plato research dialogue system
1.0.0

Esta é a v0.3.1
O sistema de diálogo de pesquisa de Platão é uma estrutura flexível que pode ser usada para criar, treinar e avaliar agentes de IA de conversação em vários ambientes. Ele suporta interações por meio de atos de fala, texto ou diálogo e cada agente de conversação pode interagir com dados, usuários humanos ou outros agentes de conversação (em uma configuração multi-agente). Todo componente de cada agente pode ser treinado independentemente online ou offline e Platão fornece uma maneira fácil de envolver praticamente qualquer modelo existente, desde que a interface de Platão seja aderida.
Citações de publicação:
Alexandros Papangelis, Mahdi Namazifar, Chandra Khatri, Yi-Chia Wang, Piero Molino e Gokhan Tur, "Sistema de diálogo Platão: uma plataforma flexível de pesquisa de IA de conversação", Arxiv Preprint [Artigo]
Alexandros Papangelis, Yi-Chia Wang, Piero Molino e Gokhan Tur, “Treinamento de modelo de diálogo multi-agente colaborativo por meio de aprendizado de reforço”, Sigdial 2019 [Paper]
Platão escreveu vários diálogos entre personagens que discutem sobre um tópico fazendo perguntas. Muitos desses diálogos apresentam Sócrates, incluindo o julgamento de Sócrates. (Sócrates foi absolvido em um novo julgamento realizado em Atenas, Grécia, em 25 de maio de 2012).
v0.2 : A atualização principal da v0.1 é que agora é fornecido o Platão como um pacote. Isso facilita a criação e a manutenção de novos aplicativos de IA de conversação e todos os tutoriais foram atualizados para refletir isso. Platão agora também vem com uma GUI opcional. Aproveitar!
Conceitualmente, um agente de conversação precisa seguir várias etapas para processar as informações que recebe como entrada (por exemplo, "Como está o clima hoje?") E produzir uma saída apropriada ("ventosa, mas não muito fria"). As etapas primárias, que correspondem aos principais componentes de uma arquitetura padrão (veja a Figura 1), são:
Platão foi projetado para ser o mais modular e flexível possível; Ele suporta arquiteturas de IA tradicionais e personalizadas e, principalmente, permitem interações multipartidárias em que vários agentes, potencialmente com diferentes papéis, podem interagir entre si, treinar simultaneamente e resolver problemas distribuídos.
As Figuras 1 e 2, abaixo, representam exemplo de arquiteturas de agentes de conversação em Platão ao interagir com usuários humanos e com usuários simulados, respectivamente. Interagir com usuários simulados é uma prática comum usada na comunidade de pesquisa para iniciar o aprendizado (ou seja, aprender alguns comportamentos básicos antes de interagir com os seres humanos). Cada componente individual pode ser treinado online ou offline usando qualquer biblioteca de aprendizado de máquina (por exemplo, Ludwig, Tensorflow, Pytorch ou suas próprias implementações), pois Platão é uma estrutura universal. Ludwig, a caixa de ferramentas de aprendizado profundo de código aberto da Uber, faz uma boa escolha, pois não requer código de gravação e é totalmente compatível com Platão.
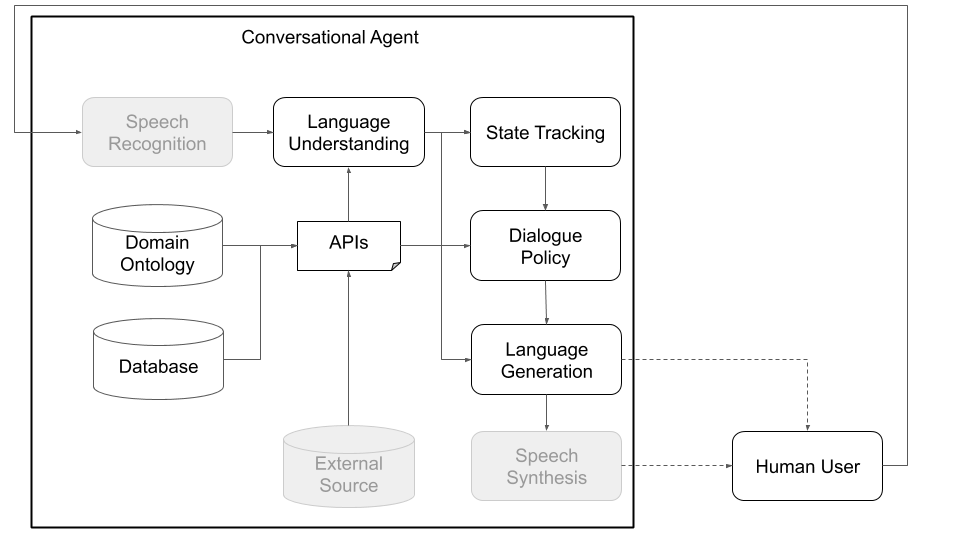 Figura 1: A arquitetura modular de Platão significa que qualquer componente pode ser treinado online ou offline e pode ser substituído por modelos personalizados ou pré-treinados. (Componentes acinzentados neste diagrama não são componentes do Platão.)
Figura 1: A arquitetura modular de Platão significa que qualquer componente pode ser treinado online ou offline e pode ser substituído por modelos personalizados ou pré-treinados. (Componentes acinzentados neste diagrama não são componentes do Platão.)
 Figura 2: Usando um usuário simulado em vez de um usuário humano, como na Figura 1, podemos pré-treinar modelos estatísticos para os vários componentes de Platão. Eles podem ser usados para criar um protótipo de agente de conversação que possa interagir com usuários humanos para coletar dados mais naturais que podem ser usados posteriormente para treinar melhores modelos estatísticos. (Os componentes acinzentados neste diagrama não são componentes do Platão, pois estão disponíveis como pronta para uso, como Google ASR e Amazon LEX, ou domínio e aplicativo específico, como bancos de dados/APIs personalizados.)
Figura 2: Usando um usuário simulado em vez de um usuário humano, como na Figura 1, podemos pré-treinar modelos estatísticos para os vários componentes de Platão. Eles podem ser usados para criar um protótipo de agente de conversação que possa interagir com usuários humanos para coletar dados mais naturais que podem ser usados posteriormente para treinar melhores modelos estatísticos. (Os componentes acinzentados neste diagrama não são componentes do Platão, pois estão disponíveis como pronta para uso, como Google ASR e Amazon LEX, ou domínio e aplicativo específico, como bancos de dados/APIs personalizados.)
