (ปฏิกิริยาเพราะมันตอบสนองต่อการสนทนาของระบบแทนสถานะการจำลองผู้ใช้) นี่เป็นพจนานุกรมง่ายๆของ:
System Dial. Act 1 --> {'dacts': {User Dial. Act 1: probability}
{User Dial. Act 2: probability}
...
'responses': {User utterance 1: probability}
{User utterance 2: probability}
...
System Dial. Act 2 --> ...
คีย์แสดงถึงพระราชบัญญัติการสนทนาอินพุต (เช่นมาจากตัวแทนการสนทนา system ) ค่าของแต่ละคีย์คือพจนานุกรมของสององค์ประกอบซึ่งแสดงถึงการแจกแจงความน่าจะเป็นมากกว่าการกระทำการสนทนาหรือเทมเพลตคำพูดที่ตัวจำลองจะสุ่มตัวอย่างจาก
หากต้องการดูตัวอย่างคุณสามารถเรียกใช้การกำหนดค่าต่อไปนี้:
plato run --config CamRest_dtl_simulator.yaml
มีสองวิธีในการสร้างโมดูลใหม่ขึ้นอยู่กับฟังก์ชั่น ตัวอย่างเช่นหากโมดูลใช้วิธีการใหม่ในการดำเนินการตามนโยบาย NLU หรือบทสนทนาคุณควรเขียนคลาสที่สืบทอดมาจากคลาสนามธรรมที่สอดคล้องกัน
อย่างไรก็ตามหากโมดูลไม่พอดีกับหนึ่งในส่วนประกอบพื้นฐานของเอเจนต์เดี่ยวตัวอย่างเช่นมันจะดำเนินการจดจำเอนทิตีที่มีชื่อหรือทำนายการสนทนาที่ทำหน้าที่จากข้อความคุณต้องเขียนคลาสที่สืบทอดมาจาก conversational_module โดยตรง จากนั้นคุณสามารถโหลดโมดูลผ่านตัวแทนทั่วไปได้โดยให้เส้นทางแพ็คเกจที่เหมาะสมชื่อคลาสและอาร์กิวเมนต์ในการกำหนดค่า
...
MODULE_i:
package: my_package.my_module
Class: MyModule
arguments:
model_path: models/my_module/parameters/
...
...
ระวัง! คุณมีความรับผิดชอบในการรับประกันว่า I/O ของโมดูลนี้สามารถประมวลผลและบริโภคได้อย่างเหมาะสมโดยโมดูลก่อนและหลังตามที่ระบุไว้ในไฟล์การกำหนดค่าทั่วไปของคุณ
เพลโตยังรองรับการดำเนินการแบบขนาน (แบบมีเหตุผล) ของโมดูล เพื่อให้คุณต้องมีโครงสร้างต่อไปนี้ในการกำหนดค่าของคุณ:
...
MODULE_i:
parallel_modules: 5
PARALLEL_MODULE_0:
package: my_package.my_module
Class: MyModule
arguments:
model_path: models/myModule/parameters/
...
PARALLEL_MODULE_1:
package: my_package.my_module
Class: MyModule
arguments:
model_path: models/my_module/parameters/
...
...
...
ระวัง! เอาต์พุตจากโมดูลที่ดำเนินการแบบขนานจะถูกบรรจุลงในรายการ โมดูลถัดไป (เช่น MODULE_i+1 ) จะต้องสามารถจัดการอินพุตประเภทนี้ได้ โมดูล PLATO ที่ให้ไว้ไม่ได้ถูกออกแบบมาเพื่อจัดการสิ่งนี้คุณจะต้องเขียนโมดูลที่กำหนดเองเพื่อประมวลผลอินพุตจากหลายแหล่ง
เพลโตได้รับการออกแบบให้สามารถขยายได้ดังนั้นอย่าลังเลที่จะสร้างสถานะการสนทนาของคุณเองการกระทำฟังก์ชั่นรางวัลอัลกอริทึมหรือองค์ประกอบอื่น ๆ เพื่อให้เหมาะกับความต้องการเฉพาะของคุณ คุณจะต้องสืบทอดจากคลาสที่เกี่ยวข้องเพื่อให้แน่ใจว่าการใช้งานของคุณเข้ากันได้กับเพลโต
Plato ใช้ PysimpleGui เพื่อจัดการส่วนต่อประสานผู้ใช้กราฟิก ตัวอย่าง GUI สำหรับ PLATO ถูกนำไปใช้ที่ plato.controller.sgui_controller และคุณสามารถลองใช้คำสั่งต่อไปนี้:
plato gui --config CamRest_GUI_speech.yaml
Special thanks to Mahdi Namazifar, Chandra Khatri, Yi-Chia Wang, Piero Molino, Michael Pearce, Zack Kaden, and Gokhan Tur for their contributions and support, and to studio FF3300 for allowing us to use the Messapia font.
Please understand that many features are still being implemented and some use cases may not be supported yet.
สนุก!