Além das interações de agente único, Platão suporta conversas multi-agentes, onde vários agentes de Platão podem interagir e aprender um com o outro. Especificamente, Platão gerará os agentes de conversação, garantirá que as entradas e saídas (o que cada agente ouve e diz) sejam passados para cada agente adequadamente e acompanhe a conversa.
Essa configuração pode facilitar a pesquisa em aprendizado multi-agente, onde os agentes precisam aprender a gerar linguagem para executar uma tarefa, bem como pesquisas em subcampos de interações multipartidárias (rastreamento de estado de diálogo, tomada de curva, etc.). Os princípios de diálogo definem o que cada agente pode entender (uma ontologia de entidades ou significados; por exemplo: preço, localização, preferências, tipos de culinária etc.) e o que ele pode fazer (peça mais informações, forneça algumas informações, ligue para uma API etc.). Os agentes podem se comunicar sobre a fala, o texto ou as informações estruturadas (atos de diálogo) e cada agente tem sua própria configuração. A Figura 3, abaixo, descreve essa arquitetura, descrevendo a comunicação entre dois agentes e os vários componentes:
 Figura 3: A arquitetura de Platão permite o treinamento simultâneo de vários agentes, cada um com papéis e objetivos potencialmente diferentes, e pode facilitar a pesquisa em áreas como interações multipartidárias e aprendizado multi-agente. (Componentes acinzentados neste diagrama não são componentes do Platão.)
Figura 3: A arquitetura de Platão permite o treinamento simultâneo de vários agentes, cada um com papéis e objetivos potencialmente diferentes, e pode facilitar a pesquisa em áreas como interações multipartidárias e aprendizado multi-agente. (Componentes acinzentados neste diagrama não são componentes do Platão.)
Finalmente, Platão suporta arquiteturas personalizadas (por exemplo, dividindo a NLU em vários componentes independentes) e componentes treinados em conjunto (por exemplo, estado de texto para diário, texto em texto ou qualquer outra combinação) através da arquitetura de agentes genéricos mostrada na Figura 4, abaixo. Esse modo se afasta da arquitetura padrão do agente de conversação e suporta qualquer tipo de arquitetura (por exemplo, com componentes conjuntos, componentes de texto em texto ou fala a fala ou qualquer outra configuração) e permite carregar modelos existentes ou pré-treinados em Platão.
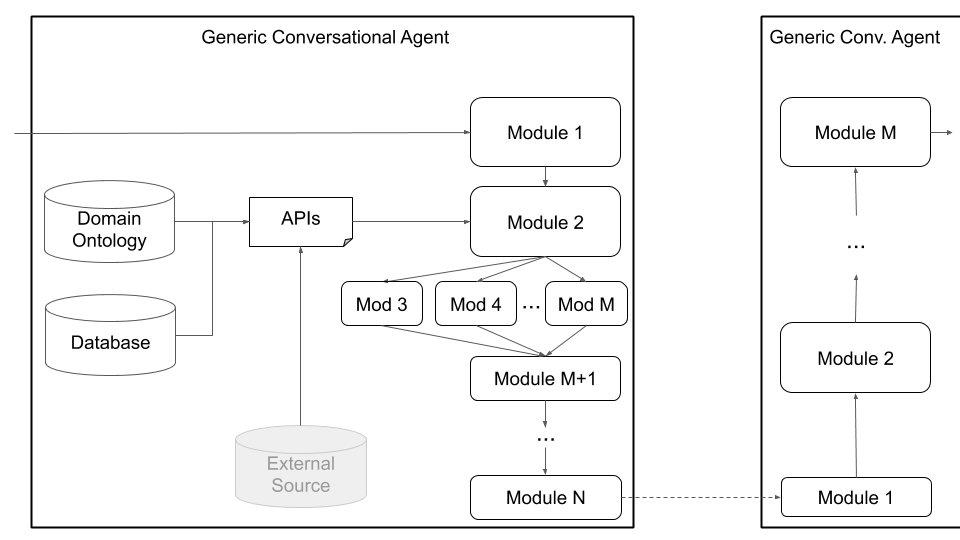 Figura 4: A arquitetura de agentes genéricos de Platão suporta uma ampla gama de personalização, incluindo componentes conjuntos, componentes de fala a fala e componentes de texto em texto, os quais podem ser executados em série ou em paralelo.
Figura 4: A arquitetura de agentes genéricos de Platão suporta uma ampla gama de personalização, incluindo componentes conjuntos, componentes de fala a fala e componentes de texto em texto, os quais podem ser executados em série ou em paralelo.
Os usuários podem definir sua própria arquitetura e/ou conectar seus próprios componentes em Platão, simplesmente fornecendo um nome de classe Python e caminho do pacote para esse módulo, bem como os argumentos de inicialização do modelo. Tudo o que o usuário precisa fazer é listar os módulos na ordem em que devem ser executados e Platão cuida do restante, incluindo envolver a entrada/saída, encadear os módulos e lidar com os diálogos. Platão suporta a execução serial e paralela de módulos.
Platão também fornece suporte à otimização bayesiana de arquiteturas de IA conversacional ou parâmetros individuais do módulo através da otimização bayesiana de estruturas combinatórias (BOCs).
Primeiro, verifique se você tem o Python versão 3.6 ou superior instalado em sua máquina. Em seguida, você precisa clonar o repositório de Platão:
git clone [email protected]:uber-research/plato-research-dialogue-system.git
Em seguida, você precisa instalar alguns pré-requisitos:
Tensorflow:
pip install tensorflow>=1.14.0
Instale a biblioteca de discursos para suporte de áudio:
pip install SpeechRecognition
Para macOS:
brew install portaudio
brew install gmp
pip install pyaudio
Para Ubuntu/Debian:
sudo apt-get install python3-pyaudio
Para Windows: nada é necessário para ser pré-instalado
O próximo passo é instalar Platão. Para instalar o PLATO, você deve instalá -lo diretamente no código -fonte.
A instalação de Platão a partir do código -fonte permite a instalação no modo editável, o que significa que, se você fizer alterações no código -fonte, isso afetará diretamente a execução.
Navegue até o diretório de Platão (onde você clonou o repositório de Platão na etapa anterior).
Recomendamos criar um novo ambiente Python. Para configurar o novo ambiente Python:
2.1 Instale o virtualenv
sudo pip install virtualenv
2.2 Crie um novo ambiente Python:
python3 -m venv </path/to/new/virtual/environment>
2.3 Ative o novo ambiente Python:
source </path/to/new/virtual/environment/bin>/bin/activate
Instale Platão:
pip install -e .
Para apoiar a fala, é necessário instalar o Pyaudio, que possui várias dependências que podem não existir na máquina de um desenvolvedor. Se as etapas acima não tiverem êxito, esta postagem em um erro de instalação do Pyaudio inclui instruções sobre como obter essas dependências e instalar o Pyaudio.
O arquivo CommonIssues.md contém problemas comuns e sua resolução que um usuário pode encontrar durante a instalação.
Para executar Platão após a instalação, você pode simplesmente executar o comando plato no terminal. O comando plato recebe 4 subcomando:
runguidomainparse Cada um desses subcomandos recebe um valor para o argumento --config que aponta para um arquivo de configuração. We will describe these configuration files in detail later in the document but remember that plato run --config and plato gui --config receive an application configuration file (examples could be found here: example/config/application/ ), plato domain --config receives a domain configuration (examples could be found here: example/config/domain/ ), and plato parse --config receives a parser configuration file (examples could ser encontrado aqui: example/config/parser/ ).
Para o valor que é passado para --config Platão primeiro verifica se o valor é o endereço de um arquivo na máquina. Se for, Platão tenta analisar esse arquivo. Caso contrário, Platão verifica se o valor é um nome de um arquivo dentro do diretório example/config/<application, domain, or parser> .
Para alguns exemplos rápidos, tente os seguintes arquivos de configuração para o domínio dos restaurantes de Cambridge:
plato run --config CamRest_user_simulator.yaml
plato run --config CamRest_text.yaml
plato run --config CamRest_speech.yaml
Um aplicativo, ou seja, o sistema de conversação, em Platão, contém três partes principais:
Essas peças são declaradas em um arquivo de configuração do aplicativo. Exemplos desses arquivos de configuração podem ser encontrados no example/config/application/ no restante desta seção, descrevemos cada uma dessas peças em detalhes.
Para implementar um sistema de diálogo orientado a tarefas em Platão, o usuário precisa especificar dois componentes que constituem o domínio do sistema de diálogo:
Platão fornece um comando para automatizar esse processo de construção da ontologia e banco de dados. Digamos, por exemplo, que você deseja construir um agente de conversação para uma loja de flores, e você tem os seguintes itens em um .csv (esse arquivo pode ser encontrado no example/data/flowershop.csv ):
id,type,color,price,occasion
1,rose,red,cheap,any
2,rose,white,cheap,anniversary
3,rose,yellow,cheap,celebration
4,lilly,white,moderate,any
5,orchid,pink,expensive,any
6,dahlia,blue,expensive,any
Para gerar automaticamente um arquivo .db SQL e um arquivo de ontologia .json, você precisa criar um arquivo de configuração de domínio no qual você deve especificar o caminho para o arquivo CSV, os caminhos de saída, além de slots informáveis, solicitáveis e requestáveis do sistema: (EG example/config/domain/create_flowershop_domain.yaml )
GENERAL:
csv_file_name: example/data/flowershop.csv
db_table_name: flowershop
db_file_path: example/domains/flowershop-dbase.db
ontology_file_path: example/domains/flowershop-rules.json
ONTOLOGY: # Optional
informable_slots: [type, price, occasion]
requestable_slots: [price, color]
System_requestable_slots: [type, price, occasion]
e execute o comando:
plato domain --config create_flowershop_domain.yaml
Se tudo correr bem, você deve ter um flowershop.json e um flowershop.db no example/domains/ diretório.
Se você receber este erro:
sqlite3.IntegrityError: UNIQUE constraint failed: flowershop.id
Isso significa que o arquivo .db já foi criado.
Agora você pode simplesmente executar os componentes fictícios de Platão como uma verificação de sanidade e converse com seu agente da loja de flores:
plato run --config flowershop_text.yaml
Controladores são objetos que orquestram a conversa entre os agentes. O controlador instanciará os agentes, inicializará para cada diálogo, passará a entrada e saída adequadamente e acompanhará as estatísticas.
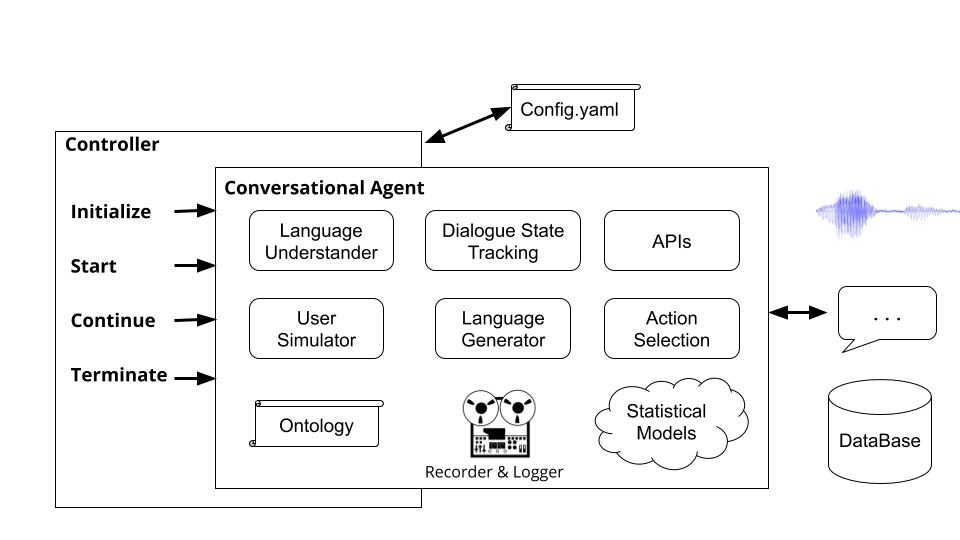
A execução do comando plato run executa o controlador básico de Platão ( plato/controller/basic_controller.py ). Este comando recebe um valor para o argumento --config , que aponta para um arquivo de configuração do aplicativo PLATO.
Para executar um agente de conversação de Platão, o usuário deve executar o seguinte comando com o arquivo de configuração apropriado:
plato run --config <FULL PATH TO CONFIG YAML FILE>
Consulte o example/config/application/ por exemplo, arquivos de configuração que contêm configurações no ambiente e o (s) agente (s) a ser criado, bem como seus componentes. Os exemplos no example/config/application/ podem ser executados diretamente usando apenas o nome do exemplo do arquivo yaml:
plato run --config <NAME OF A FILE FROM example/config/application/>
Como alternativa, um usuário pode escrever seu próprio arquivo de configuração e executar Platão, passando o caminho completo para o arquivo de configuração para --config :
plato run --config <FULL PATH TO CONFIG YAML FILE>
Para o valor que é passado para --config Platão primeiro verifica se o valor é o endereço de um arquivo na máquina. Se for, o Platão tenta analisar esse arquivo. Caso contrário, Platão verifica se o valor é um nome de um arquivo dentro do diretório example/config/application .
Cada aplicativo de IA conversacional em Platão pode ter um ou mais agentes. Cada agente tem uma função (sistema, usuário, ...) e um conjunto de componentes do sistema de diálogo padrão (Figura 1), NLU, gerente de diálogo, rastreador de estado de diálogo, política, NLG e simulador de usuário.
Um agente pode ter um módulo explícito para cada um desses componentes. Como alternativa, alguns desses componentes podem ser combinados em um ou mais módulos (por exemplo, agentes juntas / de ponta a ponta) que podem ser executados sequencialmente ou em paralelo (Figura 4). Os componentes de Platão são definidos em plato.agent.component e todos herdados de plato.agent.component.conversational_module
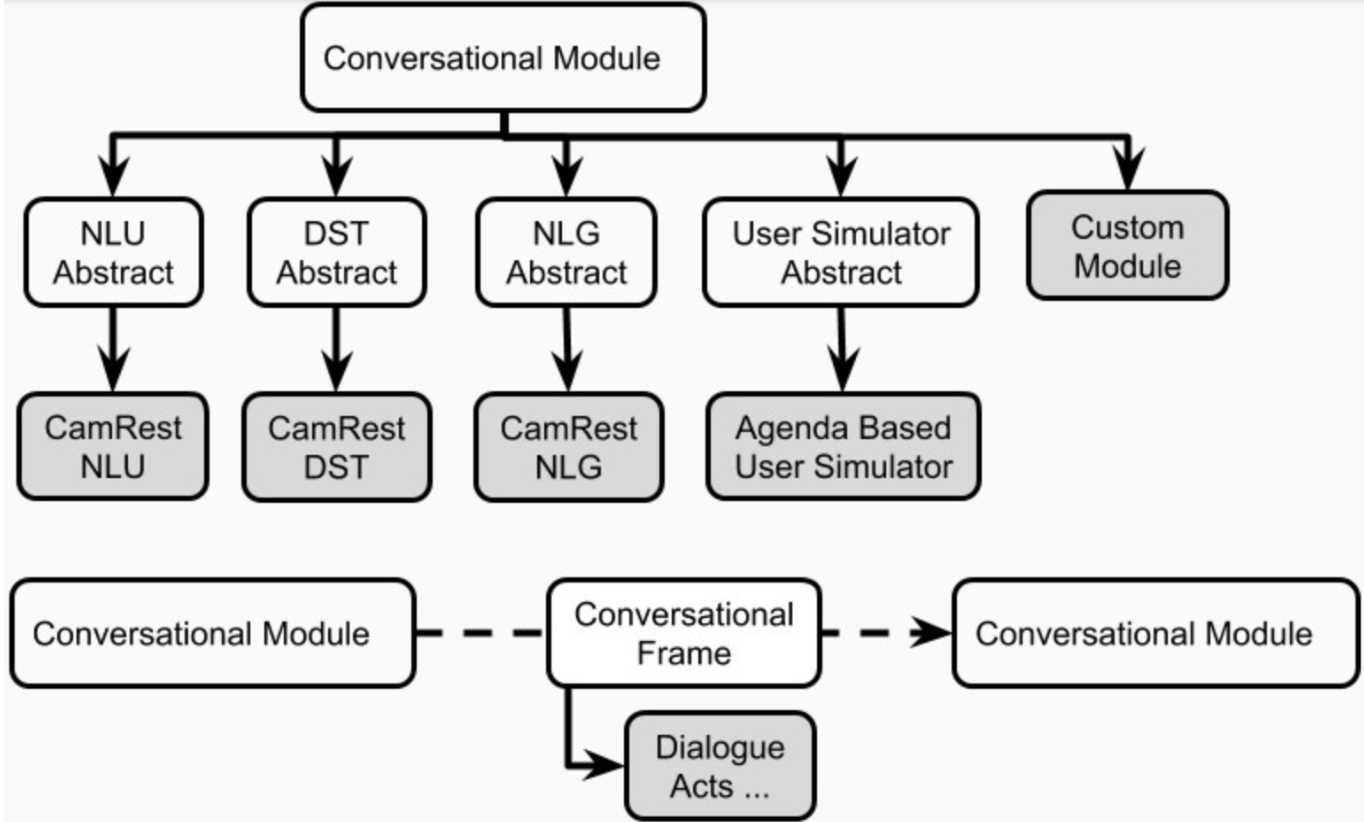 Figura 5. Componentes de agentes de Platão
Figura 5. Componentes de agentes de Platão
Observe que quaisquer novas implementações ou módulos personalizados devem herdar de plato.agent.component.conversational_module .
Cada um desses módulos pode ser baseado em regras ou treinado. Nas subseções a seguir, descreveremos como criar módulos treinados e baseados em regras para os agentes.
Platão fornece versões baseadas em regras de todos os componentes de um agente de conversação de preenchimento de slot (slot_filling_nlu, slot_filling_dst, slot_filling_policy, slot_filling_nlg e a versão padrão do agenda_based_us). Eles podem ser usados para prototipagem rápida, linhas de base ou verificações de sanidade. Especificamente, todos esses componentes seguem regras ou padrões condicionados à ontologia fornecida e às vezes no banco de dados especificados e devem ser tratados como a versão mais básica do que cada componente deve fazer.
Platão suporta o treinamento dos módulos de componentes dos agentes de maneira on -line (durante a interação) ou offline (a partir de dados), usando qualquer estrutura de aprendizado profundo. Praticamente qualquer modelo pode ser carregado em Platão, desde que a entrada/saída da interface de Platão seja respeitada. Por exemplo, se um modelo é um módulo NLU personalizado, ele simplesmente precisa herdar da classe abstrata da NLU de Platão ( plato.agent.component.nlu ) e implementar os métodos abstratos necessários.
To facilitate online learning, debugging, and evaluation, Plato keeps track of its internal experience in a structure called the Dialogue Episode Recorder, ( plato.utilities.dialogue_episode_recorder ) which contains information about previous dialogue states, actions taken, current dialogue states, utterances received and utterances produced, rewards received, and a few other structs including a custom field that can be used to track anything else that cannot be contained by the aforementioned categorias.
No final de um diálogo ou em intervalos especificados, cada agente de conversação chamará a função Train () de cada um de seus componentes internos, passando a experiência de diálogo como dados de treinamento. Cada componente escolhe as peças necessárias para o treinamento.
Para usar os algoritmos de aprendizado que são implementados dentro de Platão, quaisquer dados externos, como dados do DSTC2, devem ser analisados nessa experiência de Platão para que possam ser carregados e usados pelo componente correspondente sob treinamento.
Como alternativa, os usuários podem analisar os dados e treinar seus modelos fora de Platão e simplesmente carregar o modelo treinado quando desejam usá -los para um agente de Platão.
O treinamento on -line é tão fácil quanto virar as bandeiras de 'trem' para 'verdadeiro' na configuração para cada componente que os usuários desejam treinar.
Para treinar a partir de dados, os usuários simplesmente precisam carregar a experiência que analisaram em seu conjunto de dados. Platão fornece analistas de exemplo para conjuntos de dados DSTC2 e Metalwoz. Como exemplo de como usar esses analisadores para treinamento offline em Platão, usaremos o conjunto de dados do DSTC2, que pode ser obtido no site do 2º Diálogo State Rastreamento de Rastreamento de Diálogo:
http://camdial.org/~mh521/dstc/downloads/dstc2_traindev.tar.gz
Após a conclusão do download, você precisa descompactar o arquivo. Um arquivo de configuração para analisar esse conjunto de dados é fornecido no example/config/parser/Parse_DSTC2.yaml . Você pode analisar os dados que você baixou editando primeiro o valor de data_path no example/config/parser/Parse_DSTC2.yaml para apontar para o caminho para onde você baixou e desviou os dados do DSTC2. Em seguida, você pode executar o script parse da seguinte maneira:
plato parse --config Parse_DSTC2.yaml
Como alternativa, você pode escrever seu próprio arquivo de configuração e passar o endereço absoluto para esse arquivo para o comando:
plato parse --config <absolute pass to parse config file>
A execução deste comando executará o script de análise do DSTC2 (que vive em plato/utilities/parser/parse_dstc2.py ) e criará os dados de treinamento para o Rastreador de Estado de Diálogo, NLU e NLG para usuário e sistema no diretório data no diretório raiz deste repositório. Agora, esses dados analisados podem ser usados para treinar modelos para diferentes componentes de Platão.
Existem várias maneiras de treinar cada componente de um agente de Platão: online (como o agente interage com outros agentes, simuladores ou usuários) ou offline. Além disso, você pode usar algoritmos implementados em Platão ou pode usar estruturas externas como Tensorflow, Pytorch, Keras, Ludwig, etc.
Ludwig é uma estrutura de aprendizado profundo de código aberto que permite treinar modelos sem escrever nenhum código. Você só precisa analisar seus dados nos arquivos .csv , criar uma configuração Ludwig (no YAML), que descreve a arquitetura desejada, quais recursos usarem no .csv e em outros parâmetros e, em seguida, simplesmente executar um comando em um terminal.
Ludwig também fornece uma API, com a qual Platão é compatível. Isso permite que Platão se integre aos modelos Ludwig, ou seja, carregue ou salve os modelos, treine e consulte -os.
Na seção anterior, o analisador DSTC2 de Platão gerou alguns arquivos .csv que podem ser usados para treinar NLU e NLG. Existe um arquivo NLU .csv para o sistema ( data/DSTC2_NLU_sys.csv ) e um para o usuário ( data/DSTC2_NLU_usr.csv ). Estes se parecem com o seguinte:
| transcrição | intenção | IOB |
|---|---|---|
| restaurante caro que serve comida vegetariana | informar | B-Inform-Pricerange Ooo B-Inform-Food O |
| comida vegetariana | informar | Bod-in-inform-in-inform o |
| tipo de comida oriental asiática | informar | OOO BOOM DE ENFORMA-INFOL DE FOI-BOOM B OOO |
| Restaurante caro comida asiática | informar | B-Inform-Pricerange Ooo |
Para treinar um modelo NLU, você precisa escrever um arquivo de configuração que se parece com o seguinte:
input_features:
-
name: transcript
type: sequence
reduce_output: null
encoder: parallel_cnn
output_features:
-
name: intent
type: set
reduce_output: null
-
name: iob
type: sequence
decoder: tagger
dependencies: [intent]
reduce_output: null
training:
epochs: 100
early_stop: 50
learning_rate: 0.0025
dropout: 0.5
batch_size: 128
Existe um exemplo deste arquivo de configuração no example/config/ludwig/ludwig_nlu_train.yaml . O trabalho de treinamento pode ser iniciado executando:
ludwig experiment
--model_definition_file example/config/ludwig/ludwig_nlu_train.yaml
--data_csv data/DSTC2_NLU_sys.csv
--output_directory models/camrest_nlu/sys/
A próxima etapa é carregar o modelo em uma configuração de aplicativo. No example/config/application/CamRest_model_nlu.yaml fornecemos uma configuração de aplicativo que possui uma NLU baseada em modelo e os outros componentes não são baseados em ML. Ao atualizar o caminho para o modo ( model_path ) para o valor que você forneceu ao argumento --output_directory quando você executou Ludwig, você pode especificar o modelo NLU que o agente precisa usar para a NLU:
...
MODULE_0:
package: applications.cambridge_restaurants.camrest_nlu
class: CamRestNLU
arguments:
model_path: <PATH_TO_YOUR_MODEL>/model
...
e teste que o modelo funciona:
plato run --config CamRest_model_nlu.yaml
O analisador de dados do DSTC2 gerou dois arquivos .csv que podemos usar para o dst: DST_sys.csv e DST_usr.csv que se parecem com o seguinte:
| dst_prev_food | dst_prev_area | dst_prev_pricerange | NLU_Intent | req_slot | inf_area_value | inf_food_value | inf_pricerange_value | dst_food | dst_area | dst_pricerange | dst_req_slot |
|---|---|---|---|---|---|---|---|---|---|---|---|
| nenhum | nenhum | nenhum | informar | nenhum | nenhum | vegetariano | caro | vegetariano | nenhum | caro | nenhum |
| vegetariano | nenhum | caro | informar | nenhum | nenhum | vegetariano | nenhum | vegetariano | nenhum | caro | nenhum |
| vegetariano | nenhum | caro | informar | nenhum | nenhum | Oriental asiático | nenhum | Oriental asiático | nenhum | caro | nenhum |
| Oriental asiático | nenhum | caro | informar | nenhum | nenhum | Oriental asiático | caro | Oriental asiático | nenhum | caro | nenhum |
Essencialmente, o analisador acompanha o estado de diálogo anterior, a entrada da NLU e o estado de diálogo resultante. Podemos então alimentar isso em Ludwig para treinar um rastreador de estado de diálogo. Aqui está a configuração Ludwig que também pode ser encontrada no example/config/ludwig/ludwig_dst_train.yaml :
input_features:
-
name: dst_prev_food
type: category
-
name: dst_prev_area
type: category
-
name: dst_prev_pricerange
type: category
-
name: dst_intent
type: category
-
name: dst_slot
type: category
-
name: dst_value
type: category
output_features:
-
name: dst_food
type: category
-
name: dst_area
type: category
-
name: dst_pricerange
type: category
-
name: dst_req_slot
type: category
training:
epochs: 100
Agora precisamos treinar nosso modelo com Ludwig:
ludwig experiment
--model_definition_file example/config/ludwig/ludwig_dst_train.yaml
--data_csv data/DST_sys.csv
--output_directory models/camrest_dst/sys/
e execute um agente de Platão com o DST baseado em modelo:
plato run --config CamRest_model_dst.yaml
É claro que você pode experimentar outras arquiteturas e parâmetros de treinamento.
Até agora, vimos como treinar componentes de agentes de Platão usando estruturas externas (por exemplo, Ludwig). Nesta seção, veremos como usar os algoritmos internos de Platão para treinar uma política de diálogo offline, usar aprendizado supervisionado e online, usando o aprendizado de reforço.
Além dos arquivos .csv , o analisador do DSTC2 usou o gravador de episódios de diálogo de Platão para também salvar os diálogos analisados nos registros de experiência de Platão aqui: logs/DSTC2_system e logs/DSTC2_user . Esses logs contêm informações sobre cada diálogo, por exemplo, estado de diálogo atual, ação tomada, próximo estado de diálogo, recompensa observada, expressão de entrada, sucesso etc. Esses logs podem ser carregados diretamente em um agente de conversação e podem ser usados para preencher o pool de experiências.
Tudo o que você precisa fazer é escrever um arquivo de configuração que carregue esses logs ( example/config/CamRest_model_supervised_policy_train.yaml ):
GENERAL:
...
experience_logs:
save: False
load: True
path: logs/DSTC2_system
...
DIALOGUE:
# Since this configuration file trains a supervised policy from data loaded
# from the logs, we only really need one dialogue just to trigger the train.
num_dialogues: 1
initiative: system
domain: CamRest
AGENT_0:
role: system
max_turns: 15
train_interval: 1
train_epochs: 100
save_interval: 1
...
DM:
package: plato.agent.component.dialogue_manager.dialogue_manager_generic
class: DialogueManagerGeneric
arguments:
DST:
package: plato.agent.component.dialogue_state_tracker.slot_filling_dst
class: SlotFillingDST
policy:
package: plato.agent.component.dialogue_policy.deep_learning.supervised_policy
class: SupervisedPolicy
arguments:
train: True
learning_rate: 0.9
exploration_rate: 0.995
discount_factor: 0.95
learning_decay_rate: 0.95
exploration_decay_rate: 0.995
policy_path: models/camrest_policy/sys/sys_supervised_data
...
Observe que executamos apenas esse agente para um diálogo, mas treinamos para 100 épocas, usando a experiência que é carregada dos logs:
plato run --config CamRest_model_supervised_policy_train.yaml
Após a conclusão do treinamento, podemos testar nossa política supervisionada:
plato run --config CamRest_model_supervised_policy_test.yaml
Na seção anterior, vimos como treinar uma política de diálogo supervisionada. Agora podemos ver como podemos treinar uma política de aprendizado de reforço, usando o algoritmo de reforço. Para fazer isso, definimos a classe relevante no arquivo de configuração:
...
AGENT_0:
role: system
max_turns: 15
train_interval: 500
train_epochs: 3
train_minibatch: 200
save_interval: 5000
...
DM:
package: plato.agent.component.dialogue_manager.dialogue_manager_generic
class: DialogueManagerGeneric
arguments:
DST:
package: plato.agent.component.dialogue_state_tracker.slot_filling_dst
class: SlotFillingDST
policy:
package: plato.agent.component.dialogue_policy.deep_learning.reinforce_policy
class: ReinforcePolicy
arguments:
train: True
learning_rate: 0.9
exploration_rate: 0.995
discount_factor: 0.95
learning_decay_rate: 0.95
exploration_decay_rate: 0.995
policy_path: models/camrest_policy/sys/sys_reinforce
...
Observe os parâmetros de aprendizagem em AGENT_0 e os parâmetros específicos de algorítmicos sob os argumentos da política. Em seguida, chamamos Platão com esta configuração:
plato run --config CamRest_model_reinforce_policy_train.yaml
e testar o modelo de política treinado:
plato run --config CamRest_model_reinforce_policy_test.yaml
Observe que outros componentes também podem ser treinados on -line, usando a API de Ludwig ou implementando os algoritmos de aprendizado em Platão.
Observe também que os arquivos de log podem ser carregados e usados como pool de experiência para qualquer componente e algoritmo de aprendizado. No entanto, pode ser necessário implementar seus próprios algoritmos de aprendizado para alguns componentes de Platão.
Para treinar um módulo NLG, você precisa gravar um arquivo de configuração que se parece com este (por example/config/application/CamRest_model_nlg.yaml ):
---
input_features:
-
name: nlg_input
type: sequence
encoder: rnn
cell_type: lstm
output_features:
-
name: nlg_output
type: sequence
decoder: generator
cell_type: lstm
training:
epochs: 20
learning_rate: 0.001
dropout: 0.2
E treine seu modelo:
ludwig experiment
--model_definition_file example/config/ludwig/ludwig_nlg_train.yaml
--data_csv data/DSTC2_NLG_sys.csv
--output_directory models/camrest_nlg/sys/
O próximo passo é carregar o modelo em Platão. Vá para o arquivo de configuração CamRest_model_nlg.yaml e atualize o caminho, se necessário:
...
NLG:
package: applications.cambridge_restaurants.camrest_nlg
class: CamRestNLG
arguments:
model_path: models/camrest_nlg/sys/experiment_run/model
...
e teste que o modelo funciona:
plato run --config CamRest_model_nlg.yaml
Lembre -se de que o Ludwig criará um novo diretório experimental_run_i cada vez que for chamado, portanto, mantenha o caminho correto na configuração de Platão atualizada.
Observe que Ludwig também oferece um método para treinar seu modelo on -line; portanto, na prática, você precisa escrever muito pouco código para construir, treinar e avaliar um novo componente de aprendizado profundo em Platão.
Para este exemplo, usaremos o conjunto de dados Metalwoz que você pode baixar aqui.
Platão suporta modelos treinados em conjunto através de agentes genéricos. Aqui, veremos as etapas necessárias para criar um agente de conversação Seq2SEQ simples do zero. Usando o Metalwoz como exemplo, precisamos fazer o seguinte:
Como estamos treinando apenas um modelo simples seq2seq (texto em texto), precisamos do nosso analisador para extrair enunciados do usuário e do sistema. Estes serão salvos em arquivos .csv que serão usados pelo Ludwig na etapa 4.
Para uma simples implementação de um analisador de metalwoz, consulte utilities/parser/Parse_MetalWOZ.py
Observe que este analisador analisará apenas um único arquivo (um domínio). Você pode modificá -lo facilmente, no entanto, para atender às suas necessidades. Aqui está uma amostra da saída produzida pelo analisador para o domínio de pedidos de pizza:
| usuário | sistema |
|---|---|
| oi | Olá, como posso ajudá -lo? |
| Eu preciso fazer um pedido para uma pizza precisa de ajuda | Certamente, o que você gostaria de adicionar ao seu pedido? |
| Eu quero uma pizza com cogumelos, pepperoni e coberturas de bacon | Infelizmente, esse local está fora da cobertura de bacon que você solicitou. Haveria uma cobertura diferente que você gostaria de substituí -lo? |
| Que tal abacaxi | Essa cobertura está disponível. Adicionei uma pizza com cogumelos, pepperoni e abacaxi no seu pedido. Que tamanho você gostaria? |
| Médio | Tudo bem, atualizado. Você gostaria de adicionar mais ao seu pedido? |
| É só isso, obrigado | Tudo bem, seu total é de 14,99. Sua pizza estará pronta para a coleta em aprox. 20 minutos. |
Observe que o primeiro enunciado do usuário não existe na verdade nos dados. No entanto, precisamos de algo para solicitar o modelo para produzir a saudação do sistema - poderíamos ter usado uma frase vazia ou qualquer outra saudação (ou uma combinação dessas).
Você pode então executar Platão analisar da seguinte maneira:
plato parse --config Parse_MetalWOZ.yaml
Para começar, podemos treinar um modelo muito simples usando Ludwig (sinta -se à vontade para usar sua estrutura de aprendizado profundo favorito aqui):
input_features:
-
name: user
type: text
level: word
encoder: rnn
cell_type: lstm
reduce_output: null
output_features:
-
name: system
type: text
level: word
decoder: generator
cell_type: lstm
attention: bahdanau
training:
epochs: 100
Você pode modificar esta configuração para refletir a arquitetura de sua escolha e treinar usando Ludwig:
ludwig train
--data_csv data/metalwoz.csv
--model_definition_file example/config/ludwig/metalWOZ_seq2seq_ludwig.yaml
--output_directory "models/joint_models/"
Essa classe simplesmente precisa lidar com o carregamento do modelo, consultando -o adequadamente e formatando sua saída adequadamente. No nosso caso, precisamos envolver o texto de entrada em um quadro de dados de pandas, pegar os tokens previstos da saída e junte -se a eles em uma string que será retornada. Veja a classe aqui: plato.agent.component.joint_model.metal_woz_seq2seq.py
Consulte example/config/application/metalwoz_generic.yaml Para um exemplo de arquivo de configuração genérica que interage com o agente SEQ2SEQ sobre o texto. Você pode experimentar o seguinte:
plato run --config metalwoz_text.yaml
Lembre -se de atualizar o caminho para o seu modelo treinado, se necessário! O caminho padrão pressupõe que você execute o comando Ludwig Train no diretório raiz de Platão.
Um dos principais recursos de Platão permite que dois agentes interajam entre si. Cada agente pode ter uma função diferente (por exemplo, sistema e usuário), objetivos diferentes e receber sinais de recompensa diferentes. Se os agentes estão cooperando, alguns deles podem ser compartilhados (por exemplo, o que constitui um diálogo bem -sucedido).
Para executar vários agentes de Platão no domínio dos restaurantes de Cambridge, executamos os seguintes comandos para treinar as políticas de diálogo dos agentes e testá -los:
Fase de treinamento: 2 políticas (1 para cada agente) são treinadas. Essas políticas são treinadas usando o algoritmo Wolf:
plato run --config MultiAgent_train.yaml
Fase de teste: usa a política treinada na fase de treinamento para criar diálogos entre dois agentes:
plato run --config MultiAgent_test.yaml
Embora o controlador básico permita atualmente dois agentes, é bastante direto estendê -lo a vários agentes (por exemplo, com uma arquitetura do quadro -negro, onde cada agente transmite sua saída para outros agentes). Isso pode suportar cenários como casas inteligentes, onde cada dispositivo é um agente, interações com vários usuários com várias funções e muito mais.
Platão fornece implementações para dois tipos de simuladores de usuário. Um é o simulador de usuário baseado em agenda muito conhecido, e o outro é um simulador que tenta imitar o comportamento do usuário observado nos dados. No entanto, incentivamos os pesquisadores a simplesmente treinar dois agentes de conversação com Platão (um sendo um 'sistema' e outro sendo um 'usuário') em vez de usar usuários simulados, quando possível.
O simulador de usuário baseado na agenda foi proposto por Schatzmann e é explicado em detalhes neste artigo. Conceitualmente, o simulador mantém uma "agenda" das coisas a dizer, que geralmente é implementada como uma pilha. Quando o simulador recebe entrada, ele consulta sua política (ou seu conjunto de regras) para ver qual conteúdo entrar na agenda, como uma resposta à entrada. Após algumas tarefas domésticas (por exemplo, removendo duplicatas ou conteúdo que não é mais válido), o simulador exibirá um ou mais itens da agenda que serão usados para formular sua resposta.
O simulador de usuário baseado em agenda também possui um módulo de simulação de erros, que pode simular erros de reconhecimento de fala / entendimento do idioma. Com base em algumas probabilidades, ele distorcerá os atos de diálogo de saída do simulador - a intenção, slot ou valor (probabilidade diferente para cada um). Aqui está um exemplo da lista completa de parâmetros que este simulador recebe:
patience: 5 # Stop after <patience> consecutive identical inputs received
pop_distribution: [0.8, 0.15, 0.05] # pop 1 act with 0.8 probability, 2 acts with 0.15, etc.
slot_confuse_prob: 0.05 # probability by which the error model will alter the output dact slot
op_confuse_prob: 0.01 # probability by which the error model will alter the output dact operator
value_confuse_prob: 0.01 # probability by which the error model will alter the output dact value
nlu: slot_filling # type of NLU the simulator will use
nlg: slot_filling # type of NLG the simulator will use
Este simulador foi projetado para ser um simulador simples baseado em políticas, que pode operar no nível da Lei de Diálogo ou no nível de enunciado. Para demonstrar como funciona, o analisador DSTC2 criou um arquivo de política para este simulador: user_policy_reactive.pkl (reativo porque reage ao diálogo do sistema age em vez do estado do simulador de usuário). Este é realmente um dicionário simples de:
System Dial. Act 1 --> {'dacts': {User Dial. Act 1: probability}
{User Dial. Act 2: probability}
...
'responses': {User utterance 1: probability}
{User utterance 2: probability}
...
System Dial. Act 2 --> ...
A chave representa a Lei de Diálogo de Entrada (por exemplo, proveniente do agente de conversação system ). O valor de cada chave é um dicionário de dois elementos, representando distribuições de probabilidade sobre atos de diálogo ou modelos de enunciado de que o simulador provará.
Para ver um exemplo, você pode executar a seguinte configuração:
plato run --config CamRest_dtl_simulator.yaml
Existem duas maneiras de criar um novo módulo, dependendo de sua função. Se um módulo, por exemplo, implementar uma nova maneira de executar a política de NLU ou diálogo, você deve escrever uma classe que herda da classe abstrata correspondente.
Se, no entanto, um módulo não se encaixar em um dos componentes básicos do agente único, por exemplo, ele executa o reconhecimento de entidade nomeado ou prevê o diálogo atua do texto, você deve escrever uma classe que herda diretamente o conversational_module . Em seguida, você pode carregar o módulo por meio de um agente genérico, fornecendo o caminho de pacote apropriado, o nome da classe e os argumentos na configuração.
...
MODULE_i:
package: my_package.my_module
Class: MyModule
arguments:
model_path: models/my_module/parameters/
...
...
Tome cuidado! Você é responsável por garantir que a E/S deste módulo possa ser processada e consumida adequadamente por módulos antes e depois, conforme fornecido no seu arquivo de configuração genérica.
Platão também suporta (logicamente) a execução paralela de módulos. Para permitir que você precise ter a seguinte estrutura em sua configuração:
...
MODULE_i:
parallel_modules: 5
PARALLEL_MODULE_0:
package: my_package.my_module
Class: MyModule
arguments:
model_path: models/myModule/parameters/
...
PARALLEL_MODULE_1:
package: my_package.my_module
Class: MyModule
arguments:
model_path: models/my_module/parameters/
...
...
...
Tome cuidado! As saídas dos módulos executadas em paralelo serão embaladas em uma lista. O próximo módulo (por exemplo, MODULE_i+1 ) precisará ser capaz de lidar com esse tipo de entrada. Os módulos PLATO fornecidos não foram projetados para lidar com isso, você precisará escrever um módulo personalizado para processar a entrada de várias fontes.
Platão foi projetado para ser extensível, portanto, fique à vontade para criar seus próprios estados de diálogo, ações, funções de recompensa, algoritmos ou qualquer outro componente para atender às suas necessidades específicas. Você só precisa herdar da classe correspondente para garantir que sua implementação seja compatível com Platão.
Platão usa o PysimpleGui para lidar com interfaces gráficas do usuário. Um exemplo de GUI para Platão é implementado em plato.controller.sgui_controller e você pode experimentá -lo usando o seguinte comando:
plato gui --config CamRest_GUI_speech.yaml
Special thanks to Mahdi Namazifar, Chandra Khatri, Yi-Chia Wang, Piero Molino, Michael Pearce, Zack Kaden, and Gokhan Tur for their contributions and support, and to studio FF3300 for allowing us to use the Messapia font.
Please understand that many features are still being implemented and some use cases may not be supported yet.
Aproveitar!


